






目录
爬虫就是自动获取网页内容的程序,例如搜索引擎,Google,Baidu 等,每天都运行着庞大的爬虫系统,从全世界的网站中爬虫数据,供用户检索时使用。
二、爬虫的流程
获取网页内容解析网页内容
储存或分析数据
注意:
- 爬虫的请求数量和频率不能过高
- 可以通过访问网页的robots.txt了解可爬取的网页路径范围
三、HTTP请求和响应
1、什么是HTTP
HTTP(Hyper Text Transfer Protocol): 超文本传输协议,是应用层协议,是一种客户端和服务器之间的请求-响应协议,用于从万维网服务器传输超文本到本地浏览器的传送协议。
2、HTTP的请求和响应
输入想访问的网址客户端(浏览器)向运行该网站的服务器发送请求
等待服务器返回给浏览器响应
3、HTTP的请求方法
- GET方法:获取数据
当我们进入一个网页时,浏览器会发送GET请求得到网页的内容
- POST方法:创建数据
当我们提交账号注册时,浏览器会发送POST请求把用户名、密码等信息放到请求主体里给服务器
- PUT方法 :PUT 在能力上和 POST 类似,区别在于 PUT 的 URI 指向是具体的某个资源,而不能指向资源集合。
- DELETE方法:删除指定的资源
4、HTTP请求的组成
-
请求行(request Lines)
POST /profile.php HTTP/1.1
POST /profile.php?id=1 HTTP/1.1
/ profile.php:资源路径
id=1:查询参数(不同的参数之间用&分隔)
HTTP/1.1:协议版本,有HTTP/0.9、HTTP/1.0、 HTTP1.1、 HTTP2.0
-
请求头(request Headers)
Host: node5.anna.nssctf.cn:28490
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, brContent-Type: multipart/form-data;
- Accept: 浏览器可接受的数据格式,如text/html(接受HTML)、application/json(JSON)、text/heml,application/json(接受HTML和JSON)、*/*(接受任意类型)
- Accept-encoding: 浏览器可接受的压缩算法,如gzip(服务器压缩,客户端解压,让传输的资源变小,速度更快)
- Accept-Language: 浏览器可接收的语言,如zh-CN
- Connect:keep-alive 一次TCP连接重复使用
- Cookie:同域每次请求资源都会把cookie带上
- Host:主机域名(结合请求行里的资源路径可以得到完整的网址)
- User-agent:简称UA,浏览器信息,标识是什么浏览器,是什么系统,供给服务器分析
- Content-type:发送数据的格式(多存在于post请求中),如一般json数据为application/json ,图片或文件为multipart/form-data
-
响应头(response Headers)
- Content-type:返回数据的格式,如application/json(json),text/html(html),text/css(css)、text/javascript(javascript)、image/png,
- Content-length:返回数据的大小,多少字节
- Content-Encoding: 返回数据的压缩算法,如gzip
- Set-Cookie: 服务端需要通过该字段来修改浏览器中的cookie
-
状态行
HTTP/1.1 200 OK
-
状态码
1xx:成功接收了请求,但是处理过程还没结束,需要客户端再抛出一个请求才能完成整个过程。
2xx:表示成功接收请求、并且已经处理完毕。
200 OK:客户端请求成功
3xx:表示服务器虽然也处理了你的请求,但客户端还需要进一步的工作,才可以完成请求。
301 Moved Permanently:资源被永久移动到新地址
4xx:客户端错误,意味着请求出错了。
400 Bad Request:客户端不能被服务器所理解
401 Unauthorized:请求未经授权
403 Forbidden:服务器拒绝提供服务
404 Not Found:请求资源不存在
5xx:服务器错误,意味着服务器内部的程序处理有问题。
500 Internal Server Error:服务器发生不可预期的错误
503 Server Unavailable:服务器当前不能处理客户端的请求
还可通过HTTP 响应状态码 - HTTP | MDN查询
四、requests库
1、发送请求
import requests
response = requests.get("http://books.toscrape.com/")
print(response.status_code) #打印状态码
-----------------------------------------------------
200 #请求成功2、获取内容
import requests
#伪装成浏览器请求
head = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0"
}
response = requests.get("https://books.toscrape.com/", headers = head)
if response.ok: #respongse的Ok属性能响应为true
print(response.text) #打印到txt文件
else:
print("请求失败")UA的伪装可以利用开发者工具抓取得到
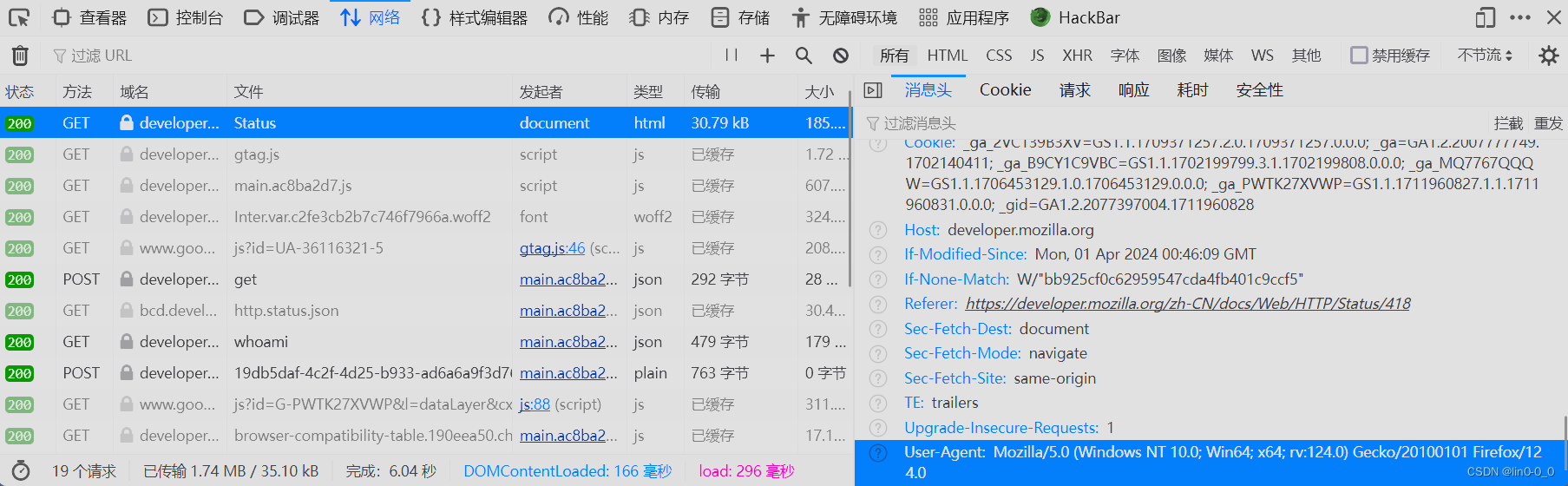
五、HTML常见标签
1、注释标签
< !-- 注释 -- >(ctrl + / 快捷键 可以快速进⾏注释/取消注释).
2、标题标签<h>
<h1>这是一个一级标题</h1>
<h2>这是一个二级标题</h2>
<h3>这是一个三级标题</h3>
<h4>这是一个四级标题</h4>
<h5>这是一个五级标题</h5>
<h6>这是一个六级标题</h6>
以层级区分标题标签,层级低的包含层级高的,直观说就是标题层级越低字号越大

