






学习之前
两个基本函数:
dir(...):了解packge结构
help(...):了解函数具体用法
举个栗子:了解torch包的结构,了解cuda.is_available()的具体用法
python console中输入:
import torch
dir(torch)控制台便会输出torch包下的细分结构:

想要继续了解torch包下cuda包的结构?
dir(torch.cuda)输出如下:
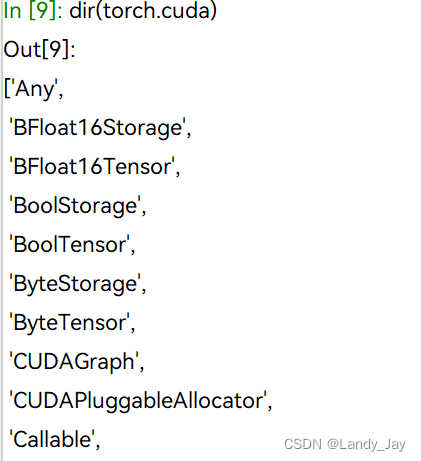
想要了解我们调用的is_available()函数的结构?

is_available结构下大部分为__xx__结构,说明is_available为一个函数,我们可以查看函数的用法。
help(torch.cude.is_available)输出如下:说明了is_available函数的返回值类型和函数概述

一、 Pytorch中的数据加载
Dataset:提供一种方式去获取数据及其label
如何获取每一个数据及其label?
如何获得一共有多少条数据?
从torch.utils.data包引入Dataset类
from torch.utils.data import Dataset
print(help(Dataset))官方对Dataset类解释如下:
Help on class Dataset in module torch.utils.data.dataset:
class Dataset(typing.Generic)
| Dataset(*args, **kwds)
|
| An abstract class representing a :class:`Dataset`.
|
| All datasets that represent a map from keys to data samples should subclass
| it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a
| data sample for a given key. Subclasses could also optionally overwrite
| :meth:`__len__`, which is expected to return the size of the dataset by many
| :class:`~torch.utils.data.Sampler` implementations and the default options
| of :class:`~torch.utils.data.DataLoader`. Subclasses could also
| optionally implement :meth:`__getitems__`, for speedup batched samples
| loading. This method accepts list of indices of samples of batch and returns
| list of samples.
|
| .. note::
| :class:`~torch.utils.data.DataLoader` by default constructs an index
| sampler that yields integral indices. To make it work with a map-style
| dataset with non-integral indices/keys, a custom sampler must be provided.
|
| Method resolution order:
| Dataset
| typing.Generic
| builtins.object
|
| Methods defined here:
|
| __add__(self, other: 'Dataset[T_co]') -> 'ConcatDataset[T_co]'
|
| __getitem__(self, index) -> +T_co
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __orig_bases__ = (typing.Generic[+T_co],)
|
| __parameters__ = (+T_co,)
|
| ----------------------------------------------------------------------
| Class methods inherited from typing.Generic:
|
| __class_getitem__(params) from builtins.type
|
| __init_subclass__(*args, **kwargs) from builtins.type
| This method is called when a class is subclassed.
|
| The default implementation does nothing. It may be
| overridden to extend subclasses.
|
| ----------------------------------------------------------------------
| Static methods inherited from typing.Generic:
|
| __new__(cls, *args, **kwds)
| Create and return a new object. See help(type) for accurate signature.
