







前言
在 AI 蓬勃发展的当下,大规模优质数据是训练精准且强大 AI 模型的关键要素。然而,开发者在数据采集环节举步维艰,面临着诸如数据来源零散、采集效率欠佳、反爬虫机制阻碍重重等困境。
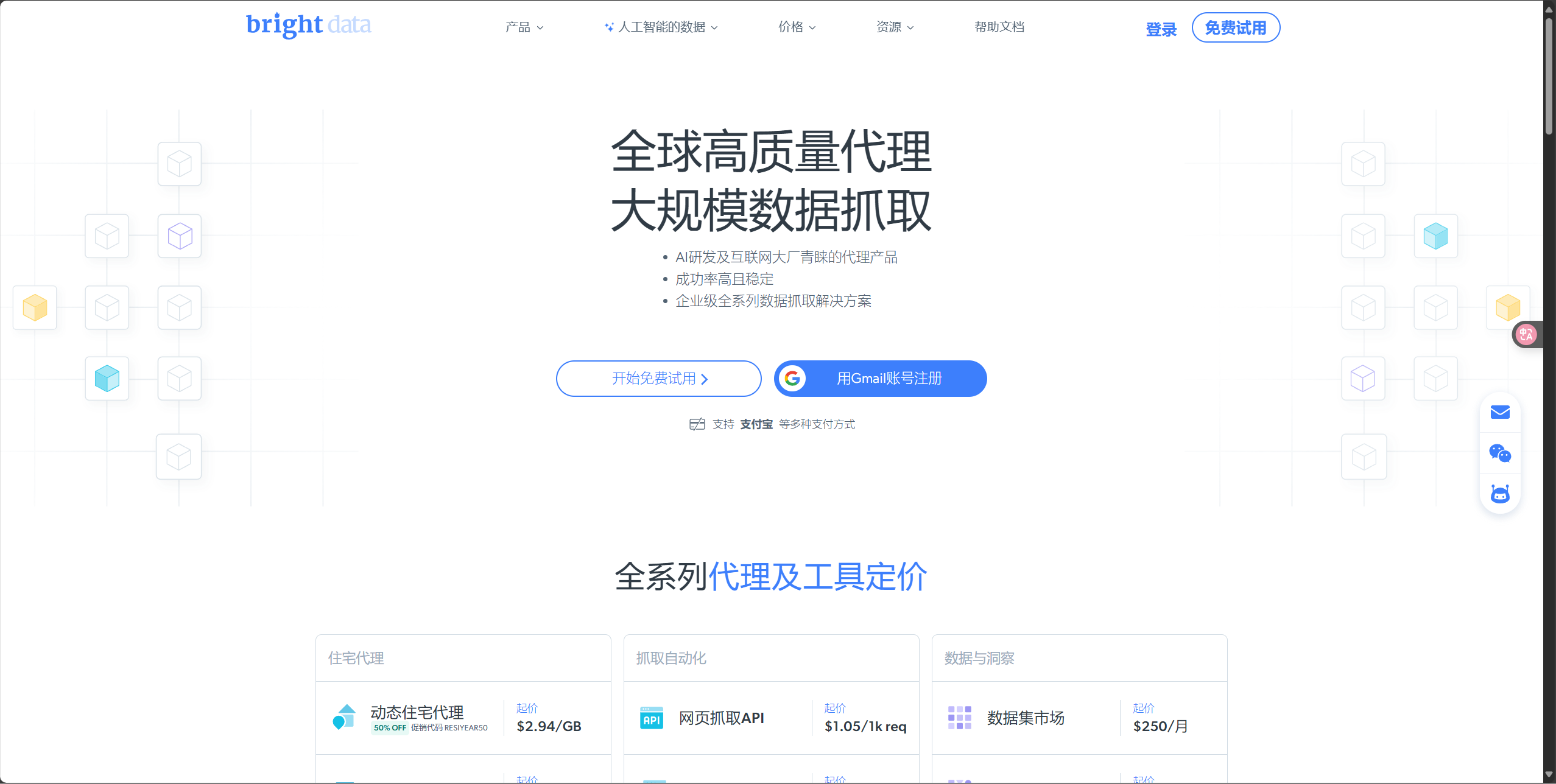
网页抓取 API、网页解锁器 API、抓取浏览器、抓取函数、搜索引擎爬虫等功能一应俱全,无论是常规网页数据提取,还是攻克复杂的反爬虫网站,都能满足开发者多样化的数据需求。此外,亮数据还设有数据集市场,并提供自定义数据集服务,可提供现成或定制化的数据资源。在技术层面,亮数据运用先进的反封锁与验证码处理技术突破障碍,严格把控数据质量,大幅提升开发者的工作效率。
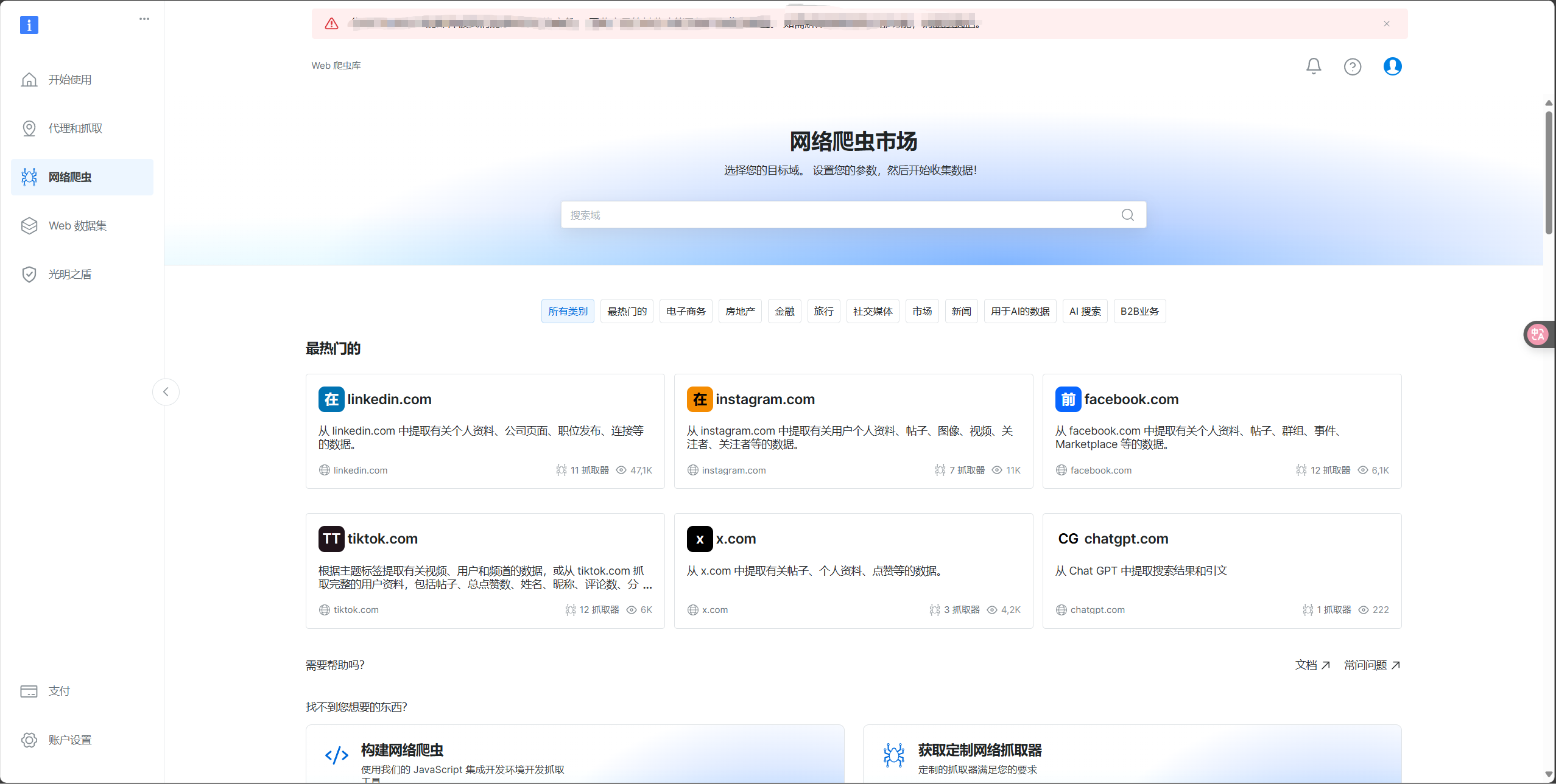
如今,为守护自身数据安全,互联网平台纷纷祭出反爬虫机制这一利器,诸如验证码、IP 限制、动态网页加载以及复杂的 JavaScript 验证等手段层出不穷。这些举措在捍卫网站数据安全领地的同时,却给合法的数据采集工作设下了重重路障。
合法的数据采集者不得不投入更多的人力与时间来应对这些阻碍,采集效率也因此大幅滑坡,更有甚者,采集工作会因这些难题而陷入停滞。特别是 IP 封锁与访问频率控制方面,一旦采集方频繁对同一网站发起访问,服务器便会拉响警报,直接将相关 IP 封禁。对于那些有着大量数据采集需求的企业而言,这无疑是一场 “噩梦”。IP 被封,数据采集工作被迫中断,效率骤降不说,运营成本还会随之增加。而部分网站实施的地域性 IP 封锁策略,更是让数据采集的难度呈几何级增长。
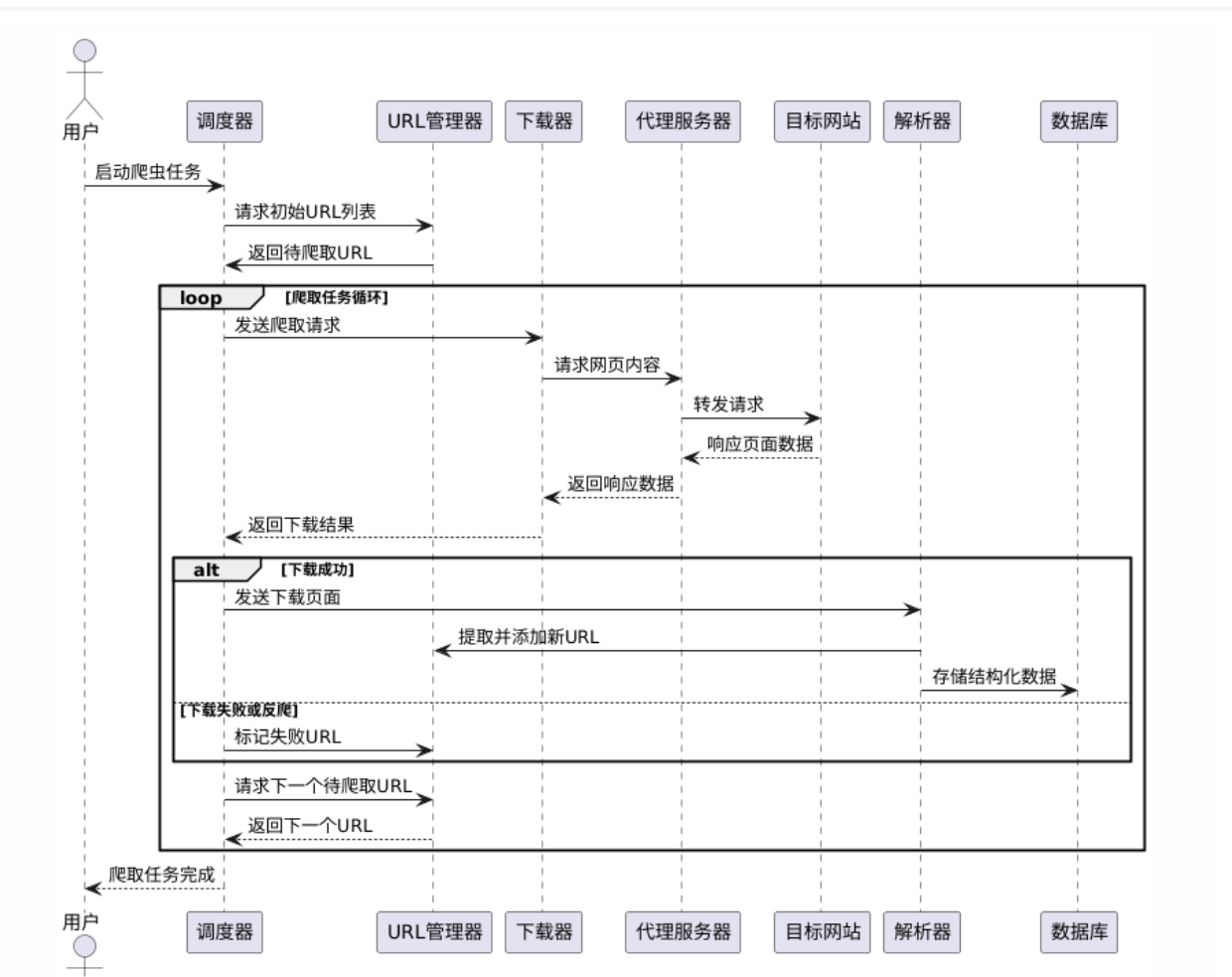
下方是传统的爬虫流程
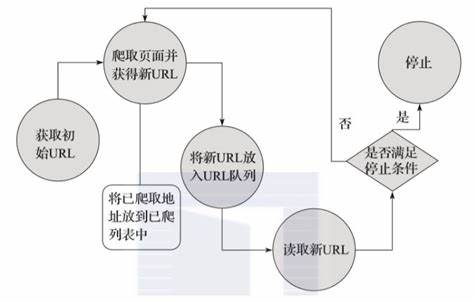
但是这个时候,亮数据出手了,亮数据凭借先进的技术与完备的解决方案,能够有效攻克反爬虫机制带来的种种难关,助力开发者与企业高效、合规地开展数据采集工作,为数据获取与利用开辟出一条顺畅的通路。
