






第二章 实践方法论
当模型在训练数据上损失很大,可能出现三类问题:模型偏差、优化问题、过拟合
2.1模型偏差
可以让损失变低的函数不在模型可以描述的范围内
解决办法:重新设计一个模型并给模型更大的灵活性,其中一个做法是增加输入的特征
2.2优化问题
我们一般用梯度下降的方法优化,但这个方法有很多问题,比如可能卡在极小值点。所以优化问题是,模型包含可以让损失变低的函数,但是找不到。
参考论文《Deep Residual Learining for Image Recognition》,这个论文中给出的示例是20层和56层的网络在训练和测试中,56层的表现均远不如20层。这就是优化问题,因为如果20层可以做到56层也一定可以做到。作者给出的决绝办法是使用残差(Residual)网络。
综上,遇到没见过的问题时,可以先用小、浅的网络甚至非深度学习的方法(线性模型,支持向量机SVM)训练,先找到这些模型训练的极限损失。再用深的模型,如果和深的模型相比,明明灵活性比较高,损失却没有办法降下来——>优化问题
2.3过拟合
如果训练数据损失大,先判断是模型偏差还是优化问题:如果是模型问题就把模型做大(比如增加特征),如果增大模型后经过努力可以让训练数据的损失变小,再看测试数据要是测试数据也小就结束;如果测试数据结果不好,把训练数据记录下来,再确定优化有没有问题(模型够大,网络做深),若优化没问题则可能是过拟合。
所谓过拟合就是训练数据上的损失小,但测试数据上损失大。
解决办法:数据增强或限制模型灵活性不要太高
数据增强:增大训练集,例如把图片左右翻转或者将其中一部分截取出来
限制灵活性:也有一些方法:给模型较少的参数、提供比较少的特征、早停(Early Stoping)、正规化(regularization)、丢弃法(dropput method)。
给模型较少的参数:对于深度学习可以少一些神经元,或者让模型共用参数可以让一些参数有一样的数值。全连接网络(fully-connected network)是一种比较灵活的架构,而卷积神经网络(Convolutional Nerual Network,CNN)是一种比较有限制的架构。
提供较少的特征:原本给3天,现在给两天
即便如此也不能给模型过多的限制,当模型越来越复杂时,过拟合的情况就会出现。
2.4交叉验证
将训练数据分成两部分:训练集(training set)和验证集(validation set)。在训练集上训练出来的模型会使用验证集来评估他们的效果。
为了防止训练集和验证集分的不好,也可以采用k折交叉验证。即将训练集分成k份,其中有k-1个训练集,1个验证集。分k次。在着k个模型上分别跑一次。
2.5不匹配
不匹配和过拟合不同,一般的过拟合可以用收集更多的数据来克服,但不匹配是指训练集和测试集的分布不同。(训练时看的图象是现实,测试时测试的是漫画)
第三章 深度学习基础
局部最值与鞍点、自适应学习率和学习率调度、批量归一化。
3.1局部最小值与鞍点
因为我们采用梯度下降法,所以当梯度为0的时候优化就会停下来。而梯度为零的时候则可能有局部最小值(local minimum)和鞍点(saddle point)两种情况。
所谓鞍点类似与马鞍,在某一维度上是极小值,在另一维度上可能就是极大值。
梯度为0——>临界点(critical point)——>局部极大值(local maxmum)、局部极小值(local minimum)、鞍点(saddle point)
如何判断是什么点?
1.根据损失函数形状——>泰勒级数近似——>第三项黑塞/海森矩阵(Hessian matrix)H
损失函数L(θ)在θ'附近可近似为式:
在临界点梯度g为零,所以根据第三项来判断:
(θ-θ')= v, 第三项变为 ,
如果对于所有v,>0,则L(θ)>L(θ‘),L(θ’)是一个local minimum
如果对于所有v,<0,则L(θ)<L(θ‘),L(θ’)是一个local maxmun
如果对于v,有时候大于0有时候小于0,则是saddle point
上面的判断需要带入所有θ,这显然很麻烦,可以通过看H的特征值的方法来判断:
若H的所有特征值为正,H为正定矩阵,则>0,临界点是local minimum
若H的所有特征值为负,H为负定矩阵,则<0,临界点是local maxmum
若H的特征值有正有负,则为saddle point
H是怎么告诉我们如何更新参数的呢?
λ是H的一个特征值,u是H对应的特征向量,令u=θ-θ',则原式变为
若λ<0,则上式小于0,L(θ)<L(θ’),此时是极大值,且θ=θ'+u,所以只需要沿着特征向量u的方向更新参数损失就会变小。所以虽然临界点的梯度为0,但如果我们处在一个saddle point,只要找出负的特征值,再找出这个特征值的特征向量,将其与θ'相加,就可以找到一个损失更低的点。
3.2批量(batch)和动量(momentum)
计算梯度时,把所有数据拆分为多个批量(batch),每个批量的大小是B即带有B笔数据,每次在更新参数的时候,取出B笔数据用来用计算出损失和梯度更新参数。
遍历所有批量的过程称为一个回合(epoch)。
在数据分为批量的时候还会进行随机打乱(shuffle),随机打乱有很多方法,一个常见的方法就是在每一个epoch之前重新划分batch,也就是说每个epoch的batch里的数据都不一样。
批量大小对梯度下降法的影响:
批量大小为训练数据的大小时称为全批量(full batch),使用全批量的数据来更新参数的方法叫做批量梯度下降法(Btach Gradient Descent,BGD)
批量大小非全部训练数据,此时使用的方法叫做随机梯度下降法(Stochastic Gradient Descent,SGD),也称为增量梯度下降法。
两者对比:
批量梯度下降法要把所有数据跑完一遍才更新一次参数,因此每次迭代的计算量非常大,但其相较于随机梯度下降法,每次更新更稳定、更准确。随机梯度下降在梯度上引入了随机噪声,因此在非凸优化问题中,相比批量梯度下降法更容易逃离局部最小值
在考虑并行计算的情况下,GPU计算批量为1和批量为1000的损失和梯度的速度可能是一样的,但是批量为1要更新的次数却远大于批量1000的更新次数,所以更新所耗费的时间更长,则一个回合所耗费的时间也就更长,因此大的批量大小反而较有效率,一个回合大的批量花的时间反而较少。
大的批量大小往往在训练的时候表现比较差,这是优化问题,对于大的批量大小,优化可能会有问题;对于小的批量大小,优化结果反而比较好。一个可能的解释就是:批量梯度下降,会沿着一个损失函数来更新参数,走到一个局部最小值或鞍点就会停下来如果不看黑塞矩阵,梯度下降就无法更新参数了。但小批量梯度下降每次挑一个批量计算损失,所以每一次更新参数使用的损失函数时有差异的。
动量法(momentum method):每次在移动参数的时候,不是只往梯度的反方向移动参数,而是根据梯度的反方向加上前一步移动的方向决定移动方向。这样就使得遇到临界点时依然可以往前走。
另一个理解角度是:更新的方向不仅需要考虑现在的梯度,而且需要考虑过去所有梯度的综合
3.3自适应学习率
学习率决定了更新参数时的不发,学习率太高意味着步伐太大,无法慢慢地滑到山谷里。
自适应学习率(adaptive learning rate)的方法,给每一个参数不同的学习率,如果在某个方向上梯度的值很小,非常平坦,我们希望学习率调大一些;如果梯度在某个方向上非常陡峭,坡度很大,我们希望学习率可以设小一点。
AdaGrad(Adapative Gradient)是典型的自适应学习率方法,它能够根据梯度的大小自动调整学习率,AdaGrad可以做到当梯度比较大的时候,学习率就小;而当梯度比较小的时候,学习率就大。
RMSprop(Root Mean Squared propagation)是一个新的自适应学习率方法:可以实现对于同一个参数的同一方向,动态调整学习率
AdaGrad和RMSprop对比:在AdaGrad里,在算均方根的时候,每一个梯度有同等的重要性;但在RMSprop里,你可以自行调整现在的这个梯度的重要性
综上:最常用的优化策略或者优化器(optimizer)是:Adam(Adapative moment estimation),可以看作是RMSprop加上动量,它使用动量作为参数更新方向,并且能够自适应调整学习率,已内置Pytorch。
3.4学习率调度
通过学习率调度(learning rate scheduling)解决梯度爆炸问题(由于在某一方向上的梯度很小而累积了很小的σ,累积到一定程度后,步伐就很大)。
最常见的策略是:学习率衰减(learning rate decay)也成为学习率退火(learning rate annealing):随着参数不断更新,让η越来越小,最后虽然步伐很大,但η变得非常小,两者的乘积也就小了。
另一种策略:预热(Warm up):让学习率先变大再变小。变到多大、变大的速度、变小的速度也是超参数。为什么要预热?刚开始多学点为了后面过的更快
3.5优化总结
从最原始的梯度下降进化到上式的版本:增加了动量m,步伐大小为动变为,再通过
来实现学习率调度
3.6分类
对于不同类别采用独热(one-hot)向量来表示
为什么要在分类过程中加入softmax函数?
一个简单的解释是:y里面的值只有0和1,但是y^里面可以有任何值。既然目标只有0和1,但y^里面有任何值,因此可以先把他们归一化到0~1,这样才能计算与标签的相似度。
但一般有两个类别的时候不用softmax函数,而是直接使用sigmoid函数,当只有两个类别的时候,sigmoid函数和softmax函数是等价的。
分类损失
计算损失也就是y和y^之间的距离不止有一种做法:一种是均方误差(MSE),一种是交叉熵(Cross-entropy)
最小化交叉熵(Minimize Cross-entropy)其实就是最大化似然(maxmize likehood),从优化的角度,相较于均方误差,交叉熵更常用在分类上。
第四章 卷积神经网络CNN
4.1观察1与简化1
Obeversion 1:检测模式不需要整幅图像
对于一个图像识别的类神经网络里面的神经元而言,他要做的就是检测图像里没有有没有出现一些特别重要pattern
简化1:receptive field 感受野
receptive field的尺寸是我们自己决定的,有大有小,可以是正方形也可以是长方形,一般是3✖3。
receptive field之间可以重叠。
receptive field的深度就等于通道(channel)数,高×宽叫做核大小(kernel size)。
我们(一个神经元)没有办法检测所有的pattern,所以同一范围内可以有多个不同的神经元,即多个神经元可以守备同一个receptive field。
同一个receptive field一般会有一组神经元去守备。
将receptive field平移来得到新的receptive field,移动的量称为步幅(stride),stride是一个超参数,我们希望receptive field重叠,所以stride一般设1或2。
一个神经元的receptive field一定要相连吗?
No,不一定,可以这样设计,但不一定有什么用,你可以设计一个神经元的receptive field就是左上角和右下角,但其实一个图片的pattern很少有是左上角和右下角组合的,一般都是在图片的某一个位置,所以这样设计有用的时候比较少,因此receptive field一般都是相连的。
为什么希望receptive field之间是有重叠的?
假设没有重叠,有一些pattern刚好是两个receptive各取一部分组成的,这样就会漏掉这个pattern。
receptive field移动时,如果超出了图像的范围,超出的部分做填充(padding),填充就是补值,一般使用零填充(zero padding),超出范围就补0,当然也可以用别的值补。
4.2观察2与简化2
Obversion 2:同样的模式可能出现在图像的不同区域
以鸟嘴这个pattern为例,一张图片的鸟嘴可能出现在图片的左上角,另一张图片的鸟嘴可能出现在图片的中心区域。原本我们是将一张图片切分成一堆receptive field,每个receptive field都有一组神经元去守备,在不同的receptive field都有一个神经元是检测鸟嘴这个pattern的,他们做的工作是一样的,只是守备的receptive field是不一样的。而之所以每个receptive field都有检测鸟嘴的神经元,是因为你无法确定哪个receptive field里面包含了你要的pattern。
简化2:共享参数
让不同的receptive field的神经元参数共享(parameter sharing),所谓参数共享,就是让两个神经元的权重完全一样。
每个receptive field有一组神经元比如64个神经元,现在上面receptive field的第一个神经元和下面receptive field的第一个神经元共享参数,上面第二个和下面第二个共享参数,以此类推。只不过每个receptive field都只有一组参数(一个receptive field对应一组神经元对应一组参数),这些参数称为滤波器(filter)
4.3简化1和简化2的总结
全连接网络弹性最大,它可以决定看整幅图还是只看一个范围,如果只看一个范围,则可以把很多权重设成0。
全连接层(fully-connected layer)可以自行决定看整幅图还是看一个范围,但在加上receptive field的概念后就只能看一个小的范围,网络的弹性将变小,参数共享则进一步限制了网络的弹性,因为本来每一个神经元都可以有各自不同的参数,加入参数共享以后则不行了。
感受野+参数共享 = 卷积层(convolutional layer)
用到卷积层的网络叫做卷积神经网络。卷积神经网络的偏差比较大,但模型偏差大而灵活性低时,比较不容易过拟合。
卷积神经网络的另一种解释
卷积层里面有很多滤波器,这些滤波器的大小是3×3×Chanel,一个卷积层里面有一组滤波器,这些滤波器的作用是去图像里面检测某种pattern,该pattern只有在3×3×通道数这个小的范围内,才能够被这些滤波器检测出来,滤波器里面的数值其实时未知的,但可以通过学习找出来。
设通道数为1,则滤波器就是一个一个的3×3张量矩阵,用一个6×6的矩阵代表图像,把滤波器里面的9个数值与图像中3×3的receptive field中对应的9个值相乘再相加,设置stride为1,移动receptive field,遍历图像后,得到一组数值,每个滤波器对应一组数值,若有64个滤波器则可以得到64组数值,这组数值称为特征映射(feature map).
一个通道对应一个滤波器,本来一副图像有3个通道,通过一个卷积层后,变成了一副新的、有64个通道的图像。
如果滤波器的大小一直设为3×3,会不会导致网络没有办法看到比较大范围的pattern呢?
