









Scrapy的crawlSpider爬虫
1. crawlSpider 是什么?
crawlSpider是Scrapy的派生类,Spider类的设计原则是 只爬取start_url列表中的网页, 而crawlSpider类定义了一些规则(rule) 来提供跟进link的方便的机制。从爬取的网页中获取link并继续爬取
crawlSpider 能够匹配满足条件的url地址,组装成Request对象后自动发送给引擎,同时能够指定callback函数
即: CrawlSpider 爬虫可以按照规则自动获取连接
2. 创建crawlSpider爬虫:
scrapy genspider -t crawl 爬虫名 域名
即创建 amazon爬虫命令:
scrapy genspider -他crawl amzonTop amazon.com
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TSpider(CrawlSpider):
name = 'amzonTop '
allowed_domains = ['amazon.com']
start_urls = ['https://amazon.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
return item
rurles 是一个元组或者是列表,包含的是Rule对象
Rule 表示规则,其中包含LinkExtractor,callback和follow等参数
LinkExtractor:链接提取器,可以通过正则,xpath,css 来进行url地址的匹配
callback:提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
follow: 提取出来的url地址对应的响应是否还会继续被rules中的规则进行提取。True:表示会。False表示不会
3.爬取amazon商品数据:
1.创建amaozn爬虫:
scrapy genspider -t crawl amazonTop2 amazon.com
项目结构:
- 提取商品列表页翻页的url和商品详情页的url
提取商品列表页所有商品Asin、rank(商品排名)------即获取所有蓝色框的Asin和rank
提取商品详情页所有的颜色Asin、规格的Asin ------ 即获取所有绿色框的Asin,绿色框包含了蓝色框的Asin
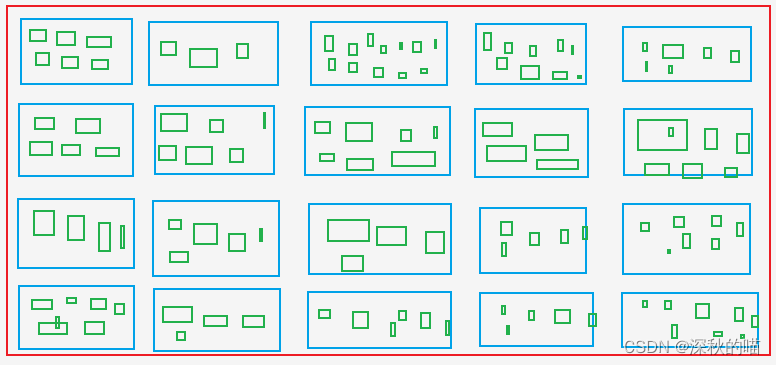
绿色框:就好比购物网站衣服的 尺码 S M L XL XXL
爬虫文件:amzonTop2.py
import datetime
import re
import time
from copy import deepcopy
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class Amazontop2Spider(CrawlSpider):
name = 'amazonTop2'
allowed_domains = ['amazon.com']
# https://www.amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2?_encoding=UTF8&pg=1
start_urls = ['https://amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2']
# rule 提取url
rules = [
Rule(LinkExtractor(restrict_css=('.a-selected','.a-normal')), callback='parse_item', follow=True),
]
def parse_item(self, response):
asin_list_str = "".join(response.xpath('//div[@class="p13n-desktop-grid"]/@data-client-recs-list').extract())
if asin_list_str:
asin_list = eval(asin_list_str)
for asinDict in asin_list:
item = {}
if "'id'" in str(asinDict):
listProAsin = asinDict['id']
pro_rank = asinDict['metadataMap']['render.zg.rank']
item['rank'] = pro_rank
item['ListAsin'] = listProAsin
# 产品详情页链接
item['rankAsinUrl'] =f"https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{listProAsin}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
print("-"*30)
print(item)
print('-'*30)
yield scrapy.Request(item["rankAsinUrl"], callback=self.parse_list_asin,
meta={"main_info": deepcopy(item)})
def parse_list_asin(self, response):
"""
获取单个产品的所有分类子asin
:param response:
:return:
"""
news_info = response.meta["main_info"]
list_ASIN_all_findall = re.findall('"colorToAsin":(.*?),"refactorEnabled":true,', str(response.text))
try:
try:
parentASIN = re.findall(r',"parentAsin":"(.*?)",', str(response.text))[-1]
except:
parentASIN = re.findall(r'&parentAsin=(.*?)&', str(response.text))[-1]
except:
parentASIN = ''
# parentASIN = parentASIN[-1] if parentASIN !=[] else ""
print("parentASIN:",parentASIN)
if list_ASIN_all_findall:
list_ASIN_all_str = "".join(list_ASIN_all_findall)
list_ASIN_all_dict = eval(list_ASIN_all_str) # 转换为字典
for asin_min_key, asin_min_value in list_ASIN_all_dict.items():
if asin_min_value:
asin_min_value = asin_min_value['asin']
news_info['parentASIN'] = parentASIN
news_info['secondASIN'] = asin_min_value # 单个产品分类的子asin
news_info['rankSecondASINUrl'] = f"https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{asin_min_value}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