亮数据简介
网络数据爬取的稳定性和功能强大性
亮数据(Bright Data)是一款专注于提供先进网络数据抓取和解析服务的平台,它为用户提供了多种工具和技术,帮助他们在复杂的数据收集环境中快速、准确地获取所需的数据。通过亮数据的服务,用户可以轻松应对常见的抓取难题,如IP限制、验证码、动态内容加载等问题。
亮数据的优势之一在于其强大的爬虫技术。平台支持各种数据源的抓取,包括但不限于电商平台、社交媒体、搜索引擎等。无论是基于URL的抓取,还是通过关键字和搜索结果进行数据挖掘,亮数据都能提供高效且可靠的解决方案。此外,亮数据还为用户提供了代理IP、API等技术支持,帮助用户突破访问限制,确保数据采集的稳定性与效率。
使用界面简易容易上手
在使用方面,亮数据的用户界面简洁易用,即便是新手也能迅速上手。用户可以根据自己的需求选择合适的工具和数据集,进行高效的抓取和分析。而且,平台提供了灵活的计费方式,用户可以根据项目需求灵活选择,避免不必要的资源浪费。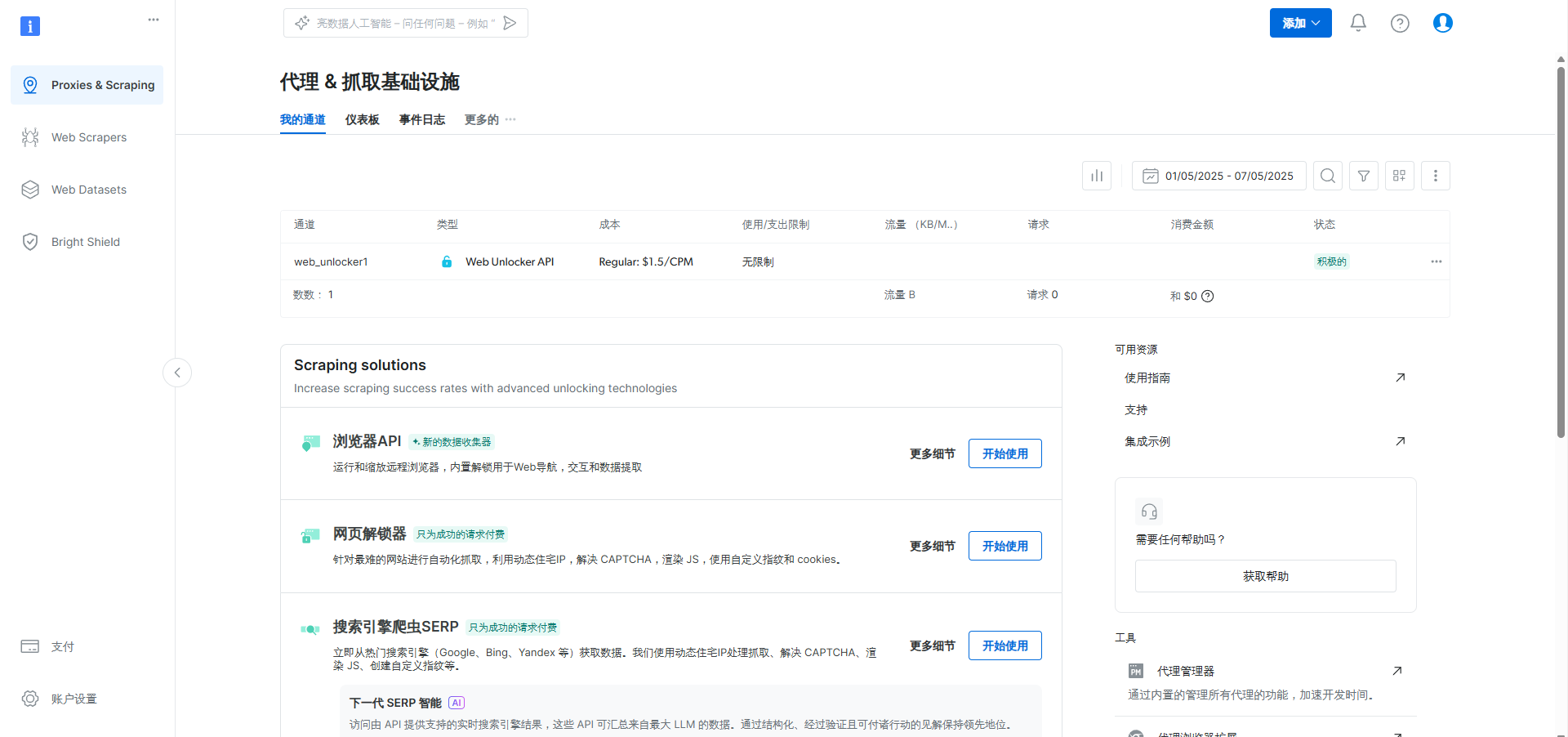
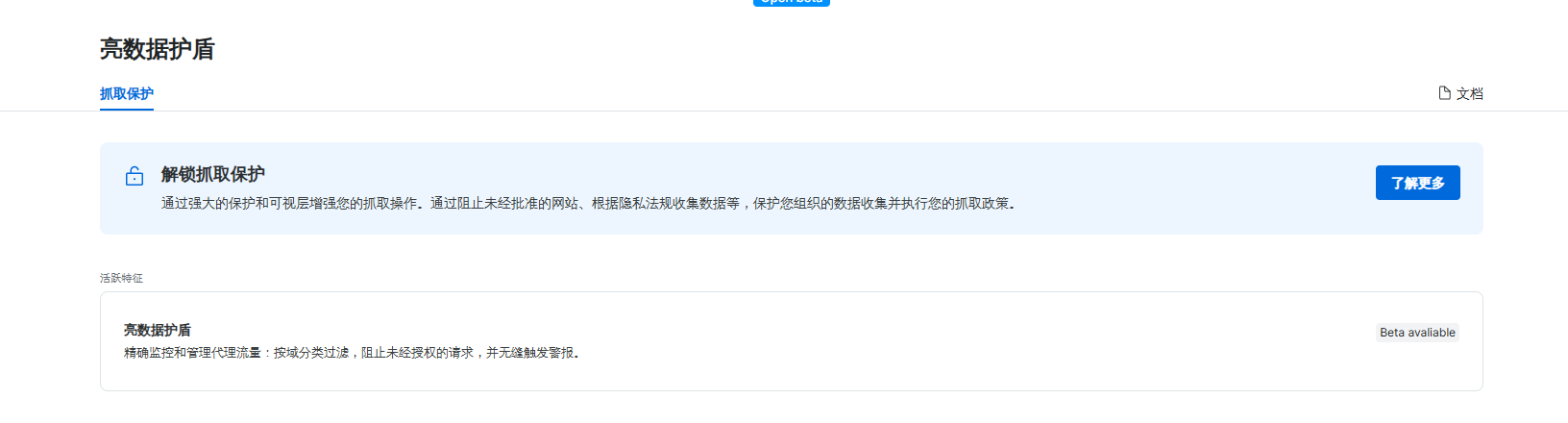
亮数据防护墙功能
亮数据还推出了名为“Bright Shield”的防护系统,专门用于保护抓取过程中可能面临的风险。这一系统可以有效防止IP封锁、数据泄露等问题,确保用户在进行大规模数据抓取时的安全性和稳定性。
综上所述,亮数据是一个功能强大的网络数据抓取平台,特别适合需要大规模、高效数据采集的企业与开发者。无论是在电商、市场分析,还是学术研究等领域,亮数据都能提供精准的数据支持和技术保障。
亮数据的内置ai回答
在我们的亮数据的主页有一个ai回答的小助手,对于刚刚开始使用量数据的同学很友好的,不懂的随时进行询问
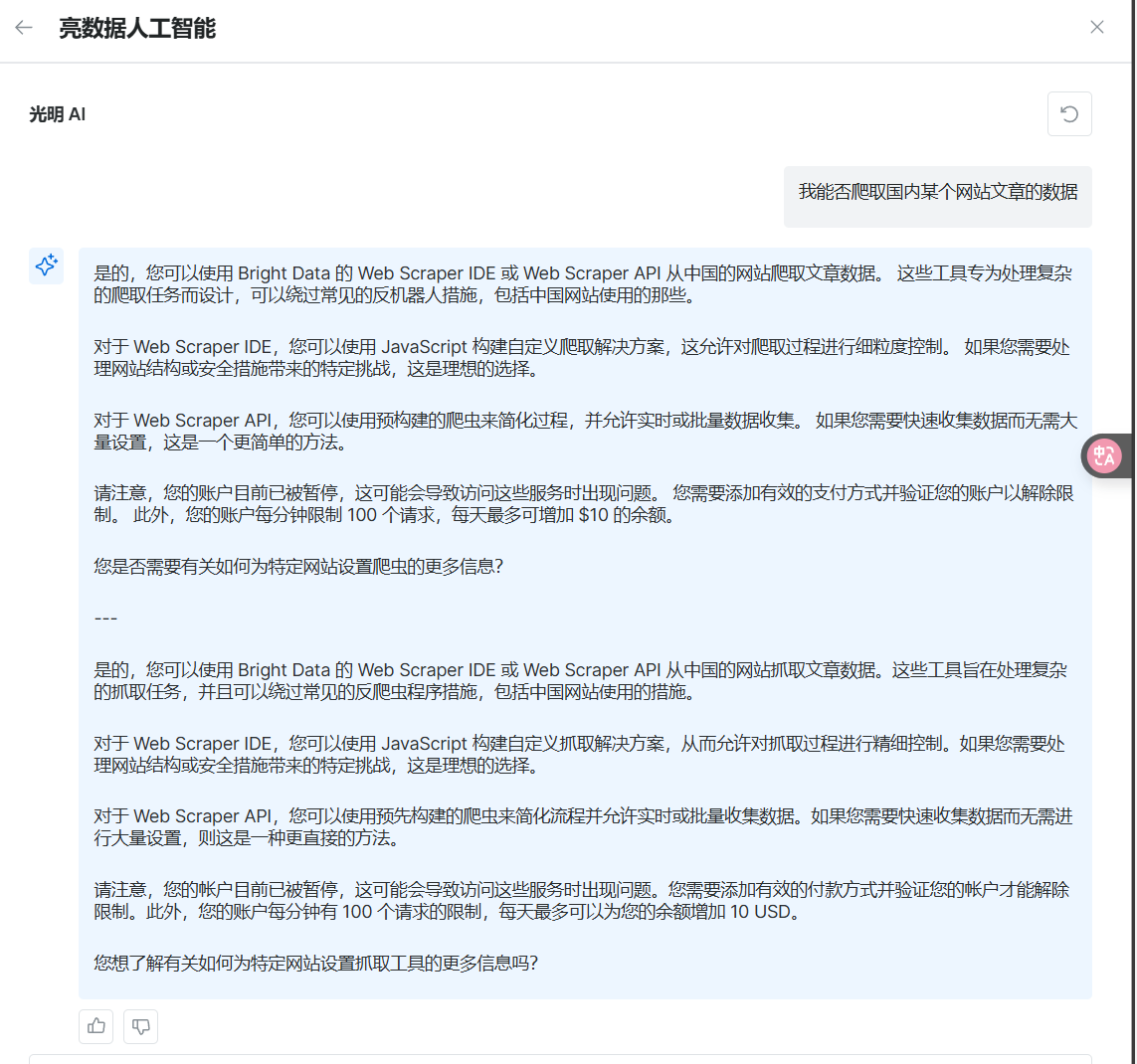
他会根据我们的账号信息以及实际的问题进行客观的评价分析
