






谈到后端项目开发,就绕不开数据库这个技术栈,谈到数据库,那就不得不提起一个如雷贯耳的大名 - MySQL数据库。MySQL 可是数据库界的“老大哥”!它就像是一个超级智能的“图书管理员”,不仅能帮助你存储海量数据,还能快速检索出你需要的信息
MySQL数据库,凭借其免费开源的特性、快速的检索效率、高效的事务处理机制、以及对海量数据存储的安全性,深受广大技术人员以及企业开发者的喜爱和追捧。但是,其对数据查询效率的优化和在高并发场景下的使用,如SQL调优、锁机制、减小查库查表压力等开发问题,也令不少技术人员和开发者倍感头疼。
博主刚好在最近也算是完成了一个业务项目的搭建的业务的编写,对于MySQL也是有了一定深度的使用认识,恰巧最近也是在学习各种MySQL相关的八股文。所以在本文中我将和大家共同探究MySQL中存储结构的奥秘。
存储引擎InnoDB
既然要将MySQL的底层存储结构,那就不得不提到构成MySQL的一个重要组成部分 - 存储引擎。MySQL 的存储引擎可是数据库的“心脏”!它们决定了数据如何存储、检索和管理,就像汽车的发动机,不同的发动机决定了汽车的性能和用途。MySQL 支持多种存储引擎,每种引擎都有其独特的特性和适用场景
MySQL常见的存储引擎
1. InnoDB
特点:
支持事务、行级锁和外键约束。
高并发、高可靠性。
默认存储引擎(MySQL 5.5 及以上版本)。
适用场景:需要事务支持和高并发的应用,如电商、金融系统。
2. MyISAM
特点:
不支持事务和外键约束。
表级锁,并发性能较低。
支持全文索引。
适用场景:读多写少的应用,如博客、新闻网站。
3. MEMORY
特点:
数据存储在内存中,读写速度极快。
不支持事务,数据易失(重启后丢失)。
适用场景:临时数据存储,如缓存、会话管理。
4. ARCHIVE
特点:
专为存储大量历史数据设计,压缩率高。
不支持索引,只支持插入和查询。
适用场景:日志存储、历史数据归档。
5. CSV
特点:
数据以 CSV 文件格式存储。
不支持索引,适合导入导出数据。
适用场景:数据交换、报表生成。
6. BLACKHOLE
特点:
数据写入后立即丢弃,不存储。
用于复制和日志记录。
适用场景:数据复制、日志记录。
InnoDB
InnoDB以其强劲的存储能力、高效的检索效率、对事务的支持、行级锁、外键约束等核心机制,从MySQL的一众存储引擎中脱颖而出,收到广大技术人员的大力追捧,同时也是MySQL 5.5 及以上版本的默认存储引擎。
InnoDB的索引结构
所谓InnoDB的索引结构,其实也就与其底层的数据结构有关,在InnoDB中,有这么两种索引结构
