






k8s是什么?
简单来说,k8s是用于自动部署、扩缩和管理容器化应用程序的开源系统。
Kubernetes,简称K8s,它是一个全新的基于容器技术的分布式架构领先方案,确切地说,Kubernetes是谷歌严格保密十几年的秘密武器Borg的一个开源版本。
Borg是谷歌内部使用的大规模集群管理系统,负责对谷歌内部很多核心服务的调度和管理*,它基于容器技术,目的是实现资源管理的自动化,以及跨多个数据中心的资源利用率的最大化。
k8s与Docker有什么关系?
在Kubernetes(简称K8s)与Docker之间,存在一种互补和依赖的关系:
(来源:https://home.cnblogs.com/u/huangjiabobk黄嘉波博客)
互补关系:
Docker:提供容器化解决方案,允许开发人员将应用及其依赖打包到可移植的容器镜像中。Docker主要负责构建、运行和分发这些容器。
Kubernetes:是一个容器编排系统,它的目标是自动化部署、扩展以及管理容器化的应用程序。Kubernetes并不直接创建或管理容器镜像,而是负责调度多个容器在集群内的运行,并为它们提供服务发现、负载均衡、自动伸缩等高级功能。
依赖关系:
在早期的Kubernetes版本中,Docker是默认的容器运行时环境。这意味着当在Kubernetes上部署容器时,会使用Docker引擎来启动和运行容器。
随着时间的发展,尽管Kubernetes不再硬性要求必须使用Docker作为唯一的容器运行时,但它仍然可以与Docker以及其他符合OCI(Open Container Initiative)标准的容器运行时(如containerd、rkt等)配合工作。