亮数据实战,对亚马逊网站数据的爬取操作
在电商行业竞争白热化的当下,精准的市场数据是卖家制定战略的核心依据。此前,我在使用亮数据进行亚马逊网页爬取操作时,原以为掌握了基础的爬取教程就能高枕无忧,却在实际业务需求中遭遇了意料之外的挑战。
按照常规爬取流程,使用传统的爬取操作,完成了亚马逊某品类下大量商品页面的基础数据采集,包括商品标题、价格、销量等信息。然而,当将这些数据用于选品决策时,问题逐渐暴露出来。我们发现,爬取的数据中商品评价的关键词缺失严重,而这些关键词恰恰能反映消费者痛点与需求偏好,对于挖掘潜在爆款商品至关重要。经过排查,发现是亚马逊针对频繁访问行为设置了反爬虫机制,部分页面在爬取时触发了验证环节,导致评价数据无法完整获取。
为解决这一问题,我进一步优化了亮数据的使用策略。首先,利用亮数据的动态 IP 轮换功能,模拟不同地区、不同用户的访问行为,降低被亚马逊识别为爬虫的概率。同时,结合亮数据的智能代理池,设置合理的请求间隔,避免短时间内大量请求同一页面。此外,针对触发验证环节的页面,通过亮数据的会话管理功能,模拟真实用户手动操作流程,完成验证后再继续数据采集。经过一系列优化,不仅成功获取了完整的商品评价关键词数据,还显著提高了数据采集的稳定性与准确性。基于这些完整的数据,我们精准定位到了消费者对某类家居用品在材质环保性、收纳便捷性方面的强烈需求,据此调整选品策略,最终肯定可以保证推出的新品在市场上获得出色的销量表现。
下面就是我如何通过亮数据解决这个问题
我们在Proxies & Scraping中找到我们的这个浏览器API,点击开始。我们这里是可以对选中的浏览器进行抓取的操作
运行和缩放远程浏览器,内置解锁用于Web导航,交互和数据提取
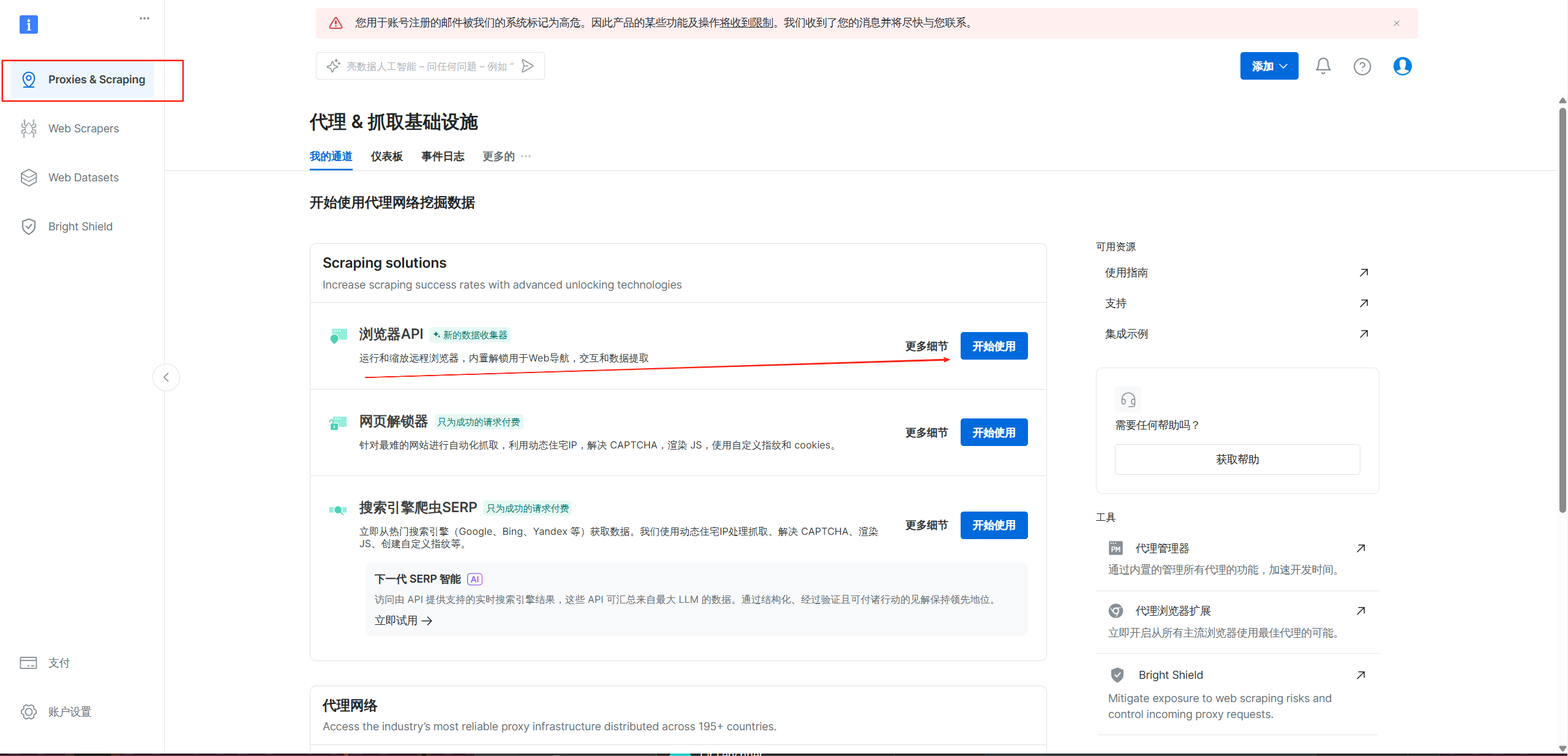
点击详情可以发现这个功能还是很强大的,可以进行全自动解锁操作,什么验证码解锁、浏览器指纹都不在话下
如果你对这个感兴趣的话,是可以点击右边的与专家进行交谈,获取技术细节
