









既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
补充点:
1.Region是HBase集群分布数据的最小单位
2.多个同样的Region不可存在于同一个RegionServer下
HLog:WAL日志
Store:存储区
MemStore:相当于缓存区
StoreFile:对HDFS上文件(HFile)的包装,其存储了映射信息【HBase存储位置,DataNode位置…】
HFile:存储于HDFS上的文件,相当于一个block
读取操作:
ZooKeeper与HMaster和备用的HMaster backup之间都具有心跳。
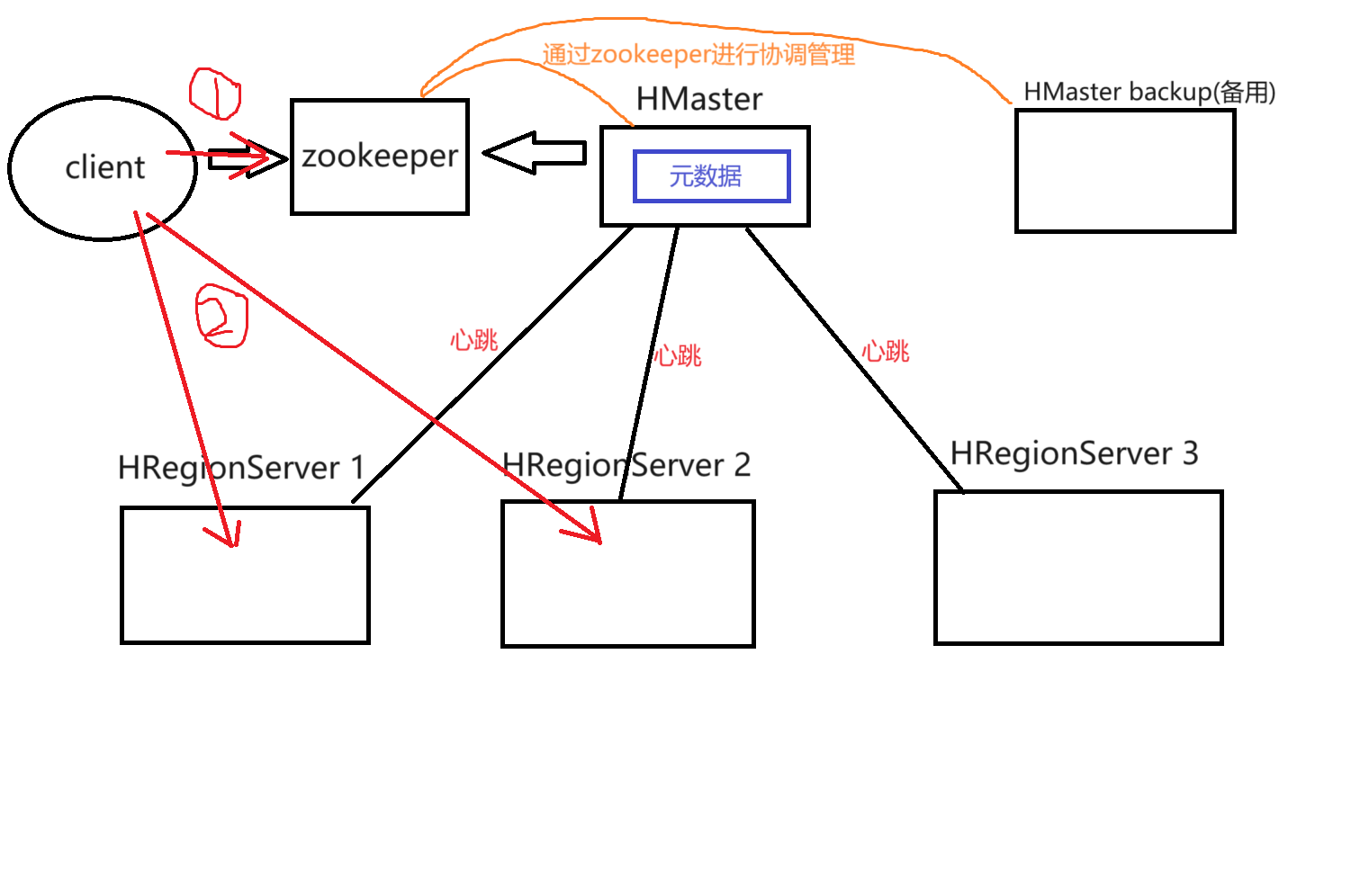
具体过程讲解:
1.客户端通过zookeeper找到HMaster【定期】通过心跳发送过来的表的元数据信息【hbase:meta】。
2.客户端获取元素信息后,就会得知表在哪台或哪几台HRegionServer上,就可直接去读取HRegionServer上的数据。
写入操作:基于内存(MemStore)写
ZooKeeper与HMaster和备用的HMaster backup之间都具有心跳。

具体过程讲解:
客户端进行建表操作后,表会在一台机器上形成一个Region【Region为基本单位】。客户端会通过put操作先让数据进入HLog中去【容灾性:便于恢复】,然后再进入Region中的MemStore中去,就此写入的操作完成。【只需写到内存(MemStore)中就算完成操作了】
后续过程补充:可以进行配置来控制MemStore的溢写条件【一定时间间隔溢出一次(3s左右)或者一定数量溢出一次】。MemStore溢写一次形成一个StoreFile,StoreFile包装了HFile。Hfile借助DFS Client写入HDFS中的DataNode中的block上面。
注意:当一个Region写满后,会进行<伸缩机制>,在另一台机器上形成一个Region继续书写。
逻辑架构(数据层面)
HBase表的逻辑结构图:

名词解释:
- Column Family(列族):HBase中的每个列都归属于某个列族,列族不能改变,一行可有多个列族,一个列族可有任意个列。
- Column(列):类似于关系型数据库中的列名。一般都是从属于某个列族,跟列族不一样,这些列都可以动态添加。
- RowKey(行键):行键是HBase记录条目的主键,物理存储时会按照RowKey的字典序排序存储,HBase基于RowKey实现索引。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
续会持续更新**















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









