







目录
课程地址:2024最新SpringCloud微服务开发与实战,java黑马商城项目微服务实战开发(涵盖MybatisPlus、Docker、MQ、ES、Redis高级等)_哔哩哔哩_bilibili
课程名称:2024最新SpringCloud微服务开发与实战,java黑马商城项目微服务实战开发(涵盖MybatisPlus、Docker、MQ、ES、Redis高级等)
一、MybatisPlus
官网:简介 | MyBatis-Plus (baomidou.com)
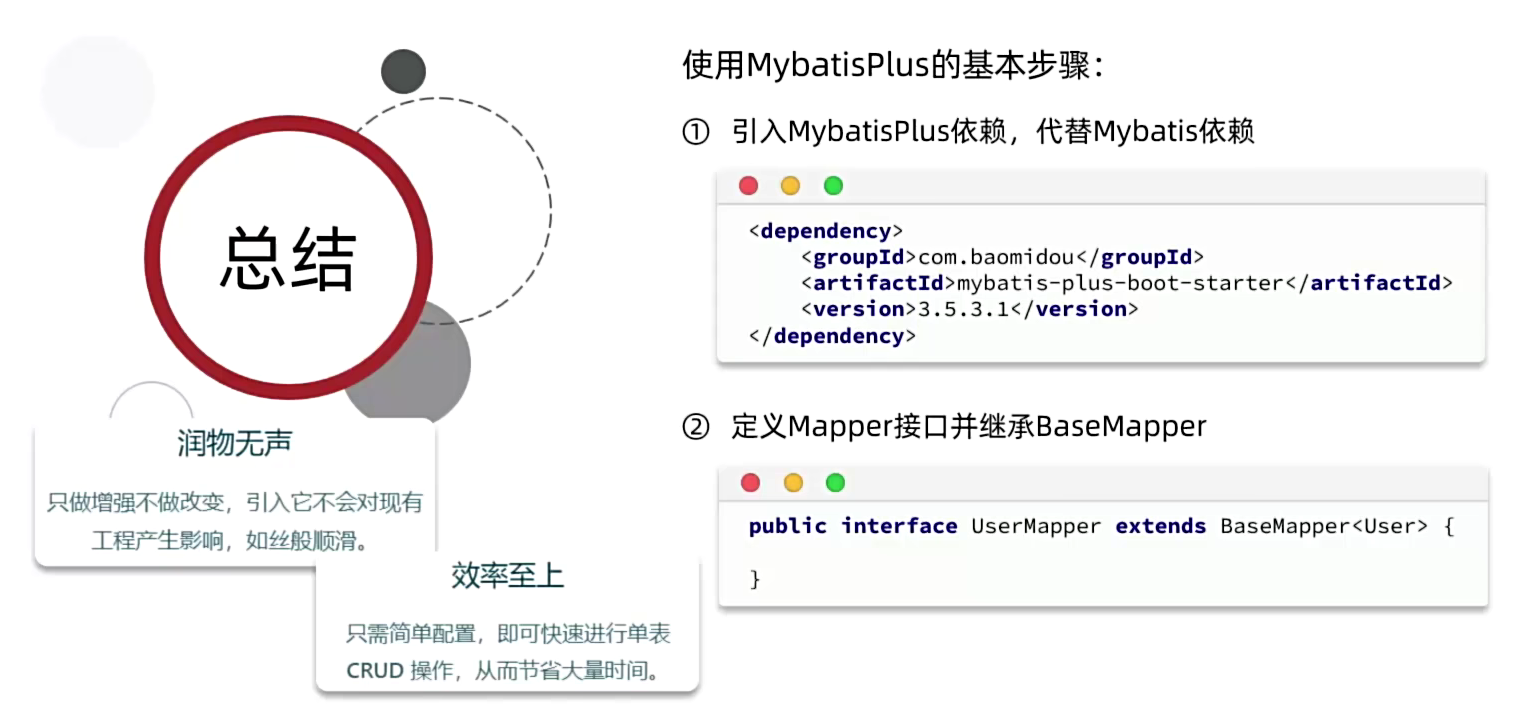
1. 使用步骤
2. 常用注解
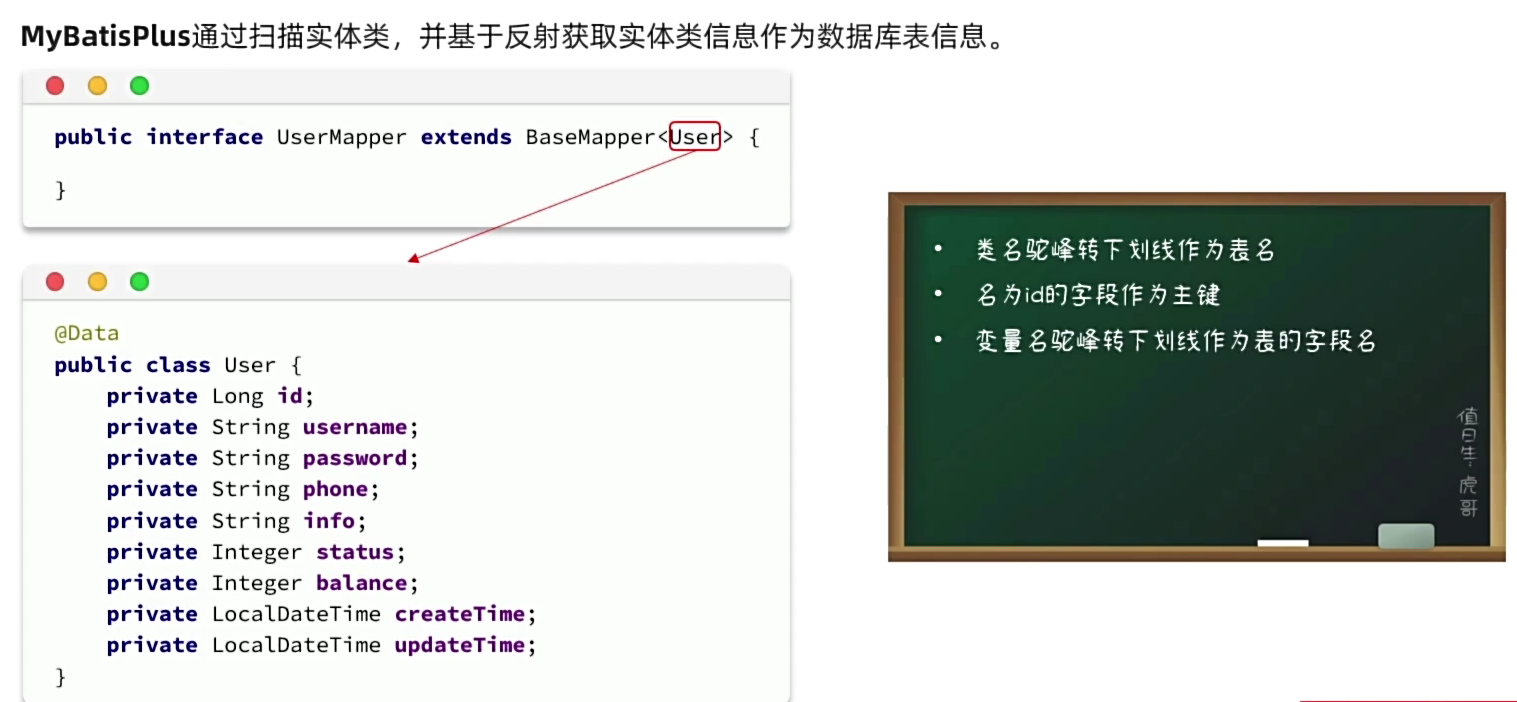
一旦与上述规则不一致时,需要使用注解:

更多注解参考官网(一般不用):注解 | MyBatis-Plus (baomidou.com)
ID生成策略默认是雪花算法。

3. 常用配置
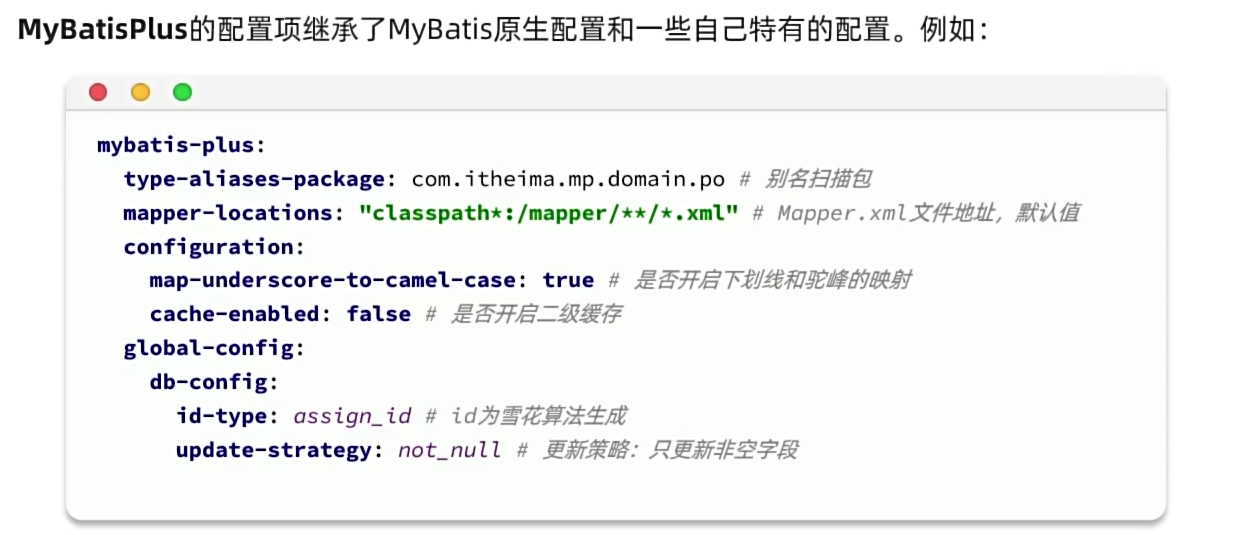
更多配置可以查看官网,或者IDEA自动提示。
MybatisPlus使用的完整流程:

