






 本文介绍了C语言中指定数据类型的原因及好处,详细阐述了整数、字符、浮点、布尔等数据类型,包括其特点、范围和存储方式。还介绍了数据类型的无符号属性、基本数据类型的格式符,以及ASCII字符表的作用和应用。
本文介绍了C语言中指定数据类型的原因及好处,详细阐述了整数、字符、浮点、布尔等数据类型,包括其特点、范围和存储方式。还介绍了数据类型的无符号属性、基本数据类型的格式符,以及ASCII字符表的作用和应用。
一、说明
1、计算机在运算时指定数据类型的原因
(1)计算机中的数据与数学中的数据的区别
1)在数学中,数字并不总是需要明确的类型,因为数学本身更关注于数值和数值之间的关系,数学是一门研究抽象问题的学科,数和数的运算都是抽象的。然而,在计算机中,数据是存放在存储单元中的,是具体的,而且计算机的存储单元是有限的,所以数据类型的概念是必要的,并且计算机是基于二进制编码的,因此它们对存储和处理数据有严格的规定和限制。
2)计算机需要知道数据的类型,因为不同类型的数据需要不同大小的内存来存储,而且对于不同类型的数据,操作和处理方法也可能会有所不同。例如,整数、浮点数、字符、布尔值等不同类型的数据在计算机内存中需要不同的存储空间和处理方式。此外,数据类型的定义也帮助程序员确保数据在被使用时不会出现不符合预期的情况,提高了程序的稳定性和可靠性。
(2)什么是类型?
1)所谓类型,就是对数据分配存储单元的安排,包括存储单元的长度(占多少个字节)以及数据的存储形式。不同的数据类型会被分配不同的长度和存储形式。
例如:
当你在计算机中使用整数和浮点数时,它们会以不同的方式存储。比如,整数通常以固定的位数进行存储,比如32位或64位整数,它们在内存中占用固定数量的位(或字节)。而浮点数则以IEEE标准规定的格式存储,包含指数和尾数部分,这使得浮点数能够表示更大范围的值,但会占用更多的存储空间。
(3)C语言中具有不同数据类型的好处
1)内存利用和优化:
每种数据类型在内存中占据的空间大小是固定的,这使得在内存使用方面更加高效。比如,`int`类型通常占据4个字节,`char`类型占据1个字节。这样可以更好地控制内存的使用,避免浪费内存空间。
2)数据存储和表示:
不同的数据类型支持不同的数值范围和精度。例如,`int`可以表示整数,`float`和`double`可以表示浮点数,`char`可以表示字符等。这种不同的数据类型有助于正确地存储和表示不同种类的数据。
3)编程规范和可读性:
使用适当的数据类型可以使代码更易读和易于维护。通过使用有意义的类型名称,可以让其他开发人员更容易理解代码的含义和目的。
4)错误检测和类型安全:
数据类型有助于在编译时或运行时检测类型不匹配的错误。这可以防止一些常见的错误,比如试图将一个字符串赋给一个整数类型的变量。
5)算术运算和精度控制:
不同的数据类型对算术运算有不同的规则,比如整数除法和浮点数除法行为不同。选择合适的数据类型可以控制运算的精度和行为。
二、数据类型
1. 整数类型(Integer Types):
1) 基本整型`int`:
表示整数,通常在大多数情况下使用。其大小通常是机器字长(在大多数现代系统中是32位或64位),可以存储范围为约 -2^31 到 2^31 - 1(具体取决于系统),占2个或4个字节的空间。(' ^ ' 符号代表了幂,如:2^3 = 8)
2)短整型`short int`:
短整数类型,通常比`int`占用更少的空间,但能表示的范围较小,可以存储的范围为约-2^15到(2^15 - 1),占2个字节的空间。
3)长整型`long int`:
长整数类型,通常比`int`占用更多的空间,能表示的范围更大,可以存储的范围约为 -2^31 到 (2^31 - 1),占4个字节的空间。
4)双长整型`long long int`:
更长的整数类型,引入于 C99 标准,通常能表示更大范围的整数,可以存储的范围为约-2^63到(-2^63 - 1),一般占8个字节的空间。
注意:C标准没有具体规定各种类型数据所占用的存储单元的长度,这是由各编译系统自行决定的。在C标准中只要求long型数据长度不短于int型,short型不长于int型。即:
sizeof(short)<= sizeof (int) <= sizeof(long) <= sizeof(long long) (sizeof 是C语言中的运算符,我们本篇文章后面会讲到运算符)
3. 字符类型(Character Types):
1)说明:
字符与字符代码并不是任意一个写一个字符,程序都能识别的。例如代表圆周率的符号![]() 在程序中是不能识别的,只能使用系统的字符集中的字符,目前大多数的系统都是采用的ASCII字符集。各种字符集(包括ASCII字符集)的基本集从0到127包括了128个字符,并且所有128个字符都可以用7个二进制位表示(ASCII代码为127时,二进制形式为1111111,7位全1)。所以在C语言中,指定用一个字节(8位)储存一个字符(所用系统都不例外),此时字节中的第一位为0,字符是以整数形式(字符的ASCII代码)存放在内存单元中的。
在程序中是不能识别的,只能使用系统的字符集中的字符,目前大多数的系统都是采用的ASCII字符集。各种字符集(包括ASCII字符集)的基本集从0到127包括了128个字符,并且所有128个字符都可以用7个二进制位表示(ASCII代码为127时,二进制形式为1111111,7位全1)。所以在C语言中,指定用一个字节(8位)储存一个字符(所用系统都不例外),此时字节中的第一位为0,字符是以整数形式(字符的ASCII代码)存放在内存单元中的。
例如:
大写字母' A '的ASCII代码是十进制数 65 ,二进制形式为1000001。
小写字母' a '的ASCII代码是十进制数 97,二进制形式为1100001。
数字字符' 1 '的ASCII代码是十进制数49,二进制形式为0110001。
......
2)字符型`char`:
用于表示单个字符,可以存储ASCII字符集或其他字符编码的字符,'char'类型占用1个字节的内存空间(在大多数系统中),可以表示256个不同的字符,包括字母、数字、标点符号和特殊字符,并且在使用有符号字符型变量时,允许存储的值为-128到127,但是字符的代码是不可能有负值的,所以在存储字符时实际上只用到0到127这一部分,并且它的第一位都是0。在C语言中,字符型数据有几个重要的特点和用途:
(1)表示字符:
‘char’类型用于存储单个字符,比如字母、数字、标点符号等。例如,`'a'`、`'7'`、`'!'`都是合法的`char`类型。举一个简单的代码示例:
#include<stdio.h>
int main()
{
char ch = 'A';
printf("%c", ch);
return 0;
}上面这个简单的代码就是将字符‘ 'A' ’赋值给变量' ch '。可能有人会问为什么要说字符'a'而不是字母a呢?那是因为在C语言中,字符 `A` 表示一个字符常量,它代表了字符集中的一个特定字符。在ASCII字符集中,`A` 是大写字母 A 的表示,它对应的ASCII码值是65(十进制),或者在八进制表示为 101,十六进制表示为 0x41。在计算机中,字符常量与其对应的ASCII码值相联系。例如,在C语言中,可以将字符常量赋值给`char`类型的变量,就像上面的代码示例,代码将字符常量 `'A'` 赋值给变量 `ch`。此时,变量 `ch` 就存储了ASCII码值为65的字符 'A'。
