






4.1 串
4.1.1 串的基本概念
1. 串是由零个或多个字符组成的有限序列。记作str="a0a1…an-1"(n≥0)。
2. 串中所包含的字符个数n称为串长度,当n=0时,称为空串。
3. 一个串中任意连续的字符组成的子序列称为该串的子串。
4. 包含子串的串相应地称为主串。
5. 若两个串的长度相等且对应字符都相等,则称两个串相等。
6. 若s是一个长度为n的串,子串个数为n(n+1)/2+1。
4.1.2 串的存储结构
1. 串的顺序存储结构—顺序串
MaxSize=100 #假设容量为100
class SqString: #顺序串类
def __init__(self): #构造方法
self.data=[None]*MaxSize #存放串中字符
self.size=0 #串中字符个数
def SubStr(self,i,j): #求子串的运算算法
s=SqString() #新建一个空串
assert i>=0 and i<self.size and j>0 and i+j<=self.size #检测参数
for k in range(i,i+j): #将data[i..i+j-1]->s
s.data[k-i]=self.data[k]
s.size=j
return s #返回新建的顺序串
2. 串的链式存储结构—链串
class LinkNode: #链串结点类型
def __init__(self,d=None): #构造方法
self.data=d #存放一个字符
self.next=None #指向下一个结点的指针
class LinkString: #链串类
def __init__(self): #构造方法
self.head=LinkNode() #建立头结点
self.size=0
串的插入:
实现:先创建一个空串s,当参数正确时,采用尾插法建立结果串s:
(1)将当前链串的前i个结点复制到s中。
(2)将t中所有结点复制到s中。
(3)再将当前串的余下结点复制到s中。
def InsStr(self,i,t): #串插入运算的算法
s=LinkString() #新建一个空串
assert i>=0 and i<self.size #检测参数
p,p1=self.head.next, t.head.next
r=s.head #r指向新建链表的尾结点
for k in range(i): #将当前链串的前i个结点复制到s
q=LinkNode(p.data)
r.next=q; r=q #将q结点插入到尾部
p=p.next
while p1!=None: #将t中所有结点复制到s
q=LinkNode(p1.data)
r.next=q; #将q结点插入到尾部
p1=p1.next
while p!=None: #将p及其后的结点复制到s
q=LinkNode(p.data)
