







接上篇继续:
目录
十、函数式编程
1、匿名函数lambda表达式
(1)匿名函数理解
匿名函数,即没有名字的函数,在程序中不用使用 def 进行定义,可以直接使用 lambda 关键字编写简单的代码逻辑,lambda 本质上是一个函数对象,可以将其赋值给另一个变量,再由该变量来调用函数,也可以直接使用
(2)lambda表达式的基本格式
lambda入参:表达式入参可有多个,如下:
power = lambda x, n: x ** n
print('%d的%d次方的结果是:%d' % (2, 3, power(2, 3)))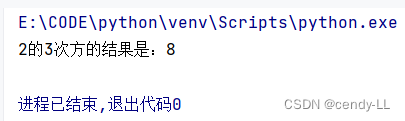
(3)lambda表达式的使用场景
一般适用于创建一些临时性的、小巧的函数,比如上面的power函数,我们可以使用 def 来定义,但使用 lambda 来创建会显得很间接,尤其是在高阶函数的使用中
(4)def 与 lambda 函数对比
示例:定义一个函数,传入一个list,将list每个元素的值加1(另一个地方调用将所有元素的值加2)
# 定义函数,把需要增加的地方抽出来,让调用者自己传
def add(func, l=[]):
return [func(x) for x in l]
def add1(x):
return x + 1
def add2(x):
return x + 2
print(add(add1, [1, 2, 3]))
print(add(add2, [1, 2, 3]))
# 直接使用lambda函数调用
def add(func, l=[]):
return [func(x) for x in l]
print(add(lambda x: x + 1, [1, 2, 3]))
print(add(lambda x: x + 2, [1, 2, 3]))
2、map函数
(1)map的基本格式
map() 函数接收两个以上的参数,开头是一个函数,剩下的是序列,将传入的函数依次作用到序列的每个元素,并把结果作为新的序列返回,也就是类似于 map(func,[1,2,3])
map(func, *iterables)(2)示例
这里还是以列表值+1为例:传入一个list,将list每个元素的值加1
# 定义函数,然后使用map()调用
def add(x):
return x + 1
result = map(add, [1, 2, 3, 4])
print(type(result))
print(list(result))
# 使用 lambda表达式简化操作
result = map(lambda x: x + 1, [1,2,3,4])
print(type(result))
print(list(result))
(3)函数中带两个参数的map函数格式
使用map()函数,将两个序列的数据对应位置求和,之后返回,也就是对[1,2,3]、[4,5,6]两个序列进行操作之后,返回结果[5,7,9],如下:
print(list(map(lambda x, y: x + y, [1, 2, 3], [4, 5, 6])))
若对于两个序列元素个数不一样的,序列各元素想加,查看返回结果,结果以个数少的为准
print(list(map(lambda x, y: x + y, [1, 2, 3], [4, 5])))
3、reduce函数
(1)reduce函数的基本格式
reduce把一个函数作用在一个序列上,这个函数必须接收两个参数,reduce函数把结果继续和序列的下一个元素做累积计算,和递归类似,reduce函数会被上一个计算结果应用到本次计算中
reduce(function, sequence, initial=None)reduce(func, [1, 2, 3]) = func(func(1, 2), 3)(2)示例
# 使用reduce函数,计算一个列表的乘积
from functools import reduce
def func(x, y):
return x * y
print(reduce(func, [1, 2, 3, 4]))
# 使用lambda表达式,计算一个列表的乘积
from functools import reduce
print(reduce(lambda x, y: x * y, [1, 2, 3, 4]))
4、filter函数
(1)filter理解
filter顾名思义是过滤的意思,不需要的数据经过filter处理之后,就被过滤掉
(2)filter函数基本格式
filter()接收一个函数和一个序列,把传入的函数依次作用于每个元素,然后根据返回值是 True 还是 False 决定保留还是丢弃该元素
filter(functin_or_None, iterable)(3)filter函数使用
使用filter函数对给定序列进行操作,最后返回序列中所有偶数
print(list(filter(lambda x: x % 2 == 0, [1, 2, 3, 4, 5])))
5、sorted函数
(1)sorted理解
sorted 从字面意思就可以看出这是一个用来排序的函数,sorted 可以对所有可迭代的对象进行排序操作
(2)sorted函数基本格式
sorted(iterable, key=None, reverse=False)- iterable:可迭代对象
- key:主要是用来进行比较的元素,只有一个参数,具体函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序
- reverse:排序规则,reverse = True 降序 ; reverse = False 升序(默认)
(3)应用
# 对序列做升序排序
print(sorted([1, 6, 4, 5, 9]))
# 对序列做降序排序
print(sorted([1, 6, 4, 5, 9],reverse=True))
# 对存储多个列表的序列做排序
data = [["Python", 99], ["c", 88]]
print(sorted(data, key=lambda item: item[1]))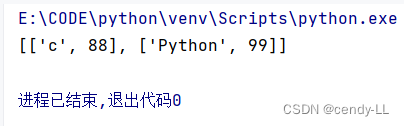
6、闭包
在万物皆对象的Python中,函数也可作为函数的返回值进行返回
def my_power():
n = 2
def power(x):
return x ** n
return power
p = my_power()
print(p(4))
从下面的代码段可以看出:my_power函数在返回的时候,也将其引用的值(n)一同带回,n 的值被新的函数所使用,这种情况被称为闭包
def my_power():
n = 2
def power(x):
return x ** n
return power
n = 3
p = my_power()
print(p(4))
print(p.__closure__)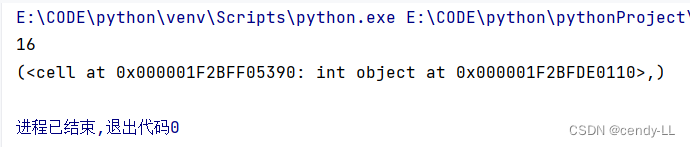
下面的例子:不是闭包,未返回环境变量,只返回了函数
n = 2
def my_power():
def power(x):
return x ** n
return power
n = 3
p = my_power()
print(p(4))
print(p.__closure__)
7、闭包经典问题
下面的程序不是闭包,且执行报错,闭包在引用变量时,不能直接修改引用变量的值
def my_power():
n = 2
def power(x):
n += 1
return x ** n
return power
p = my_power()
print(p(3))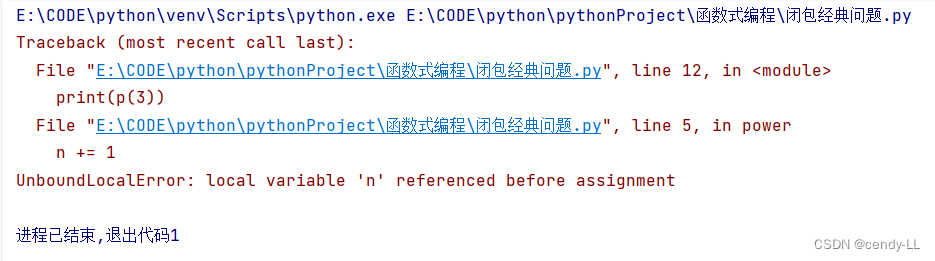
将上面的程序修改为闭包,如下:
def my_power():
n = 2
def power(x):
nonlocal n
n += 1
return x ** n
return power
p = my_power()
print(p(3))
print(p.__closure__)
Python函数只有在执行时,才会去找函数体里的变量的值,形参不确定,目标i的值就不确定;在形参未确定前,Python就只会记住最后一个值,因此i都等于2
def my_power():
n = 2
L = []
for i in range(1, 3):
def power():
return i ** n
L.append(power)
return L
f1, f2 = my_power()
print(f1())
print(f2())
print('-----------------')
print(f1.__closure__[0].cell_contents)
print(f1.__closure__[1].cell_contents)
print(f2.__closure__[0].cell_contents)
print(f2.__closure__[1].cell_contents)
8、装饰器
(1)装饰器理解
装饰器允许想一个现有对象添加新的功能,同时又不改变其结构,这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装
这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能
import time
start = time.time()
time.sleep(4)
end = time.time()
print(end - start)(2)示例
打印【这是一个函数】
def my_fun():
print("这是一个函数")
my_fun()
如果想要获取函数执行的时间,这里改动到了原来的函数,则如下
import time
def my_fun():
begin = time.time()
time.sleep(2) # 这里让结果看起来更直观点,睡眠了2秒
print("这里一个函数")
end = time.time()
print(end - begin)
