






一 快速排序的优化
1.在区间取随机数
2. 三数取中
二 快速排序的其他版本
1. 挖坑法
2. 前后指针法
三 非递归的快速排序
四 归并排序
1.递归归并排序
2.非递归归并排序
五 非比较排序
一: 快速排序的优化
1-1分析为什么要优化:
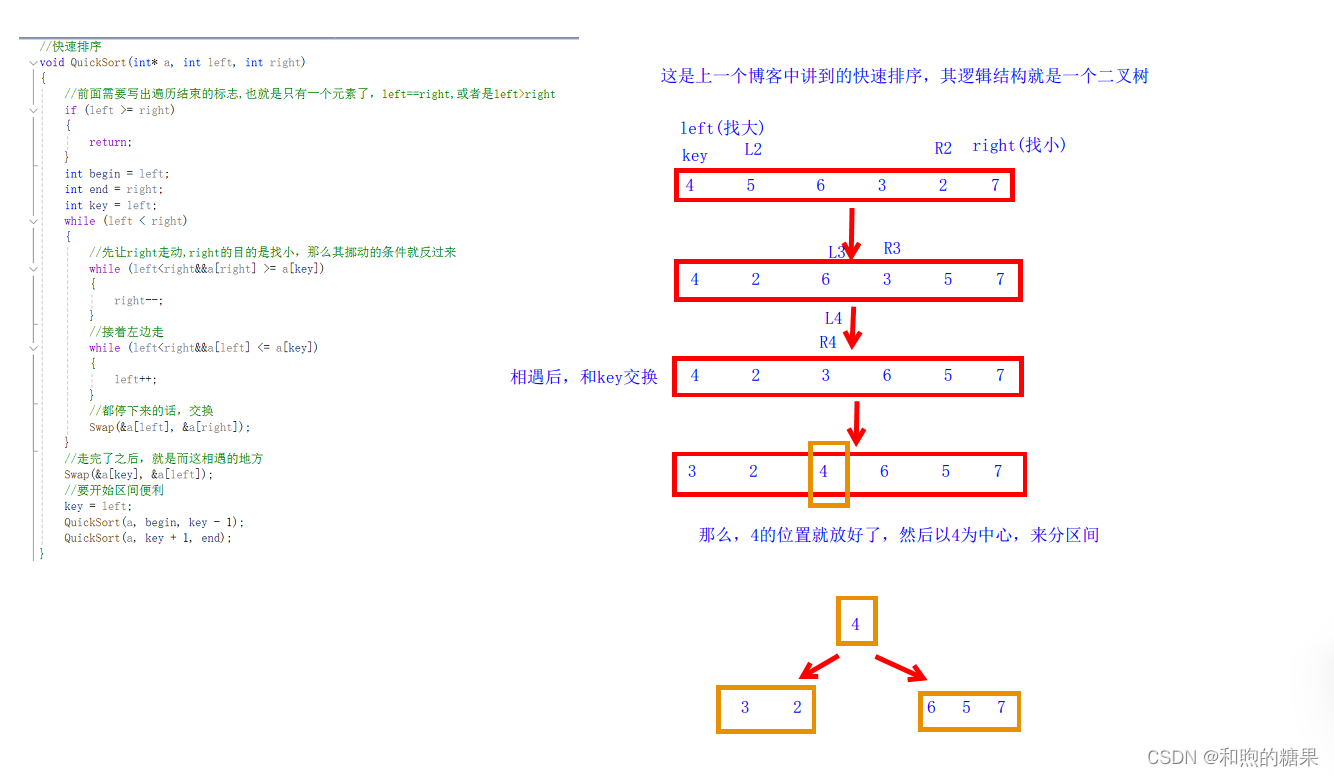
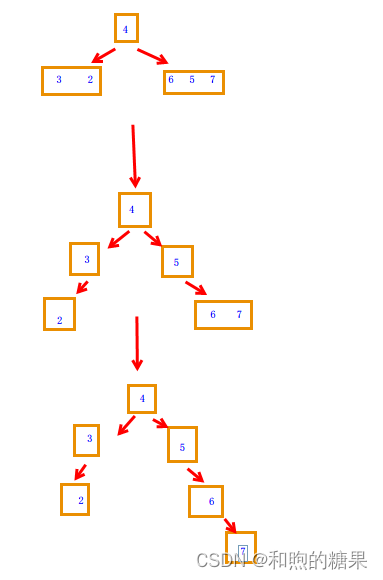
分析它的逻辑结构,就是类似于二叉树,第一层是2^0,第二层是2^1……这样子下去,在最后一层就是2^(h-1),那么如果有N个数据,其深度就是log(N+1),一般写成logN,那么,其时间复杂度就是(N*logN)。但是,这只是比较好的情况,如果是最糟糕的情况呢?首先要知道,什么时候是最糟糕的情况,也就是有序的时候:升序或是降序,为什么这么说呢,大家可以看一下下面的例子。
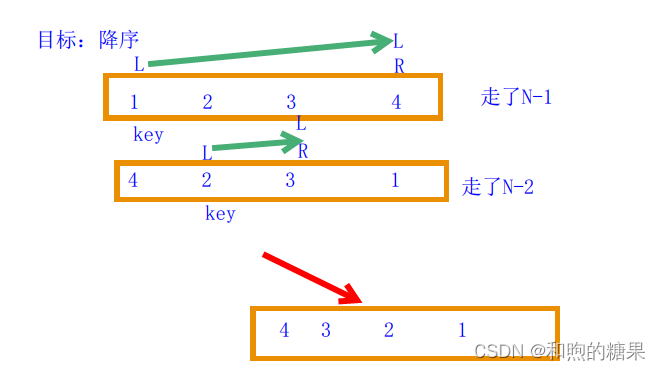
