







目录
requests模块介绍
简介:
Python requests 是一个常用的 HTTP 请求库,可以方便地向网站发送 HTTP 请求,并获取响应结果。 requests 模块比 urllib 模块更简洁。
方法常用参数 url :请求地址。发送请求方法的第一个参数均默认为 url data :设置请求体,格式默认为字典 params:设置查询参数字典 headers:设置请求体,格式为字典 timeout :设置秒数超时,仅对于连接有效
安装:
在Terminal模块中输入: pip install requests 如果安装速度慢的话可以改⽤国内的源进⾏下载安装. pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests

【提示语句1】 [notice] A new release of pip is available: 23.0.1 -> 23.1.2 翻译:注意pip的新版本可用:23.0.1 -> 23.1.2。 【提示语句2】 [notice] To update, run: python.exe -m pip install --upgrade pip 翻译:[注意]要进行更新,请运行:python.exe-m pip安装-升级pip。 【解决办法】 在【cmd.exe】中输入如下命令更新pip库。 python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ --upgrade pip pip更新完毕后,在输入一次pip3 install requests就能完成安装。
requests.get功能的使用
简介:
requests.get(url)方法就是构造一个向服务器请求资源的Request对象,这个对象是Request库内部生成的。需要注意的是,Python语言对大小写敏感的,Request对象的R是大写的。 而返回的内容,则是Response,这个Response对象返回包含了整个服务器的资源。

使用:
案例:搜索搜狗数据
代码演示:
import requests
#爬百度信息
url = "http://www.baidu.com"
#发送请求
resp = requests.get(url)
#拿到页面源代码
print(resp.text)结果:
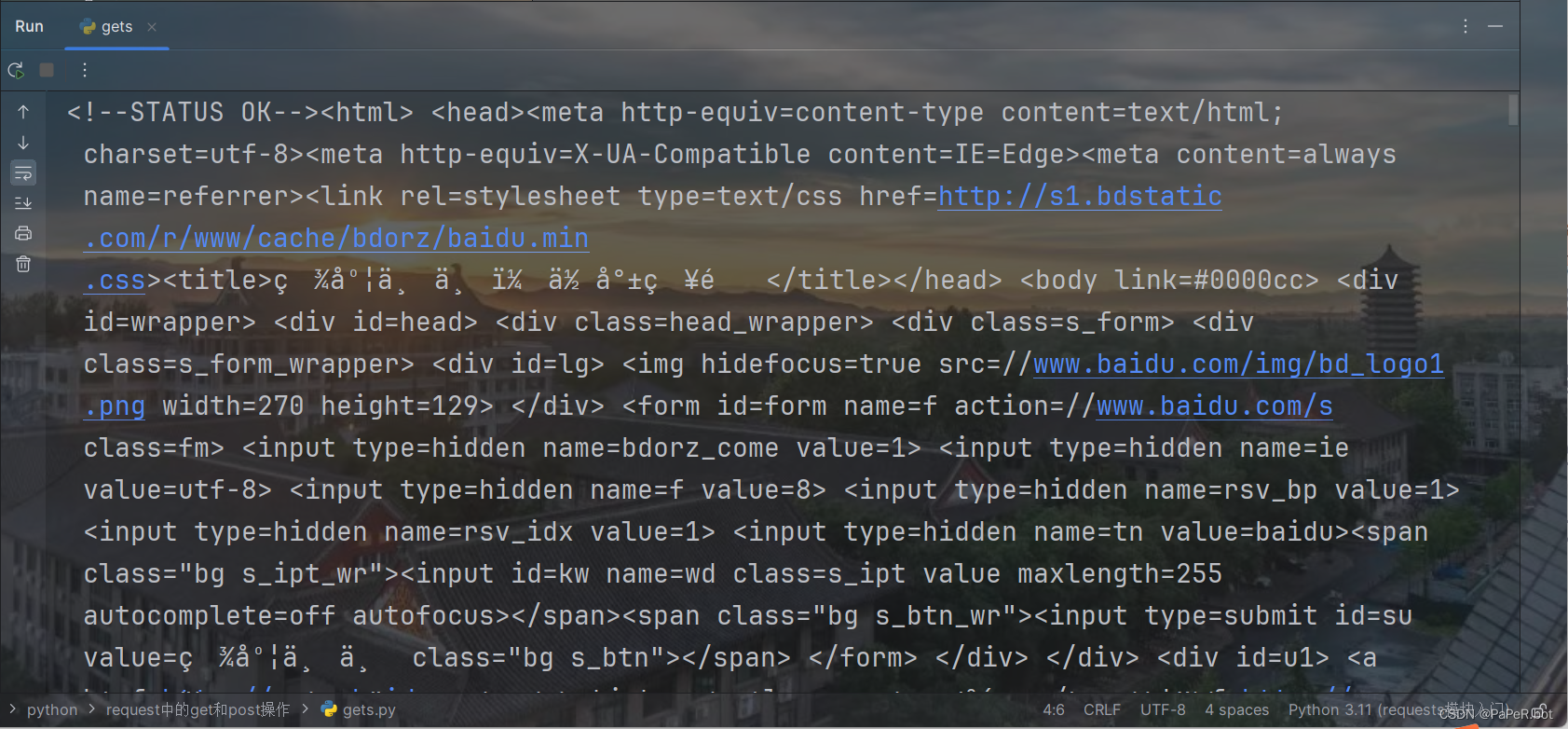
