






 本文介绍了如何使用Yolov4开源代码训练自己的动物识别数据集,包括数据准备、图像转换、LabelImg标注、环境设置,以及训练过程中遇到的OpenMP冲突问题的解决方法。作者分享了训练过程中的关键步骤和注意事项。
本文介绍了如何使用Yolov4开源代码训练自己的动物识别数据集,包括数据准备、图像转换、LabelImg标注、环境设置,以及训练过程中遇到的OpenMP冲突问题的解决方法。作者分享了训练过程中的关键步骤和注意事项。
本实验以Yolov4开源代码训练自己的数据集,开源代码连接:
https://github.com/bubbliiiing/yolov4-pytorch
代码结构:
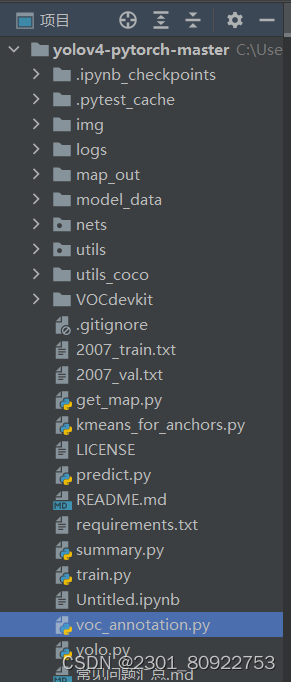
①img存放的是测试图片
②logs存放的训练的日志以及训练的模型
③model_data存放的模型配置文件以及预训练模型
④nets网络相关的代码
⑤ utils 存放的其他共性的接口文件
⑥ utils_coco存放的是处理coco格式数据的接口
⑦kmeans_ for_anchors.py 计算数据集的anchors
- 数据准备
上网寻找150张以上的动物照片,当然照片越多越好,但对于测试代码,为了节省时间,我只收集了172张做我的数据集,数据集越少运行得越快。实在懒得找也可以上网找现成的数据集。以下是存放路径:
如果都是png格式的图片,建议都转换成jpg格式的图片,可在python中完成,在现成代码中替换自己的路径即可,这里提供简单的png转jpg格式图片的Python脚本:
from PIL import Image
import os
# 设置源文件夹和目标文件夹
source_folder = '这里是需要转换的文件夹路径'
target_folder = '这里是转换输出的文件夹路径'
# 检查目标文件夹是否存在,如果不存在则创建
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# 遍历源文件夹中的所有文件
for file_name in os.listdir(source_folder):
if file_name.endswith('.png'):
# 读取PNG图片
img_path = os.path.join(source_folder, file_name)
img = Image.open(img_path)
# 转换为JPEG
rgb_im = img.convert('RGB')
# 保存JPEG图片
target_file_name = file_name[:-4] + '.jpg'
target_img_path = os.path.join(target_folder, target_file_name)
rgb_im.save(target_img_path, 'JPEG')
# 删除原始PNG图片
os.remove(img_path)
print("转换并删除原始PNG图片完成!")