综上所述,在现代云原生技术栈中,Docker通常被用于构建和推送容器镜像到仓库,而Kubernetes则作为一个更高级别的平台,负责管理和协调这些容器在生产环境中的生命周期和行为。两者共同促进了微服务架构和云原生应用的落地和发展。
为什么用k8s?K8s有什么优势?
单独使用容器的问题:
-
宿主机无法自动恢复
-
程序级的健康检查不到位
-
程序扩容、部署、回滚和更新依旧不够灵活
-
端口问题并未得到解决
k8s带来的优势:
-
轻松管理成千上万的业务容器(通过yaml或json文 件)
-
全自动容灾机制
-
全自动扩容、回滚
-
支持原生的服务发现和负载均衡(通过service实现)
-
更加灵活的健康检查(端口检测、进程检测,配置策 略)
K8S架构
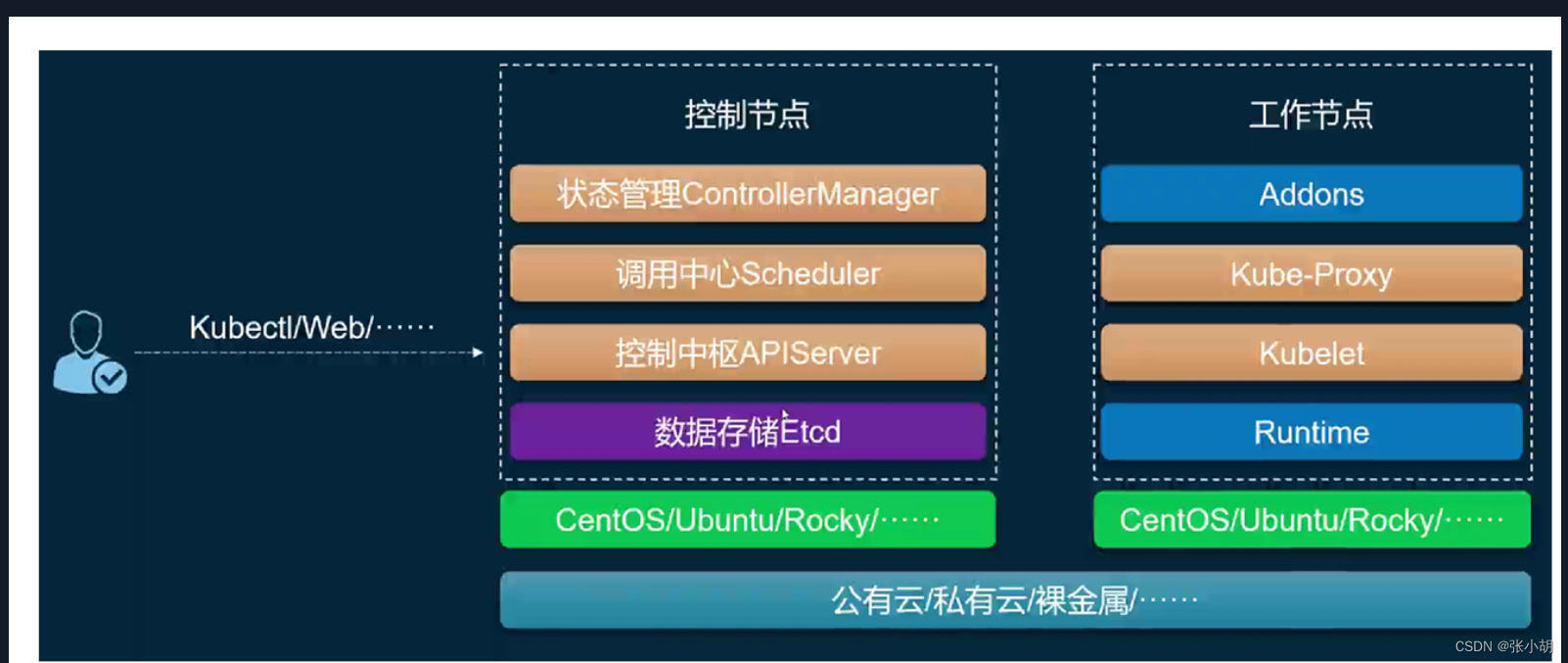
控制节点也可以作为工作节点来用的。
一切皆为资源。
master控制节点
整个集群的控制中枢。
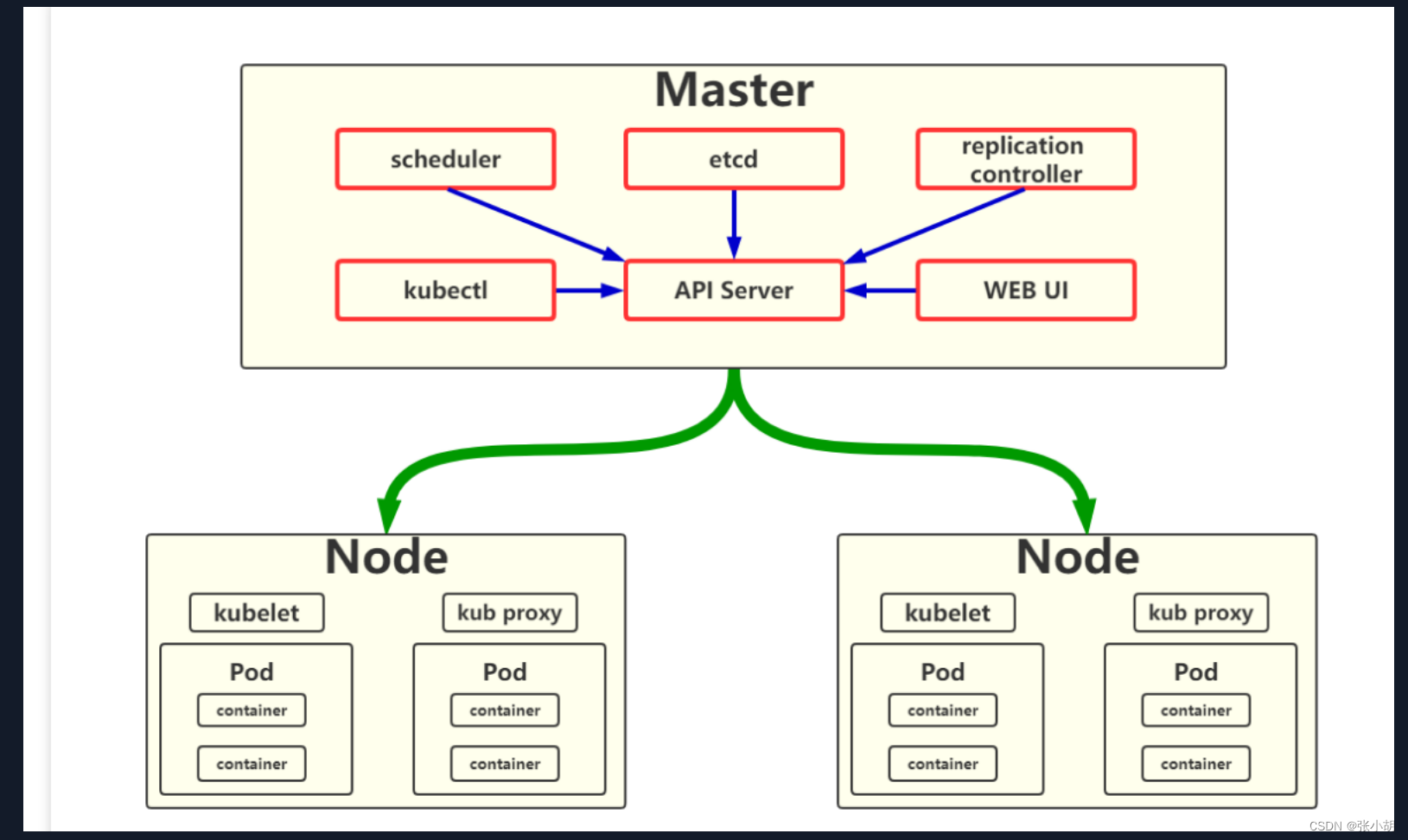
1.API Server:
API Server: 应用程序编程接口: 所有服务访问的同一入口。
【通俗地讲,通信都得经过API server】
集群控制中枢,各个模块间信息交 互需要经过Kube-APIServer,同时他也是集群管理、 资源配置、整个集群安全机制的入口。
常用命令:
查看接口:kubectl api- resources |grep xxx
例:kubectl api- resources |grep job
2.Controller Manager:
控制器管理器:负责监控维护集群状态 常规任务的后台线程;
集群的状态管理器,保证Pod 或其他资源达到期望值,也是需要和APIServer进行 通信,在需要时候创建、更新或删除它所管理的资源。
