






部分内容出自宫中号:小白debug,小破站有视频讲解。这里只是我对内容的一个汇总。
Kafka
Kafka就是一个消息队列
什么是消息队列?
说白了,它其实是个链表,链表的每个节点就是一个消息。每个节点有一个序号,我们叫它 Offset,记录消息的位置。服务依据自己的处理能力,消费链表里的消息。能处理多少是多少,不断更新已处理 Offset 的值。
但这有个问题,来不及处理的消息会堆积在内存里,如果服务更新重启,这些消息就都丢了。这个好解决,将队列挪出来,变成一个单独的进程。就算服务重启,也不会影响到了队列里的消息。
这样一个简陋的队列进程,其实就是所谓的消息队列。负责发数据到消息队列的角色,就是生产者,处理消息的角色,就消费者。但这个消息队列属实过于简陋,像什么高性能,高扩展性,高可用,它是一个都不沾。我们来看下怎么优化它。
高性能
消费者由于性能较差,消息队列里会不断堆积数据,为了提升性能,我们可以扩展更多的消费者, 这样消费速度就上去了,相对的我们就可以增加更多生产者,提升消息队列的吞吐量。

随着生产者和消费者都变多,我们会发现它们会同时争抢同一个消息队列,抢不到的一方就得等待,这不纯纯浪费时间吗!有解决方案吗?
有!首先是对消息进行分类,每一类是一个 topic,然后根据 topic 新增队列的数量,生产者将数据按 topic 投递到不同的队列中,消费者则根据需要订阅不同的 topic。这就大大降低了 topic 队列的压力。
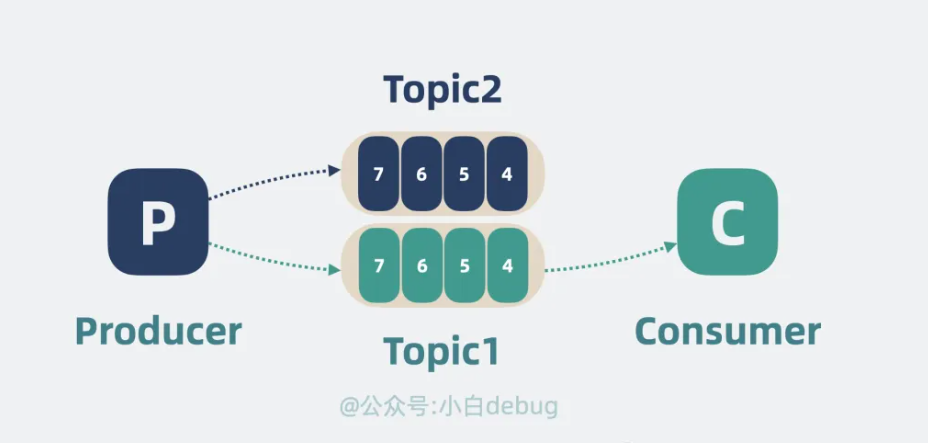
但单个 topic 的消息还是可能过多,我们可以将单个队列,拆成好几段,每段就是一个 partition分区,每个消费者负责一个 partition。这就大大降低了争抢,提升了消息队列的性能。

总结:
1、增加生产者、消费者数量来提高吞吐量。
2、按主题分为多个队列,并将每个队列partition分区降低争抢,大大提升了消息队列的性能。
高扩展性
随着 partition 变多,如果 partition 都在同一台机器上的话,就会导致单机 cpu 和内存过高,影响整体系统性能。

于是我们可以申请更多的机器,将 partition 分散部署在多台机器上,这每一台机器,就代表一个 broker。我们可以通过增加 broker 缓解机器 cpu 过高带来的性能问题。

总结:将partition分散到多个broker上,设置broker集群。
高可用
我们可以给 partition 多加几个副本,也就是 replicas,将它们分为 Leader 和 Follower。Leader 负责应付生产者和消费者的读写请求,而 Follower 只管同步 Leader 的消息。
将 Leader 和 Follower 分散到不同的 broker 上,这样 Leader 所在的 broker 挂了,也不会影响到 Follower 所在的 broker, 并且还能从 Follower 中选举出一个新的 Leader partition 顶上。这样就保证了消息队列的高可用。
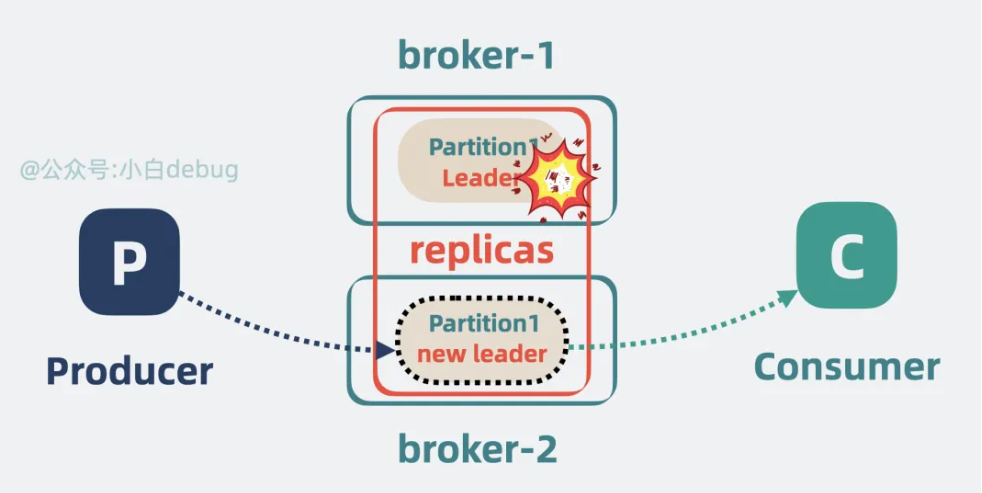
总结:
给partition设置主从,leader负责读写,follower负责同步消息。leader挂掉选择一个follower顶上。
持久化和过期策略
持久化:将数据持久化到磁盘中
持久化作用:borker都挂掉了,重启服务后,可以从磁盘中读出数据继续工作。
过期策略:也就是所谓的 retention policy,比如磁盘数据超过一定大小或消息放置超过一定时间就会被清理掉。
过期策略作用:保证磁盘空间充足,
消费者组
场景:
B 服务有多个实例,但本质上,它只有一个消费业务方,新增实例一般也是接着之前的 offset 继续消费。假设现在来了个新的业务方,C 服务,它想从头开始消费消息队列里的数据,这时候就不能跟在 B 服务的 offset 后边继续消费了。
所以我们还可以给消息队列加入消费者组(consumer group)的概念,B 和 C 服务各自是一个独立的消费者组,不同消费者组维护自己的消费进度,互不打搅。