1. 聚簇索引(Clustered Index)
-
定义:InnoDB 的主键索引,数据直接存储在叶子节点。
-
特点:
-
每个表只能有一个聚簇索引。
-
如果没有主键,InnoDB 会自动生成一个隐藏的聚簇索引。
-
-
结构:
-
非叶子节点:存储主键值和指向子节点的指针。
-
叶子节点:存储完整的行数据。
-
2. 二级索引(Secondary Index)
-
定义:InnoDB 的非主键索引,叶子节点存储主键值。
-
特点:
-
每个表可以有多个二级索引。
-
查询时需要回表(通过主键值查找聚簇索引)。
-
-
结构:
-
非叶子节点:存储索引值和指向子节点的指针。
-
叶子节点:存储索引值和对应的主键值。
-
MySQL底层数据结构剖析 - B+树
在了解MySQL底层的数据结构之前,我们先要了解一下什么是B树,来帮助我们更好的了解B+树是如何通过B树转化而来的。
由于在大部分的业务场景中,数据查询的频率源于数据插入和修改的频率,所以在对MySQL底层数据结构的剖析中,我们将会主要关注于该数据结构的检索查询效率。
何为B树
1. 定义
-
B树:一种平衡多路搜索树,每个节点可以包含多个子节点,适合存储和检索大量数据。
2. 核心特点
-
所有节点都存储数据。
-
节点中的关键字按升序排列。
3. 图解B树
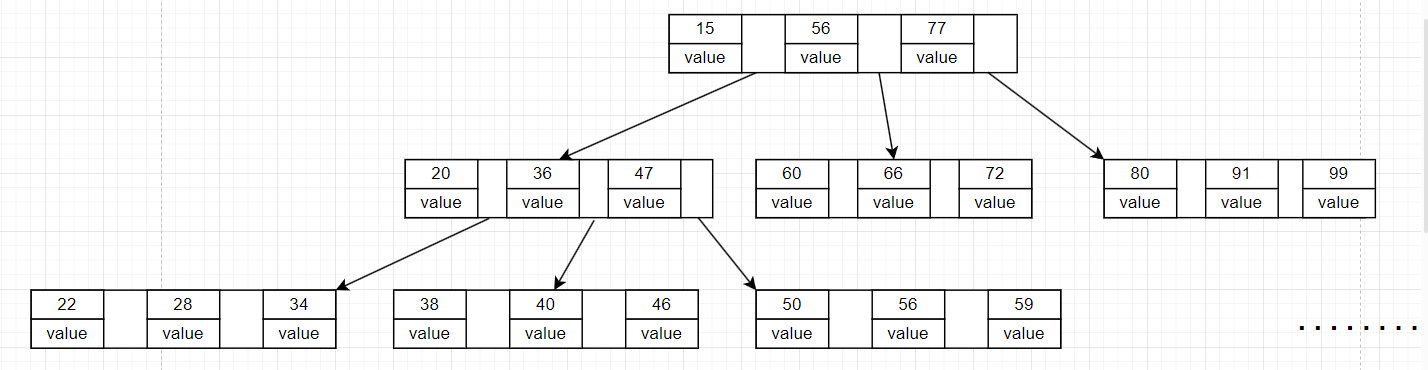
从图中我们不难看出B树的结构特点,即可将B树看成是二叉树的延申(二叉树的概念及相关操作在博主往期的博文中有所涉及),在这里,我们使用具有三个分叉的B树作为讲解的例子,即B树不再只有两个分叉,且每个分叉的节点上都存储了具体的数据和指向下一个节点的指针。这样的数据结构相比较与其他的数据结构来说,B树通过多路搜索,减少磁盘 I/O 次数,大大提高了数据检索的效率,且从平衡性的角度来说,B树的高度平衡,查询性能较为稳定。
4. B树的弊端
在上述内容中我们有提到,B树中的任意的节点都有若干个数据域和若干个指针域,这说明在B树中不管是其根节点还是叶子节点都存储了实际的数据,而恰恰是这样的结构导致的B树弊端的存在。
随着数据量的不断增长,B树的深度也必然会随之增加,当我们对两个不同的数据进行检索查询时,可能会出现待查找的两个数据分布在B树不同的层数上,且这两个层数差距过大的情况。可能数据X出现中B树的第1层,即根节点处,使得在查询数据X时的检索效率特别快;另外一个数据Y出现在B树的第3层甚至第4层,使得在查询数据Y时的检索效率特别慢。这样的情况就会产生B树的数据查询效率参差不齐,是在数据量不断增减的情况下,这个问题将会被不断的放大。
针对上述提及的B树的弊端,在B树的基础上,衍生出了B+树,很好的解决了B树数据查询效率参差不齐的问题。