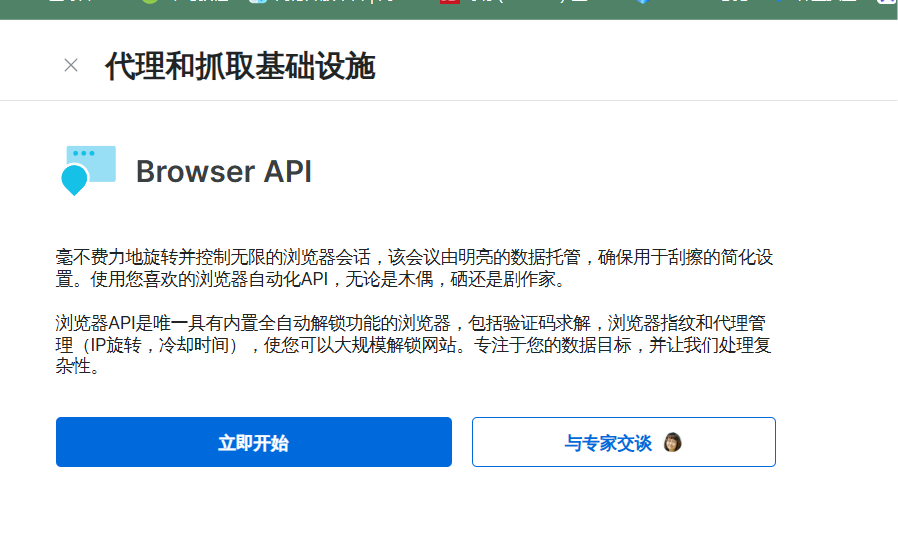
接下来我们点击立即开始,进入到设置界面之后,我们需要根据自己的要求进行操作的选择,并且这里我们看到后面两个选项是只为成功的请求进行付费,这个还是很不错的,用多少扣多少
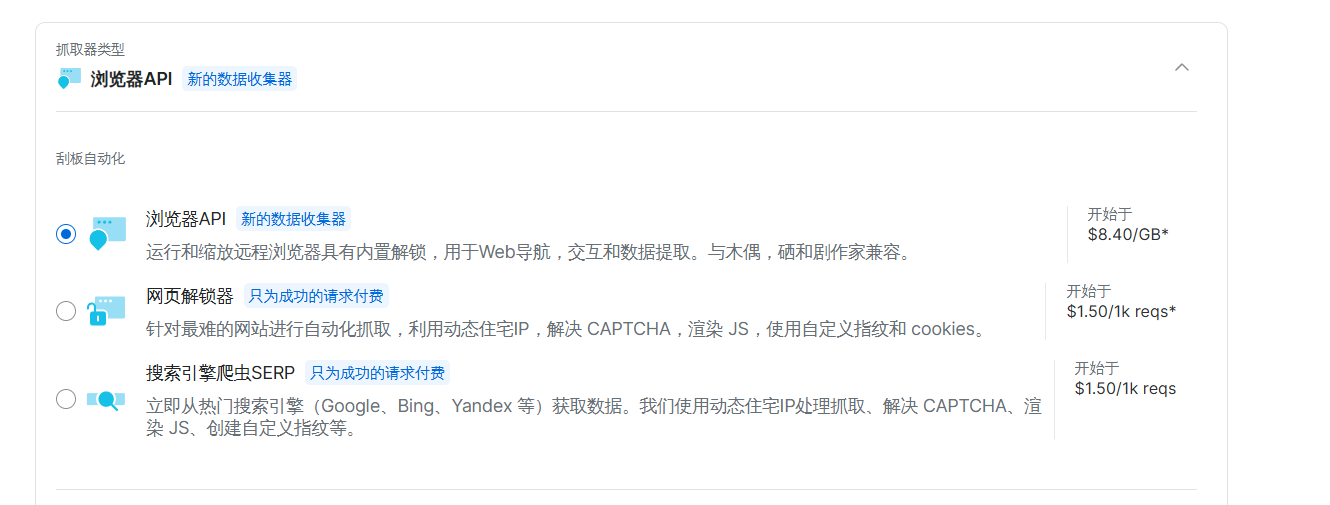
我们这里选择中间的这个份网页解锁器就ok了,针对最难的网站进行自动化抓取,利用动态住宅IP,解决 CAPTCHA,渲染 JS,使用自定义指纹和 cookies。
下面是几种抓取器的介绍
浏览器 API
可远程操控浏览器,实现 Web 导航、网页交互及数据提取,适用于需解析 JavaScript 渲染内容或借助自动化工具进行网页数据采集的场景 。比如批量抓取需 JavaScript 渲染页面的数据。
网页解锁器
针对反爬虫机制严苛的网站,利用动态住宅 IP、解决验证码、渲染 JS 、运用自定义指纹和 cookies 等方式,实现自动化网页数据抓取,满足大规模、高难度数据采集需求 。像从有复杂反爬措施的电商网站获取商品信息。
搜索引擎爬虫 SERP
从 Google、Bing 等热门搜索引擎获取数据,处理抓取中验证码、JS 渲染等问题 ,用于搜索引擎结果相关数据采集,如关键词排名监测、搜索趋势分析等。
下面的代理的话也是根据自己的需求进行变换选择的,可以进行ip的随意变换,并且每个选项下面都有一个合理的解释,帮助你进行选择
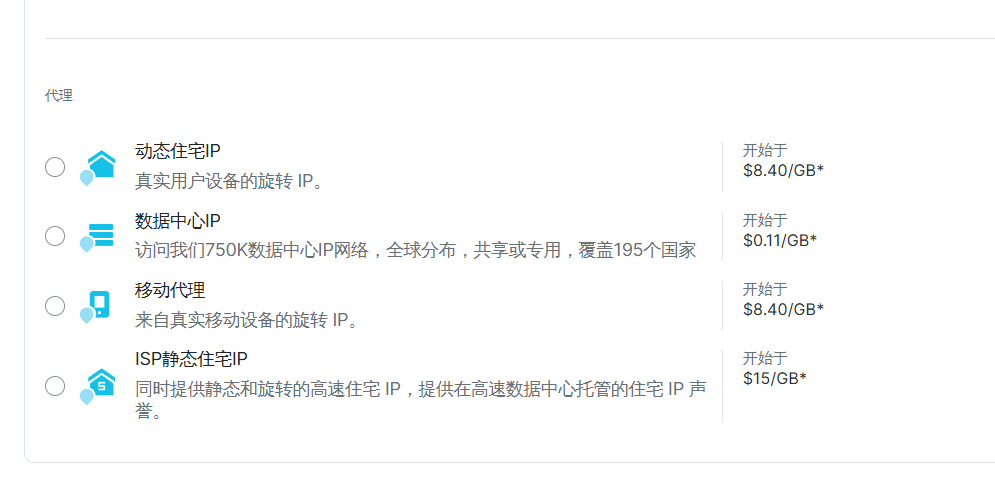
下面是几种代理的介绍
动态住宅IP
模拟真实用户设备的动态 IP,用于突破网站 IP 访问限制,适用于需大量真实 IP 模拟用户行为的大规模数据采集场景 。如电商竞品数据监测。
数据中心 IP
依托全球分布的 750K 数据中心 IP 网络,提供高速访问 ,适用于简单网站的数据采集或对访问速度要求高的场景,如快速获取新闻资讯网站数据。
移动代理