my_fun()

若不想修改原有函数,想要获取函数执行的时间,如下(第二种):
第一种:该方法不可取,因为要增加功能会导致所有的业务调用方都得进行修改
import time
def my_fun():
print("这是一个函数")
def my_time(func):
begin = time.time()
time.sleep(2)
func()
end = time.time()
print(end - begin)
my_time(my_fun)第二种:
import time
def print_cost(func):
def wrapper():
begin = time.time()
time.sleep(2)
func()
end = time.time()
print(end - begin)
return wrapper
@print_cost
def my_fun():
print("这里一个函数")
my_fun()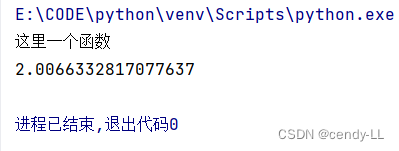
十一、Python核心知识点
1、Python工程组织结构之包、模块
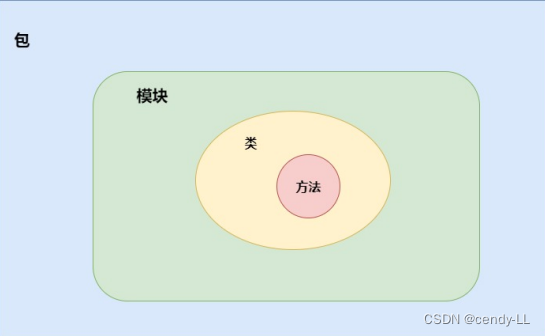
(1)模块
当我们新建一个python file,这个时候形成一个 .py 后缀的文件,这个文件就称之为模块
(2)包
在pycharm中,我们右键可以创建一个目录,也可以创建一个包,两者看起来差不多,唯一的区别在于,创建包的时候,包下面会有一个__init__.py的文件,这也是python为了区分目录和包所做出的界定
(3)包与子包
包下面,还能新建包,称之为子包
2、命名空间
(1)命名空间理解
命名空间是变量到对象的映射集合,一般都是通过字典来实现的。主要可以分为三类:
- 每个函数都有着自已的命名空间,叫做局部命名空间,它记录了函数的变量,包括函数的参数和局部定义的变量
- 每个模块拥有它自已的命名空间,叫做全局命名空间,它记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量
- 内置命名空间,任何模块均可访问它,它存放着内置的函数和异常
通俗点讲:命名空间就是为了确定全局的唯一,比如模块A中有变量c,模块B中也有一个变量c,此时,通过A.c来确定引用A中的变量c,比如在class2模块中要引用class1中的变量a,在导入class1模块之后,可以使用class1.a访问class1中的变量
(2)命名空间查找顺序
当一行代码要使用变量 x 的值时,Python 会到所有可用的命名空间去查找变量,按照如下顺序:
- 局部命名空间:特指当前函数或类的方法,如果函数定义了一个局部变量 x,或一个参数x,Python 将使用它,然后停止搜索
- 全局命名空间:特指当前的模块,如果模块定义了一个名为 x 的变量、函数或类,Python将使用它然后停止搜索
- 内置命名空间:对每个模块都是全局的,作为最后的尝试,Python 将假设 x 是内置函数或变量
- 如果 Python 在这些命名空间找不到 x,它将放弃查找并引发一个 NameError 异常,如 NameError: name 'xxx' is not defined
(3)当函数嵌套时的查找规则
- 先在当前 (嵌套的或 lambda) 函数的命名空间中搜索
- 然后是在父函数的命名空间中搜索
- 接着是模块命名空间中搜索
- 最后在内置命名空间中搜索
def my_func():
name = "小北 "
def func_son():
name = "小南 " # 此处的name变量,覆盖了父函数的name变量
print(name)
# 调用内部函数
func_son()
print(name)
my_func()
(4)命名空间的生命周期
- 内置命名空间在 Python 解释器启动时创建,会一直保留,不被删除
- 模块的全局命名空间在模块定义被读入时创建,通常模块命名空间也会一直保存到解释器退出
- 当函数被调用时创建一个局部命名空间,当函数返回结果或抛出异常时,被删除,每一个递归调用的函数都拥有自己的命名空间
a = 1
def my_func(str):
if a == 1:
print(str)
a = 24
my_func("file")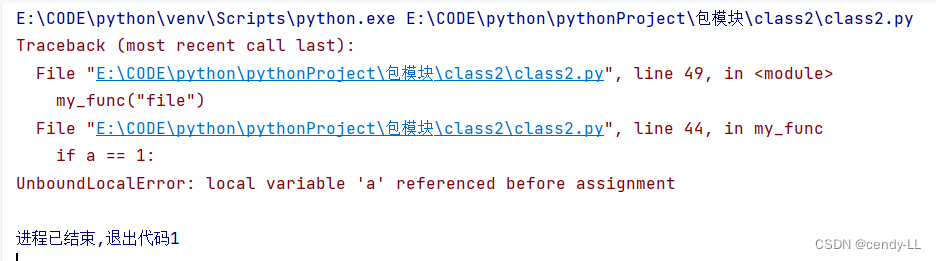
上面的程序会报错,在python的函数中和全局同名的变量,如果你有修改变量的值就会变成局部变量,在修改之前对该变量的引用自然就会出现没定义这样的错误了,如果确定要引用全局变量,并且要对它修改,就必须加上global关键字,如下:
a = 1
def my_func(str):
global a
if a == 1:
print(str)
a = 24
my_func("file")
print(a)
(5)命名空间的访问
# 局部命名空间的访问
局部命名空间可以用 locals() 来访问
def my_func():
a = 1
b = 2
print(locals())
my_func()
locals 返回一个名字/值对的 dictionary ,这个 dictionary 的键是字符串形成的变量名字,dictionary 的值是变量的实际值
# 全局命名空间的访问
全局命名空间可以通过 globals() 来访问
a = 1
b = 2
print(globals())
(6)locals 与 globals 之间的区别
locals 是只读的,但 globals 是可读写的
def my_func():
x = 123
print(locals())
locals()["x"] = 456
print("x=", x)
y = 123
my_func()
globals()["y"] = 111
print("y=", y)
3、在Python工程中导入模块
在平时的开发中,一般会有多模块,为了软件的复用性,我们通常在模块之间相互引用,以达到复用的目的
在Python中,可以使用 import 关键字进行模块的导入,语法如下:
import module_name例如,在模块 class3 中要引用同目录下 test 中的变量 a ,此时可以如下:
import test
print(test.a)
这个时候,需要使用命名空间来访问相应的变量,这个导入似乎很轻松,但是如果模块名太长,代码写起来就显得非常拖沓,这个时候想让代码看起来简短些,就可以使用别名,uti语法如下:
import module_name as aliasimport 导入时,要做的操作:
- 查找一个模块,如果有必要还会加载并初始化模块
- 在局部命名空间中为 import 语句位置所处的作用域定义一个或多个名称
当一个模块首次被导入时,Python 会搜索该模块,如果找到就创建一个 module 对象并初始化它;如果置顶名称的模块未找到,则会引发 ModuleNotFoundError ,当发起调用导入机制时,Python 会实现多种策略来搜索指定名称的模块
注意:当模块首次被导入时,会执行模块里面的代码
使用 import 关键字导入模块是最常用的方式,但是还有另外的方法可以导入模块,即使用 importlib 模块进行导入,基本语法如下:
import importlib
importlib.import_module("module_name")若想要导入另一个包中的模块,语法如下:
from package import module示例:
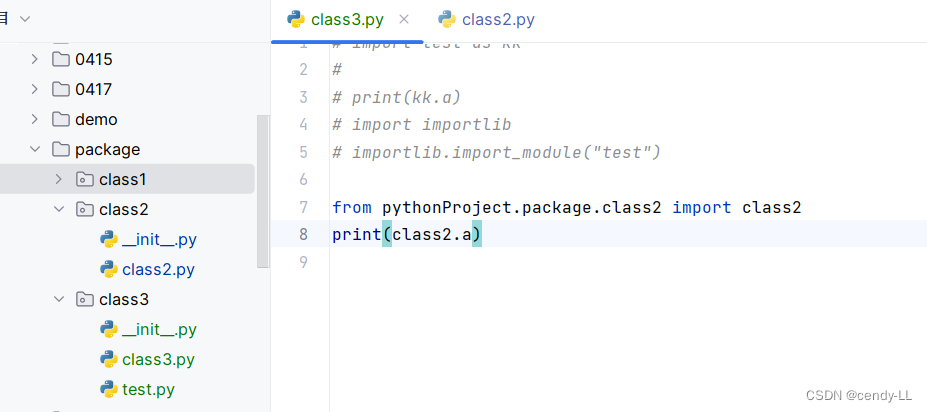
from pythonProject.package.class2 import class2
print(class2.a)
若想要导入多层包中的模块,语法如下(可参考上面示例):
from package.son import module
# 【package.son】是多层包路径4、在Python工程中导入变量
(1)导入一个变量
导入一个变量时,基本语法如下:
from module import variable示例:从 test 中导入变量 a
from test import a
print(a)
注意:当模块首次被调用时,会执行模块里面的代码
修改 test 中的内容,再次运行 class4 文件,就会发现,先输出 hello world ,再打印 a 的值
a = 1111
print("hello world")
(2)导入多个变量
如果要导入多个变量,可以使用逗号分隔
from class3 import a, b
print(a)
print(b)
若要导入的变量非常多,则可以使用【*】进行导入
from test import *
print(a)
print(b)
print(c)
注意:虽然支持【*】通配符进行导入,但是不建议过多使用,因为使用【*】导入,阅读代码时会难以理清其含义
5、python中的导包机制
(1)Python导入机制
导入期间,会在 sys.modules 查找模块名称,如存在则其关联的值就是需要导入的模块,导入过程完成,如果值为 None ,则会引发 ModuleNotFoundError;如果找不到指定
模块名称,Python 将继续搜索该模块
如果指定名称的模块在 sys.modules 找不到,则将发起调用 Python 的导入协议以查找和加载该模块。此协议由两个概念性模块构成,即查找器和加载器
- 查找器的任务是确定是否能使用其所知的策略找到该名称的模块
- 同时实现这两种接口的对象称为导入器,它们在确定能加载所需的模块时会返回其自身
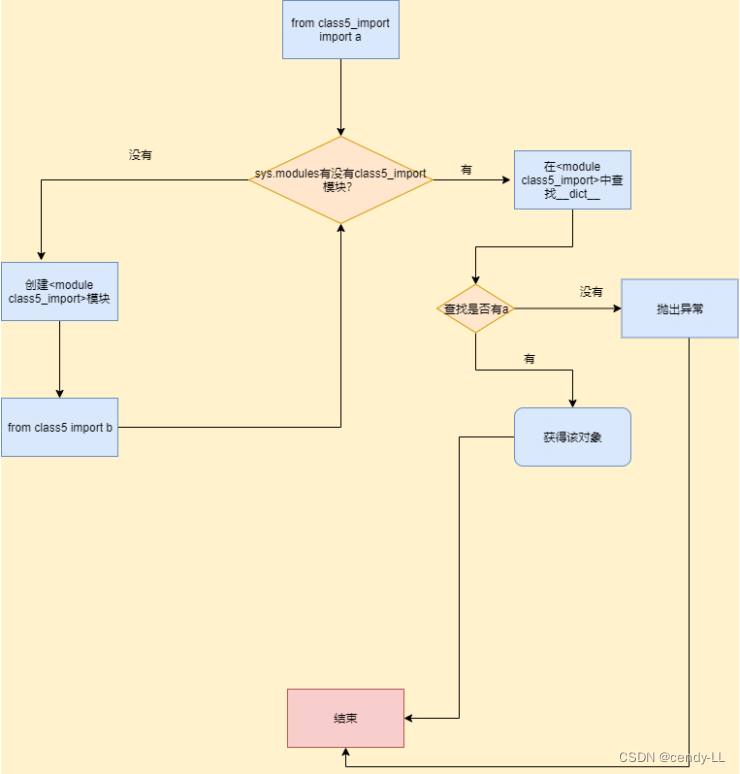
以【from class5_import import a】为例,来理解Python导入机制:
在sys.modules中查找符号"class5_import"
# 如果符号存在,则获得符号class5_import对应的module对象<module class5_import>
@ 从<module class5_import>的dict中获得符号"a"对应的对象,如果"a"不存在,则抛出异常