这里可以发现,执行run操作后,可以发现爬取的数据都是一堆看不懂的代码,这是由于字符集没有设置的原因,只需要将字符集设置成对应的格式,就能成功显示爬取的页面源代码
代码演示:
import requests
#爬百度信息
url = "http://www.baidu.com"
#发送请求
resp = requests.get(url)
#设置字符集
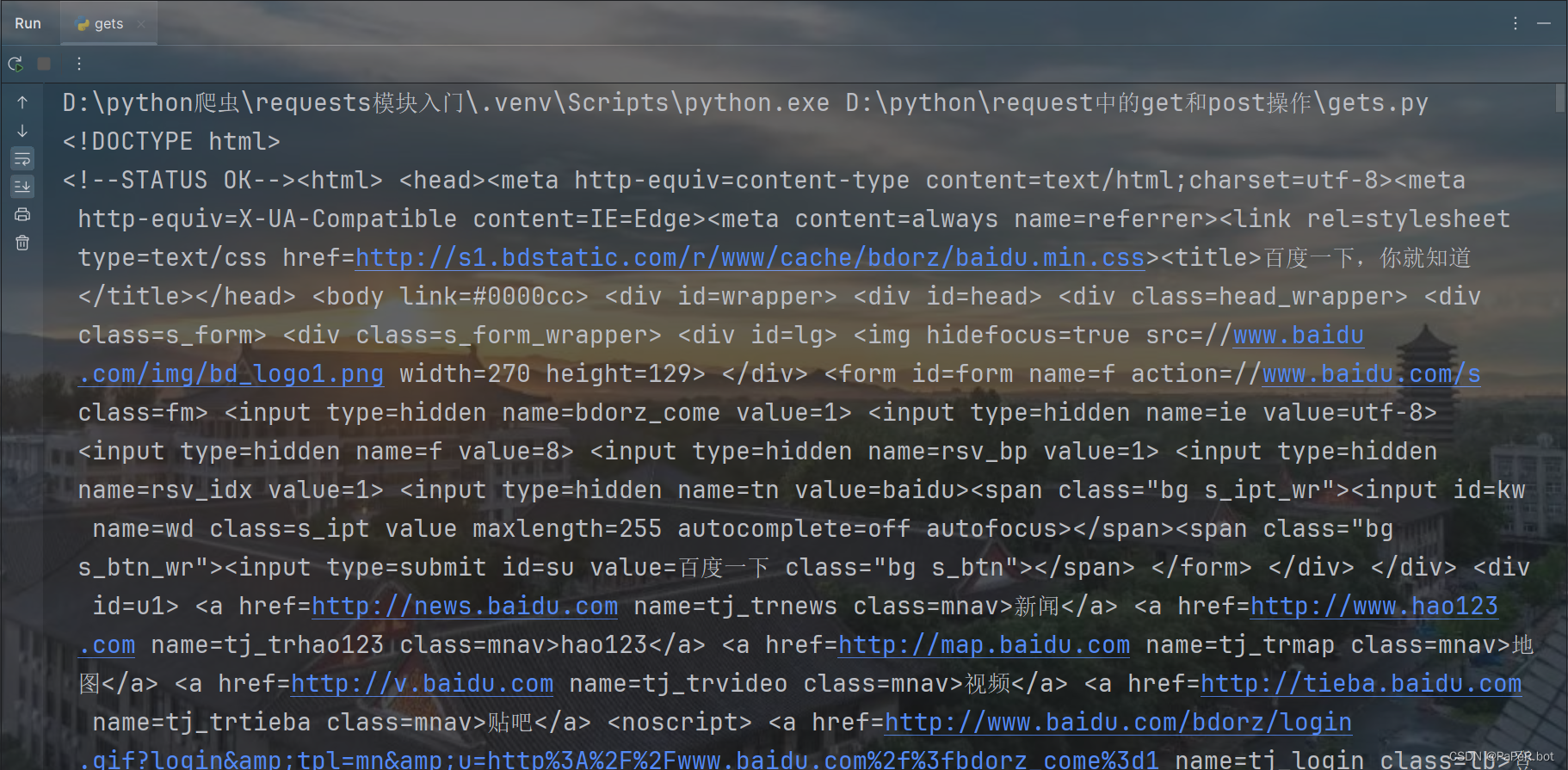
resp.encoding = 'utf-8'
#拿到页面源代码
print(resp.text)结果:
requests.post功能的使用
简介:
post和get一样,也能实现向服务器发送网络请求。 requests.post()是一个HTTP的POST请求方法,用于向指定的URL发送POST请求。 【语法】 requests.post(url, data=None, json=None, headers=None, cookies=None, auth=None, timeout=None) 【参数说明】 url:请求的URL地址。 data:请求的数据,可以是字典、元组列表、文件对象等。 