






 本文详细介绍了PyTorch中Dataloader和Dataset的区别,以及如何通过Dataloader控制数据加载的batch_size和shuffle参数。通过代码示例展示了如何使用这些功能处理CIFAR10数据集,并演示了自定义数据集的创建和操作。
本文详细介绍了PyTorch中Dataloader和Dataset的区别,以及如何通过Dataloader控制数据加载的batch_size和shuffle参数。通过代码示例展示了如何使用这些功能处理CIFAR10数据集,并演示了自定义数据集的创建和操作。
一、Dateloader:为后面的网络提供不同的数据形式
1、Dataset与Dataloader的区别:
1、Dataset是告诉程序数据集在什么位置,Dataloader是将数据加载到神经网络中
2、Dataloader的作用:从Dataset中取数据,每次取多少或取哪一个是由dataloader的参数决定
3、代码实战:
(1)、测试Dataloader的batch_size参数:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 设置转换方式
trans = torchvision.transforms.ToTensor()
# 准备测试集
test_data = torchvision.datasets.CIFAR10(root = './dataset2',train = True,transform = trans,download = True)
test_loader = DataLoader(dataset = test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
# dataset:Dataset类的实例对象(无默认参数,其余的基本上都会有默认参数)
# batch_size:每次取出的数据的个数
# shuffle:判读数据集是否被打乱,如果为True,说明顺序不一样,如果为False,则说明顺序一样,一般设置为True
# num_work: 多进程进行加载数据,大部分情况下设置为0,意为采用主进程加载,如果小于0,则windows系统下可能会发生错误
# drop_lase:将数据进行整分,整分过后可能会有剩余的部分,如果设置为True,则剩余部分舍去,如果为False,则不舍弃剩余部分
writer = SummaryWriter("dataload")