Controller Manager 负责管理 Kubernetes 集群中的所有资源,包括 Pod、ReplicaSet、Deployment、Service 等。
3. Scheduler:
调度器;
集群的调度中心,它会根据指定一系列条 件,选择一个或一批最佳的节点,然后部署我们的 Pod;即:当运行了一个新的Pod之后,调度器会根据用户需求及node节点情况选择合适的node节点运行pod;
4.Etcd:
键值数据库,保存一切集群的信息,生产环境中 建议部署3个以上节点(奇数个)
保存一切集群的配置信息、状态信息以及元数据,
这包括但不限于:
* 集群的配置:如API对象(Pod、Service、ConfigMap、Secret等)的状态和配置。
* 节点信息:包括节点的状态和标识。
* Pod和服务的状态:记录了集群中各个Pod和服务的当前状态。
* 配置文件和网络信息:集群运行所需的配置文件和网络设置。
worker工作节点
1.kubelet:
负责接收master节点上API server指令,并在node节点上执行;
负责监听节点上的Pod的状态,同时上报节 点和节点上面Pod的状态,负责和Master节点通信, 并管理节点上面的Pod。
2.kube-proxy:
负责Pod之间的通信和负载均衡,将指 定的流量分发到正确的机器上。
查看Kube-proxy工 作模式:curl 127.0.0.1:10249/proxyMode
ipvs模式
iptables模式
master和node集群间通信
Kubernetes 集群通过 Master 节点和 Node 节点之间的通信来工作。Master 节点通过 API Server 向 Node 节点发送指令,Node 节点通过 Kubelet 执行这些指令
k8s的安装方式有哪些?
