







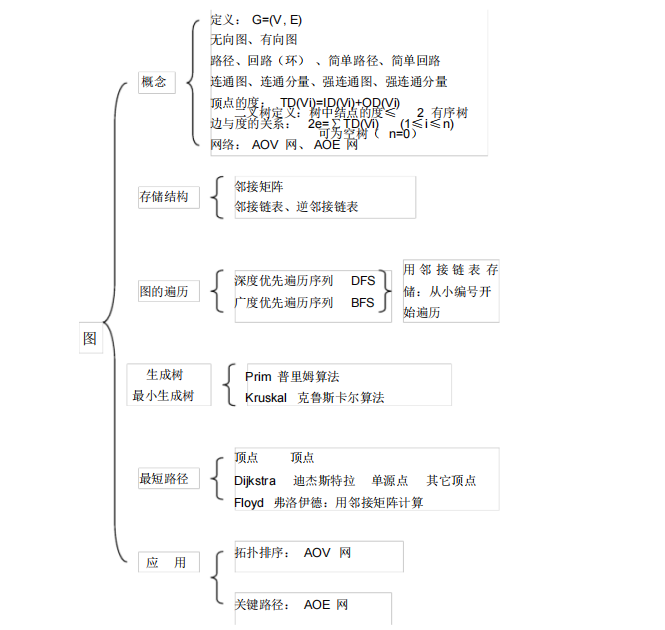
知识大概导图
什么是图?
维基百科是这样定义的,好难理解,放心,我想你已经学习过树了,其实树这种数据结构是一种特殊的图,树可以是说满足一定条件的 图(当图中只有一个顶点的出度为0其余顶点的出度为1)不必为不懂的概念纠结,接着看下去
图的定义是G(V,E) 全称是graph(Vertes,Edge)
V是顶点表有穷非空的集合
E是是边表有穷集合
这里很好理解,一个图就是有多个顶点和多条边

图的一些基本概念(了解)
首先是图的分类:有无向图,有向图 ,完全图 ,稀疏图,稠密图,网,完全图,连通图,连通分量…(好多,难受)不 慌,听我细细道来
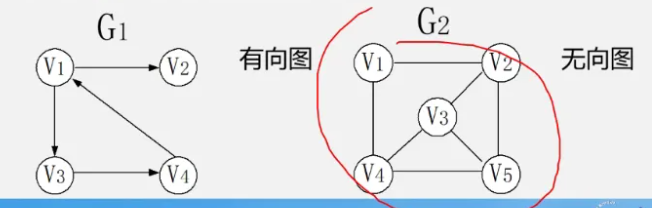
无向图就是边没有指定从那个顶点到另外一个顶点的图,简单来说就是边没有带箭头!
有向图就与无向图相反(有方向),边是指定了到达顶点的,有出度和入度的概念
度:度即使与该顶点链接的边的数量,出度是从该顶点出去,入度是进入该顶点
那么网又是什么,网是边带有权值的图,在我们学习过的哈夫曼树中就有权值的概念,忘了的话可以看我之前的讲解(https://blog.csdn.net/2301_80640266/article/details/139813029?spm=1001.2014.3001.5502) 可以把带有权值的图看作网,为啥要有带权值的边呢?
可以把权值看作两个顶点的距离,时间,等等,在日常中的使用非常广泛
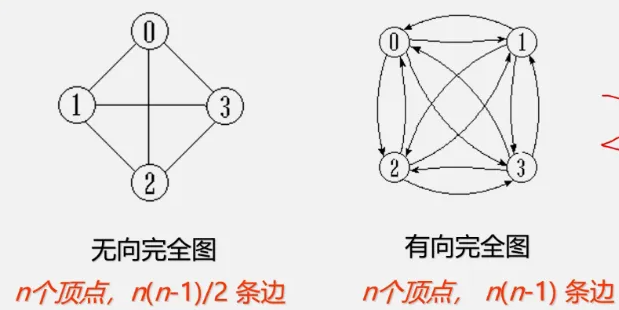
完全图:任意两个顶点都有边
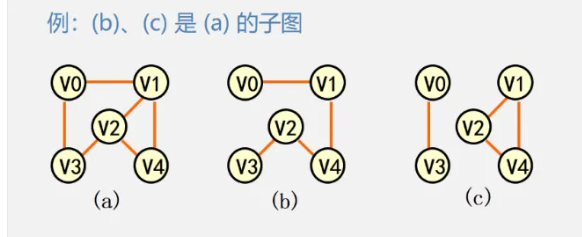
子图:子图 的 V和E中的任意成员都可以在其父图中的V和E中找到
连通图:连通图指的是任意两个顶点间都有一条 可以连通的路径
相关概念辨析:强连通图:相对有向图来说,极大连通子图:无法找到任意一个不 在其子图上,在父图中 的顶点添加到该子图并使其连通,极小连通子图:删除该子图中的任意顶点都不能使该子图连通 ,生成树:包含该图所有顶点的极小连通子图,生成森林 :对非连通图,该图的来连通分量的生成树的集合