总结:
消费者组之间互相独立,各自维护自己的消费进度。
ZooKeeper
相信你也发现了,组件太多了,而且每个组件都有自己的数据和状态,所以还需要有个组件去统一维护这些组件的状态信息,于是我们引入 ZooKeeper 组件。它会定期和 broker 通信,获取 整个 kafka 集群的状态,以此判断 某些 broker 是不是跪了,某些消费组消费到哪了。

Kafka 是什么
好了,到这里,当初那个简陋的消息队列,就成了一个高性能,高扩展性,高可用,支持持久化的超强消息队列,没错,它就是我们常说的消息队列 Kafka,上面涉及到各种概念,比如 partition 和 broker 什么的,都出自它。

Kafka的本质是日志消息代理 日志的特点就是append-only和不可变 它能带来的显而易见的好处是强大的局部性 内存中可以抽象为buffer 内核态里它又是page cache 磁盘上它会集中在同一磁道 从上至下利于软件和操作系统进行快速写入 这也是为什么大量知名系统 不论是MySQL Server的binlog还是redis的aof 都是使用类似的方式
它是典型的IO密集型应用 所以它并不是线程池 Kafka的大量技术细节都在解决IO性能 包括但不限于零拷贝
kafka 的应用场景:
消息队列是架构中最常见的中间件之一,使用场景之多,堪称万金油!比如上游流量忽高忽低,想要**削峰填谷,解决请求速度不平均问题,提升 cpu/gpu 利用率,用它。又比如系统过大,消息流向盘根错节,想要拆解组件,降低系统耦合,还是用它。再比如秒杀活动,请求激增,想要保护服务的同时又尽量不影响用户,还得用它。当然,凡事无绝对,方案还得根据实际情况来定,做架构做到最后,都是在做折中**。
总结:
- kafka 是消息队列,像消息队列投递消息的是生产者,消费消息的是消费者。增加生产者和消费者的实例个数可以提升系统吞吐。多个消费者可以组成一个消费者组,不同消费者组维护自己的消费进度,互不打搅。
- kafka 将消息分为多个 topic,每个 topic 内部拆分为多个 partition,每个 partition 又有自己的副本,不同的 partition 会分布在不同的 broker 上,提升性能的同时,还增加了系统可用性和可扩展性。
RocketMQ
快速集成RocketMQ
rocketmq:
name-server: rocketmq运行地址:端口
producer:
group: test-group
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.1.1</version>
</dependency>
注意版本兼容问题,我这里的springboot版本是2.3
@Resource
private RocketMQTemplate rocketMQTemplate;
@RequestMapping("/pushMessage")
public Result<Boolean> get(@RequestParam("id") int id) {
rocketMQTemplate.convertAndSend("first-topic","你好,Java旅途" + id);
return Result.ok(true);
}
package com.jingdianjichi.subject.application.mq;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.springframework.stereotype.Component;
@Component
@RocketMQMessageListener(topic = "first-topic",consumerGroup = "test-group")
@Slf4j
public class TestConsumer implements RocketMQListener<String> {
@Override
public void onMessage(String message) {
System.out.println(message);
}
}
和 Kafka 相比,RocketMQ 在架构上做了减法,在功能上做了加法。
在架构上做减法
简化协调节点
Zookeeper 在 Kafka 架构中会和 broker 通信,维护 Kafka 集群信息。一个新的 broker 连上 Zookeeper 后,其他 broker 就能立马感知到它的加入,像这种能在分布式环境下,让多个实例同时获取到同一份信息的服务,就是所谓的**分布式协调服务**。
但 Zookeeper 作为一个**通用的分布式协调服务,它不仅可以用于服务注册与发现,还可以用于分布式锁、配置管理等场景。Kafka 其实只用到了它的部分功能,多少有点杀鸡用牛刀的味道。太重了**。
所以 RocketMQ 直接将 Zookeeper 去掉,换成了 nameserver,用一种更轻量的方式,管理消息队列的集群信息。生产者通过 nameserver 获取到 topic 和 broker 的路由信息,然后再与 broker 通信,实现**服务发现和负载均衡**的效果。
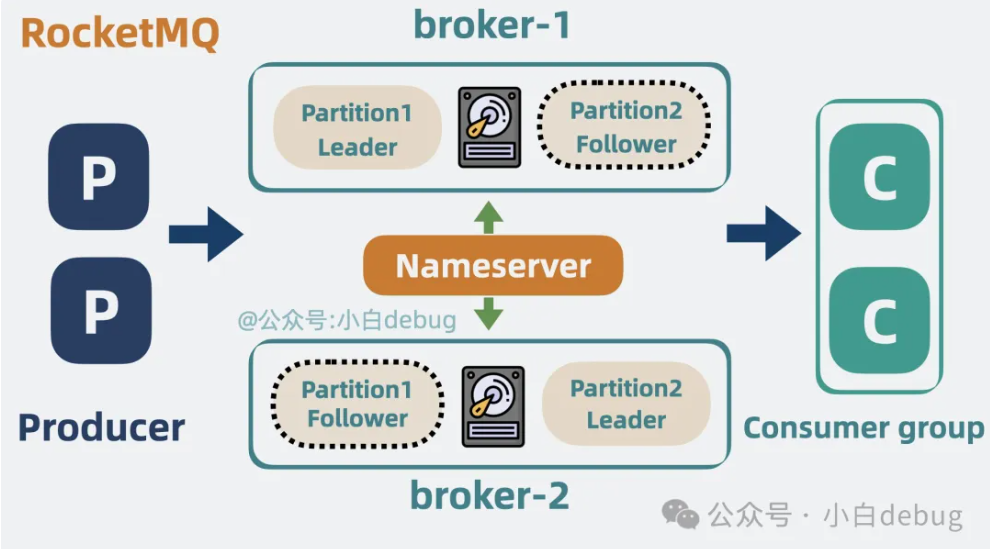
当然,开发 Kafka 的大佬们后来也意识到了 Zookeeper 过重的问题,所以从 2.8.0 版本就支持将 Zookeeper 移除,通过 在 broker 之间加入一致性算法 raft 实现同样的效果,这就是所谓的 KRaft 或 Quorum 模式。