- 数据处理
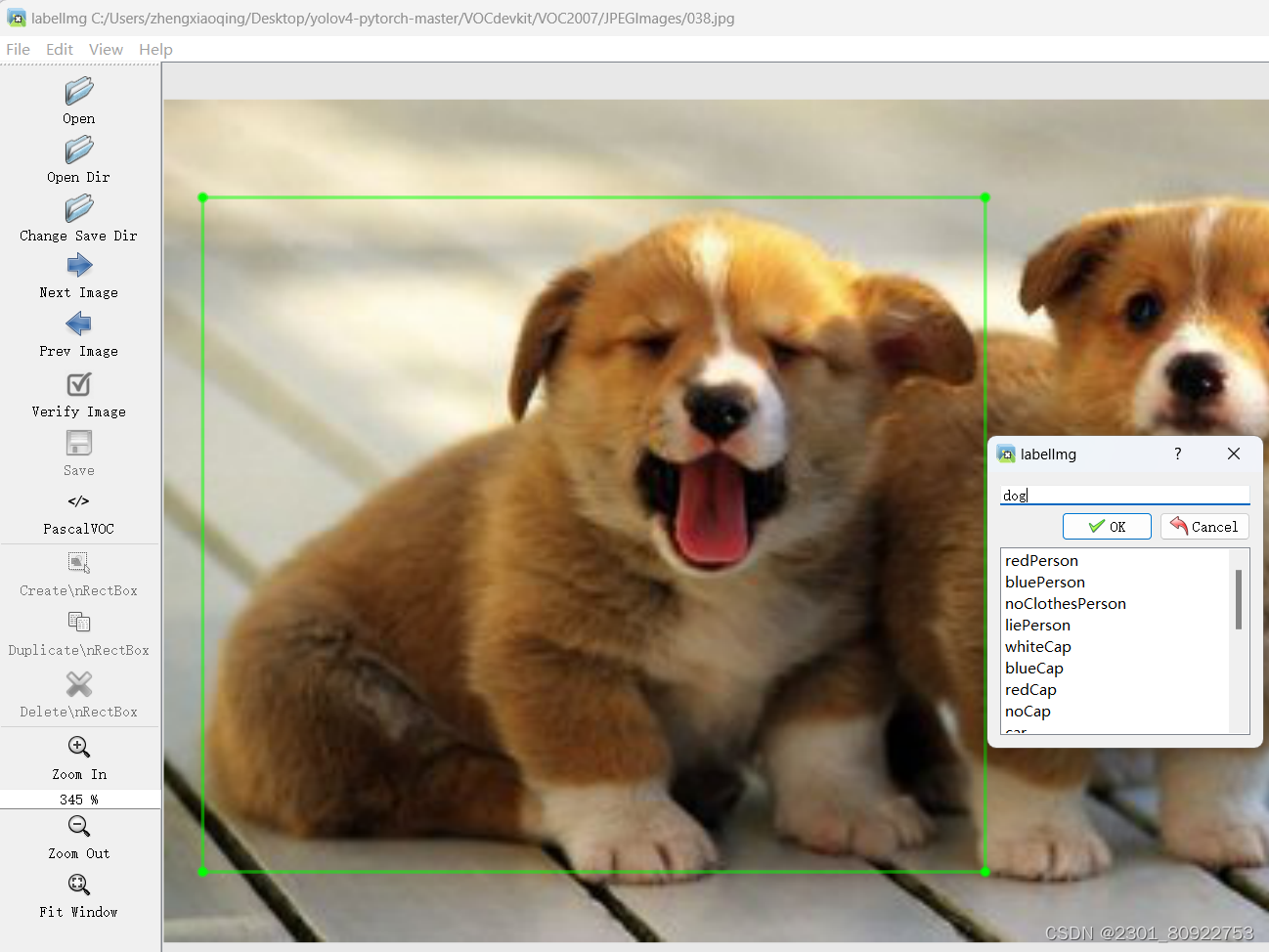
如果是自己找的数据集,就得使用labelImg标注,当图片中有多个动物都标注并打上标签。
在open中打开自己找的图片,点击Create\nRectBox框住动物会自动弹出输入标签,输入对应的动物英文。
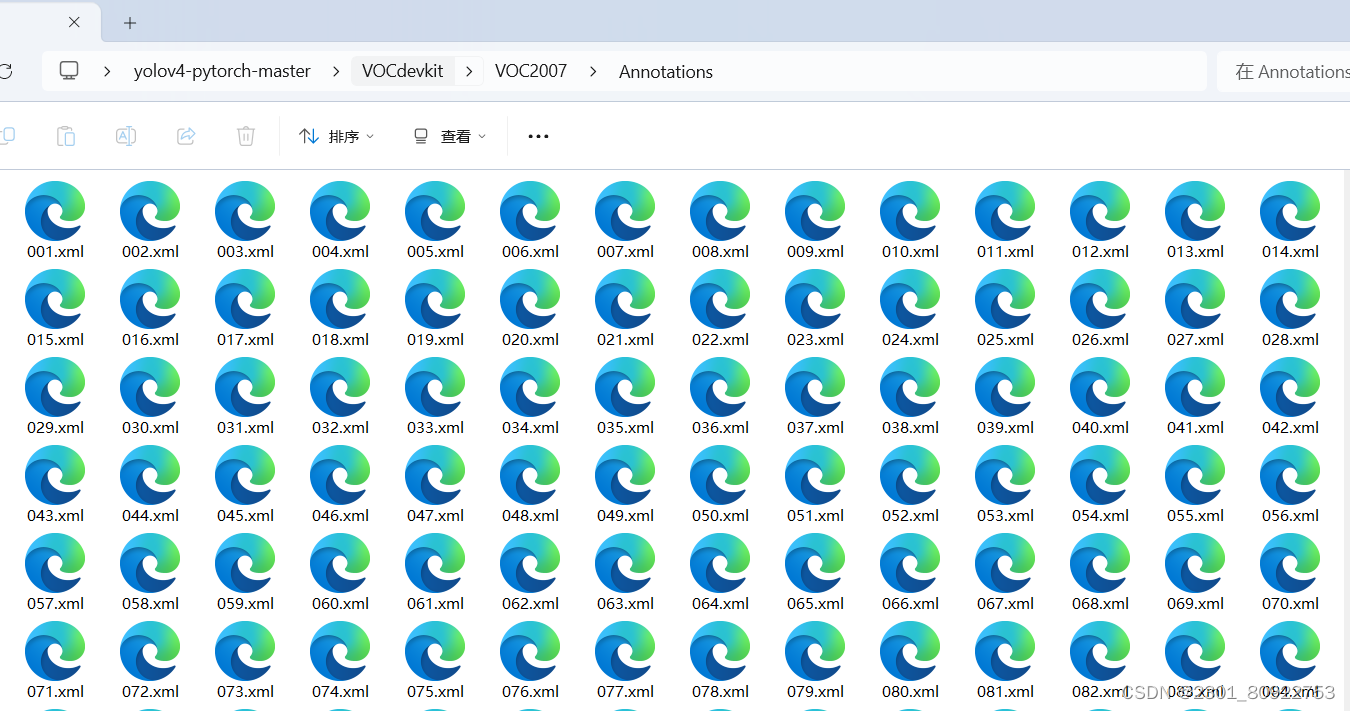
把训练自己的数据集时xml标签文件放入VOCdevkit文件夹下的VOC2007文件夹下的Annotation文件夹中,jpg图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages文件夹中即可,如图所示:
voc_annotation.py代码中有个路径需要用到我们标记的标签,打开yolov4-pytorch-master中的model_data,把里面的voc_classes.txt修改成自己标记的所有标签类型,也可以自己创建一个文件夹来存放(如下图)。
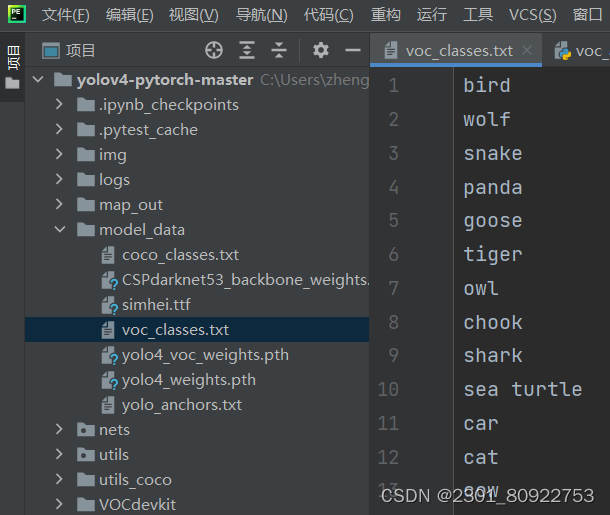
在voc_annotation.py代码中classes_path参数的路径改成voc_classes.txt文件夹路径。以上步骤我们已经完成了数据处理啦!