不会,如果第二个卷积层中的滤波器也被设成3×3,那么当看第一个卷积层输出的feature map的3×3的范围时,就相当于在原来图像上考虑一个5×5的范围。网络叠的越深,看的范围就会越来越大。
在这里共享权重,其实就是用滤波器去扫掠过一幅图像,这个过程就是卷积。这就是卷积层名字的由来。用滤波器扫过图像就相当于在不同的receptive field上的神经元共享参数,这组共用的参数正是滤波器。
4.4观察3和简化3
Obversion 3:下采样不影响检测模式
对一副比较大的图像做下采样(downsampling),把图像的偶数列和奇数行都拿掉,图像变为原来的1/4,但这不会影响图像的识别。
简化3:池化(pooling)
pooling没有参数,所以它不是一个层,它里面没有权重,也没有要学习的东西,pooling比较像sigmoid函数,ReLU等激活函数,因为里面没有要学习的参数,所以汇聚就是一个操作符(operator),其行为都是固定好的,不需要根据数据学任何东西。
pooling有很多版本:最大池化(max pooling)、平均池化(mean pooling)
在实践中,通常将卷积和汇聚交替使用,可以先做几次convolution,再做一次pooling。pooling最主要的作用是减少运算量,通过下采样把图像变小,就可以减少运算量,但算力够的时候尽量不做pooling。
扁平化(flatten)就是把图像里本来排成矩阵形式的数据"拉直",即把所有的数值排成一个向量。
当卷积神经网络在某种大小的图像上学会做图像识别后,我们把物体放大,卷积神经网络的性能就会下降不少,卷积神经网络并没有我们想象的那么强,因此在做图像识别的时候,往往要做数据增强,卷积神经网络不能处理图像缩放和旋转的问题。
第五章 循环神经网络RNN
RNN是一种有记忆的神经网络。在RNN里面,每一次隐藏层的神经元产生输出时,输出就会被存到记忆元(memory cell)里。
记忆元简称单元(cell),记忆元的值也可称为隐状态(hidden state)。
在使用RNN时,必须给记忆元设置初始值。
RNN会考虑序列的顺序,将输入序列调换顺序之后,输出将不同。
因为当前时刻的隐状态使用与上一时刻隐状态相同的定义,所以隐状态的计算是循环的(recurrent),基于循环计算的隐状态神经网络称为循环神经网络。
每一个隐藏层的输出都会被存在记忆元里,到了下一个时间点,每一个隐藏层会把前一个时刻存的值再读出来,以此类推,最后得到输出,这个过程会一直持续下去。
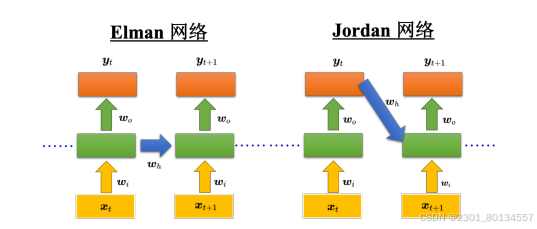
5.1Elman网络和Jordan网络
Elman网络是简单循环网络的一种,它把隐藏层的值存起来,并在下一个时间点读出来。
而Jordan网络存的是整个网络输出的值,它会把输出值在下一个时间点读进来,并把输出存到记忆元里。
Elman网络没有目标,很难说它能学到什么隐藏层信息;但Jordan网络有目标,它很清楚记忆元里存了什么东西。
5.2双向循环神经网络
双向循环神经网络(Bidirectional Recurrent Neural Network,Bi-RNN)的优点是,神经元在产生输出的时候,看的范围是比较广的。正常的单向RNN它只看前面的,而双向RNN不仅看前面的记忆还看后面的记忆,相当于看过整个输入序列。
5.3LSTM
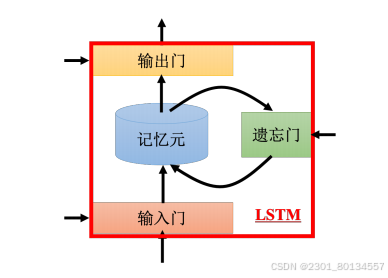
长短期记忆(Long Short-Term Memory,LSTM),有三个门(gate)。
当外界某个神经元的输出想要被写到记忆元里的时候,就必须通过一个输入门(input gate),输入门打开的时候才能把值写到记忆元里。如果把输入门关起来,就没办法把值写进去。输入门的开关时机是神经网络自己学到的。
输出的地方有一个输出门(output gate),输出门决定外界其他的神经元能否从这个记忆元里把值读出来。输出门关闭的时候,是没有办法把值读出来的,输出门打开的时候才可以把值读出来。
遗忘门(forget gate),遗忘门决定什么时候记忆元要把过去记得的东西忘掉。遗忘门打开的时候是记住,遗忘门关闭的时候是忘记。
循环神经网络的记忆元里的值,只要有新的输入进来,旧的值就会被遗忘掉,这个记忆周期是非常短的。但如果是LSTM,则记忆周期会更长一些,只要遗忘门不决定忘记,值就会被存起来。
综上,整个LSTM有四个输入、一个输出。一个输入是要存在记忆元里的值(但不一定存的进去),其他三个输入分别是操控输入门的信号、操控输出门的信号、操控遗忘门的信号。
如果LSTM网络和普通网络拥有相同数量的神经元,则LSTM网络需要的参数量是普通网络的四倍。
真正的LSTM网络会把上一个时间点的输出接进来,当作下一个时间点的输入,即下一个时间点在操控这些门的值时,不仅看那个时间点的输入x(t+1),还看前一个时间点的输出h(t)。
其实不仅如此还会添加peephole连接,如下图所示,peephole连接就是把记忆元里值也考虑进来。在操控LSTM的4个门时,需要同时考虑x(t+1)、h(t)、c(t),先将这三个向量并在一起执行不同的变换,得到4个不同的向量,之后再操控LSTM。
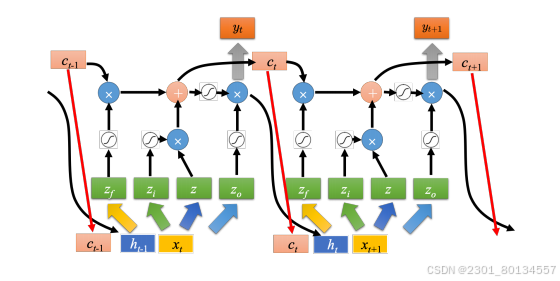
门控循环单元(Gated Recurrent Unit,GRU)是LSTM稍微简化后的版本,它只有两个门。虽然少了一个门,但GRU的性能与LSTM差不多,且参数更新少,比较不容易过拟合。
5.4梯度消失和梯度爆炸
使用LSTM网络可以让误差表面不那么平坦,它会把那些平坦的地方拿掉,解决梯度消失(vanishing gradient)的问题,但使用LSTM网络解决不了梯度爆炸(gradient exploding)问题.
为什么LSTM网络可以解决梯度消失的问题,并避免梯度特别小?为什么把RNN换成LSTM网络?
LSTM网络可以解决梯度消失的我呢提,RNN和LSTM网络在面对记忆元的时候,所处理的操作其实是不一样的。在RNN中,每一个时间点,神经元的输出都要存到记忆元里,记忆元里的值会被覆盖掉。但在LSTM网络中不是这样,而是把原来记忆元里的值乘以另一个值,再与输入的值相加并将结果存到单元里面,即记忆和输入是相加的。
LSTM网络区别于RNN的是,如果权重可以影响到记忆元里的值,则一旦发生影响,影响就会永远存在,而RNN在每个时刻的值都会被覆盖掉,所以只要这个影响被覆盖掉,他就消失了。在LSTM网络中,除非遗忘门要把记忆元里的值"清洗"掉,否则记忆元一旦有变,就只把新的值加进来,而不会把原来的值清洗掉,所以不会有梯度消失的问题。
GRU网络,只有两个门即输入门和遗忘门。当输入门打开的时候,遗忘门会自动关闭(格式化存在记忆元里的值);而遗忘门没有格式化记忆元里的值时,输入门就会被关起来。也就是说,要把记忆元里的值洗掉,才能把新的值放进来。
其实还有其他技术可以解决梯度消失的问题,比如顺时针循环神经网络(clocwise RNN)或结构约束的循环网路(Structurally Constrained Recurrent Network,SCRN)
第六章 自注意力机制
之前的问题,不论是预测观看人数,还是图像处理问题,网络的输入都是一个向量,如果是回归问题则输出是一个标量,如果是分类问题则输出是一个类别。但也有其他情况就是输入是向量序列,因此本章引入了另一种常见的网络架构——自注意力模型(self-attention model)
6.1输入是向量序列的几种情况
类型1:输入与输出数量相同
第一个例子:文字处理,每次输入的句子的长度都不一样。表示句子的方式:独热编码表示每一个单词。但独热编码没法表示一些相近词意词语的关系,故可以使用词嵌入(word embedding)。
应用:词性标注(Part-Of-Speech tagging),给一个句子判断每个词的词性。
类型2:输入是一个序列,输出是一个标签
第二个例子:声音信号。一段声音信号就是一组向量。为声音信号取一个范围,将这个范围称作一个窗口(window),把window里面的信息描述成一个向量,这个向量称为一帧(frame)。
情感分析,给一段话判断是消极的还是积极的。
类型3:序列到序列
应用:翻译,输入和输出是不同的语言,不同语言的词汇数自然是不同的。
6.2自注意力机制的运作原理
自注意力模型会考虑整个序列的数据,输入几个向量,它就输出几个向量。
self-attention model不是只能用一次,而是可以叠加很多次。
fully-connected network 和 self-attention model可以交替使用。fully-connected network专注于处理某个位置的信息,self-attention model则把整个序列信息再处理一次。
输入一组向量a,self-attention model将输出一组向量b,如何产生的b?
self-attention 的目的是考虑整个序列,但是又不希望把整个序列所有的信息包含在一个窗口里面。所以其有一个特别的机制,这个机制的作用就是找到输入a1与其他输入之间的关联程度α。
怎么计算关联程度α?
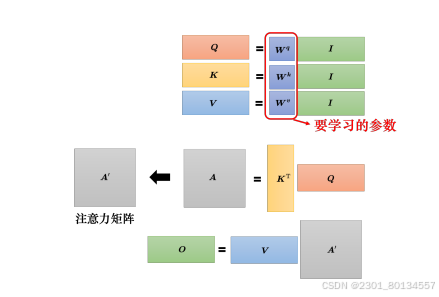
常见的做法是计算点积(dot product),把输入的两个向量分别乘以两个不同的矩阵,左边这个输入乘以Wq得到q,右边这个输入乘以Wk得到k,再对q和k计算dot product。
如何套用到self-attention model?
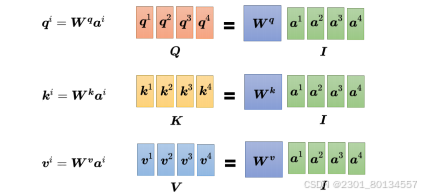
self-attention model 一般采用Query-Key-Value(QKV)模式。
将a1乘以Wq得到q1;
而a2、a3、a4分别乘以Wk得到k2、k3、k4;
用a1、a2、a3、a4分别乘以Wv得到v1、v2、v3、v4;
用q1分别于k2、k3、k4做dot product得到α12、α13、α14;
将α12、α13、α14分别通过softmax函数归一化得到α12’、α13‘、α14’;
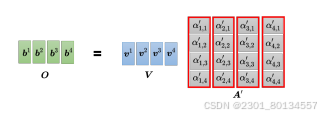
将α12’、α13‘、α14’分别乘以v1、v2、v3再加权和得到b1;
其中谁的α大乘以v后,v就占主导,v也就越接b1的值。
用矩阵统一表示如下:
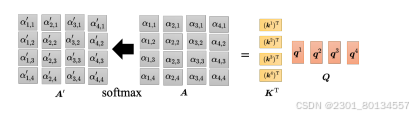
6.3多头自注意力、位置编码、截断自注意力
多头自注意力
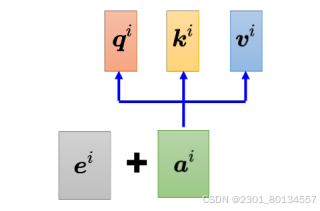
多头自注意力(Multi-head self-attention)是self-attention的高级版本。其实就是原来的a乘以W得到的q、k、v再乘以矩阵得到qi1、qi2...,ki1、ki2...,vi1、vi2...,在计算α时再分别计算。而至于有多少个head,是个超参数。
位置编码
对一个self-attention layer而言,每一个输入是出现在序列的最前面还是最后面?如果实现self-attention的时候,如何觉得位置信息很重要,就要用到位置编码(positional encoding),位置编码为每一个位置设定一个向量,即位置向量(positional vector)。
截断自注意力
截断自注意力(turncated self-attention)可以处理向量序列过长的问题,在做自注意力的时候,也许没必要让self-attention考虑整个句子,以提高运算的速度。
6.4自注意力与CNN\RNN对比
self-attention与CNN对比
用self-attention处理一副图像时,在做内积的时候,考虑的不是一个小小的范围,而是整幅图像的信息。
CNN可以看作是一种简化版的self-attention,因为在做CNN的时候,只考虑receptive field内的信息,而self-attention会考虑整幅图像的信息。
可以说,CNN就是self-attention的特例,self-attention是更灵活的CNN,而CNN是受限制的self-attention。
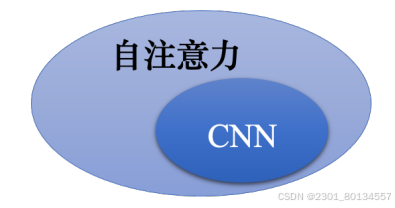
self-attention的弹性比较大,所以需要比较多的训练数据,训练数据少的时候就会过拟合。
而CNN的弹性比较小,在训练数据少的时候反而结果比较好,当训练数据多的时候,CNN没有办法从更大量的训练数据中获得好处。
选择谁?两者可以一起使用
self-attention与RNN对比
自注意力和循环神经网络有一个显然易见的不同之处:self-attention的每一个向量都考虑了整个输入序列,而RNN的每一个向量只考虑了左边已输入的向量,但如果使用Bi-RNN可以改善这个问题。
对比自注意力模型的输出和RNN的输出:对于RNN来说最右边的输出要考虑最左边的输入,就必须把最左边的输入存到记忆力才能不被以往,并且直至带到最右边才能够在最后一个时间点被考虑,但只要self-attention输出的查询和键匹配,self-attention就可以轻易的从整个序列上非常远的向量中抽取信息。
另一个更主要的不同是:RNN没有办法并行化,无法并行处理所有的输出,但self-attention可以,self-attention比RNN的运算速度更快,但自注意力最大的问题是运算量非常大。
当把self-attention按照这种限制用在图上面时,其实使用的就是一种图神经网络GNN。
第七章 Transformer
Transformer是基于自注意力的序列到序列模型,与RNN的序列到序列模型不同,Transformer支持并行计算。
7.1 Transformer结构
一般的序列到序列模型可以分解成编码器和解码器,编码器负责处理输入序列,再把处理好的结果输入解码器,由解码器决定输出序列。
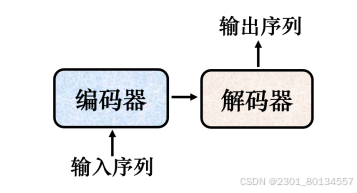
7.2 Transformer编码器(encoder)
为编码器输入一排向量,编码器将输出另一排向量。Attention、RNN、CNN均可以做到输入一排向量输出另一排向量。
Tranformer encoder使用的是Attention,输入一组向量,输出另一组数量相同的向量。
编码器内部有很多的块(block),每一个block都能输入一组向量,输出另一组向量。输入一组向量到第一个block,第一个block输出另一组向量到下一个block,以此类推,最后一个block输出最终的序列。
Transformer编码器的每个块并不是神经网络的一层。
Transformer中加入了残差网络(residual connection)
将最左边的向量b输入自注意力层,得到向量a,再将输出向量a加上输入向量b,得到新的输出。将输入与输出加在一起,即为残差结果。得到残差结果后再做层归一化(layer normalization).
layer normalization不需要考虑批量的信息,而batch normalization需要考虑batch的信息。
layer normalization能输入一个向量 ,输出另一个向量。layer normalization会计算输入向量的均值和标准差。
batch normalization是对不同样本、不同特征的同一个维度计算均值和标准差,而layer normalization是对同一个特征、同一个样本里不同的维度计算均值和标准差,接着做归一化。
7.3 Transformer解码器(decoder)
比较常见的Transformer解码器是自回归(autogressive)解码器
7.3.1 自回归解码器
解码器把编码器的输出先"读"进去,要让解码器产生输出,就得给他一个代表开始的特殊符号<BOS>,这是一个特殊的词元(token)。
解码器的输入是它在前一个时间点的输出,它会把自己的输出作为接下来的输入,因此当解码器产生一个句子的时候,它有可能看到错误的内容。比如机器的器识别成天气的气,那么接下来解码器就会根据错误的识别结果产生输出,造成误差传播(error propagation),一步错步步错,从而可能无法再产生正确的结果。
Transformer解码器的详细结构入下图所示:
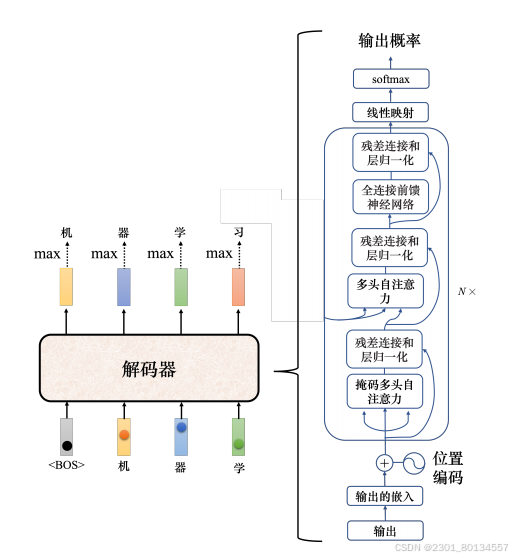
类似于编码器,解码器也有muti-head attention、residual connection、和layer normalization,以及FC。解码器在组后执行softmax操作,以使其输出变成概率。
此外解码器还使用了掩码多头自注意力,掩码多头自主注意力可以通过一个掩码(mask)来阻止每个位置选择其后面的输入信息,它不再看右边的部分。
为什么要在自注意力中添加掩码?
答:一开始,解码器的输出是一个一个产生的,所以先有a1再有a2,接下来是a3,最后是a4.
这跟原来的自注意力不一样,在原来的自注意力中,a1~a4被一次性输入模型,编码器也一次性把a1~a4读进去。
但是对于解码器而言,先有a1,才有a2,后面才有a3和a4.所以实际上当我们有a2想要计算b2的时候,a3和a4是没有的,所以无法考虑a3和a4.解码器的输出是一个一个产生的,只能考虑左边已有的部分,而没有考虑右边的部分。
要让解码器停止运行,需要准备一个词元<EOS>,输出EOS整个解码器产生序列的过程结束。
7.3.2 非自归解码器
对于自归解码器先输入<BOS>,输出w1,再把w1当作输入,输出w2,直到输出<EOS>为止。
自归解码器是一个一个的输出,而非自归解码器是可能接收一整组的<BOS>词元,一次产生一组词元。比如输入4个<BOS>token给非自归解码器,将产生4个中文汉字。
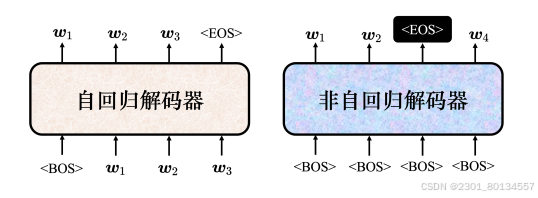
因为输出的长度是未知的,所以输入非自归解码器的<BOS>的数量也是未知的,怎么办呢?