官方显示有28种,但最常用的是下面几种:
1.二进制方式安装:
直接下载、部署二进制文件来安装Kubernetes。
优点:二进制安装便于熟悉k8s的各个组件,对学习k8s是有好处的; 便于排错;
缺点:安装比较费劲;
2.kubeadm方式安装:
是官方提供的用于快速安装k8s集群的工具,将k8s的各个组件都安装在docker之上,以容器的方式运行。
3.minikube:
作为单机运行的Kubernetes集群,直接使用官网感受一下,点击launch terminal,浏览器下发会弹出命令界面。
4.yum安装 优点:安装快速; 缺点:所有软件的依赖不能自己指定;不易排错;
CNI网络插件
CNI(Container Network Interface)网络插件作为Kubernetes集群中网络管理的关键组成部分,扮演着连接和管理容器网络的重要角色.
常用网络组件
1.CRI:容器进行时接口
-
连接容器引擎docker、containerd、cri-o、podman
-
2.CNI:容器网络接口,
-
用于连接网络插件如:flannel、calico、cilium
-
3.CSI:容器存储接口,
-
如nfs、ceph、gfs、oss、s3、minio
k8s中数据持久化
为什么要数据持久化?
容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失——容器以干净的状态(镜像最初的状态)重新启动。其次,在Pod 中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes 中的 Volume 抽象就很好的解决了这些问题。
我们可以用K8s volume来持久化保存容器的数据,Volume的生命周期独立于容器,Pod中的容器可能被销毁重建,但Volume会被保留。
数据持久化的方式
一、持久卷PV(Persistent Volumes):*
持久卷是一种独立于Pod的存储资源,可以在Pod之间共享和重用。它们可以由管理员预先配置,并通过PersistentVolumeClaim(PVC) 与Pod进行绑定,持久卷可以使用多种后端存储技术实现,如本地存储、网络存储(NFS、SCSI等)或云提供商的存储服务(如AWS EBS、Azure Disk等)。
持久卷声明(PVC)(PersistentVolumeClaim):
持久卷声明是对持久卷的请求,它定义了Pod对存储资源的需求。Pod可以通过声明一个持久卷声明来请求一个或多个持久卷,并将其绑定到Pod中的容器。
如何更好的理解PV PVC?
在整个k8s集群中,有些存储资源,如NFS、CIFS等,都由存储工程师创建,不同存储方式不同, 如果都掌握才可使用,则很不方便
所以在k8s中提供了新的对象资源叫PV(Persistent Volume)和PVC(Persistent Volume Claim),更方便用户直接进行使用
什么是PV 持久卷(Persistent Volume)
是集群中由管理员配置的一段网络存储,它是集群的一部分资源和底层存储密切相关,对象包含存储实现的细节,即 对接NFS、CIFS等存储系统 不同的PV会对应到不用的存储资源,这样在部署pod的时候直接调用集群内部的pv即可 PV没有命名空间隔离概念
什么是PVC 持久卷声明 (Persistent Volume Claim)
假如存在很多PV, K8S 要用PV的时候直接调用某个PV的话,那如果需要的是存储能力比较大存储资源,所以这个时候需要一个一个去对比pv,这样很耗费资源(因为要满足需求) PVC用户存储的一种声明, PVC 可请求特定存储空间和访问模式,PVC 消耗 PV 资源 PVC必须与对应的PV建立关系,PVC会根据定义的PV去申请
-
创建pod的时候会附带一个PVC请求,PVC请求就是去寻找一个合适的pv
使用逻辑
在 pod 中定义一个存储卷(该存储卷类型为 PVC),定义时指定大小, PVC 必须与对应的 PV 建立关系 PVC 会根据定义需求【去申请PV 】,而 PV 是由存储空间创建出来的
PV和PVC逻辑