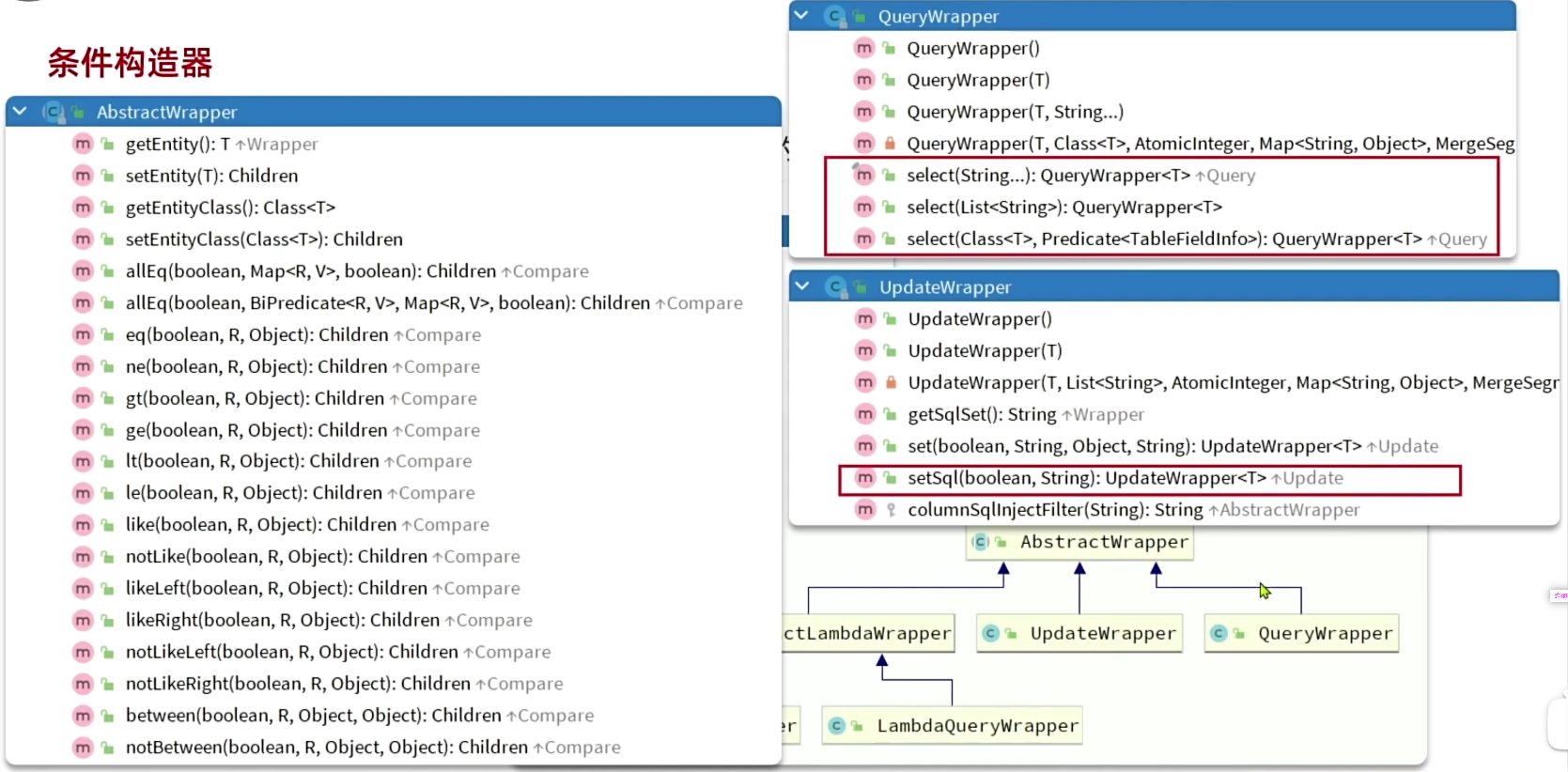
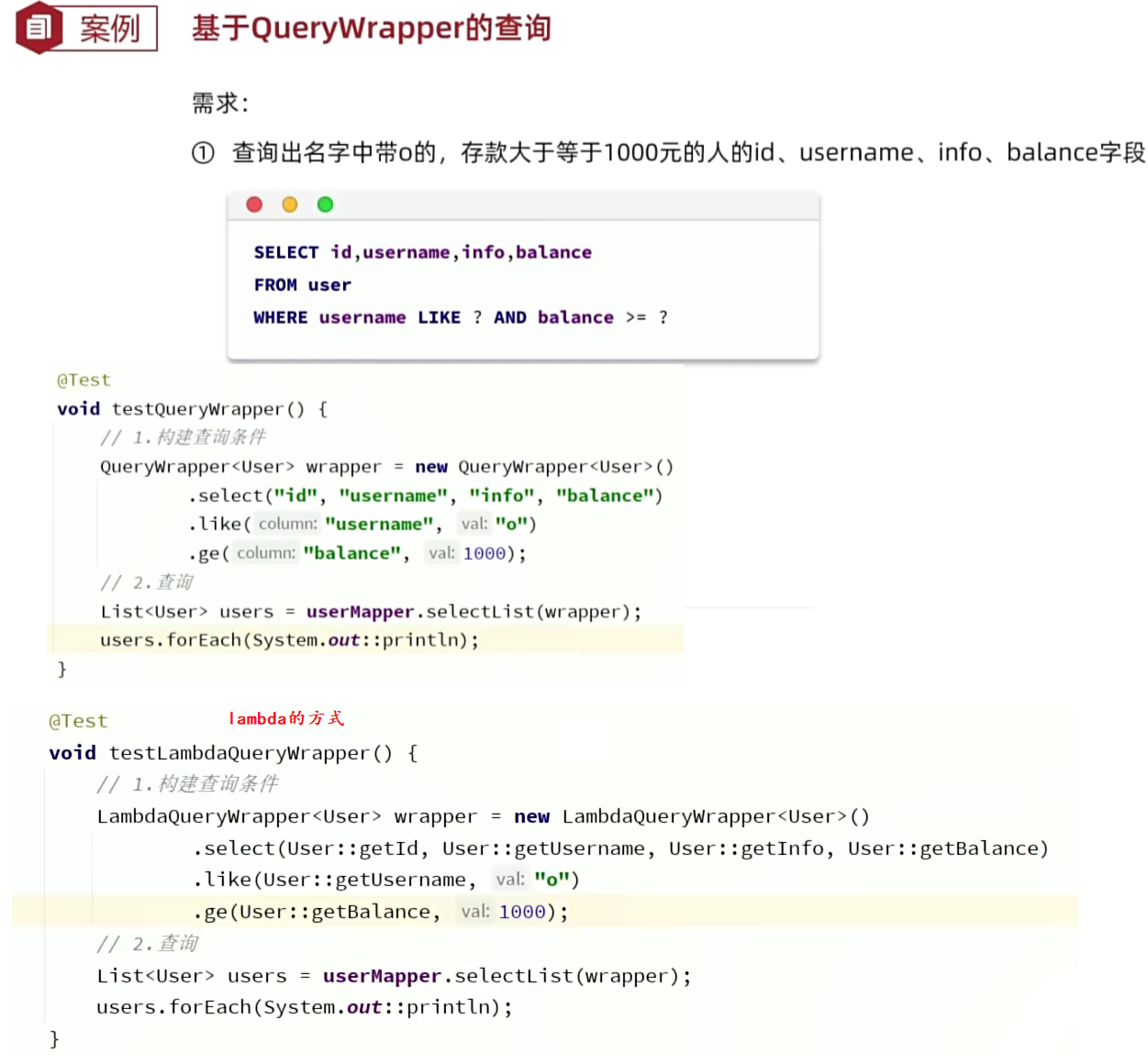
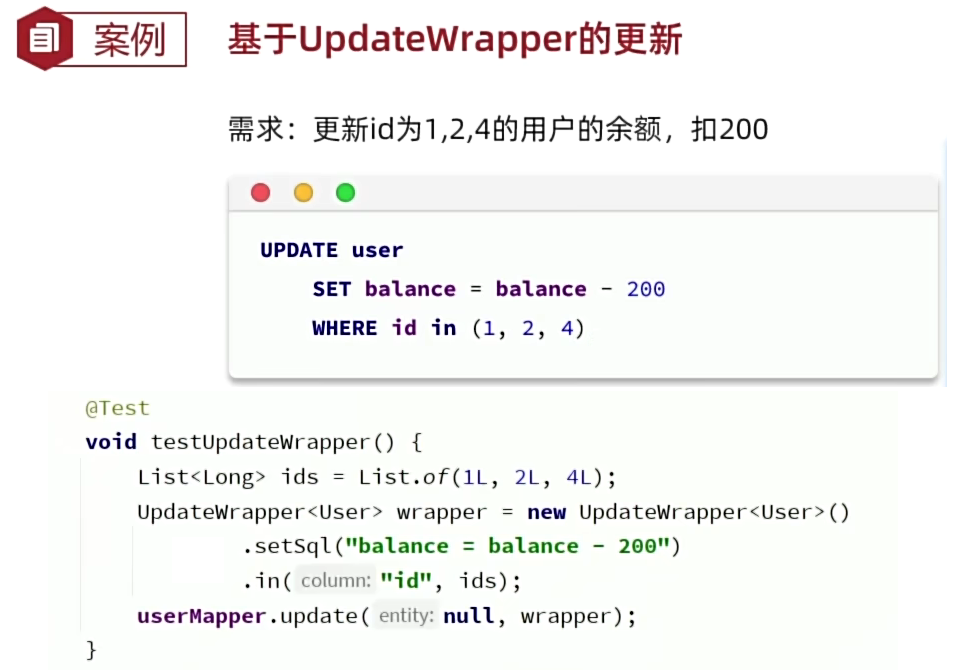
4. 条件构造器
前面的入门案例都是基于ID做的,但在真实的场景下,查询条件往往是比较复杂的,所以就有了条件构造器。Wrapper就是条件构造器,它是顶层父类。



