







哈夫曼树
你要了解的基本概念
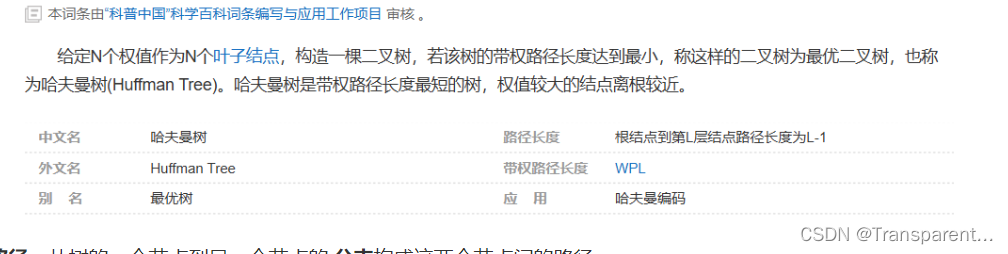
路径:从树的一个节点到另一个节点的 分支构成这两个节点间的路径
节点的路径长度:两个节点间的分支数
数的路径长度:从根节点到各个节点的路径长度之和
一般来说:节点数目相同的二叉树中,完全二叉树的路径长度是最短的
权:树中某个节点被赋值一个某种意义的数值,该数值就是该节点的权
(WPL)带权路径长度
节点的带权路径长度:从根节点到该节点的 路径长度与该节点的权的乘积
树的带权路径长度:节点的带权路径长度之和
eg:满二叉树不一定是哈夫曼树。权值越大的节点越靠近根。
要如何构造哈夫曼树
构造方式
构造哈夫曼树可以使用顺序存储和链式存储
这里我使用的顺序存储结构,也就是一个结构体数组来实现哈夫曼树
结构体的代码如下:
typedef struct Node{
int weight; // 权重
int parent; //双亲节点
int lch; //左孩子
int rch; //右孩子
//可以 在添加元素来作为数据保存
//Elem data;
}Node;
构造过程
构造哈夫曼树的过程可以有几句口诀记忆:
1.构造森林全是根
2.选用两小造新树
3.删除两小添新人
4.重复2,3剩单树
由于具有n个元素的二叉树每次要经过n-1次的合并,才能构成哈夫曼树
而却每次构成的新节点都是度为2 的节点
所有n个元素的哈夫曼树有2n-1个节点
节点只包括度 为0 或 2 的节点
//构造哈夫曼树
void createHuffmanTree(Node* huffmanTree, int n){
// m为 哈夫曼树的总节点树
int m = (2*n)-1;
//为了美观,数组的下标从1开始
huffmanTree = (Node*)malloc(sizeof(Node)*m+1);
//
for(int i = 1; i <= m ; i++){
huffmanTree[i].lch = 0;
huffmanTree[i].parent = 0;
huffmanTree[i].rch = 0;
}
//接受从控制台上输入的权重
for(int i = 1; i <= n; i++){
scanf("%d",&(huffmanTree[i].weight));
}
//开始构造哈夫曼树
/* TODO (#1#): 1.将每个有权重的节点看作是一个森林,都是根节点
2.在权重中选择最小 的两个进行 联系,添加一个新 的双亲节点
3.改变对应的元素(lch,rch,parent,weight)在下次寻找最下值时,不重复
4.重复2,3直到只有一颗树
*/
int min1,min2;
for(int i = n+1; i <= m; i++){
select(huffmanTree,&min1,&min2,i-1);
huffmanTree[min1].parent = i;
huffmanTree[min2].parent = i;
huffmanTree[i].lch = min1;
huffmanTree[i].rch = min2;