r.next=q; r=q #将q结点插入到尾部
p=p.next
s.size=self.size+t.size
r.next=None #尾结点的next置为空
return s 4.1.3 串的模式匹配
1. 设有两个串s和t,串t定位操作就是在串s中查找与子串t相等的子串。
2. 通常把串s称为目标串,把串t称为模式串,因此定位也称作模式匹配。
3. 模式匹配成功是指在目标串s中找到一个模式串t。
4. 不成功则指目标串s中不存在模式串t。
1. BF算法
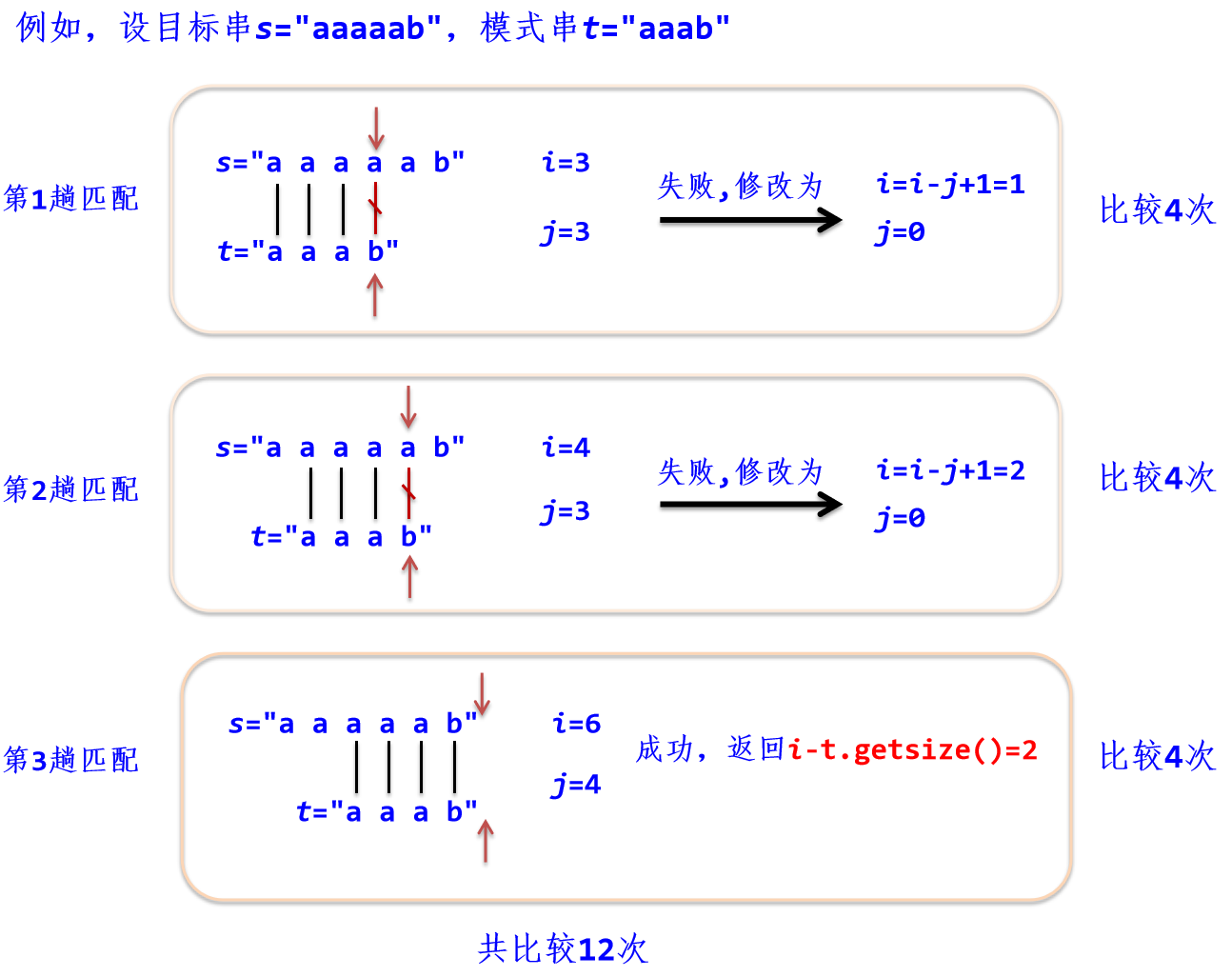
def BF(s,t): #BF算法
i,j=0,0
while i<s.getsize() and j<t.getsize(): #两串未遍历完时循环
if s[i]==t[j]: #两个字符相同
i,j=i+1,j+1 #继续比较下一对字符
else:
i,j=i-j+1,0 #i从下个位置,j从头开始匹配
if j>=t.getsize():
return (i-t.getsize()) #返回匹配的首位置
else:
return (-1) #模式匹配不成功
2. KMP算法
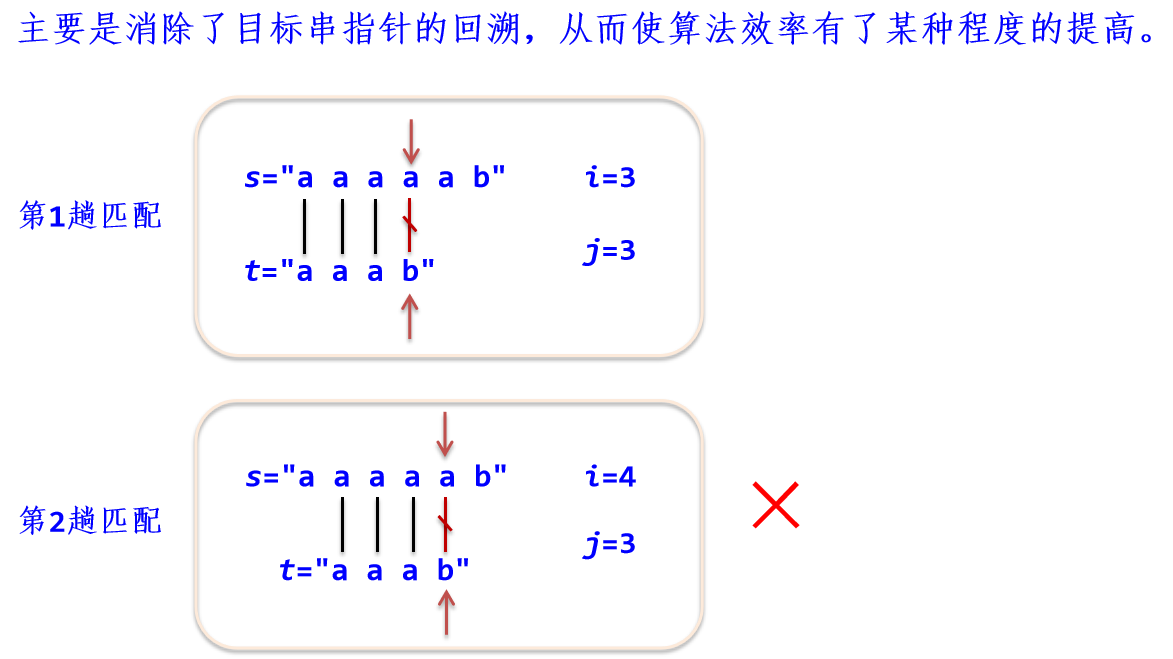

1. tj的前面有多少个连续字符(不含t0)和t开头的连续字符相同!
2. 用next数组存放,这里next[3]=2。
3. 下一次做si/tj比较。
