







百度翻译先选择返回旧版本上面
然后我发现百度翻译有2个翻译的api接口
一个api接口是这个 https://fanyi.baidu.com/transapi 这个是全明文的,没有加密的.但是这个需要多搜几次才能找到这个接口,然后就可以在Python中调用这个接口进行翻译了

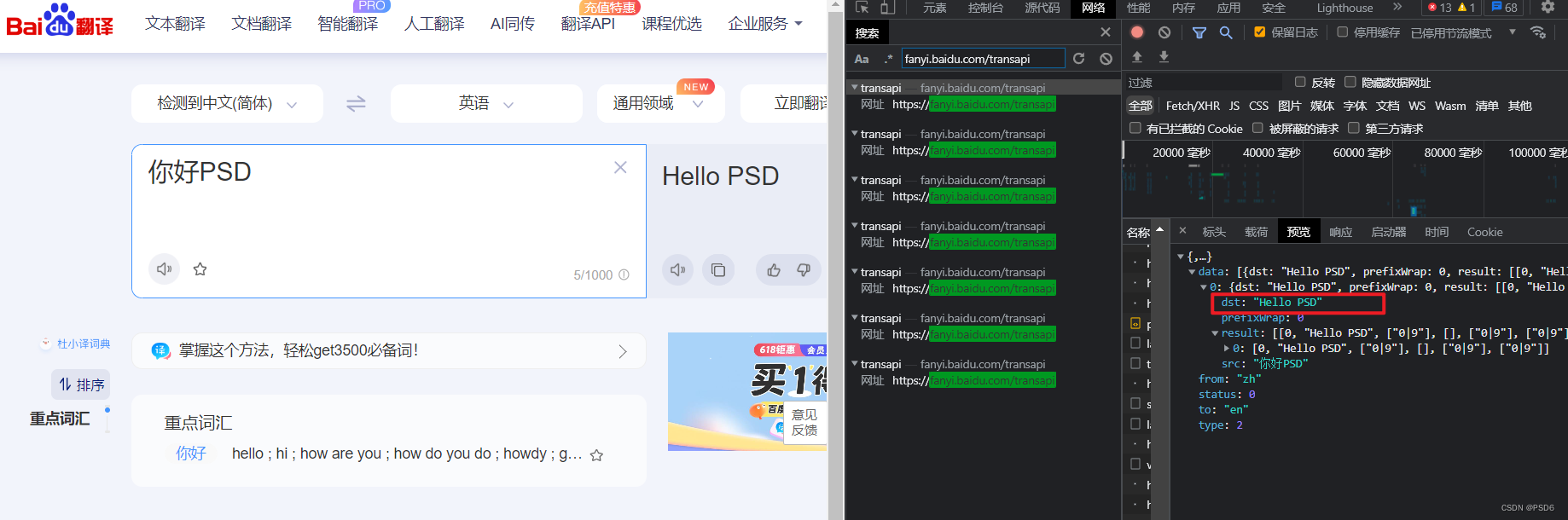

代码详情:
import requests
url = 'https://fanyi.baidu.com/transapi'
headers = {
"Origin": "https://fanyi.baidu.com",
"Referer": "https://fanyi.baidu.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
}
data = {
"from": "zh",
"to": "en",
"query": "你好PSD",
"source": "txt"
}
response = requests.post(url, headers=headers, data=data).json()
print(response['data'][0]['dst'])第二个api接口就是正常情况下搜到的 https://fanyi.baidu.com/v2transapi?from=zh&to=en
应该是应该是第一个为1代翻译接口,第二个是2代翻译的接口

可以通过翻译的 你好PSD 和 你好PSD,66666 看出来实际需要逆向的参数只有sign这个值,token是一个定值,可以直接写死
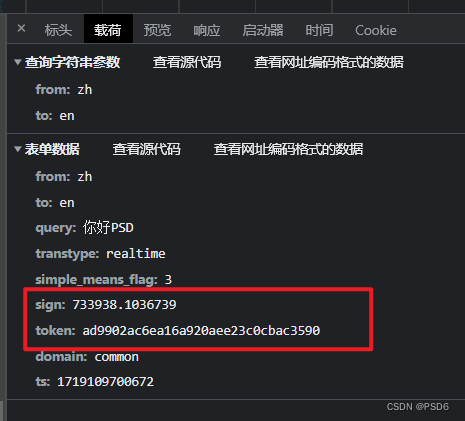