什么是连通分量?其实就是**极大连通子图,**强连通分量是对有向图的 。
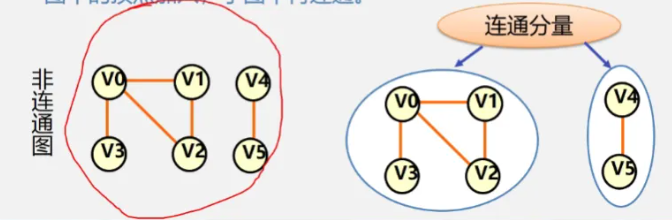
稀疏图:边的数量很少的图(e < nlogn)
稠密图:边的数量多
路径:一个顶点到另一个顶点的 边的连线
路径之和是该边的数量或边上权值的和
简单路径:除开始顶点和结束顶点可以相同,其余经过的顶点不可相同
回路:开始顶点和结束顶点相同
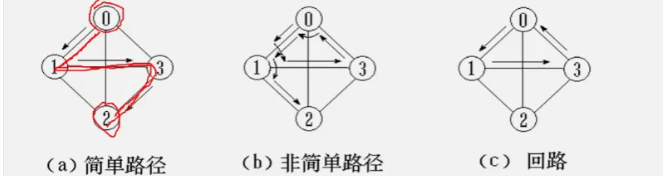
关系概念
顶点与顶点之间是邻接
顶点和边是依附
图的存储结构
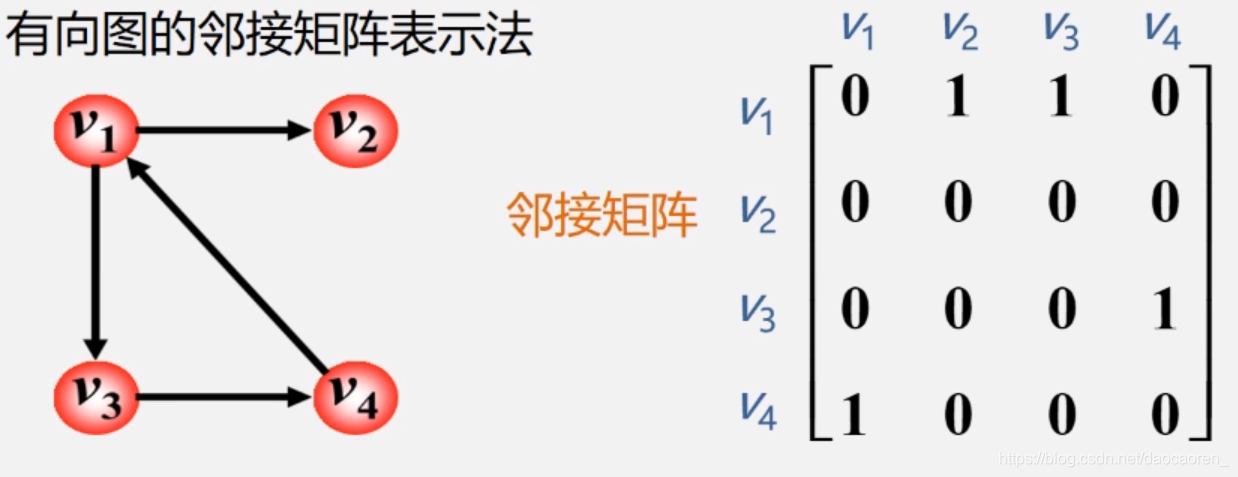
邻接矩阵
图是多对多的关系,我们通过一个二维数组来 实现元素间的关系,还有一个一维数组来记录顶点表

在无向图的邻接 矩阵中有以下特点
- 是对称矩阵
- 完全图的矩阵除对角线外全是1
- 第i行(列)的和是该顶点的 度
在无向图的邻接 矩阵中有以下特点
- 是非对称的
- 第i行的和是该顶点出度
- 第i列是该顶点的入度
- 该顶点的度就是上述之和
C语言代码表示
#define MVNum 100 //最大的顶点数
typedef char VerTexType; //设顶点的数据类型为字符型
typedef int ArcType; //边的权重类型为整型
typedef struct {
VerTexType vexs[MVNum]; //顶点表
ArcType arcs[MVNum][MVNum]; //邻接矩阵
int vexnum, arcnum; //图的点数和边数
}AMGraph;
我们实现一个通用的无向网来理解邻接矩阵的原理,以及他是如何存储的
可以很简单的从无向网更改些代码来实现无向图,有向 图等…

代码的算法实现流程
1.输入顶点数和边数
2.输入顶点信息,初始化顶点表
3.初始化邻接数组,值为-1(这里也可以是无穷符号看具体业务)
4.构造邻接矩阵
代码实现
void CreateGraph(AMGraph *G) {
//1.