这里只有一点数据,所以读者们可能觉得没有什么大问题,但是如果数据扩大到一百万,那么运行效率就会大大降低,这是因为其是在走(N-1)到(N-2)到(N-3)……直到1,那么根据等差数列的计算,其时间复杂度不久飙升为O(N^2)吗,速率肯定大大的降低,因此,程序员们就想出了一些优化的方法。
1-2 方法一_随机优化的思想核心:
因为其担忧的是有序或是预有序,那么就可以把有序变为不有序,也就是可以将一些区间中的值和第一个值经行交换,让key不是最小也不是最大。
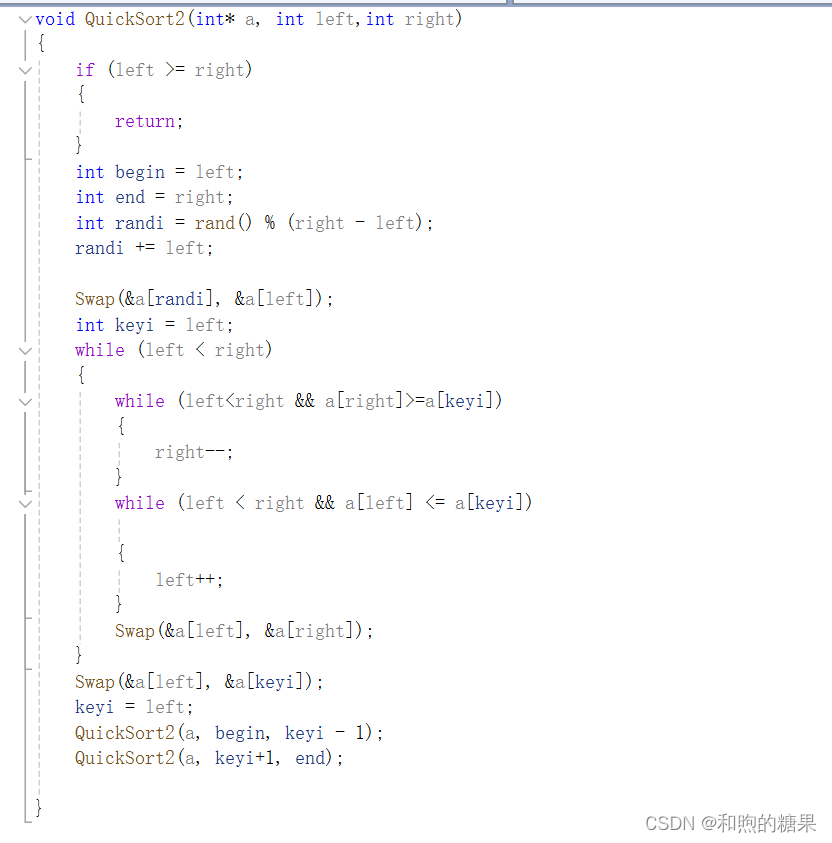
1-3 代码实现:
1-4方法2_三数中值
方法的思想核心:
因为每次比较理想的状态就是这个key值是可以被放置在中间的,这样子每次分区间的时候,都可以比较好的分为两边,因此就有一些大佬想出了利用中间的数值来作为key,就是需要找到区间中的中间的数,来将其最为key。
代码实现:


二 快速排序的其他版本
2-1 挖坑法
分析:
其实其本质和第一种快速排序的方法是一样的,只是,其把key一开始占据的值作为坑,将key当作已经被取出来了,而其之后的步骤和第一种快速排序的方法相差不大,还是先让right走(如果是为实现降序,就需要想让left先走,其任务是找小,这次的分析是以实现升序为目的),right找到了小于