






微信公众号:Garry的学习生涯
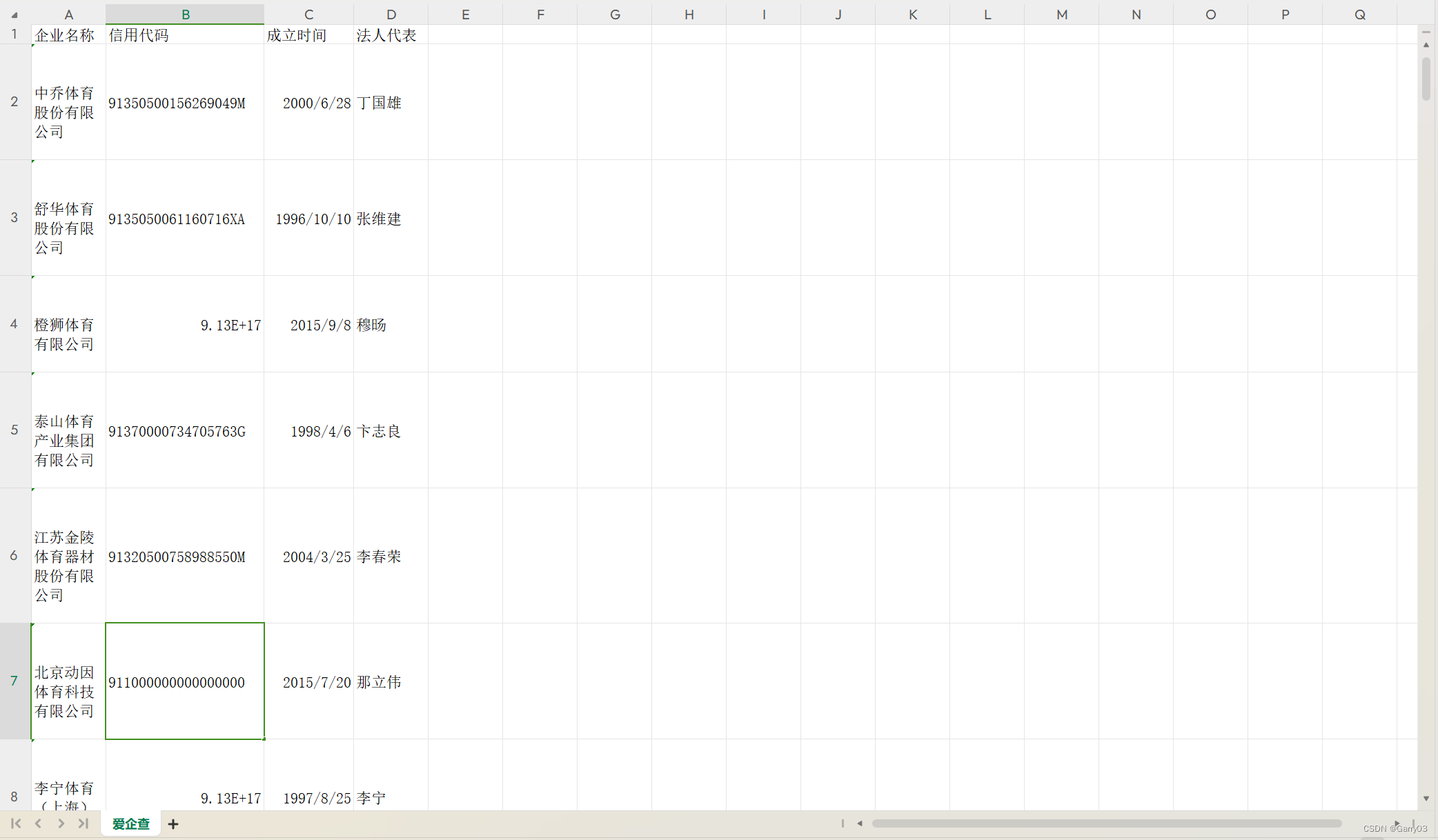
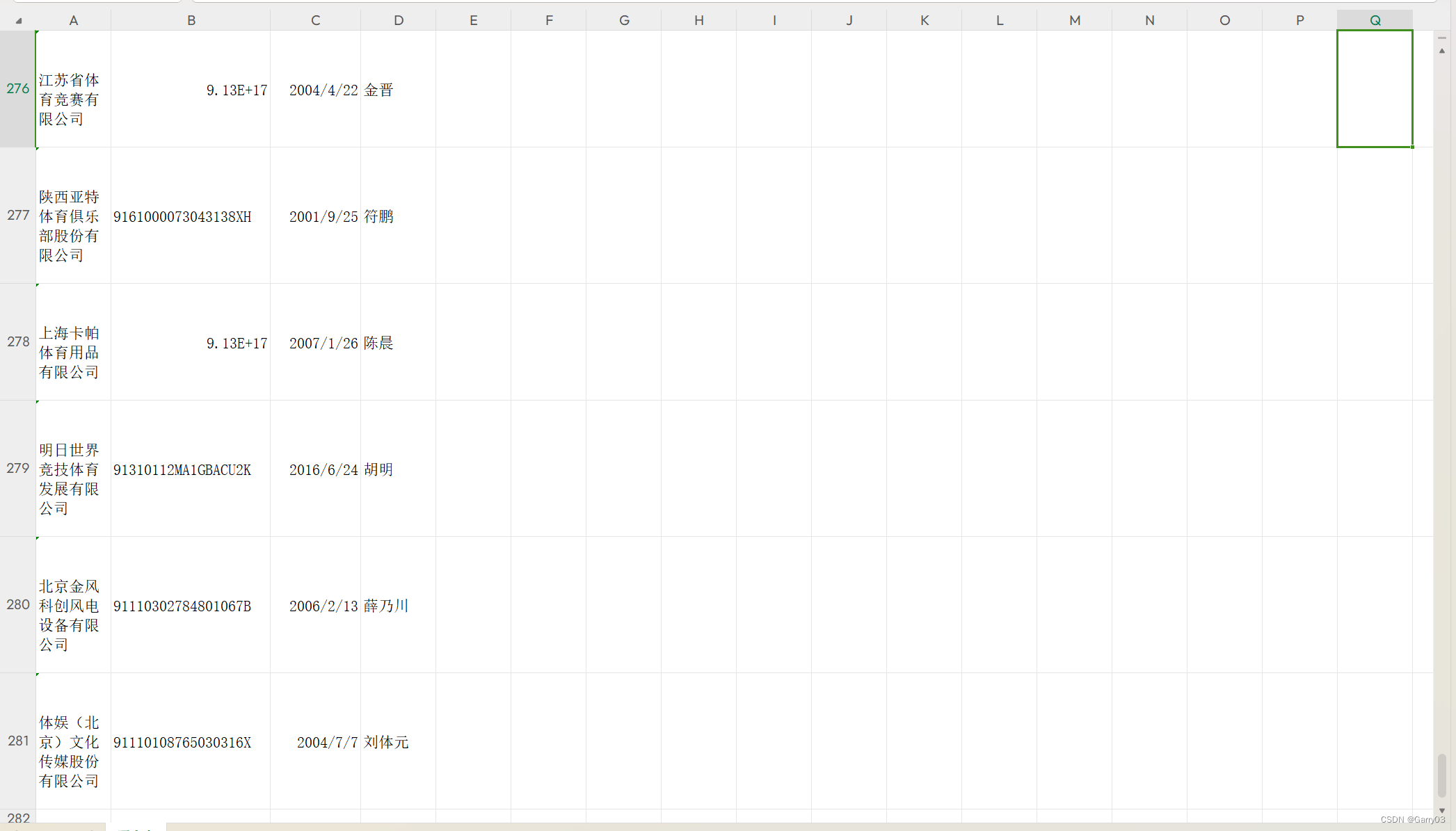
这段代码是用于爬取爱查网(https://www.aiqicha.com)上体育类企业的相关信息,包括企业名称、信用代码、成立时间和法人代表。下面是每一行代码的解释和注释:
import csv # 导入csv模块,用于处理CSV文件
import requests # 导入requests模块,用于发送HTTP请求
from time import sleep # 导入sleep函数,用于暂停程序执行
from bs4 import BeautifulSoup # 导入BeautifulSoup模块,用于解析HTML文档
from selenium import webdriver # 导入webdriver模块,用于自动化浏览器操作
from selenium.webdriver import Keys # 导入Keys类,用于模拟键盘按键操作
from selenium.webdriver.common.by import By # 导入By类,用于指定元素定位方式
from selenium.webdriver import ActionChains # 导入ActionChains类,用于模拟鼠标操作接下来,代码打开一个名为"D:\爱企查.csv"的文件,以追加模式写入数据,并设置编码为utf-8-sig。然后创建一个csv.writer对象,用于将数据写入CSV文件。
fi = open("D:\\爱企查.csv", "a", newline="", encoding="utf-8-sig")