答:用分类器接收编码器的输入,输出一个数字,该数字代表解码器应该输出的长度。也可以给编码器输入一组<BOS>token,假设输出的句子长度有上限,如绝对不会超过300个汉字,给编码器输入300个<BOS>,于是就会输出300个汉字,<EOS>右边的输出可以忽略。
非自归解码器有很多优点,其中一个优点是平行化,非自归解码器在速度上比自回归解码器快。
另一个优点是能够控制输出的长度。
7.4编码器-解码器注意力
Encoder和Decoder通过encoder-decoder attention传递信息,encoder-decoder attention是连接encoder和decoder的桥梁。
如下图所示,decoder中encoder-decoder attention的key值来自encoder的输出,query值来自解码器中前一个层的输出。
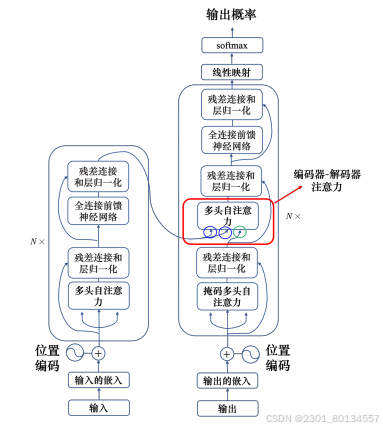
encoder-decoder attention的实际运作过程
如下图所示,编码器能输入一排向量,输出另一排向量a1、a2、a3.
解码器会先读取到<BOS>,经由掩码多头自注意力得到一个向量,然后这个乘以一个矩阵,再做一个变换,得到一个query值q。
a1、a2、a3也相应的产生key值k1、k2、k3.
用q和k1、k2、k3去计算注意力分数,得到α1、α2、α3.接下来执行softmax操作,得到α1‘、α2‘、α3‘
求加权和v,v被输入全连接网络
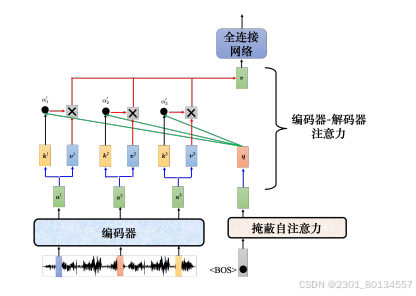
综上,解码器就是凭借着产生一个q,去编码器中将信息抽取出来,当作接下来的解码器的全连接网络的输入。
7.5 Transformer的训练过程
Transformer应该能针对输入的“机器学习”声音信号输出"机器学习"这4个字。
当把<BOS>输入编码器的时候,编码器的第一个输出应该和"机"越接近越好;解码器的输出是一个概率分布,这个概率分布应该和"机"的独热向量越来越接近越好,为此,计算标准答案(ground truth)和分布之间的交叉熵,我们希望交叉熵的值越小越好。每次解码器产生一个字的时候就相当于做了一次分别类。
在实际训练的时候,解码器的输出并非只有"机器学习这四个字",还有<EOS>.所以解码器的最终第五个位置输出的向量跟<EOS>的独热向量的交叉熵越小越好。
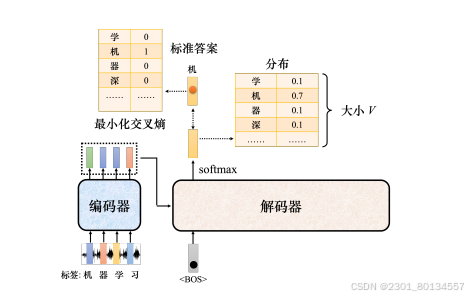
把标准答案提供给解码器,我们希望解码器的输出跟标准答案越接近越好。在训练时告诉解码器,在已经有<BOS>、"机"的情况下输出"器",在已经有<BOS>、"机"、"器"的情况下输出"学",在已经有<BOS>、"机"、"器"、"学"的情况下输出"习",在已经有<BOS>、"机"、"器"、"学"、“习”的情况下输出<EOS>。
这种在训练解码器的情况下输入时就提供标准答案的做法称为教师强制(teacher forcing)
7.6序列到序列模型训练常用技巧
复制技巧(copy mechanism)
像我是xxx这种句子,直接把xxx复制过来,或者提取文章摘要这种也可以直接复制内容过来。最早拥有从输入中复制东西这种能力的模型是指针网络(pointer network),后来出现了复制网络(copy network)。复制网络是指针网络的变体。
引导注意力
语音识别、语音合成这类任务最适合使用引导注意力。引导注意力压迫求机器在计算注意力时遵循固定的模式。对于语音合成或语音识别,我们想象中的注意力应该由左至右,如果机器先看最右边再看最左边最后随机看整个句子,那么,这样的注意力显然是有问题的,没有办法合成好的结果。
如果对问题本身就有一定的理解,知道对于像语音合成这样的问题,注意力的位置都应该由左至右,不如就直接把这个限制放在训练里面。
束搜索(beam search)
每次都找分数最高的token当作输出的方法称为贪心搜索(greedy search),又成贪心解码(greedy decoding)
接下来介绍束搜索(beam search),束搜索经常也成为集束搜索或柱搜索。束搜索的思想是用一种比较有效的方法来找近似解,但在某些情况下效果并不好。有时候对于解码器来说,没有找出分数最高的路径,反而结果是比较好的,这要看任务本身的特性。假设任务的答案非常明确,比如语音识别,对于一句话,识别的结果就只有一种可能,对于这种任务而言,通常束搜索就会比较有帮助,但如果任务需要机器发挥一点创造力,束搜索就不合适了。
加入噪声
语音合成神奇的地方是,在模型训练好后,在测试的时候要加入一些噪声,这样合成出来的声音才会好。
使用强化学习训练
计划采样
在测试的时候,解码器看到的是自身的输出,因此它会看到一些错的东西。但在训练的时候,解码器看到的是完全正确的东西,这种不一致现象焦作曝光偏置(exposure bias)
给解码器的输入加入一些错的东西,它反而学的更好,这一技巧被称为计划采样(scheduled sampling)。计划采样不是学习率调整
第八章 生成模型(generative model)
8.1生成对抗网络
8.1.1生成器(generator)
生成模型中的网络会被作为一个生成器(generator)使用。具体来说,在输入时会将一个随机变量z与原始输入x一起输入模型,这个随机变量是从一个随机分布在采样得到的。
输入时可以使用向量拼接或者等x和z长度一样时输入。
对随机分布的要求是,必须足够简单,可以较为容易地进行采样,或者可以直接写出该随机分布的函数,如高斯分布(Gaussian distribution)、均匀分布(uniform distribution)。
因为每次采样得到z不同,所以得到的输出y也就不同,对于网络来说,因为输出不再固定,因此输出其实也是一个复杂的分布。
综上 可以将输出一个复杂分布的网络称为生成器。
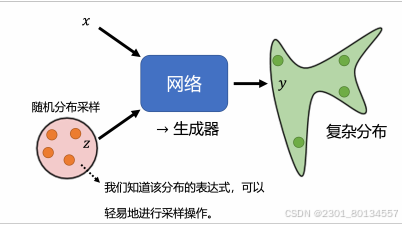
什么时候需要这类生成模型?
当我们的任务需要创造性的输出,或者我们想知道一个可以输出多种可能性的模型,且这些输出都是对的模型的时候。生成模型让模型有了创造力。
在生成模型中,非常知名的就是生成对抗网络(Gnerative Adversarial Network,GAN).
而GAN还有无限制生成(unconditional generation),即不需要原始输入x。与需要输入x的条件性生成(conditional generation)
8.1.2判别器(discriminator)
判别器通常是一个神经网络,它能输入一张图片,输出一个标量,这个标量越大,就代表现在的输入的图片越接近真是动漫人物的脸。
判别器可以用CNN也可以用Transformer,只要能够产生我们想要的输出即可。
生成器和判别器彼此之间是一种互动、促进关系。最终,生成器会学会画出动漫人物,而判别器也会学会分辨真假图片,这就是GAN的训练过程。
8.2生成器与判别器的训练过程
生成器和判别器是两个网络,再训练前需要分别进行参数的初始化。
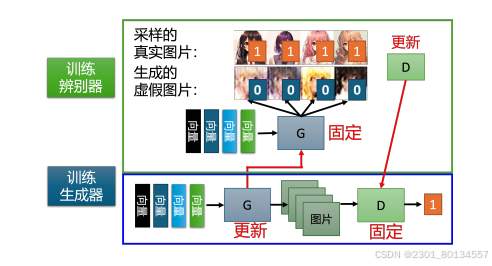
(1)训练的第一步是固定生成器,只训练判别器。
至于为什么,因为生成器的初始参数是随机初始化的,所以他什么都没学到,输入一些列采样得到的向量给他,他的输出是随机的,混乱的图片。
判别器的训练过程是从已有动漫图库中采样一些动漫人物头像出来,跟生成器生成的图片对比,从而完成训练。
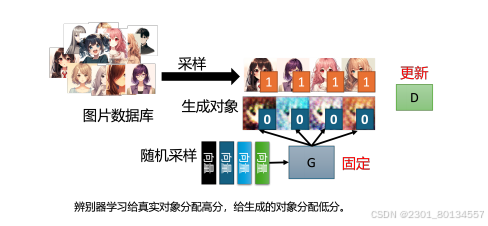
(2)训练完判别器后,固定判别器,训练生成器
训练生成器的目的是让生成器生成的图片想办法骗过判别器。其过程为:首先为生成器输入在分布中采样得到的向量,并让生成器产生一张图片,将图片输入判别器,让判别器打分,训练生成器的过程就是提高这个分数。
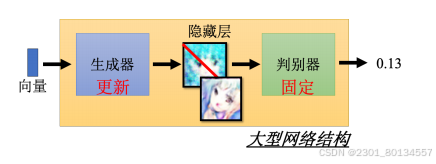
综上,GAN算法的两个关键步骤:固定生成器,训练判别器;固定判别器,训练生成器。
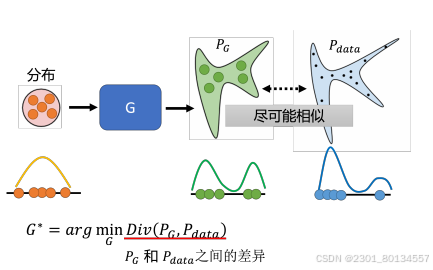
8.3GAN的理论介绍
(1)因为生成器的输出是一个复杂的分布(生成的动漫人物头像),假设这个分布为。而原始数据(图库中的动漫头像)本身也会形成另外一个分布,假设这个分布为
。训练的目标就是让
和
尽可能相似。
两者的差距越小,代表这两个分布越接近。差异是衡量两个分布之间相似度的一个指标。这两者的差异就相当CNN网络中的损失函数。
(2)估算差异,需要依靠判别器的力量。我们训练一个判别器让他看到真是数据就给出高分,看到生成数据就给出低分,我们可以把这当作一个优化问题。
具体来说就是:训练一个判别器,它可以最大化一个目标分数。在这个目标函数中,有和
两部分数据,将其都输入到判别器,然后判别器给出分数,最后使这个目标函数越大越好。
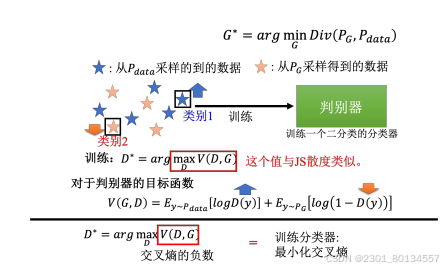
综上,这个目标函数与JS散度是相关的,关于JS散度我不懂,这个东西也没办法更好的评判GAN,所以直接跳过。
8.4WGAN算法
Wasserstein GAN(WGAN)使用了Wasserstein距离的想法,其思想如下:假设有两个分布P和Q,要想知道这两个分布之间的差异,假设我们有一台推土机,要把P这堆土推到Q这边,那么推土机平均所走的距离就是Wasserstein距离。
有时P和Q并不都是集中在一个点,而是分布在一个区域内,那么则需要考虑所有的走法,然后看走的平均距离是多少。
为了让Wasserstein距离只有一个值,我们将距离定义为穷举所有的移动方式,然后看哪一种方式可以让平均距离最小,那个最小的平均距离才是Wasserstein距离。
Wasserstein距离也成为推土机距离(Earth Mover's Distance,EMD)
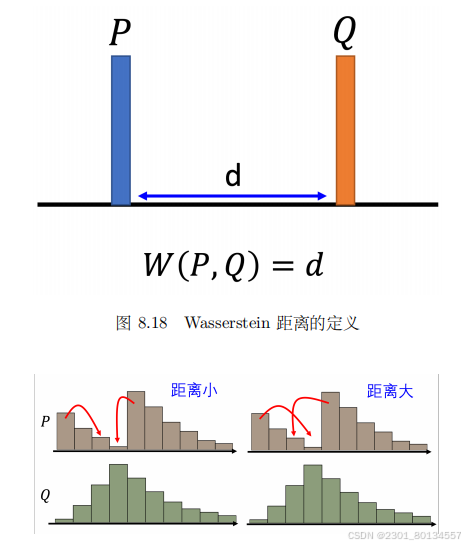
Wasserstein距离越小,对应的生成器就越好。
WGAN实际上就是用Wasserstein距离代替JS距离。
Wasserstein距离如何计算呢?
距离的计算实际上是一个最优化问题,这里直接给出解决方案,也就是下图中的最大化问题的解。
下图中如果x是从Pdata中取样出来,则判别器的输出越大越好。如果x是从PG中取样出来,则判别器输出越小越好。
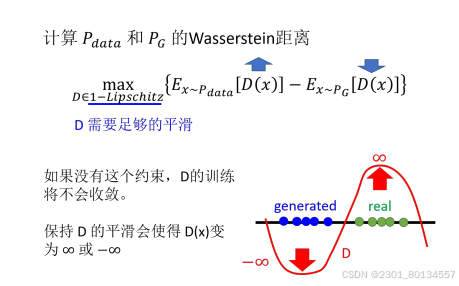
函数D必须是一个1-Lipschitz函数,如果一个函数的斜率有上限(足够平滑,变化不剧烈),则这个函数就是1-Lipschitz函数。因为花括号里面左边值越大越好,右边值越小越好,这样花括号内的值可能无限大,会导致无法收敛。
如何确保判别器一定符合1-Lipschitz函数的限制呢?