# 测试batch_size参数,即如何取数据和返回数据
step = 0
for data in test_loader:
imgs,targets = data
# for each in range(64): 不建议采用这种方法,如果最后一组存储的是剩余的数据,则可能少于64张图片,会导致程序报错
# writer.add_image(str1,imgs[each],each)
# 建议采用方式如下
writer.add_images("str1",imgs,step) #与writer.add_image使用方法类似,不同的是传入不再是单个的数据,而是一个数据的合集
#在网页中的显示也将合集中所有图片拼接成的一个图片
step += 1
# 测试结果:会将图片和targets分别打包batch_size个数据集合在一起且是随机取四个数
writer.close()注意:此时drop_last设置为False,则整分过后剩余的部分也会被保存下来:最后一部分只有16张图片,并不是设置的batch_size张
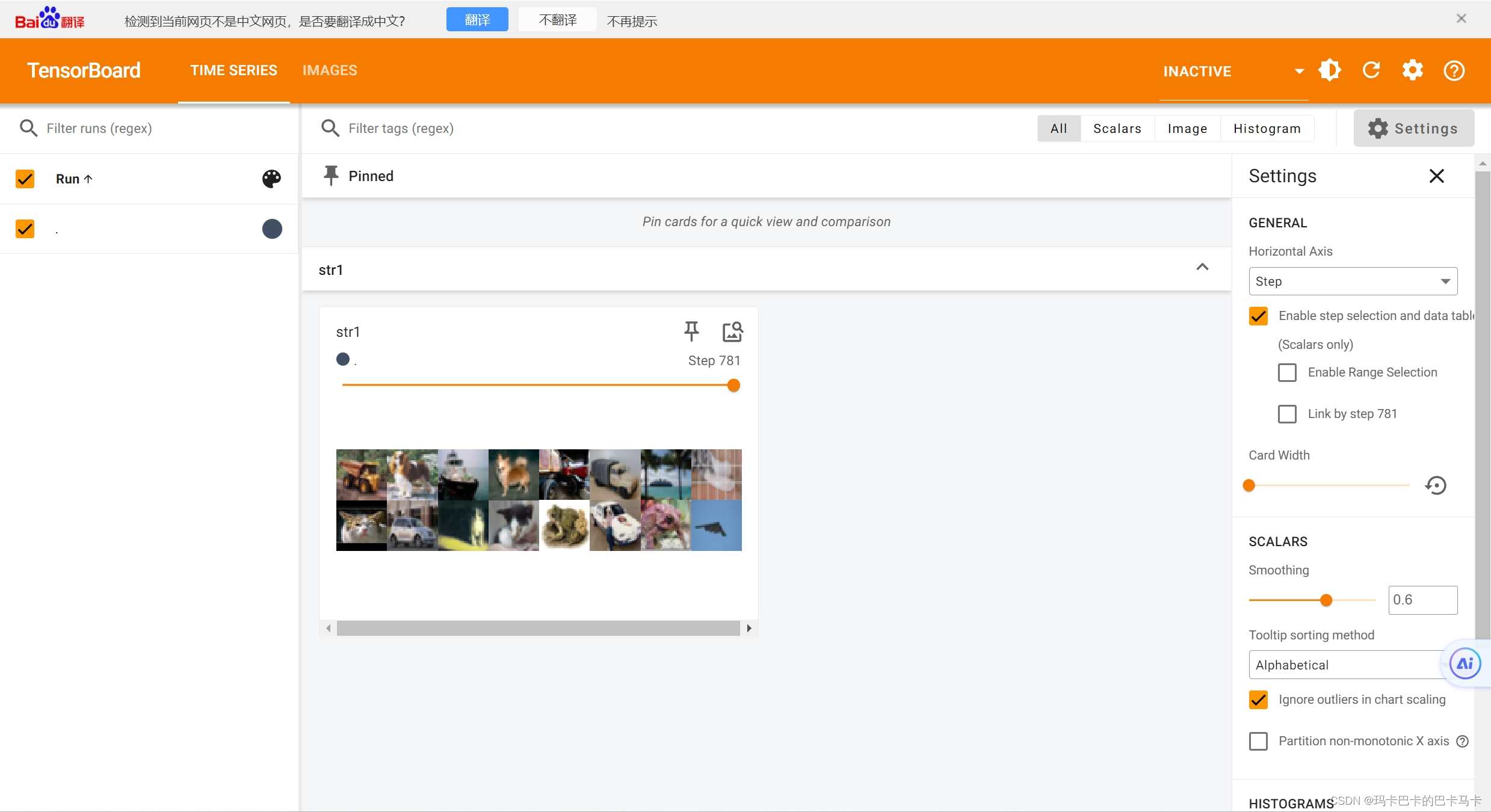
如果将drop_last设置为True,则剩余部分直接被舍弃,所有的图片都是由batch_size张小图片拼接而成,最后一张也是:
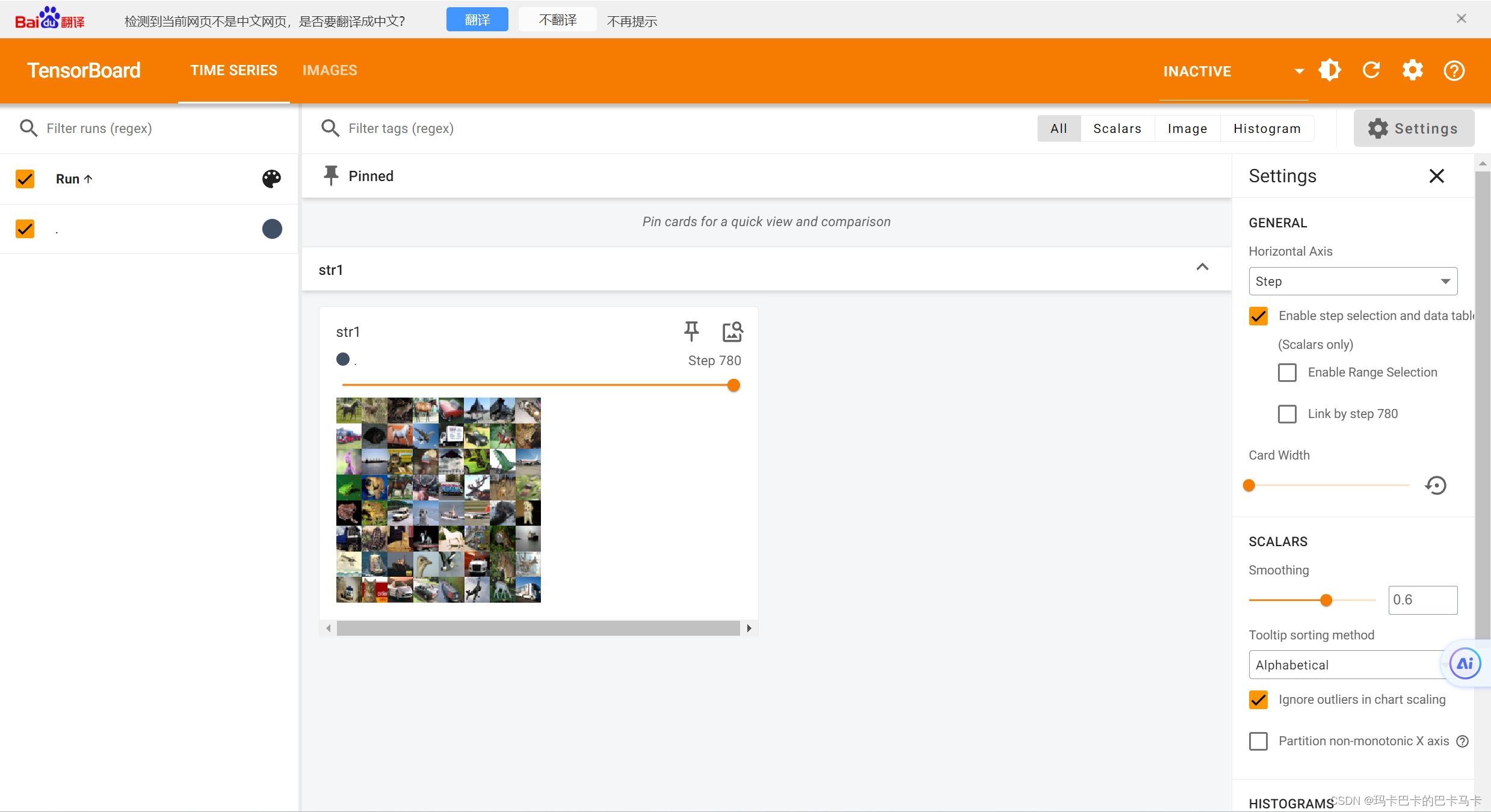
2、测试shuffle参数:
step = 0
for data in test_loader:
imgs,targets = data
# for each in range(64): 不建议采用这种方法,如果最后一组存储的是剩余的数据,则可能少于64张图片,会导致程序报错
# writer.add_image(str1,imgs[each],each)
# 建议采用方式如下
writer.add_images("str1",imgs,step) #与writer.add_image使用方法类似,不同的是传入不再是单个的数据,而是一个数据的合集
#在网页中的显示也将合集中所有图片拼接成的一个图片
step += 1