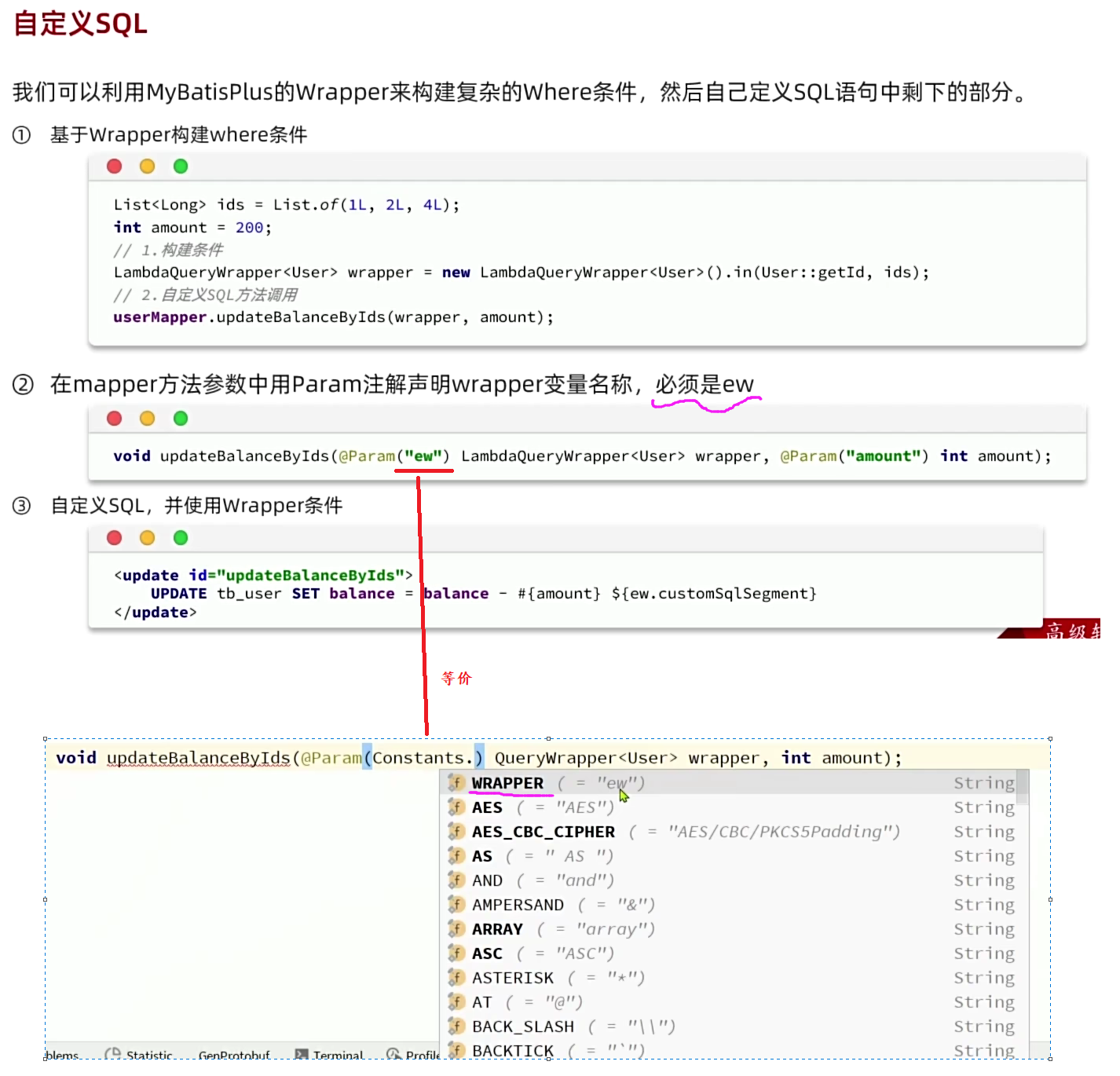
5. 自定义SQL
我们可以利用MyBatisPlus的Wrapper来构建复杂的Where条件,然后自己定义SQL语句中剩下的部分。


