






一、生成快捷键
生成按钮下的快捷键一览
1、从提示词或上次生成的图片中读取生成参数
条件:提示词输入框空的时候,才起作用
2、从提示词或上次生成的图片中读取生成参数(弹出框输入)
不知道它和直接在输入框输入的差别
3、清空提示词内容
4、显示和隐藏扩展模型
包含的模型:嵌入式、Hypernetworks、模型、Lora
5、将所选预选样式插入到当前提示词之后
条件:先执行6
作用:将7的当前选择项的提示词填入
6、将当前提示词存储为预设样式
过程:保存提示词到7(自定义一个简称到这段提示词)
7、预设样式列表选择
二、迭代步数(采样步数)
参考文档:https://getimg.ai/guides/interactive-guide-to-stable-diffusion-steps-parameter
首先,stable diffusion的相关原理。可以把模型理解为一个迭代过程——从文本输入生成随机噪声开始的重复循环,每一步都会消除一些噪声,并随着迭代步数的增加会产生更高质量的图像。而当完成所需的步骤数量时,重复就会停止。
一般来说,大约25个采样步骤(20个也可以)通常足以获得高质量图像,使用更多的步骤可能会产生略有不同的图片,但不一定有更好的质量。此外,当使用的步骤越多,生成图像所需的时间就越多。不过在大多数情况下,额外的等待时间是不值得的。
例如,一个“太空中的小狗”的展示,迭代步数从1-100,gif图片较大可能需要一定的等待时间),迭代步数4-7时,狗从斑点中出现。然后在生成大约20-25个步骤后,它就达到了较高质量。超过25个步骤后不会造成质量的显著差异:狗的形状反复变化,但没有产生更多细节。
三、不同采样方法的区别
采样方法一览