模拟真实移动设备 IP,用于采集需移动设备访问权限或适配移动设备网页的数据 。比如采集移动 APP 内特定数据。
ISP 静态住宅 IP
提供静态和旋转的高速住宅 IP,利用其住宅 IP 声誉,适用于对 IP 稳定性和真实性有要求的数据采集、网络测试等场景 。如金融行业相关数据合规采集。
接下来我们进行基本的设置,通道名称的话就是自定义的,但是后期是不能进行更改操作的,通道描述可以随便输入个描述
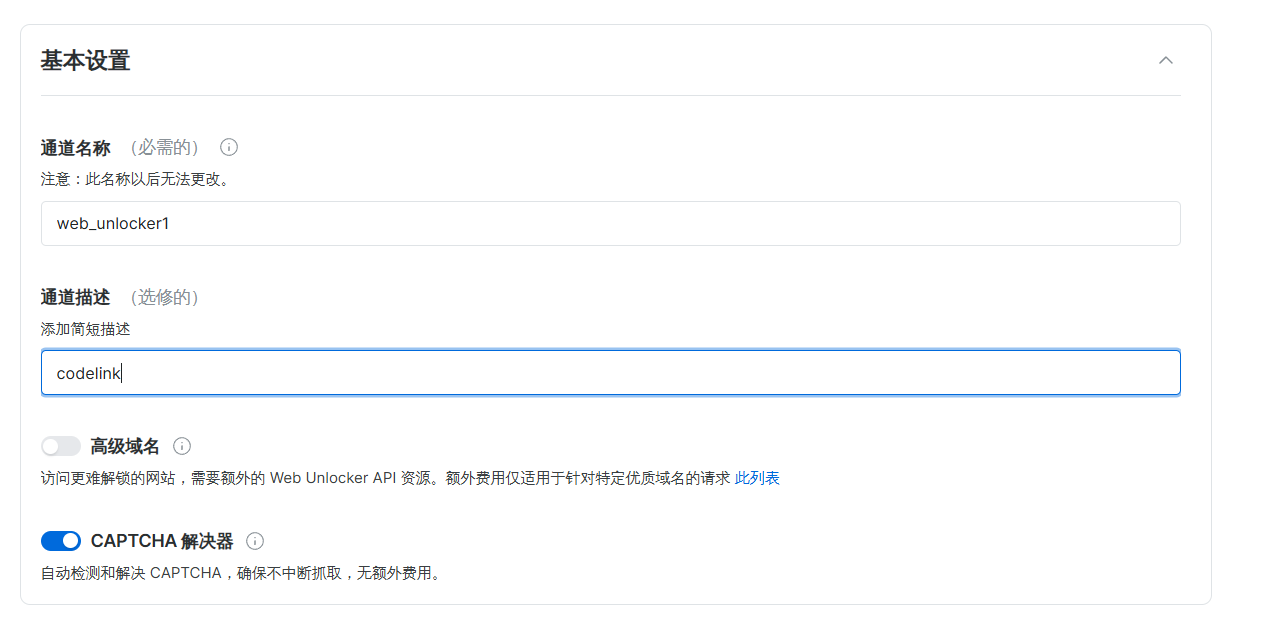
这里还有高级设计,根据你自己的需求进行设置
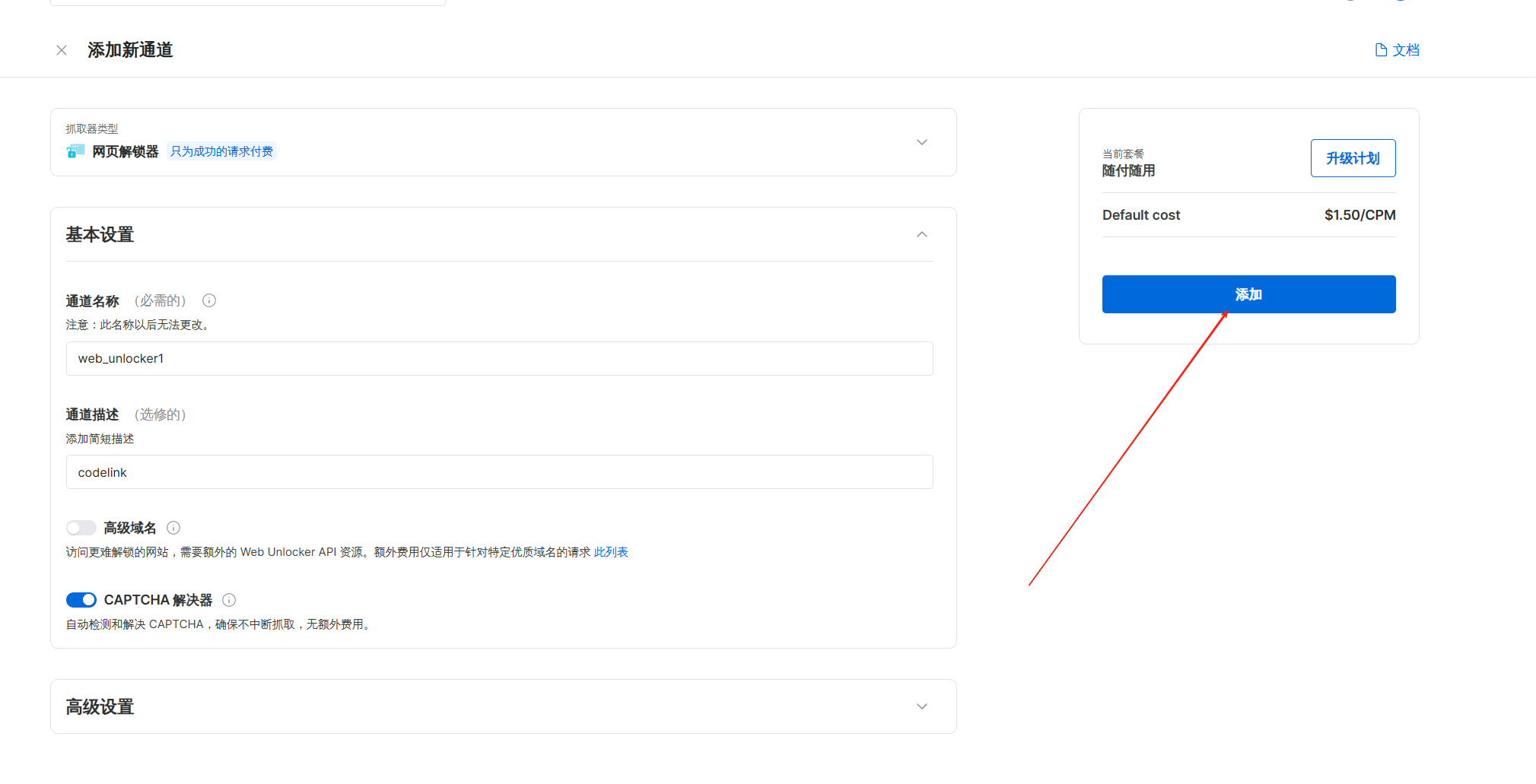
最后我们点击添加操作就行了,添加这个我们设置的通道
点击确定

这里我们需要添加下信息,对于新用户来说,他一开始会送5美元的额度供我们体验
这里我们需要进行本地的证书的安装操作,跟着教程一步步进行导入就行了
进入到控制台之后,我们可以看到概览、配置和代码示例
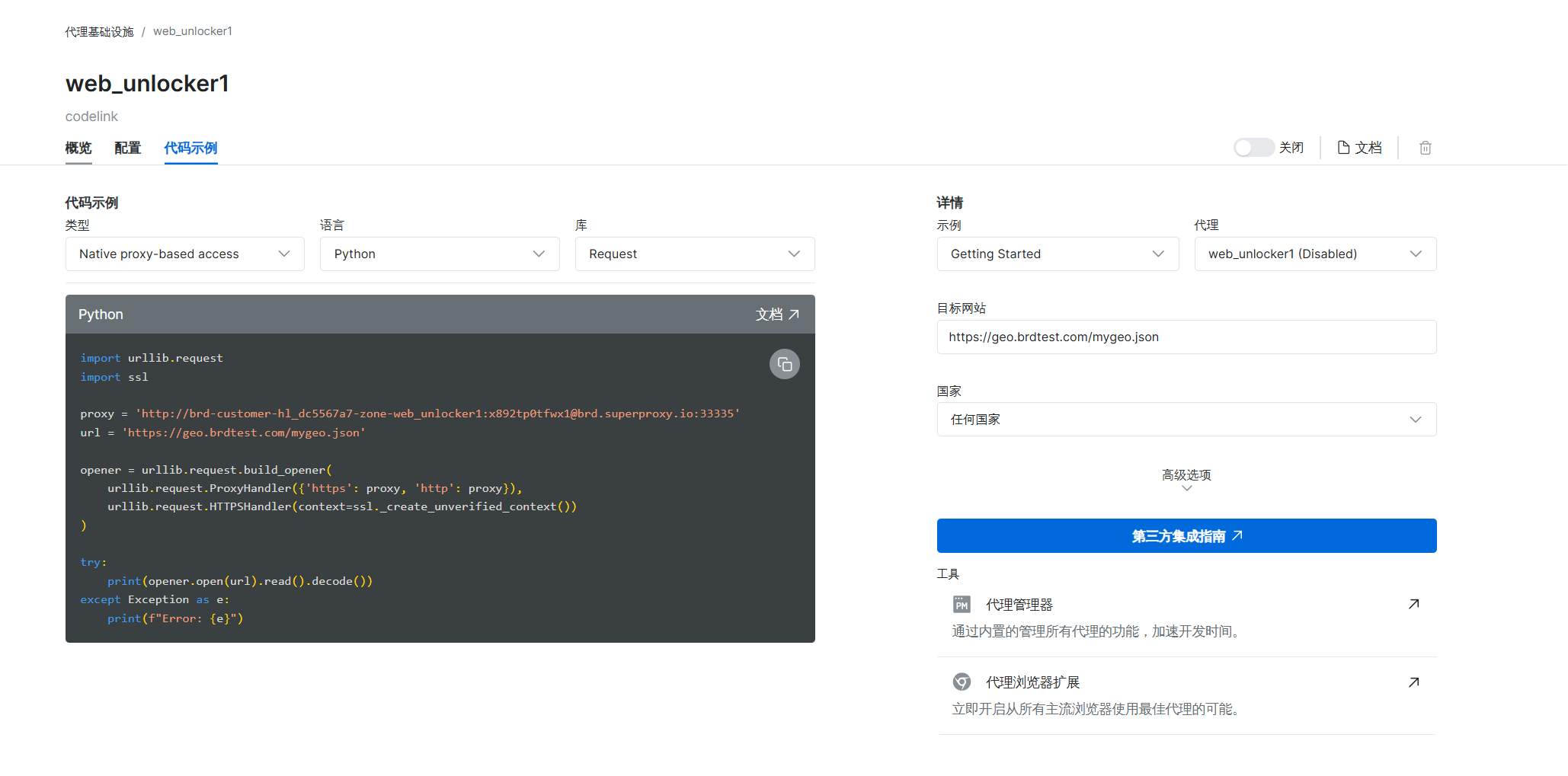
可以按照我下方的实例进行操作,语言选择Python,国家选择美国,网站的话就是亚马逊
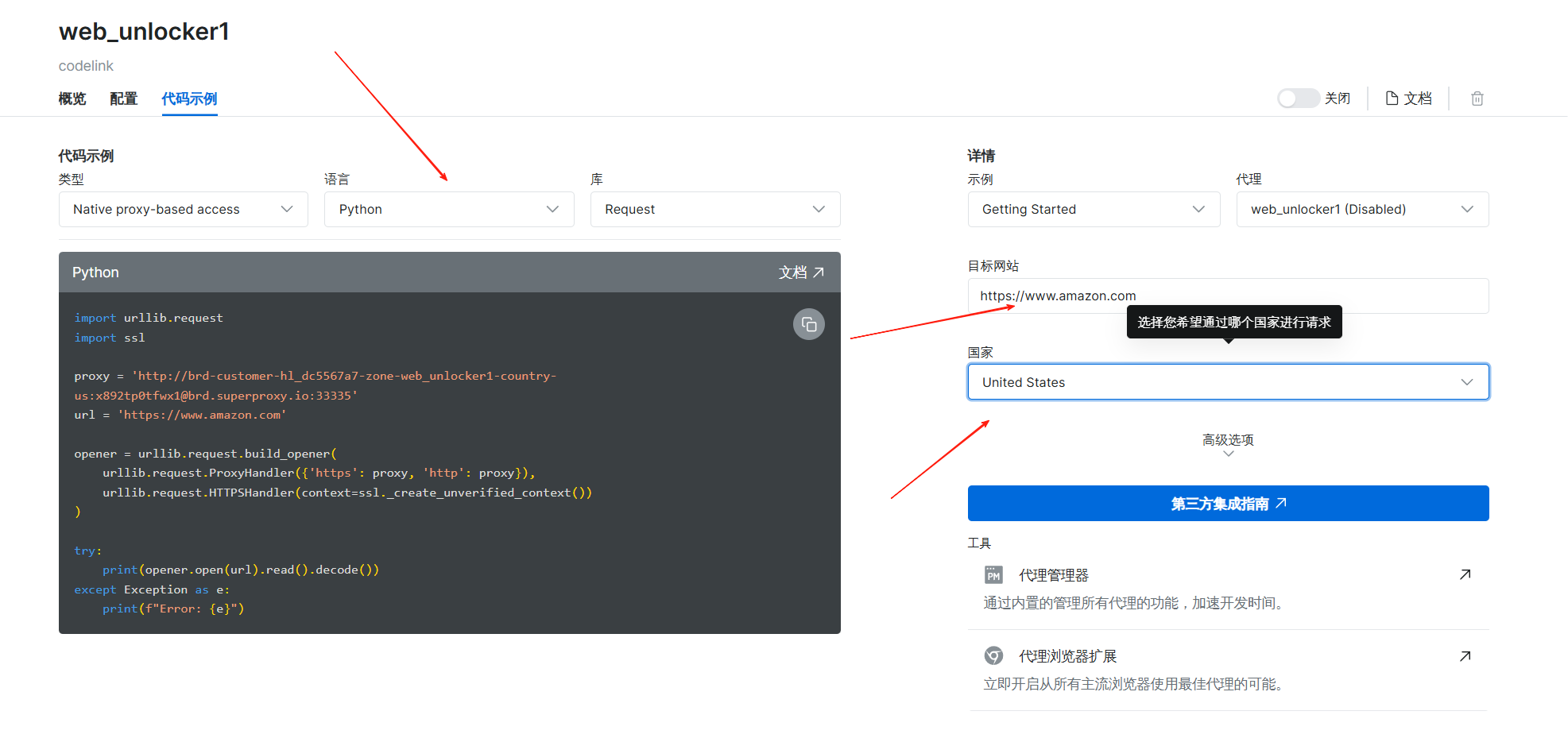
左侧的代码他会根据我们实际的配置进行改变的
下面是我的示例代码
import urllib.request
import ssl
proxy = 'http://brd-customer-hl_dc5567a7-zone-web_unlocker1-country-us:x892tp0tfwx1@brd.superproxy.io:33335'
url = 'https://www.amazon.com'
opener = urllib.request.build_opener(
urllib.request.ProxyHandler({'https': proxy, 'http': proxy}),