然后我搜索一下sign大概看一下会在哪里出现,当我在第二个搜索是返现第九个出现的位置很有可能就是sign被赋值的位置了,然后下一个断点看看

然后我重新发了一个包发现并没有断住,然后说明这个位置不是,并没有运行到这里,这个是一个僵尸代码,然后我再往下面找,在第25个那里又找到了一个,再进行断点发包一下看看
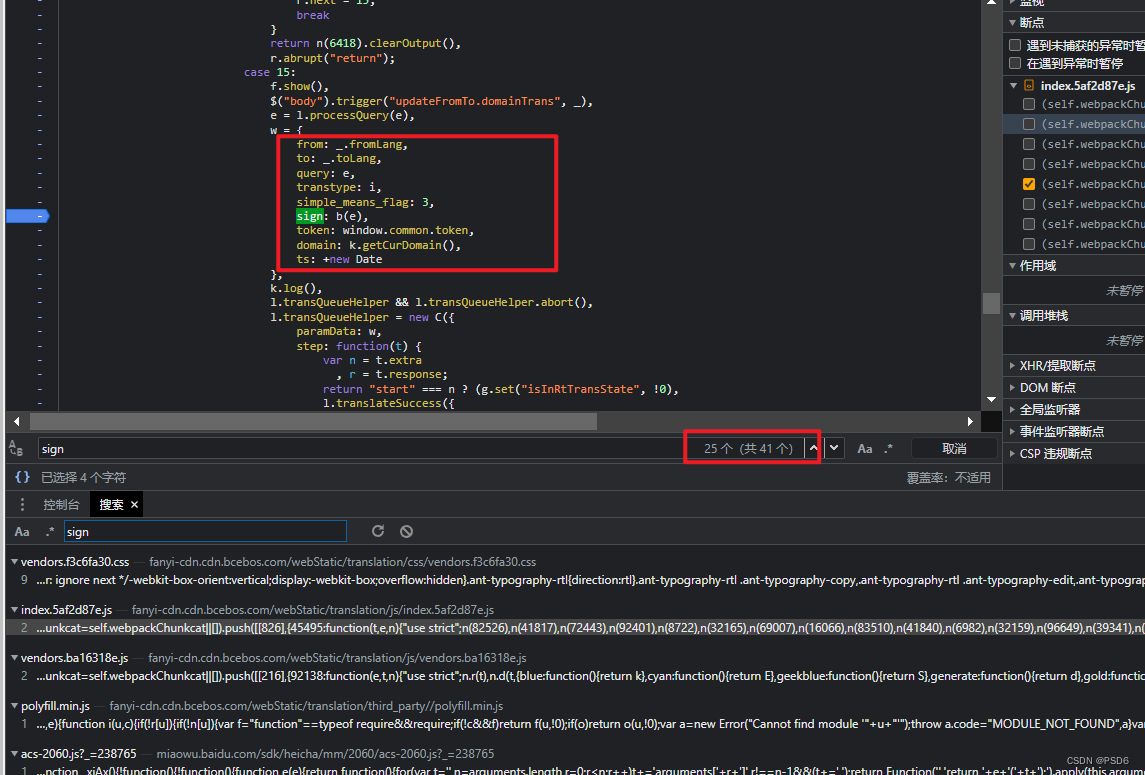
然后被断住了,说明就是这里了 b(e) 就是那个sign值