json:请求的JSON数据。 headers:请求头,可以是字典类型。 cookies:请求的cookies,可以是字典类型。 auth:认证信息,可以是元组类型。 timeout:请求超时时间,单位为秒。
使用:
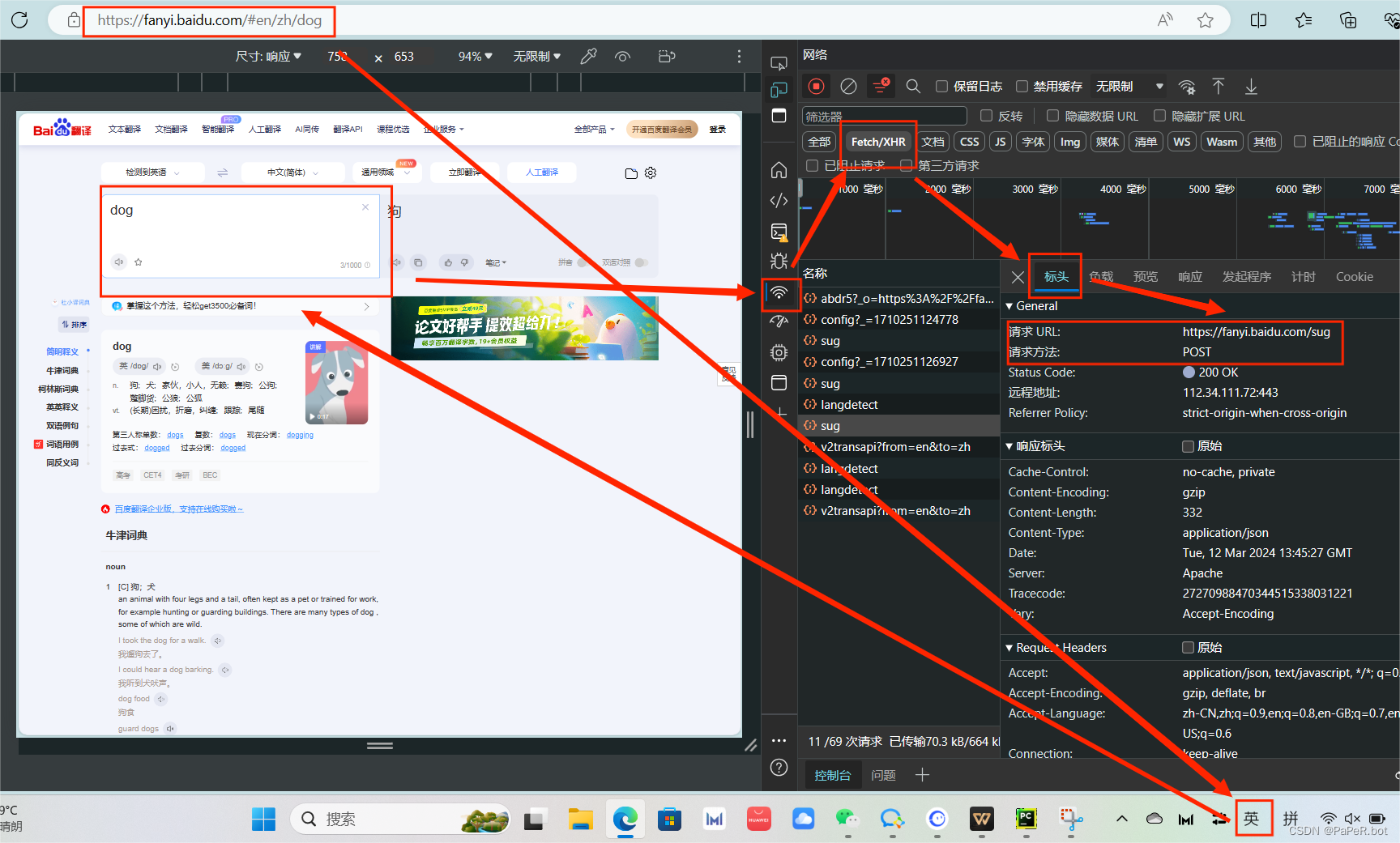
案例:抓取百度翻译数据(Fn+F12)

代码演示:
# 准备参数
dic = {
"kw": "dog" # 这⾥要和抓包⼯具⾥的参数⼀致.
}
# 请注意百度翻译的sug这个url. 它是通过post⽅式进⾏提交的. 所以我们也要模拟post请求
resp = requests.post("https://fanyi.baidu.com/sug",data=dic)
# 返回值是json 那就可以直接解析成json
print(resp.json())
结果:

Plus版本(字典翻译器)
代码演示:
import requests
# 准备参数
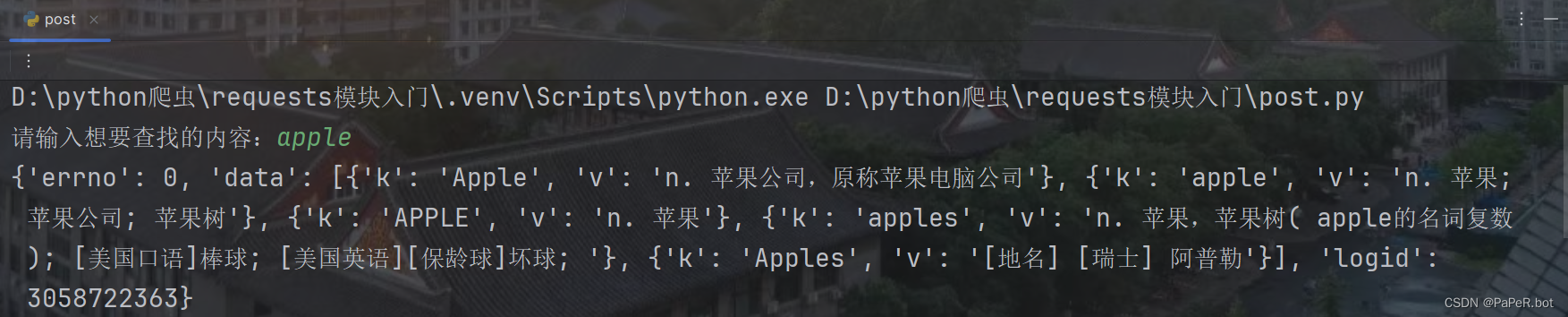
d = input("请输入想要查找的内容:")
dic = {
"kw": d# 这⾥要和抓包⼯具⾥的参数⼀致.