其中一个方法是Improved WGAN,它使用了梯度惩罚(gradient penalty),从而让判别器变成了1-Lipschitz函数。
具体做法是,在真实数据的分布内采样一个数据点,在生成数据的分布采样一个点,然后在这两个数据点之间采样第三个数据点,计算第三个数据点的梯度,使之接近1。
这就相当于在判别器的目标函数里加上一个惩罚项,惩罚项的系数是一个超参数。也可以将判别器的参数限制在一个范围内,使其变成1-Lipschitz的函数,这叫做谱归一化。
8.5 GAN训练的难点与技巧
GAN训练的难点在于生成器和判别器必须同时训练,而且必须同时训练到一个比较好的状态。其中一方发生问题停止训练,另一方就会跟着停止训练。
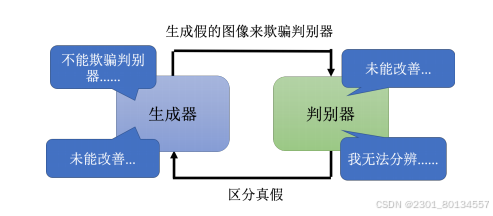
训练GAN生成文字十分困难,对于序列到序列模型真正的难点在于,如果要用梯度下降去训练解码器,想让判别器输出的得分越高越好,就会发现很难做到。
用梯度下降法优化参数,当这个生成器(解码器)的参数有一点变化时,那么输出的分布也会有一点小小的变化,但是输出的词元可能不会有变化,因为输出的词元是根据输出的分布的分数得出来的。
假设输出的分布只有一点小小的变化,并且在取最大值的时候,或者说在找得分最高的那个词元的时候,你会发现得分最高的那个词元没有发生改变。输出的分布只有一点小小的变化,所以得分最高的那个词元还是同一个词元。对于判别器来说,输出的得分没有改变,判别器的输出也不会改变,所以根本没有办法算微分,也就没有办法做梯度下降。
ScartchGAN不需要预训练,可以直接从随机的初始化参数开始,训练生成器,然后让生成器产生文字。方法是调节超参数,并且加上一些训练技巧,就可以从零开始训练生成器。
此外生成模型不仅有GAN,还有VAE、流模型等。如果想要生产一些图片,最好用GAN。如果想要产生一些文字,则建议使用VAE或流模型。
8.6GAN的性能评估
其中一个方法是,训练一个图像分类系统,然后把GAN产生的图片输入这个图像分类系统,看看会产生什么样的结果。
但是会遇到成为模式崩塌(model collaps)的问题。所谓model collapse就是生成模型输出的图片总是与某一固定的真是图片十分接近,可能单拿出来一张还不错,但多了就会漏出马脚。
发生model collapse的原因,可以理解成这个地方是判别器的一个盲点,当生成器学会产生这种图片并知道其可以骗过判别器时,他就会一直这样做而不再进步。
解决办法:在训练生成器的时候,将训练节点保存下来,在model collapse之前把训练停下来,只训练到model collapse前,然后把之前的模型拿出来用。
还有另外一个问题很难评判,就是生成器产生的图片是不是真的具有多样性,这个问题叫做模式丢失,指GAN虽然能够很好的产生训练集中的数据,但它难以生成非训练集中的数据,即“缺乏想象力”
综上,看多样性的方法是:将生成器生成的图片输入一个图片分类系统,每张图片都会给我们一个分布,将所有图片的分布平均起来,如果平均后的分布非常集中,则多样性不够;如果平均后的分布非常平坦,则代表多样性够了。
看图片质量的方式:一张图片的分布如果很平坦,那么说明他啥都不太像,则质量不够,如果分布很集中,则质量够好。
看多样性和看图片质量的方式不一样,一个是看多张图片,一个是看一张图片。
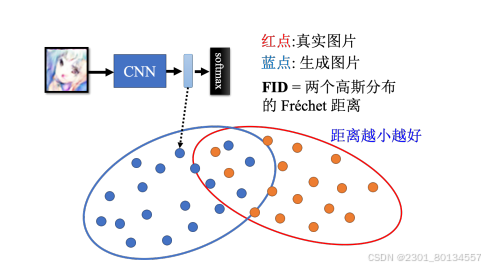
用FID分数来度量质量和多样性。具体来讲,就是先把生辰全国i产生的人脸图片输入Inception网络,让Inception网络输出图片的类别,这里需要的不是最终类别,而是进入softmax函数之前的隐藏层的输出向量,这个向量达到了上千维,代表一张人脸图片。
接下来,假设真实图片和虚假图片都服从高斯分布,然后计算这两个分布之间的FID。这两个分布之间的FID越小,代表这两张图片越接近,也就是虚假图片的品质越高。
两个细节:首先需要考虑做出真实图片和虚假图片都服从高斯分布的假设是否合理,其次,如果想要准确地得到网络的分布,则需要产生大量的采样样本,这需要一点运算量。
8.7 条件型生成
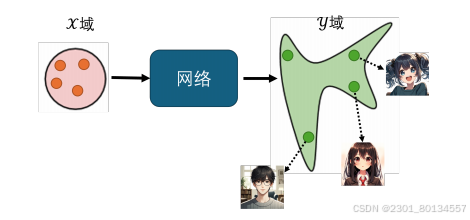
前面的GAN都是从一个分布中采样作为网络的输入,这种称为无条件型生成。而条件型生成(conditional generation)不仅要输入一个随机的分布,还要给定条件x,让生成器根据条件x和输入z产生输出y。
在条件型GAN中,让判别器不仅接收图片y,还要接收条件x。判别器输出的分数也不只看y好不好,还要看y和x配不配得上。
实际的训练中除了与文字匹配和不匹配的两种情况外,还要有一种不好的情况:已经产生了好的图片,但是和文字叙述匹配不上。所以我们通常把训练数据拿出来,然后故意把文字和图片打乱匹配,或者故意配一些错误的文字,告诉判别器看到这种状况也要输出“不匹配”。只有用这样的数据,才有办法把判别器训练好。
条件型GAN的应用:根据文字产对应图片,也可以用一张图片产生另一张图片,比如着色、素描图变实景等等,这类应用称为图像翻译,也叫做pix2pix。
8.8CycleGAN
到目前位置,前面的都是监督式学习,也就是训练数据都是成对的,有一个输入就有一个对应的输出标签。但我们还有可能遇到一种状况是,我们有一系列的输入和输出,但是输入x和输出y之间没有成对的数据。
举个例子,比如给真人图片转换成动漫图片,GAN可以在这种完全没有成对数据的情况下进行学习。
对于上面的例子,采样过程可以理解为从真实的人脸图片里随便挑一张照片出来,然后把这张照片输入生成器,让他产生另外一张图片。这时我们的判别器就需要改一下,不再只输入来自y域的图片,而是同时输入来自x域的图片和来自y域的图片,然后输出一个数值,这个数值代表这两张图片是不是一对的。
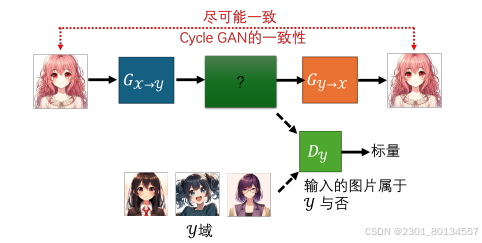
怎么强化输入与输出之间的关系呢?对于条件型GAN,默认是有成对数据的,这样才能给判别器判断输出y与输入x是否有关联,为了解决这个问题,我们可以使用循环生成对抗网络(Cycle GAN)
具体来说,在CycleGAN中,我们会训练两个生成器。第一个生成器会把x域的图片转换成y域的图片,在第二个生成器看到一张y域的图片后,它会把他还原为x域的图片。就这样经过两次转换后,输入跟输出越接近越好,或者说两张图片对应的向量之间的距离越小越好。
从x域到y域,再从y域到x域,是一个循环(cycle),所以这个方案称为CycleGAN,CycleGAN中有三个网络——两个生成器和一个判别器,判别器的工作是看第一个生成器的输出像不像y域的图片
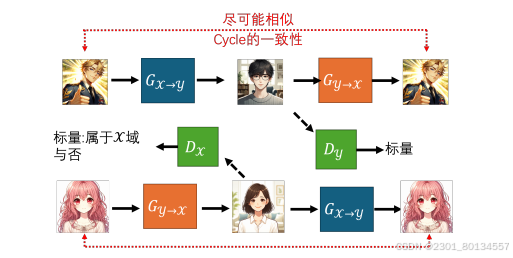
换个角度CycleGAN也可以是双向的,在把x域转换为y域的同时,也可以把y域转换为x域,但也需要增加一个判别器来判断y域转换成x域后的图片域x域的对比。
第九章 扩散模型(diffusion model)
diffusion model有很多不同的变体,本章主要介绍最知名的去噪扩散概率模型(Denoising Diffusion Probabilistic Model,DDPM)。
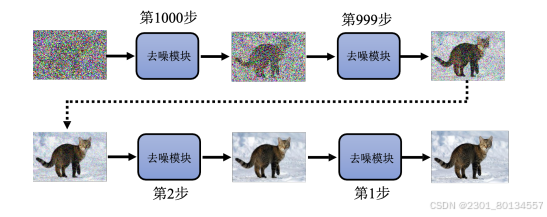
9.1diffusion model生成图片的过程
第一步,采样一张满是噪声的图片,也就是从高斯分布中采样得到一个向量,这个向量保存了一些数字,且这个向量的维度与所要生成图片的大小一模一样。
接下来是去噪模块,输入是一张满是噪声的图片,去噪模块会把噪声过滤掉一些,去噪次数是事先设定好的。
噪声到图片的过程称为逆过程(reverse process)
9.2去噪模块
扩散模型中反复使用了同一个去噪模块,对于每一种状况,输入的图片差异非常大,如果用同一个模型他可能不一定做的很好。所以去噪模块除了接收想要去噪的那张图片外,还会多接受一个输入,该输入代表现在的噪声的严重程度,如1000代表刚开始去噪的时候,噪声很多;1代表去噪的步骤快结束了,显然噪声很少。
去噪模块的内部做了什么事情呢?去噪模块内部有一个噪声预测器(noise predictor),用于预测图片里面的噪声。所以噪声预测器接收两个参数,一个是需要去噪的图片和噪声的严重程度,然后输出一张含有噪声的图片,用需要去噪的图片减去噪声图片以达到去噪的效果。
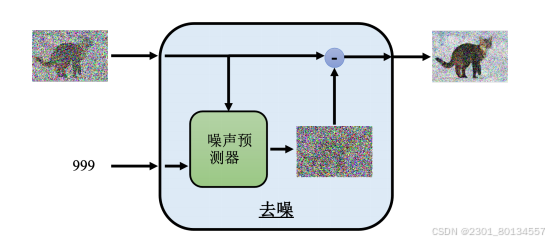
为什么不使用一个端到端的模型。使得输入是要被去噪的图片,输出就直接是去噪的结果呢?
因为产生图片的难度和产生噪声的难度是不一致的,如果它可以产生一直带噪声的猫的图片,那他几乎就可以说他学会画一只猫了,所以直接使用一个噪声预测器是比较简单的。
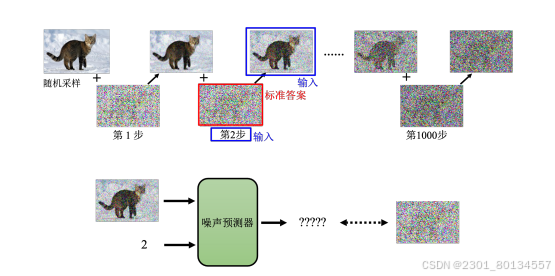
9.3训练噪声预测器
噪声预测器的训练数据是人为创造的,具体做法就是从数据集里拿出一张图片,随机的从高斯分布中采样一组噪声并加上去,从而产生有点噪声的图片,再采样一次就可以得到噪声更多的图片,以此类推。
加噪声的过程也成为前向过程,也成为扩散过程。
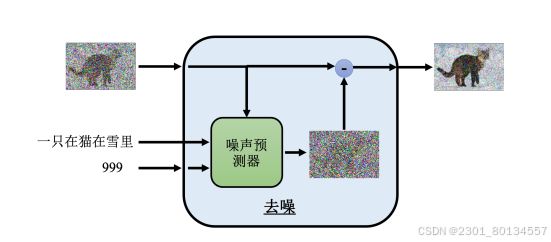
根据文字生成图像,还需要加上文字。去噪模块并非仅看输入的图片来去噪,而是根据输入的图片加上一段文字描述来把噪声去掉,所以在每一步,去噪模块都会有一个额外的输入。
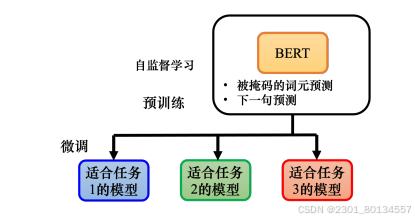
第十章 自监督学习(Self-Supervised Learning ,SSL)
如果在模型训练期间使用标注的数据,则称为监督学习;如果没有使用标注的数据,则称为无监督学习。
我们需要有标注的文章数据来训练监模型,而自监督学习是一种无标注的学习方式。如下图,假设我们有未标注的文章数据,则可以将一篇文章x分为两部分:模型的输入x’和模型的标签x”。将x‘输入模型并输出y,我们想让y尽可能地接近标签x"(学习目标),这就是自监督学习。
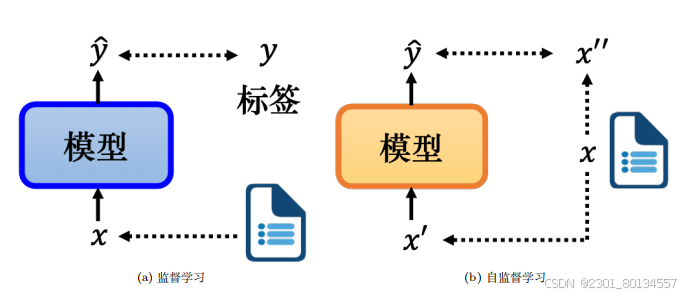
自监督学习模型的几个例子:
ELMO:来自语言模型的嵌入(Embeddings from Language Modeling),最早自监督学习模型。
BERT:来自Transformer的双向编码器表示(Bidirectional Encoder Representation from Transformers)
两种ERNIE:一个是知识增强的语义表示模型(Enhanced Representation through Knowledge Integration),另一个是具有信息实体的增强语言表示(Ehanced Language Representation with Informative Entities)
Big Bird:教长序列的Tranformer(Transformers for longer sequences)
10.1 BERT
BERT是一个Transformer编码器,BERT的架构与Transformer编码器完全相同,里面有很多自注意力、残差连接、归一化等。BERT可以输入一行向量,输出另一行向量。输出向量的长度与输入向量的长度相同。
BERT一般用在自然语言处理或者文本场景中,所以它的输入一般是一个文本序列,也就是一个数据序列。语音、图像都可以看作一种序列。
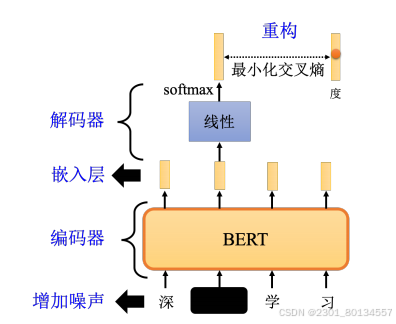
BERT的输入是一段文字。接下来需要随即掩码一些输入的文字,被掩码的部分是随机决定的
有两种方式可以实现掩码:一种方法是用特殊符号替换句子中的汉字,另一种方法是用另一个字随机替换一个字。
掩码的目的是对向量中的某些值进行掩盖,避免无关位置的数值对运算造成影响。
综上,在训练BERT的时候,应给BERT输入一个句子。先随即决定要掩码哪些汉字,再决定如何进行掩码。
BERT根据掩码做填空题,因为Transformer会考虑所有的输入,所以对掩码部分做线性变换并softmax可以得到一个分布来猜测被掩码的内容。
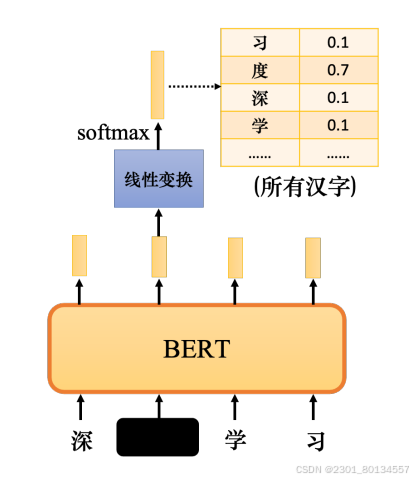
除了掩码外,还有另外一种方法——下一句预测(next sentence prediction),从数据库中拿两个句子,两个句子中间加上一个特殊词元[SEP]代表他们之间的分隔,在整个序列最前面加上一个特殊词元分类符号[CLS]。
只取[CLS]对应的输出,忽略其他输出,其是一个二元分类,它有两个可能的输出:是或否。下一句预测预测的是第二句是不是第一句的后一句,若是则输出是,否则输出否。
然而在一篇论文中表示,下一句预测几乎没什么帮助,还有一种类似于下一句预测方法——句序预测(sentense order prediction,SOP)。
主要思想为:本来相连的两个句子,要么句1在句2后面,要么句2在句1后面,BERT需要回答是哪一种可能,或许因为难度大,所以它有效。他被用在名为ALBERT的模型中。
10.1.1 BERT的使用方式
在训练时,BERT完成了填空题和预测句序两个任务,这个过程称为预训练,产生BERT的过程是自监督学习。
但BERT不仅可以做填空,还可以做一些更为实际的任务,这些任务也是实际使用BERT的任务,称为下游任务(downstream task),BERT学习完成下游任务时仍然是需要有标注的数据的。
将BERT分化并用于完成各种任务称为微调(fine-tuning)
自监督学习模型的能力通常是在多个任务上测试的。可以让BERT分化做各种任务,查看它在每个任务上的准确率,再取平均值。对模型进行测试的不同任务的这个集合,称为任务集。任务集中最著名的标杆(基准测试)称为通用语言理解评估(General Language Understanding Evaluation,GLUE)
GLUE里面一共有9个任务,如果想知道像BERT这样的模型是否训练的好,可以针对这个9个单独的任务对模型进行微调,然后我们获得9个模型,这9个任务的平均准确率代表自监督学习模型的性能。
同时,光看测试数值没什么意义,还要看模型跟人类之间的差距。
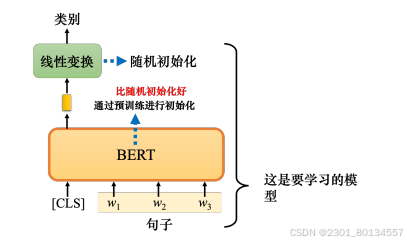
情况1:情感分析(输入一个序列,输出一个类别)
单个BERT没有办法解决情感分析问题,需要一些标注数据,将BERT与这种线性变换放在一起,称为完整的情感分析模型。线性变换和BERT都利用梯度下降来更新参数。线性变换的参数是随机初始化的,而BERT的初始参数是从学会了做填空题的BERT得来的。
在训练网络时,使用随机初始化的BERT与会做填空题的BERT相比,损失下降的速度相对较慢,这就是BERT带来的好处。
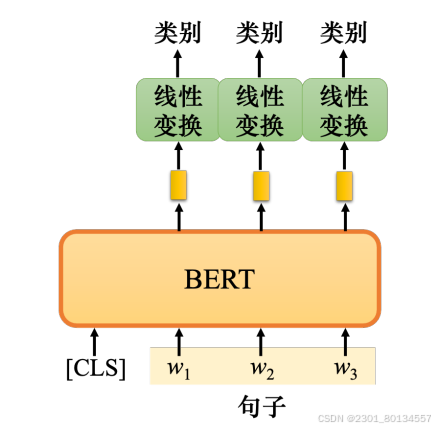
情况2:词性标注(输入一个序列,输出另一个序列)
唯一不同的是,BERT部分的参数不是随机初始化的,BERT已经在与训练过程找到了一组比较好的参数。
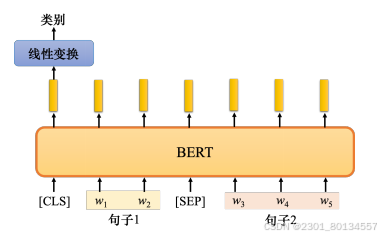
情况3:自然语言推理(输入两个句子输出一个类别)
Natural Language Inference,NLI,给机器两个输入语句:前提(premise)和假设(hypothesis)。机器要做的是判断是否可以从前提中推断出假设,即判断前提与假设是否矛盾
常见的任务为立场分析,根据文章和留言判断留言是正面的还是负面的。
情况4:基于提取的问答(问答系统)
extraction-based question answering,模型要做的实际上是预测正确答案的起始位置,如果文章中没有答案就不能使用这个技巧,蓝色和橙色向量是随机初始化的,而BERT是由预训练的权重初始化的。
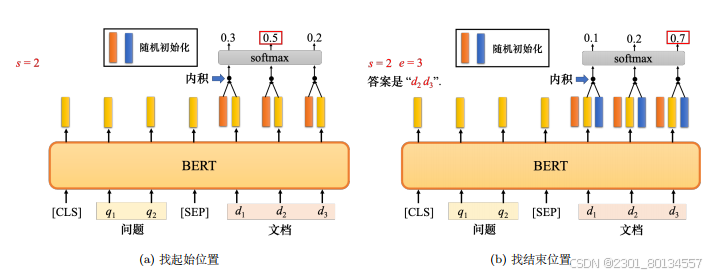
Q:BERT的训练方法是半监督的还是无监督的?
