






一、函数调用栈的原理以及栈帧概念
1.栈帧的概念
栈帧,也就是stack frame,其本质就是一种栈,只是这种栈专门用 于保存函数调用过程中的各种信息(参数,返回地址,本地变量 等)。栈帧有栈顶和栈底之分,其中栈顶的地址最低,栈底的地址最高,SP(栈指针)就是一直指向栈顶的。在x86-32bit中,我们用 %ebp 指向栈底,也就是基址指针;用 %esp 指向栈顶,也就是栈指针。
一 般来说,我们将 %ebp 到 %esp 之间区域当做栈帧(也有人认为该从函数参数开始,不过这不影响分析)。并不是整个栈空间只有一个栈帧,每调用一个函数,就会生成一个新的栈帧。在函数调用过程中,我们将调用函数的函数称为“调用者(caller)”,将被调用的函数称为“被调用者(callee)”。在这个过程中,1)“调用者”需要知道在哪里获取“被调用者”返回的值;2)“被调用者”需要知道传入的参数在哪里,3)返回的地址在哪里。同时,我们需要保证在“被调用者”返回后,%ebp, %esp 等寄存器的值应该和调用前一致。因此,我们需要使用栈来保存这些数据。
2.函数调用栈的原理
函数调用栈是计算机中用于管理函数调用和返回的一种数据结构,它基于栈(Stack)的概念。在函数调用的过程中,计算机将函数调用的信息按照一定的规则存储在调用栈中。
当一个函数被调用时,计算机会将当前函数的执行状态(如局部变量、函数参数等)保存在栈中的一个称为"栈帧"(Stack Frame)的数据结构中。栈帧包含了函数的参数、局部变量、返回地址以及其他与函数执行相关的信息。
当 main() 函数调用 foo() 函数时,计算机会在调用栈中创建一个新的栈帧,用于保存 foo() 函数的执行状态。在 foo() 函数中调用 bar() 函数时,又会创建一个新的栈帧用于保存 bar() 函数的执行状态。
调用栈的特点是"后进先出"(Last-In-First-Out,LIFO)。也就是说,最后一个进入调用栈的函数会首先执行完毕并返回,然后才会执行前一个函数。当函数执行完毕后,相应的栈帧会从调用栈中移除,恢复到上一个函数的执行状态。
