






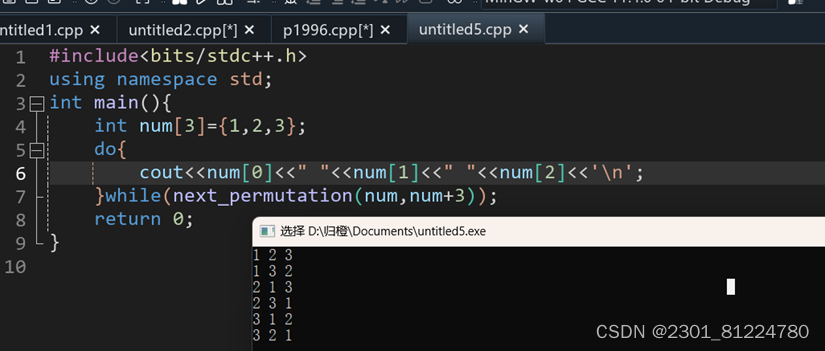
知识点一:全排列函数:next_permutation(start,end)/bool next_permutation(iterator start,iterator end),
O(n!);
Next_permutation()在使用前需要对欲排列数组按升序排序,否则只能找出该序列之后的全排列数。当前序列不存在下一个排列时,函数返回false,否则返回true.
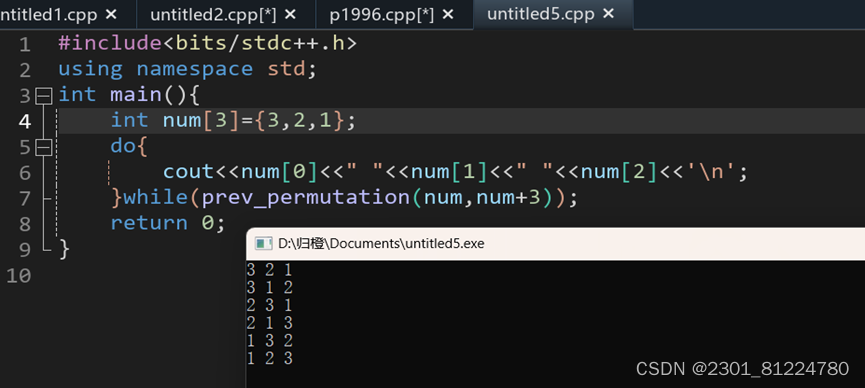
prev_permutation:对欲排列的数组按降序排序。
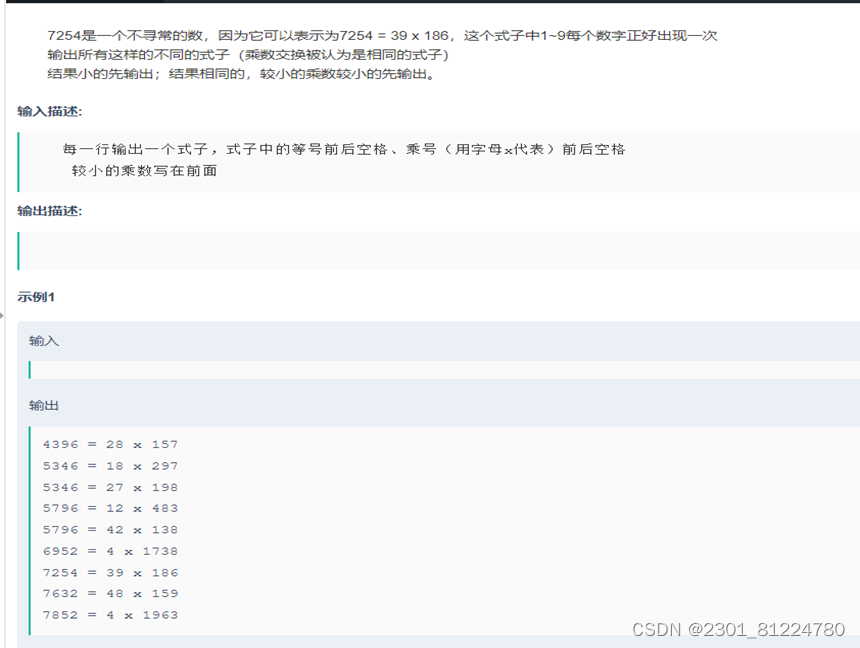
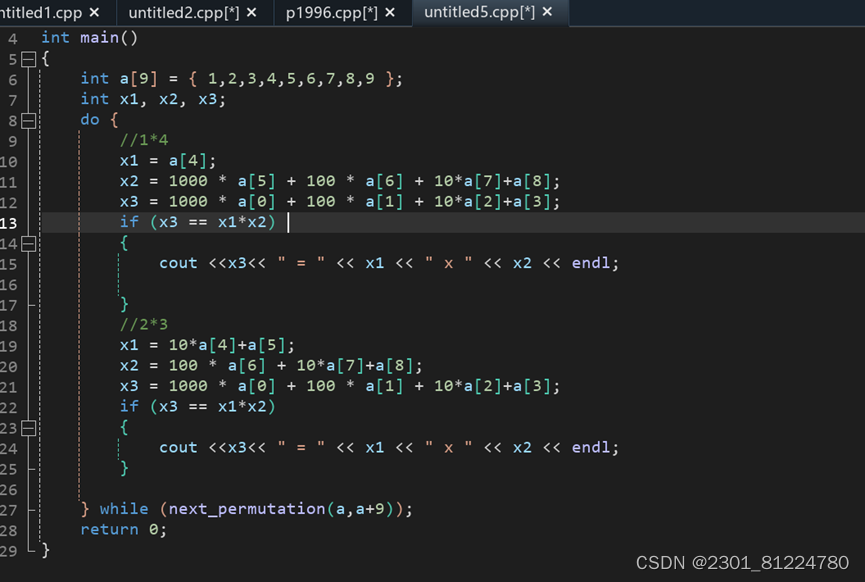
知识点二:cout<<fixed<<setprecision()<<x;
控制浮点数输出的精度,保留两位小数。
只要出现了fixed,则后面都是以fixed输出(就是说,如果之后还要继续使用,不同再打一遍fixed了),如果取消,使用unself函数。例:cout.self(ios::fixed);