6. Service接口
6.1 基础用法
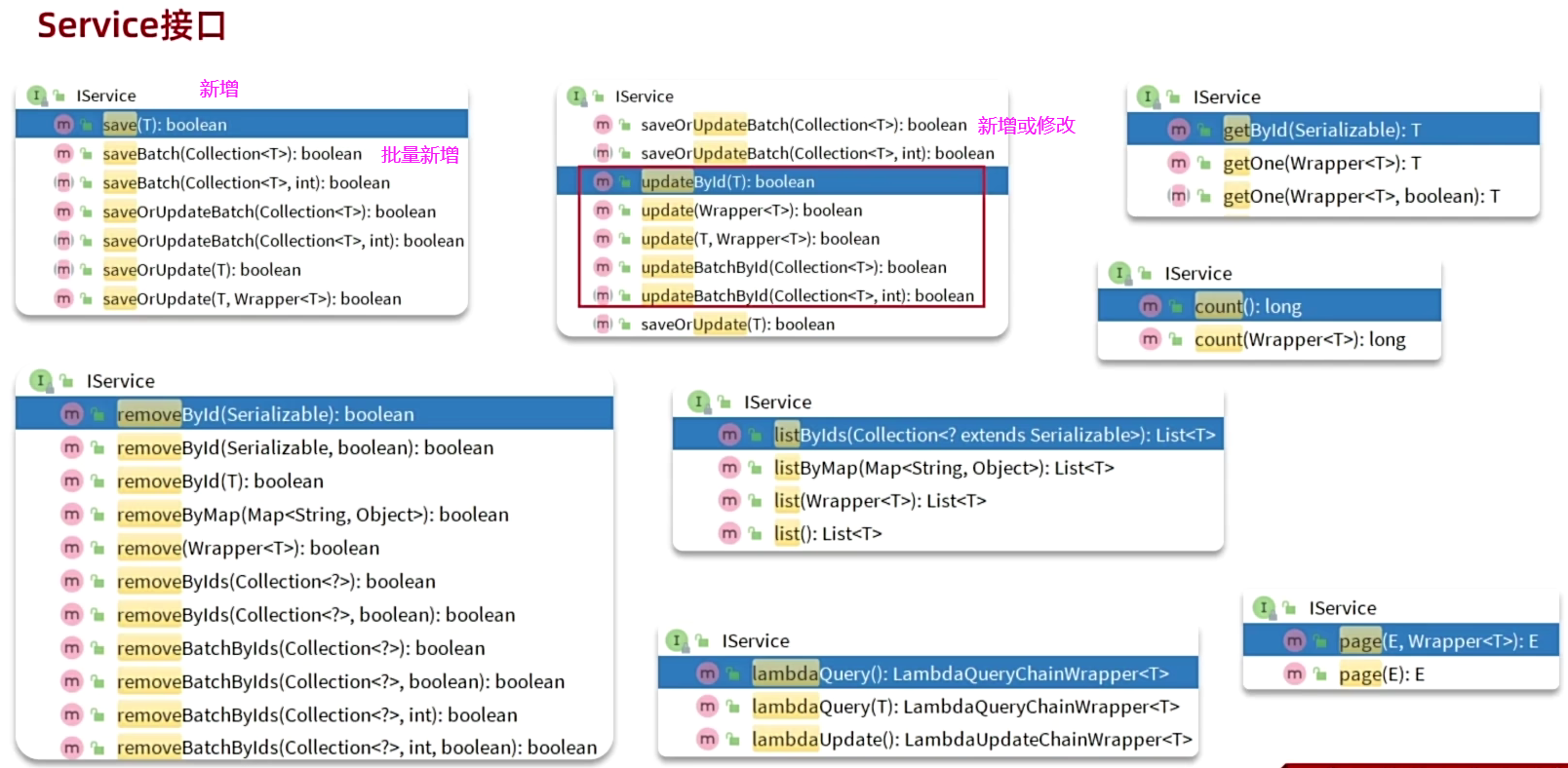

6.2 开发基础、复杂业务接口
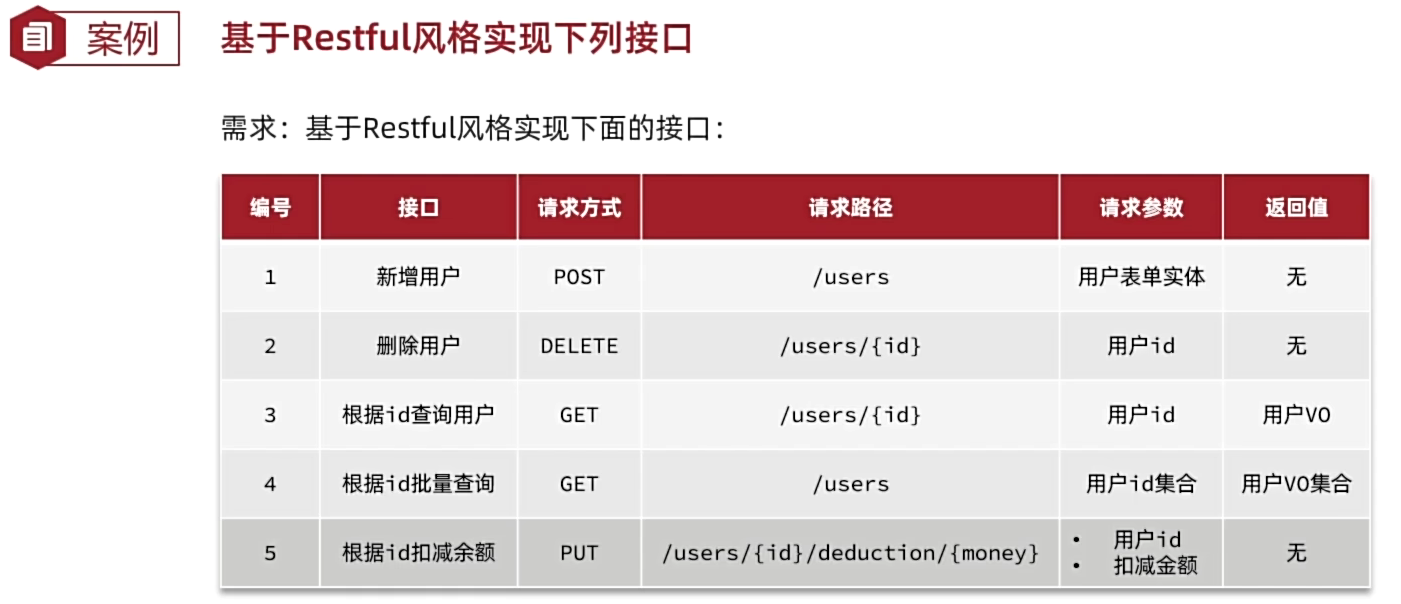
视频P9~P10讲了Swagger的使用和测试。
针对前四个接口,不用写任何Service方法,就可以使用MP提供的Service中的方法来实现。
详见飞书文档:Docs
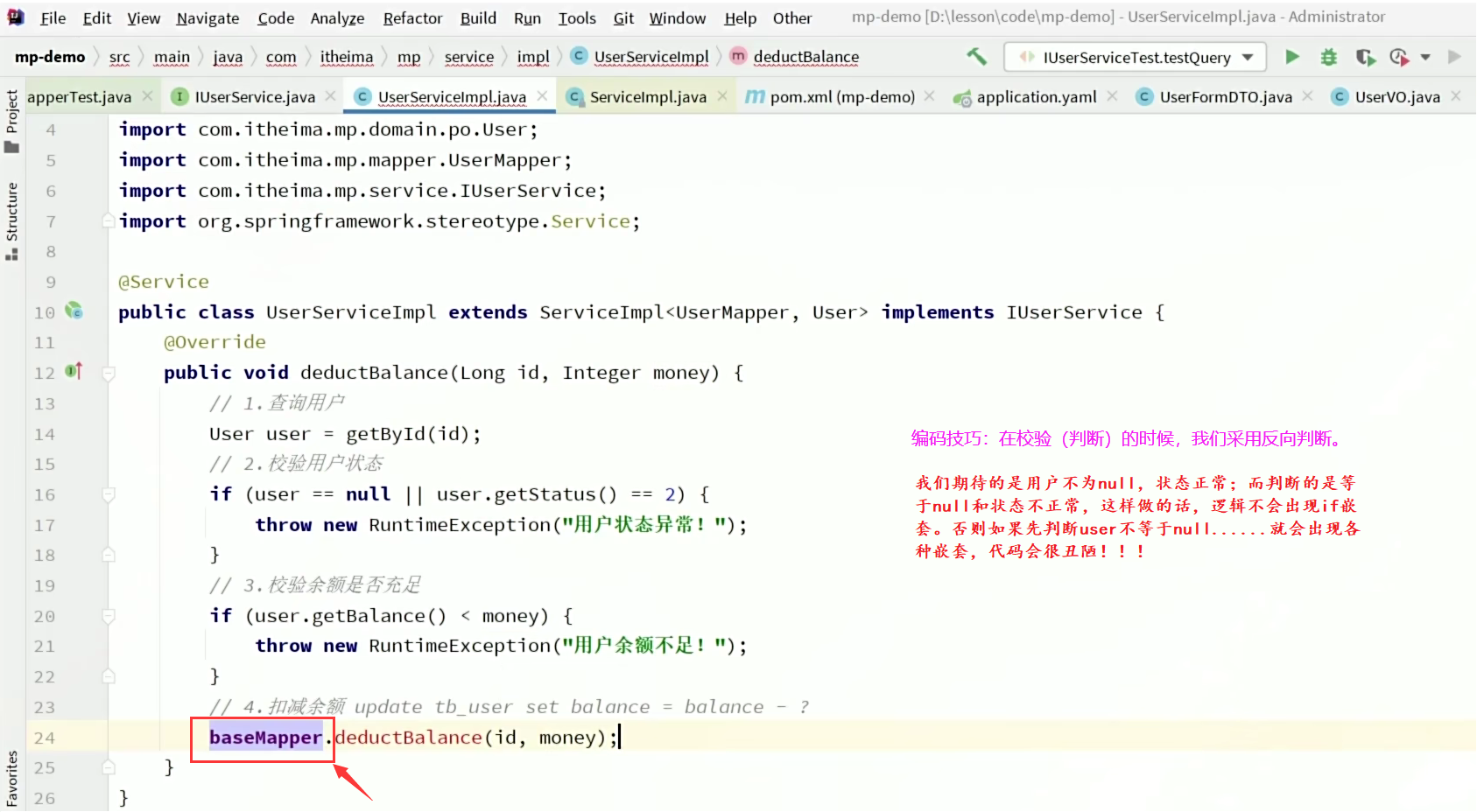
总结:
- 对于一些简单的CRUD方法,都可以直接在controller中调MP提供的Service方法,无需编写任何service代码,非常方便;
- 对于带有业务逻辑的接口才需要自定义service方法,在里面编写业务逻辑;
- 什么时候需要自定义Mapper呢?当baseMapper或者Service接口提供的方法不足以满足我们CURD需求的时候。
6.3 提供的Lambda功能
IService中还提供了Lambda功能来简化我们的复杂查询及更新功能。直接调用lambdaQuery和lambdaUpdate方法可以非常方便的实现复杂业务的查询、更新。
6.4 批量新增
计划:每次插入1000条,总共100次,共10万条数据。
为什么不是一次性10万条呢?
因为批处理肯定需要提前把用户new出来,然后再往数据库插入,如果一次性10万条的话,首先是占用内存太多了,第二是在向数据库传递数据的时候,请求的数据包其实是有上限大小的,一次网络请求传的数据量是有限的。

@Test
void testSaveBatch() {
// 准备10万条数据
List<User> list = new ArrayList<>(1000);
long b = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
list.add(buildUser(i));
// 每1000条批量插入一次
if (i % 1000 == 0) {
userService.saveBatch(list);
list.clear();
}
}
long e = System.currentTimeMillis();
System.out.println("耗时:" + (e - b));
}
private User buildUser(int i) {
User user = new User();
user.setUsername("user_" + i);
user.setPassword("123");
user.setPhone("" + (18688190000L + i));
user.setBalance(2000);
user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
user.setCreateTime(LocalDateTime.now());
user.setUpdateTime(user.getCreateTime());
return user;
}上面这种方式每次批量提交的sql语句还是1000条,性能还是差;要想真正提升,就得变为一条sql,需要将rewriteBatchedstatements这个参数设置为true,默认是false。这个参数不是MP的,是MySQL驱动的。修改项目中的application.yml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true 具体如下:(代码不变)
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: MySQL123不开启这个参数时,耗时26秒,开启后6秒,而如果用foreach一条条插入则需要四五分钟。
7. 扩展功能
7.1 代码生成
在使用MybatisPlus以后,基础的Mapper、Service、PO代码相对固定,重复编写也比较麻烦。因此MybatisPlus官方提供了代码生成器根据数据库表结构生成PO、Mapper、Service等相关代码。只不过代码生成器同样要编码使用,也很麻烦。
这里推荐大家使用一款MybatisPlus的插件,它可以基于图形化界面完成MybatisPlus的代码生成,非常简单。
第一步:安装插件
在Idea的plugins市场中搜索并安装MyBatisPlus插件。
第二步:使用
刚好数据库中还有一张address表尚未生成对应的实体和mapper等基础代码。我们利用插件生成一下。 首先需要配置数据库地址,在Idea顶部菜单中,找到other,选择Config Database:

在弹出的窗口中填写数据库连接的基本信息:
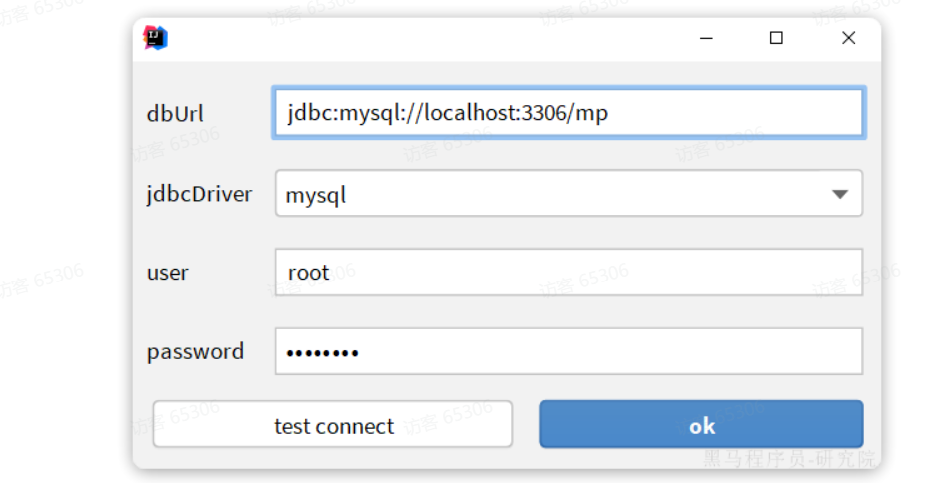
点击OK保存。
然后再次点击Idea顶部菜单中的other,然后选择Code Generator:

在弹出的表单中填写信息:
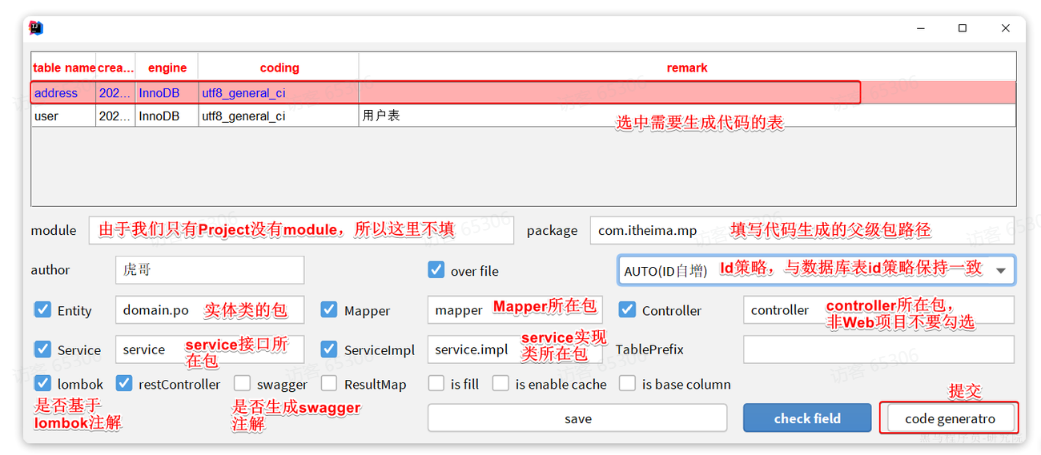
最终,代码自动生成到指定的位置了。
代码生成的三种方法:
- 代码生成器(新) | MyBatis-Plus (baomidou.com)
- 使用 MybatisX 插件:MybatisX快速开发插件 | MyBatis-Plus (baomidou.com)
- 使用MybatisPlus插件:就是本文介绍的方法。
7.2 静态工具Db
有的时候Service之间也会相互调用,为了避免出现循环依赖问题,MybatisPlus提供一个静态工具类:Db,其中的一些静态方法与IService中方法签名基本一致,也可以帮助我们实现CRUD功能。(注意:在MP最新版本才有的这个功能)
7.3 逻辑删除
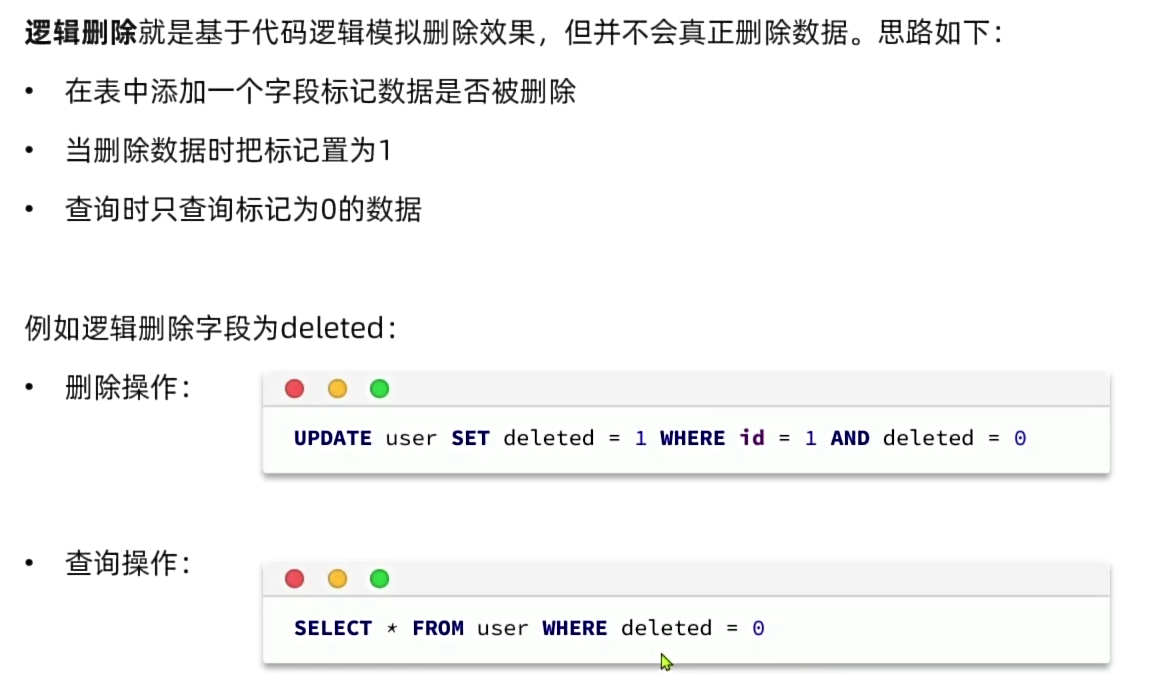
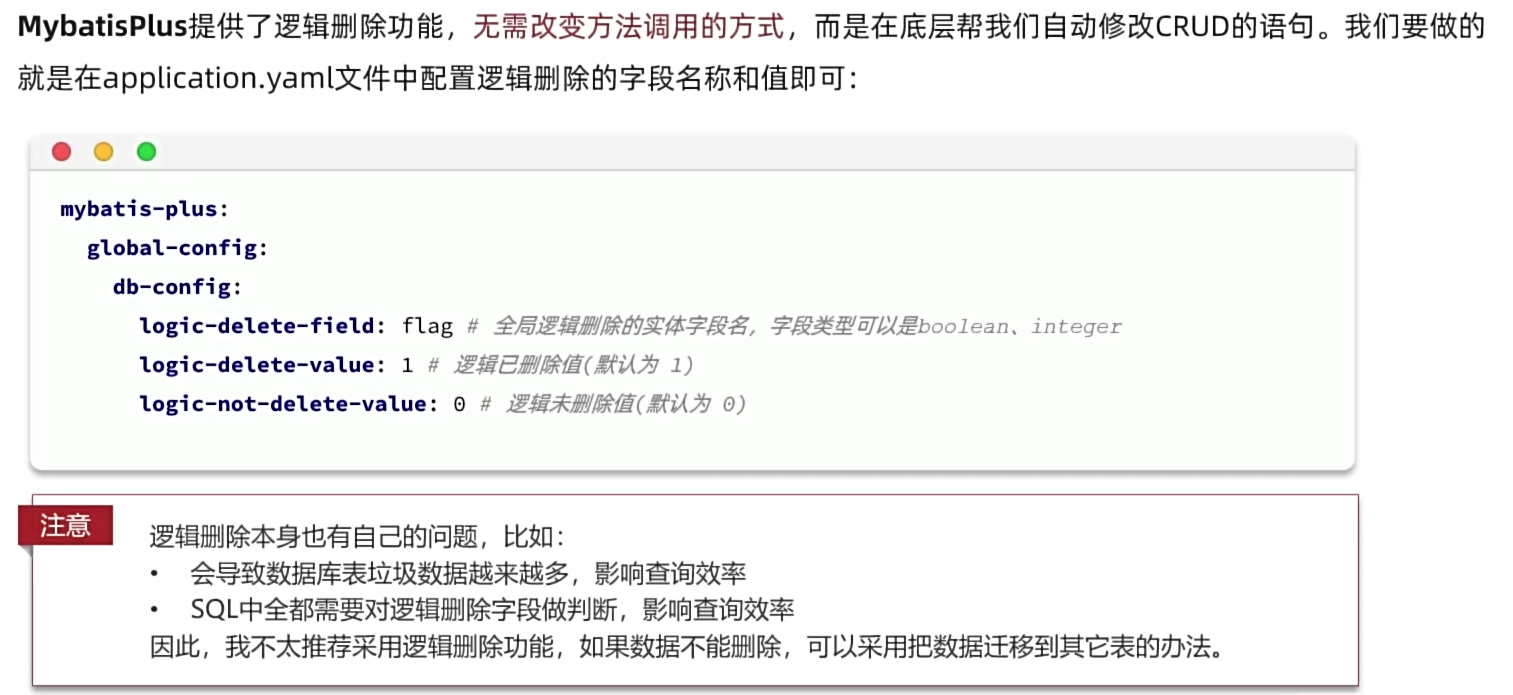
7.4 枚举处理器