简化分区
我们知道,Kafka 会将 topic 拆分为多个 partition,用来提升**并发性能。在 RocketMQ 里也一样,将 topic 拆分成了多个分区,但换了个名字,叫 Queue,也就是"队列**"。
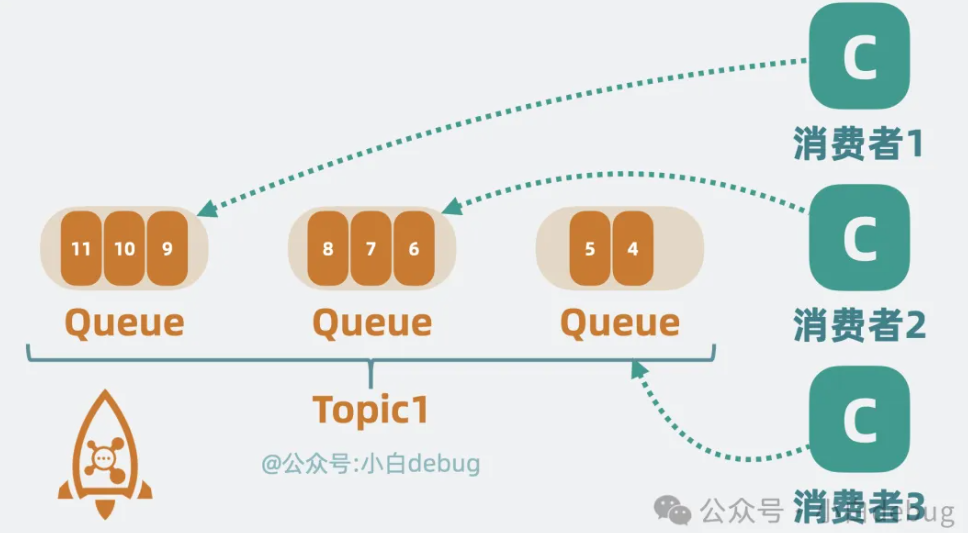
Kafka 中的 partition 会存储完整的消息体,而 RocketMQ 的 Queue 上却只存一些简要信息,比如消息偏移 offset,而消息的完整数据则放到"一个"叫 commitlog 的文件上,通过 offset 我们可以定位到 commitlog 上的某条消息。
Kafka 消费消息,broker 只需要直接从 partition 读取消息返回就好,也就是读第一次就够了。
而在 RocketMQ 中,broker 则需要先从 Queue 上读取到 offset 的值,再跑到 commitlog 上将完整数据读出来,也就是需要读两次。
那么问题就来了,看起来 Kafka 的设计更高效?为什么 RocketMQ 不采用 Kafka 的设计?
这就不得说一下 Kafka 的底层存储了。
Kafka的底层存储
Kafka 的 partition 分区,其实在底层由很多段(segment)组成,每个 segment 可以认为就是个小文件。将消息数据写入到 partition 分区,本质上就是将数据写入到某个 segment 文件下。
我们知道,操作系统的机械磁盘,顺序写的性能会比随机写快很多,差距高达几十倍。为了提升性能,Kafka 对每个小文件都是顺序写。
如果只有一个 segment 文件,那写文件的性能会很好。
但当 topic 变多之后,topic 底下的 partition 分区也会变多,对应的 partition 底下的 segment 文件也会变多。同时写**多个** topic 底下的 partition,就是同时**写多个文件,虽然每个文件内部都是顺序写,但多个文件存放在磁盘的不同地方,原本顺序写磁盘就可能劣化变成了随机写**。于是写性能就降低了。

