






 本文介绍了MySQL数据库系统中的数据查询方法,包括select语句、各种运算符(算术、比较、逻辑、位运算)、排序查询、聚合函数如count、sum、avg等,以及分组查询、分页查询和使用insertinto与正则表达式的方法。
本文介绍了MySQL数据库系统中的数据查询方法,包括select语句、各种运算符(算术、比较、逻辑、位运算)、排序查询、聚合函数如count、sum、avg等,以及分组查询、分页查询和使用insertinto与正则表达式的方法。
一.概念
数据库管理系统一个重要功能就是数据查询。数据查询不应是简单返回数据库中存储的数据,还应该根据需要对数据进行筛选以及确定数据以什么样的格式显示。
MySQL提供了功能强大,灵活的语句来实现这些操作。
MySQL数据库使用select语句来查询数据。
二:语法

三:数据准备

四.简单查询

五.运算符
1.简介
数据库中的表结构确立后,表中的数据代表的意义就已经确定。通过MySQL运算符进行运算,就可以获取到表结构以外的另一种数据。
例如。学生表中存在一个birth字段,这个字段表示学生的出生年份。而运用MySQL的算术运算符用当前的年份减学生出生的年份,那么得到的就是这个学生的实际年龄数据。
2.类型
(1)算术运算符

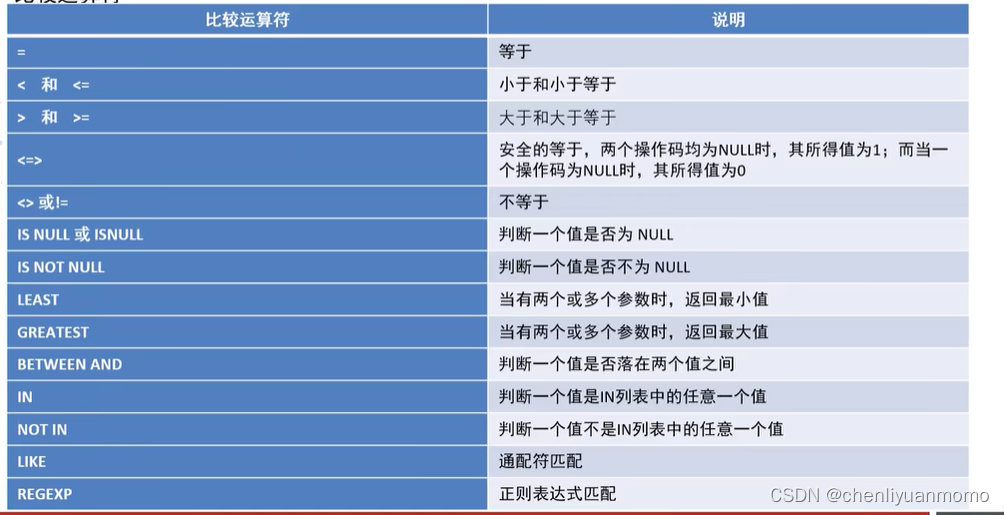
(2)比较运算符
(3)逻辑运算符

(4)位运算符

位运算符是在二进制数上进行计算的运算符。位运算符会先将操作数变成二进制数,进行位运算。然后再将计算结果从二进制数变回十进制数。
六.运算符操作
1.算术运算符

2.条件查询


%用于表示任意字符;'_'匹配单个字符;

如果求最小值时,有个值为null,则不会进行比较,结果直接为null;
如果求最大值时,有个值为null,则不会进行比较,结果直接为null;
3.位运算符
位运算符是在二进制数上进行计算的运算符。位运算符会先将操作数变成二进制数,进行位运算。然后再将计算结果从二进制数变回十进制数。

(1)位与
每一位相比较,都为1,结果才为1
(2)位或
每一位相比较,只要有一个为1,结果就是1(结果为0111,再转化为十进制:7)
(3)位异或
每一位相比较,相同为0,不同为1(结果是0110,转化为十进制:6)
 向右移一位,补零(转化为十进制:1)
向右移一位,补零(转化为十进制:1)
(4)  向左移一位,补零(转化为十进制:6)
向左移一位,补零(转化为十进制:6)
(5) 0变成1,1变成0
0变成1,1变成0
七:排序查询
1.介绍
如果我们需要对读取的数据进行排序,就可以使用MySQL的 order by 子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果
2.语法