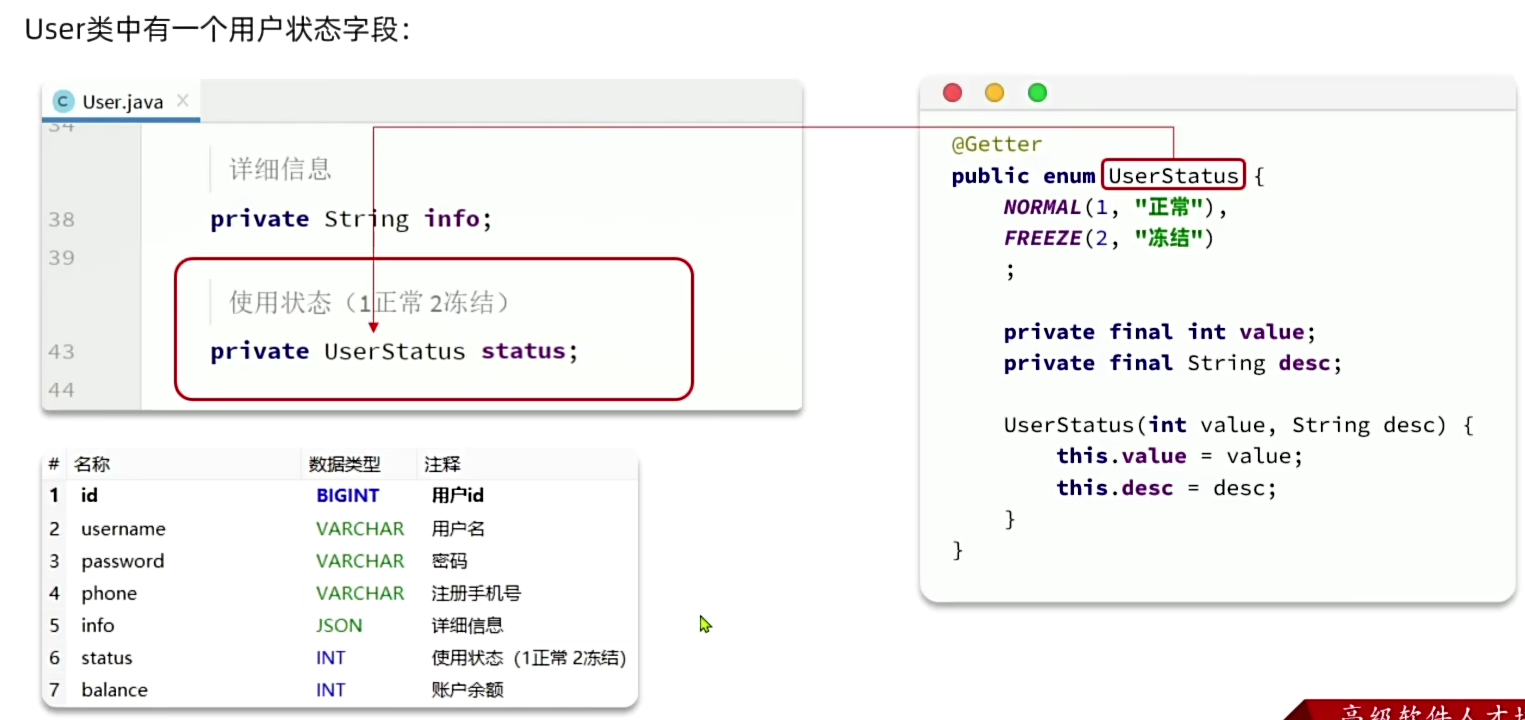
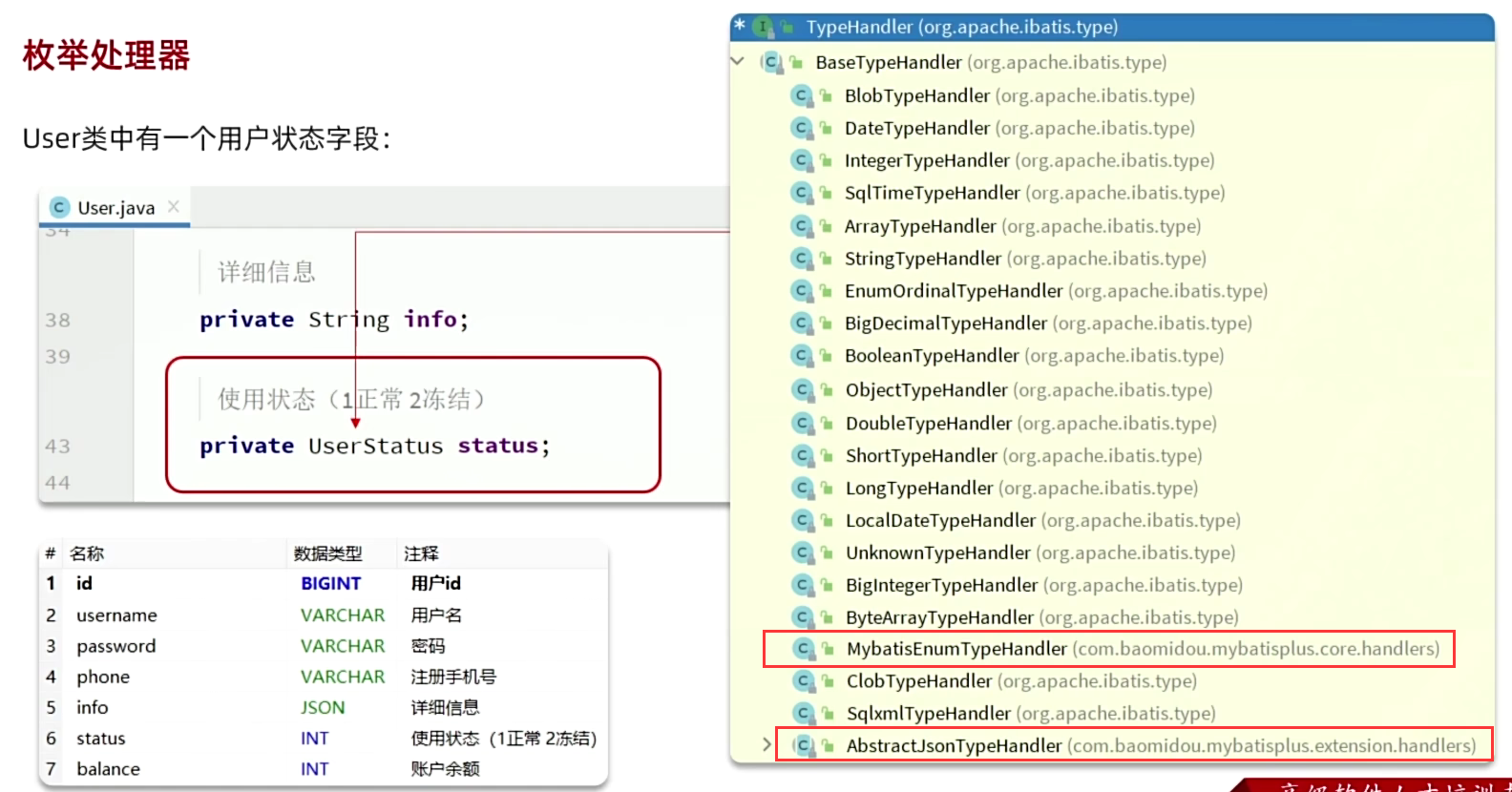