这时候我们将代码中'printf()'函数中的占位符改成' %d ':
#include<stdio.h>
int main()
{
char ch = 'A';
printf("%d", ch);
return 0;
}上面的代码运行的结果是什么呢?让我们来看看:
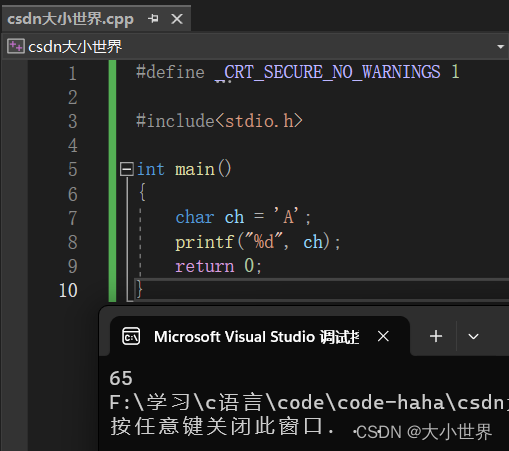
是数字65,为字母' A '的ASCII码值。无论是' ! '、' @ '、' # '....只要是电脑上有的符号,都有着它们自己的ASCII码值,至于ASCII码值的作用我再者篇文章最后会讲到(大家不要着急)
(2)字符数组和字符串:
一系列`char`类型的变量组合起来形成字符数组,多个字符连续存储在内存中。当`char`数组以空字符 `'\0'` 结尾时,它们就组成了一个字符串。例如,`char str[] = "Hello";` 定义了一个字符串,`str`中存储了字符`'H'`、`'e'`、`'l'`、`'l'`、`'o'`,并以空字符 `'\0'` 结尾。
4. 浮点类型(Floating-Point Types):
1)说明:
浮点型数据是用来表示具有小数点的实数的。C语言中将实数称为浮点数是因为实数在计算机中的表示采用了浮点数表示法。浮点数表示法使用科学计数法来表示实数,它由两部分组成:尾数(mantissa)和指数(exponent)。这种表示方法允许用有限数量的位数来表示广阔范围的实数值,但精度可能会有所损失。
"浮点"一词指的是小数点可以在尾数部分根据指数的变化而“浮动”,即小数点的位置可以根据指数的调整而移动,从而表示不同数量级的数值。浮点数因此可以表示很大或很小的数,并在不同数量级之间进行调整。C语言中的浮点数类型包括 `float`(单精度浮点数)、`double`(双精度浮点数)和 `long double`(扩展精度浮点数)。这些类型使用浮点数表示法来存储实数值,提供不同精度和范围的表示能力。
1)单精度浮点型`float`:
单精度浮点数,通常占用4个字节,可表示大约6位精度的小数。单精度浮点数采用IEEE 754标准来表示,其中大约有23位用于尾数,8位用于指数,1位用于符号。这种表示方法允许 `float` 类型的变量表示范围广泛的实数值,但相对双精度浮点数 (`double`) 而言,精度较低。单精度浮点型' float '型数据的数值范围为-3.4x10^-38到3.4x10^38。
在C语言中,使用 `float` 类型来声明单精度浮点数。例如:
float a = 3.14f;
注意:声明单精度浮点数时,通常会在数值后面添加字母 `f` 或 `F` 以明确指示这是单精度浮点数。如果省略 `f`,则默认为双精度浮点数,即 `double` 类型。
2)双精度浮点型`double`:
双精度浮点数在C语言中通常占用8个字节(64位)的存储空间,提供更高的精度,可表示大约15位精度的小数。双精度浮点数同样采用IEEE 754标准来表示,它有大约52位用于尾数,11位用于指数,1位用于符号。相比于单精度浮点数 (`float`),双精度浮点数提供了更高的精度,能够表示更广范围的实数值。双精度浮点数的数值范围为-1.7x10^-308到1.7x10^308.