- python环境设置
本次实验我使用的是Anaconda环境,一般Anaconda中拥有的包比较多。在python中右下角点击python/解释器设置中更改。
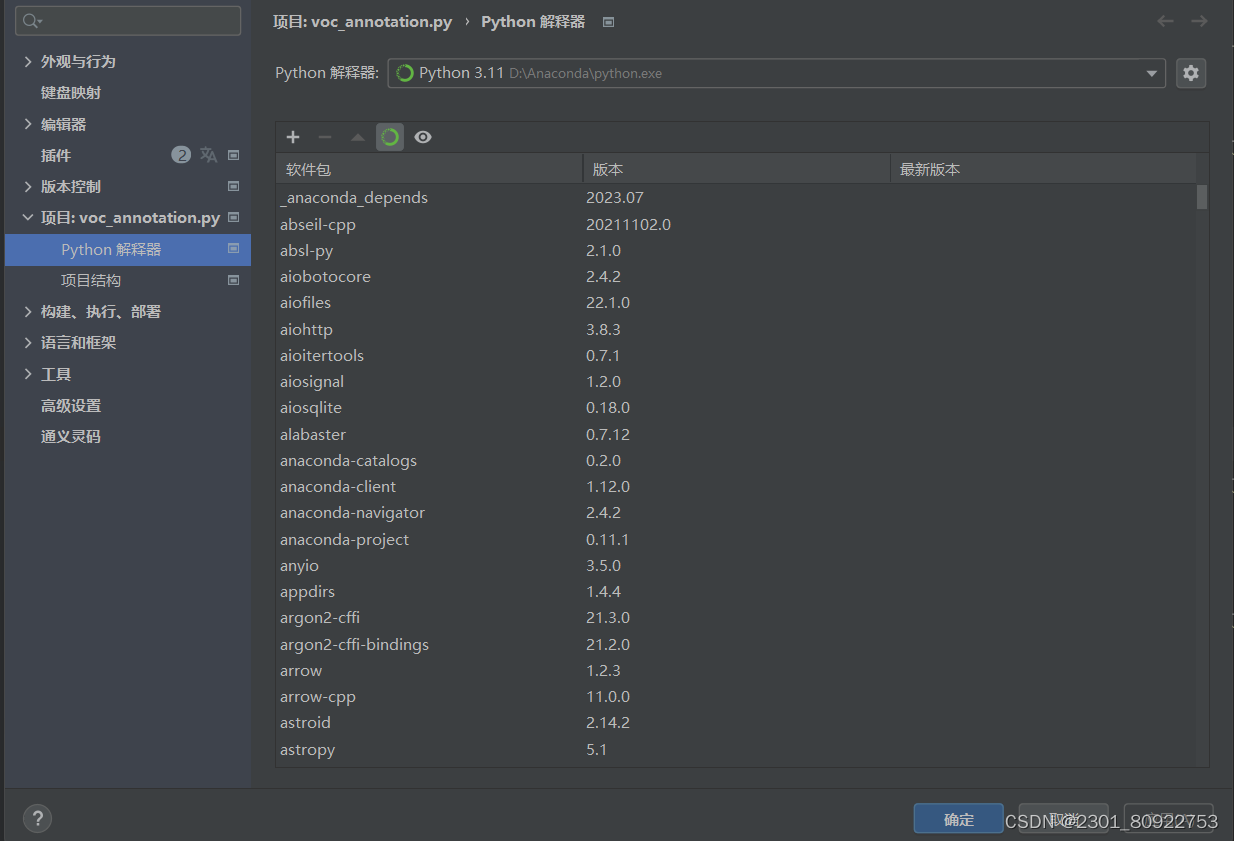
如果在代码中某些包标红或者运行后显示没有某个包,我们可以在python中左下角打开终端输入pip install 安装包,但直接这样子安装可能会非常慢,所以我们可以用镜像源来下载,以下提供常用的镜像源:
清华:https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/simple/
上海交通大学:https://mirror.sjtu.edu.cn/pypi/web/simple/
豆瓣:http://pypi.douban.com/simple/
示例:pip install -i Simple Index 安装包
- 训练数据和运行代码
1、运行voc_annotation.py代码
在整篇代码中已经给重要的代码做出解释,在这里就不再重复写了,下面我们直接看运行结果
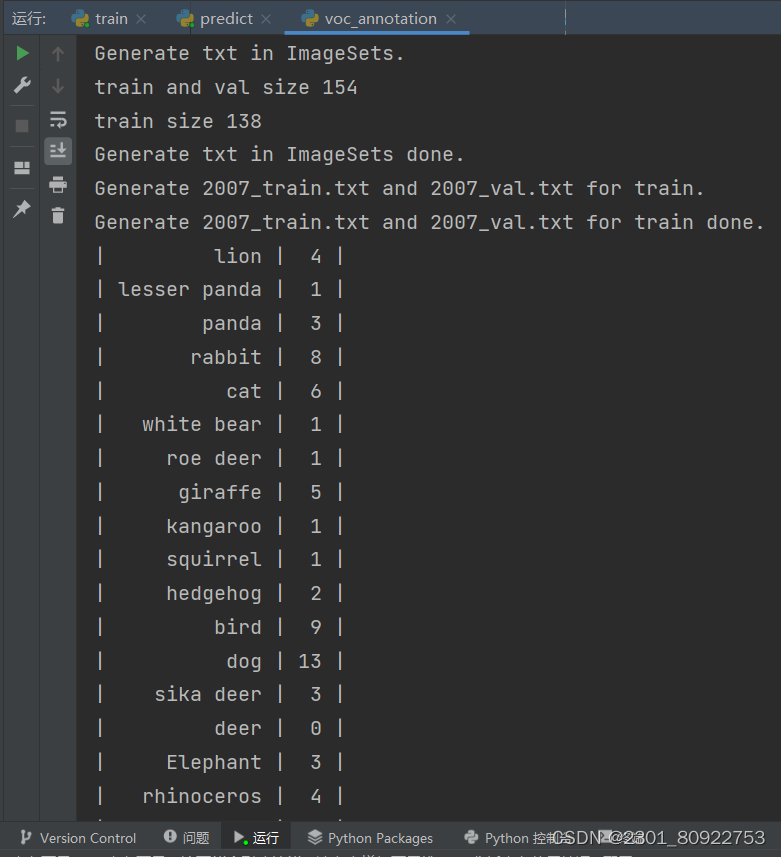