None
类定义:
Dataset()是一个抽象类,所有数据集dataset都会继承DataSet类。
抽象方法:
所有的子类都需要重写__getitem__方法,该方法用于获取每一条数据及其label,还可以选择重写__len__方法用于获取dataset的大小。
总结:
继承自 Dataset 的子类常用于机器学习和数据处理流程中,它们封装了加载、预处理和检索数据样本的逻辑。这些子类通常与 torch.utils.data.DataLoader 配合使用,以便高效地加载和处理数据。
一个简单的Dataset实现类例子:
数据集准备:https://download.pytorch.org/tutorial/hymenoptera_data.zip
数据集描述:蚂蚁蜜蜂分类数据集,数据集中有200+蚂蚁和蜜蜂的图片,分为ants和bees文件夹
class MyData(Dataset):
# 初始化函数
def __init__(self, dir_path):
# 获取当前路径下的最后一个文件夹名,用作标签路径
self.label_dir = dir_path.split("\\")[-1]
# 设置全局变量 dir_path
self.dir_path = dir_path
# 获取目录路径下的所有文件和文件夹列表
self.img_path = os.listdir(dir_path)
def __getitem__(self, idx):
# 获取每一个图片的文件名
img_name = self.img_path[idx]
# os.path.join(str1,str2,...):拼接文件路径
# 获取每一个图片的文件路径
img_item_path = os.path.join(self.dir_path, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
# 获取数据集大小
return len(self.img_path)__init__方法:
__init__方法为MyData类的初始化方法,self.属性名可以将属性声明为全局变量。
__init__方法中,需要传入dir_path参数:蚂蚁图片数据的文件路径。
self.label_dir用于存放图像的标签名,即“ant”
self.dir_path用于存放蚂蚁图片数据的文件路径,并声明为全局变量
self.img_path为一个数组,存放所有图片的文件名。os.listdir方法能将路径下的所有文件名转为数组返回。
__getitem__方法:
Dadaset的实现类需要重写__getitem__方法。传入参数idx为图片的索引。
img_name用于存放图片的文件名称用于后续拼接图片完整路径。
img_item_path为图片的完全路径,使用os.path.join方法拼接完整路径
img为根据文件路径,利用PIL库创建的Image对象,记录了图片的相关信息
label为图片对应的标签
__len__方法:
返回了数据集的大小,即图片文件的个数