那问题又又来了,究竟多少 topic 才算多?
8 个分区的情况下,超过 64 topic, Kafka 性能就会开始下降。
RocketMQ 的底层存储
为了缓解同时写多个文件带来的随机写问题,RocketMQ 索性将单个 broker 底下的多个 topic 数据,全都写到"一个"逻辑文件 CommitLog 上,这就消除了随机写多文件的问题,将所有写操作都变成了顺序写。大大提升了 RocketMQ 在多 topic 场景下的写性能。

注意上面提到的"一个"是带引号的,虽然逻辑上它是一个大文件,但实际上这个 CommitLog 由多个小文件组成。每个文件的大小是固定的,当一个文件被写满后,会创建一个新的文件来继续存储新的消息。这种方式可以方便地管理和清理旧的消息
简化备份模型
我们知道,Kafka 会将 partiton 分散到多个 broker 中,并为 partiton 配置副本,将 partiton 分为 leader 和 follower ,也就是 主和从 。broker 中既可能有 A topic 的主 partiton,也可能有 B topic 的从 partiton。
主从 partiton 之间会建立数据同步,本质上就是同步 partiton 底下的 segment 文件数据。

RocketMQ 将 broker 上的所有 topic 数据到写到 CommitLog 上。如果还像 Kafka 那样给每个分区单独建立同步通信,就还得将 CommitLog 里的内容**拆开,这就还是退化为随机读了。
于是 RocketMQ 索性以 broker 为单位区分主从**,主从之间同步 CommitLog 文件,保持高可用的同时,也大大简化了备份模型。