3.特点
(1)asc代表升序,desc代表降序,如果不写默认升序
(2)order by 用于子句中可以支持单个字段,多个字段,表达式,函数,别名
(3)order by 子句,放在查询语句的最后面,LIMIT子句除外
八:聚合查询
1.简介
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个单一的值;另外聚合函数会忽略空值。
2.函数

-- 1.查询商品的总个数
select count(pid) from product;
select count(*) from product;
-- 2.查询价格大于200商品的总个数
select count(pid) from product where price > 200;
-- 3.查询分类为'c001'的所有商品总和
select sum(price) from product where category_id = 'c001';
-- 4.查询商品的最大价格
select max(price) from product;
-- 5.查询商品的最小价格
select min(price) from product;
-- 6.查询分类为'c002'所有商品的平均价格
select avg(price) from product where category_id = 'c002';
3.聚合查询对null值的处理
(1)count函数对null值的处理
如果count函数的参数为星号(*)【count(1)也代表全部,与count(*)相同】,则统计所有记录的个数。而如果参数为某字段,不统计含null值的记录个数
(2)sum和avg函数对null值的处理
这两个函数忽略null值的存在,就好像该条记录不存在一样
(3)max和min函数对null值的处理
max和min两个函数同样忽略null值的存在
九:分组查询
1.简介
分组查询是指使用 group by 子句对查询信息进行分组(分组可以根据一个字段,也可以根据多个字段,如果是一个字段,则该字段相同就会分到一组,如果是对公字段,则多个字段都相同才能分到同一组
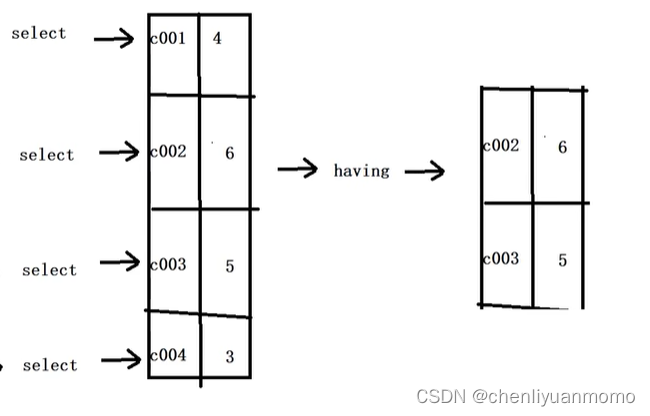
2.操作:统计各个分类商品的个数

如果要进行分组的话,则select字句之后,只能出现分组的字段和统计函数,其他的字段不能出现(分组之后,selete的后面只能写分组字段和聚合函数)

由图可得,先找到表,再group by 分成几个想要的表,再进行count,再筛选想要的字段表示出来
3.分组之后的条件筛选—having
(1)分组之后对统计结果进行筛选的话必须使用having,不能使用where
(2)where子句用来筛选from子句中指定的操作所产生的行
(3)group by 子句用来分组where子句的输出
(4) having子句用来从分组的结果中筛选行
(selete-->from-->where-->group by-->having)

十:分页查询-limit
1.简介
分月查询再项目开发中常见,由于数据量很大,显示屏长度有限,因此对数据需要采取分页显示方式,例如数据共有30条,每页显示5条,第一页显示1-5条,第二页显示6-10条
2.操作

十一:insert into select语句
1.简介:将一张表的数据导入到另一张表中,可以使用insert into select语句
2.格式

十二:正则表达式--regexp
1.介绍
正则表达式描述了一种字符串匹配的规则,正则表达式本身就是一个字符串,使用这个字符串来描述,用来匹配规则,匹配一系列符合某个语法规则的字符串,在开发中,正则表达式通常被用来检索,替换那些符合某个规则的文本。MYSQL通过regexp关键字支持正则表达式进行字符串匹配。
2.格式(符合条件则匹配,结果为1,否则为0)