yield scrapy.Request(news_info["rankSecondASINUrl"], callback=self.parse_detail_info,meta={"news_info": deepcopy(news_info)})
def parse_detail_info(self, response):
"""
获取商品详情页信息
:param response:
:return:
"""
item = response.meta['news_info']
ASIN = item['secondASIN']
# print('--------------------------------------------------------------------------------------------')
# with open('amazon_h.html', 'w') as f:
# f.write(response.body.decode())
# print('--------------------------------------------------------------------------------------------')
pro_details = response.xpath('//table[@id="productDetails_detailBullets_sections1"]//tr')
pro_detail = {}
for pro_row in pro_details:
pro_detail[pro_row.xpath('./th/text()').extract_first().strip()] = pro_row.xpath('./td//text()').extract_first().strip()
print("pro_detail",pro_detail)
ships_from_list = response.xpath(
'//div[@tabular-attribute-name="Ships from"]/div//span//text()').extract()
# 物流方
try:
delivery = ships_from_list[-1]
except:
delivery = ""
seller = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//text()').extract()).strip().replace("'", "") # 卖家
if seller == "":
seller = "".join(response.xpath('//div[@class="a-section a-spacing-base"]/div[2]/a/text()').extract()).strip().replace("'", "") # 卖家
seller_link_str = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//a/@href').extract()) # 卖家链接
# if seller_link_str:
# seller_link = "https://www.amazon.com" + seller_link_str
# else:
# seller_link = ''
seller_link = "https://www.amazon.com" + seller_link_str if seller_link_str else ''
brand_link = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/@href').extract_first() # 品牌链接
pic_link = response.xpath('//div[@id="main-image-container"]/ul/li[1]//img/@src').extract_first() # 图片链接
title = response.xpath('//div[@id="titleSection"]/h1//text()').extract_first() # 标题
star = response.xpath('//div[@id="averageCustomerReviews_feature_div"]/div[1]//span[@class="a-icon-alt"]//text()').extract_first().strip() # 星级
# 售价
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[2]/span[@class="a-offscreen"]//text()').extract_first()
except:
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[1]/span[@class="a-offscreen"]//text()').extract_first()
except:
price = ''
size = response.xpath('//li[@class="swatchSelect"]//p[@class="a-text-left a-size-base"]//text()').extract_first() # 尺寸
# 颜色
key_v = str(pro_detail.keys())
brand = pro_detail['Brand'] if "Brand" in key_v else '' # 品牌
if brand == '':
brand = response.xpath('//tr[@class="a-spacing-small po-brand"]/td[2]//text()').extract_first().strip()
elif brand == "":
brand = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/text()').extract_first().replace("Brand: ", "").replace("Visit the", "").replace("Store", '').strip()
color = pro_detail['Color'] if "Color" in key_v else ""
if color == "":
color = response.xpath('//tr[@class="a-spacing-small po-color"]/td[2]//text()').extract_first()
elif color == '':
color = response.xpath('//div[@id="variation_color_name"]/div[@class="a-row"]/span//text()').extract_first()
# 图案
pattern = pro_detail['Pattern'] if "Pattern" in key_v else ""
if pattern == "":
pattern = response.xpath('//tr[@class="a-spacing-small po-pattern"]/td[2]//text()').extract_first().strip()
# 材质 material
try:
material = pro_detail['Material']
except:
material = response.xpath('//tr[@class="a-spacing-small po-material"]/td[2]//text()').extract_first().strip()
# 形状 shape
shape = pro_detail['Shape'] if "Shape" in key_v else ""
if shape == "":
shape = response.xpath('//tr[@class="a-spacing-small po-item_shape"]/td[2]//text()').extract_first().strip()
# style # 风格
# 五点描述
five_points =response.xpath('//div[@id="feature-bullets"]/ul/li[position()>1]//text()').extract_first().replace("\"", "'")
size_num = len(response.xpath('//div[@id="variation_size_name"]/ul/li').extract()) # 尺寸数量
color_num = len(response.xpath('//div[@id="variation_color_name"]//li').extract()) # 颜色数量
# variant_num = # 变体数量
# style # 样式链接
# manufacturer
# 厂商
try:
Manufacturer = pro_detail['Manufacturer'] if "Manufacturer" in str(pro_detail) else " "
except:
Manufacturer = ""
item_weight = pro_detail['Item Weight'] if "Weight" in str(pro_detail) else '' # 商品重量
product_dim = pro_detail['Product Dimensions'] if "Product Dimensions" in str(pro_detail) else '' # 商品尺寸
# product_material
# 商品材质
try:
product_material = pro_detail['Material']
except:
product_material = ''
# fabric_type
# 织物成分
try:
fabric_type = pro_detail['Fabric Type'] if "Fabric Type" in str(pro_detail) else " "
except:
fabric_type = ""
star_list = response.xpath('//table[@id="histogramTable"]//tr[@class="a-histogram-row a-align-center"]//td[3]//a/text()').extract()
if star_list:
try:
star_1 = star_list[0].strip()
except:
star_1 = 0
try:
star_2 = star_list[1].strip()
except:
star_2 = 0
try:
star_3 = star_list[2].strip()
except:
star_3 = 0
try:
star_4 = star_list[3].strip()
except:
star_4 = 0
try:
star_5 = star_list[4].strip()
except:
star_5 = 0
else:
star_1 = 0
star_2 = 0
star_3 = 0
star_4 = 0
star_5 = 0
if "Date First Available" in str(pro_detail):
data_first_available = pro_detail['Date First Available']
if data_first_available:
data_first_available = datetime.datetime.strftime(
datetime.datetime.strptime(data_first_available, '%B %d, %Y'), '%Y/%m/%d')
else:
data_first_available = ""
reviews_link = f'https://www.amazon.com/MIULEE-Decorative-Pillowcase-Cushion-Bedroom/product-reviews/{ASIN}/ref=cm_cr_arp_d_viewopt_fmt?ie=UTF8&reviewerType=all_reviews&formatType=current_format&pageNumber=1'
# reviews_num, ratings_num # 评论数量 ,评论星级
scrap_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
item['delivery']=delivery
item['seller']=seller
item['seller_link']= seller_link
item['brand_link']= brand_link
item['pic_link'] =pic_link
item['title']=title
item['brand']=brand
item['star']=star
item['price']=price
item['color']=color
item['pattern']=pattern
item['material']=material
item['shape']=shape
item['five_points']=five_points
item['size_num']=size_num
item['color_num']=color_num
item['Manufacturer']=Manufacturer
item['item_weight']=item_weight
item['product_dim']=product_dim
item['product_material']=product_material
item['fabric_type']=fabric_type
item['star_1']=star_1
item['star_2']=star_2
item['star_3']=star_3
item['star_4']=star_4
item['star_5']=star_5
# item['ratings_num'] = ratings_num
# item['reviews_num'] = reviews_num
item['scrap_time']=scrap_time
item['reviews_link']=reviews_link
item['size']=size
item['data_first_available']=data_first_available
yield item
采集数量达到一定量时,更换ip呀,识别验证码啥的
4. 下载中间件
Downloader Middlewares默认的方法:
-
process_request(self, request, spider):