在功能上做法
消息过滤
我们知道,Kafka 支持通过 topic 将数据进行分类,比如订单数据和用户数据是两个不同的 topic,但如果我还想再进一步分类呢?比如同样是用户数据,还能根据 vip 等级进一步分类。假设我们只需要获取 vip6 的用户数据,在 Kafka 里,消费者需要消费 topic 为用户数据的所有消息,再将 vip6 的用户过滤出来。
而 RocketMQ 支持对消息打上标记,也就是打 tag,消费者能根据 tag 过滤所需要的数据。比如我们可以在部分消息上标记 tag=vip6,这样消费者就能只获取这部分数据,省下了消费者过滤数据时的资源消耗。
总结:相当于 RocketMQ 除了支持通过 topic 进行一级分类,还支持通过 tag 进行二级分类。
支持事务
我们知道 Kafka 支持事务,比如生产者发三条消息 ABC,这三条消息要么同时发送成功,要么同时发送失败。
RocketMQ 的事务支持"执行一些自定义逻辑“和”生产者发消息"这两件事,要么同时成功,要么同时失败。
加入延时队列
如果我们希望消息投递出去之后,消费者不能立马消费到,而是过个一定时间后才消费,也就是所谓的**延时消息。如果我们使用 Kafka, 要实现类似的功能的话,就会很费劲。
但 RocketMQ 天然支持延时队列**,我们可以很方便实现这一功能。
加入死信队列
消费消息是有可能失败的,失败后一般可以设置**重试。如果多次重试失败,RocketMQ 会将消息放到一个专门的队列,方便我们后面单独处理。这种专门存放失败消息的队列,就是死信队列**。
Kafka 原生不支持这个功能,需要我们自己实现。
消息回溯
Kafka 支持通过**调整 offset** 来让消费者从某个地方开始消费,而 RocketMQ,除了可以调整 offset, 还支持**调整时间**(kafka在0.10.1后支持调时间)
RocketMQ 为什么性能不如 Kafka?
现在看起来,RocketMQ 好像各方面都比 Kafka 更能打。
但 Kafka 却一直没被淘汰,说明 RocketMQ 必然是有着不如 Kafka 的地方。是啥呢?
性能,严格来说是**吞吐量**。
阿里中间件团队对它们做过压测,同样条件下,kafka 比 RocketMQ 快 50%左右。但即使这样,RocketMQ 依然能每秒处理 10w 量级的数据,依旧非常能打。你不能说 RocketMQ 弱,只能说 Kafka 性能太强了。
这就很奇怪了,为什么 RocketMQ 参考了 Kafka 的架构,性能却还不如 Kafka?在回答这个问题之前,我们来聊下什么是**零拷贝**。
零拷贝是什么
我们知道,消息队列的消息为了防止进程崩溃后丢失,一般不会放内存里,而是放磁盘上。那么问题就来了,消息从消息队列的磁盘,发送到消费者,过程是怎么样的呢?
消息的发送过程
操作系统分为**用户空间和内核空间。程序处于用户空间,而磁盘属于硬件,操作系统本质上是程序和硬件设备的一个中间层**。程序需要通过操作系统去调用硬件能力。
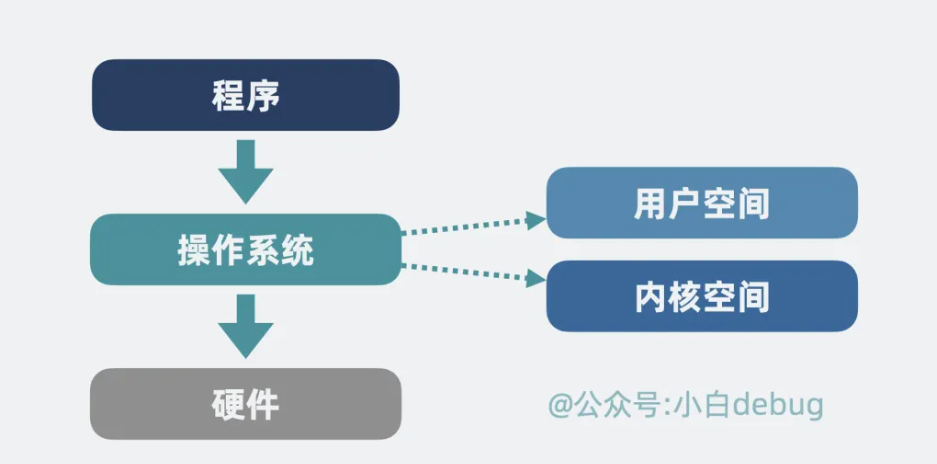
如果用户想要将数据从磁盘发送到网络。那么就会发生下面这几件事:程序会发起系统调用 read() ,尝试读取磁盘数据,
• 磁盘数据从设备拷贝到内核空间的缓冲区。
• 再从内核空间的缓冲区拷贝到用户空间。
程序再发起系统调用 write() ,将读到的数据发到网络:
• 数据从用户空间拷贝到 socket 发送缓冲区
• 再从 socket 发送缓冲区拷贝到网卡。
最终数据就会经过网络到达消费者。
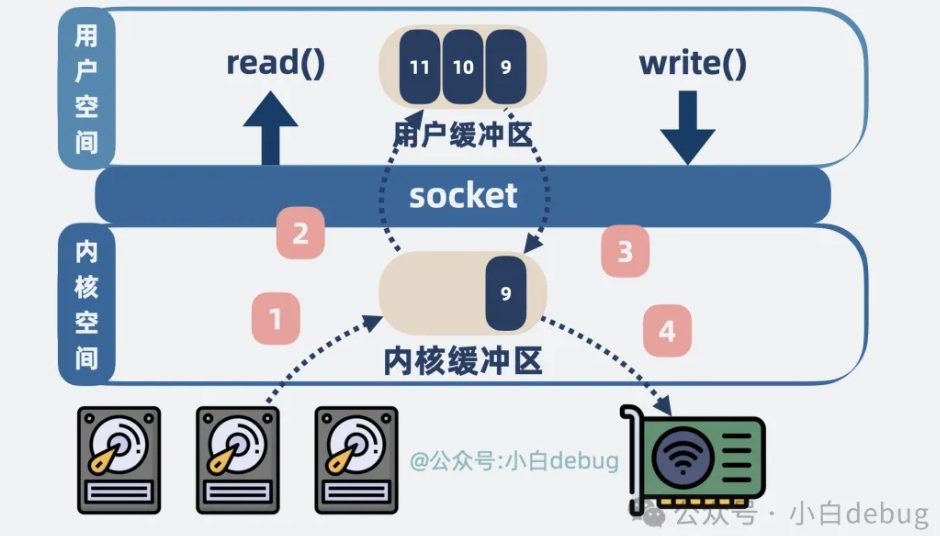
整个过程,本机内发生了 2 次系统调用对应4 次用户空间和内核空间的切换以及 4 次数据拷贝。
一顿操作猛如虎,结果就是同样一份数据来回拷贝。有没有办法优化呢?有,它就是零拷贝技术,常见的方案有两种,分别是 mmap 和 sendfile。
mmap 是什么
mmap 是操作系统内核提供的一个方法,可以将内核空间的缓冲区**映射**到用户空间。
用了它,整个发送流程就有了一些变化。程序发起系统调用 mmap(),尝试读取磁盘数据,具体情况如下:
• 磁盘数据从设备拷贝到内核空间的缓冲区。
• 内核空间的缓冲区映射到用户空间,这里不需要拷贝。
程序再发起系统调用 write(),将读到的数据发到网络:
• 数据从内核空间缓冲区拷贝到 socket 发送缓冲区。
• 再从 socket 发送缓冲区拷贝到网卡。

整个过程,发生了 2 次系统调用,对应 4 次用户空间和内核空间的切换,以及 3 次数据拷贝,对比之前,省下 一次 内核空间到用户空间的拷贝。
看到这里大家估计也蒙了,不是说零拷贝吗?怎么还有 3 次拷贝。mmap 作为一种零拷贝技术,指的是用户空间到内核空间这个过程不需要拷贝,而不是指数据从磁盘到发送到网卡这个过程零拷贝。
确实省了一点,但不多。有没有更彻底的零拷贝?有,用 sendfile。
sendfile 是什么
sendfile,也是内核提供的一个方法,从名字可以看出,就是用来发送文件数据的。程序发起系统调用sendfile(),内核会尝试读取磁盘数据然后发送,具体情况如下:
• 磁盘数据从设备拷贝到内核空间的缓冲区。
• 内核空间缓冲区里的数据可以直接拷贝到网卡。