def GetNext(t,next): #由模式串t求出next值
j,k=0,-1
next[0]=-1
while j<t.getsize()-1:
if k==-1 or t[j]==t[k]: #j遍历后缀,k遍历前缀
j,k=j+1,k+1 #next[k] next[k+1]
next[j]=k
else:
k=next[k] #k置为next[k]
def KMP(s,t): #KMP算法
next=[None]*MaxSize
GetNext(t,next) #求next数组
i,j=0,0
while i<s.getsize() and j<t.getsize():
if j==-1 or s[i]==t[j]:
i,j=i+1,j+1 #i,j各增1
else:
j=next[j] #i不变,j回退
if j>=t.getsize():
return(i-t.getsize()) #返回起始序号
else:
return(-1) #返回-1
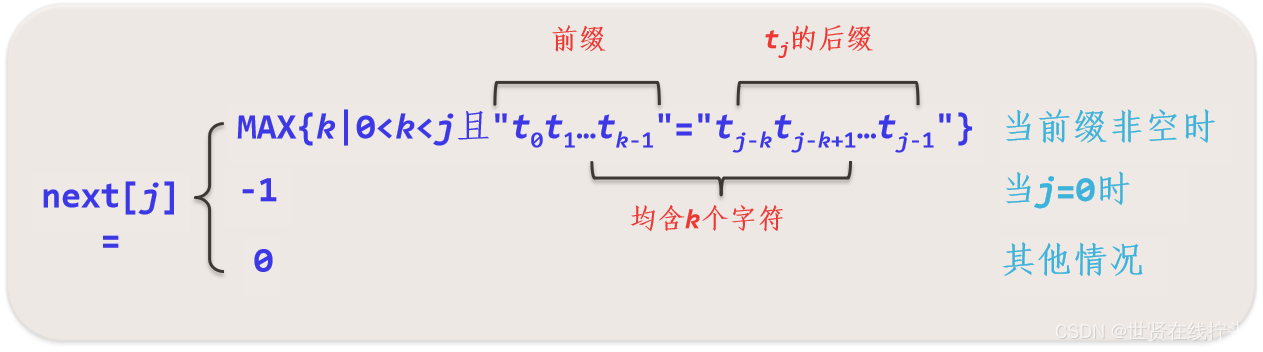
3. 改进KMP算法
实现:
将next数组改为nextval数组,与next[0]一样,先置nextval[0]=-1。假设求出next[j]=k,现在失配处为si/tj,即si≠tj,
