








🌟🌟作者主页:ephemerals__
🌟🌟所属专栏:Linux
目录
前言
本篇文章我们在了解了进程概念和状态等基础知识之上,继续学习进程的优先级,以及进程切换相关知识。
正文开始
一、进程优先级
1. 什么是进程优先级
进程优先级是操作系统分配给进程的一种“权重”或“级别”,用来决定在多个进程同时竞争 CPU 资源时,哪一个进程先获得运行的机会。优先级高的进程会被优先调度执行,低优先级的进程则可能需要等待。
2. 为什么有进程优先级
大多数情况下,正在执行的程序数量是比较多的,而CPU资源有限。为了使那些重要、急需执行的任务先执行,就有了优先级。这样一来,资源分配会得到优化,整个系统更加合理高效。
注:现代操作系统更加考虑进程获取资源的公平性,优先级的差距不会太大。
3. 进程优先级的作用
进程优先级可以保证关键任务或实时任务及时调度(如操作系统内核进程通常优先级较高),并且可以防止某个进程长期占用 CPU,改善系统性能。其次,优先级可以实现多用户或多任务下的公平资源分配。
4. Linux进程优先级的本质
在Linux下,进程优先级的本质就是一个整数,存储在task_struct结构体当中,直接影响了进程调度的先后顺序。进程优先级的值越小,优先级越高。
可以使用以下命令查看到当前所有进程的优先级:
ps -al运行结果:

PRI:进程优先级的值,默认是80
NI:也叫做nice值,是进程优先级的修正数据。其取值范围是[-20, 19]。
PRI的默认值(80) 和 NI 之和表示进程的真实优先级大小。也就是说,Linux进程优先级的范围是[60, 99],一共40个。
注:ps -l指令还可以看到当前进程的PID,父进程ID等。其中还有一项UID,它用来标识Linux下的用户,进行用户区分。当用户创建进程时,进程会记录用户的UID,访问文件时(本质是进程在访问),进程就拿这个UID与文件的拥有者或所属组的UID进行对比。
5. 修改进程优先级
在Linux下,修改进程优先级主要是通过修改nice值来完成(注意nice值的取值范围)。可以使用top命令修改进程优先级:
输入top --> 按“ r ” --> 输入进程的PID --> 输入新的nice值