3、段落标签<p>
<p>这是一段文字</p>
<p>这是一段 文字</p>
<p>这是一段
文字</p>
注意:
- html 内容首尾处的换行, 空格均无效;
- 在 html 中文字之间输入的多个空格只相当于一个空格;
- html 中直接输入换行不会真的换行, 而是相当于一个空格。

4、换行标签<br>和分割线标签<hr>
<p>这是<br/>一段<hr>文字</p>
<br/>是规范写法
<br><hr>都是单标签(不需要结束标签)

5、格式化标签
<strong>加粗</strong> <b>加粗</b>
<em>倾斜</em> <i>倾斜</i>
<del>删除线</del> <s>删除线</s>
<ins>下划线</ins> <u>下划线</u>

6、图片标签<img>
<img src="https://images.unsplash.com/photo-1609515602287-8470b8d9ac11" width="500px" height="500px">
注意:
- 图像标签可以同时拥有多个属性,属性不分前后顺序,以空格隔开
- 设置图片宽度和高度一般设一个就行,图片会自动按比例适配
- 属性使⽤ "键值对" 的格式来表示,即key="value"

| 属性 | 属性值 | 说明 |
| src | 图片路径 | 必须属性 |
| alt | 文本 | 替换文本,图片显示失败是显示 |
| title | 文本 | 提示文本,鼠标放到图片上显示的提示文字 |
| width | 像素 | 设置宽度 |
| height | 像素 | 设置高度 |
| border | 像素 | 设置图像的边框粗细 |
7、链接标签<a>
<a href="https://space.bilibili.com/523995133" target="_self">我的主页</a>
<a href="链接地址" target="目标窗口的打开方式">
href: 必须具备, 表示点击后会跳转到哪个⻚⾯;
target: 打开⽅式。

