







Sqlalchemy基本使用
前言
SQLAlchemy 是一个功能强大的 Python SQL 工具包和对象关系映射(Object-Relational Mapping ORM)框架,它提供了全功能的数据库抽象层和透明的数据库转换,使得开发者能够以面向对象的方式操作数据库,同时支持多种数据库系统,极大地简化了数据库编程的复杂性。
一、SQLalchemy的安装
在终端使用pip install SQLAlchemy==2.0.36(使用2.0.36版本)
二、使用步骤
1.基本配置
from sqlchemy import create_engine
HOST = "127.0.0.1" #数据库地址 这里使用本地数据库用localhost也可以
PORT = "3306" # 数据库端口mysql默认是3306
DATABASENAME = "test_db" #数据库名称
USE = "root" #账户名称
PWD = "123456" #密码
DB_CLASS = 'mysql' #数据库类型
DRIVER = 'pymysql' #数库驱动
#数库的链接url组成
DB_URL = f"{DB_CLASS}+{DRIVER}://{USE}:{PWD}@{HOST}:{PORT}/{DATABASENAME}"
#获取引擎
engine = create_engine(DB_URL) #通过engine可以运行sql语句
使用之前要安装pymysql使用命令pip install pymysql
2.基本使用
2.1插入数据
from sqlalchemy import Table, Column, Integer, String, MetaData
metadata = MetaData() #sqlalchemy用来存放表的集合
tab = Table(
"test_tab",
metadata,
Column("id", Integer, primary_key=True),
Column("name", String(8)),
)#声明一个表name为'test_tab'
#创建一个表结构,如果不出意外的话运行到这里数据库中就会出现一个名为test_tab的表
#并且拥有2个列id和name字段
metadata.create_all(engine)
#使用with语句可以保证代码执行结束后关闭与数据库的连接
with engine.connect() as conn:
sql = tab.insert().values(name="data1")#插入1条数据
print(sql)#打印sql
conn.execute(sql)#执行sql
conn.commit()#提交事务,提交后表中才有数据
可以看到print输出为

说明sqlalchemy已经把tab.insert().values(name="data1")映射成了对应的sql语句
并且数据已经插入到表中(Table里面把列都保存在了columns属性中并且提供了简写c以供访问列)

2.2查找数据
with engine.connect() as conn:
sql = tab.select().where(tab.c.id == 1)
print(f"SQL: {sql}")
result = conn.execute(sql) # 执行sql语句
data = result.fetchone() # 返回第一条数据
print(f"DATA: {data}")
运行结果如下

2.3更新数据
with engine.connect() as conn:
sql = tab.update().where(tab.c.id == 1).values(name="new_data")
print(f"SQL: {sql}")
result = conn.execute(sql) # 执行sql语句
conn.commit() # 提交事务
data = conn.execute(tab.select().where(tab.c.id == 1)).first() # 查询数据
print(f"DATA: {data}")
运行结果如下

2.4删除数据
with engine.connect() as conn:
sql = tab.delete().where(tab.c.id == 1)
print(f"SQL: {sql}")
result = conn.execute(sql) # 执行sql语句
conn.commit() # 提交事务
data = conn.execute(tab.select().where(tab.c.id == 1)).first() # 查询数据
print(f"DATA: {data}")
运行结果如下

