







目录

0.引入
函数模板
模板类型感悟:
template<class T>
void Swap(T& rx, T& ry) {
T tmp = rx;测试:
template<class T>
void Swap(T& rx, T& ry) {
T tmp = rx;
rx = ry;
ry = tmp;
}
int main(void)
{
int a = 0, b = 1;
double c = 1.1, d = 2.2;
char e = 'e', f = 'f';
Swap(a, b);
Swap(c, d);
Swap(e, f);
return 0;
}运行:

类模板
函数模板传的是类型,类模板传的是模板
类模板要实例化
template<class Container>
void Print(const Container& v)
{//传&可以进行修改,传的是模板类
// typename Container::const_iterator it = v.begin();
auto it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}为什么要考虑这样写 typename Container::const_iterator it = v.begin();
编译不确定Container::const_iterator是类型还是对象,typename就是明确告诉编译器这里是类型,等模板实例化再去找,因为静态的也可以这样写,存在混淆
测试:
int main()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
Print(v);
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
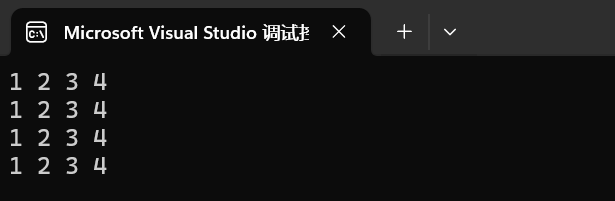
Print(lt);
return 0;
}
1. 非类型模板参数
模板参数分类类型形参与非类型形参。
类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
特点:还传了 size_t N
- 整型
- 常量
刚好也一般都是用来定义数组
template<class T, size_t N>
class Stack
{
public:
void func()
{
// 常量,不能修改
N = 0;
}
private:
T _a[N];
int _top;
};在实际场景中,运行结果如下:
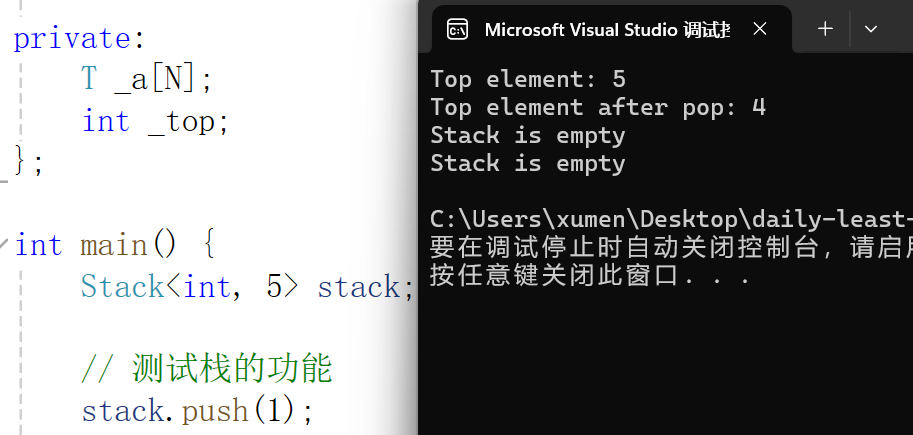
注意:
1. 浮点数、类对象以及字符串是不允许作为非类型模板参数的。
2. 非类型的模板参数必须在编译期就能确认结果。
运用 array