dir_path_ant = "D:\\coding\\pythoncoding\\dataset\\hymenoptera_data\\hymenoptera_data\\train\\ants"
dir_path_bee = "D:\\coding\\pythoncoding\\dataset\\hymenoptera_data\\hymenoptera_data\\train\\bees"
# 根据文件路径,创建蚂蚁数据集
ant_dataset = MyData(dir_path_ant)
# 根据文件路径,创建蜜蜂数据集
bee_dataset = MyData(dir_path_bee)
img, label = ant_dataset[0]
img_bee, label_bee = bee_dataset[0]
# 将蚂蚁数据集和蜜蜂数据集合并,数据集合并数据顺序按照传参顺序
all_dataset = ant_dataset + bee_dataset两个子dataset可以拼接为一个大dataset,数据的排列顺序按照子dataset拼接的先后顺序。
二、Tensorboard的使用
Tensorboard 是一个由 TensorFlow 团队开发的强大可视化工具,但它并不局限于 TensorFlow,也可以与 PyTorch 等其他深度学习框架一起使用。在 PyTorch 中,通过 TensorboardX 库可以方便地集成 TensorBoard 的功能,以便监控和分析模型的训练过程,如损失(loss)曲线、指标(metrics)变化、网络权重分布、激活图等。
使用前需在conda环境中安装tensorboard包
pip install tensorboard2.1 SummaryWriter
SummaryWriter 类在 TensorFlow 和 PyTorch 中是用于与 TensorBoard 进行交互的核心组件。TensorBoard 是一个可视化工具,它可以帮助用户理解、调试和优化 TensorFlow 或 PyTorch 模型的训练过程。SummaryWriter 是一个记录器,它将训练过程中的数据写入事件文件(.tfevents),这些文件随后会被 TensorBoard 读取并展示为各种图表和面板。
__init__方法:
log_dir: String:日志输出的文件夹
当你创建一个 SummaryWriter 实例时,你可以指定一个目录,所有写入的数据都会保存在这个目录下的事件文件中。如果不指定目录,它会默认创建一个临时目录。
writer = SummaryWriter("logs")add_scalar方法:
用于记录单个标量值随时间变化的过程,常用来绘制训练过程中的损失(loss)、准确率(accuracy)或其他性能指标。
tag: String:用于标识你要记录的度量值。例如,你可以使用 'Loss'、'Accuracy' 或者其他的自定义标签。在 TensorBoard 中,这个标签将作为图表的标题显示。