3.操作
use mydb1;
-- 正则表达式
-- ^在字符串开始处进行匹配
-- 从product表中筛选出pname(商品名称)是以海开头的
-- $在字符串末尾进行匹配
select 'abc' regexp 'a$'; -- 0
select 'abc' regexp 'c$'; -- 1
select * from product where pname regexp '水$';
-- 从product表中筛选出pname(商品名称)是以水结尾的
-- .匹配任意单个字符(除了换行符之外的任意字符)
select 'abc' regexp '.b'; -- 1
select 'abc' regexp '.c'; -- 1
select 'abc' regexp 'a.'; -- 1
-- [...]匹配括号内的任意单个字符
select 'abc' regexp '[xyz]'; -- 0
-- 任意字符是否在前面出现,未出现过为0,xyz未在abc中出现过
select 'abc' regexp '[xaz]'; -- 1
-- [^...]注意^只有在[]内才是取反的意思,在别的地方都是表示开始处匹配
select 'abc' regexp '[^xyz]'; -- 1
-- 任意字符是否在前面出现,未出现过为1,xyz未在abc中出现过
select 'abc' regexp '[^axy]'; -- 0
select 'abc' regexp '[^a]'; -- 1
-- 除了a,还有其他字符,也算
-- a*匹配0个或多个a,包括字符串。可以作为占位字符使用,有没有指定字符都可以匹配到数据
select 'stab' regexp '.ta*b'; -- 1
select 'staaab' regexp '.ta*b'; -- 1
select 'stb' regexp '.ta*b'; -- 1
select '' regexp 'a*'; -- 1
-- a+ 匹配1个或者多个(至少一次),但是不包括空字符串
select 'stab' regexp '.ta+b'; -- 1
select 'stb' regexp '.ta+b'; -- 0
-- a? 匹配0个或者1个a
select 'stb' regexp '.ta?b'; -- 1
select 'stab' regexp '.ta?b'; -- 1
select 'staab' regexp '.ta?b'; -- 0
-- a1|a2 匹配a1或a2都行
select 'a' regexp 'a|b'; -- 1
select 'b' regexp 'a|b'; -- 1
select 'b' regexp '^(a|b)'; -- 1
select 'a' regexp '^(a|b)'; -- 1
select 'c' regexp '^(a|b)'; -- 0
-- 匹配是否以a或b开头
-- a{m} 匹配m个a
select 'auuuuc' regexp 'au{4}c'; -- 1
select 'auuuuc' regexp 'au{3}c'; -- 0
-- a{m,} 匹配m个或者更多个a(至少m个)
select 'auuuuc' regexp 'au{3,}c'; -- 1
select 'auuuuc' regexp 'au{4,}c'; -- 1
select 'auuuuc' regexp 'au{5,}c'; -- 0
-- a{m,n} 匹配m到n个a,包含m和n
select 'auuuuc' regexp 'au{3,5}c'; -- 1
select 'auuuuc' regexp 'au{4,5}c'; -- 1
select 'auuuuc' regexp 'au{5,10}c'; -- 0
-- (abc) abc作为一个序列匹配,不用括号括起来都是用单个字符去匹配,如果要把多个字符作为一个整体去匹配就需要用到括号,所以括号适合上面的所有情况
select 'xababy' regexp 'x(abab)y'; -- 1
select 'xababy' regexp 'x(ab)*y'; -- 1
-- 匹配0个或多个ab
select 'xababy' regexp 'x(ab){1,2}y'; -- 1
-- 匹配1到2个ab
select 'xababy' regexp 'x(ab){3}y'; -- 0
其他注意事项:
(1)书写顺序:select-->from-->where-->group by-->having-->order by-->limit
(2)执行顺序:from-->where-->group by-->count(*)-->having-->select-->order by-->limit
(3)ifnull(comm,0) 如果comm的值为null,则当作0,不为null,则还是原来的值















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