A:在学习填空时,是无监督的。但在使用BERT执行下游任务时,下游任务需要有标注的数据。自监督学习会使用大量未标注的数据,但下游任务有少量有标注的数据,所以合起来是半监督的,即有大量未标注的数据和少量有标注的数据,这种情况称为半监督。所以使用BERT的整个过程就是进行预训练和微调,BERT可以视为一种半监督的模型。
Q:BERT的输入长度有限制吗?
A:理论上没有,实际上有,因为受运算量限制,自注意力的运算量很大,一般来说最多也就512.
Seq2Seq模型
上述任务均未涉及Seq2Seq模型,其不仅需要编码器,还需要一个解码器。而我们的BERT只有预训练的编码器,这就涉及到了如何训练解码器的问题,我们的做法是对编码器的输入做一些扰动以损坏句子,解码器想要输出的句子跟损坏之前是完全相同的,编码器看到损坏的结果,解码器则输出句子被损坏之前的结果,这样就达到了训练解码器的效果。
损坏句子的方式有很多:打乱单词顺序、掩盖单词、删除单词都可以,也可以结合使用。
10.1.2 BERT有用的原因
最常见的解释是,当输入一串文字时,每个文字都有一个对应的向量,这个向量称为嵌入,这个向量很特别,它代表了所输入文字的意思。
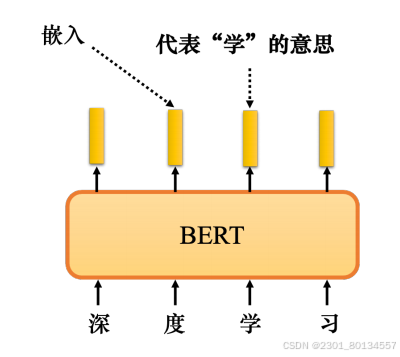
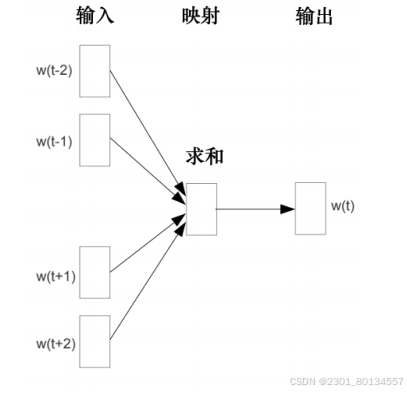
同时,BERT在学习填空的过程中所做的也许就是学习从上下文中提取信息,而这样的想法在BERT之前就已经存在了。有一种技术叫词嵌入,词嵌入中有一种技术称为连续词袋(Continuous Bag Of Words,CBOW)。
CBOW模型所做的与BERT完全相同,把中间挖空,预测空白处的内容。CBOW模型可以给每个词一个向量,这个向量代表词的意思,CBOW模型是一个非常简单的模型,他只使用了两个变换。
BERT还可以根据 不同的上下文从相同的词中产生不同的嵌入,因为他是词嵌入的高级版本,考虑了上下文。BERT抽取的这些向量或嵌入也称为语境化的词嵌入(contextualized word embedding)
10.1.3 BERT的变体
多语言BERT(multi-lingual BERT),在预训练期间,多语言BERT的学习目标是做填空题,它只学会了中文填空,接下来教他做英文问答,它自动学会了中文问答。一种简单的解释是,对于多语言BERT,不同语言的差异不大。
数据量是不同语言能否成功对其的关键,很多现象只有在数据量足够是才会显现出来。过去没有模型具有多语言能力来在一个语言中进行问答训练后直接转移到另一个语言,一个可能的原因是过去没有足够的数据。
10.2 GPT
GPT要完成的任务是预测接下来出现的词元。GPT建立在Transformer解码器的基础上,不过GPT会做掩码注意力,在给定<BOS>预测<深>的时候,GPT不会看到接下来出现的词元。
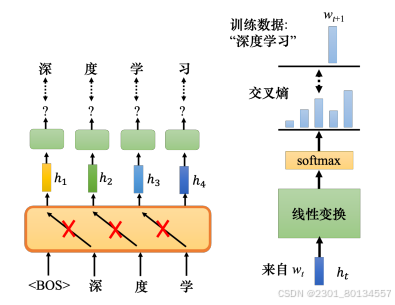
BERT是在Transformer编码器的后面借一个简单的线性分类器,也可以把GPT拿出来借一个简单的线性分类器,但是GPT的作者没有这样做,因为GPT太大了,大到连微调都可能十分困难
小样本学习(few-shot learning),即在小样本上进行快速学习。每个类只有k个标注样本,k非常小。如果k=1,称为单样本学习(one-shot learning);如果k=0,称为零样本学习(zero-shot learning)
如果要GPT做翻译,只告诉它任务描述,然后给几个例子,最后直接给出需要翻译的内容。GPT中的小样本学习不是一般的学习,这里完全没有梯度下降,训练的时候要做梯度下降,而GPT中完全没有梯度下降,也完全没有要调模型参数的意思。这种训练称为语境学习(in-context learning)

第十一章 自编码器
自编码器(autoencoder),也可以算作自监督学习的一环。
在BERT和GPT之前,其实有一个更老的,不需要使用标注数据的模型,它就是autoencoder,所以也可以把autoencoder看作一种自监督学习的预训练方法。
从自监督学习(即不需要标注数据来训练)这个角度看,autoencoder可以视为自监督学习的一种方法,与完成填空或预测接下来的词元比较类似,只是采用了另外一种不同的思路。
11.1自编码器的概念
自编码器有两个网络,即编码器和解码器。编码器把一张图片读进来,转换成向量,解码器读进向量再生成一张图片。编码器可能是拥有很多层的CNN,而解码器的网络架构可能比较像GAN中的生成器。
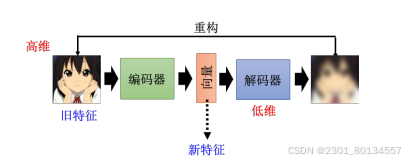
训练目标是编码器的输入与解码器的输出越接近越好。如果把图片看作一个很长的向量,那么我们希望输入图片的这个向量与解码器输出图片的向量越接近越好,也有人把这个事情叫做重构(reconstruction)。
自编码器背后的理念和CycleGAN其实一模一样,都希望所有的图片经过两次转换后,跟原来的输入越接近越好。而这个训练过程完全不需要任何的标注数据,只需要手机大量的图片就可以完成。因此这是一种无监督学习的方法。
编码器的输出有时候叫嵌入,嵌入又称为表示或编码。
怎么把训练好的自编码器用在下游任务上呢?常见做法是把输入的很长的向量输出为另一个比较短的向量,然后拿这个新的向量完成接下来的任务。即高维度压缩为低维度。
对于编码器来说,本来输入是很宽的,输出也是很宽的,但中间特别窄,这中间的一段就叫做瓶颈。
综上,编码器要做的事情就是把本来高维度的东西转成低维度的东西,这个事情叫做降维。
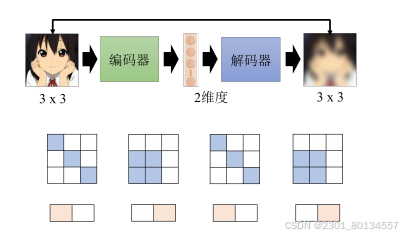
11.2为什么需要自编码器
一般在训练的时候,图片的变化是有限的,因此我们在做编码器的时候,有时只用两个维度就可以描述一张图片。
编码器要做的事情就是化繁为简,有时本来比较复杂的东西,实际上只是表面上看起来复杂,它本身的变化是有限的。我们只需要找出其中有限的变化,就可以将本来复杂的东西用更简单的方法来表示,从而只需要比较少的训练数据,就可以让机器学习,这就是自编码器的概念。
11.3去噪自编码器
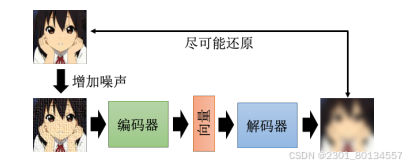
自编码器有一个常见的变体,叫做去噪自编码器(denoising autoencoder)。
我们现在还原的不是编码器的输入,输入编码器的图片是有噪声的,我们要还原的是加入噪声之前的图片。所以现在的编码器和解码器除了要完成还原图片这项任务外,还必须自己学会把噪声去掉。
去噪自编码器也不算太新的技术,BERT中的掩码可以算作一种噪声,BERT其实就是一个去噪自编码器。
解码器不一定是线性模型,从某一层的输出是嵌入开始,后面的才是解码器
11.4自编码器之特征解藕
自编码器可应用于特征解耦(feature disentanglement)。解耦是指把一堆本来纠缠在一起的东西解开。
如果我们想知道我们在训练一个自编码器的时候,同时知道嵌入的哪些维度代表了那些信息,那么所需要的技术就是 feature disentanglement
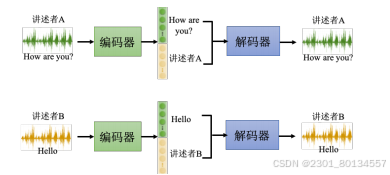
举个例子就是如果我们有两个讲述者的声音讯号,但我们想让A的声音说B的话,那么我们就需要知道嵌入每个维度所代表的信息,然后重新拼合,即可得到我们想要的效果。
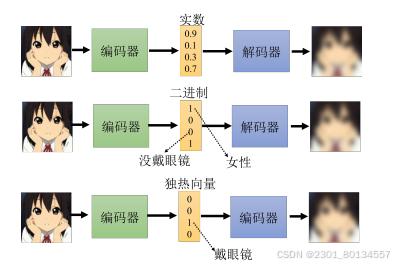
11.5自编码器应用之离散隐表征
截至目前为止,我们的编码器输出的嵌入都是一个向量,那么我们是否可以让其输出其他的东西来代替向量,比如输出二进制数,这样每一维度或许都可以表征一个信息比如性别这样;又或者可以输出独热向量,而每一个独热向量都可以表征为一个类别。
这样的输出在保留自编码器原有的功能时,或许还可以让我们在解释编码器的输出时更为容易,或者让机器自动学会无监督的分类
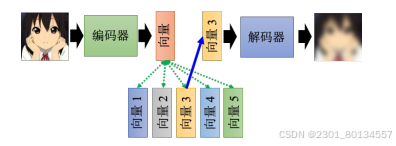
在这种离散的表征技术中,最知名的就是向量量化变分自编码器(Vector Quantized-Variational Autoencoder,VQ-VAE)
他的运作原理就是输入一张图片,然后编码器输出一个向量,这个向量很普通并且是连续的,但接下来有一个码本,码本就是一排向量,这排向量也是学出来的,计算编码器的输出和这排向量间的相似度,把相似度最大的那个向量拿出来,让这个键和那个值共用同一个向量
解码器、编码器和码本,都是一起从数据那里面学出来的,这样做的好处就是可以有离散的隐表征,也就是说,这边解码器的输入一定是那边码本里面的向量中的一个。假设码本里面有32个向量,解码器的输入就只有32种可能,这相当于让这个嵌入变成离散的,他没有无穷无尽的可能,只有32种可能而已。
如果用在语音上,码本中的每个向量就可以用来对应某个发音。
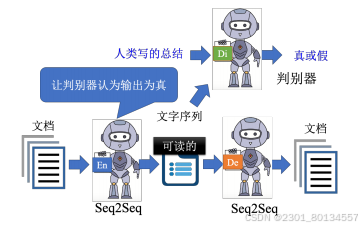
另一种疯狂的做法是,将嵌入变成一串文字,这样做有什么好处呢?也许这串文字就是文章的摘要。它不是一个普通的自编码器,而是一个Seq2Seq的自编码器。这个自编码器在训练的时候不需要标注的数据,只需要收集大量的文章即可。
然而,实际上这样训练起来以后,就会发现是行不通的,因为编码器和解码器之间会发明暗号,嵌入的文字我们根本看不懂,所以我们需要加上一个判别器
11.6自编码器的其他应用
自编码器的其他应用,解码器可以应用在生成器上。前面提到过的除了GAN以外的另外两个生成模型,其中一个就是变分自编码器(Variaional AutoEncoder,VAE),它实际上就是把自编码器中的解码器拿出来当作生成器来用。
自编码器还可以用来压缩,我们完全可以把编码器的输出当作一个压缩的结果,对应解码器做的事情就是解压缩。只是这个压缩是有损压缩,有损压缩会导致图片失真。通过自编码器压缩出来的图片必然失真,就跟JPEG图片失真是一样的。
第十二章 对抗攻击
要真正使用这些神经网络,仅仅提高他们的准确率是不够的,还需要让他们能够对抗来自外界的攻击。我们不仅要在正常情况下得到高的准确率,还要在有人试图欺骗神经网络的情况下得到高的准确率。
12.1对抗攻击简介
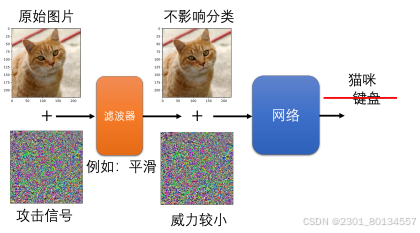
下图是一个例子,我们要做的攻击就是给这张照片加入非常小的噪声。具体做法是,一张照片可以看作一个矩阵,在这个矩阵的每一个数据上都加入一个小小的噪声,然后把这张加入噪声的照片输入网络,查看输出的分类结果。我们把被加入噪声的照片叫做受攻击的图像。
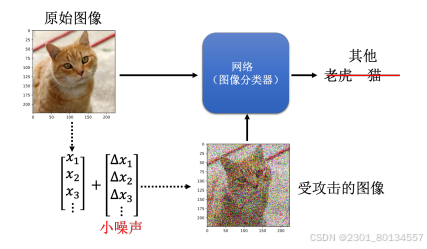
攻击大致上可以分成两种类型:一种是无目标攻击,只要受到攻击的图像的输出不是猫就算攻击成功;另一种是有目标攻击,我们希望受到攻击的图像的输出是狮子等,也就是说攻击要指定输出。
我们可以加入一些人眼看不到的噪声来改变网络的输出,同时还有一个置信得分,置信得分也就是执行完softmax操作以后得到的分数,分数越高代表机器越肯定目前的输出结果
12.2 如何进行网络攻击
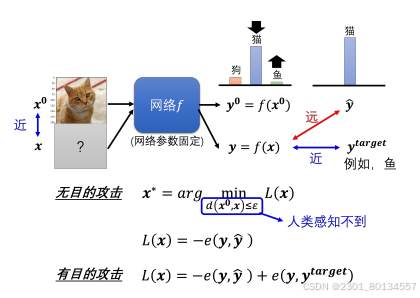
假设网络参数固定,不考虑网络的参数部分。给网络f输入一张新的图片x。无目标攻击时,我们希望网络输出y与正确答案y^越远越好;有目标攻击时,我们还希望y与ytarget越近越好。
这里我们要解一个优化问题,首先定义一个损失函数L,他表示网络输出y和正确答案y^之间的差距,我们在交叉熵前面加上一个负号以此来表示这个损失函数L,众所周知交叉熵越小表示两个y越接近,而我们现在希望两个y离得远,也就是让交叉熵越大,所以我们要L越小,两者的差距也就越大。所以L越小表示两者的距离越大,说明攻击效果好。
这样做的目的就是我们的目标仍然是让使L变小,所以我们仍然可以用梯度下降法。
而对于有目标攻击,我们还希望y和ytarget越来越接近,也就是交叉熵越来越小,所以前面不需要加负号。
另外需要注意的是,我们希望找到一个x,在最小化损失(攻击效果好)的同时保证加入的噪声越小越好。也就是说我们希望新找到的图片可以骗过网络,并且与原来的图片越相似越好。
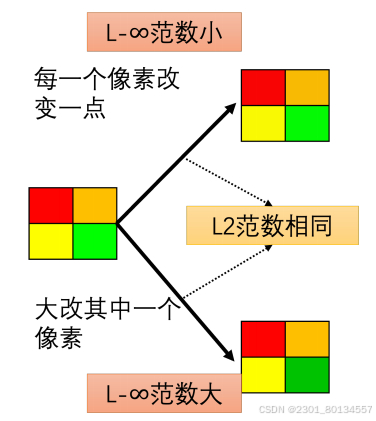
所以我们在解这个优化问题时,还会多加入一个限制——x与x0之间的差距不能大于某个阈值ε,即d(x0,x)<=ε,这个阈值是根据人类的感知能力而定的。
这个限制可以用L2范数或者L∞范数表示,具体哪个攻击更好?L2范数是取每一个Detax的平方和开根号所以它看平均差距,L∞范数是取最大的Detax的绝对值所以他看最大差距。
在图片识别领域,L∞范数更符合人类的感知能力,因为人类的感知能力更多地关注最大的变化量,而不是关注所有的变化量。
在实际应用中,其实也要凭领域知识来定义这个距离
要保证x和x0之间的距离不要太大,这里直接在梯度更新以后再加一个限制即可。比如x只能在这个方框内,更新梯度后如果x超出了方框,把它拉回来就可以了,也就是在方框内找一个与蓝色的点最近的位置,然后把蓝色的点拉进来。
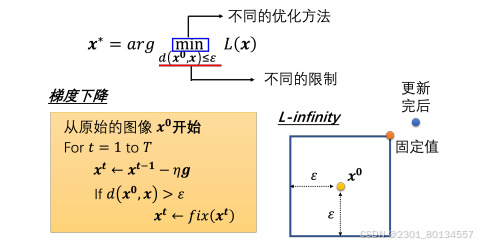
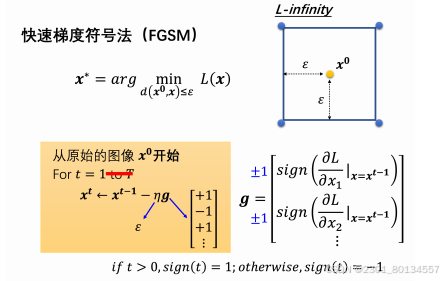
12.3快速梯度符号法