scalar_value: float:想要记录的标量数值。在训练过程中,这通常是某个指标在当前时间步的值,比如损失函数的值或者准确率。对应图表的Y轴。
global_step: int:当前的时间步或迭代次数。它用于在 TensorBoard 中沿着 x 轴绘制数据。如果省略,global_step 将默认递增,但通常建议明确指定以保持数据的清晰性。对应图表的X轴。
一个简单的add_scalar实例:绘制y=x的图像
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# writer.add_image()
# 简单地绘制一个y = x的图像
for i in range(100):
writer.add_scalar("y = x", i, i)
writer.close()随后可以发现当前文件路径下自动创建了logs文件夹,并添加了文件。
命令终端中输入如下命令:
tensorboard --logdir ...\logs文件绝对路径\logs --port 指定端口号
便可查看绘制的图像。
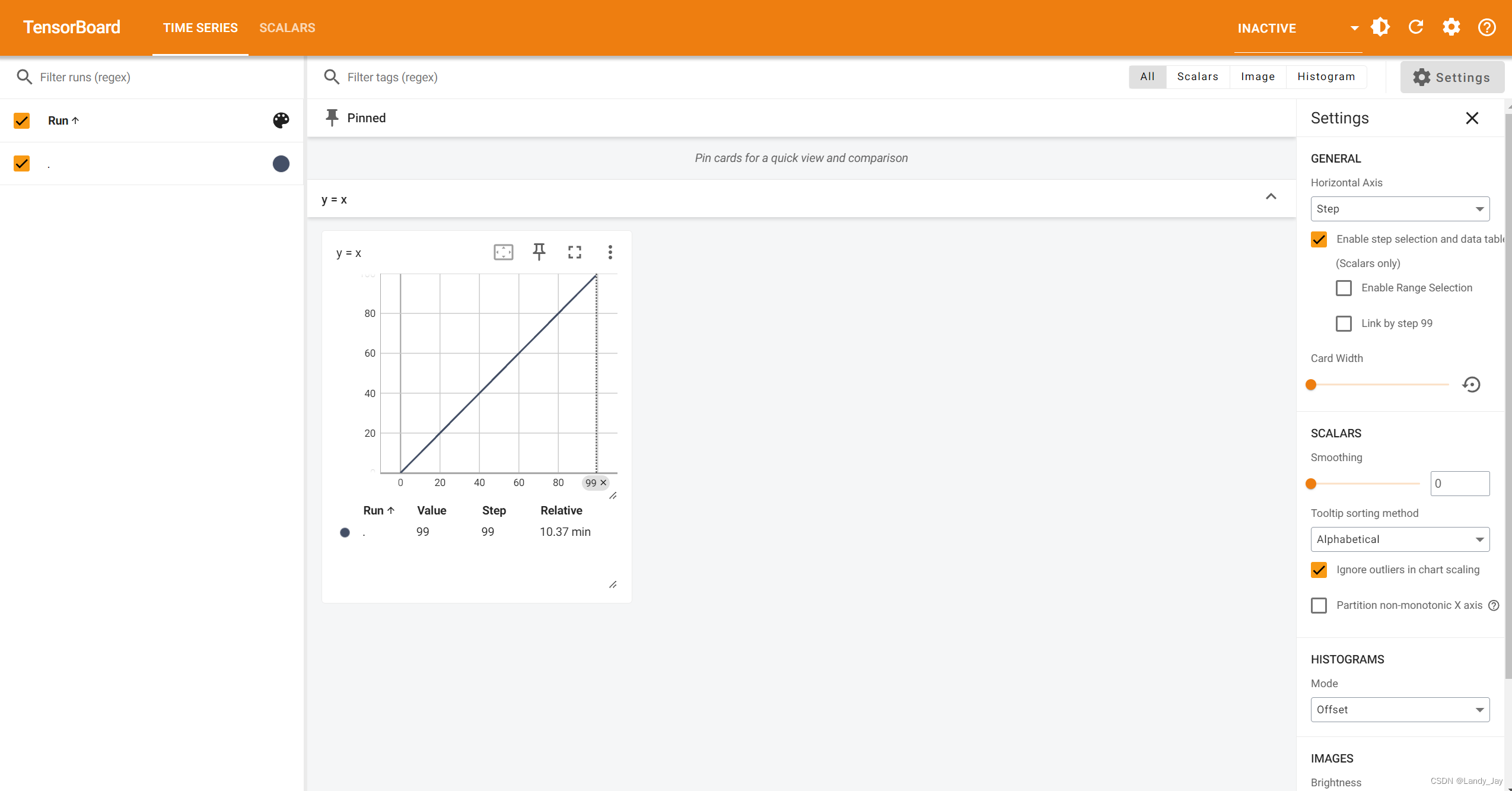
如果遇到图像成环:

最右侧的smooth值选择为0即可

add_image方法:
该方法允许将图像数据记录到 TensorBoard 中,这对于可视化网络的输入、中间层输出或是特征图等非常有用。
tag: String:用于标识图像的类别或来源。例如,你可以使用 'Input Image'、'Feature Map Layer3' 等作为标签,这将在 TensorBoard 中作为图像的标题显示。
img_tensor: torch.Tensor / np.ndarray:这是你要记录的图像数据,可以是 PyTorch 张量或 NumPy 数组。图像数据必须符合指定的维度顺序(默认是 CHW,即通道、高度、宽度)。
global_step: int:同 add_scalar 方法中的含义,用于标注图像所属的时间步或迭代次数,有助于在时间序列上定位图像。
dataformats: String:指定图像数据的维度顺序。默认为 'CHW',但如果你的数据是 (H, W, C) 格式,你需要设置为 'HWC'。确保数据格式正确,否则图像可能无法正确显示。
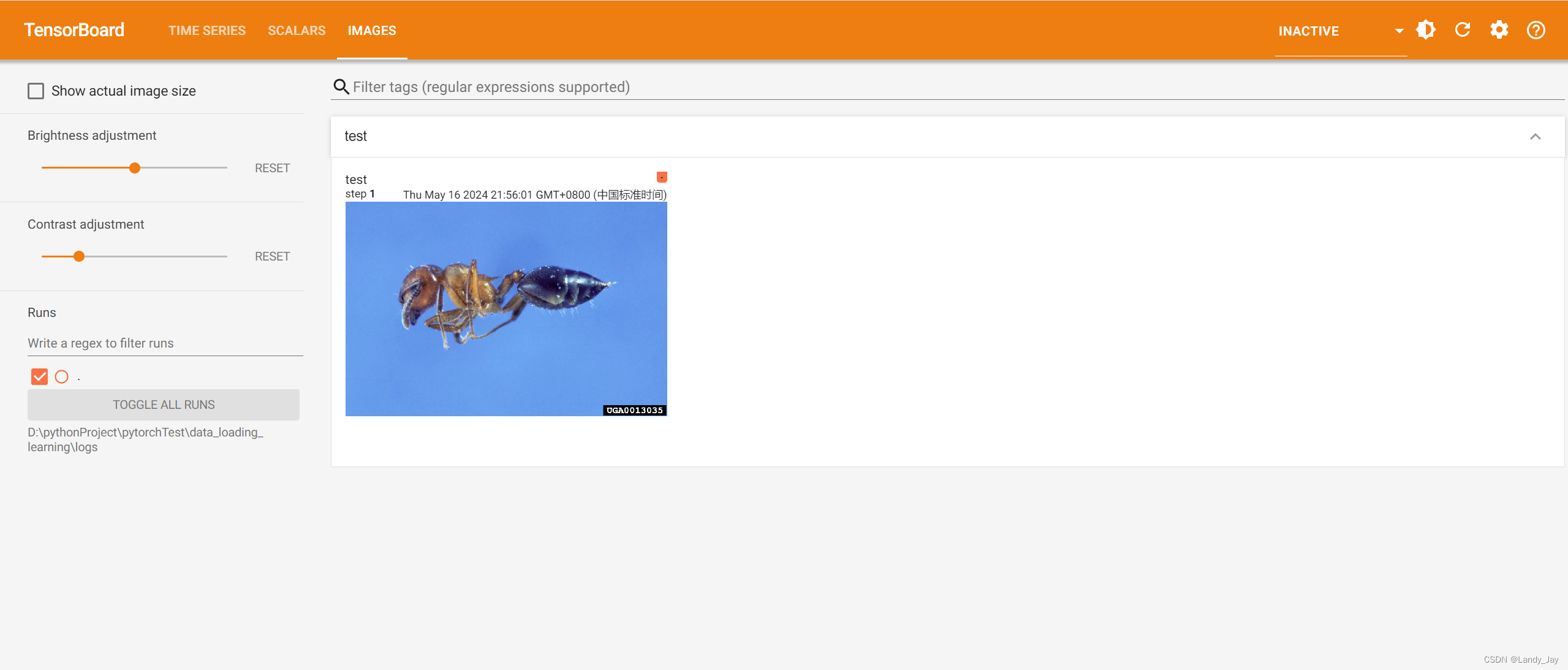
一个简单的add_image实例:
import numpy as np
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
image_path = "D:\\pythonProject\\pytorchTest\\dataset\\practice_dataset\\train\\ants_image\\0013035.jpg"
image = Image.open(image_path)
image.show()
# PIL型的图片对象转为np型图片对象
img_array = np.array(image)