e 则是我们发包需要翻译的中文,然后我们就只需要把b这个方法扣出来就行了
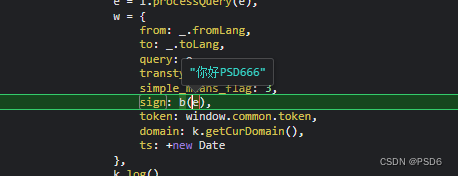
进入b中我们只需要把这个函数给扣出来
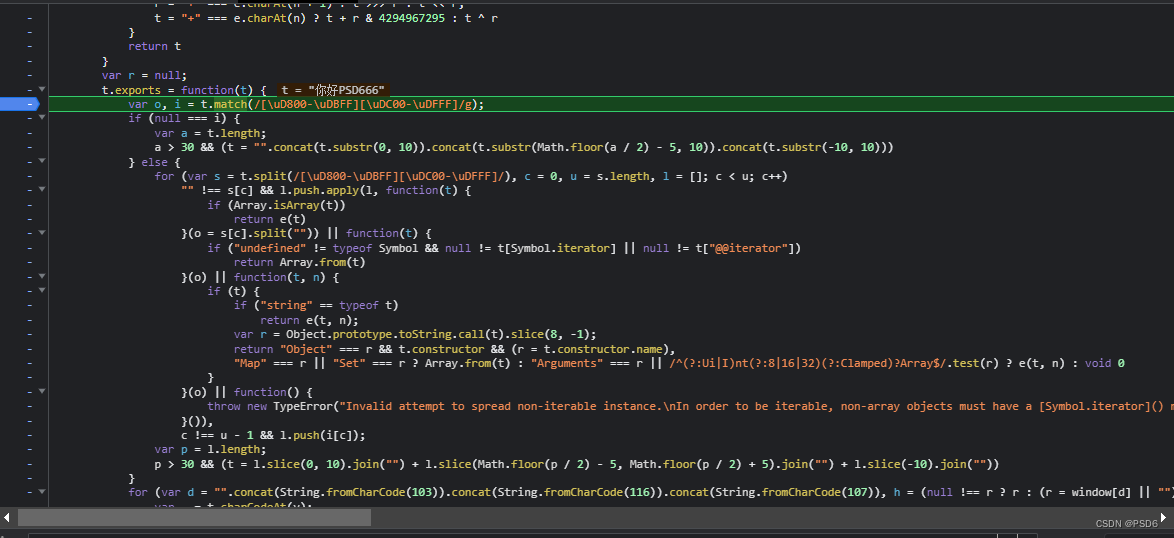
扣函数的方法我最开始用的是这种就是鼠标点击到函数开始的那个位置 { ,然后他下面会有一个下划线,然后与它对应的另一个 } 也有一个下滑线,这个的话就需要找了,有点费眼睛,而且代码很长的时候还非常的难找
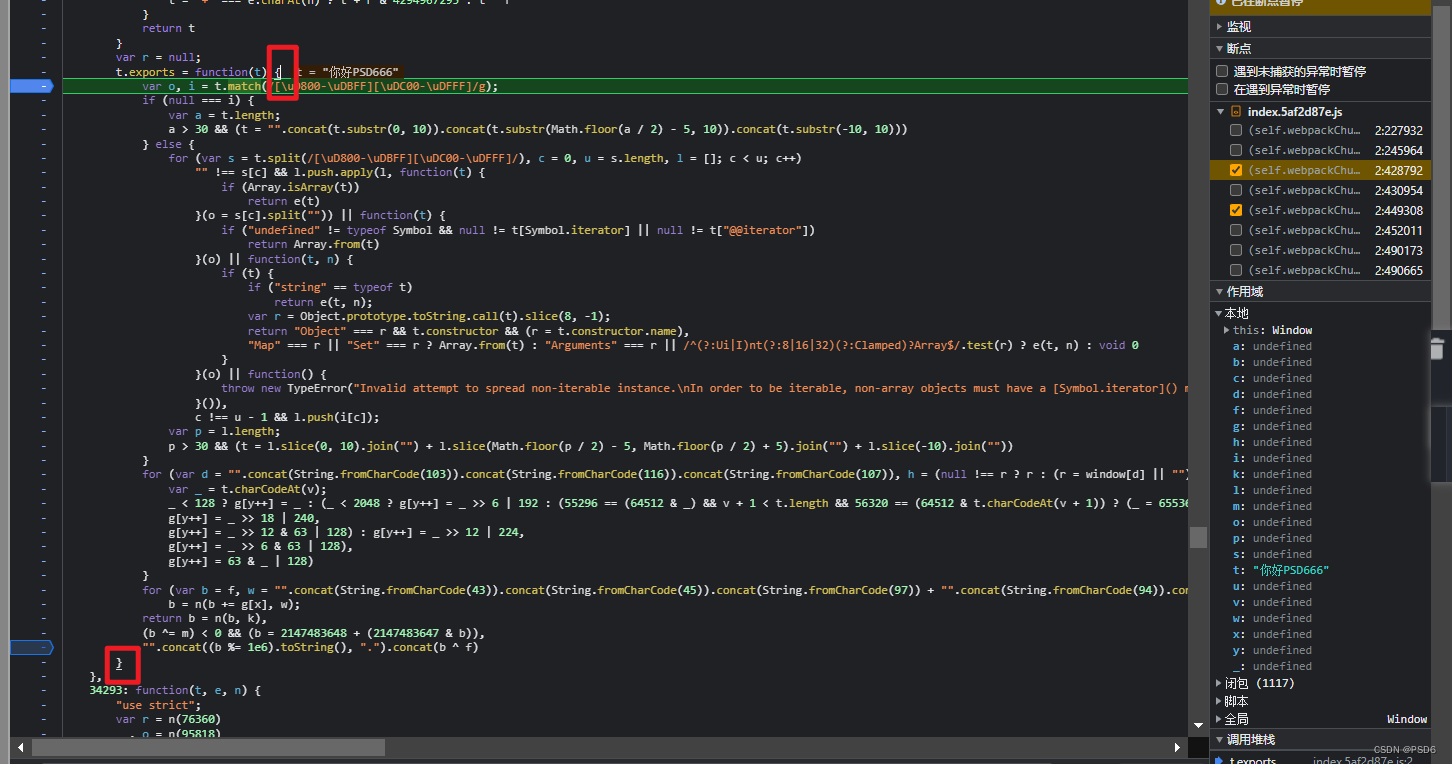
第二种方法就是点击左边那里可以把代码给折叠起来,然后他就可以把这个函数都给折叠起来了