huffmanTree[i].weight = huffmanTree[min1].weight + huffmanTree[min2].weight;
}
}
select函数(找出最小和次小)
//找出结构数组中权重最最小和次小的数对于的数组下标
void select(Node* t,int* min1,int* min2,int l){
for(int i = 1; i <= l; i++){
if(t[i].parent == 0){
(*min1) = i;
break;
}
}
for(int i = 1; i <= l; i++){
if(t[i].parent == 0 && (*min1) != i && t[i].weight < t[(*min1)].weight){
(*min1) = i;
}
}
for(int i = 1; i <= l; i++){
if(t[i].parent == 0 && i != (*min1)){
(*min2) = i;
break;
}
}
for(int i = 1; i <= l; i++){
if(t[i].parent == 0 && t[i].weight < t[(*min2)].weight){
if((*min1) == i){
continue;
}
(*min2) = i;
}
}
}
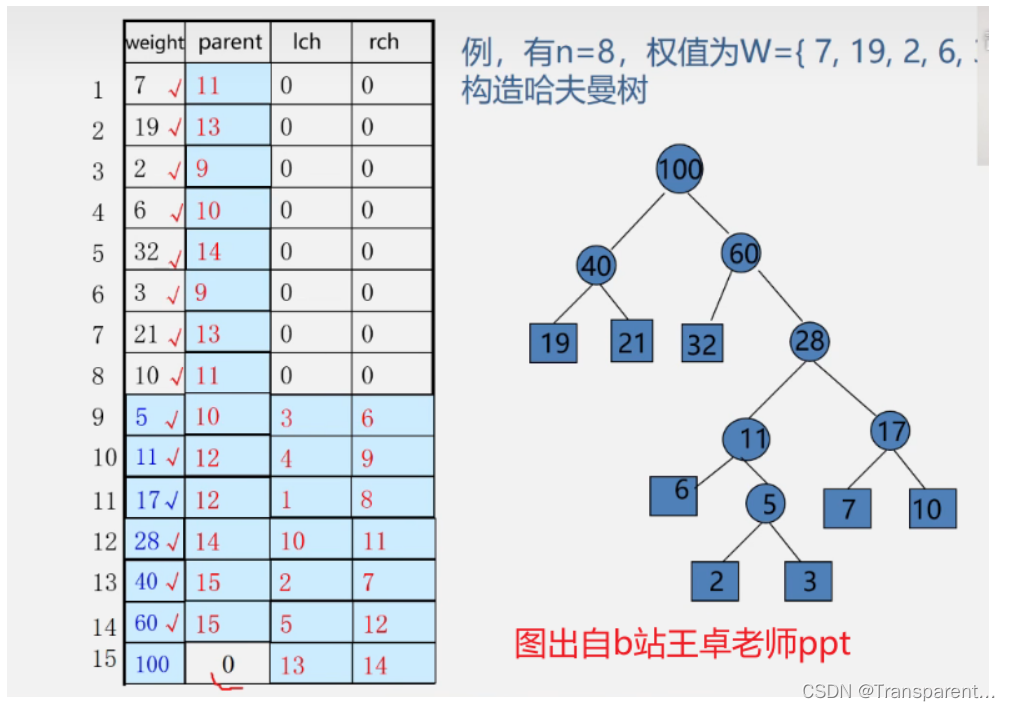
实现效果
int main(void){
//使用结构数组
Node *huffmanTree;
//n是有权重 的节点的数量
int n = 8;
createHuffmanTree(huffmanTree,n);
free(huffmanTree);
return 0;
}
哈夫曼编码
初识
在将文件转为二进制文件,如果不是使用哈夫曼编码,比如个每个字符特定相同的二进制来表述很容易造成内存的浪费
还有其他,假设使用自定义编码有可能发生重码
要避免的关键在于:要设计一种长度不同,而且任意一个编码不是另一个编码的前缀
什么编码符合这个,或哪一个编码是前缀编码?
哈夫曼编码

什么样的编码可以是文件的二进制总长最小呢?
哈夫曼编码
例如,在英文中,e的出现概率最高,而z的出现概率则最低。当利用霍夫曼编码对一篇英文文章进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节,即8个比特。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
How can do that
首先是统计文件字符各自的概率(概率越高,要求编码的长度越短)
通过哈夫曼树的性质我们知道,权值越大的节点离根节点越近,将每个字符的概率为权值,概率越大的路径越短
最后通过左分支为1,右分支为0作为编码,从根节点带该目标节点的分支排序表示每个字符
为什么哈夫曼编码能保证是前缀编码?
哈夫曼编码的字符都 处于叶子节点,而没有路径相同的两个叶子节点
就好像是没有完全相同 的两片叶子
为什么哈夫曼编码能保证字符编码总长度最短?