1.当每个request通过下载中间件时,该方法被调用
2.返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
3.返回Response对象:不再请求,把response返回给引擎
4.返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法 -
process_response(self, request, response, spider):
1.当下载器完成http请求,传递响应给引擎的时候调用
2.返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
3.返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
在settings.py中配置开启中间件,权重值越小越优先执行
middlewares.py
- 设置代理更换ip
class ProxyMiddleware(object):
def process_request(self,request, spider):
# 设置代理 根据具体使用填写
request.meta['proxy'] = proxyServer
# 设置认证
request.header["Proxy-Authorization"] = proxyAuth
# 检验代理ip是否可用
def process_response(self, request, response, spider):
if response.status != '200':
request.dont_filter = True # 重新发送的请求对象能够再次进入队列
# 把对象返回给引擎,引擎再从头重新给第一个中间件的process_request
return request # 返回request,则中间件终止,该request返回引擎再给调度器
- 更换User-Agent或者是cookie
class AmazonspiderDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# USER_AGENTS_LIST: setting.py
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
cookies_str = '浏览器粘贴过来的cookie'
# 将cookies_str转换为cookies_dict
cookies_dict = {i[:i.find('=')]: i[i.find('=') + 1:] for i in cookies_str.split('; ')}
request.cookies = cookies_dict
# print("---------------------------------------------------")
# print(request.headers)
# print("---------------------------------------------------")
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
- amazon的验证码
def captcha_verfiy(img_name):
# 识别验证码
reader = easyocr.Reader(['ch_sim', 'en'])
# reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
# 读取图像
result = reader.readtext(img_name, detail=0)[0]
# result = reader.readtext('https://www.somewebsite.com/chinese_tra.jpg')
if result:
result = result.replace(' ', '')
return result
def download_captcha(captcha_url):
# 下载验证码图片
response = requests.get(captcha_url, stream=True)
try:
with open(r'./captcha.png', 'wb') as logFile:
for chunk in response:
logFile.write(chunk)
logFile.close()
print("Download done!")
except Exception as e:
print("Download log error!")
class AmazonspiderVerifyMiddleware:
# 验证码
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
# print(response.url)
if 'Captcha' in response.text:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
session = requests.session()
resp = session.get(url=response.url, headers=headers)
response1 = etree.HTML(resp.text)
# 获取验证码图像
captcha_url = "".join(response1.xpath('//div[@class="a-row a-text-center"]/img/@src'))
amzon = "".join(response1.xpath("//input[@name='amzn']/@value"))
amz_tr = "".join(response1.xpath("//input[@name='amzn-r']/@value"))
# 下载验证码图片并保存
download_captcha(captcha_url)
# 识别验证码字母
captcha_text = captcha_verfiy('captcha.png')
# 重新发送请求
url_new = f"https://www.amazon.com/errors/validateCaptcha?amzn={amzon}&amzn-r={amz_tr}&field-keywords={captcha_text}"
resp = session.get(url=url_new, headers=headers)
if "Sorry, we just need to make sure you're not a robot" not in str(resp.text):
response2 = HtmlResponse(url=url_new, headers=headers,body=resp.text, encoding='utf-8')
if "Sorry, we just need to make sure you're not a robot" not in str(response2.text):
return response2
else:
return request
else:
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
初学scrapy,随便写写记录一下,写的有什么问题可以指出来。嘿嘿~~~














 1374
1374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