# 测试结果:会将图片和targets分别打包batch_size个数据集合在一起且是随机取四个数
# 测试shuffl参数:
# 查看第二次取数据与第一次取得的数据顺序是否一样
step = 0
for data in test_loader:
imgs,targets = data
# for each in range(64): 不建议采用这种方法,如果最后一组存储的是剩余的数据,则可能少于64张图片,会导致程序报错
# writer.add_image(str1,imgs[each],each)
# 建议采用方式如下
writer.add_images("str2",imgs,step) #与writer.add_image使用方法类似,不同的是传入不再是单个的数据,而是一个数据的合集
#在网页中的显示也将合集中所有图片拼接成的一个图片
step += 1两次读取相同的数据集,查看读取的结果图片顺序是否相同:
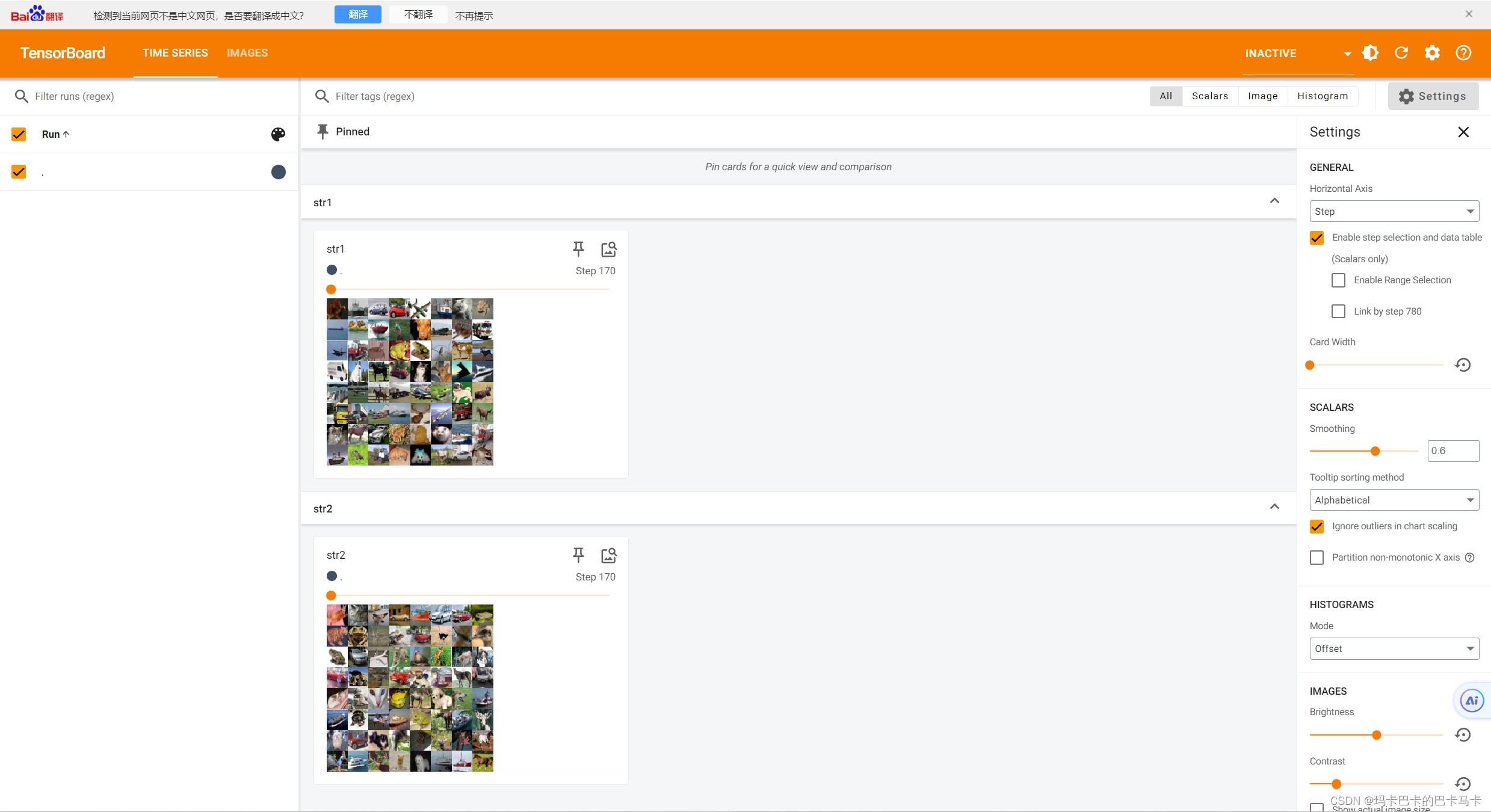 当shuffle为True时,读取结果图片顺序会不相同,当shuffle为False时,读取结果图片顺序相同
当shuffle为True时,读取结果图片顺序会不相同,当shuffle为False时,读取结果图片顺序相同
二、Dataset:用于表示一个数据集。当你想要加载自定义的数据集到PyTorch中以便进行训练和测试时,你需要继承这个基类并实现两个方法,同时提供一种方式去获取数据及其label(标签)
1、如何获取每一个数据及其label
2、告诉我们总共有多少个数据
3、Dataset类代码实战:
from torch.utils.data import Dataset
from PIL import Image
import os
class Mydata(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir # 获取保存所有照片的文件的路径
self.label_dir = label_dir # 获取需要使用的文件的路径
self.path = os.path.join(self.root_dir,self.label_dir) # 将两个路径进行拼接成相对路径
self.img_path = os.listdir(self.path) # 将路径中的每个照片的位置保存成列表,后序可以通过下标直接访问(保存的只是图片的存储码,不带有路径,具体原因可查询listdir方法的作用)
def __getitem__(self, idx):
img_name = self.img_path[idx] #此时获得的是照片的名称,如果想要打开文件,还需要获得文件的相对路径
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) #获取图片的相对路径
img = Image.open(img_item_path) # 获取图片的一个名称,使用img.show打开图片
label = self.label_dir
return img,label
def __len__(self):
return len(list(self.img_path))
root_dir = 'D:\Python项目\pytorch练习\dateset\\train'
ants_label_dir = "ants"
ants_dataset = Mydata(root_dir,ants_label_dir)
ants_img,ants_label = ants_dataset[3]
ants_len = ants_dataset.__len__()
print(ants_len)
bees_label_dir = "bees"
bees_dataset = Mydata(root_dir,bees_label_dir)
bees_img,bees_label = bees_dataset[0]
bees_len = bees_dataset.__len__()
print(bees_len)
train_dataset = ants_dataset + bees_dataset
train_img,train_dataset = train_dataset[11]
train_img.show()
1、导入os模块的主要作用是:找到数据集所在的文件并进行操作(具体操作保存至作者语雀笔记中)
2、os.path.join函数的作用:将两个路径进行拼接,并根据系统环境进行选择使用正斜杠或反斜杠
3、导入Image主要是用于对图片进行操作















 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