cout<<hex<<x<<endl;(输出十六进制)
知识点三:

知识点四:substr函数:
substr除了有字段截取的功能外,还可以用来替换字段。

(string,start<,length>)从string 的start位置开始提取字符串
length:待提取的字符串的长度,若length为一下情况时,返回整个字符串的所有字符。
1、length不指定
2、length为空
3、length为负值
样例:
str="wqerwtweafs";
str1=substr(str,5);
str2=substr(str,5,"");
str3=substr(str,5,-3);
str4=sunstr(str,5,30);
注意:
substr中的start为负数时返回空值
当length为负值时,默认从start位置截取所有字符
substr从字符串右侧截取字符的方法
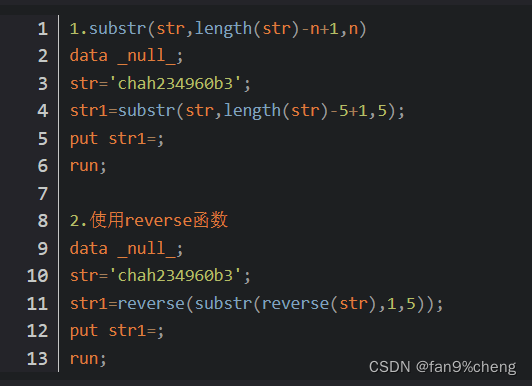
substr除了有字段截取的功能外,还可以用来替换字段。