PV 是集群中的【资源】,PVC 是对这些【资源的请求】 PV 和 PVC 之间的相互作用遵循这个生命周期 Provisioning(配置) ---> Binding(绑定) ---> Using(使用) ---> Releasing(释放) ---> Recycling(回收)
PersistentVolume(PV)和 PersistentVolumeClaim(PVC)是 Kubernetes 中用于抽象底层存储资源的一种机制。
PV 表示一个实际的存储资源,PVC 表示对该存储资源的使用请求。通过 PVC 请求一个 PV,可以动态地将该 PV 绑定到请求该存储资源的 Pod 上。
访问模式缩写为:
-
ReadWriteOnce——该卷可以被单个节点以读/写模式挂载
-
ReadOnlyMany——该卷可以被多个节点以只读模式挂载
-
ReadWriteMany——该卷可以被多个节点以读/写模式挂载
-
RWO - ReadWriteOnce
-
ROX - ReadOnlyMany
-
RWX - ReadWriteMany
二、本地存储(Local Volumes):
本地存储是指将数据存储在节点的本地磁盘上,而不是网络存储。它适用于需要高性能和低延迟的应用程序。本地存储不具备数据复制和故障转移的能力,因此在节点故障或Pod重新调度时,数据可能会丢失或不可用。
三、动态卷配置(Dynamic Volume Provisioning):
动态卷配置是一种自动创建持久卷的机制。当Pod请求一个持久卷声明时,动态卷配置可以根据定义的存储类(StorageClass)自动创建一个新的持久卷,并将其绑定到Pod中。
四、分布式存储系统(Distributed storage Systems):
Kubernetes支持使用分布式存储系统,如GlusterFS、Ceph等。这些系统提供了可扩展的、高可用的存储解决方案,可以在多个节点上分布数据,并提供数据几余和故障转移的功能。
NFS
6.1 存储卷
存储卷是 Kubernetes 中用于为容器提供数据持久化的一种机制,它可以将容器中的数据存储到一个卷(Volume)中,并在容器启动和停止时保持数据不丢失。Kubernetes 中提供了多种类型的存储卷,下面介绍几种常见的类型。
6.1.1 EmptyDir
EmptyDir 是 Kubernetes 中最简单的存储卷类型之一,它是一个空的目录卷,可以被多个 Pod 共享。当 Pod 离开节点时,EmptyDir 卷中的数据将被删除。
【默认使用内存作为存储介质。
临时存储,一般用户pod中容器间的数据交换与共享。
生命周期与Pod相同;pod内的容器发生重启不会造成emptyDir里面数据的丢失,但是当pod被重启后,emptyDir数据会丢失】
6.1.2 HostPath
HostPath 存储卷类型将主机上的文件或目录挂载到 Pod 内部,使得 Pod 可以访问主机上的文件系统。HostPath 存储卷类型也称为宿主机路径存储卷,它可以用于在容器中共享主机上的某些资源。
【不推荐使用,缺点:
将node节点上的目录挂载到pod中,不推荐使用;因为它会导致pod和node节点上强耦合。
高内聚, 低耦合;
高内聚:同个pod或程序只实现一个或一类功能,将相关的功能组合在一起
低耦合:尽量减少依赖,能够独立运行;
用途:pod节点需要node中的数据时】
6.1.3 ConfigMap/Secret
【k8s内部的资源】
ConfigMap 和 Secret 存储卷类型用于从集群外部注入配置信息或机密信息到容器内部。它们都可以在 Pod 创建或者更新时注入指定的键值对或者文本文件,并将这些信息作为文件或者环境变量暴露给应用程序使用。
6.1.4 NFS
NFS 存储卷类型将多个节点上的文件系统挂载到 Pod 中,使得 Pod 可以跨节点共享数据。NFS 存储卷通常用于需要在多个节点之间共享数据的应用程序中。















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