writer = csv.writer(fi)
writer.writerow(("企业名称", "信用代码", "成立时间", "法人代表"))接下来,使用selenium的webdriver模块启动Chrome浏览器,并访问爱查网的网址。
driver = webdriver.Chrome()
driver.get('https://www.aiqicha.com')在网页中查找输入框,并输入关键词"体育"。
el_1 = driver.find_element(By.ID, 'aqc-search-input')
el_1.send_keys('体育')点击搜索按钮,等待页面加载完成。
driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div/div[1]/div[2]/button').click()
sleep(2)获取当前页面的源代码,并使用BeautifulSoup解析HTML文档。
a = driver.page_source
soup = BeautifulSoup(a, "lxml")找到包含验证码的元素,并提取其id属性值。
number = soup.find("div", class_="vcode-spin-button")['id']根据验证码元素的id属性值,构造验证码拖动的目标元素的xpath表达式。
number_last_3 = number[-3:]#此步破解百度图片滑动验证
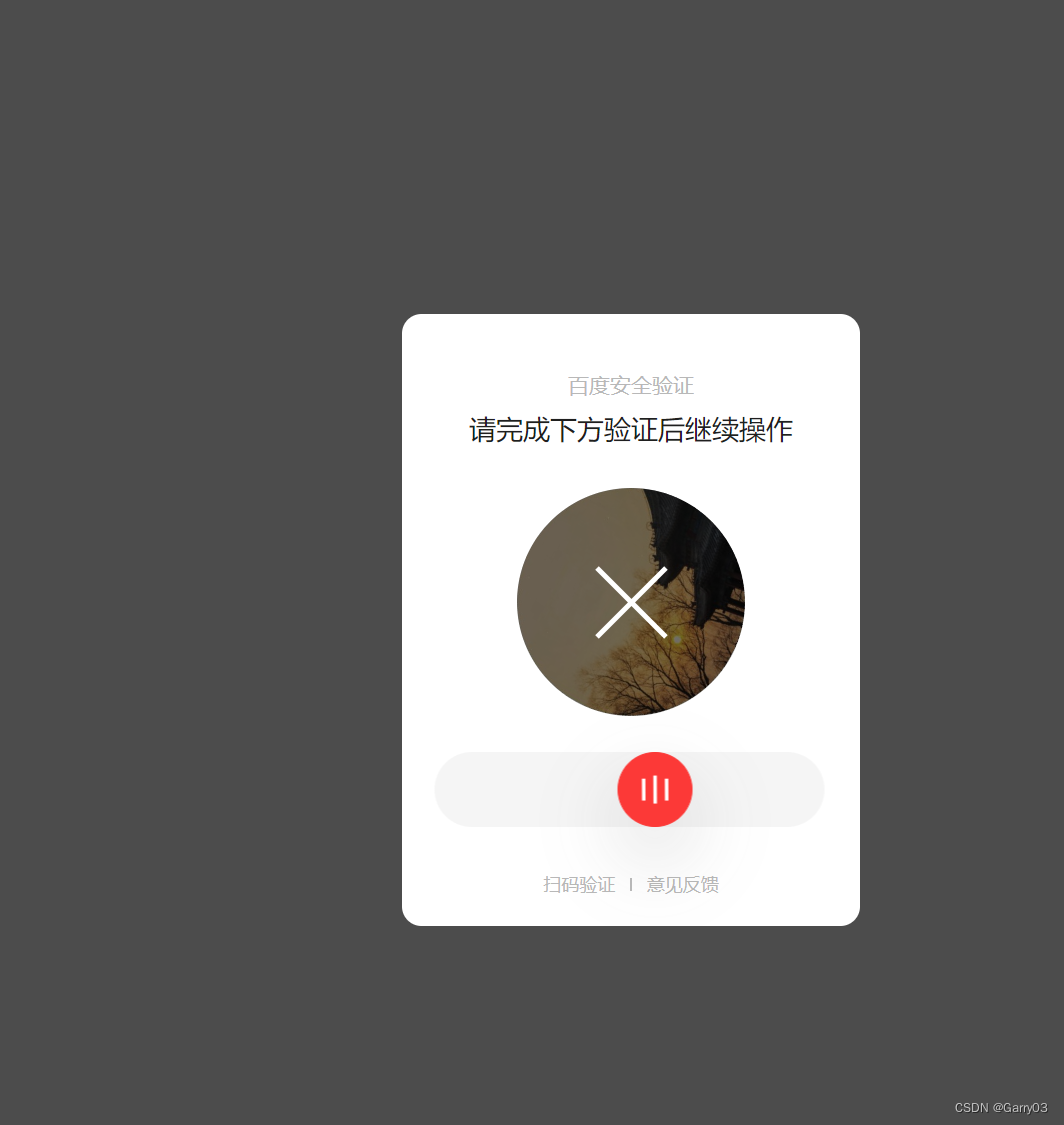
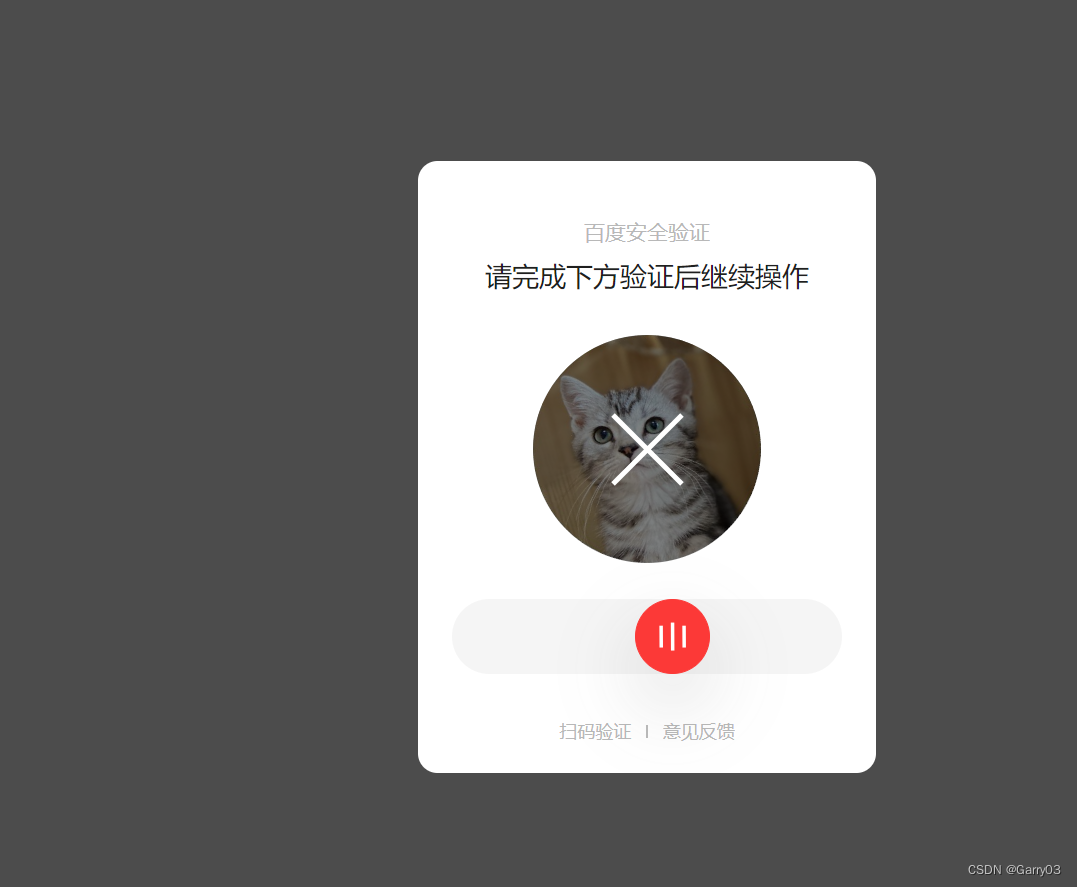
当页面源代码长度大于0时,循环执行以下操作:
-
切换到新打开的窗口。
-
找到验证码源元素和目标元素。
-