注意:普通用户只能给自己的进程设置优先级,且只能将优先级调低(nice值调高);而root用户可以在取值范围内随意调整任意进程的优先级。
接下来我们尝试调整一个进程process的优先级:
process的源码:
#include <stdio.h>
#include <unistd.h>
int main()
{
while(1)
{
sleep(1);
printf("hello\n");
}
return 0;
}
首先运行process,查看process的优先级:

可以看到process的优先级是80。接下来将nice修改为10:

这里process的PRI变成了90,而nice值为10。此时90是process的真实优先级。
如果修改为-10:
![]()
可以看到,普通用户下,将nice值调低是不被允许的。
如果改为100:

由于取值范围的限制,nice值最高为19,输入100只能将其改为19。
注意:如果优先级设置不合理,就会导致优先级低的进程长时间获取不到CPU资源,导致进程饥饿。
二、进程切换
1. 概念
CPU在执行一个进程时,由于还有其他进程的存在,它不会一次将所有代码全部跑完,而是跑一会后,转而去执行其他进程,再来执行当前进程......这样才可以在一段时间之内使得多个进程都有所推进。CPU从执行当前进程变为执行其他进程的过程叫做进程切换。
当代操作系统都是分时的,每个进程都有它相应的时间片(本质就是一个计时器)。当前进程的时间片用完后,就会切换到其他进程。
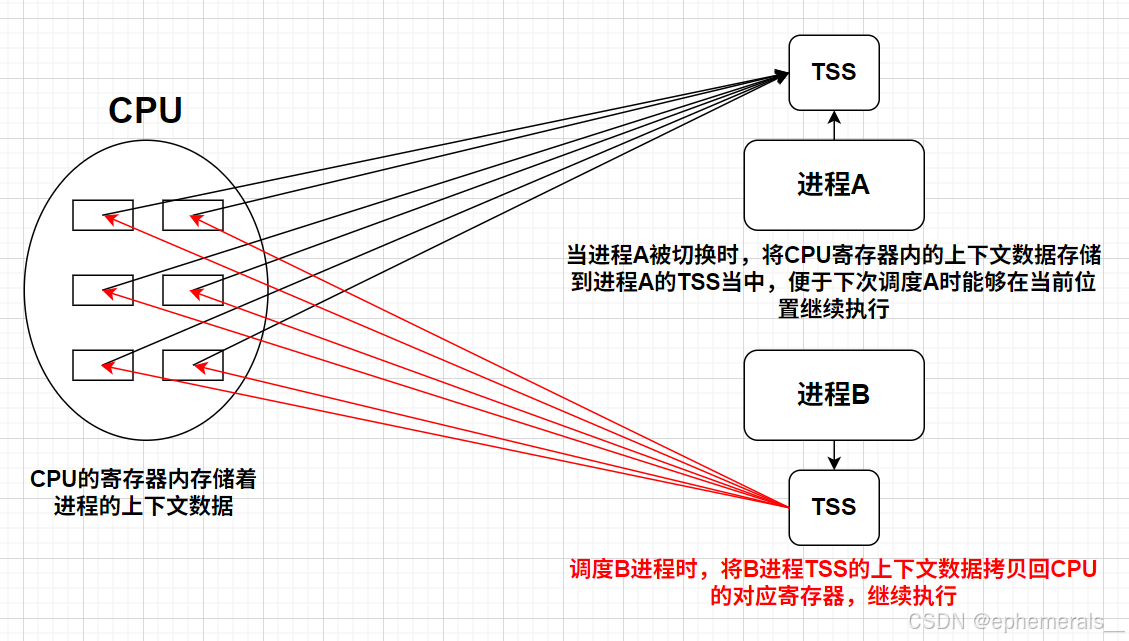
2. 进程切换的过程
一个进程在CPU上运行到时间片结束之后,首先存储自己执行位置的上下文数据到自己的TSS(任务状态段,存储在task_struct当中)当中,然后将进程重新放入调度队列队尾。进程发生切换时,将新的进程的TSS中的数据拷贝(恢复)到CPU的对应寄存器中,继续执行。
进程的上下文数据指的是进程在运行时,需要保存和恢复的所有关键信息(例如发生切换时CPU寄存器中的数据),这样就可以保证进程发生一系列切换后,重新执行该进程时,能从原来的状态继续执行。
3. 进程切换的意义
进程切换让操作系统能管理多个进程,保证各进程能按照优先级获得CPU使用权,是实现多任务的基础。多个进程可以“轮流”运行,系统利用率和响应速度得以提高。