在哈夫曼树的构建过程中就保证了频率较高的分支数小于频率低的
哈夫曼树做到了树的路径上的带权路径和的最小
算法实现
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <string.h>
typedef struct Node {
int weight; // 权重
int parent; //双亲节点
int lch; //左孩子
int rch; //右孩子
} Node;
typedef struct NodeCode {
char chr;
int node;
char* code;
} NodeCode;
//找出结构数组中权重最最小和次小的数对应的数组下标
void select(Node* t, int* min1, int* min2, int l) {
for (int i = 1; i <= l; i++) {
if (t[i].parent == 0) {
(*min1) = i;
break;
}
}
for (int i = 1; i <= l; i++) {
if (t[i].parent == 0 && (*min1) != i && t[i].weight < t[(*min1)].weight) {
(*min1) = i;
}
}
for (int i = 1; i <= l; i++) {
if (t[i].parent == 0 && i != (*min1)) {
(*min2) = i;
break;
}
}
for (int i = 1; i <= l; i++) {
if (t[i].parent == 0 && t[i].weight < t[(*min2)].weight) {
if ((*min1) == i) {
continue;
}
(*min2) = i;
}
}
}
//将对应的编码写入NodeCode中
void CreateHuffmanCode(Node* huffmanTree, NodeCode* hc, int n) {
if (huffmanTree == NULL) {
printf("huffmanTree is NULL\n");
return;
}
//分配 n个字符的 头指针
char* cd = (char*)malloc(n * sizeof(char));
//编码结束符
cd[n - 1] = '\0';
for (int i = 1; i <= n; i++) {
int start = n - 1;
int c = i;
int f = huffmanTree[c].parent;
while (f != 0) {
--start;
if (huffmanTree[f].lch == c) {
cd[start] = '0';
}
else {
cd[start] = '1';
}
c = f;
f = huffmanTree[f].parent;
}
hc[i].code = (char*)malloc((n - start) * sizeof(char));
strcpy(hc[i].code, &cd[start]);
}
free(cd);
printf("char\tcode\n");
for (int i = 1; i <= n; i++) {
printf("%c\t%s\n", hc[i].chr, hc[i].code);
}
}
//构造哈夫曼树
void createHuffmanTree(Node** huffmanTree, int n) {
// m为 哈夫曼树的总节点数
int m = (2 * n) - 1;
//为了美观,数组的下标从1开始
*huffmanTree = (Node*)malloc((m + 1) * sizeof(Node));
for (int i = 1; i <= m; i++) {
(*huffmanTree)[i].lch = 0;
(*huffmanTree)[i].parent = 0;
(*huffmanTree)[i].rch = 0;
}
//接受从控制台上输入的权重
for (int i = 1; i <= n; i++) {
scanf("%d", &((*huffmanTree)[i].weight));
}
//开始构造哈夫曼树
int min1, min2;
for (int i = n + 1; i <= m; i++) {