urllib.request.HTTPSHandler(context=ssl._create_unverified_context())
)
try:
print(opener.open(url).read().decode())
except Exception as e:
print(f"Error: {e}")
我们这边还可以点击文档查看具体的API调用操作
API调度文档
通过本地编译器的ai,我们很快就能将代码进行生成了
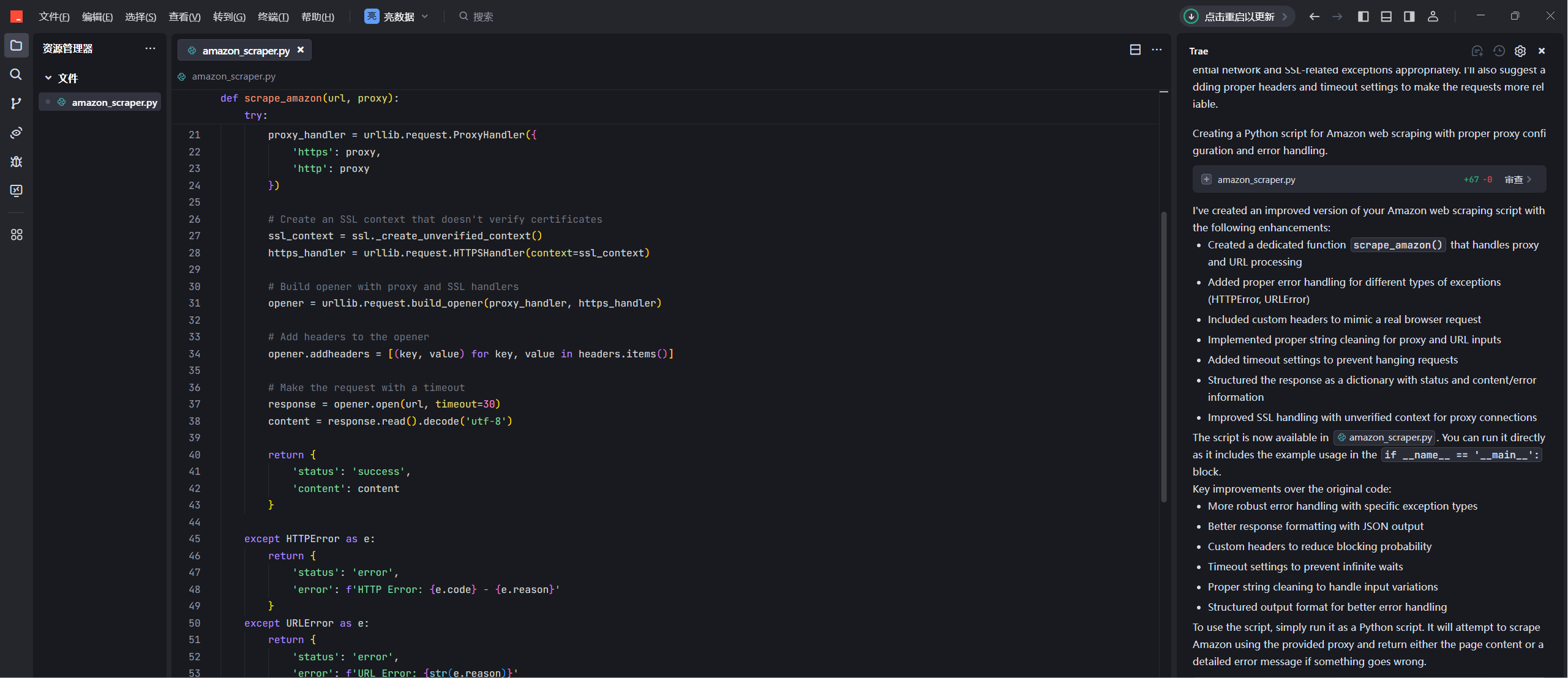
结果输出的数据有点混乱,因为我们是自己调用的,没有经过数据分析和处理操作的
所以这里就使用我们官方模版进行亚马逊电商数据的获取,官方的模版获取到的数据都是井井有条的,对应的数据放在一起的,不会出现数据错乱的现象,我们是不需要进行后期的数据处理和分析操作的
我们在网页抓取器这里搜索我们的amazon.com这个域
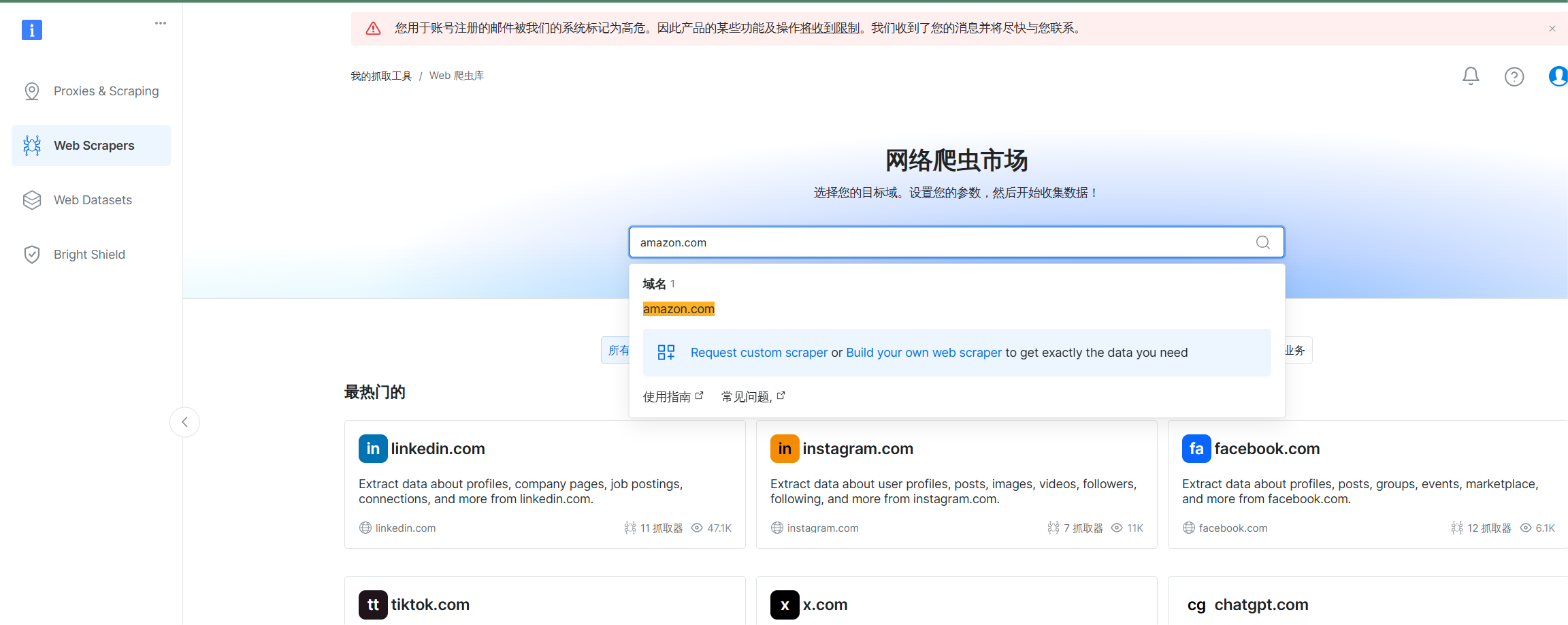
进入到页面后,我们选择我们所需要的要求,这里我就选择了Amazon products global dataset - discover by brand
这个的功能就是从品牌网站搜集产品
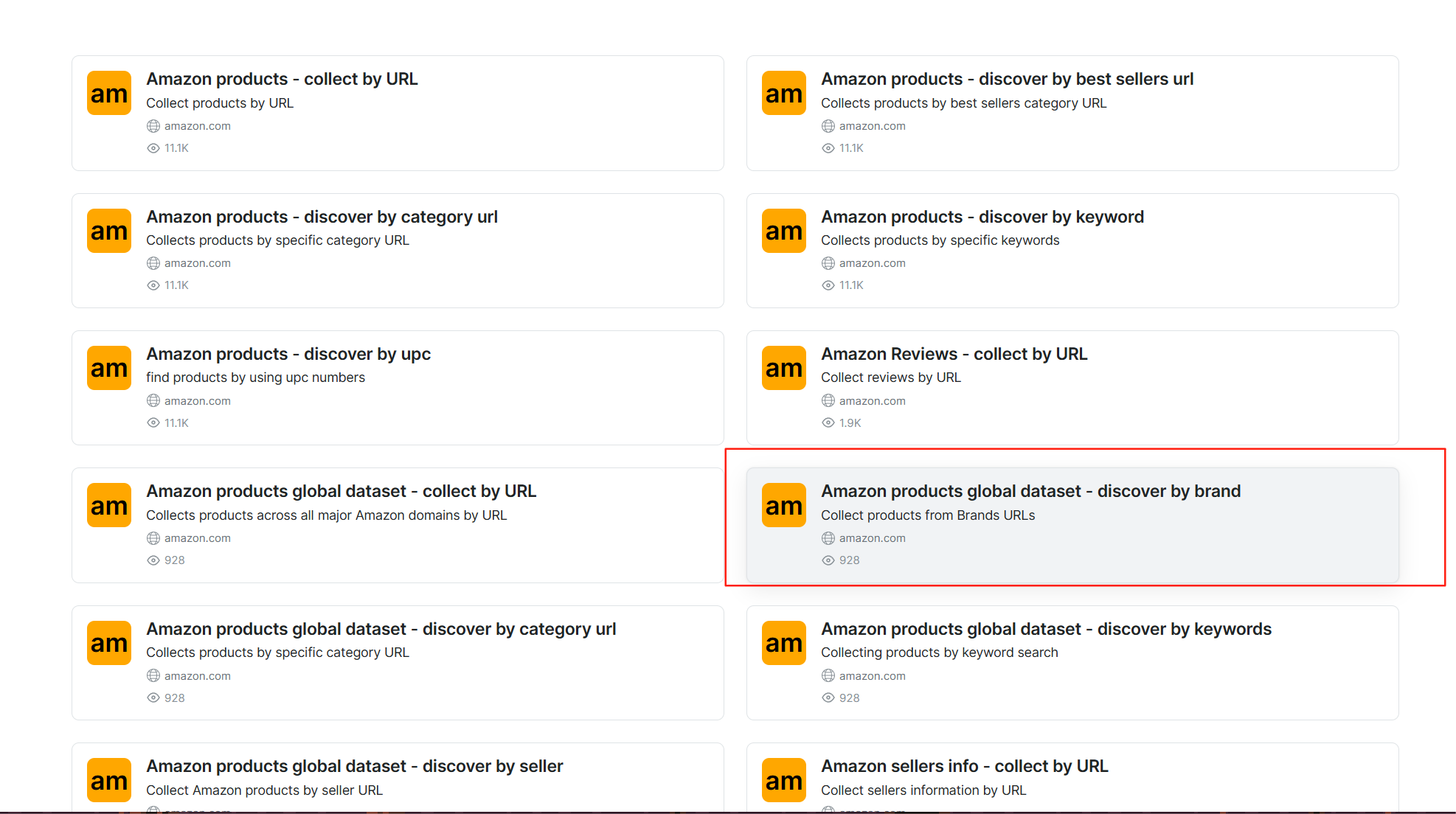
选择左侧的爬虫API就行了
这里我们需要将细节改成CSV
保存的文件路径就选择本地的一个文件路径就行行了,我们可以本地创建一个空文件夹进行保存就行了
代码的语言我们就选择Python就行了
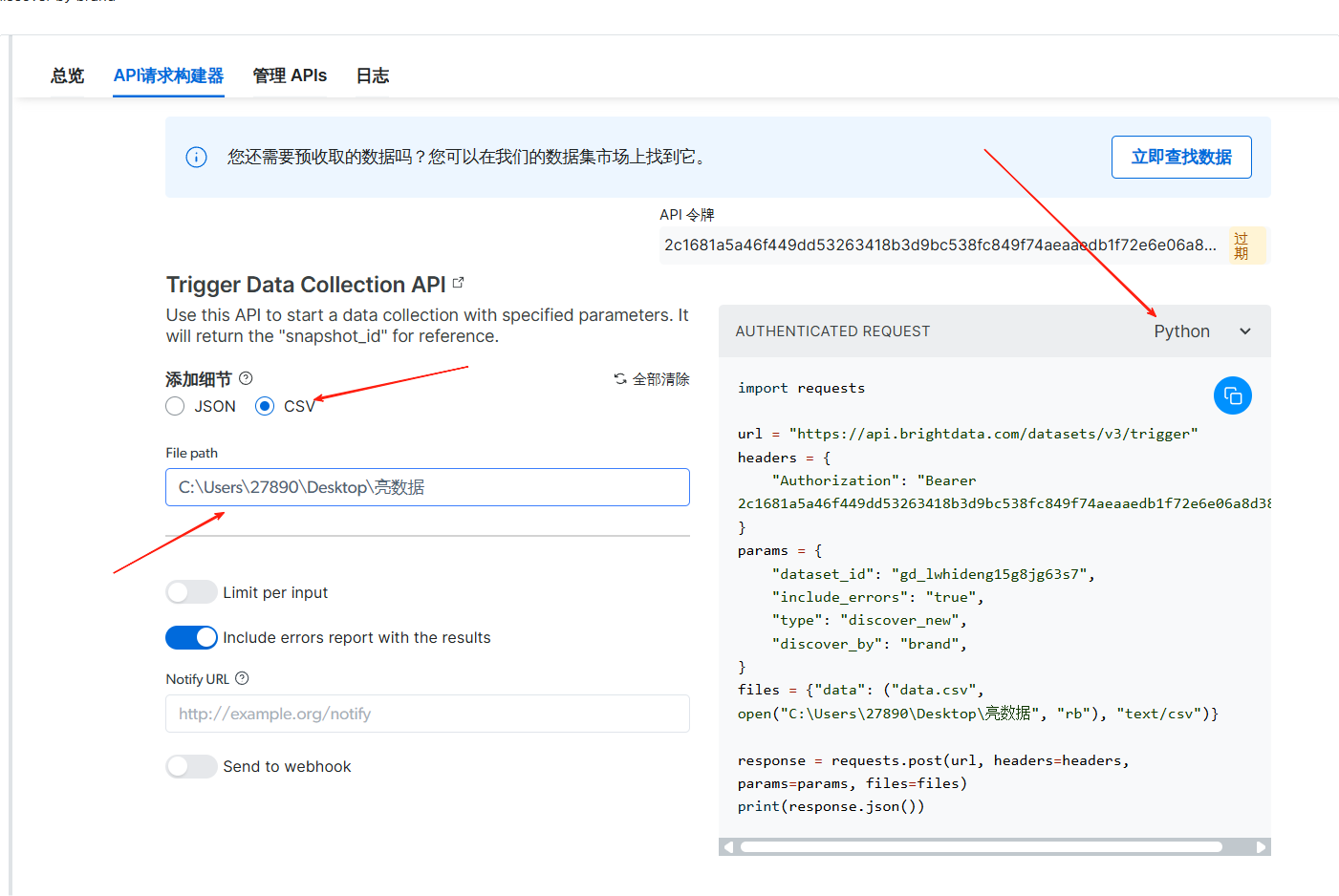
我们将代码复制到本地的文件,进行命令行运行操作
然后稍等一会儿就能看到我们的


如果你搜索的产品是没有的话,他这里是不会进行数据的显示的
并且我们是可以进行数据下载的

将访问出来的数据以表格的形式呈现在我们的眼前
我们选择这个Amazon products-discover by keyword