整个过程,发生了 1 次系统调用,对应 2 次用户空间和内核空间的切换,以及 2 次数据拷贝。这时候问题很多的小明就有意见了,说好的零拷贝怎么还有 2 次拷贝?
其实,这里的零拷贝指的是零 CPU拷贝。也就是说 sendfile 场景下,需要的两次拷贝,都不是 CPU 直接参与的拷贝,而是其他硬件设备技术(比如DMA控制器)做的拷贝,不耽误我们 CPU 跑程序。
kafka 为什么性能比 RocketMQ 好
聊完两种零拷贝技术,我们回过头来看下 kafka 为什么性能比 RocketMQ 好。
这是因为 RocketMQ 使用的是 mmap 零拷贝技术,而 kafka 使用的是 sendfile。kafka 以更少的拷贝次数以及系统内核切换次数,获得了更高的性能。
但问题又来了,为什么 RocketMQ 不使用 sendfile?参考 kafka 抄个作业也不难啊?
主要原因是两种方法返回的内容差异
mmap 返回的是数据的具体内容,应用层能获取到消息内容并进行一些逻辑处理

而 sendfile 返回的则是发送成功了几个字节数,具体发了什么内容,应用层根本不知道。

而 RocketMQ 的一些功能,却需要了解具体这个消息内容,方便二次投递等,比如将消费失败的消息重新投递到死信队列中,如果 RocketMQ 使用 sendfile,那根本没机会获取到消息内容长什么样子,也就没办法实现一些好用的功能了。
并且一个broker中多个topic对应的文件是混合存储在一个大文件上, sendfile没办法像mmap一样细粒度的选择发送哪部分数据, 这样就会造成不必要的IO浪费。
而 kafka 却没有这些功能特性,追求极致性能,正好可以使用 sendfile。
除了零拷贝以外,kafka 高性能的原因还有很多,比如什么批处理,数据压缩啥的,但那些优化手段 rocketMQ 也都能借鉴一波,唯独这个零拷贝,那是毫无办法。如果还要深入理解 Kafka,Log 对象是绕不过的,ConcurrentSkipListMap 表示日志分段,优化版的二分查找,都是 Kafka 的可以说的点。
所以还是那句话,没有一种架构是完美的,一种架构往往用于适配某些场景,你很难做到既要又要还要。当场景不同,我们就需要做一些定制化改造,通过牺牲一部分能力去换取另一部分能力。做架构,做到最后都是在做折中。是不是感觉升华了。
kafka 和 RocketMQ 怎么选?
如果是大数据场景,比如你能频繁听到 spark,flink 这些关键词的时候,那就用 kafka。除此之外,如果公司组件支持,尽量用 RocketMQ。
总结:
• RocketMQ 和 kafka 相比,在架构上做了减法,在功能上做了加法
• 跟 kafka 的架构相比,RocketMQ 简化了协调节点和分区以及备份模型。同时增强了消息过滤、消息回溯和事务能力,加入了延迟队列,死信队列等新特性。
• 凡事皆有代价,RocketMQ 牺牲了一部分性能,换取了比 kafka 更强大的功能特性。
RabbitMQ
MQ的基本结构:
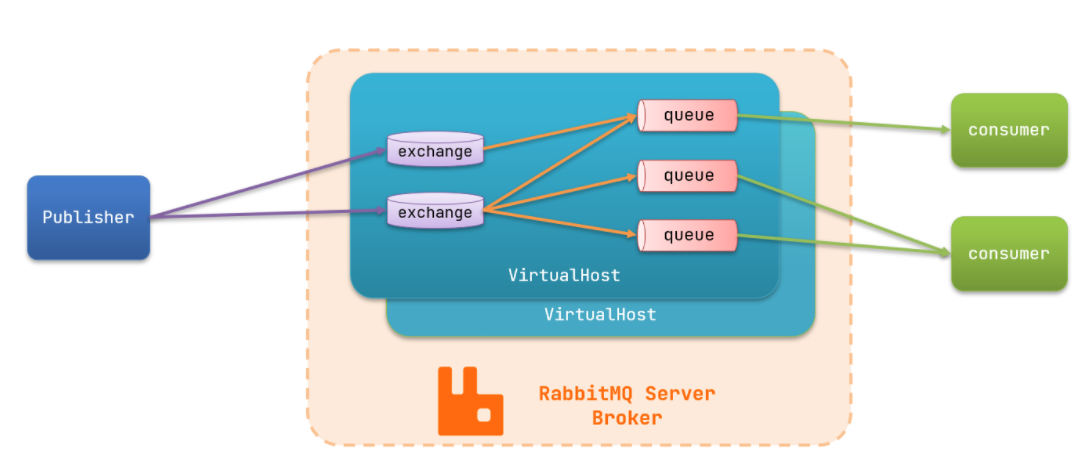
RabbitMQ中的一些角色:
- publisher:生产者
- consumer:消费者
- exchange个:交换机,负责消息路由
- queue:队列,存储消息
- virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离
RabbitMQ消息模型
使用网上现有的封装模板,比如SpringAMQP是基于RabbitMQ封装的一套模板,并且还利用SpringBoot对其实现了自动装配,使用起来非常方便。
SpringAmqp的官方地址:https://spring.io/projects/spring-amqp
SpringAMQP提供了三个功能:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消息
下面例举常见的模型
WorkQueue
Work queues,也被称为(Task queues),任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。

