






一、题目解析
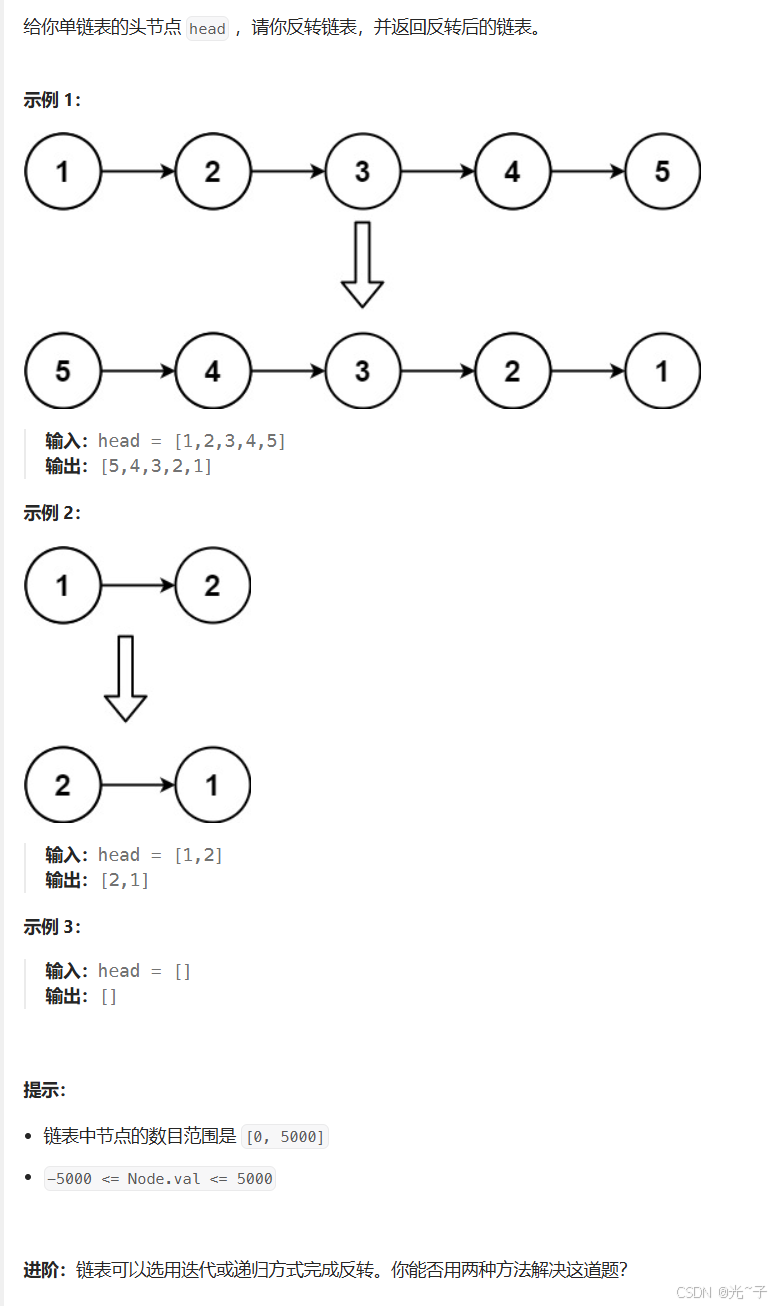
二、算法
1.正常解析--算法1(三指针)
翻转即将所有节点的next指针指向前驱节点。
由于是单链表,我们在迭代时不能直接找到前驱节点,所以我们需要一个额外的指针保存前驱节点。同时在改变当前节点的next指针前,不要忘记保存它的后继节点。
空间复杂度分析:遍历时只有3个额外变量,所以额外的空间复杂度是 O(1)
时间复杂度分析:只遍历一次链表,时间复杂度是 O(n)
代码如下(C++示例):
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode *prev = nullptr;
ListNode *cur = head;
while (cur)
{
ListNode *next = cur->next;
cur->next = prev;
prev = cur, cur = next;
}
return prev;
}
};
2.递归解析--算法2
代码如下(C++示例):
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if (!head || !head->next) return head;
ListNode *tail = reverseList(head->next);
head->next->next = head;
head->next = nullptr;
return tail;
}
};
示例解释:
假设我们有一个简单的链表:1 -> 2 -> 3。
-
第一次递归调用:
- 最初
head指向节点1,进入函数后,因为不满足基础情况(有next节点),会进行递归调用reverseList(head->next),此时head变为指向节点2,再次进入函数,同样继续递归,直到head指向节点3,此时满足了终止条件(因为3的next是nullptr),直接返回节点3给上一层递归调用。
- 最初
-
第一次反转操作:
- 当从最底层的递归返回后(此时处于
head指向节点2的那一层递归),拿到了返回的节点3(也就是tail),然后执行head->next->next = head;,也就是让3的next指向了2,接着head->next = nullptr;断开2原本指向3的连接,此时链表变成了1 -> 2 <- 3(局部反转好了以2开头的部分链表),然后返回节点3给再上一层递归(也就是head指向节点1的那层)。
- 当从最底层的递归返回后(此时处于
-
第二次反转操作:
- 回到
head指向节点1的那层递归后,再次执行head->next->next = head;,就会让2的next指向1,然后head->next = nullptr;断开1原本指向2的连接,此时整个链表就完全反转成了3 -> 2 -> 1,最后返回节点3作为反转后链表的头节点。
- 回到
所以通过这样的递归方式,就可以巧妙地将链表反转过来,每一层递归都处理好一部分链表的反转,最终完成整个链表的反转操作。
3.迭代解析--算法3
以下是使用迭代法反转链表的详细步骤:
1. 定义相关指针