这个就是按照关键词进行搜索,输入商品的关键词就能搜索到具体的数据
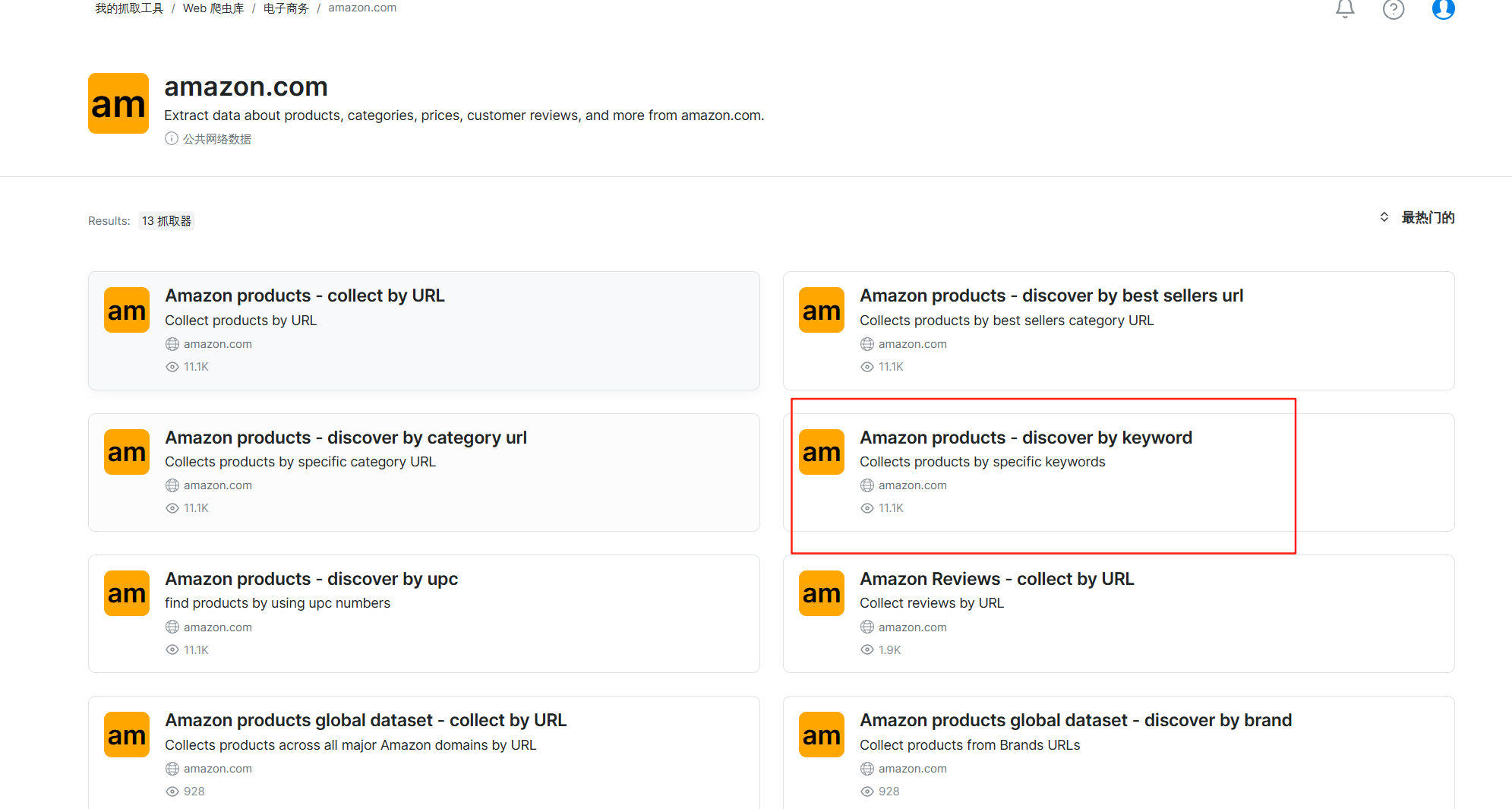
选择左侧的爬虫API
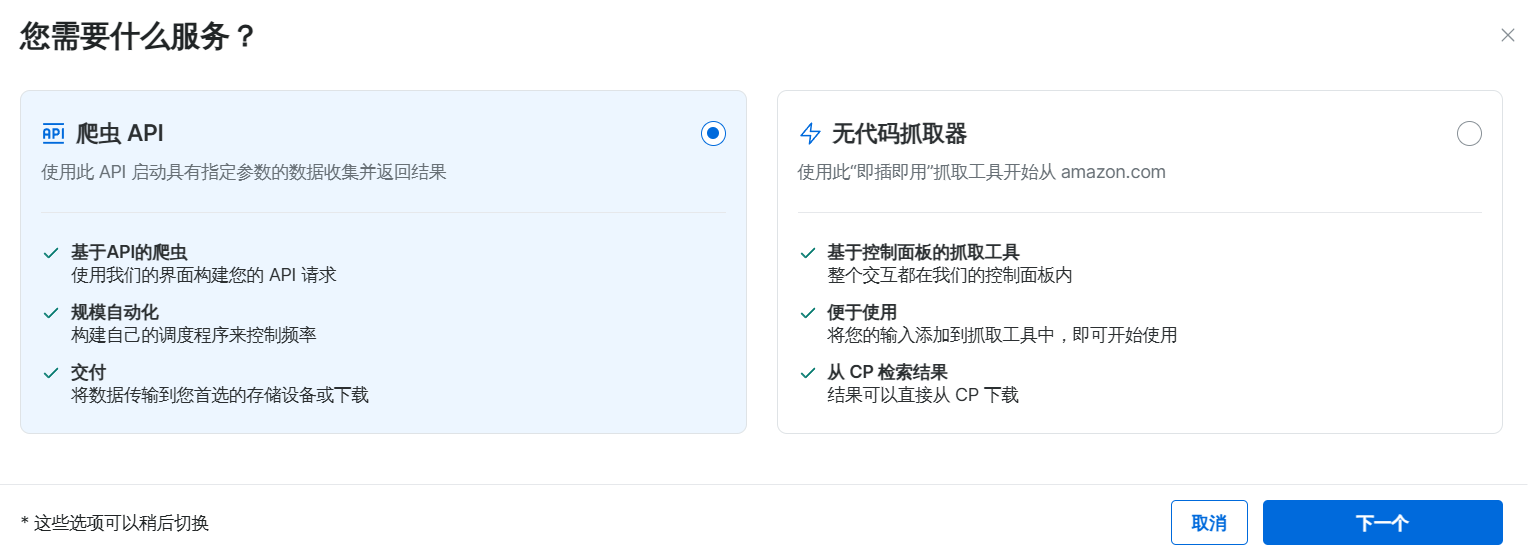
进入到页面之后我们打开这个Deliver results to external storage
直接使用默认的Amazon S3作为爬取结果服务器存储
下面的桶我们就输入一个自定义的名称就行了
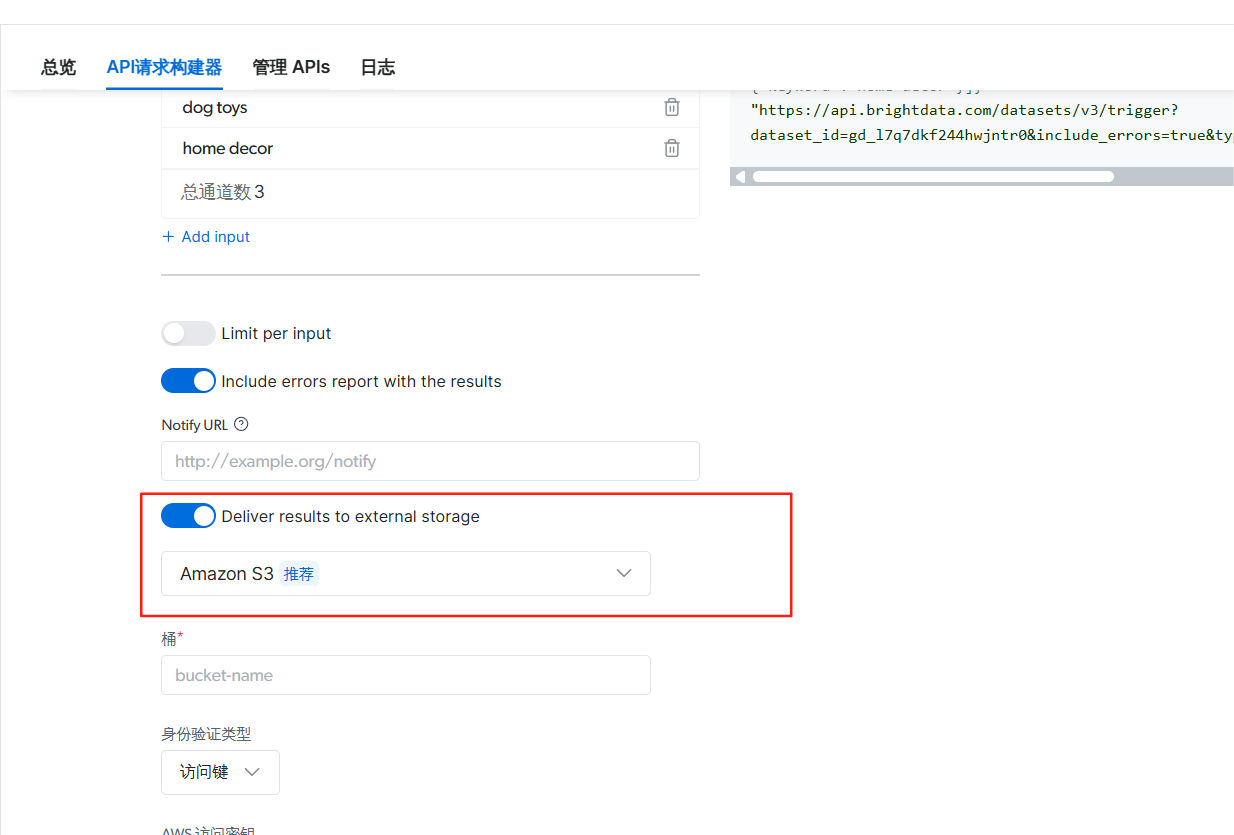
在右侧选择Python代码进行api的调用操作
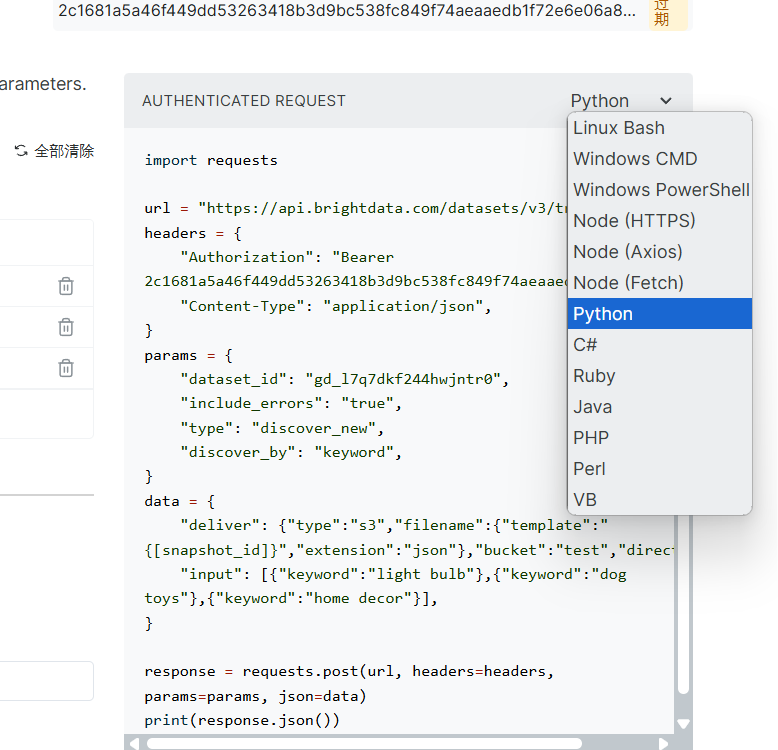
将代码复制后,将代码贴到本地的编译器里面进行命令行运行操作
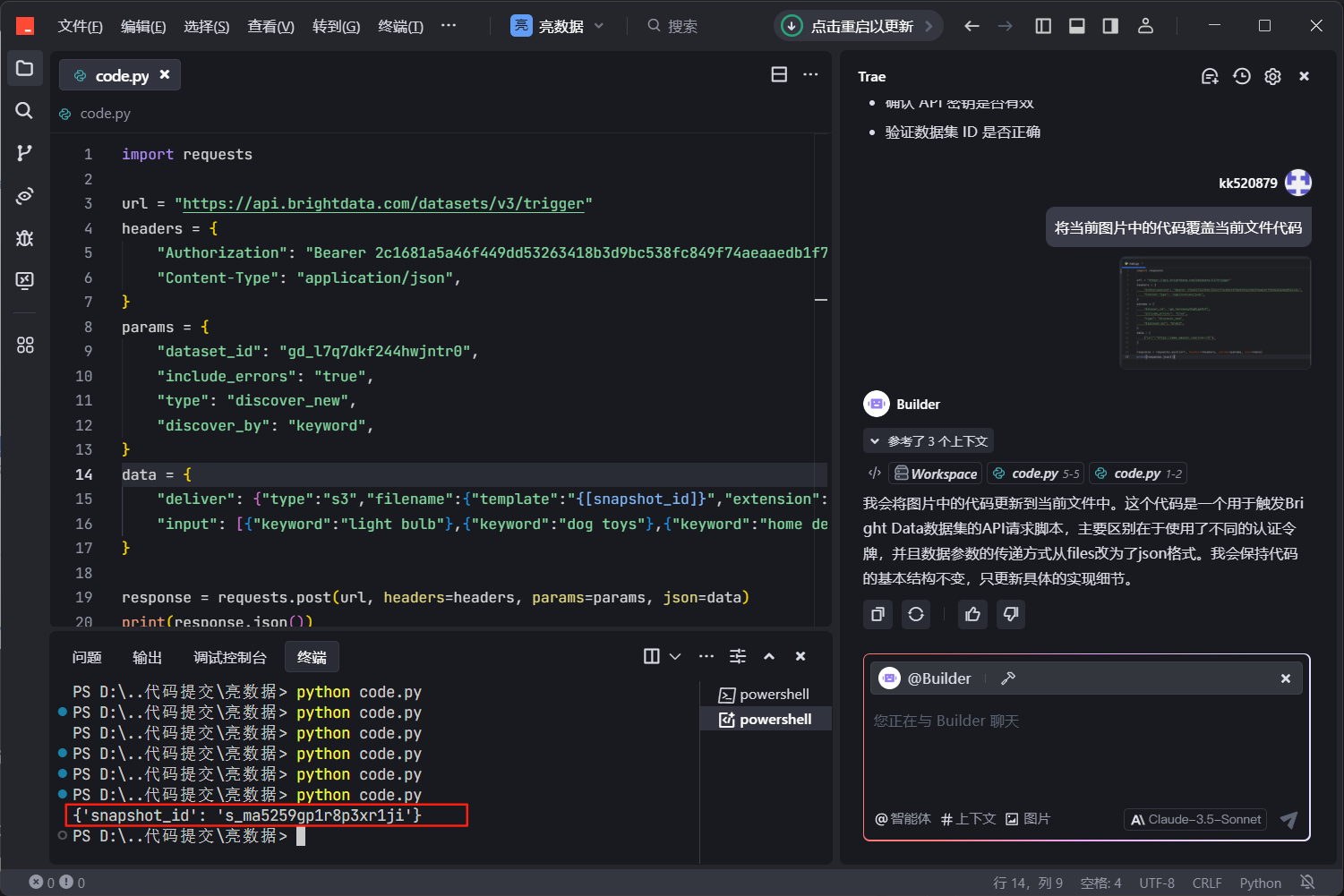
但是这个时候代码反馈快照id,说明我们调用成功了

我们回到日志界面,可以看到我们的数据是正在采集中的
这里我们等个几分钟就可以进行数据的观察了
这里我们等了8分钟他就将数据归纳好了
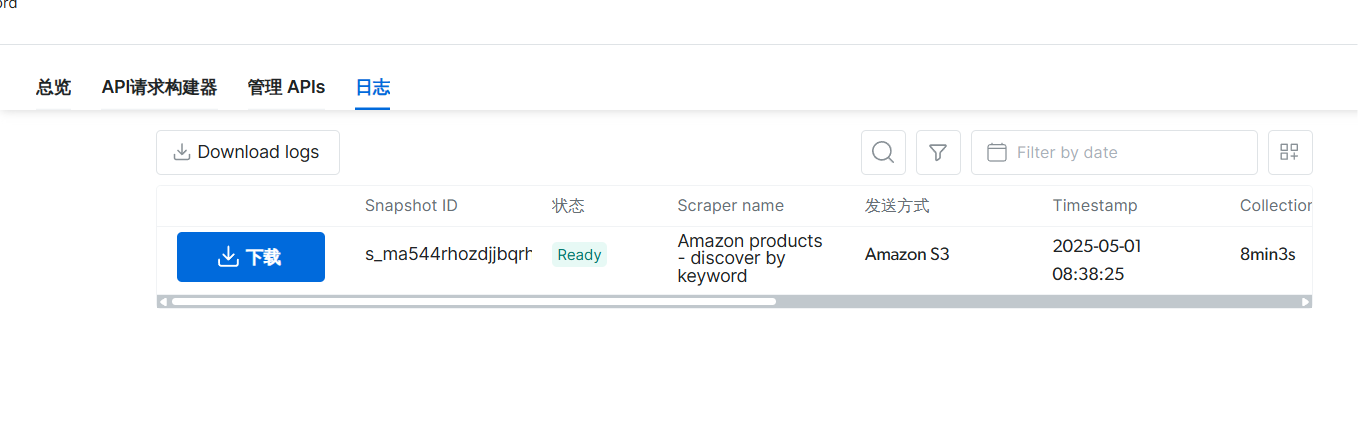
我们直接点击下载就行了,打开文件可以看到十分具体的数据,并且数据量还很大,很难相信亮数据通过8分钟就能爬取亚马逊网站上对应的信息,真的很厉害
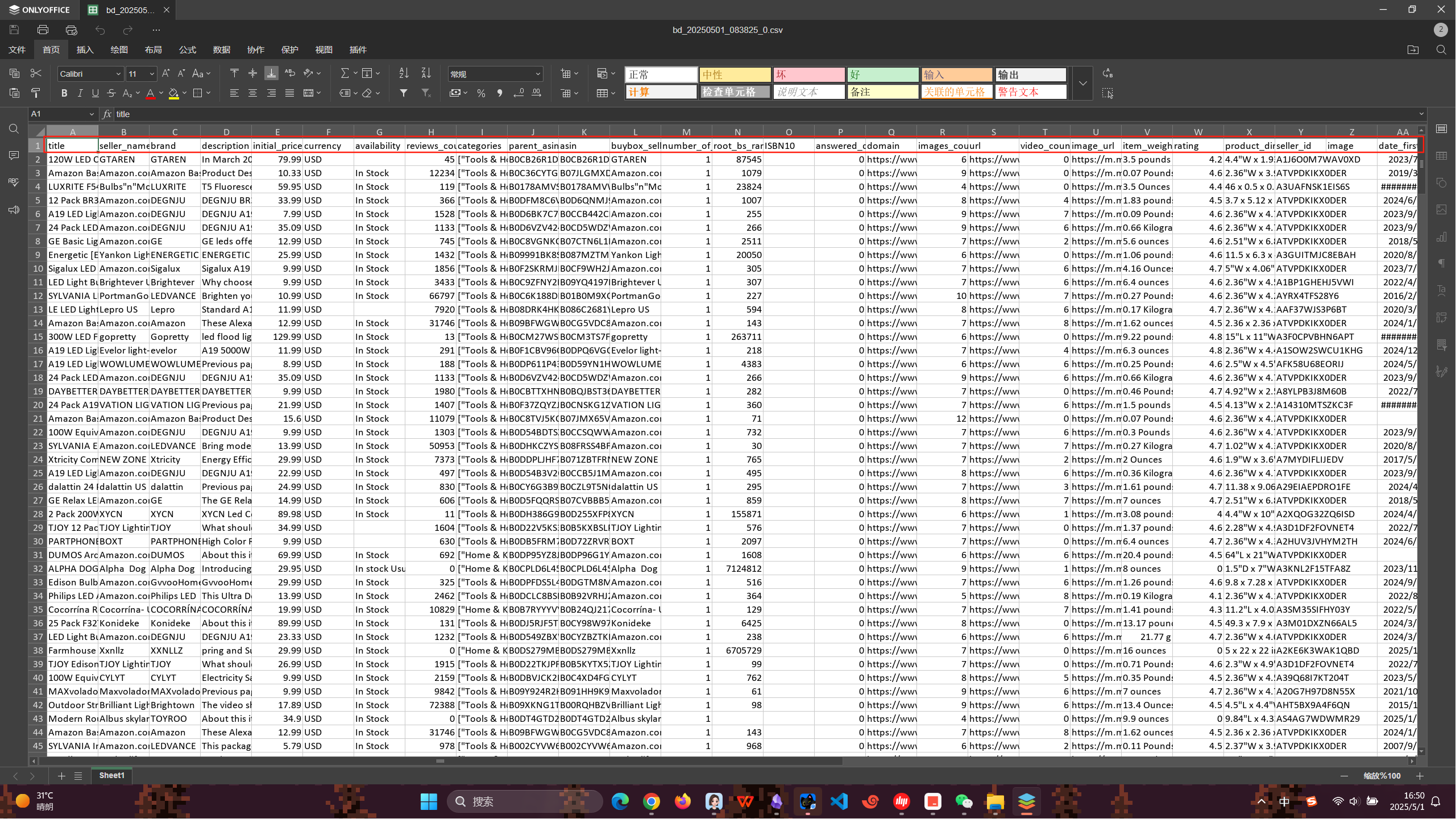
亮数据的爬取效率可见是十分出众,凭借先进的算法和高效的技术架构,能够在短时间内处理海量数据,大大缩短了数据收集的周期,为后续的数据分析和应用节省了宝贵的时间成本。同时,亮数据拥有出色的灵活性和适应性,可针对不同类型的网站和数据源进行定制化爬取,轻松应对各种复杂的网络环境和反爬机制。
使用GPT 4O大模型进行数据爬取表格分析
这里我们直接让我们的GPT帮我们进行大数据的分析操作
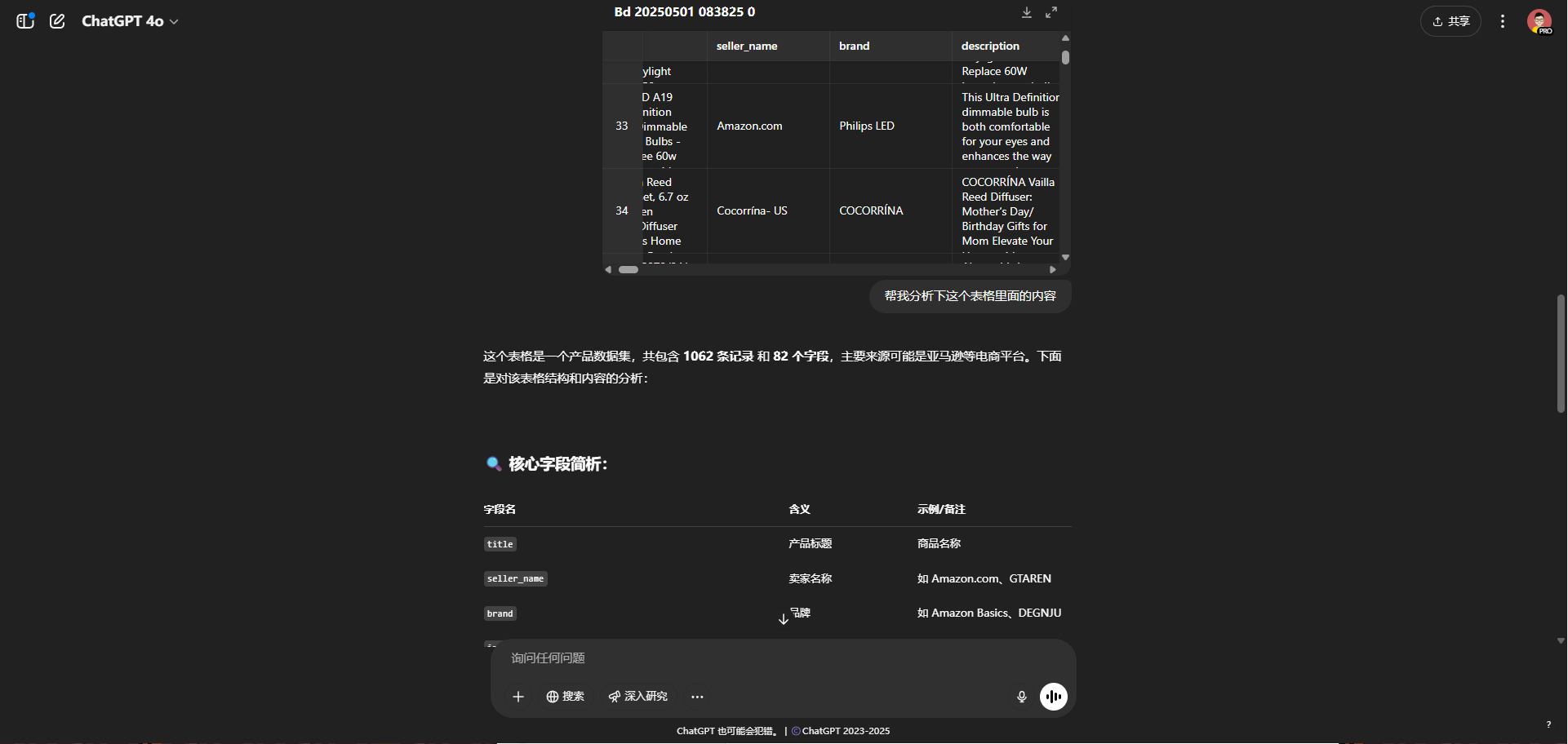