当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,速度就能大大提高了。
消息发送
这次我们循环发送,模拟大量消息堆积现象。
在publisher服务中的SpringAmqpTest类中添加一个测试方法:
/**
* workQueue
* 向队列中不停发送消息,模拟消息堆积。
*/
@Test
public void testWorkQueue() throws InterruptedException {
// 队列名称
String queueName = "simple.queue";
// 消息
String message = "hello, message_";
for (int i = 0; i < 50; i++) {
// 发送消息
rabbitTemplate.convertAndSend(queueName, message + i);
Thread.sleep(20);
}
}
消息接收
要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法:
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {
System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(20);
}
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(200);
}
注意到这个消费者sleep了1000秒,模拟任务耗时。
测试
启动ConsumerApplication后,在执行publisher服务中刚刚编写的发送测试方法testWorkQueue。
可以看到消费者1很快完成了自己的25条消息。消费者2却在缓慢的处理自己的25条消息。
也就是说消息是平均分配给每个消费者,并没有考虑到消费者的处理能力。这样显然是有问题的。
能者多劳
在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
发布/订阅
发布订阅的模型如图:
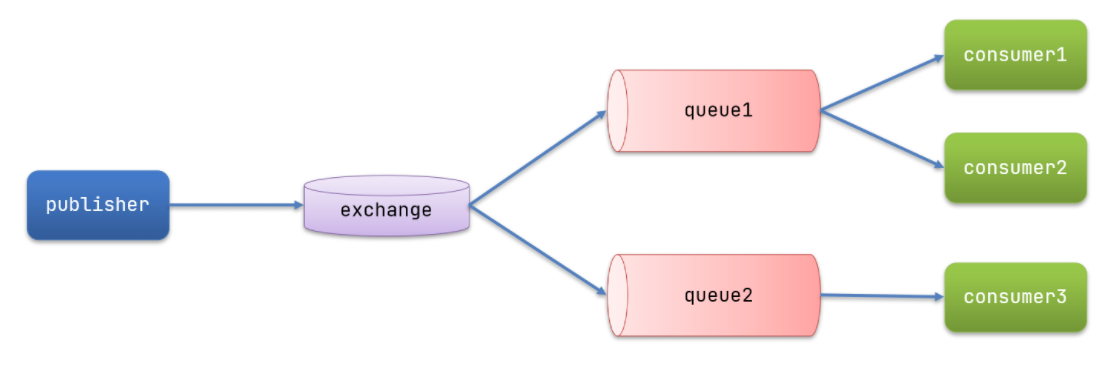 可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
- Publisher:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给X(交换机)
- Exchange:交换机,图中的X。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
- Exchange有以下3种类型:
- Fanout:广播,将消息交给所有绑定到交换机的队列
- Direct:定向,把消息交给符合指定routing key 的队列
- Topic:相比定向加入了通配符,也是把消息交给符合routing key 的队列
- Consumer:消费者,与以前一样,订阅队列,没有变化
- Queue:消息队列也与以前一样,接收消息、缓存消息。
注意:
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
Fanout
Fanout,英文翻译是扇出,我觉得在MQ中叫广播更合适。

在广播模式下,消息发送流程是这样的:
- 1) 可以有多个队列
- 2) 每个队列都要绑定到Exchange(交换机)
- 3) 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定
- 4) 交换机把消息发送给绑定过的所有队列
- 5) 订阅队列的消费者都能拿到消息
代码实现流程:
- 创建一个交换机 itcast.fanout,类型是Fanout
- 创建两个队列fanout.queue1和fanout.queue2,绑定到交换机itcast.fanout
声明队列和交换机
Spring提供了一个接口Exchange,来表示所有不同类型的交换机:
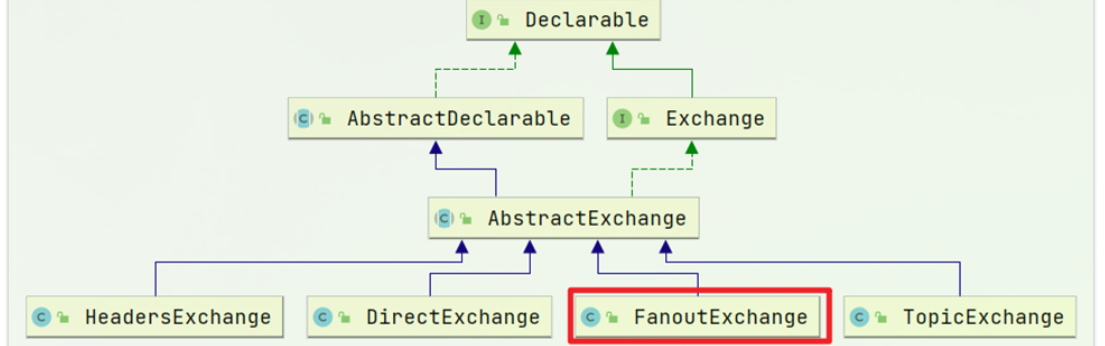
在consumer中创建一个配置类,通过bean注解声明队列和交换机:
package cn.itcast.mq.config;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.FanoutExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class FanoutConfig {
/**
* 声明交换机
* @return Fanout类型交换机
*/
@Bean
public FanoutExchange fanoutExchange(){
return new FanoutExchange("itcast.fanout");
}
/**
* 第1个队列
*/
@Bean
public Queue fanoutQueue1(){
return new Queue("fanout.queue1");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
/**
* 第2个队列
*/
@Bean
public Queue fanoutQueue2(){
return new Queue("fanout.queue2");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue2(Queue fanoutQueue2, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
}
}
消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
@Test
public void testFanoutExchange() {
// 队列名称
String exchangeName = "itcast.fanout";
// 消息
String message = "hello, everyone!";
rabbitTemplate.convertAndSend(exchangeName, "", message);
}
消息接收
在consumer服务的SpringRabbitListener中添加两个方法,作为消费者:
@RabbitListener(queues = "fanout.queue1")
public void listenFanoutQueue1(String msg) {
System.out.println("消费者1接收到Fanout消息:【" + msg + "】");
}
@RabbitListener(queues = "fanout.queue2")
public void listenFanoutQueue2(String msg) {
System.out.println("消费者2接收到Fanout消息:【" + msg + "】");
}
总结
交换机的作用是什么?
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange的会将消息路由到每个绑定的队列
声明队列、交换机、绑定关系的Bean是什么?
- Queue
- FanoutExchange
- Binding
Direct
在Fanout模式中,一条消息,会发送给所有绑定当前交换机的队列。但是,在某些场景下,我们希望不同的消息被不同的队列获取。这时就要用到Direct类型的Exchange。