点开后就是bilibili主页
| target属性值 | 说明 |
| _self | 默认方式,在当前窗口打开链接 |
| _blank | 在一个全新的空白窗口打开链接 |
| _top | 在顶层框架中打开链接 |
| _parent | 在当前框架的上一层打开链接 |
注意:只需要掌握“_self”和“_blank”这两个属性值就可以了,其他两个用不到。
8、容器标签<div><span>
<a href="https://baidu.com">
这是<div style="background-color:red">一个</div>红色<div style="background-color:red;">链接</div>
</a><a href="https://baidu.com">
这是<span style="background-color:red">一个</span>红色<span style="background-color:red;">链接</span>
</a>注意:
- div是块级元素一行最多放一个
- span是内联元素一行可以放多个


9、列表标签 <ol> <ul>
<ol> <ul> <dl>
<li>语</li> <li>语</li> <dd>语</dd>
<li>数</li> <li>数</li> <dd>数</dd>
<li>英</li> <li>英</li> <dd>英</dd>
</ol> </ul> </dl><ol>是有序列表
<ul>是无序列表
<dl>是自定义列表
有序列表和无序列表都比较常用,而定义列表比较少用,最常用的是无序列表。



10、表格标签<table>
<table border="1">
<thead>
<tr>
<td>表头1</td>
<td>表头2</td>
</td>
</thead>
<tbody>
<tr>
<td>1</td>
<td>2</td>
</tr>
<tr>
<td>3</td>
<td>4</td>
</tr>
</tbody>
</table>基本使用:
- table 标签 : 表示整个表格 。 table 包含 tr , tr 包含 td 或者 th.
- tr: 表示表格的⼀⾏
- td: 表示⼀个单元格
- th: 表示表头单元格. 会居中加粗
- thead: 表格的头部区域(注意和 th 区分, 范围是⽐ th 要⼤的)
- tbody: 表格得到主体区域.
设置边框:
- align: 是表格相对于周围元素的对⻬⽅式. align="center" (不是内部元素的对⻬⽅式)
- border: 表示边框. 1 表示有边框(数字越⼤, 边框越粗), "" 表示没边框.
- cellpadding: 内容距离边框的距离, 默认 1 像素
- cellspacing: 单元格之间的距离. 默认为 2 像素
- width / height: 设置尺⼨
注意:
- 设置⼤⼩边框等. 但是⼀般使⽤ CSS ⽅式来设置,属性都要放到 table 标签中
 ‘
‘
六、BeautifulSoup类
1、作用
BeautifulSoup能将网页的html解析为树状结构,使得搜索和修改html结构变容易
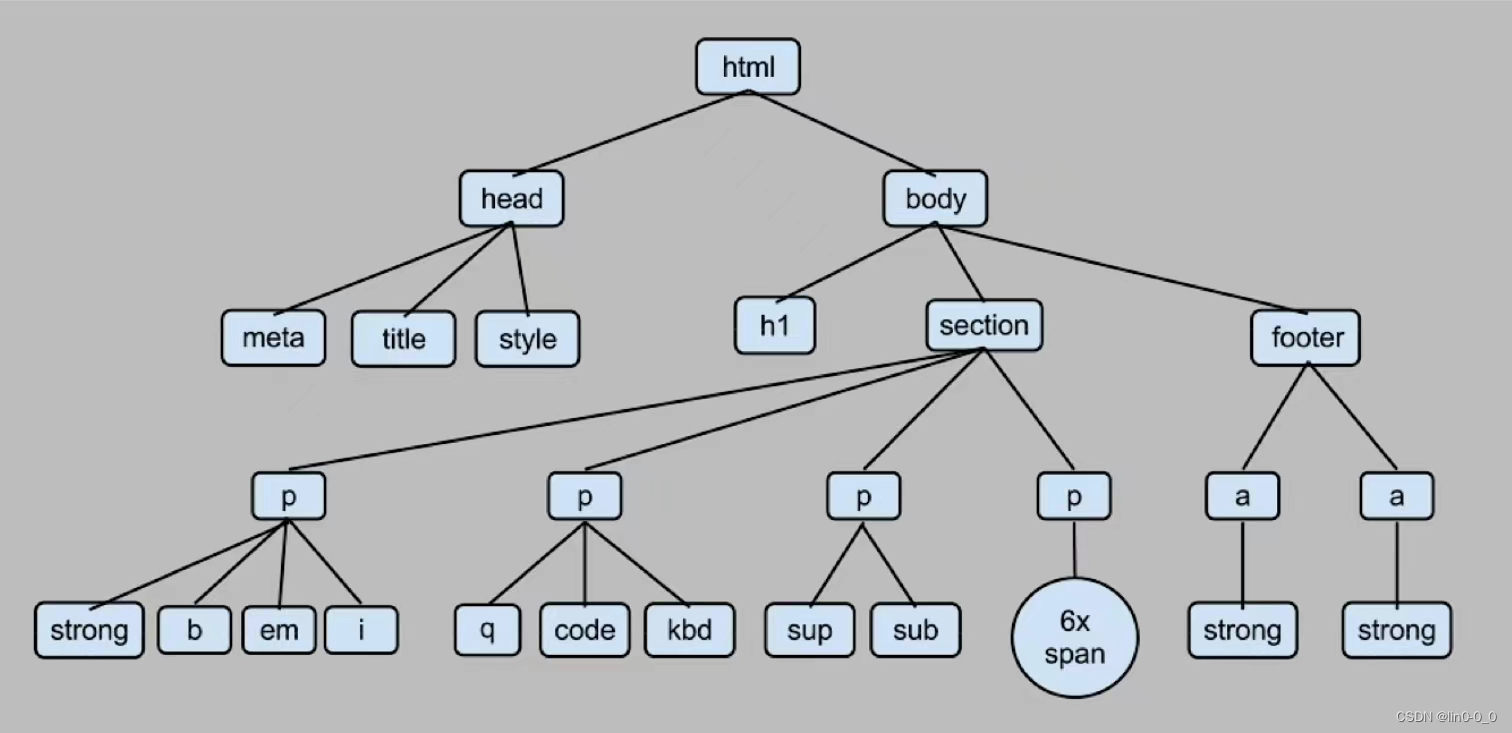
2、获取标签内内容
from bs4 import BeautifulSoup
import requests
#通过requests库里的get方法发送GET请求得到网页的html
content = requests.get("https://books.toscrape.com/").text
#BeautifulSoup不止解析html用 "html.parser"指定解析器
soup = BeautifulSoup(content, "html.parser")
print(soup.p) #得到html里的第一个段落元素
----------------------------------------------------------
<p class="star-rating Three">
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
</p>3、抓取价格
from bs4 import BeautifulSoup
import requests
content = requests.get("https://books.toscrape.com/").text
soup = BeautifulSoup(content, "html.parser")
all_prices = soup.find_all("p", attrs={"class": "price_color"}) #p标签,class属性,price_color值
for price in all_prices: #for循环依次打印获取的数据
print(price.string[2:]) #string[2:]从索引值为2开始读取