一种最简单的攻击,叫做快速梯度符号法(Fast Gradient Sign Method,FGSM),一般在做梯度下降的时候,需要迭代更新参数很多次,但有了这种方法以后,只需要更新一次参数就可以了。
FGSM为原始梯度g做了一个特别的设计,不是直接使用梯度下降的值,而是加了一个符号函数,值大于0就输出1,值小于0就输出-1,所以加了符号函数以后g要么1要么是-1。至于学习率,直接设置为ε,这样更新后的x一定落在蓝色框的边缘。
但是这种方法只需要更新迭代一次就够了,多迭代几次的坏处是可能一不小心就出界,这样还需要之前的方法把x拉回来。
基于更新迭代的FGSM,效果要比原始的FGSM效果好,但也更复杂了。
12.4白箱攻击与黑箱攻击
白箱攻击需要知道模型的参数,所以也许白箱攻击不是很危险。换个角度,其实如果要保护我们的模型不被别人攻击,只要注意不要随便把自己的模型放到网络上公开让大家取用就好。
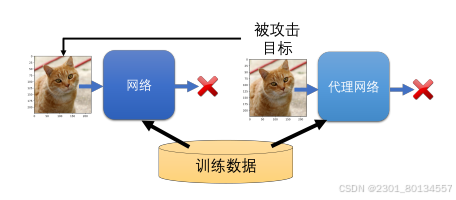
然而,其实我们的模型参数是可以通过一些方法反推出来的,这叫黑箱攻击。
如果我们无法获知一个模型中的具体参数,但我们知道他用什么样的训练数据训练出来的,我们就可以训练一个代理网络,用代理网络来模仿我们想要攻击的对象。如果他们都使用同样的训练数据,也许他们就会有一定的相似度。如果代理网络与要攻击的网络有一定程度的相似性,我们只要对代理网络进行攻击,也许要攻击的网络也会被攻击成功。
如果没有训练数据,直接将一些现有的图片输入到攻击目标网络中,然后看他会输出什么,再把输入输出的成对数据拿去训练一个模型,我们就有可能训练出一个类似的网络,也就是代理网络了,我们再对代理网络进行攻击即可。
实际上,黑箱攻击在进行无目标攻击的时候比较容易成功,在进行有目标攻击的时候不太容易成功。为了提高黑箱攻击的成功率,我们可以使用集成学习的方法,也就是使用多个网络来攻击。
为什么黑箱攻击非常容易成功?小丑鱼的实验表明:攻击的方向对不同的网络的影响都很类似,所以有些人认为攻击会成功,主要的问题来自数据而非模型。机器把这些加入了非常小的噪声的图片误判为另一个物体,可能是因为数据本身的特征就是如此,在有限的数据上,机器学到的就是这样的结论。所以对抗攻击成功的原因来自数据,当我们有足够的数据时,也许就有机会避免对抗攻击。
对于攻击信号,我们希望它越小越好,到底可以小到什么程度呢?其实已经有人做出了单向素攻击——仅仅改动了图片里面的一个像素。
单向素攻击的成功率并不是特别高,所以我们还是希望能找到更好攻击方式
比单向素攻击更好的攻击方式是通用对抗攻击,也就是说,我们需要找到一个攻击信号,这个攻击信号可以攻击所有的图片。
12.5 其他模态数据被攻击案例
目前虽然语音合成系统往往可以合成出以假乱真的声音,但这些以假乱真的声音大部分具有固定的模式和特征,与真正的声音相比存在一定程度的差异,这种差异可能人耳听不出来,但机器可以捕捉到。我们可以利用机器学习的方法来检测这些差异,从而达到检测声音是不是合成的这一目的。
但是这些可以检测语音合成的系统,其实也会被攻击。比如有些声音人耳可以听出来是合成的,检测模型也可以正确的输出,在这段声音里加入一个小的噪声,这个噪声人耳是听不出来的,同一个检测模型就会觉得这段声音是真实的声音,而非合成的声音。
12.6现实世界中的攻击
真实世界的攻击比虚拟世界中的攻击更加困难,需要考虑的实际问题也会更多。
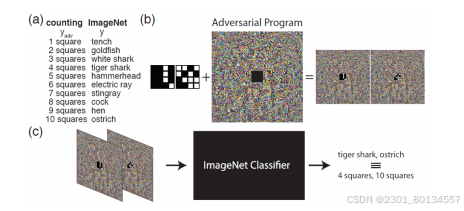
有一种攻击叫做对抗重编程(adversarial reprogramming),如下图对抗重编程想做一个方块识别系统,去数图片中方块的数量,但它不像训练自己的模型,而是希望寄生在某个已有的训练在ImageNet的模型上面。
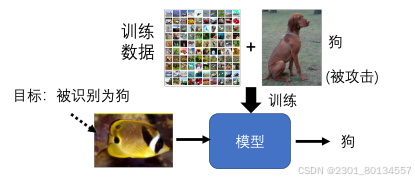
还有一种令人惊叹的攻击方式,就是在模型里面开一个后门 。这种攻击在训练截断就展开的。
在训练数据中加入一些特别的、看起来没有问题但实际上有问题的数据,这些数据会让模型在训练的时候开一个后门,使得模型在测试的时候识别错误,而且只对某些图片识别错误,对其他图片的识别没有影响。
这种攻击方式是非常隐蔽的,因为我们的训练数据是正常的,而且我们的模型也是正常的,直到有人拿这张图片来攻击模型的时候,我们才发现模型被攻击了。
当然,基于后门的攻击也不是那么容易成功的,里面有很多的限制,比如模型和训练方式都会直接影响基于后门的攻击能否成功。
12.7防御方式中的被动防御
防御方式分为两类:一类是被动防御,另一类是主动防御。
被动防御就是保持已经训练好的模型不动,在模型的前面加上一个“盾牌”,也就是一个滤波器。攻击者期待为图片加上攻击信号就可以骗过网络,但是这个滤波器可以削弱攻击信号的威力。一般的图片不会受到这个附加的滤波器的影响,但是攻击信号在经过滤波器后就会失去原有的为例,使得原始网络不会识别错误。
我们要设计的滤波器其实也很简单,比如把图片稍微模糊一点,就可以使攻击信号减弱。
这种方法可行的原因是,只有某个特定的攻击信号才能够攻击成功,在做了平滑模糊化处理以后,那个本可以攻击成功的特殊噪声就变了,也失去了攻击的威力。但是这个新加的滤波器对原来的图片影响很小,所以我们的原始网络还是可以正确识别图片。
当然这种模糊化的方法也有一些副作用,比如本来完全没有被攻击的图片,在稍微平滑模糊化以后,虽然仍可以被正确识别,但置信分数下降了。
所以像这种平滑模糊化的滤波器,我们要有限制地使用,否则会产生副作用,导致正常的图片被识别错误。
还有一种被动防御的方法,失真这件事情就可以让攻击图片失去原有的攻击威力。
此外,还有另一种基于生成的方法,即给定一张图片,然后让生成器生成一张和输入一摸一样的图片。对于生成器而言,它从没有看过某些噪声,所以只有很小的概率可以复现能够攻击成功的噪声。
被动防御有一个非常大的弱点,虽然模糊化非常有效,但一旦被别人知道我们在用模糊化这种防御方法,这种防御就失去了作用。还有一种强化版的防御方法,叫做随机化防御,就是想方设法不让别人猜中你的下一招。
12.8防御方式中的主动防御
主动防御的思路是,在训练模型的时候,一开始就要训练一个比较不会被攻破的鲁棒性(robustness)非常强的模型,这种训练方式被称为对抗训练。对抗训练就是在训练的时候,不要只用原始的数据,还要加入一些攻击的数据。
所以整个对抗训练的流程就是,先训练好一个模型,再看看这个模型有没有社么漏洞,把漏洞找出来,并且填好漏洞,循环往复,最后就可以训练出一个鲁棒性比较强的模型。
这也可以视为一种数据增强的方法,因为我们产生了更多的图片x~,把这些新图片添加到原始的训练数据里就相当于数据增强。
对抗训练有一个非常大的缺点,就是不见得能挡住新的攻击算法。
所以总结起来,对于比较容易成功的攻击(黑箱攻击也是有可能成功的),防御的难度就会大一些。目前攻击和防御的方法仍在不断地演化,国际会议上也会不断有新的攻击和防御方法被提出,他们仍然互为对手,独自演化。

第十三章 迁移学习(transfer learing)
假设A、B是两个相关的任务,A任务有很多训练数据,可以把A任务中学习到的某些可以泛化的知识迁移到B任务。迁移学习有很多类型,本章介绍领域偏移(domain shift)、领域自适应(domain adaptation)和领域泛化(domain generalization)。
13.1领域偏移(domain shift)
若训练数据和测试数据的分布不同,在训练数据上训练出来的模型,在测试数据上就可能效果不佳,这称为domain shift。举个例子就是训练数据是黑白数字图片识别数字,而测试数据是彩色数字图片。
domain shift其实有很多种不同的类型:
1.模型输入数据分布有变化:训练数据上每个数字出现概率一样,测试数据上每个数字出现概率不一样.
2.模型输出的分布有变化:某个数字输出的概率特别大.
3.输入输出分布一样但关系变了:一张图片在训练数据里标签为0,在测试数据里标签为1.
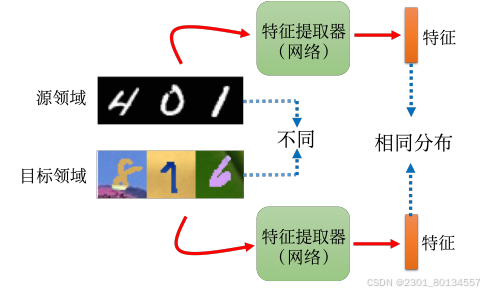
接下来我们专注第一种情况即输入数据分布有变化。我们称测试数据来自目标领域(target domain),训练数据来自源领域(source domain)。
在实际应用中,当训练数据和测试数据稍有有点差异时,机器的表现可能就会比较差,因此需要domain adaptation来提升机器的性能。
对于domain adaptation,训练数据是一个domain,测试数据是另一个domain,我们需要机器从其中一个domain学到的信息用到另一个domain。
domain adaptation侧重于解决特征空间与类别空间一致,但特征分布不一致的问题。
13.2领域自适应(domain adaptation)
用源领域训练出来的模型要想用在不一样的领域,必须对测试数据所在的目标领域有一定的了解。
随着了解的程度不同,domain adaptation的方法也不同:
1.target domain有一大堆有标签的数据:不需要做domain adaptation,可以直接使用target domain的数据进行训练。
2.target domain有一些有标签的数据:可以用domain adaptation,用这些有标注的数据微调在source domain上训练出来的模型。
这里的微调和BERT的微调很像,已经有在source domain上训练好的模型,只要拿target domain上的数据跑两三个回合就足够了。但因为target domain上的数据很少,需要注意不要在target domain的数据上迭代太多次,否则容易过拟合到target domain上的少量数据上。
过拟合的解决办法:调校学习率、模型微调前后的参数不要差太多、模型微调前后输入和输出也不要差太多等等。
3.target domain上有大量未标注的数据:最基本思路是:训练一个特征提取器(feature extractor),特征提取器会把他们不一样的部分去除,只提取出他们共同的部分。source domain和target domain的图片在通过feature extractor之后得到的特征是没有差异的,分布相同。通过feature extractor我们可以在source domain训练一个模型,然后直接用在target domain。通过领域对抗训练(domain adversarial training),我们可以得到领域无关的表示。
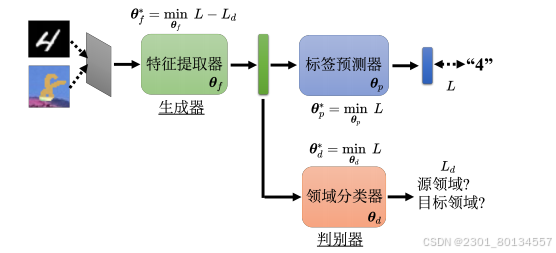
一般的分类器分成特征提取器和标签预测器(label predictor)两部分 。比如一个图像分类器有10层,可能前5层是特征提取器,后5层是标签预测器,具体是哪些层自己调整。
如下图所示我们要训练一个领域分类器,他是一个二元分类器,其输入是feature extractor 输出的向量,其学习目标是判断这个向量来自source domain 还是target domain,而feature extractor的学习目标是想办法骗过领域分类器。这很像GAN中的生成器和判别器。标签预测器也会根据feature extractor输出的向量来判断图片的类别,所以这就限制了feature extractor不能永远输出0向量来骗过领域分类器。
各个参数分别如下图所示,θ为参数,L为交叉熵代表的损失。我们要去找一个θp,让L越小越好。
还要找一个θd让Ld越小越好。
标签预测器要让source domain的图像分类越正确越好,领域分类器要让领域的分类越正确越好。而特征提取器站在标签预测器这边,它要做的事情与领域分类器相反,他要找出两个领域相同点,让其越接近越好使两个领域提取出来的分布是一样的。所以特征提取器的损失就是L-Ld。
如果领域分类器根据一张图片的特征来判断这张图片是否属于源领域,则特征提取器根据这张图片的特征来判断这张图片是否属于目标领域,这样就可以分开源领域和目标领域的特征。
本来领域分类器要让Ld越小越好,特征提取器要让Ld的值越大越好,他们的目标都是分开源领域和目标领域的特征,这就是最原始的领域对抗的方法。
当我们给无标签数据划分类别时,应该尽量让这个类别远离已有的决策边界。最简单的做法就是把很多无标注的图片先输入特征提取器在输入标签预测器,如果输出的结果集中于某个类别就表示离决策边界远,如果输出结果的每一个类别都非常近则表示离决策边界近。
除了这个简单的方法外,还可以使用DIRT-T、最大分类器差异(maximum classifier discrepancy)等方法。
到目前为止,我们一直假设源领域和目标领域的类是一模一样的,比如源领域有老虎狮子狗,目标领域也有老虎狮子狗,但目标领域实际上是没有标签的,里面的类是未知的。强制性的将源领域与目标领域完全对其是有问题的。源领域和目标领域有不同标签这一问题的解决方法,参考论文“Universal Domain Adaptation”
但还有一种可能就是,目标领域不仅没有标签,而且数据很少,比如目标领域只有一张图片,也就无法和源领域对其,这种情况可以使用测试时训练(Testing Time Training,TTT)方法。
Q:假设特征提取器是CNN而不是线性层,领域分类器的输入是特征映射,特征映射本来就有空间的关系,把两个领域拉在一起会不会影响隐空间(latent space),导致latent space没能学到我们希望它学到的东西?