由于我个人的数据集类别比较多,在这里的结果图比较长,这里只截取部分结果。
2、运行train.py代码
1.训练自己的目标检测模型一定需要注意以下几点:
训练前仔细检查自己的格式是否满足要求,该库要求数据集格式为VOC格式,需要准备好的内容有输入图片和标签 输入图片为.jpg图片,无需固定大小,传入训练前会自动进行resize。 灰度图会自动转成RGB图片进行训练,无需自己修改。 输入图片如果后缀非jpg,需要自己批量转成jpg后再开始训练。 标签为.xml格式,文件中会有需要检测的目标信息,标签文件和输入图片文件相对应。
损失值的大小用于判断是否收敛,比较重要的是有收敛的趋势,即验证集损失不断下降,如果验证集损失基本上不改变的话,模型基本上就收敛了。 损失值的具体大小并没有什么意义,大和小只在于损失的计算方式,并不是接近于0才好。如果想要让损失好看点,可以直接到对应的损失函数里面除上10000。 训练过程中的损失值会保存在logs文件夹下的loss_%Y_%m_%d_%H_%M_%S文件夹中
训练好的权值文件保存在logs文件夹中,每个训练世代(Epoch)包含若干训练步长(Step),每个训练步长(Step)进行一次梯度下降。 如果只是训练了几个Step是不会保存的,Epoch和Step的概念要捋清楚一下。