# 如果符号class5_import不存在,则创建一个新的module对象<module class5_import>,注意,这时,module对象的dict为空
# 执行class5_import.py中的表达式,填充<module class5_import>的dict
# 从<module class5_import>的dict中获得"a"对应的对象,如果"a"不存在,则抛出异常
(2)模块导入示例
【模块 class5.py】
from class5_import import a
b = 22
print(a)【模块 class5_import.py】
from class5 import b
a = 11执行过程如下:
class5.py会执行报错
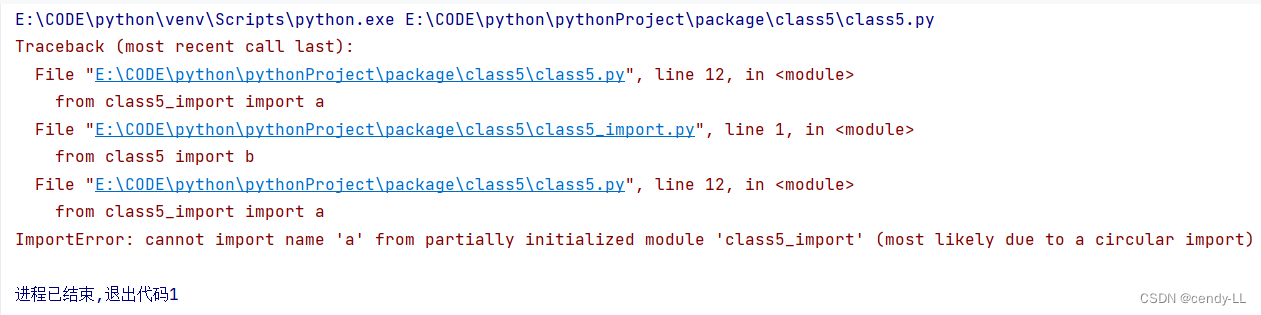
# 执行class5.py中的from class5_import import a,由于是执行的python class5.py,所以在sys.modules中并没有<module class5_import>存在,首先为B.py创建一个module对象(<module class5_import>),【注意,这时创建的这个module对象是空的,里边啥也没有】,在Python内部创建了这个module对象之后,就会解析执行class5_import.py,其目的是填充<module class5_import>这个dict
# 执行class5_import.py中的 from class5 import b,在执行class5_import.py的过程中,会碰到这一句,首先检查sys.modules这个module缓存中是否已经存在<module class5>了,由于这时缓存还没有缓存<module class5>,所以类似的,Python内部会为class5.py创建一个module对象(<module class5>),然后,同样地,执行class5.py中的语句
# 再次执行class5.py中的from class5_import import a,这时,由于在第1步时,创建的<module class5_import>对象已经缓存在了sys.modules中,所以直接就得到了<module class5_import>【注意,从整个过程来看,我们知道,这时<module class5_import>还是一个空的对象,里面啥也没有】,所以从这个module中获得符号"a"的操作就会抛出异常;如果这里只是import class5_import,由于"class5_import"这个符号在sys.modules中已经存在,所以是不会抛出异常的
流程图如下:
6、__init__.py的作用及用法
(1)作用
- 标志所在目录是一个模块包
- 本身也是一个模块
- 可用于定义模糊导入时要导入的内容
(2)用法
我们使用【from package import *】时会报错误,如果想使用该语法不报错,可以在__init__.py 中定义要导入的模块,即使用 __all__=['module_name1','module_name2'] 定义【*】号匹配时要导入的模块,之后再导入的时候,就可以使用【*】通配符进行模糊导入
- 导入一个包的时候,包下的 __init__.py 中的代码会自动执行
- 用于批量导入模块
当我们的许多模块汇总,都需要导入某些公共的模块,此时可以在__init__.py 中进行导入,之后直接导入该包即可
7、__all__、 __name__的作用及其用法
(1)__all__ 的作用及其用法
__all__是list的结构,其作用如下:
- 在普通模块中使用时,表示一个模块中允许哪些属性可以被导入到别的模块中
- 在包下的__init__.py中,可用于标识模糊导入时的模块
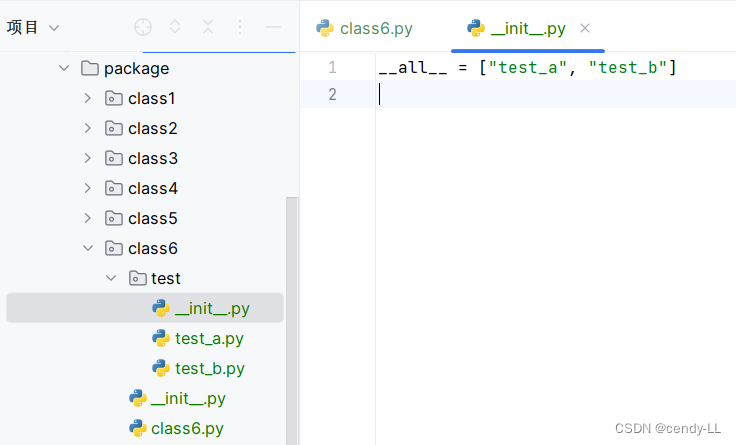
在class6.py中导入包test,即可调用test包下的内容
class6.py
from pythonProject.package.class6.test import *
print(test_a.a)(2)__name__ 的作用及其用法
- __name__这个系统变量显示了当前模块执行过程中的名称,如果当前程序运行在这个模块中,__name__ 的名称就是__main__,如果不是,则为这个模块的名称
- __main__一般作为函数的入口,类似于C语言,尤其在大型工程中,常常有【if __name__ == "__main__"】来表明整个工程开始运行的入口
示例:
def my_fun():
if __name__ == "__main__":
print("this is main")
else:
print(__name__)
my_fun()
十二、错误处理
1、Python中异常的捕获与处理
(1)错误
即还没开始运行,在语法解析的时候就发现语法存在问题,这个时候就是错误,例如:
print("hello world"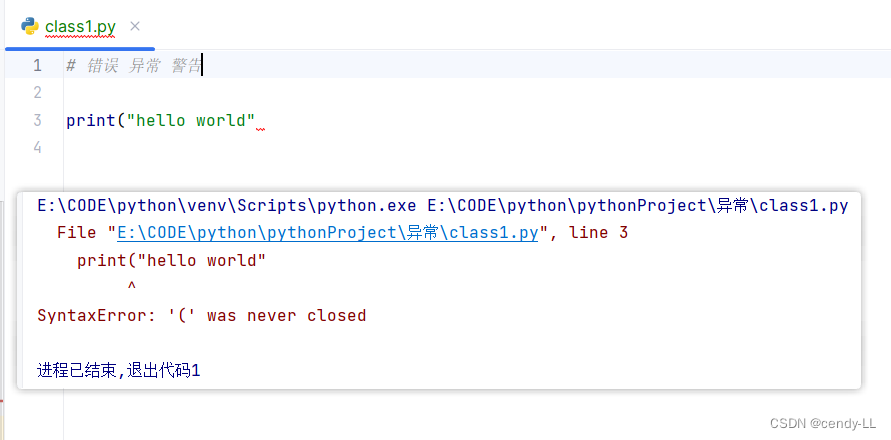
上面这句少了个括号,这个时候编辑器已经告诉我们这句语法有问题,如果继续运行,就会报相应的错误
(2)异常
代码写好之后,无明显语法错误(编辑器不知道有错,语法解析时也不知道有错),但是运行的时候会发生错误,这个时候称之为异常,例如:
print(10 / 0)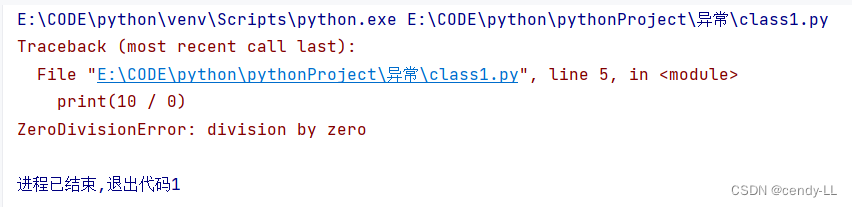
(3)警告
import warnings
def fxn():
print("hello")
warnings.warn("deprecated", DeprecationWarning)
fxn()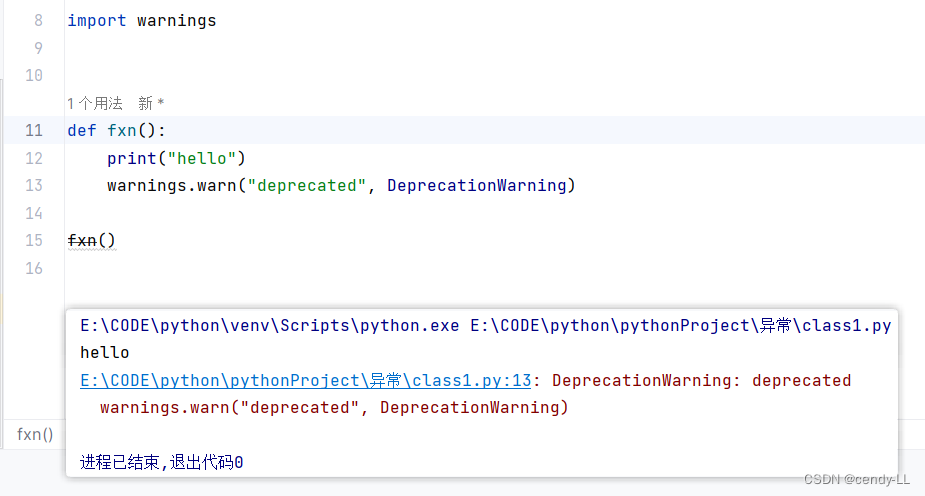
(4)异常处理
异常的处理格式如下:
try:
你要做的可能会发生异常的事
except 可能会发生的异常:
发生异常之后要做的事
except 可能会发生的异常2:
发生异常之后要做的事2
finally:
最终要做的事情示例如下:
try:
print(10 / 0)
except ZeroDivisionError:
print("除数不能为0")
在平时的开发中,也会使用预定义清理的操作,来避免因为异常而导致程序崩溃,比如在进行IO操作的时候,可以使用如下代码,这样一旦运行时发生异常,程序会自动帮你关闭文件,避免整程序崩溃
with open("myfile.txt") as f:
for line in f:
print(line, end="")2、自定义异常与异常的抛出
(1)自定义异常
虽然Python中提供了非常多的内置异常类,但是在平时开发中,针对特定业务,可能需要自定义异常,此时通过自定义集成Exception类的类,可以实现异常的自定义
class MyException(Exception):
def __init__(self, parameter):
err = '非法入参{0},分母不能为0'.format(parameter)
Exception.__init__(self, err)
self.parameter = parameter(2)异常抛出
当我们代码中碰到某种特殊业务情况,需要向调用方抛出自定义异常,可以使用【raise】关键字
from class12.my_exception import MyException
def my_fun(x):
if x == 0:
raise MyException(x)
return 12 / x
print(my_fun(0))
我们在捕获异常后,也可直接将异常抛出,此时直接使用【raise】关键字即可
def my_func():
try:
print(10 / 0)
except ZeroDivisionError:
print("除数不能为0")
# 此处直接将捕获的异常抛出
raise
my_func()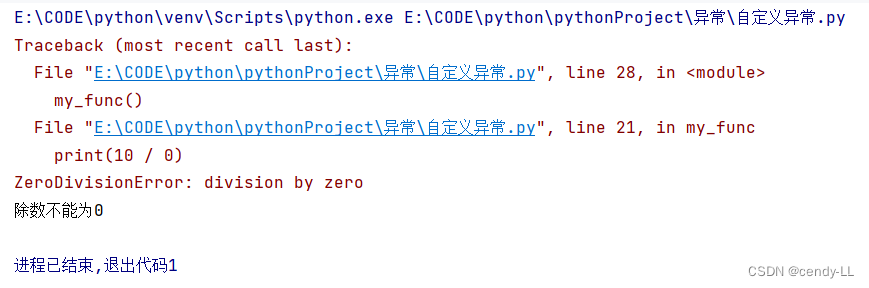
3、如何通过debug分析问题
(1)简单问题分析
首先,我们编写一个函数,有两入参 x,y,函数的返回值是 x/y 的值
def my_fun(x, y):
result = x / y
return result
print(my_fun(12, 0))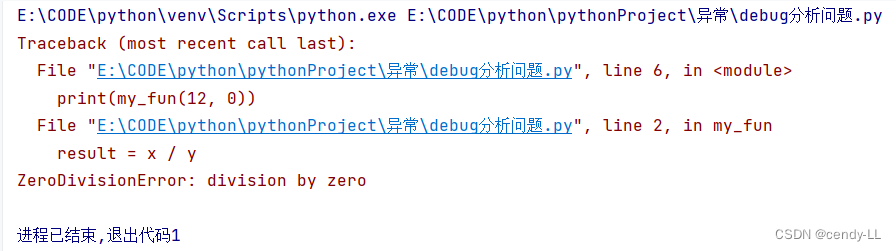
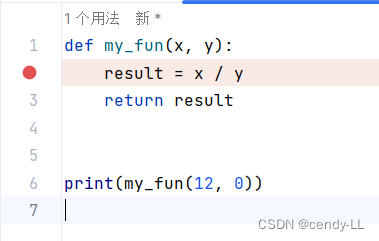
如上图,当入参变成[12,0]的时候,就会发生异常,这时候去定位问题:
- 看错误信息,提取关键部分
- 看错误发生的地方,并找出对应的位置(PyCharm中有行数显示)
这个时候可以看到,这个错误发生的地方是在第2行,当第6行调用第2行时发生错误,对于这种问题结合上面的推断,就可以解决问题了
(2)复杂问题分析
第一步:在对应出错的地方打下断点
第二步:右键选择debug

此时,程序运行至断点处就会停住,在下面的控制台可以看到此时对应的值,至此,可以确定异常产生的原因,从而解决问题
4、为代码编写单元测试
(1)什么是单元测试
单元测试(英语:Unit Testing)又称为模块测试,是针对程序模块(软件设计的最小单位)来进行正确性检验的测试工作。程序单元是应用的最小可测试部件,在过程化编程中,一个单元就是单个程序、函数、过程等;对于面向对象编程,最小单元就是方法,包括基类(超类)、抽象类、或者派生类(子类)中的方法。
简而言之:就是写一段代码,用来验证另一段代码在特定情况下的正确性
(2)单元测试的优缺点
- 好处:减少bug、提高代码质量、可以放心重构(在未来修改实现的时候,可以保证代码的行为仍旧是正确的)
- "坏处":占用开发时间,尤其是在起步阶段
(3)如何编写单元测试
第一步:新建Python文件,编写具体业务代码
class MyTest():
def my_add(self, a, b):
return a + b第二步:右键类名,选择【Go To】---> 【test】,或者直接【ctrl+shift+t】
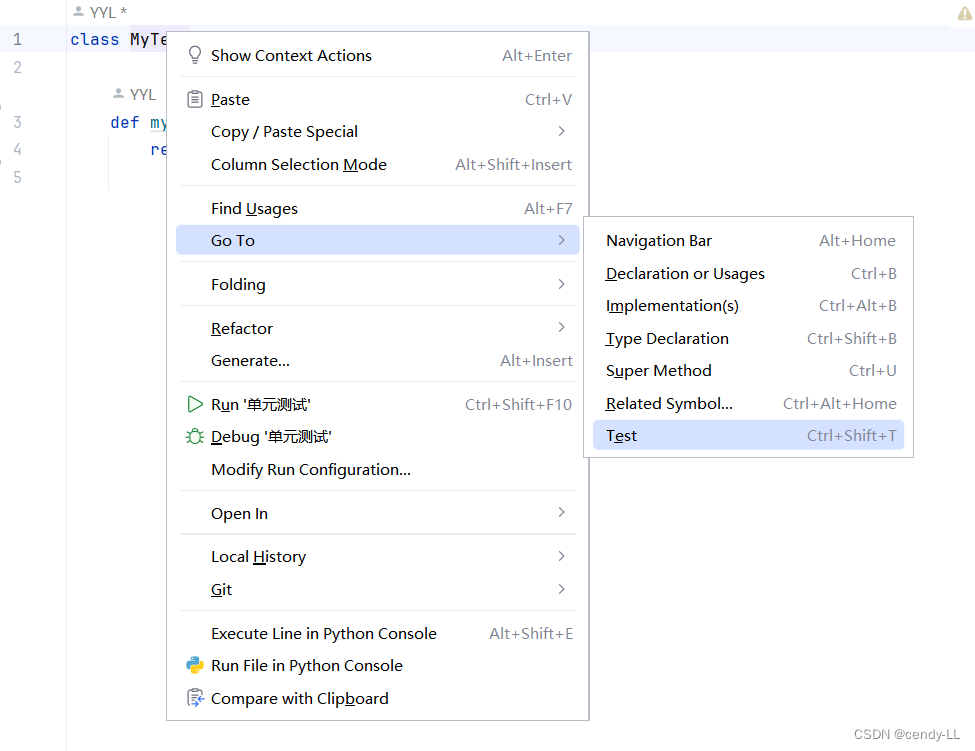