(1)如果有tj=tk成立,可以直接推出si≠tk成立,没有必要再做si/tk的比较,直接置nextval[j]=nextval[k](nextval[next[j]]),即下一步做si/tnextval[j]的比较。
(2)如果有tj≠tk,没有改进的,置nextval[j]=next[j]。

def GetNextval(t,nextval): #由模式串t求出nextval值
j,k=0,-1
nextval[0]=-1
while j<t.getsize()-1:
if k==-1 or t[j]==t[k]:
j,k=j+1,k+1
if t[j]!=t[k]:
nextval[j]=k
else: #t[j]=t[k]
nextval[j]=nextval[k]
else: k=nextval[k]
def KMPval(s,t): #改进后的KMP算法
nextval=[None]*MaxSize
GetNextval(t,nextval) #求nextval数组
i,j=0,0
while i<s.getsize() and j<t.getsize():
if j==-1 or s[i]==t[j]:
i,j=i+1,j+1 #i,j各增1
else: j=nextval[j] #i不变,j回退
if j>=t.getsize():
return(i-t.getsize()) #返回起始序号
else:
return(-1) #返回-1
4.2 数 组
4.2.1 数组的基本概念
1. 数组是一个二元组(idx,value)的集合,对每个idx,都有一个value值与之对应。idx称为下标,可以由一个整数、两个整数或多个整数构成,下标含有d(d≥1)个整数称为维数是d。
2. 数组按维数分为一维、二维和多维数组。
3. 一维数组A是n(n>1)个相同类型元素a0,a1,…,an-1构成的有限序列,其逻辑表示为A=(a0,a1,…,an-1),其中,A是数组名,ai(0≤i≤n-1)是数组A中序号为i的元素。
4. 一个二维数组可以看作是每个数据元素都是相同类型的一维数组的一维数组。 以此类推。
特点
(1)数组中各元素都具有统一的数据类型。
(2)d(d≥1)维数组中的非边界元素具有d个前驱元素和d个后继元素。
(3)数组维数确定后,数据元素个数和元素之间的关系不再发生改变,特别适合于顺序存储。
(4)每个有意义的下标都存在一个与其相对应的数组元素值。
1. 一维数组
一维数组的所有元素依逻辑次序存放在一片连续的内存存储单元中。
其起始地址为第一个元素a0的地址即LOC(a0)。
假设每个数据元素占用k个存储单元。
则任一数据元素ai的存储地址LOC(ai)就可由以下公式求出
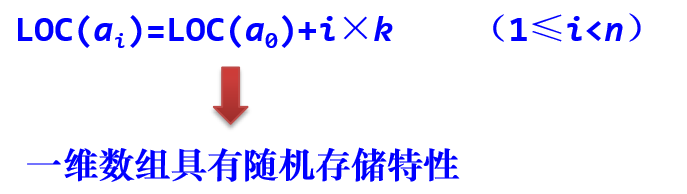
MAXN=10
a=[None]*MAXN
2. d维数组

4.2.2 特殊矩阵的压缩存储
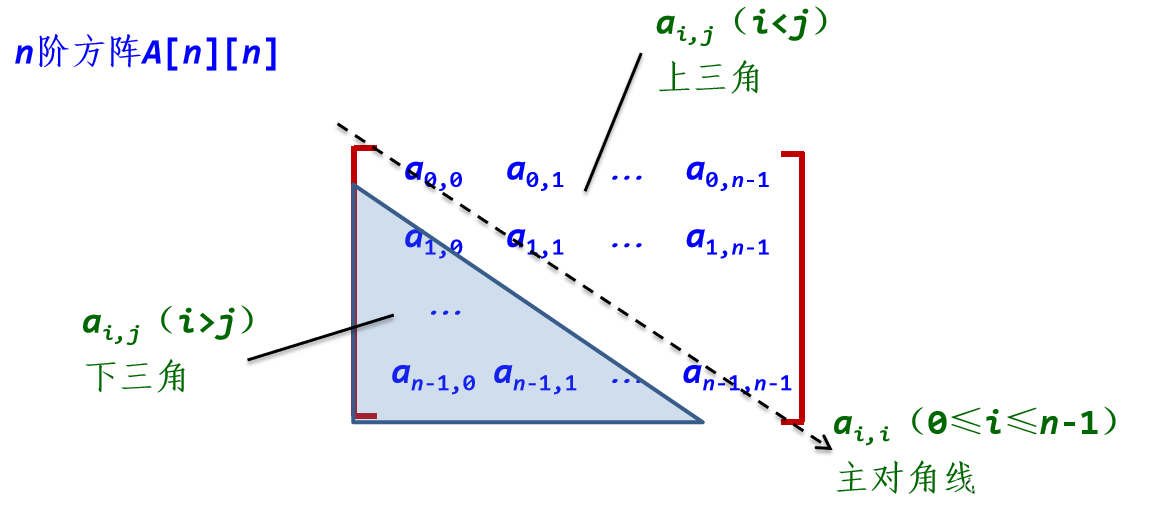