如果有的人不能进行折叠的话就需要在右上角设置那里把这个代码折叠给勾选上,然后就可以了
代码折叠后就直接复制者折叠的全部就行了
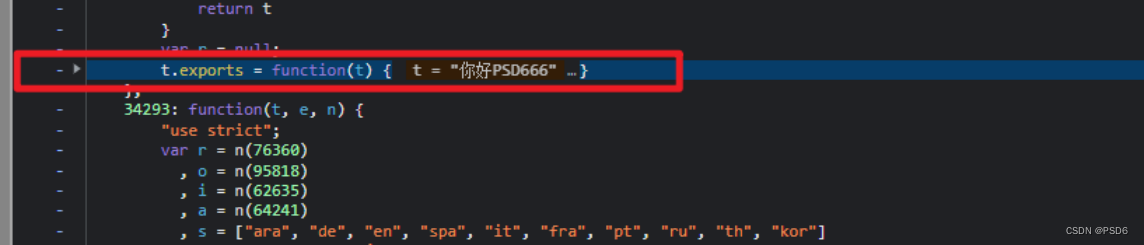
扣下来后我们把它放到 js 代码中,并把前面直接方法给改为b 吧,然后复制后按按 Ctrl+Alt+L 格式化一下代码,看起来好看舒服一些

然后我们再测试一下传入参数 你好PSD 看看能不能直接翻译出来,结果报错了说没有r

然后我们去浏览器中找一下 r 的值是什么,然后就知道了它的值,再在第一行声明一下r 值
var r = '320305.131321201'