第三步:填写相应的模块名及测试类名,点击OK,此时PyCharm 会帮我们自动创建测试模块及类
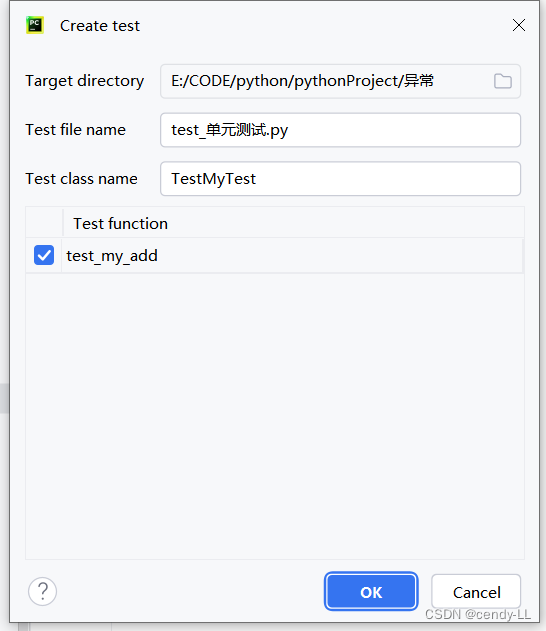
第四步:编写测试代码,并执行单元测试
import unittest
from unittest import TestCase
from pythonProject.异常.单元测试 import MyTest
class TestMyTest(TestCase):
def test_add(self):
s = MyTest()
self.assertEqual(s.my_add(1, 5), 6)
if __name__ == "__main__":
unittest.main()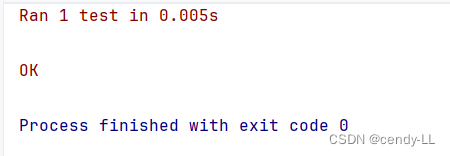

十三、IO操作
1、输入输出
Python提供了 input() 内置函数从标准输入读入一行文本,默认的标准输入是键盘
print("用户输入的内容是:",input())当用户在控制台输入内容之后按回车,此时我们可以看到控制台输出如下:

优化内容,实现用户的友好交互,如下:
print("请输入内容,按回车结束:")
str = input()
print("用户输入的内容是:", str)
2、文件的读取
(1)打开文件
在Python中,可以使用 open 函数来打开文件,具体语法如下:
open(filename, mode)- filename:文件名,一般包括该文件所在的路径
- mode:模式,如果读取时读取中文文本,需要在打开文件的时候使用 encoding 指定字符编码为 utf-8
常见的打开文件的模式如下:
| 模式 | 描述 |
| t | 文本模式(默认) |
| x | 写模式,新建一个文件,如果该文件已存在则会报错 |
| b | 二进制模式 |
| + | 打开一个文件进行更新(可读可写) |
| r | 以只读方式打开文件,文件的指针将会放在文件的开头,这是默认模式 |
| rb | 以二进制格式打开一个文件用于只读,文件指针将会放在文件的开头,这是默认模式,一般用于非文本文件如图片等 |
| r+ | 打开一个文件用于读写,文件指针将会放在文件的开头 |
| rb+ | 以二进制格式打开一个文件用于读写,文件指针将会放在文件的开头,这是默认模式,一般用于非文本文件如图片等 |
| w | 打开一个文件只用于写入,如果该文件已存在则打开文件,并从头开始编辑,即原有内容会被删除;如果该文件不存在,则创建新文件 |
| wb |
以二进制格式打开一个文件只用于写入,如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等
|
| w+ |
打开一个文件用于读写,如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件
|
| wb+ |
以二进制格式打开一个文件用于读写,如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等
|
| a |
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入
|
| ab |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入
|
| a+ |
打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写
|
| ab+ |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写
|
(2)读取文件
读取文件的内容,使用 read 相关方法
使用 read 方法,读取文件的全部内容(如果文件较大,一次性读取可能会导致内存不足,此时需要进行行数指定)
使用 readline() 方法,读取文件的一行
使用 readlines() 方法,一次读取所有内容并按行返回 list
示例:
file = open("E:\\Desktop\\test.txt", "r", encoding="utf-8")
print(file.readline())
print(file.read())特别注意:
每次打开文件完成相应操作之后,都必须关闭该文件,且因为文件在读写过程中可能会出现 IOError 而导致文件不能正常关闭,所以每次读写文件时,必须使用 try finally 语法包裹,使其最终都能正常关闭文件
try:
file = open("E:\\Desktop\\test.txt", "r", encoding="utf-8")
print(file.readline())
print(file.read())
finally:
file.close()
如果觉得 try finally 语法有点繁琐,也可以使用 Python 提供的另外一种方式:
with open("E:\\Desktop\\test.txt", "r", encoding="utf-8") as file:
print(file.readline())
print(file.read())
使用 with 这种方式,无须显示去关闭文件,该语法在使用完文件后,会自动帮我们关闭文件
3、文件内容的写入
写入文件内容时,需要使用 open 打开文件,相应的 mode 指定为追加写入,之后可以使用 write 函数进行文件的写入
try:
file = open("E:\\Desktop\\test.txt", "a", encoding="utf-8")
file.write("hello world123")
finally:
file.close()4、操作文件夹
(1)创建文件夹
可以使用 os.mkdir(dir_name) 来在当前目录下创建一个目录
import os
os.mkdir("test")(2)创建多层级文件夹
import os
os.makedirs("test\\my")(3)获取当前所在目录
import os
print(os.getcwd())(4)改变当前的工作目录
import os
os.chdir("test")
print(os.getcwd())(5)删除空文件夹
import os
os.rmdir("test")(6)删除多层空文件夹
import os
os.removedirs("test\\my")5、操作文件夹示例
(1)文件夹下仅有文件的删除
问题:如果一个文件夹下仅有文件,自定义一个函数,用于删除整个文件夹
思路:获取文件夹中所有的文件,遍历删除,之后删除空的文件夹
import os
def my_rmdir(dir):
files = os.listdir(dir)
os.chdir(dir)
# 删除文件夹中所有的文件
for file in files:
os.remove(file)
print("删除成功!", file)
# 删除空的文件夹
os.chdir("..")
os.rmdir(dir)
my_rmdir("E:\Desktop")
def remove_dir(dir):
dir = dir.replace('\\', '/')
if (os.path.isdir(dir)):
for p in os.listdir(dir):
remove_dir(os.path.join(dir, p))
if (os.path.exists(dir)):
os.rmdir(dir)
else:
if (os.path.exists(dir)):
os.remove(dir)
(2)文件夹下有子文件夹的删除
问题:如果一个文件夹下有子文件夹,自定义一个函数,用于删除整个文件夹
思路:获取文件夹下所有文件及文件夹,文件删除,文件夹递归处理
import os
def my_rmdir(dir):
# 判断是不是文件夹,如果是,递归调用my_rmdir
if (os.path.isdir(dir)):
for file in os.listdir(dir):
my_rmdir(os.path.join(dir, file))
# 如果是空的文件夹,直接删除
if (os.path.exists(dir)):
os.rmdir(dir)
print("删除文件夹成功===>", dir)
# 只是文件,直接删除
else:
if (os.path.exists(dir)):
os.remove(dir)
print("删除文件成功===>", dir)
my_rmdir("E:\\Desktop")
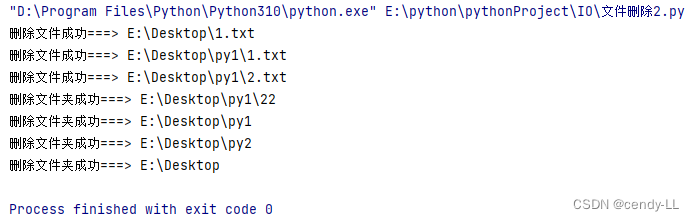
其实删除文件夹,直接调用 python 提供的 api即可
import shutil
shutil.rmtree("E:\\Desktop")6、StringIO和BytesIO
(1)理解
在前面,我们更多接触到IO操作,都是在文件层面上进行操作,但是,在平时的开发中,某些场景下,我们只是要缓存相应的文本内容,方便后续处理,这时候我并不需要新建文件并写入,我只想直接在内存中缓存这些文本,此时StringIo,BytesIo就派上用场了
StringIo,BytesIo均属于io包下(3.7环境),类似于操作文件,临时在内存中缓存文本,两者api与直接进行文件io的操作相似,StringIO跟ByteIo的区别在于前者写入字符串,后者写入二进制
(2)用法
from io import StringIO
str_io = StringIO("hello world")
print(str_io.readline())
str_io.close()from io import StringIO
str_io = StringIO()
str_io.write("hello")
str_io.write(" world")
print(str_io.getvalue())
str_io.close()from io import StringIO
with StringIO() as str_io:
str_io.write("hello")