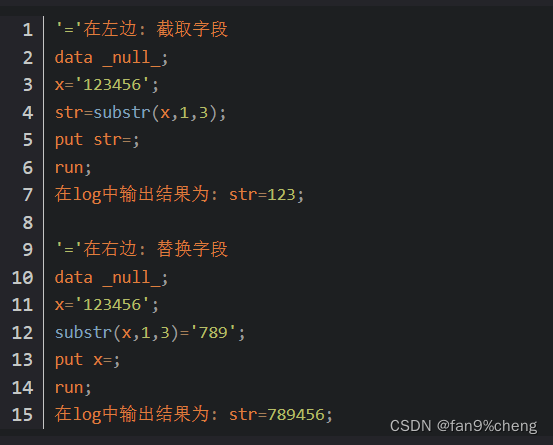
通常情况下,substr往往结合find一起使用。
转载自:https://www.cnblogs.com/huangbiquan/articles/8007613.html

知识点五:find的用法
int ans = s1.find(s2) ; //在S1中查找子串S2;
说明:如果查找成功则输出查找到的第一个位置,否则返回-1;
int ans = s1.find(s2, 2) ; //从S1的第二个字符开始查找子串S2;
查找子串中的某个字符最先出现的位置。
int ans = s1.find_first_of(s2) ; //在S1中查找子串S2;(非全匹配)
其中find_first_of()也可以约定初始查找的位置:s1.find_first_of(s2, 2) ;
3.find_last_of()(非全匹配)
这个函数与find_first_of()功能差不多,只不过find_first_of()是从字符串的前面往后面搜索,而find_last_of()是从字符串的后面往前面搜索。
4.rfind()(全匹配)