然后n又没有,再找一下方法 n 为什么

然后找到 n 后,直接点进去扣它的方法

然后我把他折叠了再把它这个方法直接复制到 js 代码中去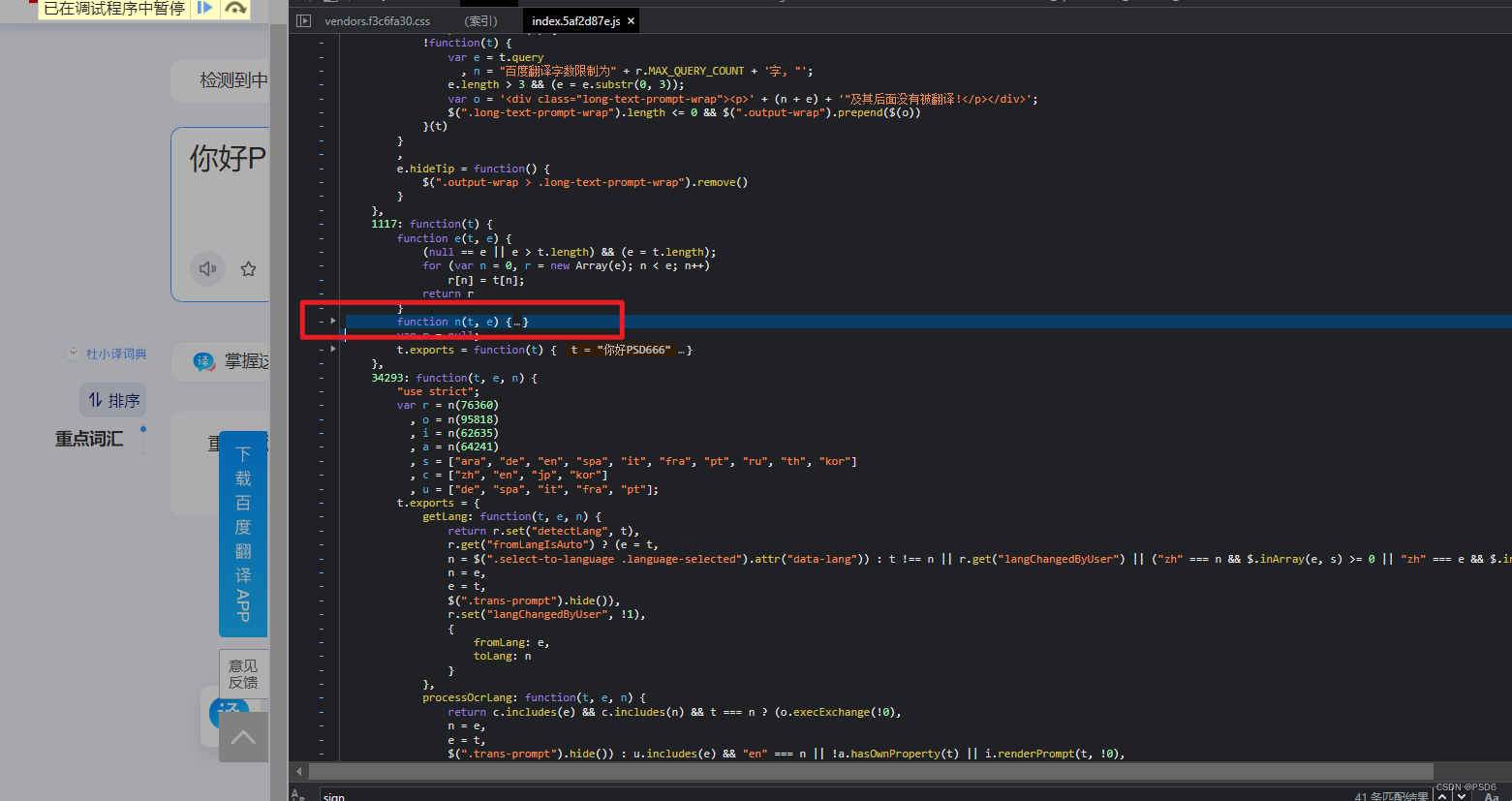
直接粘贴到第二行那里
然后再一运行发现没报错了运行出来了,翻译 你好PSD 的sign为 733938.1036739
然后发现这个值和我们前面翻译这个出来的sign值一模一样,那就说明没问题了,到此js就扣完了
js详细代码:
var r = '320305.131321201'
function n(t, e) {
for (var n = 0; n < e.length - 2; n += 3) {
var r = e.charAt(n + 2);
r = "a" <= r ? r.charCodeAt(0) - 87 : Number(r),
r = "+" === e.charAt(n + 1) ? t >>> r : t << r,
t = "+" === e.charAt(n) ? t + r & 4294967295 : t ^ r
}
return t
}
b = function (t) {
var o, i = t.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === i) {
var a = t.length;
a > 30 && (t = "".concat(t.substr(0, 10)).concat(t.substr(Math.floor(a / 2) - 5, 10)).concat(t.substr(-10, 10)))
} else {
for (var s = t.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), c = 0, u = s.length, l = []; c < u; c++)
"" !== s[c] && l.push.apply(l, function (t) {
if (Array.isArray(t))
return e(t)
}(o = s[c].split("")) || function (t) {
if ("undefined" != typeof Symbol && null != t[Symbol.iterator] || null != t["@@iterator"])
return Array.from(t)
}(o) || function (t, n) {
if (t) {
if ("string" == typeof t)
return e(t, n);
var r = Object.prototype.toString.call(t).slice(8, -1);
return "Object" === r && t.constructor && (r = t.constructor.name),
"Map" === r || "Set" === r ? Array.from(t) : "Arguments" === r || /^(?:Ui|I)nt(?:8|16|32)(?:Clamped)?Array$/.test(r) ? e(t, n) : void 0
}
}(o) || function () {
throw new TypeError("Invalid attempt to spread non-iterable instance.\nIn order to be iterable, non-array objects must have a [Symbol.iterator]() method.")
}()),
c !== u - 1 && l.push(i[c]);
var p = l.length;
p > 30 && (t = l.slice(0, 10).join("") + l.slice(Math.floor(p / 2) - 5, Math.floor(p / 2) + 5).join("") + l.slice(-10).join(""))
}
for (var d = "".concat(String.fromCharCode(103)).concat(String.fromCharCode(116)).concat(String.fromCharCode(107)), h = (null !== r ? r : (r = window[d] || "") || "").split("."), f = Number(h[0]) || 0, m = Number(h[1]) || 0, g = [], y = 0, v = 0; v < t.length; v++) {