str_io.write(" world")
print(str_io.getvalue())
十四、面向对象编程
1、面向对象及其三大特性
(1)面向对象理解
面向对象程序设计(Object Oriented Programming)作为一种新方法,其本质是以建立模型体现出来的抽象思维过程和面向对象的方法。模型是用来反映现实世界中事物特征的,任何一个模型都不可能反映客观事物的一切具体特征,只能对事物特征和变化规律的一种抽象,且在它所涉及的范围内更普遍、更集中、更深刻地描述客体的特征。通过建立模型而达到的抽象是人们对客体认识的深化。
(2)面向对象的三大特性
面向对象的三大特性分别为封装、继承和多态
- 封装:把对象的属性私有化,同时提供可以被外界访问这些属性的方法
- 继承:使用已存在的类的定义,作为建立新类的基础技术,新类可以增加新的属性或新的方法,也可以用父类的功能,但不能选择性的继承;通过使用继承,能够非常方便的复用这些代码
- 多态:python中的多态,本质也是通过继承获得多态的能力(不同的子类调用相同的父类方法,产生不同的执行结果,可以增加代码的外部调用灵活度)
2、类和对象
(1)类和对象的理解
类和对象(class)是两种以计算机为载体的计算机语言的合称。对象是对客观事物的抽象,类是对对象的抽象,类是一种抽象的数据类型
客观事物:张三、李四、王五这几个同事,都是客观存在的,可抽象成对象,将这些对象进一步抽取共同特征:名字、性别、年龄,就形成了类
(2)类和对象的关系
类就像工厂里生产产品的模具,它负责对象的创建,决定了对象将被塑造成什么样,有什么属性、做出来之后能做什么
比如:有个女娲造人的模具(类),定义了名字、性别、身高(属性),能自我介绍(方法)
(3)定义类以及实例化对象
# 定义person类
class Person():
# 所有类方法,无论是否要用到,都必须有self参数
def introduce_self(self):
print("my name is cendy")
# 实例化对象的时候 使用类名(),即可完成实例化
person = Person()
# 调用对象方法可以使用对象名.方法名()
person.introduce_self()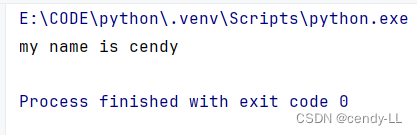
注意:定义类的时候,类名需使用驼峰的命名方式(即单词首字母大写,如果类名由多个单词组成,同样每个单词的首字母都大写)
虽然说都是通过同一个模板(类)刻出来来的(多个对象),但是,每个对象都是独立的个体,都不一样,如下:person跟person2看起来几乎一样,但是,通过id函数可以很明确的知道,两者不同
# 定义Person类
class Person():
# 所有类方法,无论是否要用到,都必须有self参数
def introduce_self(self):
print("my name is cendy")
# 实例化多个对象
person = Person()
person2 = Person()
# 通过id函数证明实例化出来的两个对象都是不同的
print("person对象的ID值为:", id(person))
print("person2对象的ID值为:", id(person2))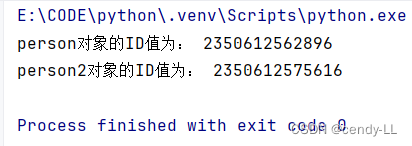
3、类的构造函数
(1)什么是构造函数
构造函数,是一种特殊的方法,主要用来在创建对象的时候去初始化对象,即为对象成员变量赋初始值
注意:python中不支持多个构造函数
在python中,使用__init__作为构造函数,如果不显式写构造函数,python会自动创建一个什么也不干的默认构造函数,如下:
# 定义person类
class Person():
pass
# 实例化对象的时候,使用类名(),即可完成实例化
person = Person()
person1 = Person()
person2 = Person()每次实例化对象的时候,均会帮我们自动执行构造函数里面的代码,如下:
# 定义Person类
class Person():
def __init__(self):
print("hello world")
# 实例化对象的时候 使用类名(),即可完成实例化
person = Person()
person1 = Person()
person2 = Person()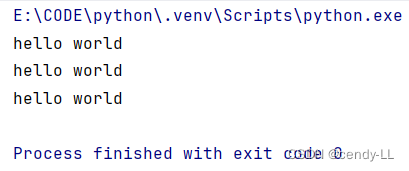
(2)构造函数的用途
# 定义person类
class Person():
# 作为模板,在构造函数中,为必须的属性绑定对应的值
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
def introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))
# 实例化对象的时候 使用类名(),即可完成实例化
person = Person('cendy', 25, 175)
# 访问对象属性可以使用对象实例.属性名的方式为属性赋值
# 调用对象方法可以使用对象名.方法名()
person.introduce_self()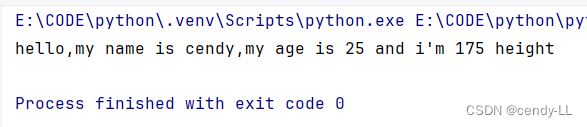
特别注意:当使用了构造函数,且构造函数式带参的且无默认参数,此时,实例化对象的时候,必须显式入参,否则会报错。若要避免错误,可以在构造函数使用默认参数
# 定义person类
class Person():
# 作为模板,在构造函数中,为必须的属性绑定对应的值
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
def introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))
# 实例化对象的时候 使用类名(),即可完成实例化
person = Person()
# 访问对象属性可以使用对象实例.属性名的方式为属性赋值
# 调用对象方法可以使用对象名.方法名()
person.introduce_self()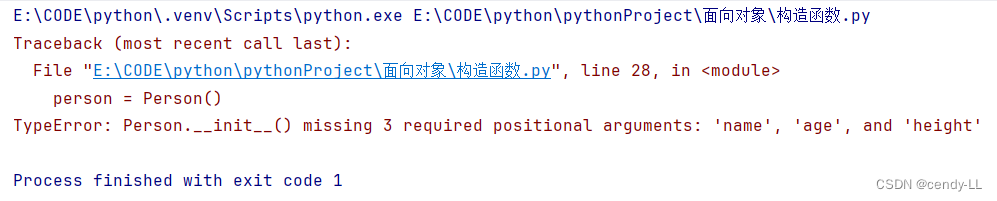
4、类变量与实例变量
(1)类变量
类变量定义在类中且在函数体之外,类变量通常不作为实例变量使用;类变量在整个实例化的对象中是公用的
(2)实例变量
实例变量是定义在方法中的变量,用 self 绑定到实例上,只作用于当前实例的类
(3)访问实例变量和类变量
访问实例变量可以使用【对象名.属性】,访问类变量可以使用【类名.属性】
# 定义person类
class Person():
total = 0
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
person = Person('cendy', 25, 175)
# 访问实例变量
print(person.name)
# 访问类变量
print(Person.total)
(4)修改实例变量和类变量的值
如果要修改实例变量的值,可以使用【对象名.属性=新值】的方式进行赋值;
如果要修改类变量的值,可以使用【类名.属性=新值】的方式进行赋值,在实例方法里,可以使用 self.__class__
# 定义person类
class Person():
total = 0
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
person = Person('cendy', 25, 175)
# 修改实例变量的值
person.name = 'summer'
# 访问实例变量
print(person.name)
# 修改类变量的值
Person.total = 1
# 访问类变量
print(Person.total)
下面的代码段显示如下:该代码不会报错,实例变量的查找规则优先从实例对象中查找,若找不到会去类变量里查找
# 定义person类
class Person():
total = 0
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
person = Person('cendy', 25, 175)
print(person.total)
(5)实例变量查找规则
先从实例变量里面找,找不到的话再看看类变量,若没有,就去父类找,如果还是找不到,就报错
在对象里,有一个__dict__对象,存储着对象相关的属性
# 定义person类
class Person():
name = 0
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
person = Person('cendy', 25, 175)
print(person.name)
print(person.__dict__)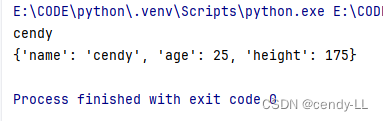
(6)类变量存储
类也有对应的__dict__,存储着与类相关的信息
# 定义person类
class Person():
total = 0
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
person = Person('cendy', 25, 175)
print(Person.__dict__)
案例:定义一个动物类,有name、age的属性,动物有eat的行为,每次调用该行为,直接打印具体动物 is eating,如 老虎 is eating
class Animal():
def __init__(self, name, age):
self.name = name
self.age = age
def eat(self):
print(self.name, "is eating")
animal = Animal("dog", 5)
animal.eat()
5、实例方法与self关键字
(1)实例方法
与实例变量类似,属于实例化之后的对象,定义实例方法至少要有一个self入参,由实例对象调用
(2)self关键字作用