在C语言中,使用 `double` 类型来声明双精度浮点数。例如:
double b = 3.14159265359;
`double` 类型通常是默认的浮点数类型,如果要声明一个双精度浮点数,可以直接使用 `double` 关键字。
3)扩展精度浮点数`long double`:
扩展精度浮点型在C语言中通常使用 `long double` 来表示。它是一种更高精度的浮点数数据类型,相比于 `double` 类型,`long double` 提供了更大的存储空间和更高的精度。
`long double` 类型通常使用80位或更多的存储空间(取决于具体的计算机架构),比起 `double` 的64位,它能够表示更大范围和更高精度的实数值。
在一些特定的应用中,比如科学计算或者需要极高精度的计算任务,`long double` 类型可能会更适合,因为它提供了比标准双精度浮点数更高的精度和范围。但是并非所有的计算机架构和编译器都对 `long double` 进行了一致的实现,因此在不同系统上它的精度和范围可能有所不同。
4)复数浮点型 '_Complex':
在C语言标准库中,并没有直接支持复数的内建类型,即没有专门用于表示复数的数据类型。C语言标准库提供了一些复数操作的库函数,但是它们是通过使用结构体或者其他方式来模拟复数的运算。
在C99标准之后,C语言引入了复数支持,提供了一种 `_Complex` 关键字来支持复数操作。例如:
double complex z = 3.0 + 4.0*I; // 表示复数3+4i
这里,`I` 是一个虚数单位。但需要注意的是,要使用复数相关的函数和运算符,需要包含 `<complex.h>` 头文件,并且需要编译器支持 C99 标准或更高版本的特性。
虽然C语言提供了这些支持,但并非所有的编译器都完全支持复数类型,而且复数操作可能不够高效。在实际应用中,为了处理复数,有时会使用自定义结构体或者数组来表示复数,并自行实现相应的运算。在大多数情况中我们都不需要用到复数浮点型大家在这里有个印象,不用死记。
5. 布尔类型(Boolean Type):
在C语言中,布尔类型是用来表示逻辑值的数据类型。C99标准之后,引入了`stdbool.h`头文件,其中定义了`bool`类型,以及`true`和`false`两个常量。
基本的布尔类型定义如下:
#include <stdbool.h>
bool a = true; // 声明一个布尔类型的变量,并初始化为true
bool b = false; // 声明一个布尔类型的变量,并初始化为false
`bool`类型只有两个可能的取值,即`true`和`false`,分别表示真和假。在条件语句、循环控制和逻辑运算等场景下,布尔类型通常用于判断条件、表示开关状态等。
在C语言之前的版本中,并没有内建的布尔类型,通常使用`int`类型来模拟布尔类型,其中`0`代表假,非零整数代表真。但是引入`stdbool.h`之后,使用`bool`类型更为直观和方便。
6. 其他类型:
1)`void`:表示无类型,通常用于函数返回类型、指针类型等。
2) 指针类型:`int*`, `char*`等,用于存储变量的地址。
3)自定义类型:使用`struct`、`enum`等关键字可以创建用户自定义的复合类型。
4)枚举类型:枚举类型提供了一种有意义的方式来定义一组相关的命名常量。
(这里的空类型、指针类型、自定义类型和枚举类型我会在之后的文章中向大家解释清楚,在这里说明大家可能会一头雾水。)
7.数据类型的无符号属性:
当我们谈论数据类型的无符号属性时,指的是数据类型能否表示负数。在C语言中,不同的数据类型可以具有无符号(unsigned)或有符号(signed)的属性。这种属性在声明变量时用于描述该变量可以表示的范围。
1、整型数据类型的无符号属性:
1)无符号整型
只能表示非负数(即正数和零)。
例如,`unsigned int`, `unsigned short`, `unsigned long` 等。比如 `unsigned int num = 10;` 这个 `num` 变量只能存储正数或零。这就意味着基本整型的范围原来是 -2^31 到 2^31 - 1 变为了0到2^32-1,无符号浮点型和无符号字符型数据也是一样的,它们的取值范围都变成了正值,并且属于正值的范围扩大了两倍。