并且可以进行表格数据的生成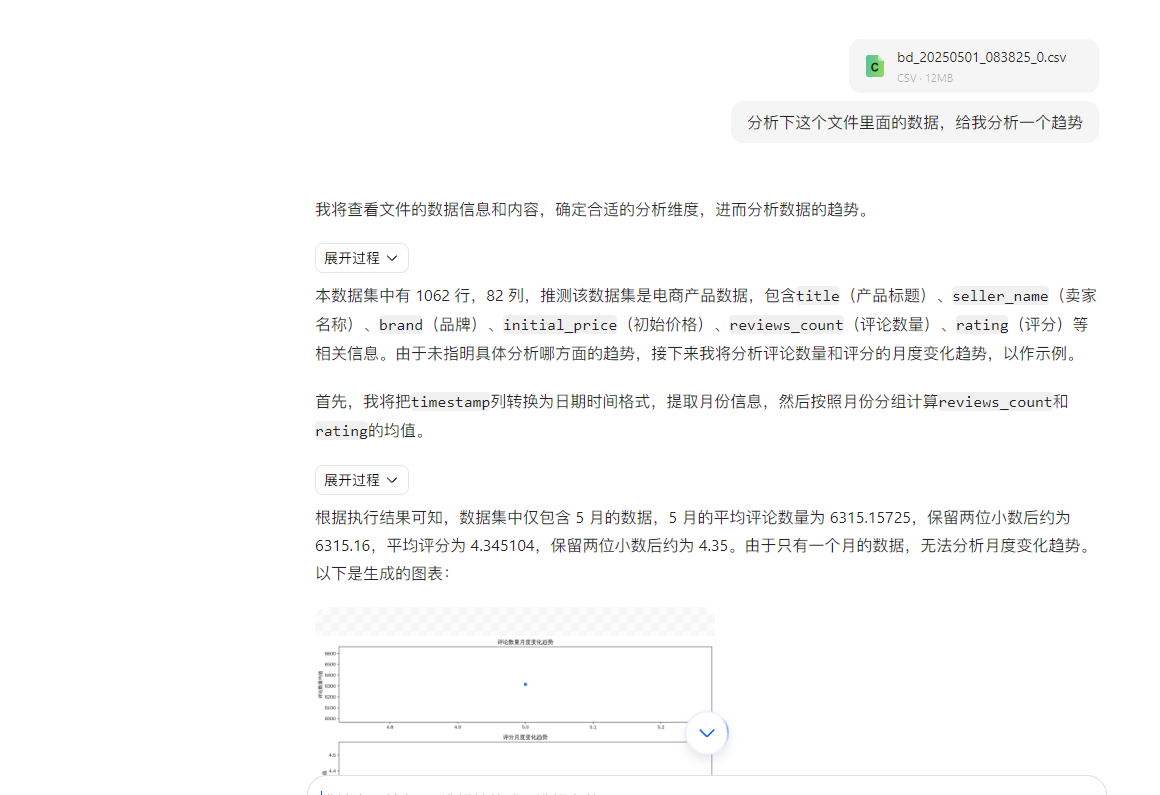
以及通过ai的分析,我们能更快获取民众的购买去向
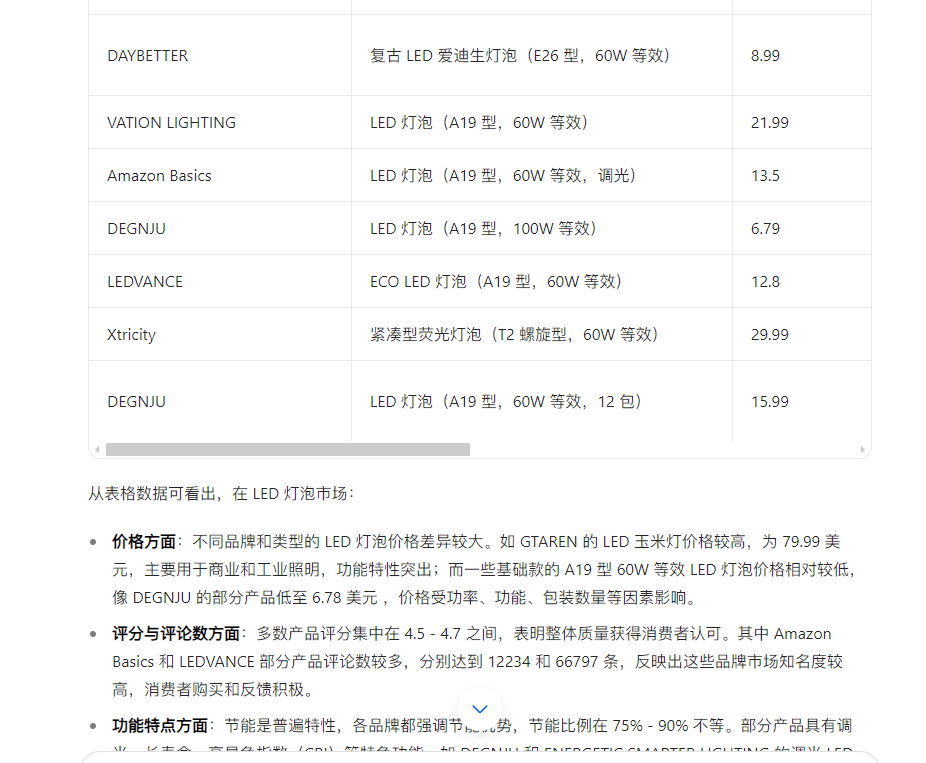
下面是ai的回答,
- 价格方面:不同品牌和类型的 LED 灯泡价格差异较大。如 GTAREN 的 LED 玉米灯价格较高,为 79.99 美元,主要用于商业和工业照明,功能特性突出;而一些基础款的 A19 型 60W 等效 LED 灯泡价格相对较低,像 DEGNJU 的部分产品低至 6.78 美元 ,价格受功率、功能、包装数量等因素影响。
评分与评论数方面:多数产品评分集中在 4.5 - 4.7 之间,表明整体质量获得消费者认可。其中 Amazon Basics 和 LEDVANCE 部分产品评论数较多,分别达到 12234 和 66797 条,反映出这些品牌市场知名度较高,消费者购买和反馈积极。- 功能特点方面:节能是普遍特性,各品牌都强调节能优势,节能比例在 75% - 90% 不等。部分产品具有调光、长寿命、高显色指数(CRI)等特色功能,如 DEGNJU 和 ENERGETIC SMARTER LIGHTING 的调光 LED 灯泡,以及 Brightever 高 CRI 90 + 的产品,满足不同消费者对光线品质和使用场景的需求。
总结
亮数据与 AI 技术相辅相成,为电商产业提供了强大的数据基础与智能化的运营手段。它们助力电商企业在激烈的市场竞争中,更精准地把握市场需求,优化运营流程,提升服务质量与竞争力,推动电商产业朝着更加高效、智能、创新的方向持续发展 。
感兴趣的可以点击下方链接进行注册哦!
https://get.brightdata.com/h96id4


















 6488
6488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











