







欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
一、项目背景与意义
在数据分析和机器学习的项目中,特征提取和数据降维是两个至关重要的步骤。特征提取能够从原始数据中提取出关键信息,帮助模型更好地理解和预测数据;而数据降维则能够降低数据的维度,减少计算复杂度,提高模型的训练速度和预测准确性。基于Python的强大数据处理能力和丰富的库支持,本项目旨在实现高效、准确的特征提取和数据降维,为数据分析和机器学习项目提供有力支持。
二、技术原理
特征提取
定义:特征提取是指从原始数据中提取有用的特征,以便更好地描述和区分数据。它可以通过各种方法实现,如基于统计学的特征提取方法、基于机器学习的特征提取方法等。
方法:
基于统计学的特征提取:包括平均数、中位数、众数、方差、标准差等常见的数值型数据的统计特征,以及偏度和峰度等描述数据分布特性的指标。
基于机器学习的特征提取:如主成分分析(PCA)、独立成分分析(ICA)等,这些方法能够从数据中提取出具有代表性的特征,降低数据的维度。
Python实现:在Python中,可以使用pandas、numpy等库进行基于统计学的特征提取;使用scikit-learn等机器学习库进行基于机器学习的特征提取。
数据降维
定义:数据降维是一种将高维数据投影或转换到低维空间的技术,同时尽可能保留原数据中的关键信息。
方法:
主成分分析(PCA):通过计算数据的协方差矩阵,找到数据的主要变化方向(即主成分),然后将数据投影到这些主成分上,实现数据降维。
线性判别分析(LDA):一种经典的线性降维方法,它试图将数据投影到一个低维空间,使得同一类别内的样本尽可能接近,不同类别之间的样本尽可能远离。
奇异值分解(SVD):一种矩阵分解方法,可以将一个高维矩阵分解为几个低维矩阵的乘积,从而实现数据降维。
Python实现:在Python中,可以使用scikit-learn等机器学习库中的PCA、LDA、SVD等算法进行数据降维。
三、项目实现
数据预处理:对原始数据进行清洗、去噪、归一化等操作,以减少噪声和提高数据质量。
特征提取:根据任务需求和数据特点选择合适的特征提取方法,从原始数据中提取出具有代表性的特征。
数据降维:使用PCA、LDA、SVD等算法对提取出的特征进行降维处理,降低数据的维度和计算复杂度。
模型训练与评估:使用降维后的数据训练机器学习模型,并评估模型的性能。
四、项目特点与优势
高效性:利用Python的高效数据处理能力和丰富的库支持,实现快速、准确的特征提取和数据降维。
灵活性:根据项目需求和数据特点选择合适的特征提取和数据降维方法,提供灵活的解决方案。
可扩展性:项目采用模块化设计,方便后续添加新的特征提取和数据降维方法。
实用性:项目成果可直接应用于数据分析和机器学习项目中,提高模型的性能和效率。
二、功能
基于Python实现特征提取和数据降维
三、系统
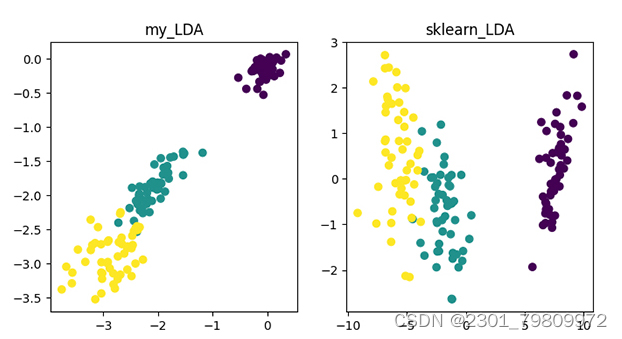
四. 总结
图像识别:在图像识别任务中,通过特征提取和数据降维提取出图像的关键特征,提高识别准确率。
自然语言处理:在自然语言处理任务中,通过特征提取和数据降维将文本数据转换为数值型特征,便于模型处理。
金融数据分析:在金融数据分析中,通过特征提取和数据降维提取出关键的市场指标和趋势,为投资决策提供支持。
推荐系统:在推荐系统中,通过特征提取和数据降维提取出用户的兴趣和偏好特征,提高推荐的准确性和个性化程度。















 1571
1571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