A:会有影响,就是说CNN输出给领域分类器的是特征映射,如果把来自两个源领域和目标领域的两个特征映射强行拼接在一起让领域分类器去判断,可能会影响他们各自原来的latent space丢失重要信息从而导致后续的标签分类器没法正确分类。
所以领域自适应的训练要做好两方面的事情,一方面要骗过领域分类器,另一方面要让分类变正确,即不仅要把两个领域对其在一起,还要使得隐空间的分布是正确的。比如我们觉得1和7很像,为了让领域分类器也这么认为,特征提取器会让1和7比较像,因为要提高标签预测器的性能,所以隐表示(latent representation)里面的空间仍然是一个比较好的隐空间。但如果我们的目的仅仅是骗过领域分类器,这件事情的权重就太大了。模型学会的就只是骗过领域分类器,而不会产生好的隐空间。
13.3领域泛化(domain generalization)
对目标领域一无所知,而且并不是要适应到某些特定领域的问题通常称为领域泛化。领域泛化分为两种情况:
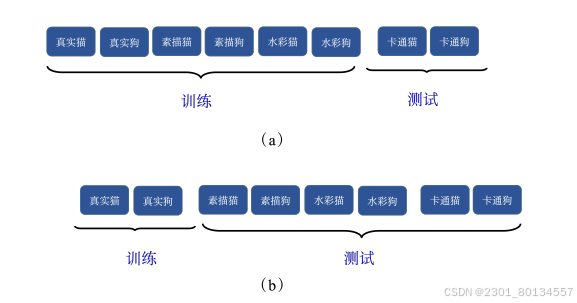
一种情况是:训练数据非常丰富,包含各个不同的领域,而测试数据只有一个领域。具体细节见论文“Domain Generalization with Adversarial Feature Learning”
另一种情况是:训练数据只有一个领域,而测试数据包含多个不同的领域。我们可以使用数据增强的方法产生多个领域的训练数据,具体细节见“Learning to Learn Single Domain Generalization”
第十四章 强化学习(Reinforcement Learning,RL)
在强化学习里,给定机器一个输入,最佳的输出是未知的。所以当正确答案是未知的或者收集有标注的数据很困难时,可以考虑使用强化学习。强化学习在学习的时候,机器不是一无所知的,虽然不知道正确的答案,机器会和环境(environment)互动,得到奖励(reward),从而知道输出的好坏。
强化学习里面有一个智能体(agent)和一个环境,agent会和环境互动。环境会给智能体一个观测(observation),智能体在看到这个观测后,就会采取一个动作(action),该action会影响环境,环境会给出新的观测,智能体则给出新的动作。
观测是智能体的输入,动作是智能体的输出,所以智能体本身就是一个函数。这个函数的输入是环境提供给他的观测,输出是智能体所要采取的动作。在互动的过程中,环境会不断地给智能体奖励(reward),让智能体知道它现在采取的这个动作的好坏。智能体的目标是最大化从环境获得的奖励总和。
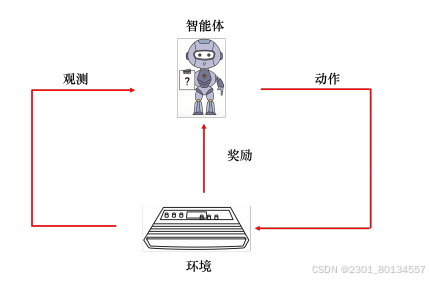
14.1强化学习的应用
电子游戏、下围棋。
14.2强化学习框架
强化学习也有类似与机器学习的3个步骤:定义函数、定义损失、优化。
14.2.1第一步 定义函数
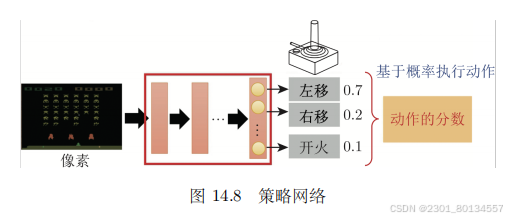
有未知数的函数是智能体。在强化学习里面,智能体是一个网络,通常称为策略网络(policy network)。
网络的架构可以自行设计,只要网络能够输入游戏的画面、输出动作即可。
如下图所示的网络,输入游戏画面,policy network的输出是左移0.7分,右移0.2分、开火0.1分。这类似于分类网络,输入一张图片,输出则决定了这张图片的类别,分类网络会给每个类别一个分数。分类网络的最后一层是softmax层,每个类别都有一个分数,这些分数的总和是1。机器最终决定采取哪一个动作,取决于每一个动作的分数。常见的作法是把这个分数当作一个概率,按照概率采样,随机决定所要采取的动作。
随机采样的好处是,机器每次看到同样的游戏画面时采取的动作也会略有不同。
14.2.2第二步 定义损失
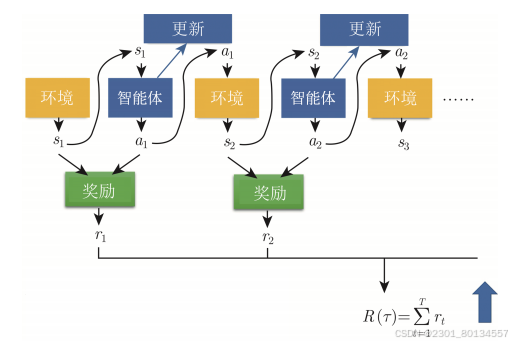
游戏从开始到结束的整个过程称为一个回合(episode)。在整个游戏过程中,机器会采取非常多的动作,每一个动作都会有一个奖励,所有奖励的总和称为整个游戏的总奖励(total reward),也称为回报(return)。
回报将从游戏一开始得到的r1,一直累加到游戏最后结束时得到的rt。假设这个游戏互动了T次,得到回报R。我们想要最大化回报R,这是训练的目标。
回报和损失不一样,损失越小越好,回报则越大越好。如果把负的回报当作损失,则回报越大越好,负的回报越小越好。
14.2.3第三步 优化
在一次游戏中,我们把状态和动作全部组合起来得到的一个序列称为轨迹(trajectory)。
智能体在与环境互动的过程中会得到奖励,奖励可以看成一个函数。奖励函数有不同的表示方法,在有的游戏里,智能体采取的动作可以决定奖励。但通常我们在决定奖励的时候,需要动作和预测。因此通常在定义奖励函数的时候,需要同时看动作和观测,奖励函数的输入是动作和观测。
我们需要最大化总奖励,因此将问题优化为学习网络的参数,让总奖励越大越好。可以通过梯度上升(gradient ascent)来最大化回报。
一个问题是,智能体的输出是有随机性的,同样的环境可能会产生不一样的输出。假设环境、智能体、奖励合起来可以当成一个网络,那么这个网络不是一般的网络,而是有随机性的。这个网络里的某一个层,每一次的输出都是不一样的。要是在下围棋问题里,对手的回应每次可能也是不一样的。由于环境和奖励的随机性,强化学习的优化问题不是一般的优化问题。
在生成对抗网络,判别器也是一个神经网络,但是在强化学习的优化问题里,奖励和环境不是网络,不能用一般的梯度下降的方法调整参数来得到最大的输出,这是强化学习和一般机器学习不一样的地方。
让一个智能体在看到某个特定观测的时候采取某个特定的动作,这可以看成一个分类。如果希望智能体采取动作a,可以定义损失L等于交叉熵e,如果希望智能体不要采取动作a,可以定义损失为-e。
下图是希望看到s时采取a,看到s'时不要采取a',则设置损失L=e1-e2,e1越小越好,e2越大越好,再找一个θ来最小化损失。
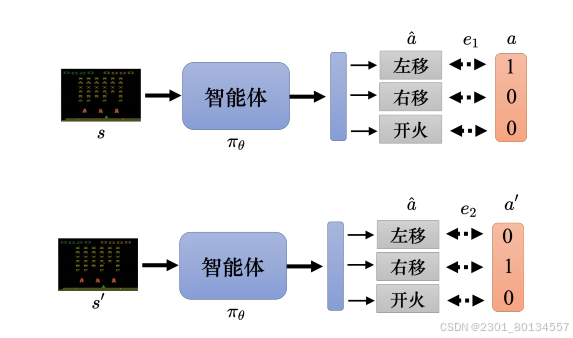
为了训练智能体,需要收集一组数据,即看到s1时采取a1,看到s2时采取a2,s可以看作图像,a看作标签。
如果每一个动作只有采取或不采取两种可能,则可以用+1和-1来表示,这就是一个二分类问题。但是每一个还有采取程度上的差别,每一个状态-动作对(state-action pair)对应一个分数Ai,可以通过Ai来控制每一个动作被采取的程度。

综上所述,强化学习可分为三个阶段,只是优化的步骤和一般的机器学习方法不同,强化学习使用了策略梯度(policy gradient)等优化方法,接下来的难点是如何定义Ai,我们先介绍最容易想到的4个版本。
14.3评价动作的标准Ai
评价的标准有很多,可以用即时奖励作为评价标准,也可以使用累计奖励作为评价标准,还可以使用折扣累计奖励作为评价标准,以及使用折扣累计奖励减去基线作为评价标准。
14.3.1使用即时奖励作为评价标准
智能体和环境互动使得我们可以收集一些训练数据(state-action pair)。智能体的动作都是随机的,我们将每一个动作都记录下来,接下来评价每一个动作的好坏,如果奖励是正的代表该动作是好的,如果奖励是负的代表该动作是不好的。奖励可以当成Ai
以上是版本0,它并不好,因为把奖励设为Ai,会让智能体短视,不再考虑长期利益。每一个动作并不是独立的,每一个动作都会影响接下来的发生的事情。
在和环境做互动的时候,有一个技巧叫做延迟奖励(delayed reward),即牺牲短期利益以换取更长期的利益。
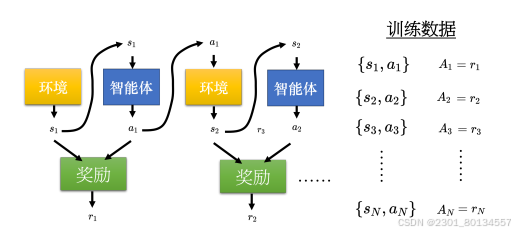
14.3.2使用累计奖励作为评价标准
现在是版本1,把未来所有的奖励加起来即可得到累计奖励G ,用以评估一个动作的好坏。
Gt是从时间点t开始,将rt一直加到rN的结果,即
但是版本1也有问题,智能体采取动作a1导致可以得到rN的可能性很低,接下来的版本2可以解决这个问题。
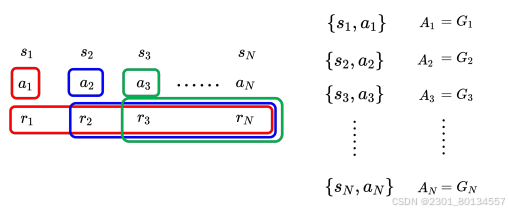
14.3.3使用折扣累计奖励作为评价标准
现在是版本2,用G'来表示累计奖励,G'的定义为,我们在r的前面乘以了一个折扣因子γ,折扣因子是一个小于1的值,比如0.9或0.99。
距离a1越远,乘以的γ次数越多,等累加到rN的时候,rN对G1'几乎没有影响,因为γ已经被乘以很多次了,已经很小了。
通过引入折扣因子,可以赋予距离a1较近的奖励比较大权重,距离a1较远的奖励较小的权重。
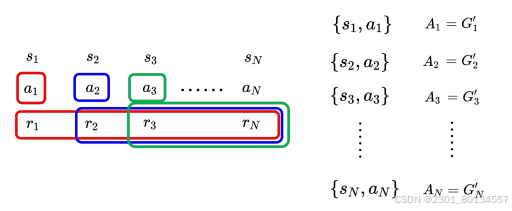
14.3.4使用折扣累计奖励减去基线作为评价标准
现在是版本3,用G'来表示评估标准会有一个问题,就是在有些动作虽然是正的,但其实是不好的,但我们仍然会鼓励采取这种动作,因此我们需要做一下标准化,最简单的方法就是把所有的G'都减去一个基线b,让G'有正有负,让特别高的G'是正的,而让特别低的G'是负的。

策略梯度算法中的评价标准就是G'-b,如下图

与一般的训练不同,强化学习中,收集数据实在训练迭代的过程中进行的。
下图表示训练过程,训练数据中有很多来自某个智能体的state-action pair,对于每个state-action pair可以使用评价Ai来判断动作的好坏。
通过训练数据训练智能体,使用评价Ai定义损失L并更新参数一次。
一旦更新完一次参数,就只有等重新收集完数据后才能更新下一次参数,这就是强化学习的训练过程非常花时间的原因。强化学习没更新完一次参数以后,数据就要重新收集一次,才能更新参数,如果数据要更新400次,数据就要收集400次,这个过程非常耗费时间。
在策略梯度算法中,每次更新完模型参数后,就需要重新收集数据。同一个动作,对于不同的智能体而言,好坏是不一样的。
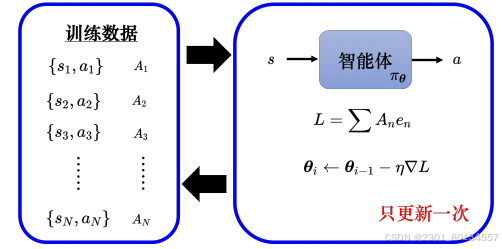
使用paiθ^i-1收集的数据用来评估paiθ^i接下来得到的奖励其实是不合适的。如果收集数据的智能体与要训练的智能体是同一个智能体,那么当智能体更新后,就得重新收集数据。异策略学习(off-policy learning)可以解决这个问题
这个训练数据集只是一个代表,后面的智能体面临的环境就是中间的环境,也可能出现跟前面的环境相同的环境,所以我们不仅要收集同一环境不同操作的奖励,还要收集跨环境动作的奖励。
根据老师的围棋例子自己总结一个例子:训练数据就是今天的我面对不同棋局可以采取的不同操作,既有同一种情况的不同操作,也有不同情况(跨环境)的不同操作,而训练就是下一盘棋,在一次训练中,我会从前面的知识库里选择应对今天的棋局,棋局结束也就意味着一次训练结束,而我在新的实践中也更新了我对下棋的理解也就是更新参数,所以面对下一次下棋时我必须更新一下我对每一种棋局要做的操作的储备,也就是更新训练数据。总结来说就是,今天的我比昨天的我更强自然要更新操作库。
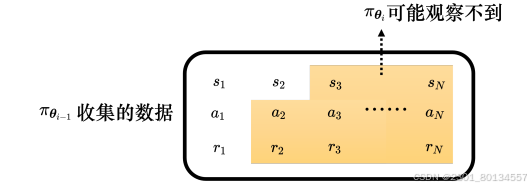
与异策略学习(off-policy learning)相反的是同策略学习(one-policy learning)是指要训练的智能体与和环境互动的智能体是同一个智能体,比如策略梯度算法就是同策略的学习算法。而在异策略学习中,和环境互动的智能体是两个智能体,要训练的智能体能够根据另一个智能体和环境互动的经验进行学习,因此异策略学习不需要一直收集数据。
同策略的学习每更新一次参数就要收集一次数据;异策略的学习收集一次数据,就可以更新参数很多次。
下棋的比喻:
同策略学习:你自己下棋:在同策略学习中,智能体(你)通过自己与环境(棋局)互动,不断学习和积累经验。随着棋艺的进步,你需要根据自己的新知识更新训练数据。这就像你每次下棋后,都要分析自己的决策和结果,以便不断改进。
异策略学习:智能体 B 的经验就像一本书:在异策略学习中,你可以利用其他智能体(如智能体 B)的经验,这些经验就像一本书,记录了各种下棋的方法和策略。即使你并没有亲自去下棋,也能从书中获得很多有用的信息,这样你就不需要频繁地更新自己的数据,而是可以直接从这本书中学习。
优势:高效学习:通过利用智能体 B 的经验,你可以更快速地获取知识,而不必每次都去尝试和修正。这种方式让你能在相对较短的时间内学到更多的棋法和策略。
探索(exploration),智能体在采取动作的时候是有一些随机性的。随机性非常重要,有些时候随机性不够就训练不起来。假设有一些动作从来没有被采取过,这些动作的好坏就是未知的。
在训练的过程中,与环境互动的智能体本身的随机性非常重要,只有随机性强一点,才能够收集到较多的数据。
为了增加随机性,我们会在训练的时候刻意加强智能体的随机性。比如智能体的输出是一个分布就加大该分布的熵,让其在训练的时候比较容易采样到概率比较小的动作。或者增加一些噪声,让他每次采取的动作都不一样。
14.3.5Actor-Critic
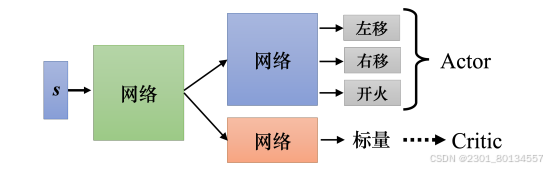
与环境交互的网络称为Actor(演员,策略网络),而Critic(评论员,价值网络)的作用就是判断一个智能体的好坏。
Critic有很多不同的变体,有的Critic只看游戏画面来判断;而有的Critic还要求Actor采取某个动作,在以上两者都具备的前提下,智能体才会得到奖励。
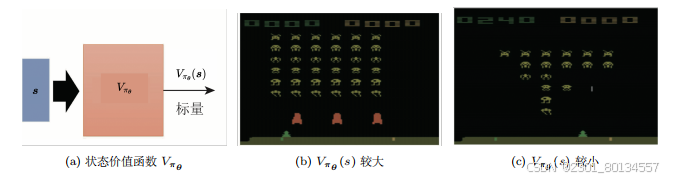
Critic又称为价值函数(value function),可以用Vpaiθ(s)来表示,Vpaiθ是一个函数,输入是s,输出是一个标量Vpaiθ(s)
paiθ代表观测V的Actor的策略为paiθ。
价值函数Vpaiθ(s)代表智能体paiθ看到观测后得到的折扣累计奖励(discounted cumulated reward)G'
价值函数与他所观察的智能体是有关系的,对于同样的观测,不同的智能体得到的折扣累计奖励应该不同。
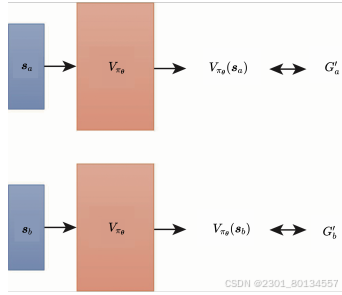
Critic有两种常用的训练方法:Monte-Carlo方法和时序差分法。
在游戏记录中,看到画面Sa,累计奖励为Ga'。如果使用Monte-Carlo法,输入Sa给价值函数Vpaiθ,其输出Vpaiθ(sa)和Ga'越接近越好;将Sb输入价值函数Vpaiθ,其输出Vpaiθ(sb)和Gb'越接近越好。
使用时序差分(Temporal-Difference,TD)法不用玩完整个游戏,只要看到数据{st,at,rt,st+1},就能够训练Vpaiθ(s),也就可以更新Vpaiθ(s)的参数。使用Monte-Carlo则需要玩完整个游戏。
在TD法中,Vpaiθ(st)和Vpaiθ(st+1)的关系如下图所示:
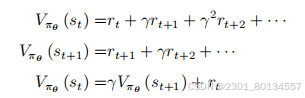
虽然Vpaiθ(st)和Vpaiθ(st+1)的值都是未知的,但是他们满足如下关系,左边与右边越接近越好
![]()
对于使用同样的paiθ得到的训练数据,Monte Carlo方法和用TD法计算出的价值可能是不一样的。MC 方法基于完整的回报而 TD 方法则依赖于逐步更新的即时奖励和未来估计
通过训练 Critic,无论是使用 Monte Carlo 还是时序差分方法,最终的目标都是学习一个准确的价值函数。这使得 Critic 能够有效预测给定状态(或状态-动作对)的预期奖励。然后,Actor 可以利用这些评估信息来调整其策略,以选择更有价值的动作。
如何用Critic训练Actor
现在是版本3.5。在学习出Vpaiθ后,给定一个状态si,产生分数Vpaiθ(si),基线b可设成Vpaiθ(si),因此Ai可设成Gi'-Vpaiθ(si).