7.5 JSON类型处理器
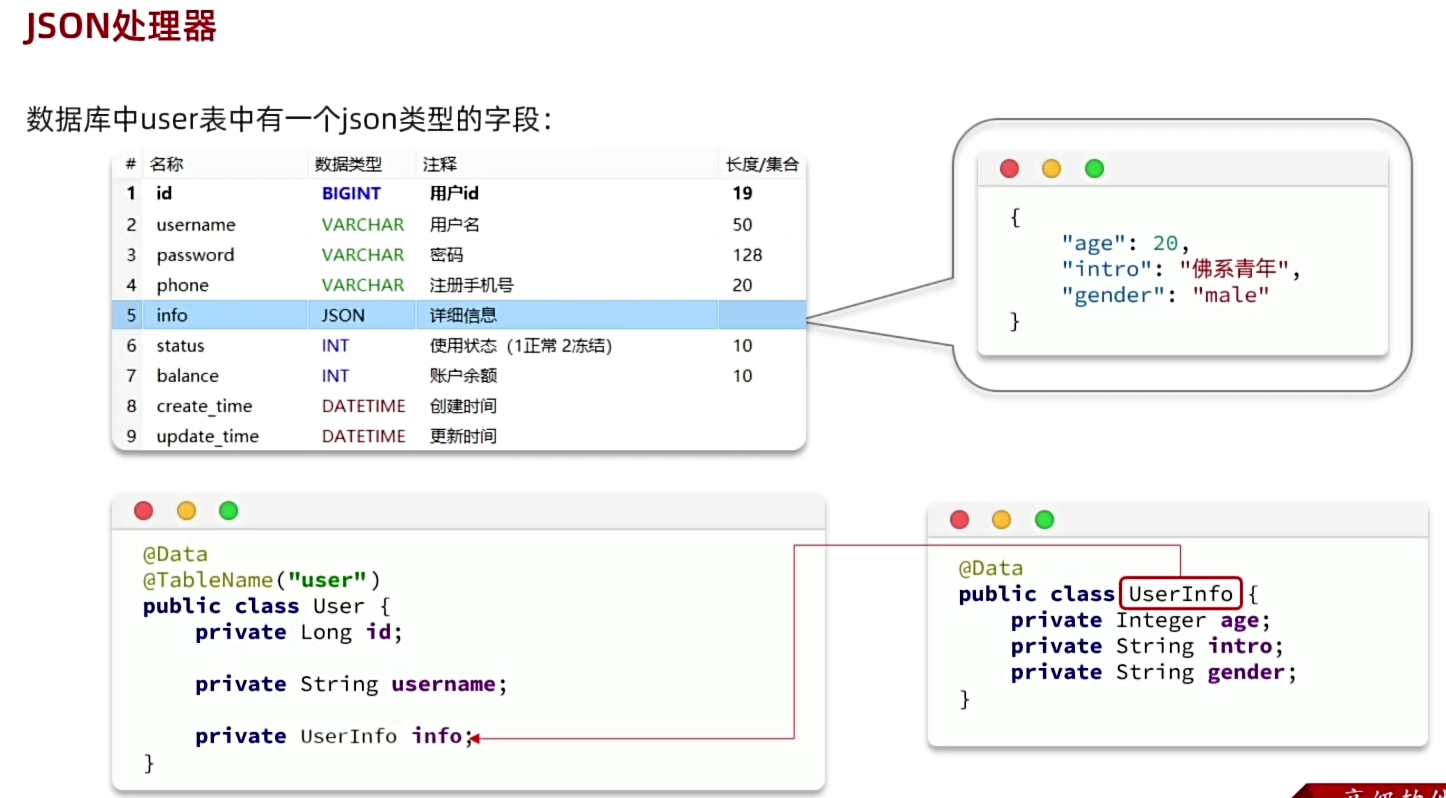
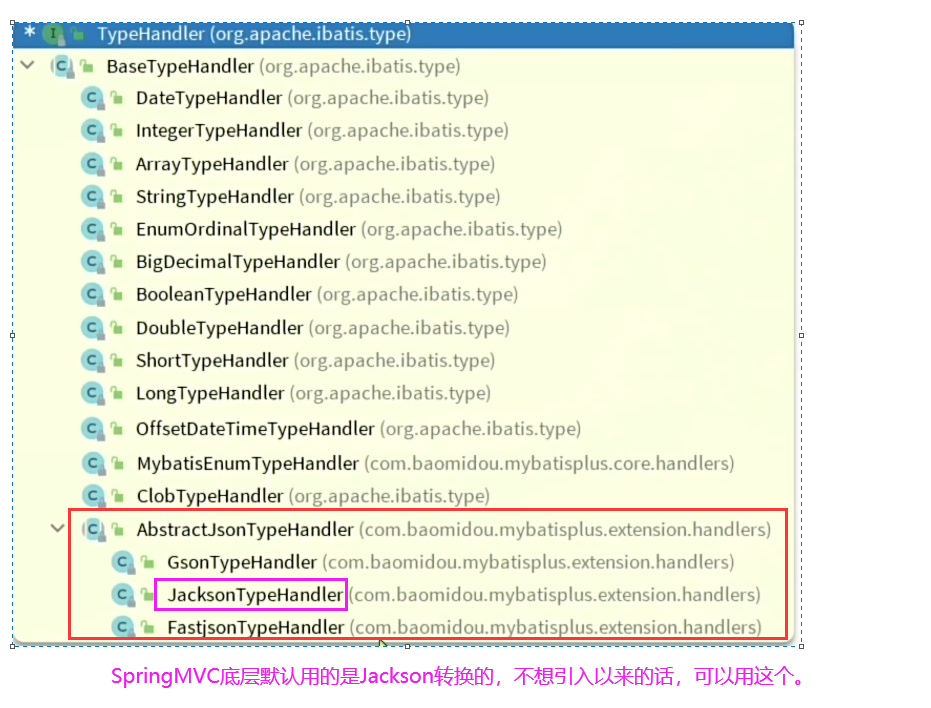
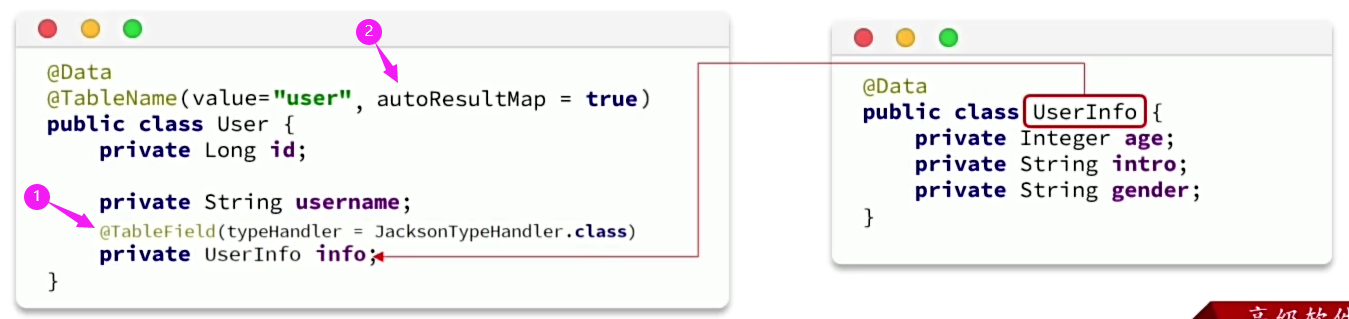 7.6配置加密
7.6配置加密
详见飞书讲义文档。
8. 插件功能

最常用的就是分页功能。(PageHelper也是可以用的)
8.1 分页插件基本用法
在未引入分页插件的情况下,MybatisPlus是不支持分页功能的,IService和BaseMapper中的分页方法都无法正常起效。 所以,我们必须配置分页插件。
第一步:配置分页插件
在项目中新建一个配置类,其代码如下:
package com.itheima.mp.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
// 初始化核心插件
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 添加分页插件
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}第二步:分页API
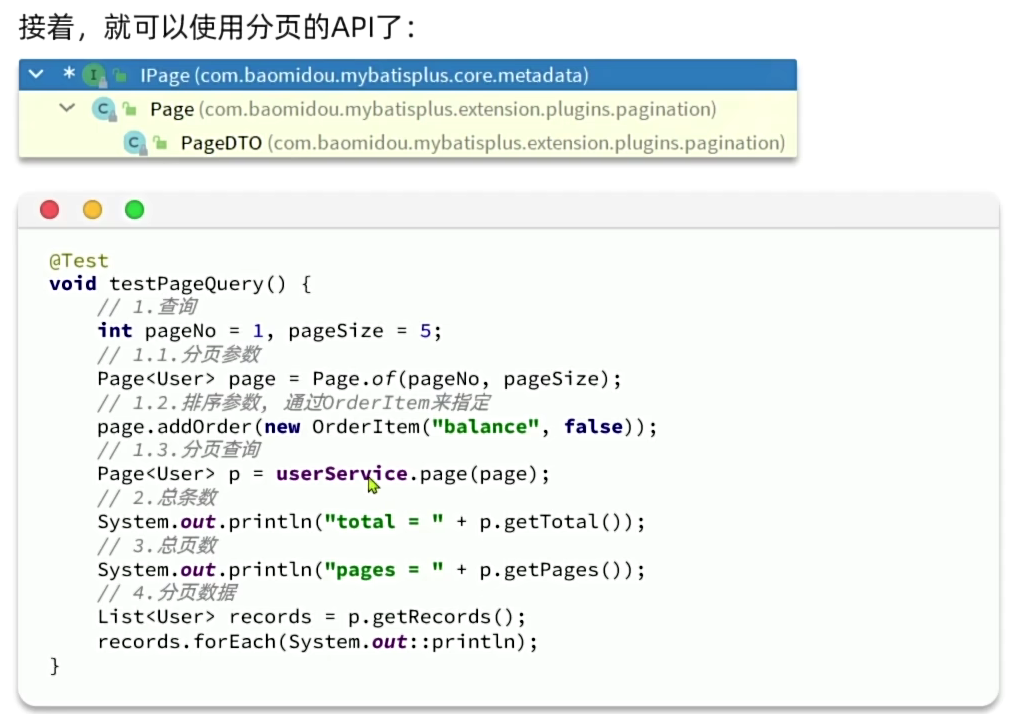
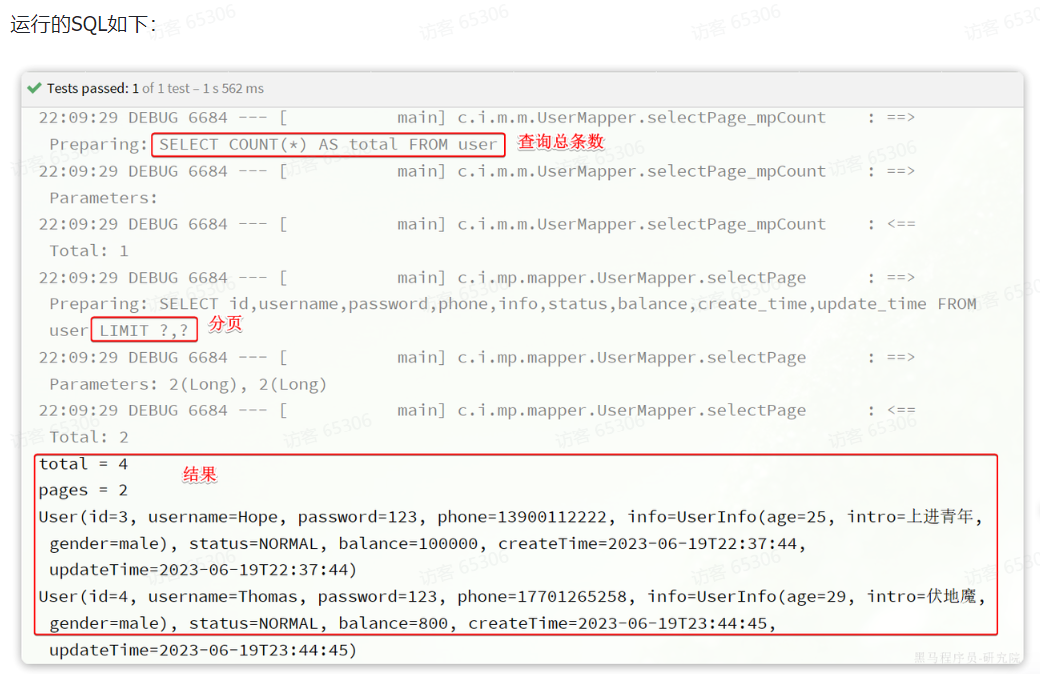
编写一个分页查询的测试:
@Test
void testPageQuery() {
// 1.分页查询,new Page()的两个参数分别是:页码、每页大小
Page<User> p = userService.page(new Page<>(2, 2));
// 2.总条数
System.out.println("total = " + p.getTotal());
// 3.总页数
System.out.println("pages = " + p.getPages());
// 4.数据
List<User> records = p.getRecords();
records.forEach(System.out::println);
}
这里用到了分页参数,Page,即可以支持分页参数,也可以支持排序参数。常见的API如下:
int pageNo = 1, pageSize = 5;
// 分页参数
Page<User> page = Page.of(pageNo, pageSize);
// 排序参数, 通过OrderItem来指定
page.addOrder(new OrderItem("balance", false));
userService.page(page);8.2 通用分页实体