}
# 请注意百度翻译的sug这个url. 它是通过post⽅式进⾏提交的. 所以我们也要模拟post请求
resp = requests.post("https://fanyi.baidu.com/sug",data = dic)
print(resp.json())
# 返回值是json 那就可以直接解析成json结果:
User-Agent的介绍
简介:
User-Agent中文名为用户代理,简称 UA,是Http协议中的一部分,属于头域的组成部分,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。在网络请求当中,User-Agent 是标明身份的一种标识,通过这个标识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计;例如用手机访问谷歌和电脑访问是不一样的,这些是谷歌根据访问者的UA来判断的。UA可以进行伪装。
使用:
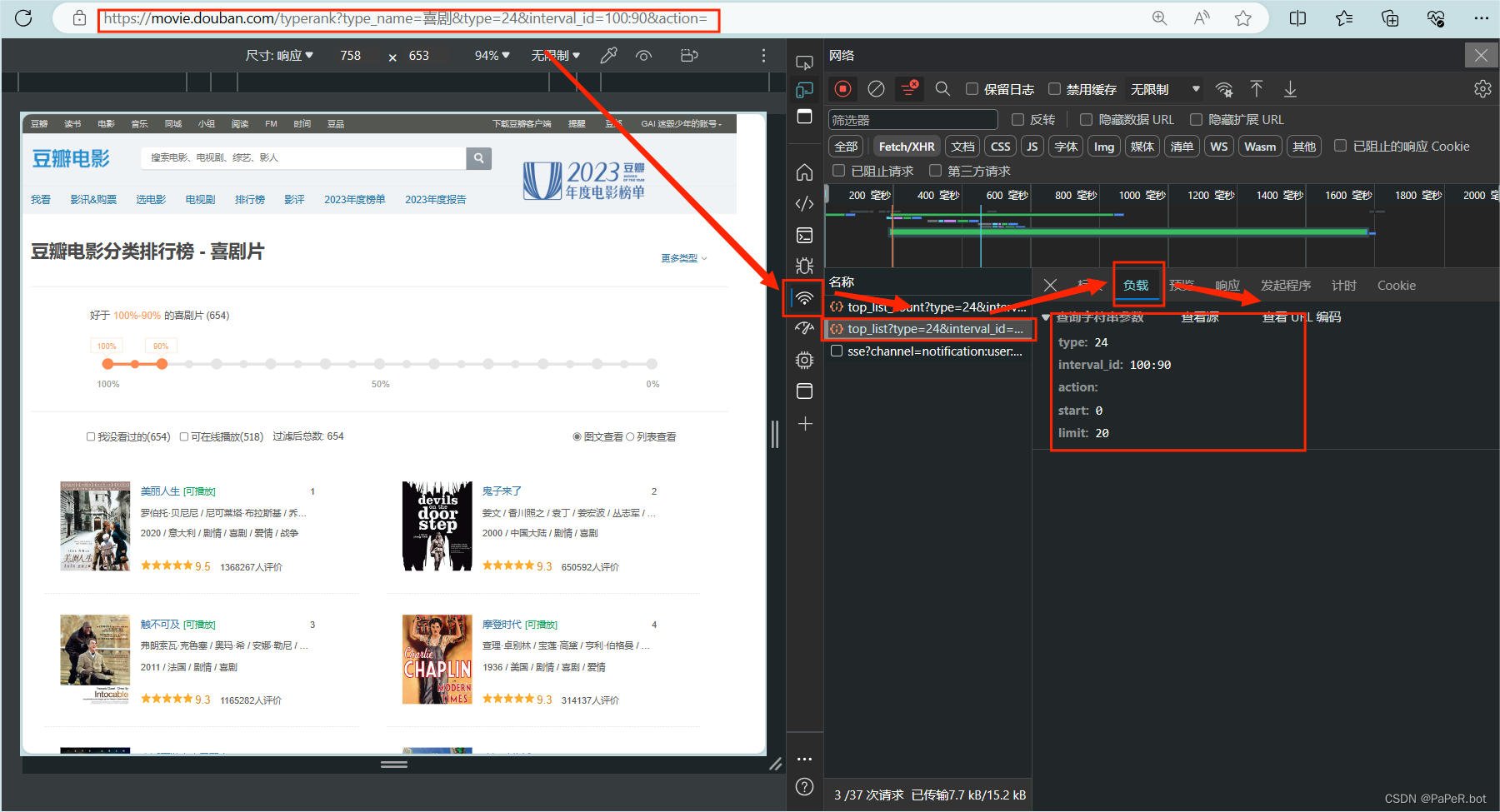
案例:抓取豆瓣戏剧电影排行榜
代码演示:
import requests
url = 'https://movie.douban.com/j/chart/top_list'
param = {
'type': '24',
'interval_id': '100:90',
'action':'',
'start': '0',#从库中的第⼏部电影去取