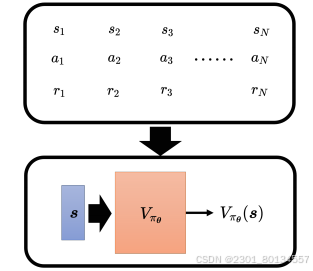

总结:At代表{st,at}的好坏,智能体在看到某个画面st后,会继续玩游戏,游戏有随机性,每次得到的奖励不太一样,Vpaiθ(st)是一个期望值。
此外,智能体在看到画面st以后不一定会输出动作at,因为智能体本身是随机性的,在训练过程中,同样的状态,智能体输出的动作不一定一模一样。这是一个概率问题,有的动作概率高,有的动作概率低。
那么在看到画面st后既然会有很多不同的动作,那么对应的累计奖励G也就是不一样的,把这些结果平均起来就是Vpaiθ(st)。
Gt'是看到画面st之后采取动作at得到的累计奖励,如果At大于零,代表累计奖励大于平均累计奖励值,代表动作at比随机采样的的动作要好。
但是用采样减去平均也不好,有的采样特别低有的采样特别高,我们希望用平均减去平均。
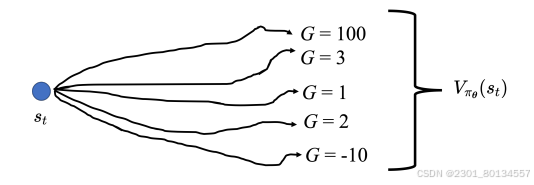
14.3.6优势Actor-Critic
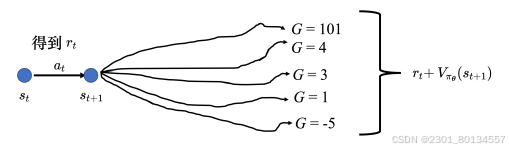
在画面st采取动作at会得到奖励rt,再跳到画面st+1,st+1对应的期望奖励为Vpaiθ(st+1),用rt+Vpaiθ(st+1)代表再st这边采取动作at会得到的奖励的期望值。
把Gt'换成rt+Vpaiθ(st+1)这个期望值,就是期望-期望。如果rt+Vpaiθ(st+1)>Vpaiθ(st)则代表at好于从一个分布中随便采样到的动作好。
不等式 rt+Vpaiθ(st+1)>Vpaiθ(st)的含义是,通过采取特定动作 at,我们可以获得高于当前策略在状态 st下随机选择动作的期望回报。
左侧的期望奖励是针对特定动作 ata_tat 的结果(即时奖励 + 未来期望奖励),而右侧是对当前状态 sts_tst 下的所有可能动作的期望回报。这意味着左侧是“确定性的”部分,因为它特定于某个动作,而右侧是“随机性的”,因为它是基于整个策略计算的平均结果。
我自己的解释:左侧就是根据画面st确定了要做at这个动作之后未来动作的平均奖励,右侧是只有画面st,初始动作也是随机的全是随机的未来动作的平均奖励。这样就可以看出at这个动作的价值了。
Actor和Critic有一个训练技巧,就是两者都需要输入游戏画面,他们的输入是一样的,所以这两个网络应该有部分参数可以共用。
当输入非常复杂时(比如游戏画面),前面的几层需要CNN,所以Actor和Critic可以共用前面几层。下图绿色网络就是共用层。
强化学习还可以直接用Critic决定要采取的动作,比如深度Q网络(Deep Q-Network),DQN有非常多的变体,有一篇知名论文把7中变体集中起来,因为集中起来,所以这种方法又称为彩虹法。
第十五章 元学习 (meta learning)
字面意思就是学习的学习,learn to learn。人们希望让机器自己去调整超参数,让机器自己去学习一个最优的模型和网络架构,然后得到好的结果。元学习就诞生了。
meta learning的本质:首先meta learning算法简化来看其实就是一个函数,我们用F来表示这个函数,F的输入就是训练数据它是一个数据集,F的输出是另外一个函数,我们用f表示。
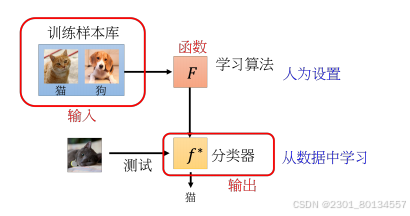
15.1元学习的三个步骤
(1)学习算法
在meta learning中,我们通常会考虑让机器自己学习网络架构、初始化的参数、学习率等。我们把这些在学习算法里想要机器自己学的东西统称为Φ,接下来我们将F添加一个下标Φ代表学习算法里有一些未知的参数。
当机器想办法去学习模型里不同的参数时也就有了不同的meta learning的方法。
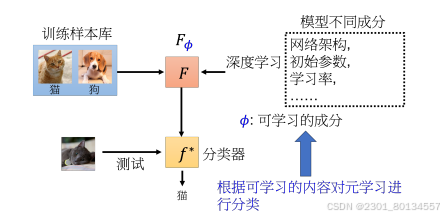
(2) 定义损失函数
设定一个损失函数,损失函数在meta learning里决定了学习算法的好坏。在机器学习中,损失函数来自训练数据,而在meta learning中我们收集的是训练任务,训练任务包含多个子任务,每个子任务中都有训练数据和测试数据。
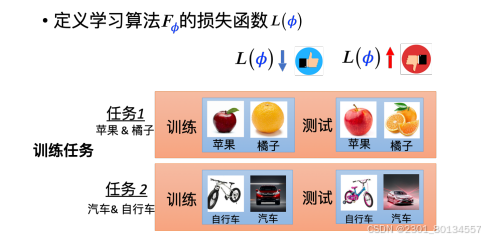
评价一个学习算法的好坏,看他在训练任务中使用训练数据学习到的算法的好坏。对于不好的学习算法(在测试数据上表现不好),我们就给他较大的损失 ,每个任务的损失设为li,如果有N个任务,则综合N个任务上的损失li为总损失L(Φ),这个损失就是meta learning的损失,它代表了这个学习算法在学习所有问题时的表现有多好。
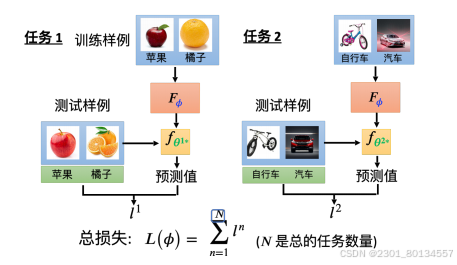
(3)找一个学习算法,即找到一个Φ,让损失越小越好
我们现在要找到一个Φ,使得L(Φ)最小,我们将这个Φ定义为Φ* 。解优化问题的方法很多,可以用梯度下降,如果无法计算梯度则可以用RL,或者用进化算法。总之找到一个FΦ*。
综上,首先收集一批训练数据,这些训练数据是由很多训练任务组成的,我们称其为训练任务,每一个任务都包含训练数据和测试数据。根据训练任务里的数据执行上述3个步骤,找到一个学习算法FΦ*。
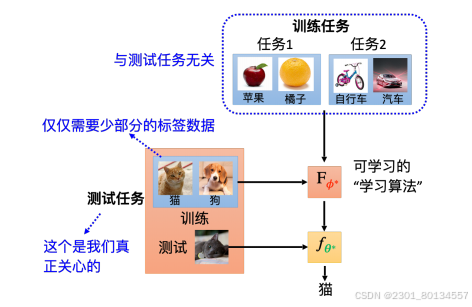
15.2meta learning与machine learning
机器学习的目标是找一个函数f,这个f可以是分类器这样的函数。而元学习的目标也是找一个函数,这个函数是学习算法F,F可以接收训练数据然后产生分类器f。
有些文献把任务里的训练数据叫做支持(support)数据,把测试数据叫做查询(query)数据。在元学习中,我们用查询数据训练,而在机器学习中我们用支持数据训练。
在元学习中,学习算法部分的学习又称为跨任务(Across-task)学习 ,因为我们要在不同的任务里不断学习。而对应机器学习中的学习则称为单一任务(within-task)学习,比如在生成f时,只用一个任务中的训练数据和测试数据。
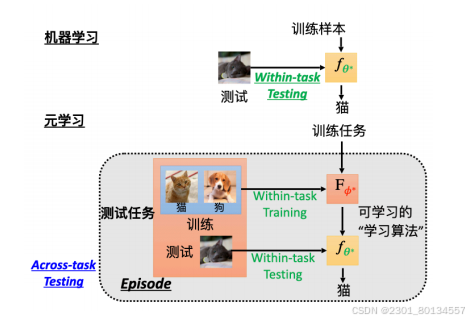
在meta learning中,我们要测试的不是一个分类表现得好坏,而是一个学习算法表现得好坏。
整个流程中一次within-task training和一次across-task training叫做一个回合,所以在meta learning中我们在一个回合里进行训练和测试,在机器学习中,在一个任务里进行训练和测试。
across-task traning 包含了很多within-task 的训练+测试,有些文献将across-task training叫做外循环,而把within-task training叫做内循环。
元学习中也有过拟合的问题,解决办法就是——收集更多的训练任务。
也就是说,训练任务越多,就代表训练的数据样本越多,学习算法就越有机会被泛化并用在新的任务上。
在元学习中我们也可以做数据增强,也就是想一些办法来增加训练任务。
可以对训练任务做一些变化,包括改变训练任务的类、数据、等等
元学习中也要做优化,这并非时没有意义的,因为只需要把学习算法的参数调整好,就可以一劳永逸地用在其他任务中,而不需要为每一个任务都去调整参数。这样我们可以节省很多时间,也可以让我们的学习算法更加高效。
机器学习中有验证样本,所以元学习中也应该有用于验证的任务,验证任务确定了学习算法时的一些超参数,然后才将其用在测试任务中。
15.3元学习的实例算法
在优化时最常用的学习算法是梯度下降法,梯度下降法就是随机初始化网络参数θ0,然后利用采样出来一个批次的数据进行训练,用梯度来更新参数θ0到θ1,不断反复知道更新到一个满意的参数θ*为止。
那么其实初始的参数θ0是可以训练的,一般的θ是随机初始化的,也就是从某个固定的分布里面采样出来的,同时θ0对结果也会有一定的影响,这种影响甚至是决定性的,因此我们可以通过一些训练任务,借用模型诊断元学习(Model-Agnostic Meta-Learning,MALL)算法来找到一个对训练特别有帮助的初始化参数。
MAML的基本思路:最大化模型对超参数的敏感性。
也就是说,学习到的超参数要让模型的损失函数因为样本的微小变化而有较大的优化。 因此模型的超参数设置应该可以让损失函数的变化速度最快,即损失函数此时有最大的梯度。
于是,损失函数被定义为每一个任务下损失函数的梯度和。
接下来就是根据这个损失函数做梯度下降。
在训练的过程中要求两次梯度,第一次是针对每个任务计算损失函数的梯度,进行梯度下降;第二次对梯度下降后的参数求和,再求梯度,进行梯度下降。
需要补充的是:虽然在MAML中,我们需要学习初始化参数的过程,但也有很多超参数需要我们自行决定。
Q:找一个好的初始化参数与自监督学习中预训练想要做的事情一样,那么MAML与自监督学习有什么不同呢?
A:目的一样,都是要找到好的初始化参数,但他们使用的方法不一样。自监督学习用一些数据做预训练,MAML用一些任务做预训练。
MAML的优势:第一个假设是找到的初始化参数是一个很厉害的初始化参数,它可以让梯度下降这种学习算法更快的找到每一个任务的参数。第二个假设是这个初始化参数本来就和每一个任务的理想结果非常接近,所以我们执行梯度下降次数很少就可以轻易找到好结果。在一篇论文中其证实了第二种假设。
MAML也有一些变体比如ANIL、First Order MAML、Reptile等
除了学习初始化参数外,MAML还可以学习优化器,如下图所示,在更新参数的时候,学习率和动量这种超参数需要自行设定,我们也想让其自动更新,参考论文“Learning to Learn by Gradient Descent by Gradient Descent”
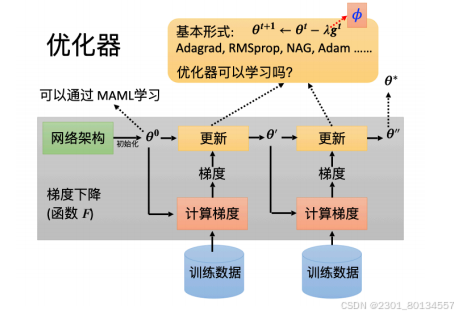
还可以训练网络架构,这部分的研究被称为神经架构搜索(Neural Architecture Search,NAS),如果我们在元学习中学习的是网络架构,并将网络架构当作Φ,那我们就是在做NAS。
但L(Φ)可能无法求微分,可以借助RL,把Φ想成一个智能体的参数,这个智能体输出的是NAS中相关的超参数,这个智能体每次都会输出一个与网络架构有关的参数。
除了网络架构可以学习,数据处理部分也有可能是可以学习的。我们在训练网络时有时要做数据增强,在元学习中,我们可以选择让机器自己做数据增强。
或者换个角度说,有时候需要给不同样本赋予不同的权重,具体操作有不同的策略,我们可以直接把采样策略训练出来,然后让他根据采样数据的特性自动决定权重应该如何设计。
learn to compare,又叫基于度量的方法,利用这种方法,网络直接把训练数据和测试数据都读进去,并直接输出测试数据的答案。
15.4 元学习的应用
我们最常拿来测试元学习技术的任务是少样本图像分类,在做这种少样本图像分类的时候会经常看到一个名词——N类K样例(N-way K-shot)分类,意思就是每一个人物只有N个类,而每一个类只有K个样例。常用的数据集是Omniglot


















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