返回值如下:
{
"total": 100006,
"pages": 50003,
"list": [
{
"id": 1685100878975279298,
"username": "user_9****",
"info": {
"age": 24,
"intro": "英文老师",
"gender": "female"
},
"status": "正常",
"balance": 2000
}
]
}@Override
public PageDTO<UserVO> queryUsersPage(PageQuery query) {
// 1.构建条件
// 1.1.分页条件
Page<User> page = Page.of(query.getPageNo(), query.getPageSize());
// 1.2.排序条件
if (query.getSortBy() != null) {
page.addOrder(new OrderItem(query.getSortBy(), query.getIsAsc()));
}else{
// 默认按照更新时间排序
page.addOrder(new OrderItem("update_time", false));
}
// 2.查询
page(page);
// 3.数据非空校验
List<User> records = page.getRecords();
if (records == null || records.size() <= 0) {
// 无数据,返回空结果
return new PageDTO<>(page.getTotal(), page.getPages(), Collections.emptyList());
}
// 4.有数据,转换
List<UserVO> list = BeanUtil.copyToList(records, UserVO.class);
// 5.封装返回
return new PageDTO<UserVO>(page.getTotal(), page.getPages(), list);
}8.3 改造通用分页实体

1)改造PageQuery实体
在刚才的代码中,从PageQuery到MybatisPlus的Page之间转换的过程还是比较麻烦的。我们完全可以在PageQuery这个实体中定义一个工具方法,简化开发。 像这样:
package com.itheima.mp.domain.query;
import com.baomidou.mybatisplus.core.metadata.OrderItem;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import lombok.Data;
@Data
public class PageQuery {
private Integer pageNo;
private Integer pageSize;
private String sortBy;
private Boolean isAsc;
public <T> Page<T> toMpPage(OrderItem ... orders){
// 1.分页条件
Page<T> p = Page.of(pageNo, pageSize);
// 2.排序条件
// 2.1.先看前端有没有传排序字段
if (sortBy != null) {
p.addOrder(new OrderItem(sortBy, isAsc));
return p;
}
// 2.2.再看有没有手动指定排序字段
if(orders != null){
p.addOrder(orders);
}
return p;
}
public <T> Page<T> toMpPage(String defaultSortBy, boolean isAsc){
return this.toMpPage(new OrderItem(defaultSortBy, isAsc));
}
public <T> Page<T> toMpPageDefaultSortByCreateTimeDesc() {
return toMpPage("create_time", false);
}
public <T> Page<T> toMpPageDefaultSortByUpdateTimeDesc() {
return toMpPage("update_time", false);
}
}这样我们在开发也时就可以省去对从PageQuery到Page的的转换:
// 1.构建条件
Page<User> page = query.toMpPageDefaultSortByCreateTimeDesc();2)改造PageDTO实体
在查询出分页结果后,数据的非空校验,数据的vo转换都是模板代码,编写起来很麻烦。我们完全可以将其封装到PageDTO的工具方法中,简化整个过程:
package com.itheima.mp.domain.dto;
import cn.hutool.core.bean.BeanUtil;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Collections;
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageDTO<V> {
private Long total;
private Long pages;
private List<V> list;
/**
* 返回空分页结果
* @param p MybatisPlus的分页结果
* @param <V> 目标VO类型
* @param <P> 原始PO类型
* @return VO的分页对象
*/
public static <V, P> PageDTO<V> empty(Page<P> p){
return new PageDTO<>(p.getTotal(), p.getPages(), Collections.emptyList());
}
/**
* 将MybatisPlus分页结果转为 VO分页结果
* @param p MybatisPlus的分页结果
* @param voClass 目标VO类型的字节码
* @param <V> 目标VO类型
* @param <P> 原始PO类型
* @return VO的分页对象
*/
public static <V, P> PageDTO<V> of(Page<P> p, Class<V> voClass) {
// 1.非空校验
List<P> records = p.getRecords();
if (records == null || records.size() <= 0) {
// 无数据,返回空结果
return empty(p);
}
// 2.数据转换
List<V> vos = BeanUtil.copyToList(records, voClass);
// 3.封装返回
return new PageDTO<>(p.getTotal(), p.getPages(), vos);
}
/**
* 将MybatisPlus分页结果转为 VO分页结果,允许用户自定义PO到VO的转换方式
* @param p MybatisPlus的分页结果
* @param convertor PO到VO的转换函数
* @param <V> 目标VO类型
* @param <P> 原始PO类型
* @return VO的分页对象
*/
public static <V, P> PageDTO<V> of(Page<P> p, Function<P, V> convertor) {
// 1.非空校验
List<P> records = p.getRecords();
if (records == null || records.size() <= 0) {
// 无数据,返回空结果
return empty(p);
}
// 2.数据转换
List<V> vos = records.stream().map(convertor).collect(Collectors.toList());
// 3.封装返回
return new PageDTO<>(p.getTotal(), p.getPages(), vos);
}
}最终,业务层的代码可以简化为:
@Override
public PageDTO<UserVO> queryUserByPage(PageQuery query) {
// 1.构建条件
Page<User> page = query.toMpPageDefaultSortByCreateTimeDesc();
// 2.查询
page(page);
// 3.封装返回
return PageDTO.of(page, UserVO.class);
}如果是希望自定义PO到VO的转换过程,可以这样做:
@Override
public PageDTO<UserVO> queryUserByPage(PageQuery query) {
// 1.构建条件
Page<User> page = query.toMpPageDefaultSortByCreateTimeDesc();
// 2.查询
page(page);
// 3.封装返回
return PageDTO.of(page, user -> {
// 拷贝属性到VO
UserVO vo = BeanUtil.copyProperties(user, UserVO.class);
// 用户名脱敏
String username = vo.getUsername();
vo.setUsername(username.substring(0, username.length() - 2) + "**");
return vo;
});
}二、Redis面试题
1. 如何保证缓存的双写一致性?
答:缓存的双写一致性很难保证强一致,只能尽可能降低不一致的概率,确保最终一致。我们项目中采用的是
Cache Aside模式。简单来说,就是在更新数据库之后删除缓存;在查询时先查询缓存,如果未命中则查询数据库并写入缓存。同时我们会给缓存设置过期时间作为兜底方案,如果真的出现了不一致的情况,也可以通过缓存过期来保证最终一致。追问:为什么不采用延迟双删机制?
答:延迟双删的第一次删除并没有实际意义,第二次采用延迟删除主要是解决数据库主从同步的延迟问题,我认为这是数据库主从的一致性问题,与缓存同步无关。既然主节点数据已经更新,Redis的缓存理应更新。而且延迟双删会增加缓存业务复杂度,也没能完全避免缓存一致性问题,投入回报比太低。
2. 如何解决缓存穿透问题?
答:缓存穿透也可以说是穿透攻击,具体来说是因为请求访问到了数据库不存在的值,这样缓存无法命中,必然访问数据库。如果高并发的访问这样的接口,会给数据库带来巨大压力。
我们项目中都是基于布隆过滤器来解决缓存穿透问题的,当缓存未命中时基于布隆过滤器判断数据是否存在。如果不存在则不去访问数据库。
当然,也可以使用缓存空值的方式解决,不过这种方案比较浪费内存。
3. 如何解决缓存雪崩问题?
答:缓存雪崩的常见原因有两个,第一是因为大量key同时过期。针对问这个题我们可以可以给缓存key设置不同的TTL值,避免key同时过期。
第二个原因是Redis宕机导致缓存不可用。针对这个问题我们可以利用集群提高Redis的可用性。也可以添加多级缓存,当Redis宕机时还有本地缓存可用。
4. 如何解决缓存击穿问题?
答:缓存击穿往往是由热点Key引起的,当热点Key过期时,大量请求涌入同时查询,发现缓存未命中都会去访问数据库,导致数据库压力激增。解决这个问题的主要思路就是避免多线程并发去重建缓存,因此方案有两种。
第一种是基于互斥锁,当发现缓存未命中时需要先获取互斥锁,再重建缓存,缓存重建完成释放锁。这样就可以保证缓存重建同一时刻只会有一个线程执行。不过这种做法会导致缓存重建时性能下降严重。
第二种是基于逻辑过期,也就是不给热点Key设置过期时间,而是给数据添加一个过期时间的字段。这样热点Key就不会过期,缓存中永远有数据。
查询到数据时基于其中的过期时间判断key是否过期,如果过期开启独立新线程异步的重建缓存,而查询请求先返回旧数据即可。当然,这个过程也要加互斥锁,但由于重建缓存是异步的,而且获取锁失败也无需等待,而是返回旧数据,这样性能几乎不受影响。
需要注意的是,无论是采用哪种方式,在获取互斥锁后一定要再次判断缓存是否命中,做dubbo check. 因为当你获取锁成功时,可能是在你之前有其它线程已经重建缓存了。
三、微服务面试题
文档地址:Docs
微服务在面试时被问到的内容相对较少,常见的面试题如下:(用自己的语言回答)
-
SpringCloud有哪些常用组件?分别是什么作用?
-
服务注册发现的基本流程是怎样的?
-
Eureka和Nacos有哪些区别?
-
Nacos的分级存储模型是什么意思?
-
OpenFeign是如何实现负载均衡的?
-
Ribbon和SpringCloudLoadBalancer有什么差异
-
什么是服务雪崩,常见的解决方案有哪些?
-
Hystix和Sentinel有什么区别和联系?
-
限流的常见算法有哪些?
-
什么是CAP理论和BASE思想?
-
项目中碰到过分布式事务问题吗?怎么解决的?
-
AT模式如何解决脏读和脏写问题的?
-
TCC模式与AT模式对比,有哪些优缺点
-
RabbitMQ是如何确保消息的可靠性的?
-
RabbitMQ是如何解决消息堆积问题的?
总体来说,还是看 黑马微服务课程1-CSDN博客 即可。这个最新的课程只是多了一些内容,如MP。
















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