self指向实例本身,我们在实例方法中药访问实例变量,必须使用【self.变量名】的形式
(3)self名称统一
self名称不是必须的,在python中,self不是关键字,你可以定义成 a 或者 b 或者其他名字都可以,但是约定俗成,为了和其他编程语言统一,减少理解难度,最好还是不要另起名称
# 定义person类
class Person():
total = 0
# 构造函数,用于为成员变量赋初始值
def __init__(aa, name, age, height):
aa.name = name
aa.age = age
aa.height = height
def introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))
# 实例化对象的时候 使用类名(),即可完成实例化
person = Person('cendy', 25, 175)
person.introduce_self()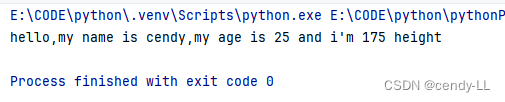
在实例方法中,如果不使用【self.属性名】的方式去访问对应的属性,会发生报错
# 定义person类
class Person():
# 构造函数,用于为成员变量赋初始值
def __init__(self, nick, age, height):
self.name = nick
self.age = age
self.height = height
# 不使用self.属性名的方式去访问对应的属性
print(name)
def introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))
# 实例化对象的时候 使用类名(),即可完成实例化
person = Person('cendy', 25, 175)
person.introduce_self()
如果不实例化对象,直接使用【类名.实例方法名】的方式调用方法,则会报错
# 定义person类
class Person():
# 构造函数,用于为成员变量赋初始值
def __init__(self, nick, age, height):
self.name = nick
self.age = age
self.height = height
def introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))
Person.introduce_self()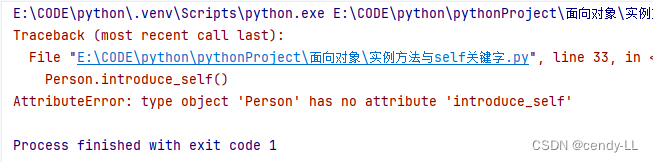
6、类方法与静态方法
(1)类方法
类方法使用装饰器@classmethod。第一个参数必须是当前类对象,该参数名一般约定为“cls”(不是cls也没关系,但是,约定俗成的东西不建议变动),通过它来传递类的属性和方法(不能传实例的属性和方法);其调用对象可以是实例对象和类
# 定义Person类
class Person():
total = 1
@classmethod
def print_total(cls):
cls.total += 1
print(cls.total)
# 类调用
Person.print_total()
# 实例对象调用(不建议)
person = Person()
person.print_total()
(2)静态方法
使用装饰器@staticmethod。参数随意,没有“self”和“cls”参数,但是方法体中不能使用类或实例的任何属性和方法
静态方法是类中的函数,不需要实例,静态方法主要是用来存放逻辑性的代码,逻辑上属于类,但是和类本身没有关系,也就是说在静态方法中,不会涉及到类中的属性和方法的操作,可以理解为:静态方法是个独立的、单纯的函数,它仅仅托管于某个类的名称空间中,便于使用和维护
# 定义person类
class Person():
@staticmethod
def print_hello():
print("hello world")
Person.print_hello()
小总结:
实例方法:与具体实例相关,用于操作实例变量
类方法:与类相关,用于操作类变量,虽然实例可以直接调用,但是不建议通过实例调用
静态方法:与类和具体的实例无关,相当于一个独立的函数,只是依托于类的命名空间内
7、Python中的访问限制
如下我们定义了一个类,实例化了一个对象,给其年龄赋值-1,程序正确运行,但是,这不符合现实生活中的场景,当我们不加限制的将属性暴露出去,也就是意味着我们的类失去了安全性
# 定义person类
class Person():
# 构造函数,用于为成员变量赋初始值
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
def introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))
person = Person("cendy", 25, 175)
person.age = -1
person.introduce_self()
当我们不希望外部可以随意更改类内部的数据,可以将变量定义为私有变量,并提供相应的操作方法,为了保证外部不可以随意更改实例内部的数据,可以在构造函数中,在属性的名称前加上两个下划线__,这样该属性就变成了一个私有变量,只有内部可以访问,外部不能访问
# 定义person类
class Person():
# 构造函数,用于为成员变量赋初始值
def __init__(self, name, age, height):
self.name = name
self.__age = age
self.height = height
def set_age(self, age):
if age < 0 or age > 150:
raise Exception("非法入参,年龄不合法")
self.__age = age
def introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" % (self.name,self.age, self.height))
person = Person("cendy", 25, 175)
print(person.age)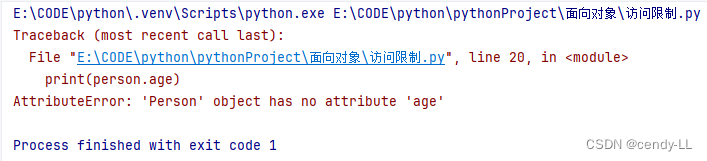
方法私有化,同样也是在方法名前面加上__
# 定义person类
class Person():
# 构造函数,用于为成员变量赋初始值
def __init__(self, name, age, height):
self.name = name
self.__age = age
self.height = height
def set_age(self, age):
if age < 0 or age > 150:
raise Exception("非法入参,年龄不合法")
self.__age = age
def __introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" % (self.name,self.age, self.height))
person = Person("cendy", 25, 175)
person.__introduce_self()
8、打破Python中的访问限制
问题1:下面的程序依旧可以运行,可以打印实例的__dict__来看下:我们可以看到,在实例里面,自动帮我们整了一个__age的属性
# 定义person类
class Person():
# 构造函数,用于为成员变量赋初始值
def __init__(self, name, age, height):
self.name = name
self.__age = age
self.height = height
def set_age(self, age):
if age < 0 or age > 150:
raise Exception("非法入参,年龄不合法")
self.__age = age
def introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" % (self.name,self.age, self.height))
person = Person("cendy", 25, 175)
person.__age = -1
print(person.__age)
print(person.__dict__)
问题2:在python中,仅属性或方法前面加上__时,表示私有;如果后面再加上__,此时含义就发生改变,变成了普通的属性或方法
# 定义person类
class Person():
# 构造函数,用于为成员变量赋初始值
def __init__(self, name, age, height):
self.name = name
self.__age__ = age
self.height = height
def set_age(self, age):
if age < 0 or age > 150:
raise Exception("非法入参,年龄不合法")
self.__age__ = age
def introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" %(self.name, self.age, self.height))
person = Person("cendy", 25, 175)
print(person.__age__)
问题3:通过问题1,我们看出对象的__dict__打印出来的结果,多了个_Person__age,其值刚好对应私有属性的值,因此,可以如下访问:
# 定义person类
class Person():
# 构造函数,用于为成员变量赋初始值
def __init__(self, name, age, height):
self.name = name
self.__age = age
self.height = height
def set_age(self, age):