反向查找字符串,即找到最后一个与子串匹配的位置
5.find_first_not_of()(非全匹配)
找到第一个不与子串匹配的位置
原文链接:https://blog.csdn.net/laobai1015/article/details/62426137/;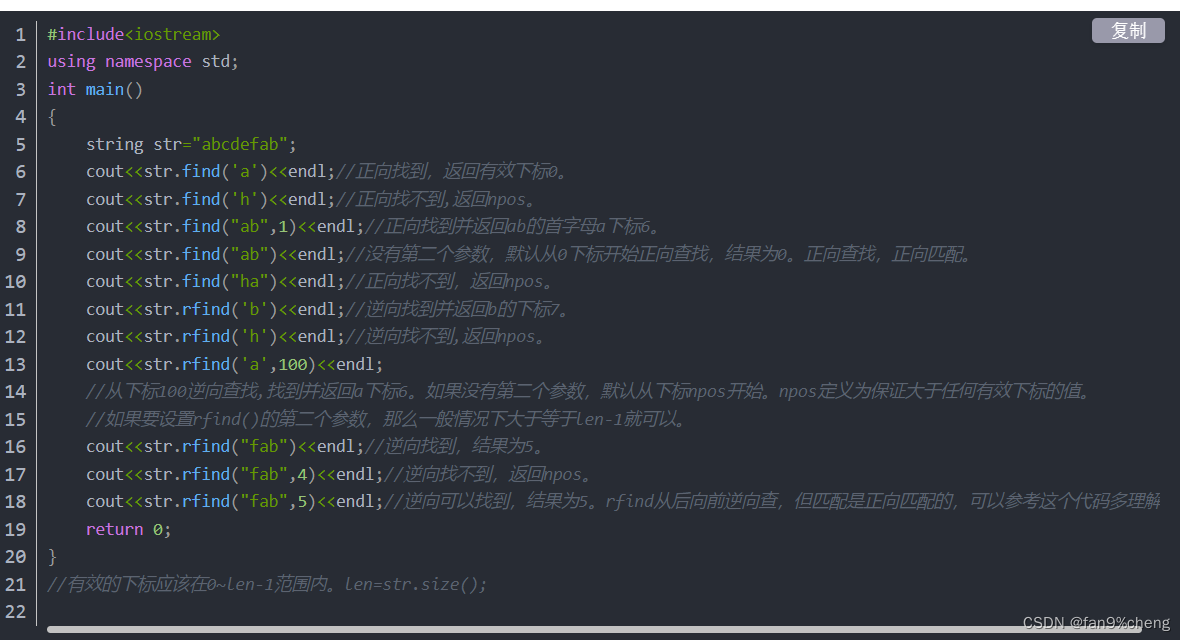
知识点六:sprintf的用法:
sprintf函数打印到字符串中,而printf函数打印输出到屏幕上。
sprintf函数的格式:
int sprintf( char *buffer, const char *format ,[argument, ...])
buffer是字符数组名;format是格式化字符串(像:"%3d%6.2f%#x%o",
char str[20];
double f=14.309948;
sprintf(str,"%6.2f",f);
可以控制精度
5、char str[20];
int a=20984,b=48090;
sprintf(str,"%3d%6d",a,b);//要打双引号。
str[]="2098448090"