可以看到输出结果为None说明已经成功删除
3.使用ORM映射类的方式
from sqlalchemy.orm import declarative_base
Base = declarative_base() #通过此函数获得一个DeclarativeBase对象,然后可以通过它来用python的类的方式定义表结构
class TestOrmTab(Base):
"""
通过继承Base的方式可以将表结构映射到python的类型
"""
__tablename__ = 'test_orm_tab'#指定了表的名称,如果没有填写则使用类名
id = Column(Integer, primary_key=True, autoincrement=True)#声明一个名称为id的列,如果没有传入名称则使用变量名
name = Column('name', String(16))
#Base里面有meatadaa对象用来存储表结构,创建表的方式与2.1一样只是多了个Base
Base.metadata.create_all(engine)
3.1通过orm插入数据
通过orm映射类的方式的增删改查有点不一样
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(engine) #建立一个会话对象
with Session() as session:
data = TestOrmTab(name="data1") # 创建一个实例
session.add(data) # 添加到session
#也可以通过session.add_all(实例列表)传入一个列表将列表里面的数据都插入。
session.commit() # 提交事务
可以看到创建数据是通过类的方式。
3.2通过orm查找数据
通过orm的删改查都是通过Query对象来实现的
with Session() as session:
sql = session.query(TestOrmTab).filter_by(id=1)
# session.query(TestOrmTab).filter(TestOrmTab.name == 'data1')通过filter可以实现更加复杂的操作
#所有的删改都是建立在先查询到数据的基础之上的,要不然就是更新或者删除整张表,要先拿到数据才能再做操作。
print(f"SQL: {sql}")
result = sql.all() #通过all函数可以拿到查询到的所有对象一个list
print(f"Result: {result}")
data = result[0]
print(f"Data: {data.name}, {data.id}")
运行结果如下