G = (AMGraph*)malloc(sizeof(AMGraph));
printf("输入顶点数:");
scanf("%d", &(G->vexnum));
getchar();
printf("输入边数:");
scanf("%d", &(G->arcnum));
getchar();
//2.
for (int i = 0; i < G->vexnum; i++) {
printf("输入%d个顶点的值:", i + 1);
scanf("%c", &(G->vexs[i]));
getchar();
}
//3.
for (int i = 0; i < G->vexnum; i++) {
for (int j = 0; j < G->vexnum; j++) {
G->arcs[i][j] = MaxInt;
}
}
//开始构造邻接矩阵
for (int i = 0; i < G->arcnum; i++) {
printf("输入V1--V2 和 边的权重:");
char V1 = '0', V2 = '0';
int W = 0;
scanf("%c %c %d", &V1, &V2, &W);
getchar();
//查询出对应顶点值的在顶点表 的坐标
int i = locate(&(G->vexs), V1, G->vexnum);
int j = locate(&(G->vexs), V2, G->vexnum);
//无向网是对称的矩阵
G->arcs[i][j] = W;
G->arcs[j][i] = W;
}
showGraph(G);
}
辅助函数的 分析
showGraph()
将顶点表和矩阵形象化打印
void showGraph(AMGraph* g) {
//printf顶点表
for (int i = 0; i < g->vexnum; i++) {
printf("%d-%c ", i, g->vexs[i]);
}
printf("\n-------------------\n");
//printf出这个图的邻接矩阵
for (int i = 0; i < g->vexnum; i++) {
for (int j = 0; j < g->vexnum; j++) {
printf("%d ", g->arcs[i][j]);
}
printf("\n");
}
}
locate(VerTexType* arr, VerTexType n, int l)
找到对应顶点在顶点表中的位置
int locate(VerTexType* arr, VerTexType n, int l) {
int index = -1;
for (int i = 0; i < l; i++) {
if (arr[i] == n) {
index = i;
}
}
return index;
}
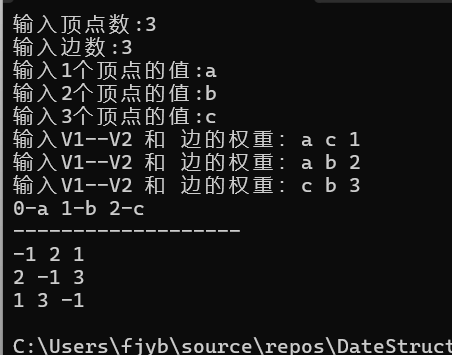
测试结果:
邻接矩阵的优缺点:
优点:简单明了,适合稠密表,便于查看顶点与边的关系,容易计算度
缺点:难以删除和修改,对应稀疏图来说浪费空间,在查找边,浪费时间
邻接表
链式的存储,通过在顶点表(一维结构数组)中一个指针域,每个头顶点都是链表的头节点
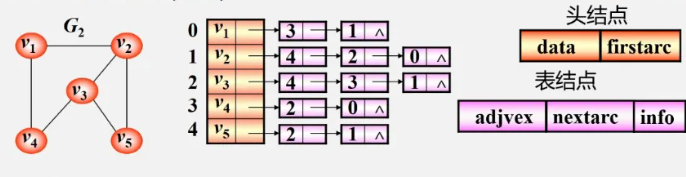
邻接表的代码结构
/*
邻接表的实现
*/
//边表的定义
typedef struct ArcNode { //边节点
int adjvex; // 该 边所指向的顶点的位置
OtherInfo info; //和边相关的信息
struct ArcNode* nextarc; //指向下一条边的指针
}ArcNode;
//顶点表的定义
typedef struct VNode {
VerTexType data; //顶点信息
ArcNode* firstarc; //指向第一条关联该节点的指针
}VNode,AdList[MVNum];
//图的结构定义
typedef struct {
AdList vertices; //存储顶点的一维数组
int vexnum, arcnum; //图的信息
}ALGraph;
算法实现流程
1.输入总项数,和总边数
2.建立顶点表
2.1依次输入点的信息存入顶点表中
