






有如下数据:
如何按照"学校名称"进行分组,然后对每个学校的"专业代码"进行计数统计呢?
请看下边介绍
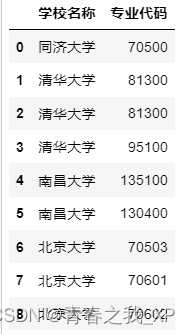
(一)导入数据
import pandas as pd
data=pd.read_excel("C:\\Users\\86159\Desktop\\CSDN\\分组计数数据.xlsx")(二)查看重复行
data.duplicated()#查看重复行结果如下:
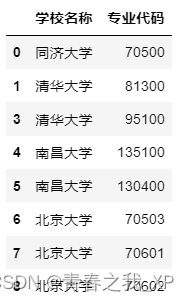
说明索引为2,也就是第三行是重复行,一般在进行分组计数前需要去除重复数据

(三) 去除重复行
#删除重复行
data=data.drop_duplicates(keep='first')其中,`keep='first'` 表示在删除重复记录时,保留第一次出现的记录。换句话说,它会删除后续出现的相同记录,只保留第一个出现的记录。
结果如下:
可以看出,索引为2 的那一行重复值被删除掉了,剩下的数据都是不重复的
(四)分组计数
#groupby按学校名称分组
#agg对"专业代码"这一列数据进行统计频数
result=pd.DataFrame(data.groupby(['学校名称'])["专业代码"].agg('count'))
result.columns=["专业数量"]#指定列的名称为专业数量代码的意思是对名为"学校名称"的列进行分组,然后对"专业代码"列进行计数求和操作
result.columns=["专业数量"]:指定列的名称为专业数量
结果如下:

(五) 对数据进行排序(降序或升序)
#根据"专业数量"进行排序
result.sort_values(by="专业数量",inplace=True, ascending=False)
这是一行Python代码,用于对名为`result`的DataFrame进行排序。
以下是代码的组成部分和含义:
1. `result.sort_values()`:这是Pandas库中的一个方法,用于对DataFrame进行排序。
2. `by="专业数量"`:指定排序的依据是列名称为"专业数量"的列。
3. `inplace=True`:表示在原地(inplace)进行排序,而不是创建一个新的排序后的DataFrame。
4. `ascending=False`:表示按照降序(descending)排序。如果设置为True,则表示按照升序(ascending)排序。
综上,这行代码的意思是:根据名为"专业数量"的列,对名为`result`的DataFrame进行降序排序。
结果如下:

排完序后,可以取专业数量前三名的数据,如下:
result_top=result.head(3)#前3个数据















 2195
2195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