2.在运行train.py代码时,可能会报以下错误:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.Process finished with exit code 3
可以使用以下两种方法解决:
方法一:import osos.environ["KMP_DUPLICATE_LIB_OK"]="TRUE
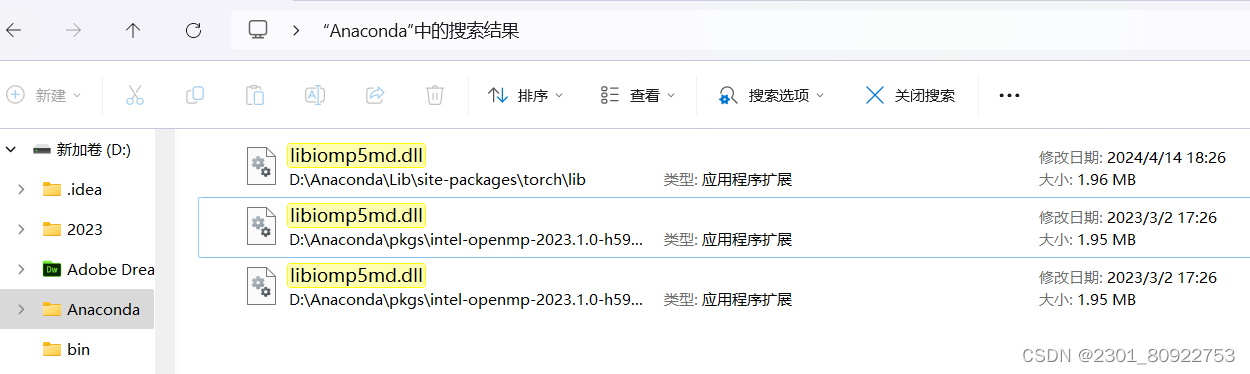
但是这种方式治表不治里,在下一个项目运行中还有可能出行同样的问题。本问题出现主要是因为torch包中包含了名为libiomp5md.dll的文件,与Anaconda环境中的同一个文件出现了某种冲突,所以需要删除一个。
方法二:在Anaconda文件夹下搜索,如下图,删除Anaconda包中libiomp5md.dll这个文件,只保留如下图所示即可。
3.结果图
① epoch_loss损失曲线图
图中有四条线,分别用不同颜色标识:
红色实线表示训练损失(train loss)。
橙色实线表示验证损失(val loss)。
绿色虚线表示平滑后的训练损失(smooth train loss)。
