






目录
1.2引出 ROC 曲线和 PR 曲线在实际应用中的作用与意义
一、引言
1.1简介机器学习模型评估的重要性
机器学习模型评估是确保模型在实际应用中有效性的关键步骤。通过评估,我们可以准确地判断一个模型在未见数据上的表现,避免过拟合或不足拟合的情况。模型评估不仅仅是选择正确的模型,还涉及揭示其在不同场景下的优缺点,包括对数据不平衡的敏感度、对错误分类的容忍度等。合理的评估方式帮助我们优化模型,确保其在真实世界中的工作效果,提升决策的准确性,并且指导模型的进一步改进。
1.2引出 ROC 曲线和 PR 曲线在实际应用中的作用与意义
在实际应用中,ROC 曲线和 PR 曲线为我们提供了一种直观的方式来评估和比较二分类模型的性能。具体来说:
ROC 曲线 通过展示不同阈值下的真正性率(TPR)与假正性率(FPR)的关系,帮助我们了解模型在整体上如何区分正负样本。这种曲线不受正负样本比例的直接影响,适合用来评估模型的整体判别能力,并通过 AUC(曲线下面积)这一指标来量化模型性能。
PR 曲线 则侧重于反映正例的检测情况,即展示精确率(Precision)与召回率(Recall)之间的权衡。在正例稀缺或数据极度不平衡的场景中,PR 曲线能够更准确地揭示模型在正例识别上的表现,避免 ROC 曲线可能存在的乐观偏差。
二、混淆矩阵与关键指标
1. 混淆矩阵(Confusion Matrix)
混淆矩阵是分类模型性能评估的核心工具,通过统计预测结果与真实标签的对应关系,将样本分为四类:
| 真实正类(Positive) | 真实负类(Negative) | |
| 预测正类 | TP(True Positive) | FP(False Positive) |
| 预测负类 | FN(False Negative) | TN(True Negative) |
TP(真阳性):正确预测为正类的样本(例:患病者被正确诊断)。
FP(假阳性):负类样本被误判为正类(例:健康人被误诊为患病)。
TN(真阴性):正确预测为负类的样本(例:健康人被正确识别)。
FN(假阴性):正类样本被误判为负类(例:患病者被漏诊)。
2. 关键性能指标
从混淆矩阵中可推导出多个核心指标,分别反映模型的不同能力:
2.1 召回率(Recall )
意义:模型捕捉正类样本的能力(查全率)。
2.2 精确率(Precision)
意义:模型预测为正类的样本中,真实正类的比例(查准率)
3. 阈值的作用与调整
3.1 分类阈值(Threshold)的定义
分类阈值是判断样本属于正类或负类的概率分界线:
若样本预测概率 ≥ 阈值,则判为正类;
若样本预测概率 < 阈值,则判为负类。
3.2 阈值如何影响预测结果
阈值升高:
正类预测更严格 → 精确率↑,召回率↓(减少FP,但可能增加FN)。例:法律判决中提高定罪阈值,减少冤案(FP↓),但可能放过真凶(FN↑)。
阈值降低:
正类预测更宽松 → 召回率↑,精确率↓(减少FN,但可能增加FP)。例:疾病筛查中降低诊断阈值,减少漏诊(FN↓),但误诊率可能上升(FP↑)。三、 ROC 曲线的定义与基本原理
三、ROC 曲线的概念