if age < 0 or age > 150:
raise Exception("非法入参,年龄不合法")
self.__age = age
def introduce_self(self):
print("hello,my name is %s,my age is %d and i'm %d height" % (self.name,self.age, self.height))
person = Person("cendy", 25, 175)
#打破访问限制
print(person._Person__age)
十五、面向对象高级特性
1、python中的继承
(1)继承的理解
继承可以使得子类具有父类的属性和方法或者重新定义、追加属性和方法等
(2)python中如何继承
# 子类直接继承
# 定义animal类
class Animal():
def __init__(self, name):
self.name = name
def walk(self):
print(self.name + " is walking")
# Dog继承animal
class Dog(Animal):
pass
# cat继承animal
class Cat(Animal):
pass
# Dog和cat均因为继承animal而获得walk的能力和属性
dog = Dog("Dog")
dog.walk()
print('当前的小动物是:', dog.name)
print('---------------------')
cat = Cat("Cat")
cat.walk()
print('当前的小动物是:', cat.name)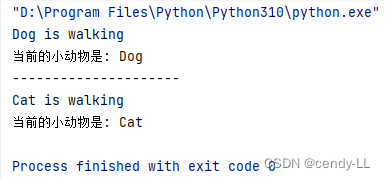
# 子类可以有自己的属性与方法
# 定义animal类
class Animal():
def __init__(self, name):
self.name = name
def walk(self):
print(self.name + " is walking")
# Dog继承animal
class Dog(Animal):
# Dog有吠叫的功能
def bark(self):
print(self.name + " is bark")
dog = Dog("Dog")
print(dog.name)
dog.walk()
dog.bark()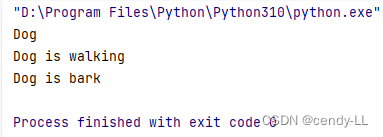
# 子类具备父类所有的属性与功能,但是父类并不具备子类的属性与功能
# 定义animal类
class Animal():
def __init__(self, name):
self.name = name
def walk(self):
print(self.name + " is walking")
# Dog继承animal
class Dog(Animal):
def bark(self):
print(self.name + " is bark")
animal = Animal("animal")
dog = Dog("Dog")
print(isinstance(dog, Animal))
print(isinstance(animal, Dog))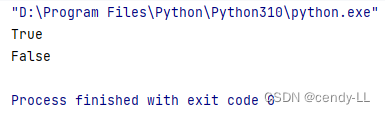
# 当子类有自己的构造方法时,将会覆盖父类的构造方法
# 定义animal类
class Animal():
def __init__(self):
print("Animal")
# Dog继承animal
class Dog(Animal):
def __init__(self):
print("Dog")
dog = Dog()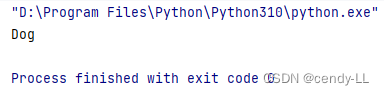
# 子类重写父类方法
# 定义animal类
class Animal():
def __init__(self):
print("Animal")
def eat(self, name):
print("Animal is eating")
# Dog继承animal
class Dog(Animal):
def __init__(self):
print("Dog")
def eat(self, name):
print("Dog is eating \n" + "it's name is:" + name)
dog = Dog()
dog.eat("aimy")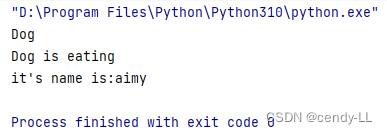
注意:当且仅当子类方法与父类同名,入参相同,才可称之为重写父类的方法
不要为了获得某些属性或功能而继承,比如:因为在Dog类中写了一个 eat 方法,觉得 Person 也该有这样的方法,就直接继承 Dog,这种不可取
问题:如下所示,程序会报错
原因:之所以会报错,是因为子类自己写了init方法,程序运行的时候就不会去调用父类的构造方法,所以,实例中就不存在name这样一个属性
# 定义animal类
class Animal():
def __init__(self,name):
self.name = name
# Dog继承animal
class Dog(Animal):
def __init__(self):
print("Dog")
dog = Dog()
print(dog.name)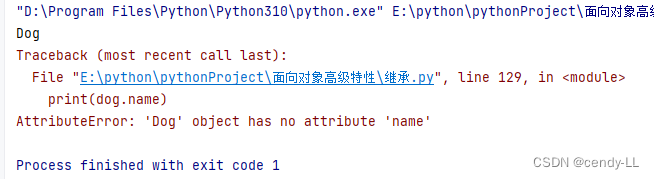
2、super的作用及其用法
(1)super函数理解
super() 函数是用于调用父类(超类)的一个方法,一般是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题
(2)super函数的基本语法
在python3中,可以直接使用super() 而无需任何参数来调用父类
super(类名, self)(3)super函数应用
第一节出现一个问题,子类自己写了init方法,因此无法调用父类init方法中的name属性,如果想要调用父类的该属性,有两种方法:
方法1:直接通过父类名.__init__来调用,虽然可以达到目的,但是不建议直接通过类名去调用
# 定义animal类
class Animal():
def __init__(self, name):
self.name = name
# Dog继承animal
class Dog(Animal):
def __init__(self, name):
Animal.__init__(self, name)
print("Dog")
dog = Dog("tomcat")
print(dog.__dict__)
print(dog.name)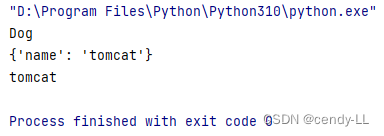
方法2:通过super去进行调用
# 定义animal类
class Animal():
def __init__(self, name):
self.name = name
# Dog继承animal
class Dog(Animal):
def __init__(self, name):
super(Dog, self).__init__(name)
print("Dog")
dog = Dog("tomcat")
print(dog.__dict__)
print(dog.name)
3、抽象方法与多态
(1)抽象方法理解
在面向对象编程语言中抽象方法指一些只有方法声明,而没有具体方法体的方法;抽象方法一般存在于抽象类或接口中,抽象类的一个特点是它不能直接被实例化,子类要么是抽象类,要么必须实现父类抽象类里定义的抽象方法
在python3中可以通过使用abc模块轻松的定义抽象类
(2)定义抽象类
from abc import ABCMeta, abstractmethod
# 定义抽象类时,使用metaclass=ABCMeta
class Animal(metaclass=ABCMeta):
@abstractmethod
def eat(self):
pass
class Dog(Animal):
def eat(self):
print("dog is eating")
dog = Dog()
dog.eat()
抽象类的子类必须实现抽象类中所定义的所有方法,否则,程序不能正确运行
from abc import ABCMeta, abstractmethod
# 定义抽象类时,使用metaclass=ABCMeta
class Animal(metaclass=ABCMeta):
@abstractmethod
def eat(self):
pass
class Dog(Animal):
pass
dog = Dog()
即使是实现部分抽象方法也是不行的
class Animal(metaclass=ABCMeta):
@abstractmethod
def eat(self):
pass
@abstractmethod
def run(seft):
pass
class Dog(Animal):
def eat(self):
print("Dog is eating")
dog = Dog()
(3)多态理解
不同的子类对象调用相同的父类方法,产生不同的执行结果,可以增加代码的外部调用灵活度
# 定义animal类
from abc import ABCMeta, abstractmethod
# 定义抽象类时,使用metaclass=ABCMeta
class Animal(metaclass=ABCMeta):
@abstractmethod
def eat(self):
pass
@abstractmethod
def run(seft):
pass
def activity(self):
self.eat()
self.run()
class Dog(Animal):
def eat(self):
print("Dog is eating")
def run(self):
print("dog is running")
class Cat(Animal):