和数组有什么区别呢?
貌似没有...(C++11 更新出来的)
对越界检查非常的严格~
//C++11
//
// 鸡肋
//int a[10];
array<int, 10> a;
a[0] = 0;
for (auto e : a)
{
cout << e << " ";
}
//array对越界的检验非常严格,越界读写都能检查
// 普通数组,不能检查越界读,少部分越界写可以检查
//a[10];
//vector<int> v(10, 0);array 挺少用的,了解一下就好啦
因为话说这样写
v[10] vector检查不香吗?还可以初始化
2. 函数模板的特化
2.1 概念
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{
return left < right;
}
int main()
{
cout << Less(1, 2) << endl; // 可以比较,结果正确
Date d1(2022, 7, 7);
Date d2(2022, 7, 8);
cout << Less(d1, d2) << endl; // 可以比较,结果正确
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl; // 可以比较,结果错误
return 0;
}模板无法对指针进行比较,怎么办呢?--特化
函数模板的特化步骤:
- 必须要先有一个基础的函数模板
- 关键字template后面接一对空的尖括号<>
- 函数名后跟一对尖括号,尖括号中指定需要特化的类型
- 函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
//函数模板
template<class T>
bool Less(T left, T right)
{
return left < right;
}
//针对某些类型进行的特化 ---Date*
template<>
bool Less<Date*>(Date* left, Date* right)
{
return *left < *right;//比较解引用的值
}
2.2 类模板的特化
全特化
全特化即是将模板参数列表中所有的参数都是确定化。
template<class T1,class T2>
class Data
{
public:
Data()
{
cout << "Data<T1,T2>" << endl;
}
private:
T1 _d1;
T2 _d2;
};
//全特化
template<>
class Data<double, int>//参数匹配上了,就走这条
{
public:
Data()
{
cout << "Data<double,int>" << endl;
}
};
int main()
{
Data<int, int> d1;
Data<double, double> d2;
//特化
Data<double, int> d3;//直接走特化
return 0;
}
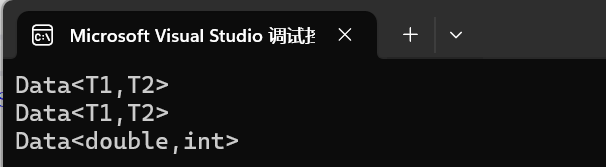
偏特化
偏特化:针对模板参数进一步进行条件限制设计的特化版本。
1.部分特化
将模板参数表中的一部分参数特化
template<class T1>
class Data<T1,char>
{
public:
Data()
{
cout << "Data<T,char>" << endl;
}
private:
T1 _d1;
};不管第一个参数是什么,只要第二个参数是我需要的特化,就去走那个特化。
2.参数进一步限制
偏特化并不仅仅是指特化部分参数,也有针对模板参数更进一步的条件限制所设计出来的一个特化版本。
//两个参数偏特化为指针类型
template<class T1, class T2>
class Data<T1*,T2*>
{
public:
Data()
{
cout << "Data<T1*,T2*>" << endl;
}
private:
T1 _d1;
T2 _d2;
};
//两个参数偏特化为指针类型
template<class T1, class T2>
class Data<T1&, T2&>
{
public:
Data()
{
cout << "Data<T1&,T2&>" << endl;
}
private:
T1 _d1;
T2 _d2;
};

3. 模板不可以分离编译
回顾类和对象
可见往期文章2.C++类和对象(上)
- 大型项目:类声明放在.h文件中,成员函数定义放在.cpp文件中,注意:成员函数名前需要加类名::

类的命名规则:
一般在成员变量前加_,来区分赋值,例如 _year= year,这样就区分开了
- 类的访问限定符及封装
访问限定符
用类将对象的属性与方法结合在一块,让对象更加完善,通过访问权限选择性的将其接口提供给外部的用户使用,以此来对程序进行保护,防止其被破坏
- public修饰的成员在类外可以直接被访问
- protected和private修饰的成员在类外不能直接被访问(此处protected和private是类似的)
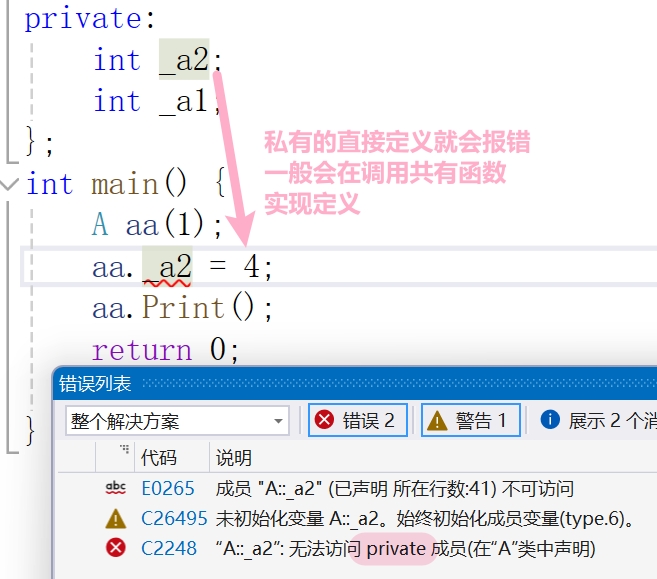
例如
#include <iostream>
using namespace std;
class Example {
private:
int privateVar;
void privateMethod() {
cout << "This is a private method." << endl;
}
public:
int publicVar;
void publicMethod() {
cout << "This is a public method." << endl;
}
// Public method to set the private variable
void setPrivateVar(int value) {
privateVar = value;
}
// Public method to get the private variable
int getPrivateVar() {
return privateVar;
}
};
int main() {
Example obj;
// Accessing public member variable
obj.publicVar = 10;
cout << "Public variable: " << obj.publicVar << endl;
// Accessing public member method
obj.publicMethod();
// Accessing private member variable through public method
obj.setPrivateVar(20);
cout << "Private variable (accessed through public method): " << obj.getPrivateVar() << endl;
// Error: Accessing private member variable directly
// obj.privateVar = 30; // Uncommenting this line will cause a compilation error
// Error: Accessing private member method directly
// obj.privateMethod(); // Uncommenting this line will cause a compilation error
return 0;
}解释
- 正确的调用:
-
obj.publicVar = 10;:设置公共变量的值。obj.publicMethod();:调用公共方法。obj.setPrivateVar(20);和obj.getPrivateVar():通过公共方法间接访问私有变量。
- 错误的调用:
-
obj.privateVar = 30;:直接访问私有变量会导致编译错误,因为privateVar是私有的。obj.privateMethod();:直接调用私有方法会导致编译错误,因为privateMethod是私有的。
3.1 什么是分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链 接起来形成单一的可执行文件的过程称为分离编译模式。
3.2 模板的分离编译
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:
template<class T>
T Add(const T& left, const T& right);
// a.cpp
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
// main.cpp
#include"a.h"
int main()
{
Add(1, 2);
Add(1.0, 2.0);
return 0;
}分析:

修改:
将声明和定义放到一个文件 "xxx.hpp" 里面或者xxx.h其实也是可以的。
#ifndef ADD_HPP
#define ADD_HPP
// 模板函数声明和定义
template<class T>
T Add(const T& left, const T& right) {
return left + right;
}
#endif // ADD_HPP4. 模板总结
【优点】
- 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
- 增强了代码的灵活性
【缺陷】
- 模板会导致代码膨胀问题,也会导致编译时间变长
- 出现模板编译错误时,错误信息非常凌乱,不易定位错误
代码膨胀
代码膨胀(Code Bloat)是指软件中的代码量过大,且可能包含许多冗余、重复或不必要的代码,从而导致程序变得庞大且效率低下。代码膨胀通常在以下几种情况下发生:
1. 模板和泛型编程:
- 在使用C++模板时,如果同一个模板被实例化为多个类型,那么编译器会为每个实例生成独立的代码。这会导致二进制文件的体积增加。例如,
std::vector<int>和std::vector<double>会生成两套不同的代码。
2. 宏和预处理器指令:
- 使用大量的宏定义和预处理器指令会生成许多重复的代码片段,增加了代码的体积和复杂性。
3. 过度使用设计模式:
- 一些设计模式(如工厂模式、单例模式等)如果过度使用或滥用,可能会引入许多额外的代码,增加了程序的复杂性。
4. 缺乏代码优化和重构:
- 在软件开发过程中,缺乏代码优化和重构可能会导致大量冗余代码的累积。例如,重复的函数、无效的变量声明和不必要的对象创建。
5. 库和框架的使用:
- 使用大型库或框架时,往往会引入许多不必要的功能和代码,导致程序体积膨胀。
代码膨胀的影响:
1.性能:
- 代码膨胀会导致程序的加载时间增加,运行速度变慢,内存占用增大,影响整体性能。
2.维护性:
- 过多的冗余代码使得代码的可读性和可维护性降低,增加了维护的难度和成本。
3.编译时间:
- 大量的代码会显著增加编译时间,影响开发效率。
代码膨胀的应对方法:
1.模板优化:
- 使用模板元编程技巧来减少不必要的模板实例化。
- 使用类型擦除(type erasure)技术来减少模板代码膨胀。
2.宏定义的合理使用:
- 尽量减少宏定义的使用,使用内联函数或常量表达式替代。
3.适度使用设计模式:
- 在适当的场景下使用设计模式,不滥用设计模式。
4.定期进行代码重构:
- 定期进行代码重构,删除冗余代码,优化代码结构,提高代码质量。
5.选择合适的库和框架:
- 使用轻量级的库和框架,根据需求选择合适的第三方工具,避免引入过多的无关功能。















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









