






一.Hadoop生态圈

1.Hadoop Common是Hadoop体系最底层的一个模块,为Hadoop各个子模块提供各种工具
2.HDFS是Hadoop分布式文件系统缩写,它是Hadoop的基石。HDFS是一个具备高度容错性的文件系统,适合部署在廉价的机器上,它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
3.YARN是统一资源管理和调度平台。
4.MapReduce是一种编程模型,利用函数式编程思想,将对数据集的过程分为Map和Reduce两个阶段。
5.Spark是加州伯克利大学AMP实验室开发的新一代计算框架,对迭代计算有很大优势,与MapReduce相比性能提升明显,并且可以和Yarn集成,并且还提供了SparkSQL组件。
6.HBase是一个分布式的,面向列族的开源数据库。HBase擅长大规模数据的随机、实时读写访问。
7.Zookeeper作为一个分布式服务框架,是基于Fast Paxos算法实现,解决分布式系统中一致性的问题。提供了配置维护,名字服务,分布式同步,组服务等。
8.Hive,是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,提供简单的SQL查询功能。
9.Pig是对大数据集进行分析和评估的工具,面向领域的抽象语言Pig Latin.同样Pig也可以将Pig Latin转化为MapReduce作业。相比与SQL,Pig Latin更加灵活,但学习成本更高。
10.Impala,可以对存储HDFS、HBase的海量数据提供交互查询的SQL接口。提供了一个熟悉的面向批量或者实时查询的统一平台。
11.Mahout是一个机器学习和数据挖掘库
12.Flume是Cloudera提供的一个高可用,高可靠,分布式的海量日志采集、聚合和传输系统
13.Sqoop是SQL to Hadoop的缩写,主要作用在于结构化的数据存储与Hadoop之间进行数据双向交换
14.Kafka是一种高吞吐量的分布式发布订阅消息系统。具有分布式、高可用的特性
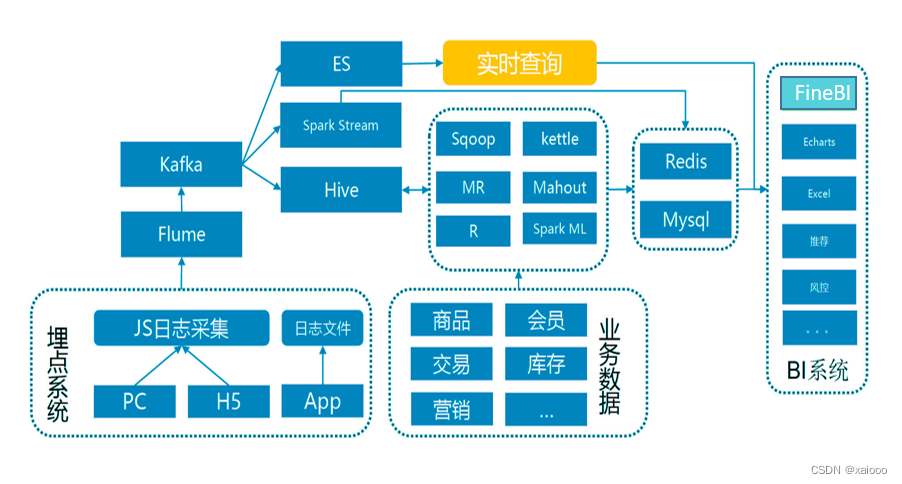
二.Spark概述:
Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台的系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件。

Spark生态圈

特点
1.速度。执行速度快,开发速度提高了很多。
2.易用。支持多种语言,如Python,Java,Scala等
3.通用性,解决多个框架学习成本和运维成本
4. 运行在很多地方
三.mapreduce的运行框架

MapReduce是一种计算模型,其工作流程体现了MapReduce的“分而治之”思想,通过将大数据集分割成小块,并在多个节点上并行处理,提高了处理大规模数据的效率。
MapReduce这个术语来自两个基本的数据转换操作:map过程和reduce过程。
MapReduce的工作流程可以分为以下几个阶段:
1.分片和格式化数据源:在Map阶段,源文件被划分为大小相等的小数据块(Hadoop 2.x中默认128M),这些块被称为分片(split)。每个分片被格式化为键值对(key-value)形式,其中key代表偏移量,value代表每行的内容。
2.执行MapTask:每个MapTask负责处理一个分片,并生成中间结果。MapTask有一个内存缓冲区,用于存储处理后的数据。当缓冲区中的数据量达到一定阈值时,数据会被溢写到磁盘中,并进行排序。如果数据量较大,可能会产生多个溢写文件,最终这些文件会被合并为一个大的文件。
3.Shuffle阶段:Shuffle阶段是MapReduce中的关键阶段,负责将Map阶段处理过的数据传递(数据按照key进行分区和排序,以确保相同key的数据被发送到同一个ReduceTask)给Reduce阶段。
4.执行ReduceTask:ReduceTask从各个MapTask上远程拷贝数据,并可能将数据写入内存或磁盘。
Spark与Hadoop MapReduce的运行速度差异较大的原因:
Spark的中间数据存放于内存中,有更高的迭代运算效率
MapReduce基于硬盘的迭代
四.Linux常用命令的使用:
1.:pwd:显示当前所在目录(即工作目录)。

2.ls 命令 显示指定目录中的文件或子目录信息。
当不指定文件或目录时,显示 当前工作目录中的文件或子目录信息。
-a :全部的档案,连同隐藏档( 开头为 . 的档案) 一起列出来。
-l :长格式显示,包含文件和目录的详细信息。
-R :连同子目录内容一起列出来。

3.cd :用于切换当前用户所在的工作目录,其中路径可以是绝对路径也可以 是相对路径。

4.mkdir :用于创建目录。创建目录前需保证当前用户对当前路径有修改的权 限。
-p 用于创建多级文件夹。



5.rm :用于删除文件或目录
常用选项-r -f,-r 表示删除目录,也可以用于 删除文件,-f 表示强制删除,不需要确认。删除文件前需保证当前用户对当 前路径有修改的权限。

6.cp :复制文件或目录

7.mv:移动文件或对其改名。
-i 表示若存在同名文件,则向用户 询问是否覆盖;
-f 直接覆盖已有文件,不进行任何提示;
-b 当文件存在时,覆盖 前为其创建一个备份。

8.cat :查看文件内容。
-n 显示行号(空行也编号)。

9.tar:为文件和目录创建档案。
利用 tar 命令,可以把一大堆的文件和目录 全部打包成一个文件,这对于备份文件或将几个文件组合成为一个文件以便 于网络传输是非常有用的。该命令还可以反过来,将档案文件中的文件和目 录释放出来。
-c 建立新的备份文件。
-C 切换工作目录,先进入指定目录再执行压缩/解压缩操作,可用于 仅压缩特定目录里的内容或解压缩到特定目录。
-x 从归档文件中提取文件。
-z 通过 gzip 指令压缩/解压缩文件,文件名为*.tar.gz。
-f 指定备份文件。
-v 显示命令执行过程。
![]()
10.clear :清除屏幕。
实质上只是让终端显示页向后翻了一页,如果向上滚动屏 幕还可以看到之前的操作信息。
11.source:用于重新执行刚修改的初始化文件,使之立即生效,而不必注销用 户,重新登录。

五.结构化数据和非结构化数据
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。
六.冷备,热备和温备
热备(在线备份):在数据库运行时直接备份,对数据库操作没有任何影响。
冷备(离线备份):在数据库停止时进行备份。
温备:在数据库运行时加全局读锁备份,保证了备份数据的一致性,但对性能有影响。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