var _ = t.charCodeAt(v);
_ < 128 ? g[y++] = _ : (_ < 2048 ? g[y++] = _ >> 6 | 192 : (55296 == (64512 & _) && v + 1 < t.length && 56320 == (64512 & t.charCodeAt(v + 1)) ? (_ = 65536 + ((1023 & _) << 10) + (1023 & t.charCodeAt(++v)),
g[y++] = _ >> 18 | 240,
g[y++] = _ >> 12 & 63 | 128) : g[y++] = _ >> 12 | 224,
g[y++] = _ >> 6 & 63 | 128),
g[y++] = 63 & _ | 128)
}
for (var b = f, w = "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(97)) + "".concat(String.fromCharCode(94)).concat(String.fromCharCode(43)).concat(String.fromCharCode(54)), k = "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(51)) + "".concat(String.fromCharCode(94)).concat(String.fromCharCode(43)).concat(String.fromCharCode(98)) + "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(102)), x = 0; x < g.length; x++)
b = n(b += g[x], w);
return b = n(b, k),
(b ^= m) < 0 && (b = 2147483648 + (2147483647 & b)),
"".concat((b %= 1e6).toString(), ".").concat(b ^ f)
}
console.log(b('你好PSD'));
运行js代码的话需要调用 execjs 这个包,需要如没有需要下载 PyExecJS2
pip install PyExecJS2下载的 PyExecJS 可能会出现编码问题,下载PyExecJS2 可以避免这个问题
然后编写响应的Python代码就行了
import time
import requests
import execjs
# 读取 JavaScript 代码
with open('百度翻译v2.js', encoding='utf-8') as f1:
js_ = js_code = execjs.compile(f1.read())
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.6367.118 Safari/537.36",
'Cookie':'xxxxxxxxx根据自己的填写xxxxxxxxx'
}
url = "https://fanyi.baidu.com/v2transapi?from=zh&to=en"
words = '你好PSD'
sign = js_.call('b',words)
ts = str(int(time.time()*1000))
data = {
"from": "zh",
"to": "en",
"query": words,
"transtype": "realtime",
"simple_means_flag": "3",
"sign": sign,
"token": "ad9902ac6ea16a920aee23c0cbac3590",
"domain": "common",
"ts": ts
}
response = requests.post(url, headers=headers, data=data).json()
res = response['trans_result']['data'][0]['dst']
print(res)然后就翻译出来 
感兴趣的朋友可以关注一下,点个赞,后面还会发布一些其他的网站爬取和逆向分析,还有一些网络安全的学习资料和实践分享
👈(゚ヮ゚👈) (👉゚ヮ゚)👉















 4463
4463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