为了生成图像,首先,在潜在空间中生成完全随机的图像,然后噪声预测器估计图像的噪声,再从图像中减去预测的噪声。这个过程重复十几次,最后便会得到一个干净的图像。
这个去噪过程称为采样,因为稳定扩散在每个步骤中都会生成一个新的样本图像。抽样所采用的方法称为抽样器或抽样方法。
1、采样方式介绍:
从目前这些采样方法来看,主要分为几个类型:Euler、LMS、Heun、DPM、DDIM、PLMS、UniPC,下面我们来详细解释一下:
参考文档:https://stable-diffusion-art.com/samplers/https://www.reddit.com/r/StableDiffusion/comments/zgu6wd/comment/izkhkxc/?utm_source=share&utm_medium=web2x&context=3
Euler:是最简单的采样器。它在数学上与求解常微分方程的欧拉方法相同。它是完全确定性的,这意味着采样期间不会添加随机噪声。它的一般步骤为:
步骤1:噪声预测器根据潜在图像估计噪声图像。
步骤2:根据噪声表计算需要减去的噪声量。这就是当前步骤和下一步之间的噪声差异。
步骤3:将潜像减去归一化噪声图像(来自步骤1)乘以要减少的噪声量(来自步骤2)。
重复步骤1至3,直到噪声计划结束。
LMS:与欧拉方法非常相似,线性多步法(LMS)是求解常微分方程的标准方法。它的目的是通过巧妙地使用先前时间步骤的值来提高准确性。
Heun:是对Euler方法更精确的改进。但它每一步需要预测噪声两次,因此比欧拉慢两倍。
DPM:DPM(扩散概率模型求解器)和DPM++(对DPM的改进)是为2022年发布的扩散模型设计的新采样器,它们代表了一系列具有相似架构的求解器。DPM自适应可能会很慢,因为它不能保证在采样步骤数内完成。
DPM2:DPM和DPM2类似,只不过DPM2的DPM-Solver-2算法,求解器精确到二阶。(更准确但速度更慢,文献:https://arxiv.org/abs/2206.00927)。
DDIM和PLMS:DDIM(去噪扩散隐式模型)和PLMS(伪线性多步方法)是原始稳定扩散v1附带的采样器。DDIM是最早为扩散模型设计的采样器之一。PLMS是DDIM更新、更快的替代方案。它们通常被认为已经过时并且不再广泛使用。
UniPC(Unified Predictor Corrector方法)是2023年新开发的扩散采样器,由两部分组成:统一预测器(UniP)、统一校正器(UniC)它支持任何求解器和噪声预测器。
2、采样方式后缀的意思:
a:比如Euler和Euler a,这个加上的a值的是ancestral samplers(也有人称之为祖先采样器)。Ancestral samplers在每个采样步骤向图像添加噪声,并且作为随机采样器,使得采样结果具有一定的随机性。
Karras:指使用Karras噪声表。一般来讲,噪声预测器会根据潜在图像估计噪声图像,并根据噪声表计算需要减去的噪声量。第一步的噪音最大,然后噪音逐渐减小,并在最后一步降至零。(改变采样步数会改变噪声表,并使得噪音时间表变得更加平滑。采样步数越多,任何两个步之间的噪声降低越小。这有助于减少错误。)
下面这张图展示了原版噪声表(stable diffusion就是一个消去噪声,让图片更明晰的过程):
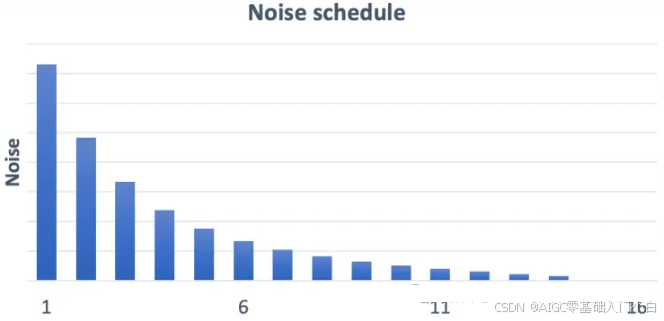
常规噪声表图(来源:https://stable-diffusion-art.com/samplers/)
至于Karras噪声表,则是一个比原版更好的去噪方式。需要注意的是带有“Karras”标签的采样器并不是由Karras制作的,而是使用了来自Karras论文的程序和灵感(https://arxiv.org/abs/2206.00364)。如果仔细观察,你会发现噪声的步长在接近末尾时更小,他们发现这提高了图像质量。以下是默认噪声表和Karras噪声表之间的比较:
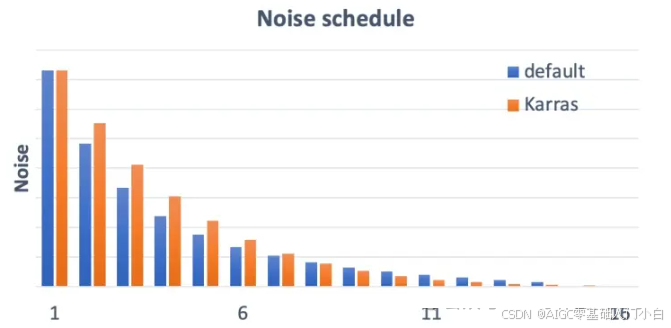
默认噪声表和Karras噪声表之间的比较图(来源:https://stable-diffusion-art.com/samplers/)
DPMFast:是具有统一噪声表的DPM求解器的变体,因此它的速度是DPM2的两倍。(参见:https://arxiv.org/abs/2206.00927)
DPMAdaptive:是具有自适应噪声调度的一阶DPM求解器。它会忽略你设置的步数并自适应地确定自己的步数。(参见:https://arxiv.org/abs/2206.00927)
其他:它们的后缀名称都与其算法相关,如DPM++2M【DPM-Solver++(2M)】;DPM++SDE【DPM-Solver++(stochastic)】;DPM++2S【a-Ancestral sampling with DPM-Solver++(2S) second-order steps】。
3、采样方式比较:
从速度上来看:
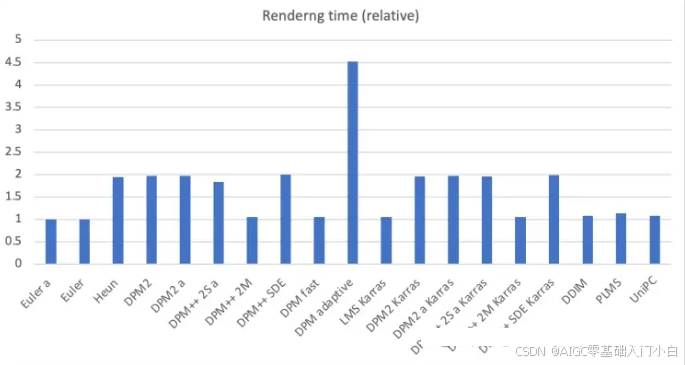
每种方法的相对渲染时间图(以euler a为基)(来源:https://stable-diffusion-art.com/samplers/)
上面这张图可见DPM自适应最慢,而其他的渲染时间可以分为两组,第一组花费大约相同的时间(约1倍),另一组花费大约两倍的时间(约2倍)。这反映了求解器的顺序。二阶求解器虽然更准确,但需要对去噪U-Net进行两次评估。所以它们的速度慢两倍。
从质量上看:
这里运用BRISQUE方法测量的感知质量,具体方法见这个文章:https://learnopencv.com/image-quality-assessment-brisque/(数值越低越好)
图片来源于:https://stable-diffusion-art.com/samplers/

一个有关所有采样器的简单对照(来源:https://stable-diffusion-art.com/samplers/)
4、总结与建议
按收敛行为来分类(选择收敛=选择稳定、可重复的图像):
不收敛:Euler_a、DPM2a、DPMFast、DDIM、PLMS、DPMAdaptive、DPM2aKarras
收敛:Euler、LMS、Heun、DPM2、DPM++2M、LMSKarras、DPM2Karras、DPM++2MKarras
按所需步骤时间:
Euler_a=Euler=DPM++2M=LMSKarras(图像在高步长时退化)>
LMS=DPM++2MKarras=Heun(较慢)=DPM++2S a(较慢)=DPM++2S a Karras>
DDIM=PLMS=DPM2(较慢)=DPM2 Karras>
DPM快速=DPM2a(较慢)
使用快速且质量不错的东西,选择DPM++2M Karras,UniPC
高质量的图像并且不关心收敛,选择DPM++SDE Karras
稳定、可重复的图像,请避免使用任何ancestral samplers(加a的东西)。
简单的东西,选择Euler和或Heun。
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