首先,需要定义至少三个指针来辅助完成链表的反转操作,通常定义为 prev(指向已反转部分链表的尾节点,初始时为 nullptr)、curr(指向当前正在处理的节点,初始时指向链表的头节点)以及 next(指向当前节点 curr 的下一个节点,用于保存后续节点的位置,方便链表的遍历)。
例如,有链表 1 -> 2 -> 3 -> 4,最开始,prev 初始化为 nullptr,curr 指向头节点 1,通过 curr->next 可以获取到节点 2,并将其赋值给 next。
2. 遍历链表并反转节点间的指向关系
在迭代过程中,按以下步骤进行操作:
-
第一步:
使用next指针暂存当前节点curr的下一个节点,即next = curr->next。这一步很关键,因为后续要改变curr的next指针指向,如果不提前保存,就会丢失后续链表节点的信息。
比如对于上述链表,第一次执行时,next就指向了节点2。 -
第二步:
将当前节点curr的next指针指向已反转部分链表的尾节点,也就是prev指针所指向的节点,即curr->next = prev。
对于初始状态下的链表,第一次执行此操作时,会将节点1的next指针从原来指向节点2改为指向nullptr(因为此时prev初始为nullptr),相当于把节点1从原链表中 “摘” 出来,准备将其作为反转后链表的尾节点。 -
第三步:
更新prev指针,将其指向当前已经处理好的节点curr,即prev = curr。这样prev就始终指向已反转部分链表的尾节点,随着迭代不断更新,已反转链表部分不断变长。
在第一次迭代结束后,prev就从nullptr变为指向节点1了。 -
第四步:
更新curr指针,让其指向之前保存的下一个节点next,即curr = next,以便处理下一个节点,进行下一轮的迭代。
例如,第一次迭代结束后,curr就从指向节点1变为指向节点2了,然后可以继续进行下一轮的迭代操作。
3. 循环迭代直到遍历完整个链表
不断重复上述的四个步骤,直到 curr 指针变为 nullptr,这意味着已经遍历完了原链表的所有节点,此时整个链表就完成了反转。
例如,对于链表 1 -> 2 -> 3 -> 4,经过多次迭代后:
- 第一轮迭代后,链表变为
nullptr <- 1 2 -> 3 -> 4,prev指向节点1,curr指向节点2。 - 第二轮迭代后,链表变为
nullptr <- 1 <- 2 3 -> 4,prev指向节点2,curr指向节点3。 - 第三轮迭代后,链表变为
nullptr <- 1 <- 2 <- 3 4,prev指向节点3,curr指向节点4。 - 第四轮迭代后,链表变为
nullptr <- 1 <- 2 <- 3 <- 4,curr变为nullptr,整个链表反转完成,此时prev指向的节点4就是反转后链表的头节点。
代码如下(C++示例):
#include <iostream>
// 定义链表节点结构体
struct ListNode {
int val;
ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* curr = head;
while (curr!= nullptr) {
ListNode* next = curr->next;
curr->next = prev;
prev = curr;