def eat(self):
print("cat is eating")
def run(self):
print("cat is running")
# 不同的子类对象,调用父类的activity方法,产生不同的执行结果
dog = Dog()
cat = Cat()
dog.activity()
cat.activity()
(4)多态的好处
- 增加了程序的灵活性
- 增加了程序的可扩展性
4、python中的多重继承
python里面支持多重继承,也就是一个子类能有多个父类
class Father:
def power(self):
print("拥有很大的力气")
class Mother:
def sing(self):
print("唱歌")
class Me(Father, Mother):
pass
me = Me()
me.power()
me.sing()
当继承多个父类时,如果父类中有相同的方法,那么子类会优先使用最先被继承的方法
class Father:
def power(self):
print("拥有很大的力气")
def sing(self):
print("唱草原歌")
class Mother:
def sing(self):
print("唱情歌")
# 改变继承的顺序
class Me(Mother, Father):
pass
me = Me()
me.power()
me.sing()
5、多重继承所带来的的问题
(1)新式类和旧式类
新式类都从object继承(python3中,默认都继承自object),经典类不需要
新式类的MRO(method resolution order 基类搜索顺序)算法采用C3算法广度优先搜索,而旧式类的MRO算法是采用深度优先搜索
新式类相同父类只执行一次构造函数,经典类重复执行多次
class Father:
def my_fun(self):
print("Father")
class Son1(Father):
def my_fun(self):
print("Son1")
class Son2(Father):
def my_fun(self):
print("Son2")
class Grandson(Son1, Son2):
def my_fun(self):
print("Grandson")
d = Grandson()
d.my_fun()
(2)菱形继承(钻石继承)
之前学习继承的时候说过,要执行父类构造方法有两种方式,一种是直接使用父类名字调用构造,一种是使用super(),普通的继承中,这两种方法没啥大问题,但是,如果在多重继承里,使用父类名字调用构造可能会发生问题
class Father:
def __init__(self):
print("this is Father")
def my_fun(self):
print("Father")
class Son1(Father):
def __init__(self):
Father.__init__(self)
def my_fun(self):
print("Son1")
class Son2(Father):
def __init__(self):
Father.__init__(self)
def my_fun(self):
print("Son2")
class Grandson(Son1, Son2):
def __init__(self):
Son1.__init__(self)
Son2.__init__(self)
def my_fun(self):
print("Grandson")
d = Grandson()
d.my_fun()
(3)解决菱形继承问题
要解决菱形继承多次调用构造的问题,可以使用super()
class Father:
def __init__(self):
print("this is Father")
def my_fun(self):
print("Father")
class Son1(Father):
def __init__(self):
print("Son1 init")
super().__init__()
def my_fun(self):
print("Son1")
class Son2(Father):
def __init__(self):
print("son2 init")
super().__init__()
def my_fun(self):
print("Son2")
class Grandson(Son1, Son2):
def __init__(self):
super().__init__()
def my_fun(self):
print("Grandson")
d = Grandson()
d.my_fun()
6、枚举类
(1)枚举理解
在数学和计算机科学理论中,一个集的枚举是列出某些有穷序列集的所有成员的程序,或者是一种特定类型对象的计数。这两种类型经常(但不总是)重叠
(2)枚举实例
假设现在开发一个程序,大概内容是记录车子在通过路口时红绿灯的颜色,并判断司机是否违规,程序普通的写法如下:
# 1 红色 2:黄 3:绿
def judge(color):
if color == 1 or color == 2:
print("司机闯红灯")
else:
print("司机正常行驶")
judge(1)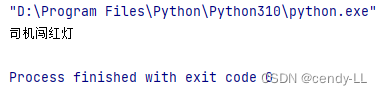
上面的程序存在一个很明显的问题,程序是自己写的,自己能理解。但是,如果别人来看我的程序,会无法理解1跟2这两个数字的意义,这里有注释还好,但是还有一个问题,可能另外的同事1是表示绿灯,这个时候双方理解就会产生很大的问题。
这个时候,我希望在系统里统一一下这些定义,枚举类的的作用就提现出来了,在枚举类里将有限个可能取值都列出来,大家统一用枚举类里的定义,如下:
from enum import Enum
class TrafficLight(Enum):
RED = 1
YELLOW = 2
GREEN = 3
def judge(color):
if color == TrafficLight.RED or color == TrafficLight.YELLOW:
print("司机闯红灯")
else:
print("司机正常行驶")
judge(TrafficLight.GREEN)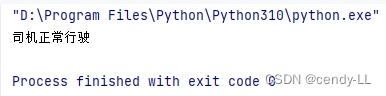
在枚举类中, RED = 1 这样的是枚举成员, RED 是名字, 1 是值
(3)枚举访问
# 通过名字获取枚举成员
from enum import Enum
class TrafficLight(Enum):
RED = 1
YELLOW = 2
GREEN = 3
print(TrafficLight.RED)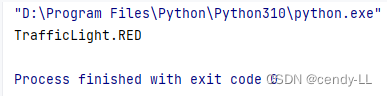
# 通过枚举成员获取名字以及值
from enum import Enum
class TrafficLight(Enum):
RED = 1
YELLOW = 2
GREEN = 3
# 通过枚举成员获取名字
print(TrafficLight.RED.name)
# 通过枚举成员获取值
print(TrafficLight.RED.value)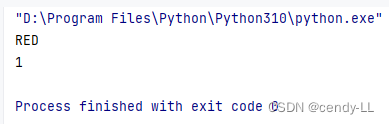
# 通过值获取枚举成员
from enum import Enum
class TrafficLight(Enum):
RED = 1
YELLOW = 2
GREEN = 3
# 通过枚举成员获取名字
print(TrafficLight(1))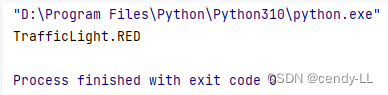
(4)枚举类的特性
# 定义枚举时,其枚举成员的名称不允许相同
from enum import Enum, unique
class TrafficLight(Enum):
RED = 0
RED = 1
YELLOW = 2
GREEN = 3
# 1 红色 2:黄 3:绿
def judge(color):
if color == TrafficLight.YELLOW or color == TrafficLight.RED:
print("司机闯红灯")
else:
print("司机正常行驶")
judge(TrafficLight.YELLOW)
默认情况下,不同的成员值允许相同。但是两个相同值的成员,其第二个成员名称是第一个成员名称的别名;因此在访问枚举成员时,只能获取第一个成员
from enum import Enum, unique
class TrafficLight(Enum):
RED = 1
BLACK = 1
YELLOW = 2
GREEN = 3
print(TrafficLight(1))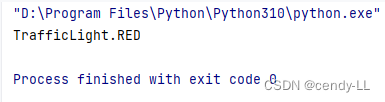
如果要限定枚举里面所有的值必须唯一,可以在定义枚举类时,加上@unique
from enum import Enum, unique
@unique
class TrafficLight(Enum):
RED = 1
BLACK = 1
YELLOW = 2
GREEN = 3
print(TrafficLight(1))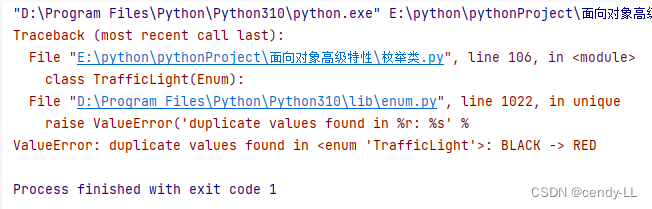
(5)枚举成员的比较
from enum import Enum
class TrafficLight(Enum):
RED = 1
YELLOW = 2
GREEN = 3
# 通过名字获取枚举成员
print(TrafficLight.RED == 1)
# 通过枚举成员获取值
print(TrafficLight.RED.value == 1)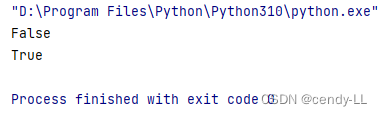















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