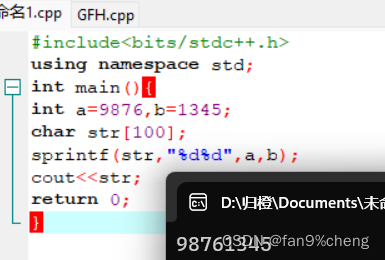
可以将多个数值数据连接起来。
6、char str[20];
char s1[5]={'A','B','C'};
char s2[5]={'T','Y','x'};
sprintf(str,"%.3s%.3s",s1,s2);
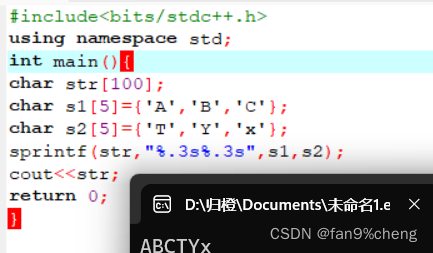
可以将多个字符串连接成字符串
%m.n在字符串的输出中,m表示宽度,字符串共占的列数;n表示实际的字符数。%m.n在浮点数中,m也表示宽度;n表示小数的位数。
7、可以动态指定,需要截取的字符数
char s1={'A','B','C'};
char s2={'T','Y','x'};
sprintf(str,"%.*s%.*s",2,s1,3,s2);
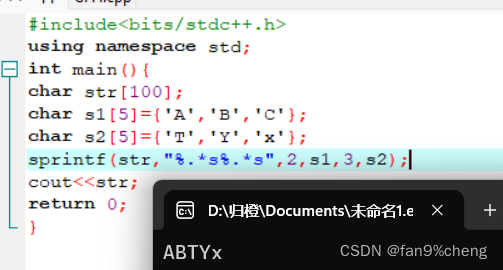
sprintf(s, "%*.*f", 10, 2, 3.1415926);小数点之前的宽度;小数点后几位

8、sprintf(s, "%p", &i);
可以打印出i的地址
上面的语句相当于