4. Linux的进程调度(O(1)调度算法)
高效的进程切换不仅保证了多任务系统的流畅运行,还直接影响着系统的响应速度与整体性能。为了实现快速、合理的进程调度,Linux内核采用了多种调度算法,其中O(1)调度器就是在2.6版本中所引入的一种重要算法。接下来,我们将深入了解O(1)调度算法,看看它是如何实现对大量进程的高效管理的。
在之前的文章中,我们提到过一个CPU维护一个进程调度队列,该队列中存放着一个个PCB,等待CPU对它们进行调度。实际上这个“进程调度队列”远远比传统的队列复杂。在Linux中,进程调度队列叫做runqueue,它的结构如图所示:
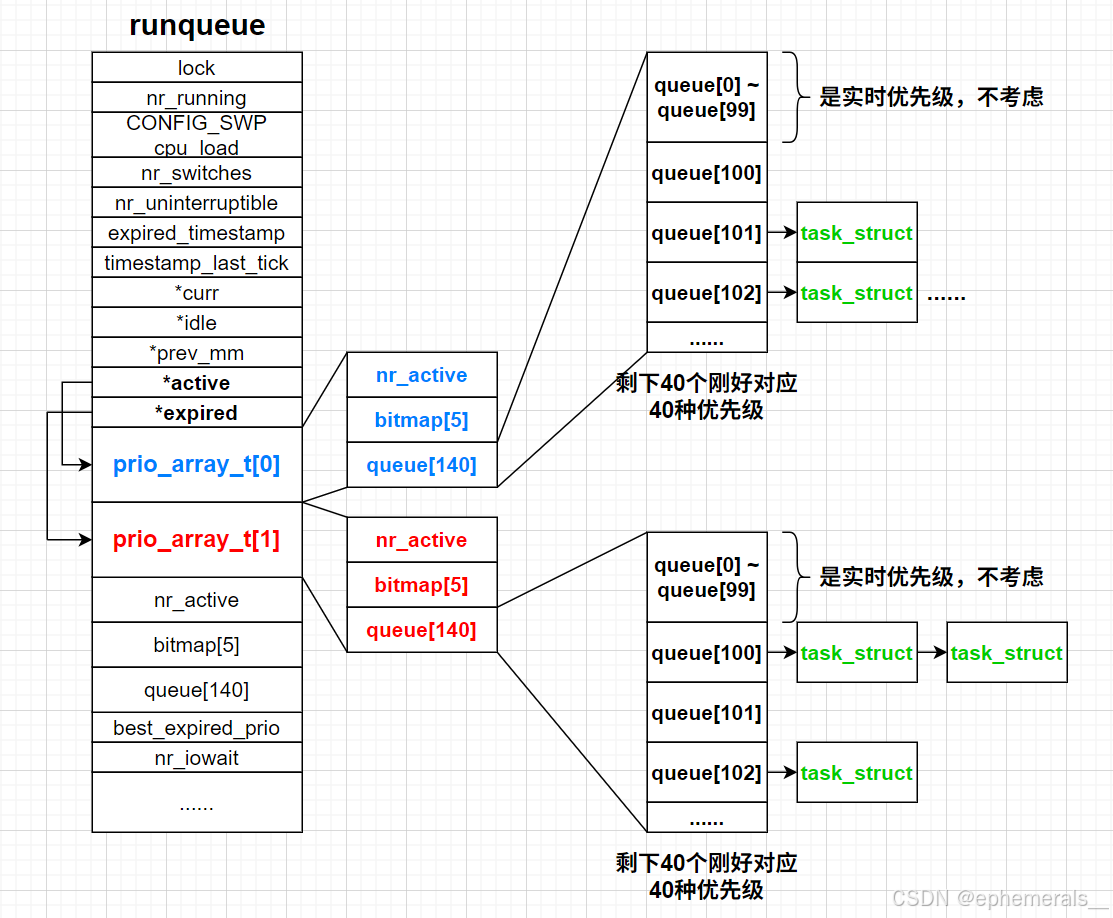
一个CPU维护一个运行队列runqueue,其中数组prio_array_t中的queue是存放进程PCB的关键。
queue本质是一个链地址法的哈希表,其中有140个哈希桶(前100个哈希桶表示实时优先级,剩余40个刚好对应40种优先级,所以哈希桶的下标 - 40就是进程优先级),相同优先级的进程task_struct存放在同一个哈希桶中,这样,当需要调度时,按照下标小到大的顺序扫描每一个哈希桶,先访问到的进程就是优先级高的(因为优先级的值越小,优先级越高),然后拿出桶中的task_struct进行调度。
考虑到每次都要遍历140个哈希桶,效率较低,所以有一个位图bitmap,位图中有5个32位的整形变量,加起来一共160位,其中的140位表示对应的哈希桶中是否有task_struct,所以可以直接判断哪一位是“1”,就表示哪一个桶需要被访问。除此之外,还有一个变量nr_active,表示整个哈希表中的元素个数,对应正在运行时的进程个数。
queue、bitmap、nr_active共同构成一个结构体,叫做rqueue_elem。
如此,访问位图,按顺序找到存在元素的哈希桶,进行调度,整个调度过程效率就能达到O(1)。
但是图中的prio_array_t数组有两个元素,也就是说有两张哈希表,这是为什么呢?这就要从进程切换的角度开始谈起了。
试想,如果只有一张哈希表,那么发生进程切换时会怎么样?
