






在上一篇博客中,介绍了堆的实现,现在来介绍一下堆排序。
一.打印有序:
现在先给一个无序的数组,现在我们利用我们实现的堆的功能先完成一下打印排序:
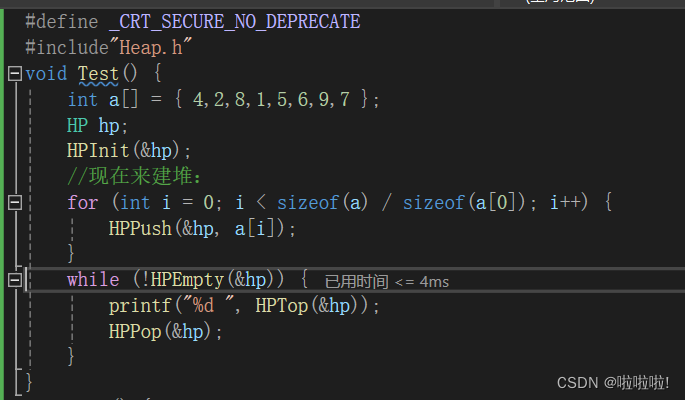
在for循环里是一个建堆的过程,每来一个数据就放入堆中。
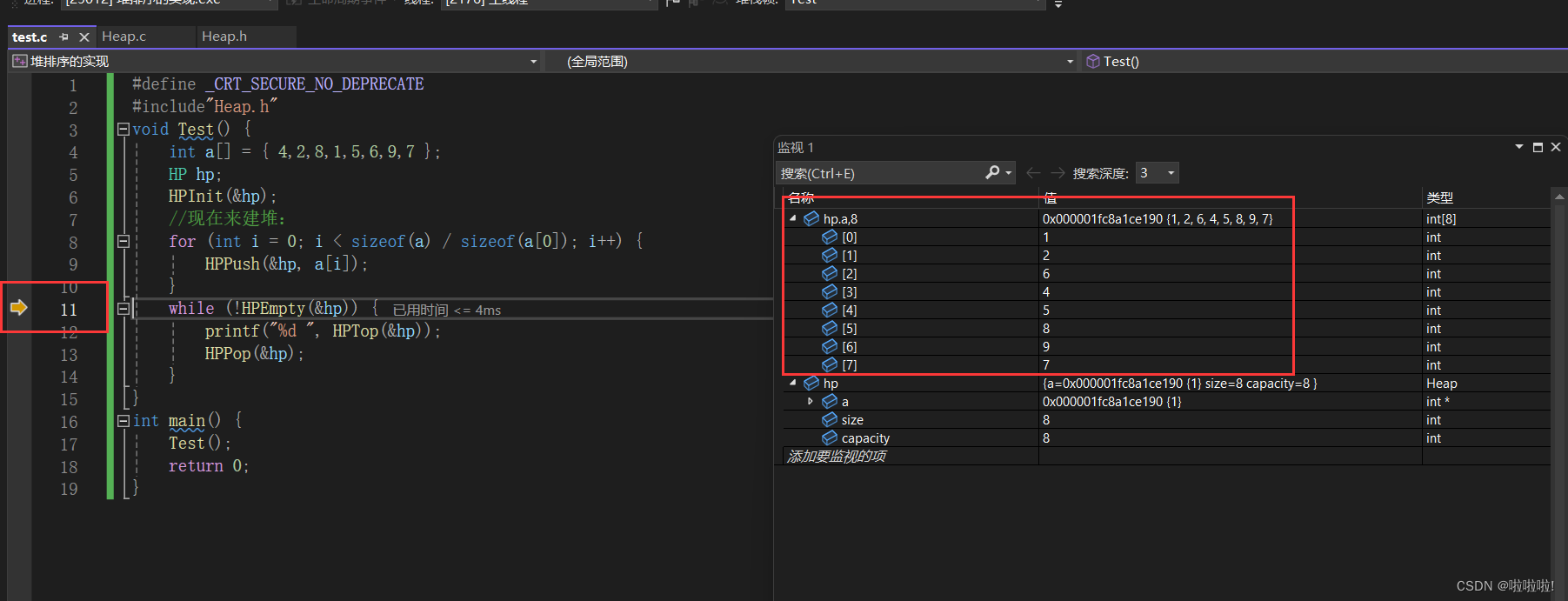
在调试中不难发现,在经过建堆过程之后,我们在这里建的是小堆:
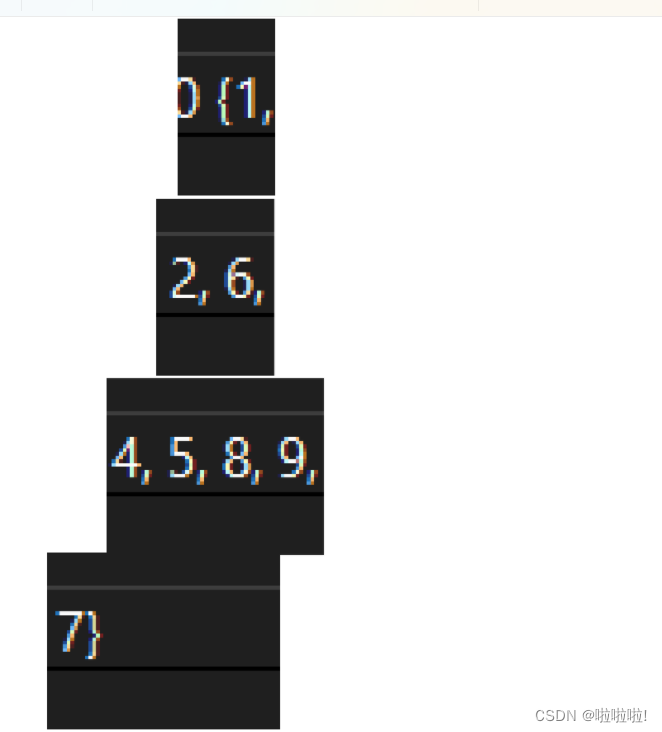
建立小堆完之后,此时我们要完成打印上的排序,在这里就利用循环不断利用取堆顶数据的函数,和删除堆顶数据的函数(利用了向下调整算法在删除后还是保持小堆的性质),这样就完成了打印排序:
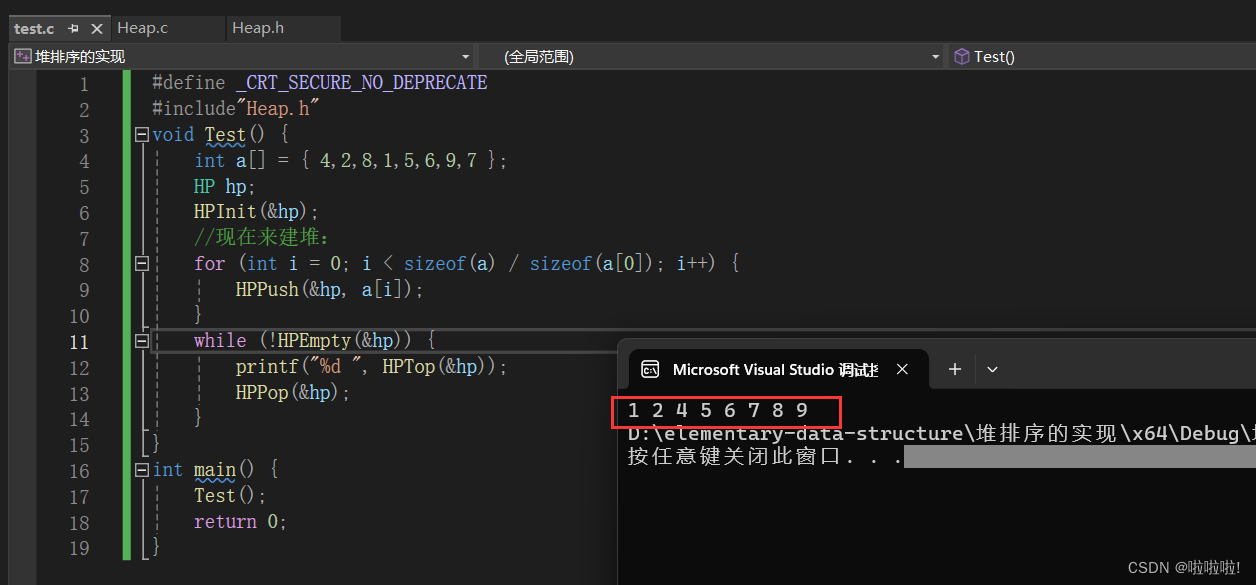
上面实现了从小往大的打印排序,现在要建大堆,来实现从大往小打印排序:
这里只需要改一下向上和向下算法里,孩子节点与父亲节点的比大小关系即可:
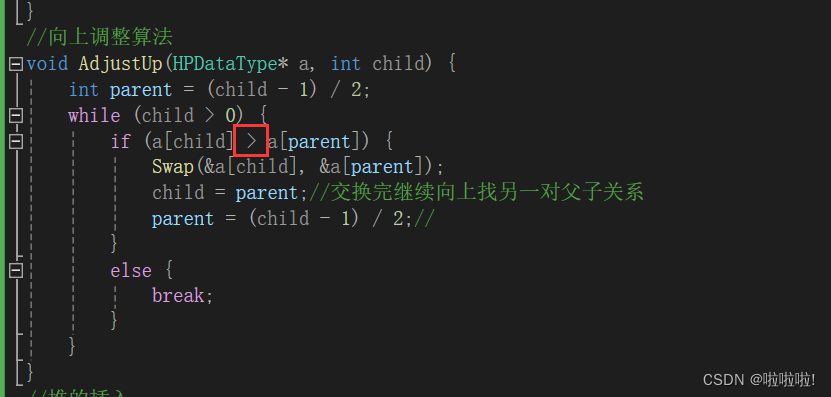
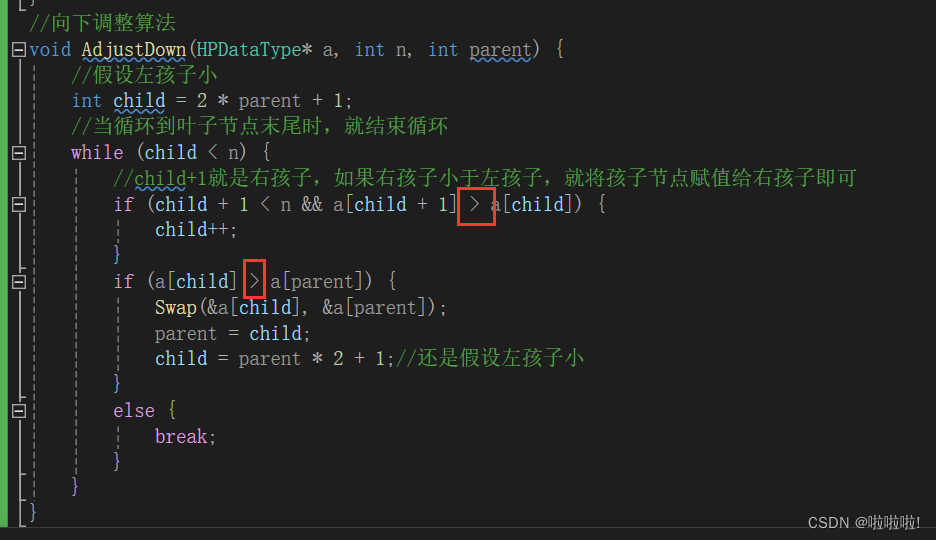
将这两个大小比较换一下即可,这样就变成了大堆,现在就完成了降序:
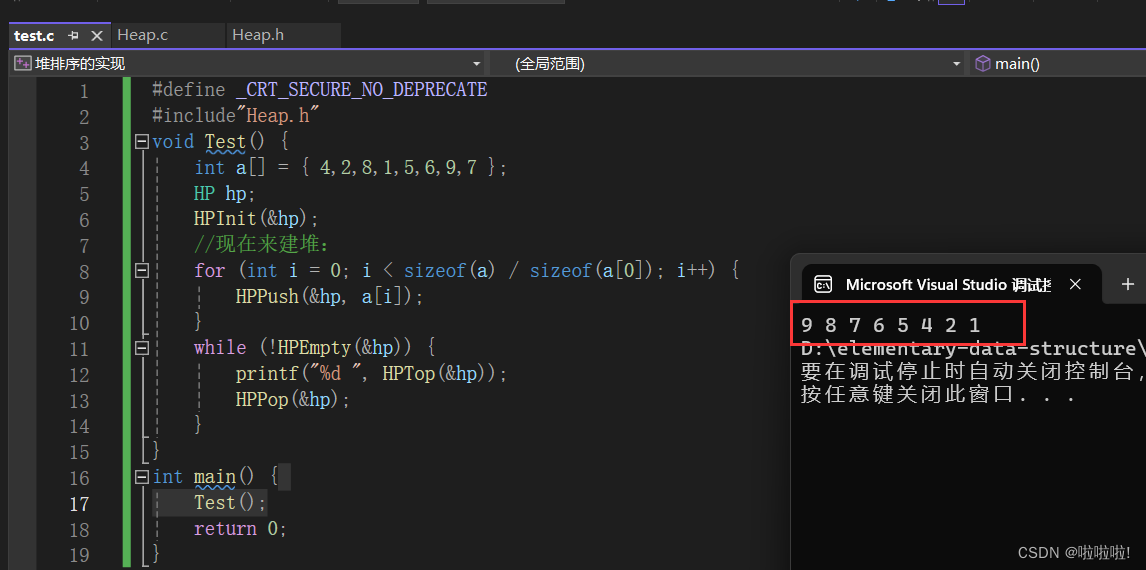
所以这就是为什么HPPop是删除堆顶的数据了,这样不管是小堆还是大堆这样就能实现排序,每次删除都能找到次小或者次大的值。在介绍二叉树的性质时,我们推导过,假设这个数是N个节点,则高度为:

所以这样排序的时间复杂度就是log2(N),而冒泡排序的时间复杂度是N^2,所以这个排序是效率非常高的。
二.真正实现堆排序:

这里如果给你一个数组,而我们如果再去利用我们封装好的堆的初始化之类的函数的时候,这样我们就会开辟新的空间,所以我们实现堆的排序,直接就是利用向上调整算法,直接将数组调成堆的样子,这也是为什么在写向上和向下调整算法时,传的是数组的地址,而不是传数据结构。
而这里循环从数组的1的位置开始,原因是这里直接将数组0的位置直接看成堆,然后向下插入,再向下调整。
现在来试一下,建堆是否成功:
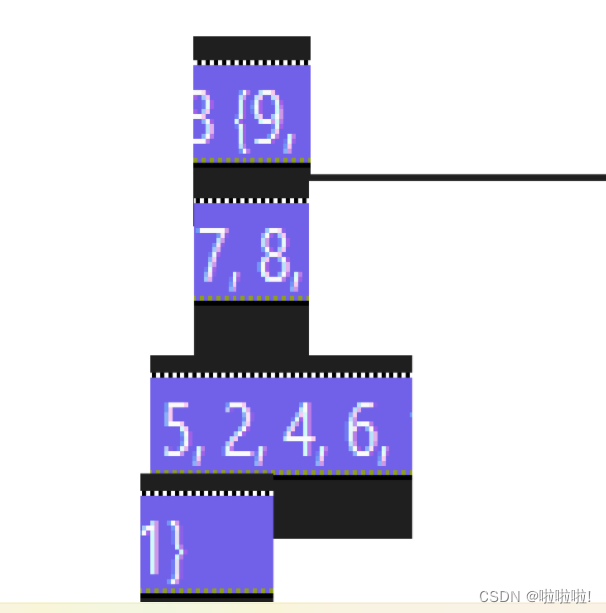
这里也是建大堆成功。
这里虽然建大堆成功,但我们想要降序时,堆顶的数据就不能动了,此时我们要找出次大的数据,这里我们只能将剩下的数看成一个堆:

左边是每删数据前,后面是要找次大的数据把剩下的数据看成堆的情况,但是我们可以发现,原本父子关系的节点,现在变成了兄弟节点,关系变混乱了,所以这里不是大堆了,不管用向上还是向下的算法都不行了,这里可以重新建堆,但是这里会导致复杂度上去,代价太大了,所以不用这种方法。
所以在这里我们要考虑降序建大堆还是小堆,升序建大堆还是小堆:
这里直接说结果,降序去建小堆,升序去建大堆。
先来解释降序建小堆怎么玩:
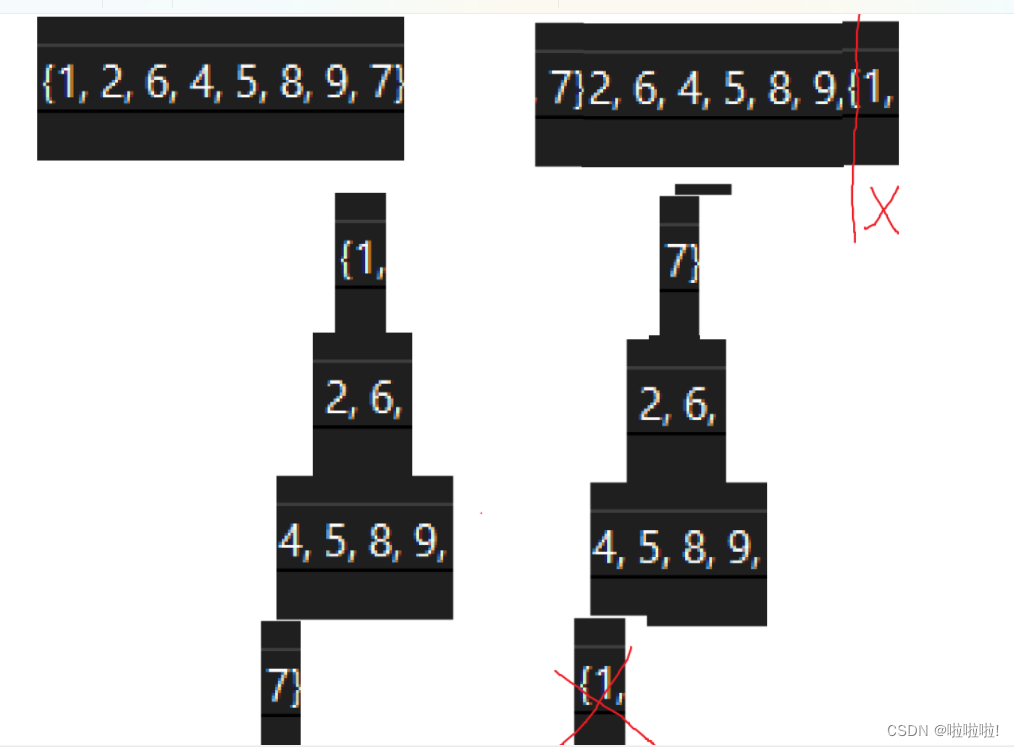
首先小堆建完,这里我们要降序,因为是小堆,所以最小的数在堆顶,此时我们就将堆顶的数与最后一个数进行交换,然后将最后一个数覆盖掉(不是真覆盖),此时在利用向下调整算法,找到次小的那个数据,然后再与倒数第二个数交换,然后再利用向下调整算法,整个一套流程下来,数组里的值的位置就发生了变化,此时也实现了降序。
在这里我们可以算一下这样堆排序的复杂度,每调整一次是二叉树的高度logN,一共有N个数据,所以其复杂度就是logN*N,所以这样排序效率更高。

在向上向下调整算法中,小于就是建小堆,大于就是大堆。
在上面的叙述中先前用的都是向上调整建堆,有没有别的建堆方法呢,这里我们还有向下调整建堆,当左子树右子树都是大堆或者小堆时可以用向下调整算法,但是如果不是呢
这里有个方法就是倒着建堆:

思路就是先找到最后一个叶子节点在这里就是9,然后找到其父亲节点也就是5,然后先进行调整,调整完过后圈1里的那个数据就成堆了,再次调整,5减减之后就是另一个父亲节点1,再给1那里建堆也就是圈2,再减减找到另一个父亲节点8,再次建堆,建完之后就是圈3,再减减父亲节点就是2,因为上面已经将父亲节点2下面的孩子节点已经调成了堆,所以直接用向下调整算法调整大圈里的数据,也就是圈4,最后就调整整个树就是,这样堆就完成了,这个向下调整建堆的时间复杂度是O(N).效率更高

总结:堆排序是脱离了堆的结构,只是用了向上和向下调整算法,并且堆排序的时间复杂度是O(logN*N)和O(N),而冒泡排序时间复杂度是O(N*N),当数据很大时,堆排序的时间效率更高,更快,比冒泡排序好很多。















 5298
5298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