sprintf(s, "%0*x", 2 * sizeof(void *), &i);
9、sprintf的返回值是字符数组中字符的个数,即字符串的长度,不用在调用strlen(s)求字符串的长度。
转自:http://nnssll.blog.51cto.com/902724/198237/
知识点七:最长公共子序列(LCS):
不唯一;
详细笔记:
https://www.cnblogs.com/Lee-yl/p/9975827.html
题目:
https://www.luogu.com.cn/problem/P8638?contestId=154515
时间O(n * m),空间O(n * m)
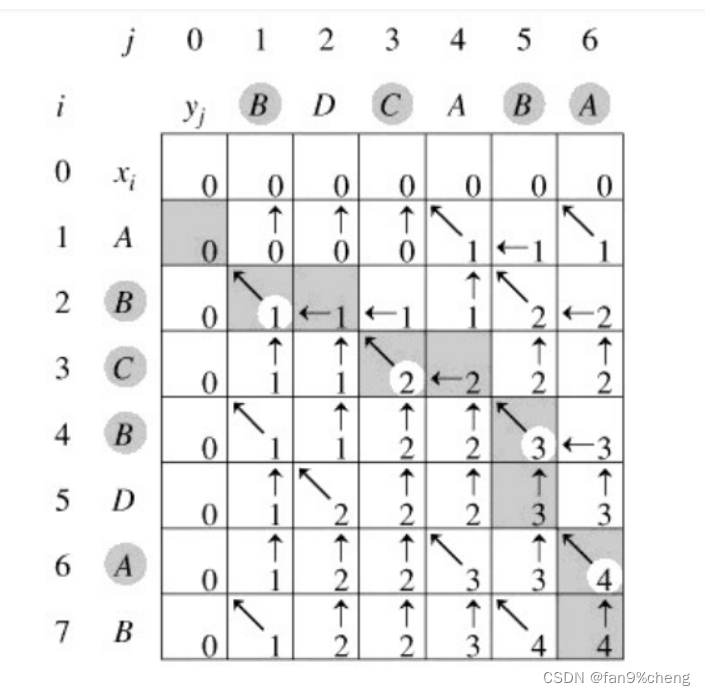
模板:

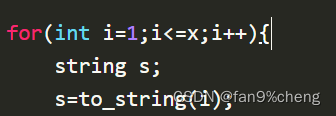
知识点八:to_string();
知识点九: 链式前向星:
图储存的方式:{
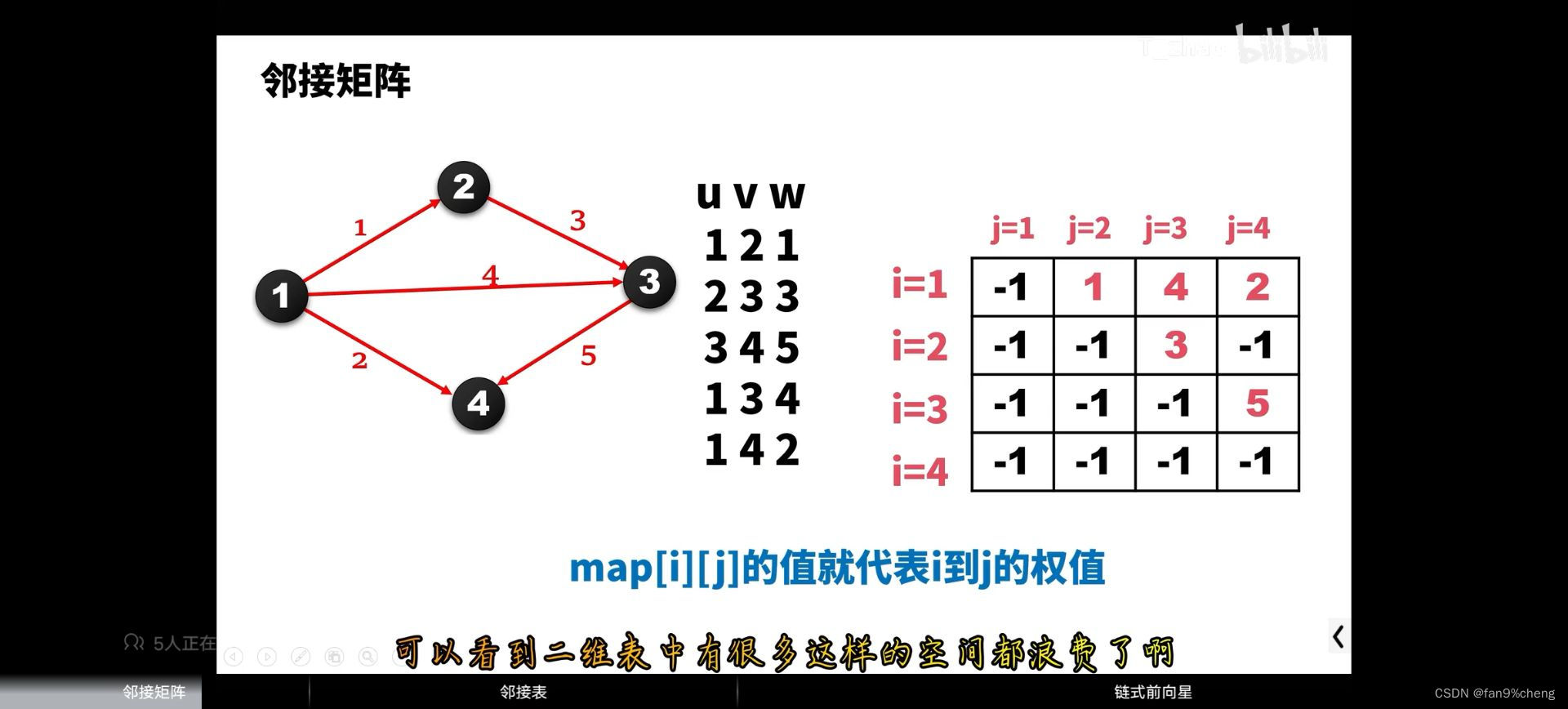
1.邻接矩阵
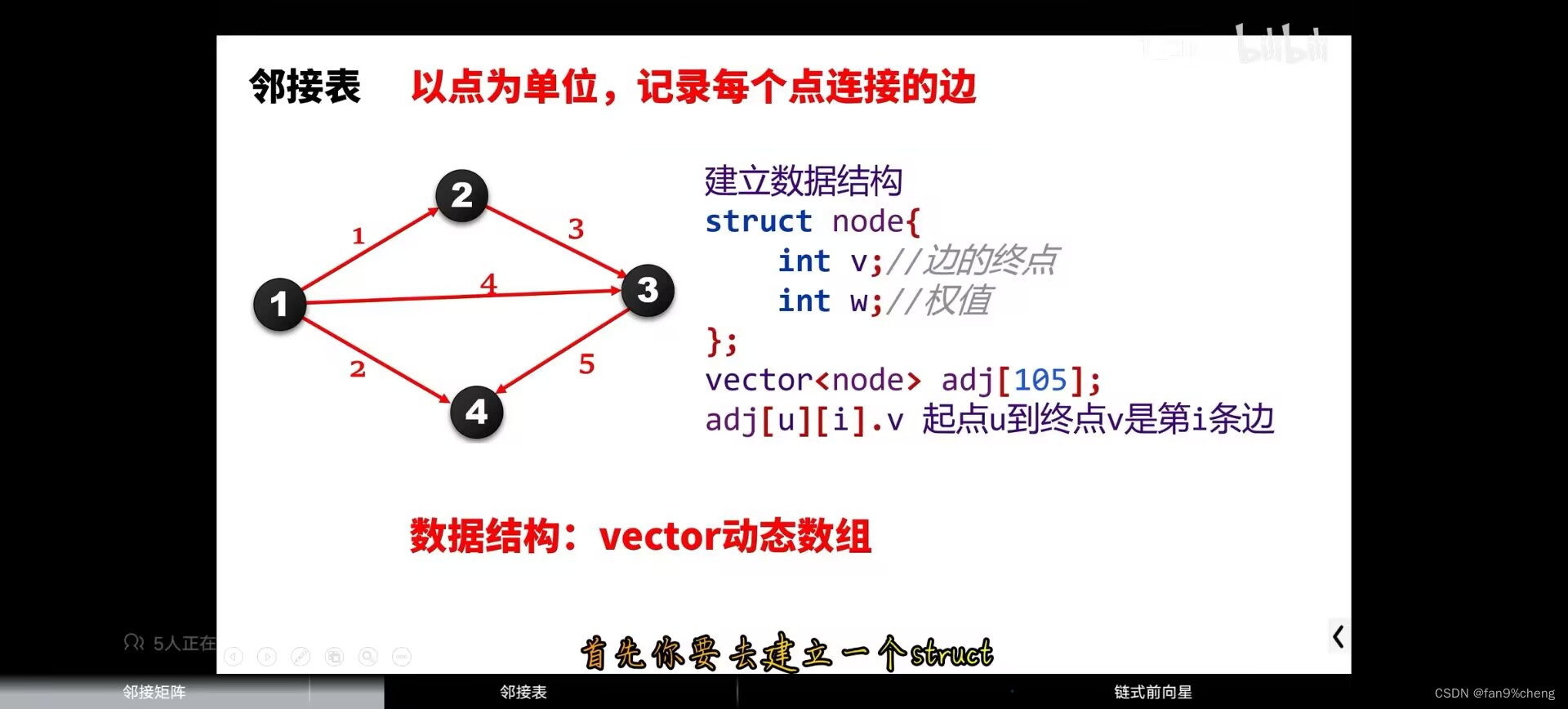