curr = next;
}
return prev;
}总结
-
迭代法的优点
- 效率方面:
- 迭代法的时间复杂度是 ,其中 是链表的长度。这是因为它只需要遍历链表一次,对每个节点进行一次操作来反转链表。在空间复杂度上,迭代法通常只需要使用几个额外的指针变量(如前面提到的
prev、curr和next),空间复杂度为 。这意味着它在处理长链表时,不会占用过多的额外内存空间,对内存的使用比较高效。
- 迭代法的时间复杂度是 ,其中 是链表的长度。这是因为它只需要遍历链表一次,对每个节点进行一次操作来反转链表。在空间复杂度上,迭代法通常只需要使用几个额外的指针变量(如前面提到的
- 易于理解和调试:
- 迭代过程是一种比较直观的顺序操作过程。通过循环逐步改变节点之间的指针方向,每一步的操作和效果都比较清晰。例如,对于开发者来说,在调试过程中可以很容易地跟踪每一个指针的变化情况,以及每一次循环中链表的状态变化。这种直观性使得代码的逻辑相对容易理解,尤其是对于初学者或者对递归概念不太熟悉的开发者。
- 效率方面:
-
迭代法的缺点
- 代码结构灵活性差:
- 迭代法的代码结构相对固定,对于一些复杂的链表操作场景,如果需要在反转过程中同时进行其他复杂的操作(例如,同时检查节点是否满足某些特定条件,或者对部分节点进行特殊处理),可能会导致代码变得复杂和难以维护。因为所有的操作都集中在一个循环结构中,添加新的功能可能会干扰原有的反转逻辑。
- 代码结构灵活性差:
-
递归法的优点
- 代码简洁优雅:
- 递归法能够以一种简洁的方式实现链表反转。对于熟悉递归概念的开发者来说,代码的表达力很强。例如,在上面的递归代码中,通过一个简单的递归调用和少量的指针操作就能实现链表反转,不需要像迭代法那样使用显式的循环结构。这种简洁性在某些情况下可以使代码更易于阅读和理解,特别是当问题本身具有递归性质时,递归法能够很好地体现问题的本质。
- 可扩展性强:
- 递归法在处理一些更复杂的链表结构或者与其他递归操作结合时具有优势。例如,如果要对一个嵌套的链表结构(如链表中的节点本身又包含链表)进行反转,或者在反转过程中需要结合其他基于递归的算法(如对链表节点值进行递归计算),递归法可以很方便地进行扩展。因为递归的本质是将一个大问题分解为相似的小问题,在处理复杂的层次结构或者组合问题时能够自然地融入到已有的递归框架中。
- 代码简洁优雅:
-
递归法的缺点
- 效率问题:
- 递归法虽然时间复杂度也是 ,但是由于递归调用会在函数调用栈中占用额外的空间。对于一个长度为 的链表,在最坏情况下,函数调用栈的深度可能达到 ,这会导致空间复杂度为 。如果链表很长,可能会出现栈溢出的情况。此外,函数调用的开销(如参数传递、栈帧的创建和销毁等)也会在一定程度上影响性能。
- 理解难度较大:
- 递归法的执行过程相对抽象,对于不熟悉递归概念的开发者来说,理解代码的执行流程可能会比较困难。例如,很难直观地想象出每一层递归调用时节点指针的变化情况以及函数调用栈的状态。这可能会导致在调试过程中遇到更多的困难,因为需要深入理解递归的执行机制才能准确地定位问题。
- 效率问题:

















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