# np.ndarray一定要指定dataformats="HWC"!!!
writer.add_image("test", img_array, 1, dataformats="HWC")
# 记得一定要写writer.close(),否则无法读取
writer.close()运行成功后,便可以查看图片,可以用于检测训练时每一步输入了哪些图片。
三、Transforms的使用
3.1 transforms的结构及用法
class ToTensor:将一个PIL Image或np.ndarray转化为tensor
class ToPILImage:将图片转为PILImage对象
class Compose:将多个transforms组合
用法:将图片转为Tensor数据类型
3.2 tansforms.ToTensor()
实例化transforms.ToTensor()类对象,将PIL.Image转化为Tensor
from torchvision import transforms
from PIL import Image
# 通过transforms.ToTensor解决两个问题
# transforms如何使用?
# 为什么我们需要Tensor数据类型?
image_path = "D:\\pythonProject\\pytorchTest\\dataset\\practice_dataset\\train\\ants_image\\0013035.jpg"
image = Image.open(image_path)
# 使用transforms.ToTensor()将PIL.Image转化为Tensor
trans_tensor = transforms.ToTensor()
tensor_img = trans_tensor(image)
3.3 为什么需要Tensor数据类型?
Tensor是包装了神经网络所需要的基本参数的数据类型
3.4 torchvision数据集
PyTorch官方提供了许多数据集,我们可以通过代码直接调用,以CIFAR10数据集为例:
数据集介绍:60000张32x32px 的彩色图像,分为10个类别,每个类别6000张图,有50000张训练图像和10000张测试图像
获取数据集:
# 创建transform实例,transforms多用于dataset实例化的transform属性中
dataset_transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# root:数据集的存放路径
# train:是否为训练集
# download:是否需要下载
# transform:transform实例
train_set = torchvision.datasets.CIFAR10(root="../dataset",train=True,transform=dataset_transforms,download=True)
test_set = torchvision.datasets.CIFAR10(root="../dataset",train=False,transform=dataset_transforms,download=True)
# img:图片对象,target:图片标签(图片类型的idx)
img, target = train_set[0]获取数据集后便可通过下标访问数据集中的数据对象
四、DataLoader的使用
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)dataset: Dataset :需要加载的数据集
batch_size: int :采样数
shuffle: bool:打乱顺序
num_workers: int:运行进程数。默认为0,代表运行主进程
drop_last: bool:是否舍去多余的sample
以torchvision数据集为例:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# 准备的测试集数据
test_set = torchvision.datasets.CIFAR10(root="../dataset",train=False,transform=dataset_transforms,download=True)
# 实例化DataLoader对象
# 当batch_size=4时,dataloader每次从dataset中取出4个数据,打包返回
test_loader = DataLoader(dataset=test_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
# 测试数据集中第一个样本
img, target = test_set[0]
print(img.shape)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("epoch:{}".format(epoch),imgs,step)
step+=1
writer.close()dataset=CIFAR的测试集
batch_size=64 每次从dataset采取64个样本为一组
shuffle=True 每次循环打乱数据
num_workers=0 使用主进程
drop_last=False 不会省去最后不满足一个batch_size的数据















 1917
1917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