2.邻接表(以点为基本单位)
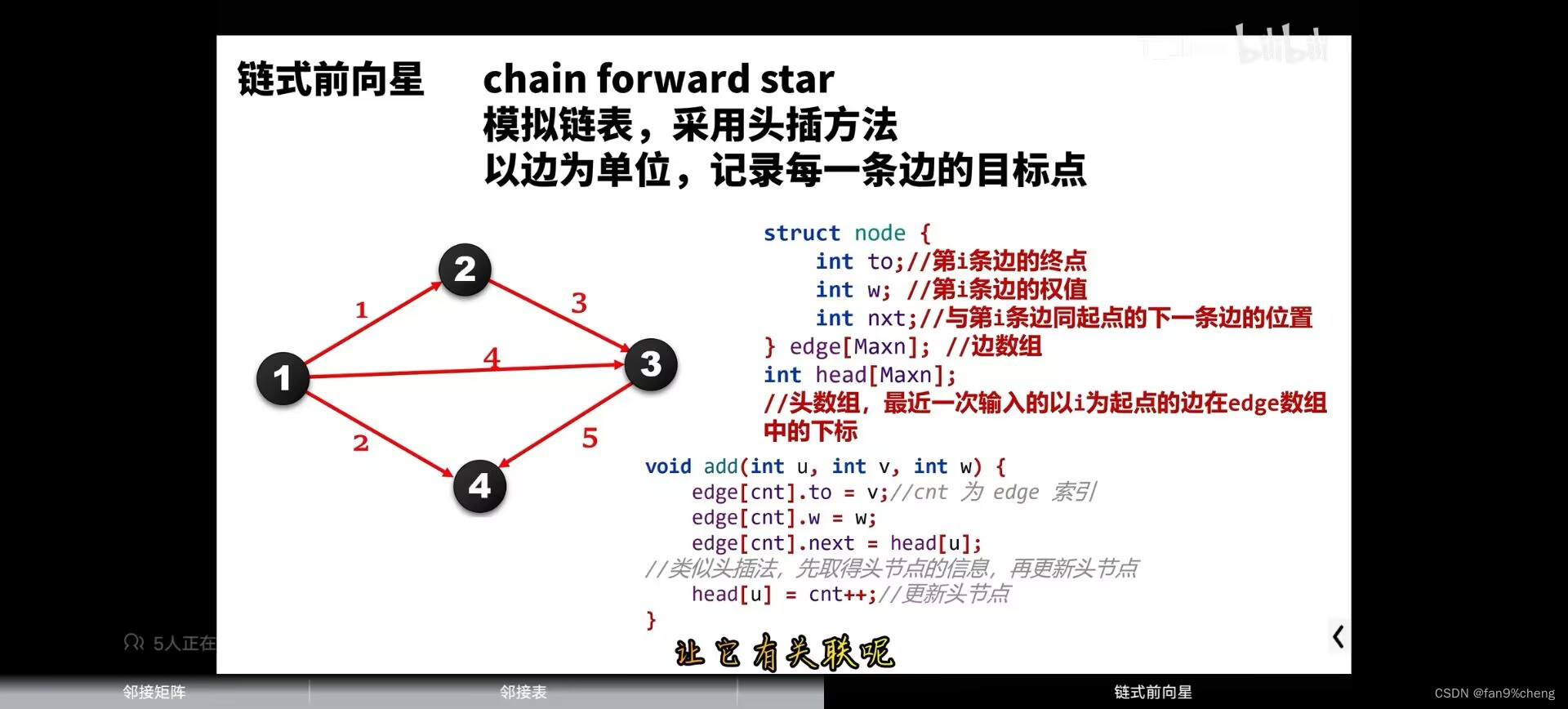
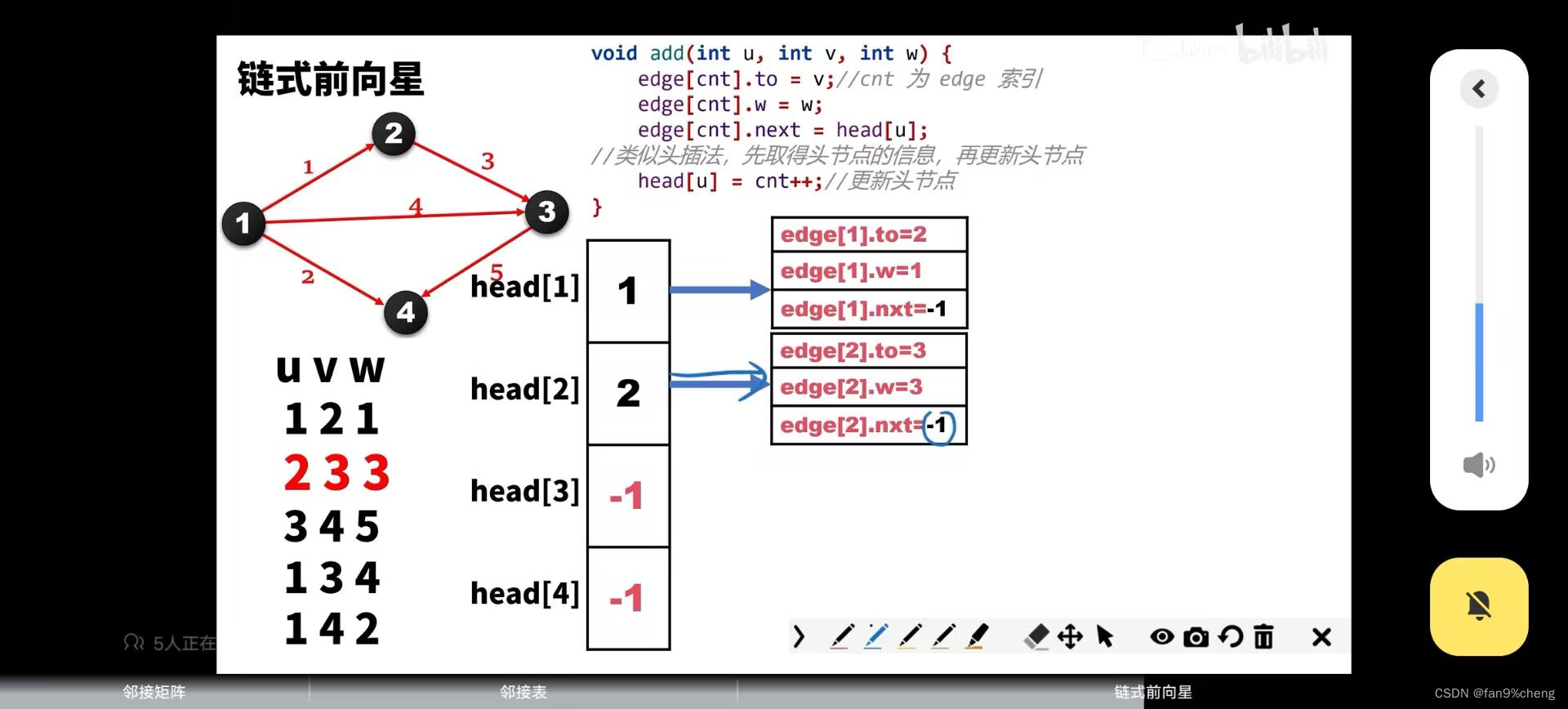
3.链式前向行(以边为基本单位)


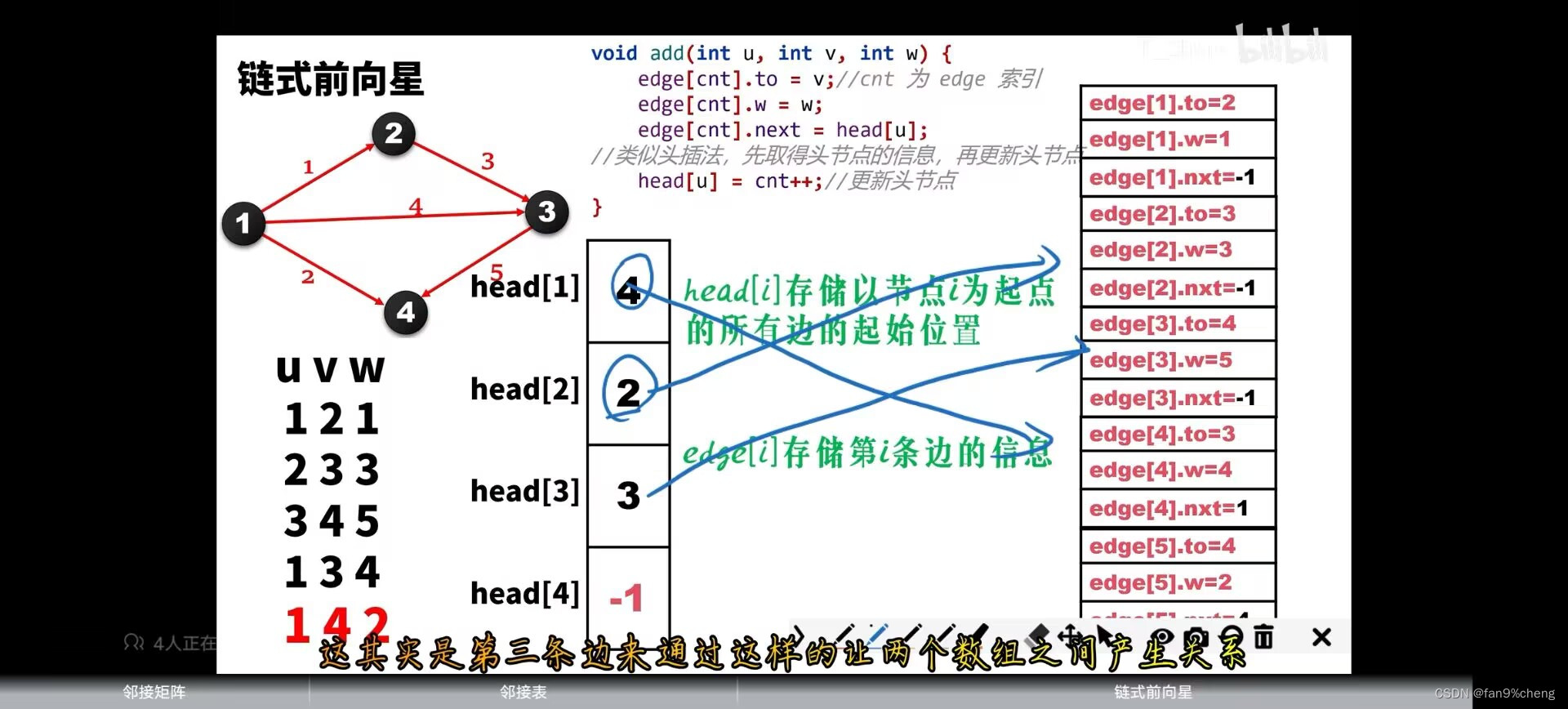

}
题目1:
P8808 [蓝桥杯 2022 国 C] 斐波那契数组 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
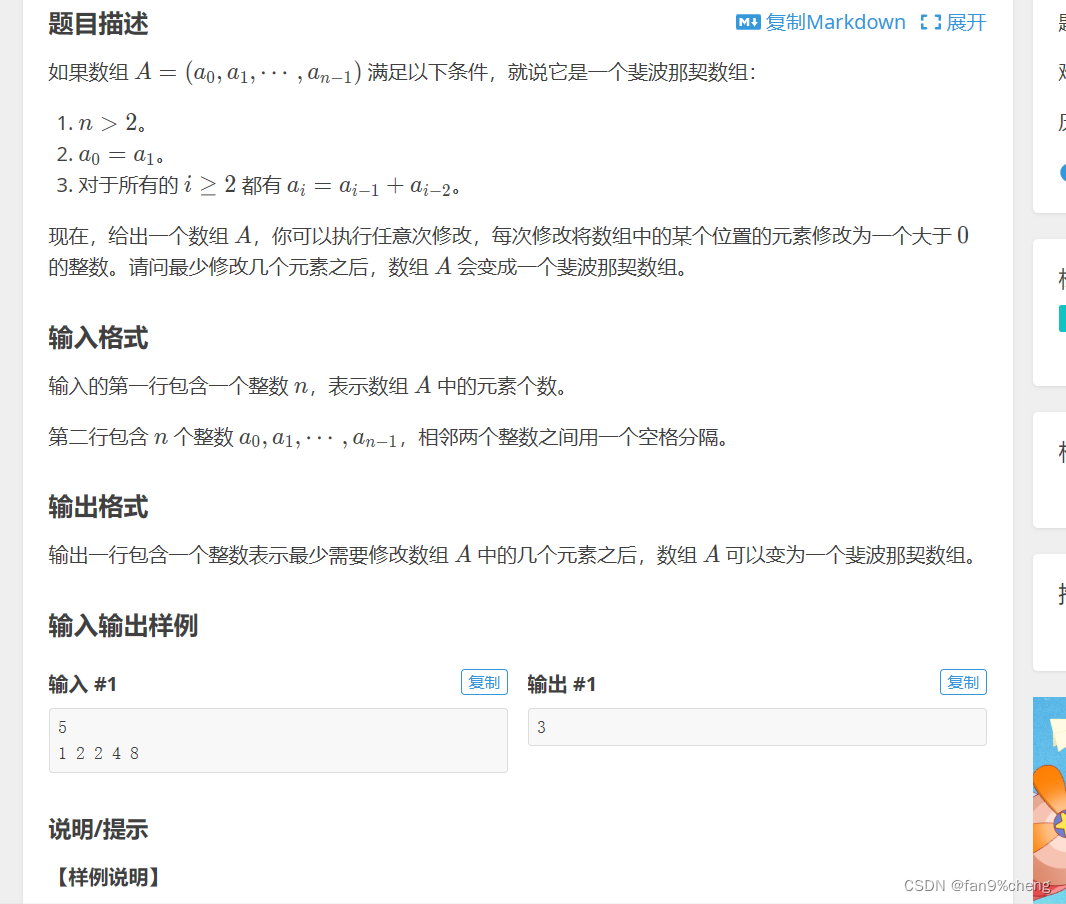
题目的斐波那契数组中的a0,a1,不一定是1,且不同的首项,数组不一样,对应修改的元素个数也有偏差。要求求修改的个数最少。
首先我们来证明一个东西:
如果 a是一个斐波那契数组,那么满足以下关系式:
首先我们来证明一个东西:
ai=fi*a1(i>=3)
其中,f表示原始的斐波那契数列;
证明如下:a1=a2=x
a3=2*x
a4=(1+2)*x=3x,
a5=(2+3)x=5x;

#include<bits/stdc++.h>
using namespace std;
int n,a[100010],s=0,t[1000010],maxx=-1,f[100010]={0,1,1},l=2,maxxx=10000000;
int main()
{
scanf("%d",&n);
for( int i=1;i<=n;i++) scanf("%d",&a[i]),maxx=max(maxx,a[i]);
while(1)
{
if(f[l-1]+f[l]>maxxx) break;
l++;//顺便记录数组可改范围
f[l]=f[l-2]+f[l-1];//记忆化搜索斐波那契数列;
}
for( int i=1;i<=l;i++) if(a[i]%f[i]==0) t[a[i]/f[i]]++;
for( int i=1;i<=maxx;i++) s=max(s,t[i]);
printf("%d",n-s);
return 0;
}














 2798
2798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