蓝色虚线表示平滑后的验证损失(smooth val loss)。
横轴标记为“Epoch”,范围从0到300。
纵轴标记为“Loss”,范围从0.04到0.12左右。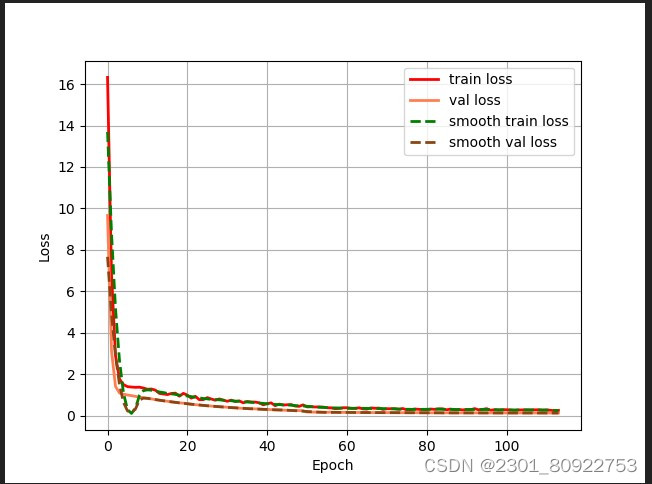
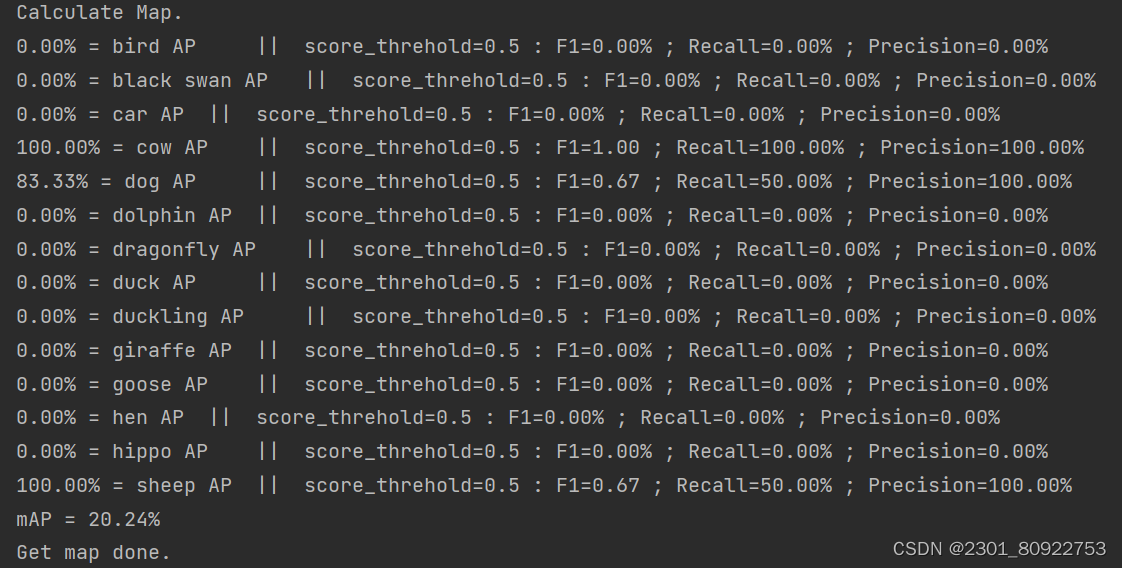
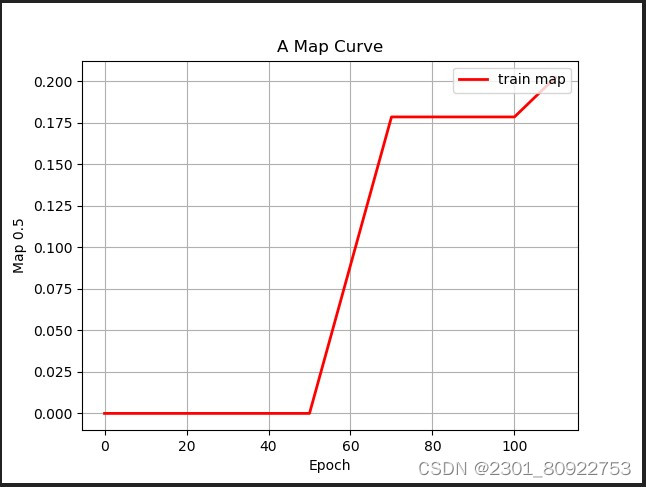
② epoch_map平均精度曲线图
红色曲线代表“train_map”随“Epoch”变化的趋势。
横轴标记为“Epoch”,范围从0延伸至300。
纵轴标记为“mAP”,范围从0到1.0。
3、运行predict.py代码
结果图:
由于标签的顺序乱了,就会存在以下情况,能识别出动物和准确率,但识别的目标标签不准确的情况。

之后我把voc_classes.txt和coco_classes.txt中的horse的标签换成sheep的标签,输入的图就正确对应目标标签了


此篇内容并不完美,个人作业,仅供参考。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