select(*huffmanTree, &min1, &min2, i - 1);
(*huffmanTree)[min1].parent = i;
(*huffmanTree)[min2].parent = i;
(*huffmanTree)[i].lch = min1;
(*huffmanTree)[i].rch = min2;
(*huffmanTree)[i].weight = (*huffmanTree)[min1].weight + (*huffmanTree)[min2].weight;
}
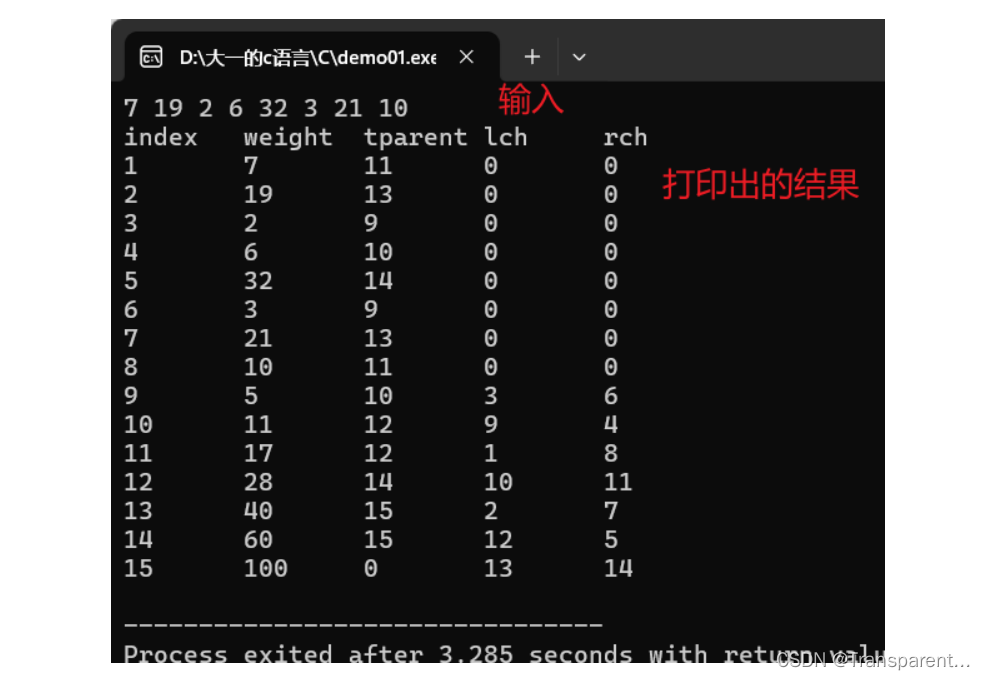
printf("index\tweight\tparent\tlch\trch\n");
for (int i = 1; i <= m; i++) {
printf("%d\t%d\t%d\t%d\t%d\n", i, (*huffmanTree)[i].weight, (*huffmanTree)[i].parent, (*huffmanTree)[i].lch, (*huffmanTree)[i].rch);
}
NodeCode* hc = (NodeCode*)malloc((n + 1) * sizeof(NodeCode));
for (int i = 1; i <= n; i++) {
hc[i].node = i;
hc[i].code = NULL;
}
hc[1].chr = 'A';
hc[2].chr = 'B';
hc[3].chr = 'C';
CreateHuffmanCode(*huffmanTree, hc, n);
for (int i = 1; i <= n; i++) {
free(hc[i].code);
}
free(hc);
}
int main(void) {
Node* huffmanTree = NULL;
int n = 3;
//在 createHuffmanTree 函数中,huffmanTree 是局部变量,您在函数内分配内存,但它在函数返回后不会影响主函数中的指针。这可以通过传递指针的指针来解决。
createHuffmanTree(&huffmanTree, n);
free(huffmanTree);
return 0;
}
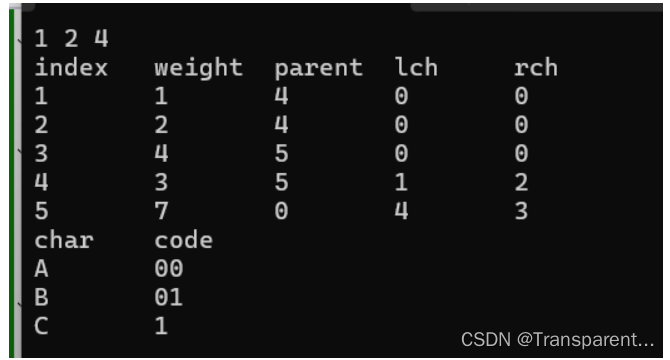
结果成功 A 对应 的哈夫曼编码为00,b…
加密实现
将输入的字符与哈夫曼字符表中的字符比较,得到对应的哈夫曼编码
//将字符转成对应的哈夫曼编码
void encrypted(NodeCode* hc,char* arr,int m) {
int n = strlen(arr);
printf("加密完成:");
for (int i = 0; i < n; i++) {
for (int j = 1; j <= n; j++) {
if (hc[j].chr == arr[i]) {
int c = strlen(hc[j].code);
for (int k = 0; k < c; k++) {
printf("%c",hc[j].code[k]);
}
}
}
}
}
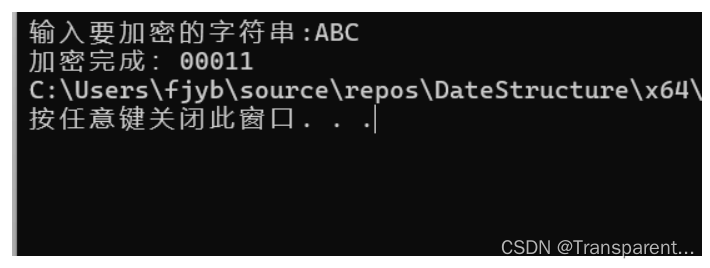
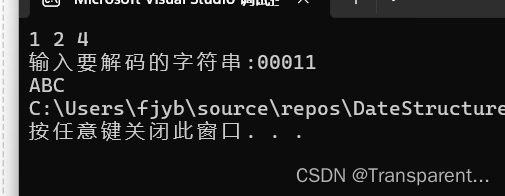
解码算法实现
//将哈夫曼编码解码成对应的字符
void decoder(Node* huffmanTree, NodeCode* hc, char* arr,int m) {
int n = strlen(arr);
int index = 2 * m - 1;
for (int i = 0; i < n; i++) {
if (arr[i] == '0') {
index = huffmanTree[index].lch;
}
else {
index = huffmanTree[index].rch;
}
if (huffmanTree[index].lch == 0 && huffmanTree[index].rch == 0) {
printf("%c", hc[index].chr);
index = 2 * m - 1;
}
}
}















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