使用ActionChains模拟鼠标拖动操作。
-
等待2秒。
-
重新获取页面源代码,并使用BeautifulSoup解析HTML文档。
-
更新页面源代码长度。
while len(a) > 0:
windows = driver.window_handles
driver.switch_to.window(windows[-1])
source = driver.find_element(By.XPATH, f'//*[@id="vcode-spin-button-p{number_last_3}"]')
target = driver.find_element(By.XPATH, f'//*[@id="vcode-spin-button-p{number_last_3}"]')
ActionChains(driver).drag_and_drop(source, target).perform()
sleep(2)
soup = BeautifulSoup(driver.page_source, "lxml")
a = soup.find_all("div", class_="vcode-spin-button")切换回主窗口。
windows = driver.window_handles
driver.switch_to.window(windows[-1])添加cookie,刷新页面。(写入登录后你的cookie的名字和value)
existing_cookie = {"name": " ", "value": " "}
driver.add_cookie(existing_cookie)
driver.refresh()循环抓取第1页至第30页的数据。
for b in range(1, 31):
windows = driver.window_handles
driver.switch_to.window(windows[-1])
sleep(1)
for c in range(1, 11):
js = f'window.scrollTo(10000,0);'
driver.execute_script(js)
driver.find_element(By.XPATH, f"/html/body/div[1]/div[2]/div/div[1]/div[3]/div[2]/ul/div/div/input").click()
windows = driver.window_handles
driver.switch_to.window(windows[-1])
concent = driver.page_source
soup = BeautifulSoup(concent, "lxml")
try:
company_name = soup.find("h1", class_="name").get_text()
except:
company_name = "无相关内容"
try:
cridit_code = soup.find("span", class_="social-credit-code-text").get_text()
except:
cridit_code = "无相关内容"
try:
founding_time = soup.find_all("div", class_="info-item")[3].get_text().split()[1]
except:
founding_time = "无相关内容"
try:
legal_representative = soup.find("div", class_="info-item").get_text().split()[1]
except:
legal_representative = "无相关内容"
writer.writerow((company_name, cridit_code, founding_time, legal_representative))
driver.back()
l = driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div/div[1]/div[3]/div[2]/ul/div/div/input')
l.send_keys(Keys.BACK_SPACE)
l.send_keys(Keys.BACK_SPACE)
l.send_keys(f'{b}', Keys.ENTER)
sleep(5)
print("抓取完成第{}页".format(b))
el_3 = driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div/div[1]/div[3]/div[2]/ul/div/div/input')
el_3.send_keys(Keys.BACK_SPACE)
el_3.send_keys(Keys.BACK_SPACE)
el_3.send_keys(f'{b + 1}', Keys.ENTER)
js = f'window.scrollTo(10000,0);'
driver.execute_script(js)
sleep(3)
fi.close()
print("抓取完成!")
















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