1. 对称矩阵的压缩存储
若一个n阶方阵A的元素满足ai,j=aj,i(0≤i,j≤n-1),则称其为n阶对称矩阵。
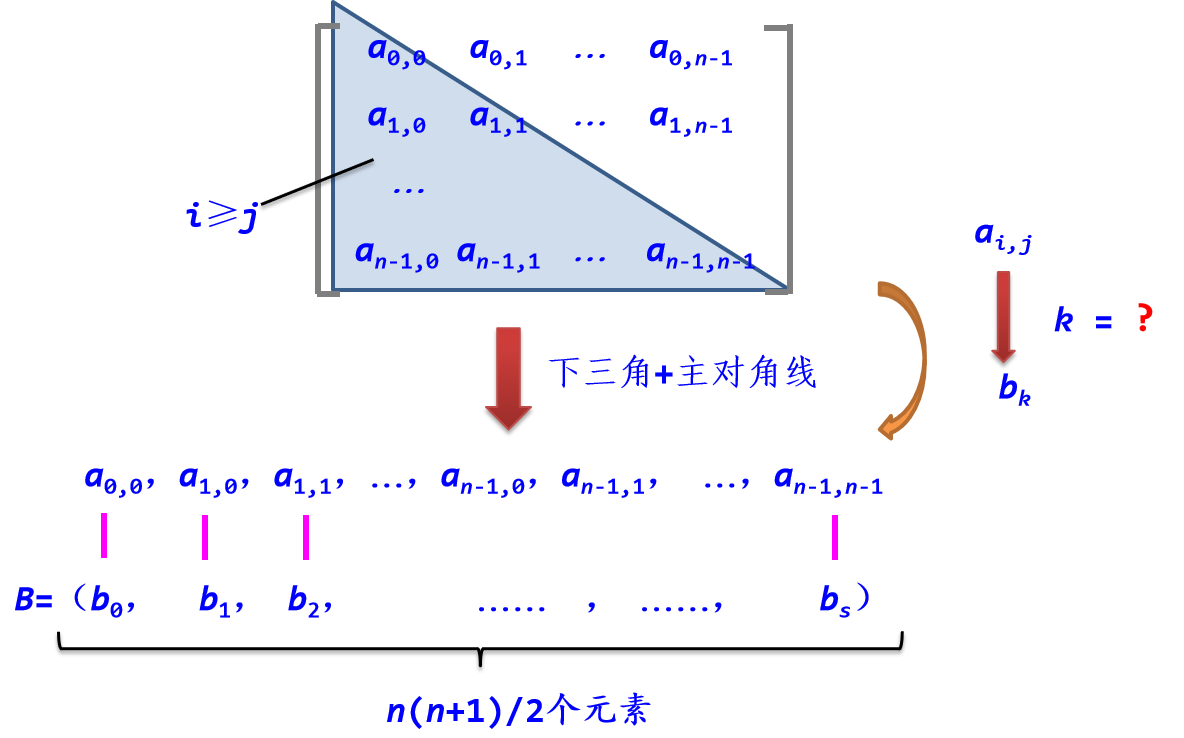
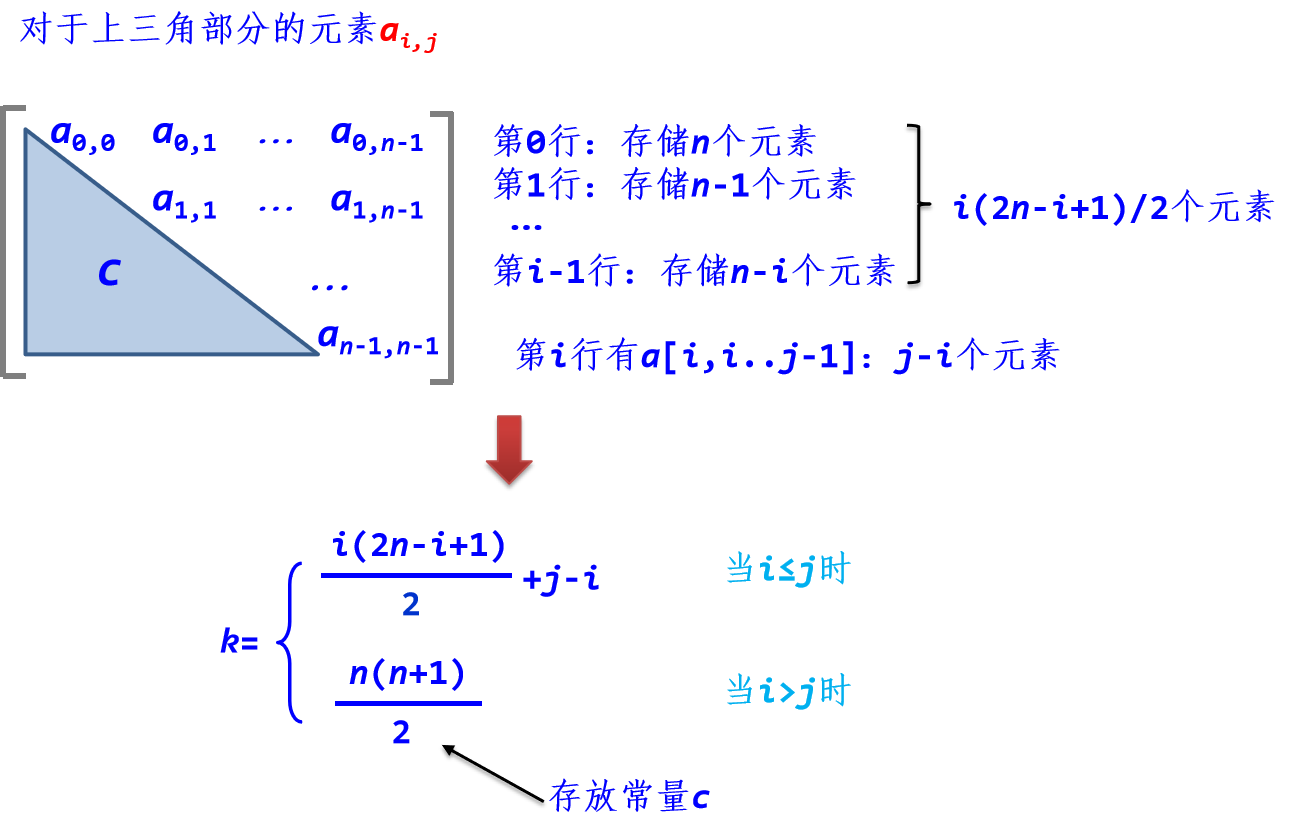
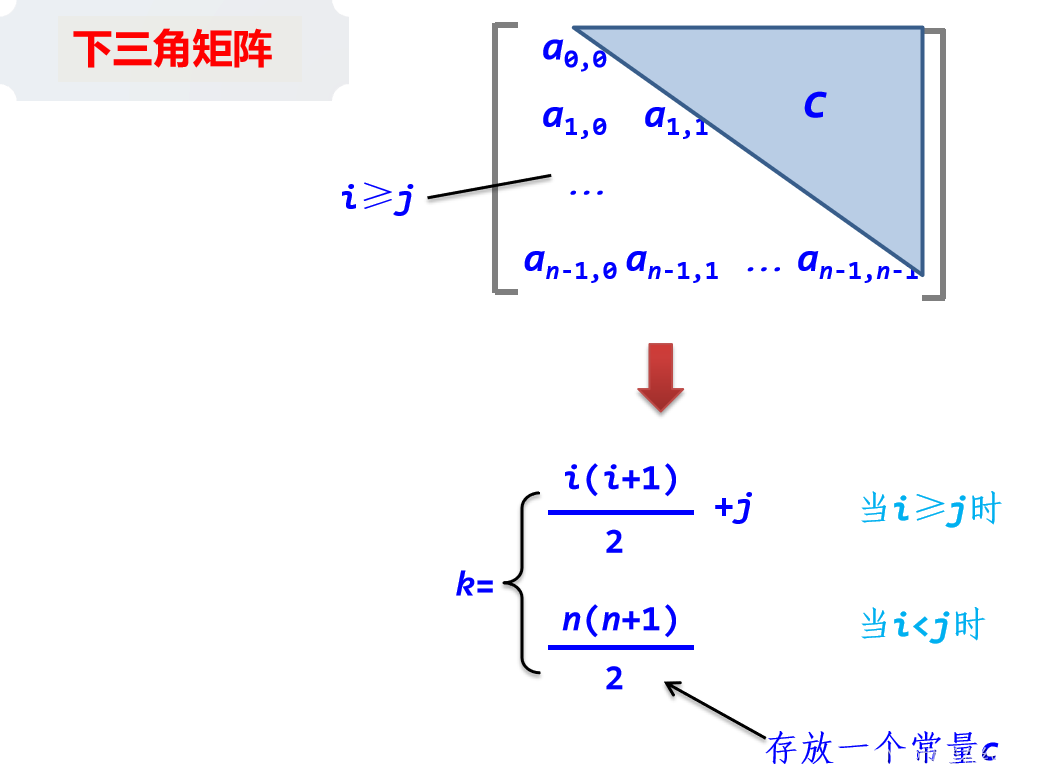
2. 三角矩阵的压缩存储
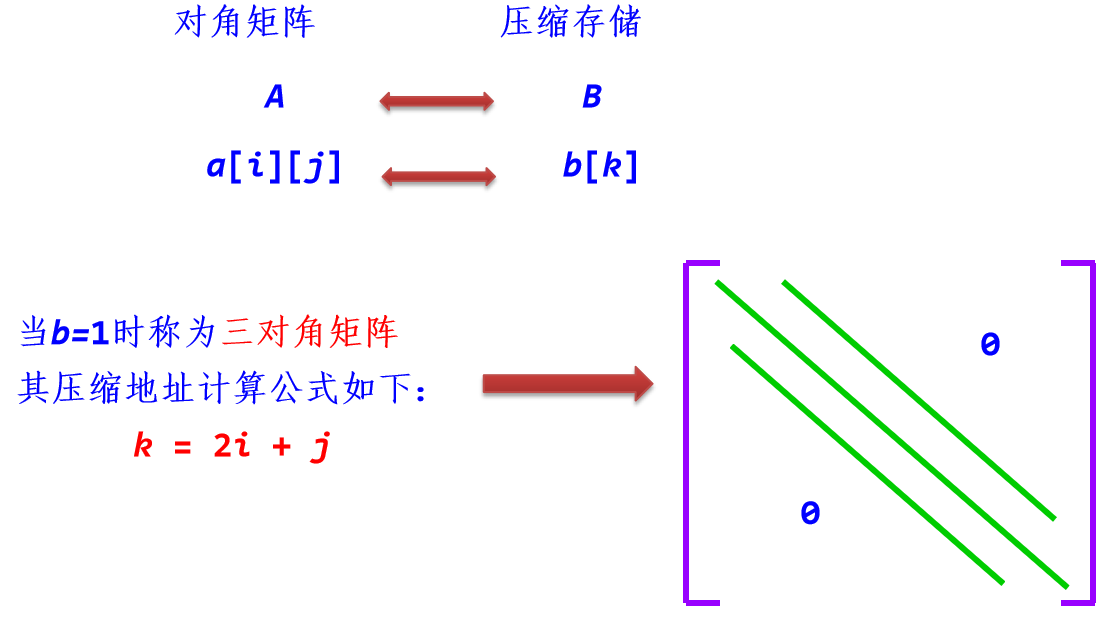
3. 对角矩阵的压缩存储
4.2.3 稀疏矩阵

三元组表示中每个元素的类定义如下:
class TupElem: #三元组元素类
def __init__(self,r1,c1,d1): #构造方法
self.r=r1 #行号
self.c=c1 #列号
self.d=d1 #元素值
设计稀疏矩阵三元组存储结构类TupClass如下:
class TupClass: #三元组表示类
def __init__(self,rs,cs,ns): #构造方法
self.rows=rs #行数
self.cols=cs #列数
self.nums=ns #非零元素个数
self.data=[] #稀疏矩阵对应的三元组顺序表















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