● 消息的发送方在 向 Exchange发送消息时,也必须指定消息的 RoutingKey。
● Exchange不再把消息交给每一个绑定的队列,而是根据消息的Routing Key进行判断,只有队列的Routingkey与消息的 Routing key完全一致,才会接收到消息
代码流程如下:
- 利用@RabbitListener声明Exchange、Queue、RoutingKey
- 在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2
- 在publisher中编写测试方法,向itcast. direct发送消息
基于注解声明队列和交换机
基于@Bean的方式声明队列和交换机比较麻烦,Spring还提供了基于注解方式来声明。
在consumer的SpringRabbitListener中添加两个消费者,同时基于注解来声明队列和交换机:
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red", "blue"}
))
public void listenDirectQueue1(String msg){
System.out.println("消费者接收到direct.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue2"),
exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red", "yellow"}
))
public void listenDirectQueue2(String msg){
System.out.println("消费者接收到direct.queue2的消息:【" + msg + "】");
}
消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
@Test
public void testSendDirectExchange() {
// 交换机名称
String exchangeName = "itcast.direct";
// 消息
String message = "红色警报!日本乱排核废水,导致海洋生物变异,惊现哥斯拉!";
// 发送消息
rabbitTemplate.convertAndSend(exchangeName, "red", message);
}
总结
描述下Direct交换机与Fanout交换机的差异?
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
基于@RabbitListener注解声明队列和交换机有哪些常见注解?
- @Queue
- @Exchange
Topic
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!
Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert
通配符规则:
#:匹配一个或多个词
*:匹配不多不少恰好1个词
举例:
item.#:能够匹配item.spu.insert 或者 item.spu
item.*:只能匹配item.spu
案例需求:
实现思路如下:
- 并利用@RabbitListener声明Exchange、Queue、RoutingKey
- 在consumer服务中,编写两个消费者方法,分别监听topic.queue1和topic.queue2
- 在publisher中编写测试方法,向itcast. topic发送消息
消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
/**
* topicExchange
*/
@Test
public void testSendTopicExchange() {
// 交换机名称
String exchangeName = "itcast.topic";
// 消息
String message = "喜报!孙悟空大战哥斯拉,胜!";
// 发送消息
rabbitTemplate.convertAndSend(exchangeName, "china.news", message);
}
消息接收
在consumer服务的SpringRabbitListener中添加方法:
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue1"),
exchange = @Exchange(name = "itcast.topic", type = ExchangeTypes.TOPIC),
key = "china.#"
))
public void listenTopicQueue1(String msg){
System.out.println("消费者接收到topic.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue2"),
exchange = @Exchange(name = "itcast.topic", type = ExchangeTypes.TOPIC),
key = "#.news"
))
public void listenTopicQueue2(String msg){
System.out.println("消费者接收到topic.queue2的消息:【" + msg + "】");
}
总结
描述下Direct交换机与Topic交换机的差异?
描述下Direct交换机与Topic交换机的差异?
● Topic交换机接收的消息RoutingKey必须是多个单词,以 . 分割
● Topic交换机与队列绑定时的bindingKey可以指定通配符
● #:代表0个或多个词
● *:代表1个词
三者的共同点和区别
共同点:组成上都有生产者,消费者,交换机,队列。流程都是生产者产生消息交给交换机,交换机路由给队列,消费者从绑定的队列中获取消息进行消费。
区别:
广播交换机将消息路由到所有绑定了自己的队列中。
定向交换机根据消息的路由key,路由到也有包含相同路由key的队列上。
主题交换机与定向交换机类似,只不过路由key多了通配符。
消息转换器
之前说过,Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。
20200525170410401.png&pos_id=img-fkXWBaCH-1728110758199)
只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:
- 数据体积过大
- 有安全漏洞
- 可读性差
配置JSON转换器
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。
在publisher和consumer两个服务中都引入依赖:
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.9.10</version>
</dependency>
配置消息转换器。
在启动类中添加一个Bean即可:
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