2) 浮点型数据类型的无符号属性:
浮点数类型(`float`, `double`, `long double`)总是有符号的。因为浮点数旨在表示包括正数、负数和零在内的各种实数,所以它们没有无符号的版本。
选择有符号或无符号数据类型取决于所需范围和表示的数据本身。无符号类型可以表示更大的正数范围,但无法表示负数。在选择数据类型时,需要考虑到数据的范围、符号以及程序的需求。
三、基本数据类型的格式符(占位符)
C语言中常见的格式符(占位符)有很多种,每种都用来指示不同类型的数据。以下是一些常见的格式符及其作用:
1. `%d`: 用于输出或输入整数(十进制数)。
2. `%f`: 用于输出或输入浮点数。
3. `%c`: 用于输出或输入字符。
4. `%s`: 用于输出或输入字符串。
5. `%u`: 用于输出或输入无符号整数。
6. `%x`、`%X`: 用于输出或输入十六进制数,`%x` 输出小写字母表示,`%X` 输出大写字母表示。
7. `%o`: 用于输出或输入八进制数。
8. `%e`、`%E`: 用于以科学计数法形式输出浮点数,`%e` 输出小写字母表示,`%E` 输出大写字母表示。
9. `%g`、`%G`: 根据值的大小自动选用 `%f` 或 `%e` 格式进行输出,`%g` 输出小写字母表示,`%G` 输出大写字母表示。
10. `%p`: 用于输出指针的地址。
11. `%lld`、`%llu`: 用于输出长长整数和无符号长长整数。
12. `%%`: 输出一个百分号 `%`。
这些格式符在 `printf` 和 `scanf` 函数中被用于指示要输出或输入的数据的类型和格式。它们确保了数据以正确的格式进行读取和显示,以及使得输出结果更符合预期。使用正确的格式符对于数据的处理和显示非常重要,能够避免错误和产生意外的输出。
ASCII字符表:
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)字符集是用于表示文本信息的字符编码标准。它为键盘、显示器、打印机等设备上的字符提供了一种统一的表示方式。ASCII 字符集使用 7 位二进制数字来表示 128 个字符,包括控制字符(例如换行符、回车符)和可显示字符(例如字母、数字和标点符号)。
ASCII 字符标有以下几个作用:
1. 字符编码:
每个 ASCII 字符都与一个唯一的 7 位二进制数值相对应。这种对应关系使得计算机能够存储和处理文本信息。
2. 字符输入输出:
ASCII 字符编码使得设备(如键盘、显示器、打印机)能够正确地读取和显示文本信息,因为这些设备遵循 ASCII 标准,能够正确地识别和处理 ASCII 字符。
3. 数据传输:
在网络通信或数据存储中,ASCII 字符集作为一种基本的字符编码方式被广泛使用。它提供了一种简单的方式来表示和传输文本数据,例如在电子邮件、网页和文本文件中。
4. 编程中的应用:
在编程中,ASCII 字符编码常常用于处理和操作文本数据。例如,在 C 语言中,字符型变量(`char`)通常用 ASCII 码来表示对应的字符。
虽然 ASCII 字符编码在计算机领域仍然有用,但它的局限性在于只能表示 128 个字符,这对于某些语言或特殊符号来说可能是不够的。后续的编码标准(如 Unicode)扩展了字符集的大小,使得更多字符能够被表示。
四、总结
在本篇文章中我们学习了计算机中具有各种基本类型的好处、整型类型、浮点类型,提了一下枚举类型(enum)、空类型(void)、指针类型(*)、结构体类型(struct)和共用体类型(union),还大体的学习了ASCII字符表的作用。本篇文章较为基础,希望大家能理解本篇文章哦!
以上就是本篇文章的基本内容啦,希望小伙伴们能够学到有用的知识,别忘了点赞、收藏加关注哦!!!
下期预告:第三幕:C语言基础篇之运算符和表达式(原码,反码和补码介绍、C语言中常见运算符及其使用、优先级与结合性、不同数据类型间的混合运算)
(这篇文章写这么久的原因实在是因为事情太多了(也有懒的原因),等过了这段时间就会好很多了,最后在这里给大家送上新年的祝福:新年快乐!!!新的一年希望大家天天向上,每天都没有烦恼,每次出门都踩狗屎!)

















 4346
4346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