可以看到通过query对象同样可以把操作映射到对应的sql语句,并且通过更加灵活和方便(毕竟是操作的python对象)
result的每个数据都是我们定义的TestOrmTab对象实例,要拿到数据就直接通过python的方式即可。
3.3更新和删除对象
通过3.2我们已经可以拿到数据了,可以直接操作拿到的类的实列,然后commit提交即可
下面给出示例
with Session() as session:
data = session.query(TestOrmTab).filter(TestOrmTab.id == 1).first()
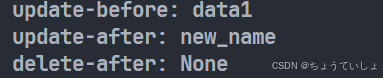
print(f"update-before: {data.name}")
data.name = "new_name" #直接操作python对象就可以更改数据库的数据(当然commit之后更改才会生效)
session.commit()
data = session.query(TestOrmTab).filter(TestOrmTab.id == 1).first()
print(f"update-after: {data.name}") # new_name
session.delete(data) #删除则是通过session对象里面的delete函数
# 还可以通过session.query(TestOrmTab).filter(TestOrmTab.id == 1).delete(sync_session=False)来删除数据
# sync_session=False不同步会话中的对象状态。即删除操作不会影响当前会话中的任何对象状态。
# 这通常在你对性能有较高要求,但不需要处理会话中相应对象的情况时使用。适用于批量删除的场景。
session.commit()
data = session.query(TestOrmTab).filter(TestOrmTab.id == 1).first()
print(f"delete-after: {data}") # None
运行结果如下
4.orm操作中的一些常用比较函数
def create_data():
Base.metadata.drop_all(engine)#表的结构依然是3中的,这是通过drop_all我把表删了因为主键自增影响我插入下面的数据
Base.metadata.create_all(engine)
with Session() as session:
for i in range(10):
data = TestOrmTab(name=f"name{i+1}", id=i + 1)
session.add(data)
session.commit()
create_data()
通过运行create_data函数test_orm_tab表中就会有10条数据了
常用的函数有
from sqlalchemy import and_, or_, not_, asc, desc
4.1 and_,or_,not_的使用
def print_data(data: list[TestOrmTab]):
for i, item in enumerate(data):
print(f"第{i+1}条数据:<{item.id},{item.name}>")
with Session() as session:
#and_的使用
data = session.query(TestOrmTab).filter(TestOrmTab.id > 2, TestOrmTab.id < 6).all()
#filter中使用,隔开的条件默认就是and
#为了可读性还是建议使用data = session.query(TestOrmTab).filter(and_(TestOrmTab.id > 2, TestOrmTab.id < 6)).all()
#or_的使用
data = (
session.query(TestOrmTab)
.filter(or_(TestOrmTab.id < 2, TestOrmTab.id > 9))
.all()
)
#同理not_
data = session.query(TestOrmTab).filter(not_(TestOrmTab.id < 2)).all()
#这些条件也可以搭配使用
data = (
session.query(TestOrmTab)
.filter(
or_(
and_(TestOrmTab.id > 1, TestOrmTab.id < 5, not_(TestOrmTab.id == 3)),
TestOrmTab.id > 9,
)
)
.all()
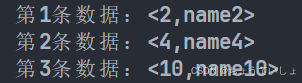
)#这个条件就是找id>1且小于5且不等于3,或者id>9的数据
print_data(data)
运行结果如下
4.2asc和desc函数的使用
和sql语句中的一样这2个函数是让数据通过指定字段排序的分别代表升序和降序
示例代码如下
with Session() as session:
#排序是要使用Query对象中的order_by函数(我这里没有给过滤条件默认就是操作的整张表)
data = session.query(TestOrmTab).order_by(asc(TestOrmTab.id)).all()
#其实order_by默认就是升序的所有这代码等价于
#data = session.query(TestOrmTab).order_by(TestOrmTab.id).all()
#其实Column类中就有desc和asc函数,所以这代码也等价于
#data = session.query(TestOrmTab).order_by(TestOrmTab.id.asc()).all()
#降序也同理
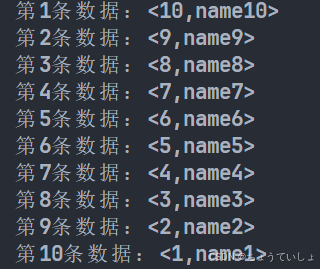
data = session.query(TestOrmTab).order_by(desc(TestOrmTab.id)).all()
print_data(data)
代码运行结果如下
三、总结
总的来说sqlalchemy提供的这种orm关系映射对不熟悉sql语句的人来说十分的友好。让python操作数据库变的十分的简单。分享结束,谢谢!!!
更多关于sqlalchemy的操作请见
Sqlalchemy中的Query对象的使用
Sqlalchemy中的数据类型
Sqlalchemy中的relationship的使用
四、补充
1.使用原生sql语句
sqlalchemy也能够使用原生的sql语句,在一些复杂的场景下非常有用。
示例如下
from sqlalchemy import text
with engine.begin() as conn:
#使用engine中的begin函数可以在with中没有发生异常时自动提交事务,发生异常时自动回滚。
sql = "SELECT * FROM test_orm_tab"
result = conn.execute(text(sql))#将sql字符串用text包裹
print(result.all())
"""
#Session对象也可以使用
#这里的begin也是保证在with中没有发生异常时自动提交事务,发生异常时自动回滚。当然我们这里是查找数据,似乎用处不大
with Session.begin() as session:
sql = "SELECT * FROM test_orm_tab"
result = session.execute(text(sql))
print(result.all())
"""
运行结果如下

2.sqlalchemy新特性
在sqlalchemy2.0版本引入了mapped_column, 它提供了更加清晰的接口,可以与Mapped搭配使用
Mapped用于类型注解,使代码的可读性更高
from sqlalchemy.orm import Mapped, mapped_column
class TestMapped(Base):
__tablename__ = "test_mapped"
# 可以看到使用这样的搭配,甚至可以不用标明Integer类型,而是直接使用Mapped[int]也是更加的方便
id: Mapped[int] = mapped_column(primary_key=True, autoincrement=True)
name: Mapped[str] = mapped_column(String(16))
可以看到mapped_column只是一个函数,它的作用就是将传的参数传给MappedColumn并返回一个实例(这种方式只适用于orm定义,不能直接用在Table中)

从下面这张图可以看到MappedColumn里面也是引用了Column对象的,只是MappedColumn更加的清晰,同时这也是官方文档推荐的方式。(就用Column也可以)



















 5650
5650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











