







 本文介绍了MapReduce作为Hadoop核心技术在大数据处理中的重要性,详细阐述了其工作原理、编程模型,包括Map和Reduce函数,以及在数据统计、分析、挖掘和文本处理中的应用。
本文介绍了MapReduce作为Hadoop核心技术在大数据处理中的重要性,详细阐述了其工作原理、编程模型,包括Map和Reduce函数,以及在数据统计、分析、挖掘和文本处理中的应用。
随着大数据时代的到来,数据量的快速增长使得传统的数据处理方式难以满足需求。Hadoop作为开源的大数据处理框架,以其高效、可扩展和容错性强的特点,成为了大数据处理领域的佼佼者。而MapReduce作为Hadoop的核心技术之一,更是为大数据处理提供了强大的计算能力。本文将深入探讨MapReduce分布式计算框架的原理、编程模型以及其在大数据处理中的应用。
一、MapReduce简介
MapReduce是一种编程模型,它允许开发者将复杂的计算任务拆分为简单的Map和Reduce两个阶段,从而实现对大规模数据集的并行处理。在Hadoop中,MapReduce被封装为一个独立的计算框架,为开发者提供了方便的编程接口和强大的计算能力。
1.定义:MapReduce是一个分布式运算程序的编程框架,其核心功能是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
一个基本完整的MapReduce程序流程,包括:数据分片-数据映射-数据混洗-数据归约-数据输出
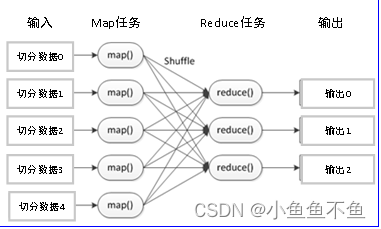
二、MapReduce的工作原理
MapReduce的工作原理可以概括为“分而治之”。首先,Map阶段将输入数据划分为多个数据块,并分发到集群中的各个节点上进行处理。每个节点上的Map任务读取数据块中的记录,并应用Map函数进行处理,生成一系列的中间键值对。然后,MapReduce框架会对这些中间键值对进行洗牌(Shuffle)操作,即按照相同的键进行分组和排序。最后,在Reduce阶段,系统将分组后的键值对分发到Reduce节点上进行处理。每个Reduce任务读取与自己相关的键值对,并应用Reduce函数进行归约操作,生成最终的输出结果。
1).Map阶段处理过程
a. 对于输入文件进行键值对组合,即切割出每个单词,并发配初始频数1。
b. 如,Hello组成<Hello , 1>,其中,Hello是键;1是键值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 31
31

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