函数调用栈的原理如下:
当一个函数被调用时,当前函数的执行状态(函数参数、局部变量等)被保存在一个新的栈帧中。
新的栈帧被推入调用栈的顶部,成为当前活动栈帧。
被调用的函数开始执行。
如果被调用的函数又调用了其他函数,新的栈帧会被创建并推入调用栈的顶部。
当一个函数执行完毕后,它的栈帧会从调用栈中弹出,恢复到上一个函数的执行状态。
当所有函数执行完毕,调用栈为空。
函数调用栈的管理由编译器和操作系统共同完成。编译器会生成相应的代码来处理函数调用和返回的细节,而操作系统则负责在运行时管理调用栈的分配和释放。函数调用栈在程序执行过程中起到了重要的作用,它使得函数能够嵌套调用,并保证正确的执行顺序和状态管理。
二、ubuntu安装与环境配置
 1.先在官网下载镜像
1.先在官网下载镜像
2.打开vmware,新建虚拟机
3.安装过程同kali,这里不再过多赘述。
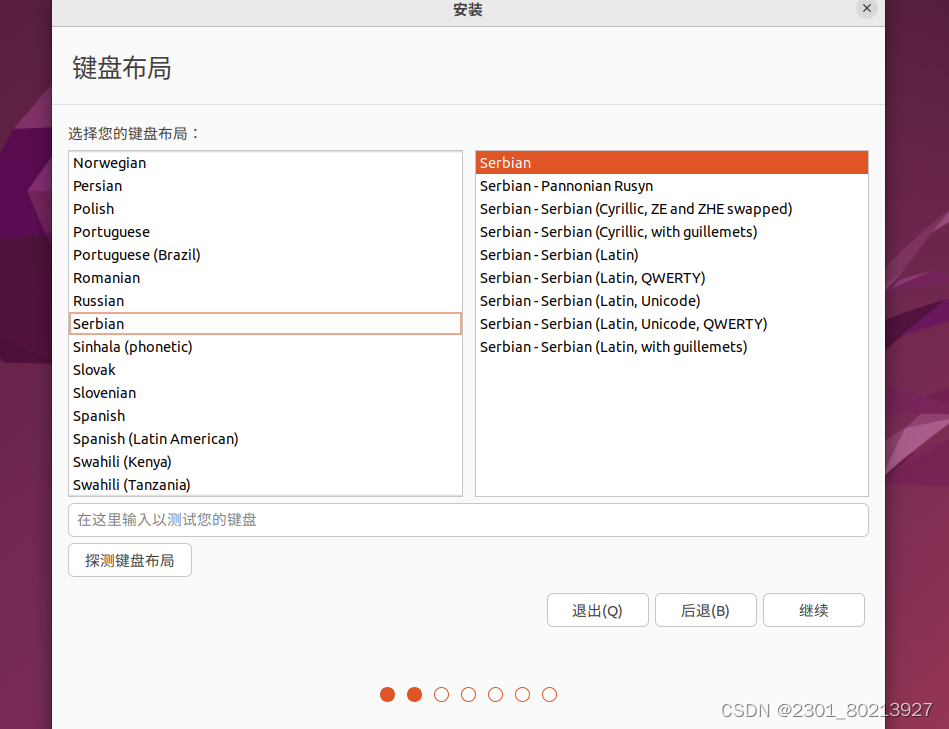 4.安装好以后,打开虚拟机,选择语言和键盘布局,然后前进,
4.安装好以后,打开虚拟机,选择语言和键盘布局,然后前进,
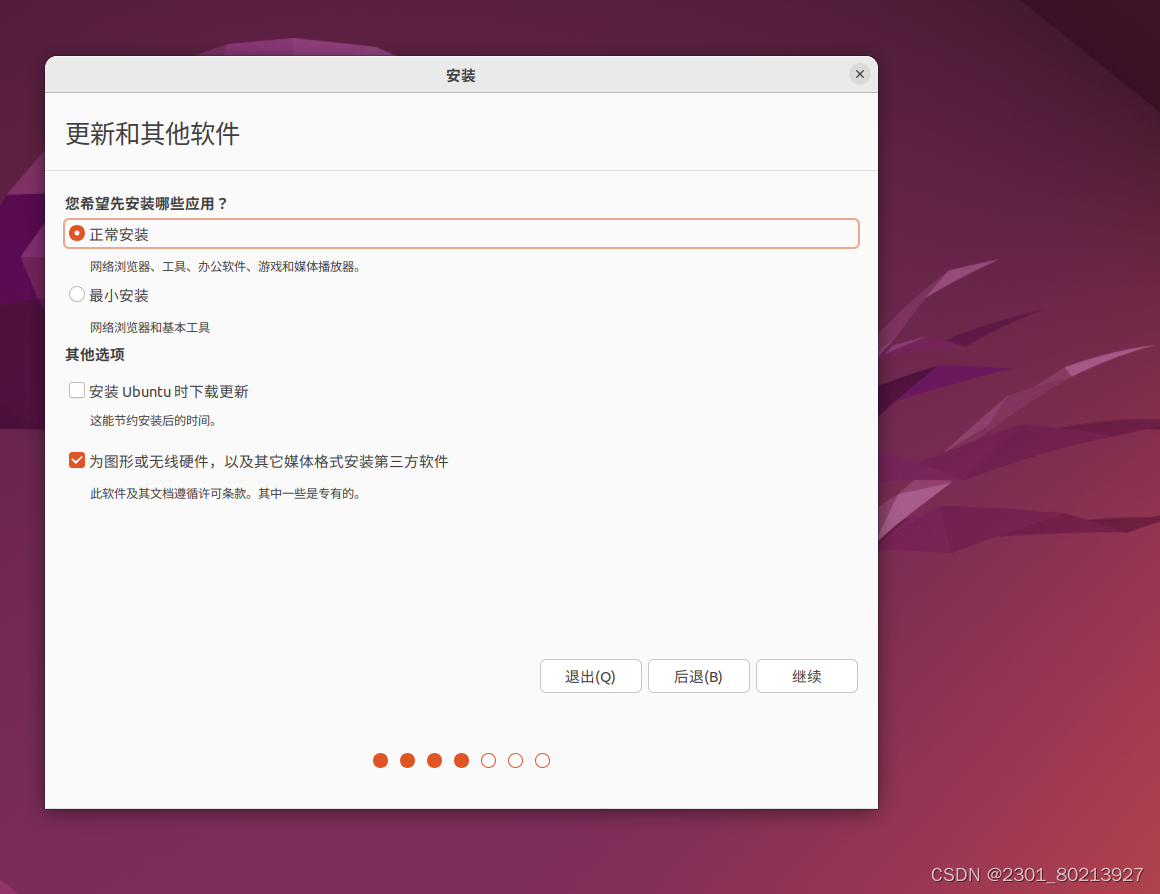 5.其他选项中将自动下载更新关了,然后选择下面那个,然后继续。
5.其他选项中将自动下载更新关了,然后选择下面那个,然后继续。
6.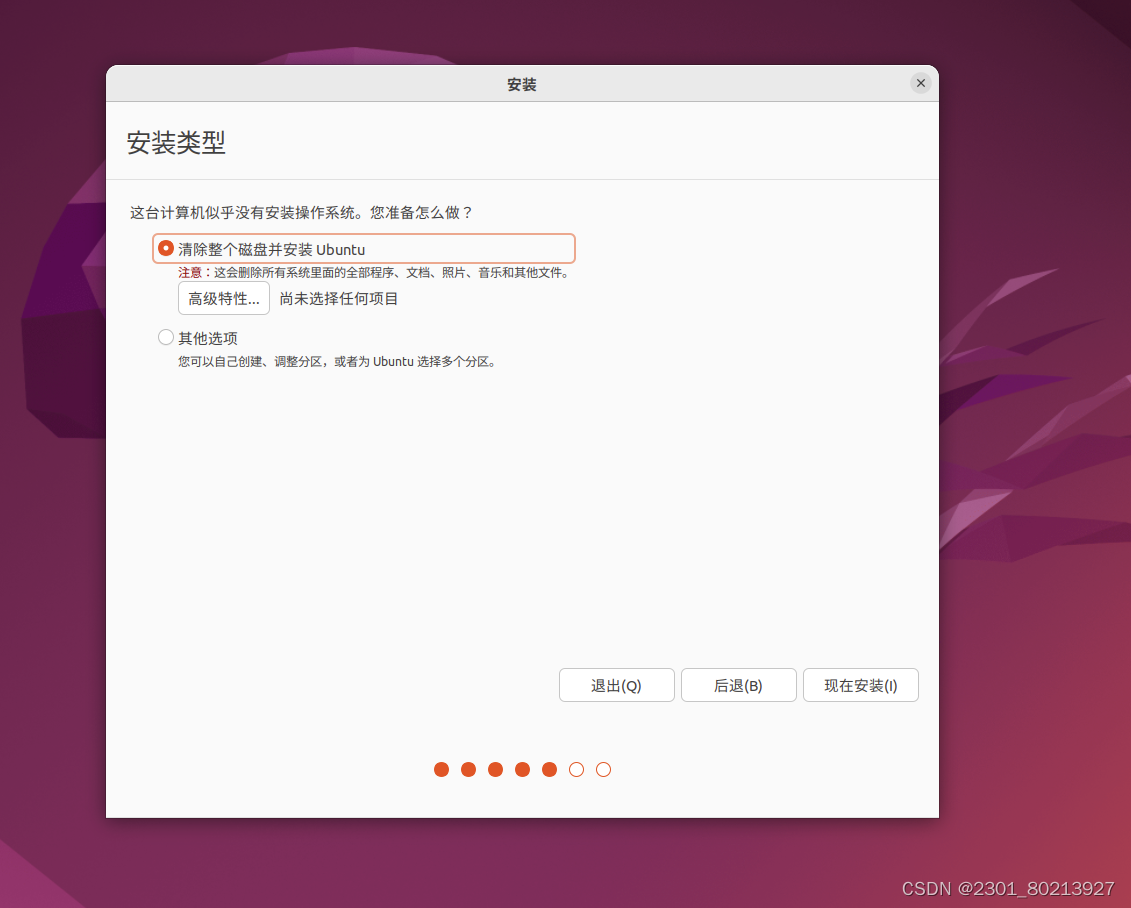 安装类型选择清楚整个磁盘并安装ubuntu
安装类型选择清楚整个磁盘并安装ubuntu
7. 时区选择上海
时区选择上海
8. 设置自己的用户名和密码
设置自己的用户名和密码
9.安装完成
10.虚拟机换源
作为国内用户首要任务安装完成之后首要任务就是更改ubuntu 22.04的镜像/软件源。指令直接一键配置就行
11.记得安装pwndbg
安装Pwndbg:
首先,确保你已经在系统上安装了GDB调试器。如果没有,请使用以下命令安装:sudo apt-get install gdb
然后,使用以下命令克隆Pwndbg的存储库:git clone https://github.com/pwndbg/pwndbg
进入pwndbg目录:cd pwndbg
运行安装脚本:./setup.sh
启动GDB调试器:
在终端中,进入你要调试的可执行文件所在的目录。
运行以下命令以启动GDB调试器:gdb <executable>
其中,<executable>是你要调试的可执行文件的路径。
加载Pwndbg插件:
在GDB命令行中,输入以下命令加载Pwndbg插件:source /path/to/pwndbg/gdbinit.py
在这里,将/path/to/pwndbg替换为你克隆Pwndbg存储库的路径。
开始调试:
一旦加载了Pwndbg插件,你可以使用许多Pwndbg的命令和功能来进行调试。
一些常用的Pwndbg命令包括:
pwndbg:显示Pwndbg的特定命令列表和功能。
context:显示当前寄存器、堆栈和内存的内容。
break:设置断点。
run:运行程序。
continue:继续执行程序。
next:执行下一条指令。
step:单步执行。
x:查看内存地址的内容。
disassemble:反汇编函数或代码块。
backtrace:显示函数调用栈。
三、栈溢出原理
(1)栈溢出介绍
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏洞,类似的还有堆溢出,bss 段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程。此外,我们也不难发现,发生栈溢出的基本前提是
程序必须向栈上写入数据。
写入的数据大小没有被良好地控制。















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