何为B+树
1. 定义
-
B+树:和B树类似,也是一种平衡多路搜索树。B+树是B树的变种,与B树不同,B+树的所有数据都存储在叶子节点,非叶子节点只存储索引
2. 核心特点
-
非叶子节点只存储索引,不存储数据。
-
叶子节点通过指针连接,形成一个有序链表。
3. 图解B+树
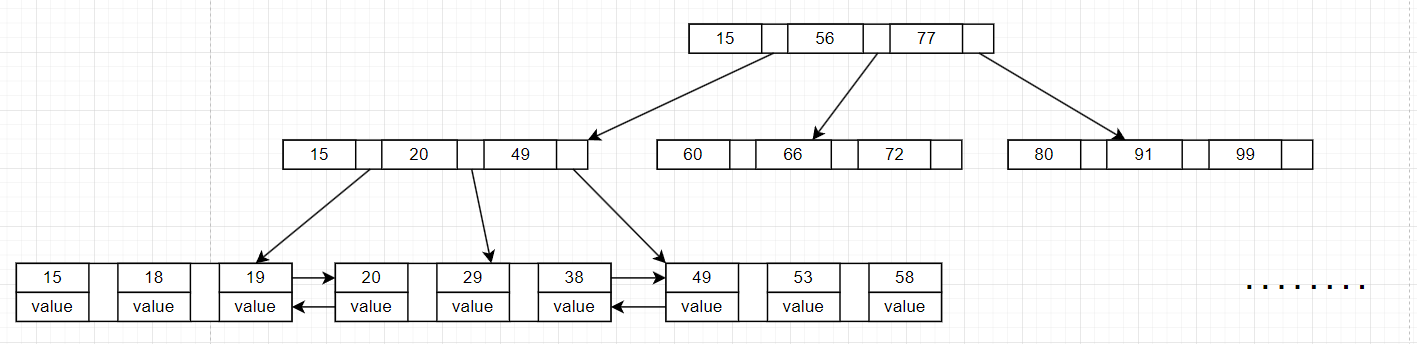
综合上述B树和B+树的图解,通过比较我们可以看出B+树所有的具体数据都存储在了其叶子节点上;且B+树的非叶子节点上存储的只有指向具体数据的索引,并没有具体的数据;除此之外,我们可以看到,在B+树最底层的叶子节点上,使用了双向指针将所有的叶子节点串联起来,使得所有的叶子节点形成了一个双向链表,提高了B+树检索大范围数据的性能。
4. B+树的优势
回顾在上面我们提到的B树的弊端:由于B树在每个节点上都存储了具体的数据,很可能导致两个不同数据的查询效率相差很大,不同数据检索效率不一致的问题。再看到B+树的结构特性:B+树只有在最底层的叶子节点上存储了具体的数据,使得B+树在不同节点数据的检索查询效率的一致性强,不会产生不同数据查询效率参差不齐的弊端;再鉴于B+树的层数大部分情况下一般都是三层的结构,采用多路搜索的,减少磁盘的I/O次数,这也使得其查询的高效性能够得以保证。
除此之外,B+树在最底层的各个叶子节点中间使用了指针进行连接,使各个叶子节点构成了一条有序的双向链表,即B+树在对一组有序数据进行查询是,不需要再检索完一个数据后,再回到根节点向下查询下一个数据;而是借助叶子节点组成的双向链表,在查询到一个数据后通过连接的指针顺序查询下一个数据,提高了B+树进行大范围有序数据查询的效率。
总结
MySQL凭借其对事务机制的支持、高效的检索速度,成为了众多企业级项目在关系型数据库上的首选,其强大核心存储引擎InnoDB中的底层数据结构 - B+树,正是MySQL数据库能够在检索查询数据方面有着高效表现的关键因素。学习了解 B+ 树,不仅仅能够了解MySQL的底层数据结构,还能够通过其结构特性,帮助我们更好的从底层的角度提升数据库的检索效率,更好的进行SQL调优。
本文的内容为博主学习总结而来,代表了博主本人的理解和看法,如果文中有出现表述不当甚至是表述错误的内容,还望各位技术大佬和前辈们不吝赐教,多多指正。
最后也是感谢大家的耐心观看,也希望大家能够多多鼓励和支持,多多关注,你的关注和支持,也是博主不断前进的动力。

















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