'limit': "20"#⼀次取出的个数
}
resp = requests.get(url,params = param)
print(resp.text)结果:

这里可以发现,格式符合标准却没有结果输出,这里可能是由于浏览器的反爬虫机制,只需要将headers设置成电脑系统格式,就可以解决这个反爬虫
代码演示:
import requests
url = 'https://movie.douban.com/j/chart/top_list'
param = {
'type': '24',
'interval_id': '100:90',
'action':'',
'start': '0',#从库中的第⼏部电影去取
'limit': "20"#⼀次取出的个数
}
head = {
'User-Agent':
'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 '
'Mobile Safari/537.36 Edg/122.0.0.0'
}
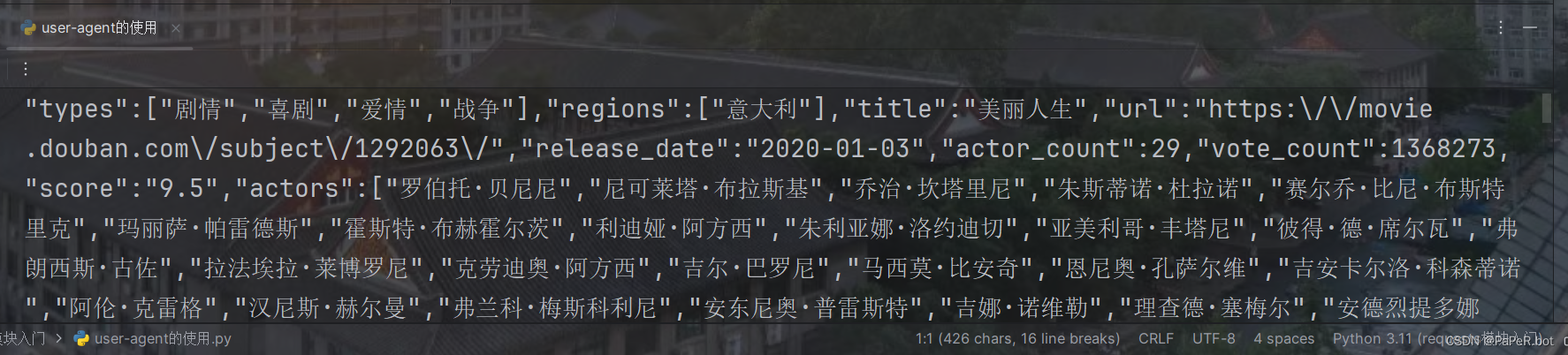
resp = requests.get(url,params = param,headers=head)
print(resp.text)结果:















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