-------------------------------------------------------------
51.77
53.74
50.10
47.82
54.23
22.65
33.34
17.93
22.60
52.15
13.99
20.66
17.46
52.29
35.02
57.25
23.88
37.59
51.33
45.174、抓取书名
from bs4 import BeautifulSoup
import requests
content = requests.get("https://books.toscrape.com/").text
soup = BeautifulSoup(content, "html.parser")
all_titles = soup.findAll("h3") #爬取h3标签里内容
for title in all_titles:
all_links = title.findAll("a") #爬取a标签里内容
for link in all_links:
print(link.string) #打印string元素
-------------------------------------------------------------
A Light in the ...
Tipping the Velvet
Soumission
Sharp Objects
Sapiens: A Brief History ...
The Requiem Red
The Dirty Little Secrets ...
The Coming Woman: A ...
The Boys in the ...
The Black Maria
Starving Hearts (Triangular Trade ...
Shakespeare's Sonnets
Set Me Free
Scott Pilgrim's Precious Little ...
Rip it Up and ...
Our Band Could Be ...
Olio
Mesaerion: The Best Science ...
Libertarianism for Beginners
It's Only the Himalayas注意:
在写爬虫时要对比要抓取的数据之间的共同点,需要对数据敏感灵机应变
七、爬取豆瓣top250
import requests
from bs4 import BeautifulSoup
#伪装成浏览器请求
head = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0"
}
for ye in range(0,250,25): #更新链接(换页抓取,0是第一个电影索引值,249是最后一个电影索引值,25一页有25个电影
content = requests.get(f"https://movie.douban.com/top250?start={ye}", headers = head).text #f把链接格式化
soup = BeautifulSoup(content, "html.parser")
all_titles = soup.findAll("span", attrs={"class": "title"})
for title in all_titles:
title_string = title.string
if "/" not in title_string: #排除掉电影英文原名
print(title_string)
-------------------------------------------------------------------------------------
肖申克的救赎
霸王别姬
阿甘正传
泰坦尼克号
千与千寻
这个杀手不太冷
美丽人生
星际穿越
......(省略)八、实战练习(爬取签到表)
import requests
from bs4 import BeautifulSoup
head = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0"
}
content = requests.get("http://172.16.17.201:8000/?sign=rank", headers = head).text
soup = BeautifulSoup(content, "html.parser")
all_people = soup.findAll("ul")
for people in all_people:
all_links = people.findAll("li")
for link in all_links:
print(link.string)

总结:
1、写爬虫首先要锁定你所要爬取的数据;
2、其次要对比数据之间的差别从而精准识别到所要爬取的数据;
3、爬虫需要灵机应变,需要多加练习。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