2.2初始化每个头顶点的指针域为NULL
3.创建邻接表
3.1输入边所关联的两个顶点
3.2获取顶点的下标,建立边节点
3.3使用头插法来插入到顶点指针域
代码实现
void createGraph(ALGraph** G) {
printf("输入顶点数:");
scanf("%d", &((*G)->vexnum));
getchar();
printf("输入边数:");
scanf("%d", &((*G)->arcnum));
getchar();
for (int i = 0; i < (*G)->vexnum; i++) {
printf("输入节点的值:");
scanf("%c", &((*G)->vertices[i].data));
getchar();
(*G)->vertices[i].firstarc = NULL;
}
for (int i = 0; i < (*G)->arcnum; i++) {
printf("输入边对应的顶点和权重(eg:V1 V2 W):");
char V1, V2;
int W;
scanf("%c %c %d",&V1,&V2,&W);
getchar();
int i = locate(*(*G), V1);
int j = locate(*(*G), V2);
ArcNode* edgeNode1 = (ArcNode*)malloc(sizeof(ArcNode));
ArcNode* edgeNode2 = (ArcNode*)malloc(sizeof(ArcNode));
headInsert(G, edgeNode1, i, j,W);
headInsert(G, edgeNode2, j, i,W);
}
showAdList(G);
}
其他函数:
//查找对应的下标
int locate(ALGraph g, char u) {
int index = -1;
for (int i = 0; i < g.vexnum; i++) {
if (g.vertices[i].data == u) {
index = i;
}
}
return index;
}
void headInsert(ALGraph** g, ArcNode* f, int i, int j,int w) {
if ((*g)->vertices[i].firstarc == NULL) {
(*g)->vertices[i].firstarc = f;
f->nextarc = NULL;
}
else {
ArcNode* temp = (*g)->vertices[i].firstarc;
(*g)->vertices[i].firstarc = f;
f->nextarc = temp;
}
f->adjvex = j;
f->info = w;
}
//显示邻接表
void showAdList(ALGraph** g) {
for (int i = 0; i < (*g)->vexnum; i++) {
printf("头顶点:%d-%c ->", i,(*g)->vertices[i].data);
ArcNode* temp = (*g)->vertices[i].firstarc;
while (temp != NULL) {
printf("%d-%d->", temp->adjvex, temp->info);
temp = temp->nextarc;
}
printf("NULL\n");
}
}
最后的代码运行结果:
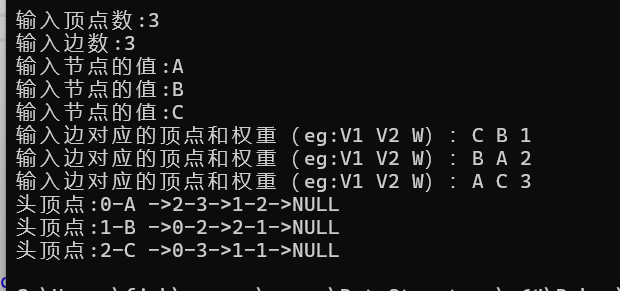
邻接表的pros and cons
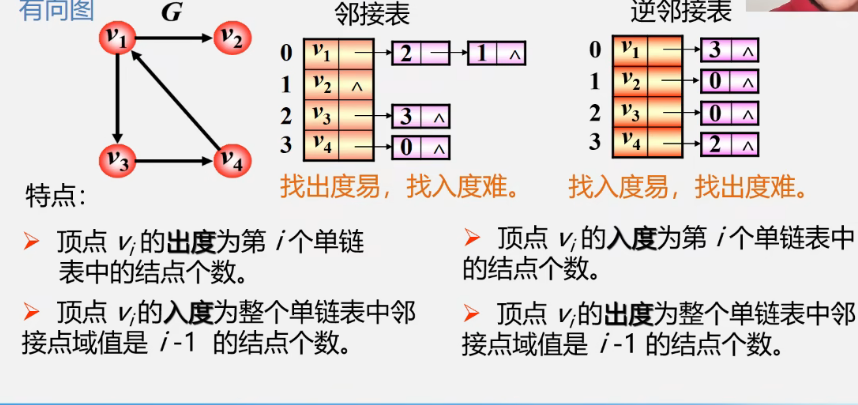
相比与邻接矩阵,邻接表相对于节省空间,同时不能够直接的看到任意两个顶点是否存在边,没有邻接矩阵直观,在邻接矩阵中每个下标是固定的,而在邻接表不是唯一的
在邻接表中每一个顶点链表对应邻接矩阵的每一行
在 邻接矩阵中空间复杂度是O(n^2),在 邻接表中是O(n+e)















 2190
2190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