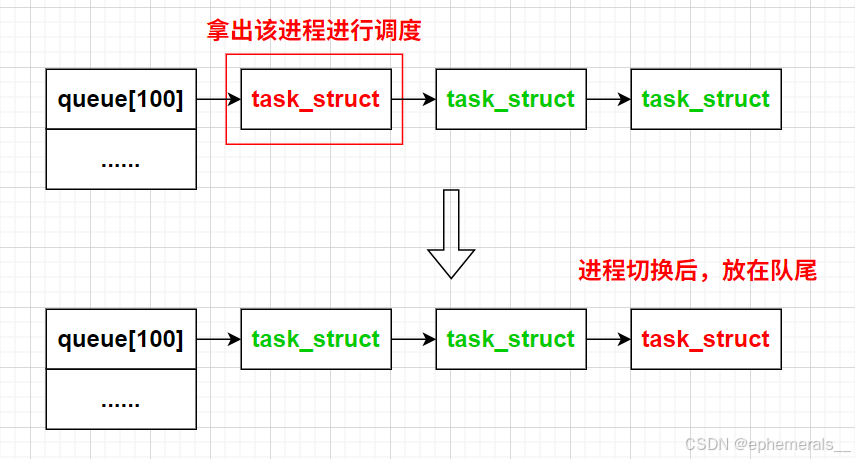
假设第100个哈希桶当中有3个进程,第一个进程的时间片耗尽后,会发生进程切换,此时按照优先级,只能将它重新插入在当前哈希桶的链表尾部,当然,其他两个进程也是如此。这样虽然能够完成这3个进程的轮流调度,但是更低优先级(也就是下标更大的哈希桶)的进程呢?当前哈希桶中只要有元素,CPU就会一直轮流调度当前哈希桶中的进程,而会忽略优先级更低的进程,导致进程饥饿。要调度优先级更低的进程,就必须等待当前优先级的进程全部调度完毕,显然是不合理的,极大地损失了公平性。
因此,前辈们想到了一个巧妙的方法:再创建一个相同的结构体rqueue_elem,其中也包含一个queue、bitmap、nr_active,两个rqueue_elem构成一个数组prio_array_t[2]。
然后创建两个指针native和expired,分别指向prio_array_t[0]和prio_array_t[1],native指向的表示“活跃队列”;expired指向的表示“过期队列”。当发生进程切换时,被调度结束的进程会插入到“过期队列”的对应优先级的哈希桶中,然后继续访问“活跃队列”中的哈希桶,一个个地调度。这样,当前“活跃队列”哈希桶中的元素就会越来越少,直到为0,就可以访问优先级更低的哈希桶......最后所有进程都会被调度,而不是高优先级进程运行完毕后才能调度低优先级进程。
当“活跃队列”整个哈希表内的进程都被调度过后(此时这些进程应全都位于“过期队列”对应的哈希桶中),交换native和expired两个指针的指向,这样“过期队列”就变成了“活跃队列”,就可以开始下一轮的调度了。
如果有新进程出现,会直接插入“过期队列”当中。此时新进程处于“就绪状态”,等待一轮的调度结束后,新进程就可以被调度。
总结
本篇文章,我们系统地了解了进程优先级的定义、意义以及在Linux下的调整方法,也梳理了进程切换的基本流程与核心作用。从进程优先级到切换机制,再到Linux的O(1)调度算法,这些知识共同揭示了操作系统在多任务管理中的高效与精妙。掌握这些原理,有助于更深入理解和优化 Linux 系统的性能,为后续程序地址空间和进程控制的学习打下坚实基础。如果你觉得博主讲的还不错,就请留下一个小小的赞在走哦,感谢大家的支持❤❤❤

















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