key的值后,把这个值传入到第一个坑中,那么这个right所在的位置就变为新的坑,然后再让left走,left找到了大于key的值,就把这个大的值传入到right所在位置的坑中,实现了把大的数值往后靠,就这样持续下去,直到left和right相遇,那么这一处就变为新的坑,用来存放key。其本质上还是和第一种quicksort排序思想一致,只不过是把swap(数据交换)变为了存放数据后再覆盖数据。
代码实现:



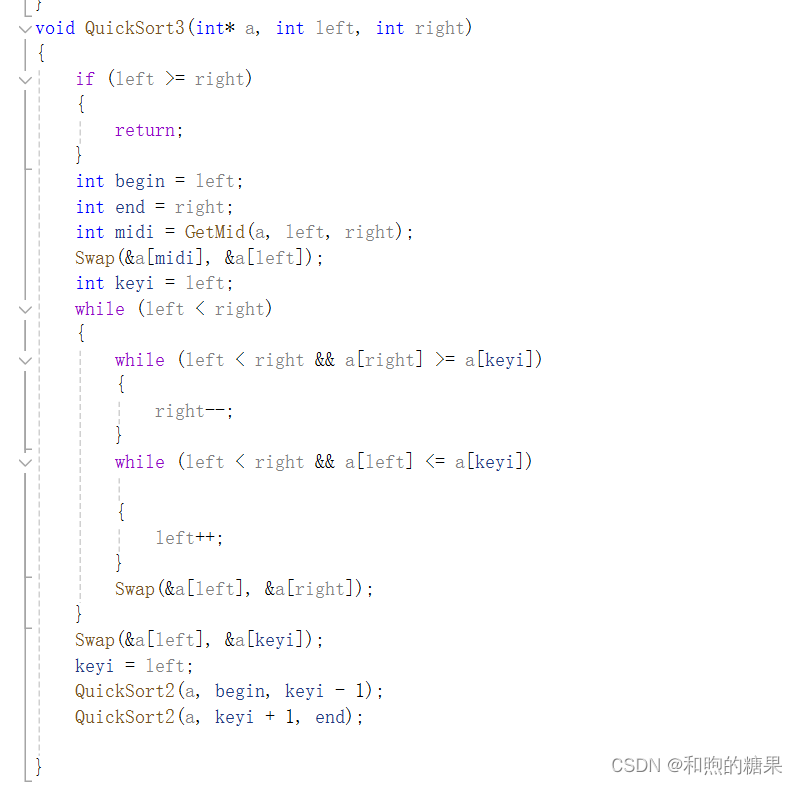
2-2 前后指针法
核心思想:
其不同于前面两种快速排序的方法在于其两个指针的位置不是左右两边,而是一前一后,对于先走的指针,代码中用cur表示,其目的是找到小于key的值,找到了小于key的值后,prev(另一个指针)就会往前走一步,然后进行交换,其中cur的任务是找小,prev的任务是找大,然后进行交换,目的是把小的值往前放置,大的数值往后放置。
代码实现:
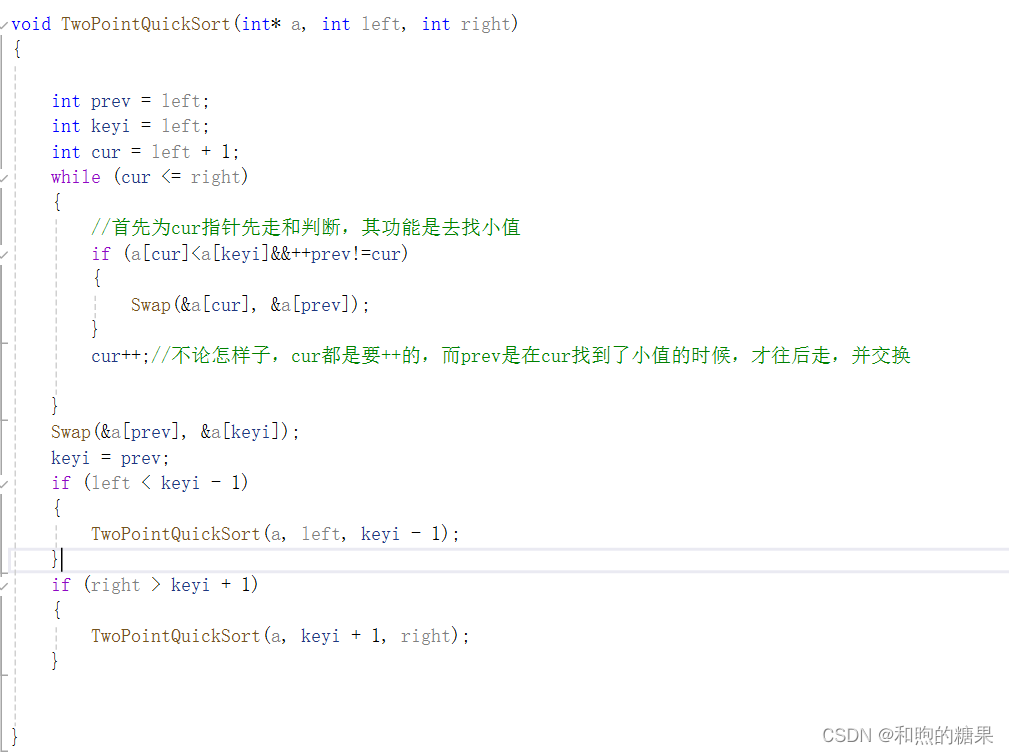
三 非递归排序法
分析:
首先想一下为什么我们还需要非递归的方法来实现排序?因为递归是在不断的开空间,如果数量太大,可能会发生栈溢出,因此,就有人相除了利用非递归的方法,就是利用循环和栈来模拟递归。
那么为什么栈可以用来模拟快速排序中的递归呢?想一下栈的性质——先进先出,而我们要递归的原因是我们要不断的分割区间来得到最小的区间
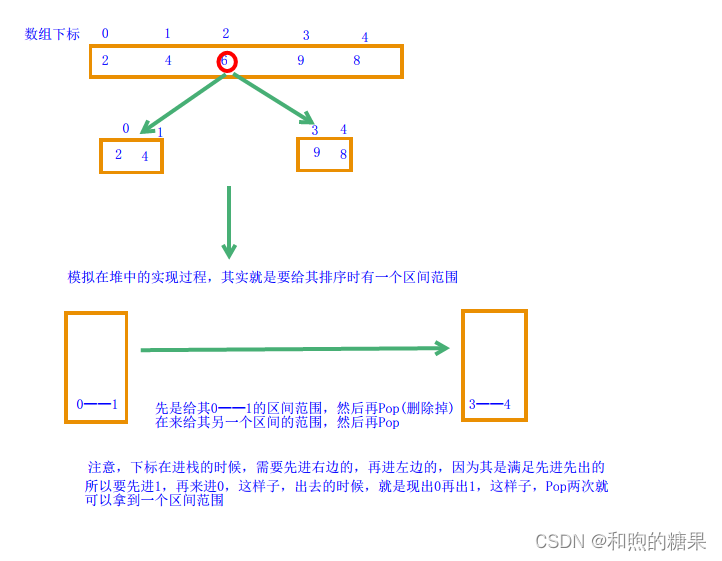
代码实现:




这一部分是需要额外调用堆的内容(手搓)
接下来就是非递归快速排序的代码


四 归并排序
1.递归归并排序
分析:
归并,就是把两组有序数组合并后,再来把其变为有序的,仿照前面的排序思路,它们的排序都是从最小的数组部分开始的这里也是,先是要分割成一个个小数组(至少包含两个数据),然后按一定的顺序关系排好位置,然后再将这两个(左和右)小数组合并,然后再来将其有序化,直到最后合并为一个数组。
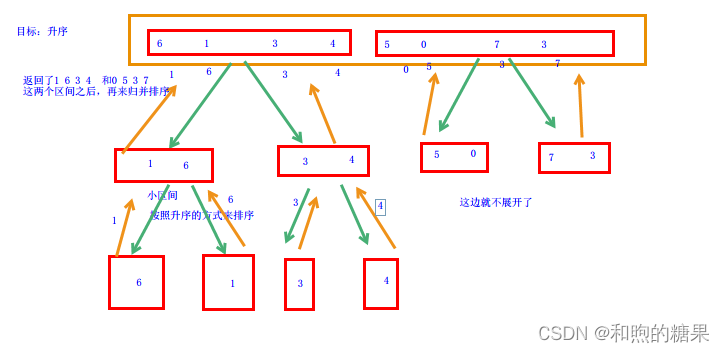
代码实现:
















 3068
3068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