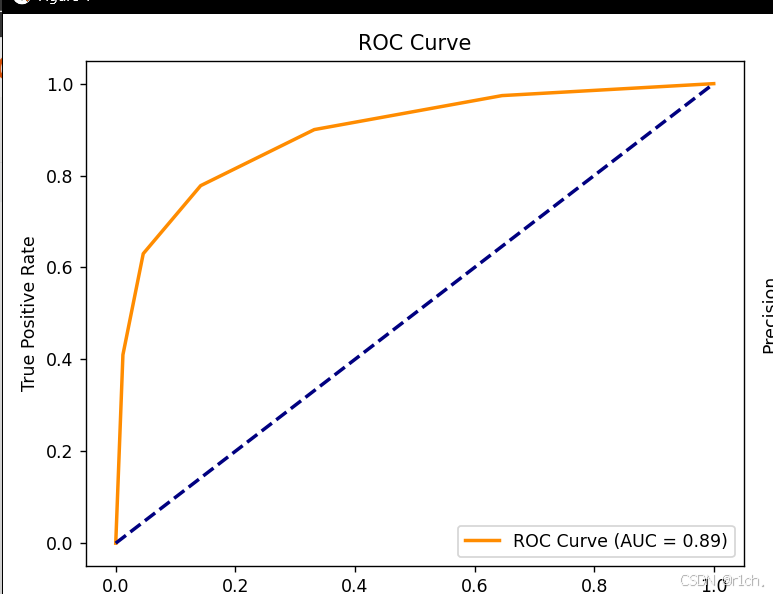
ROC(Receiver Operating Characteristic)曲线是一种评估二分类模型性能的可视化工具。通过动态调整分类阈值,ROC 曲线展示了模型在不同权衡下的真阳性率(TPR)和假阳性率(FPR)的变化情况。
横轴(FPR)
表示将负类错误判为正类的比例。
纵轴(TPR / 敏感度)
表示模型正确识别正类的比例。
1.ROC 曲线的构建方法
数据准备:获取模型对每个样本的预测概率(例如,逻辑回归输出)。
排序:将样本按预测概率从高到低排序。
动态阈值:依次以各样本的预测概率作为阈值,计算相应的 TP、FP、TN、FN,然后得到 TPR 和 FPR。
绘制曲线:将每个阈值对应的 (FPR,TPR)(\text{FPR}, \text{TPR})(FPR,TPR) 点连接起来,形成 ROC 曲线。
AUC 计算:通常采用梯形法(Trapezoidal Rule)计算 ROC 曲线下的面积,作为模型排序能力的量化指标。
代码如下:
# 计算ROC曲线
fpr, tpr, _ = roc_curve(y, y_scores)
roc_auc = roc_auc_score(y, y_scores)
# ROC曲线
plt.subplot(1, 2, 1)
plt.plot(fpr, tpr, color="darkorange", lw=2,
label=f"ROC Curve (AUC = {roc_auc:.2f})")
plt.plot([0, 1], [0, 1], color="navy", lw=2, linestyle="--")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve")
plt.legend(loc="lower right")ROC 曲线越靠近左上角,模型性能越好
2. AUC 的意义与解读
定义:AUC(Area Under the Curve)是 ROC 曲线下的面积,范围在 [0.5, 1]。
AUC = 0.5:模型表现等同随机猜测。
AUC = 1:完美分类器,所有正样本均排在负样本之前。AUC > 0.8:通常认为模型具有较好的区分能力。
统计解释:AUC 表示随机选择一个正样本和一个负样本时,正样本得分高于负样本的概率。例如,AUC=0.9 意味着有 90% 的概率正样本得分高于负样本。
应用:AUC 用于衡量模型整体的排序能力,并在模型选择时作为比较标准,但它不直接反映某个具体阈值下的性能。
3. ROC 曲线的优缺点
优点:
阈值无关性:综合评估所有可能的阈值,不局限于单个阈值的表现。
对样本比例不敏感:即使正负样本比例差异较大(如 1:100),ROC 曲线仍能较稳定地反映模型排序能力。
适用场景:适用于全局排序需求的场景,如广告推荐、金融风控等
缺点:
类别不平衡问题:在负样本极多时,FPR 的分母变大,FPR 变化可能不明显,导致 AUC 虚高,难以反映模型在正类识别上的不足。忽略精确率:ROC 曲线未直接体现精确率,而在某些应用中(例如法律判决),精确率至关重要。
四、PR 曲线的概念
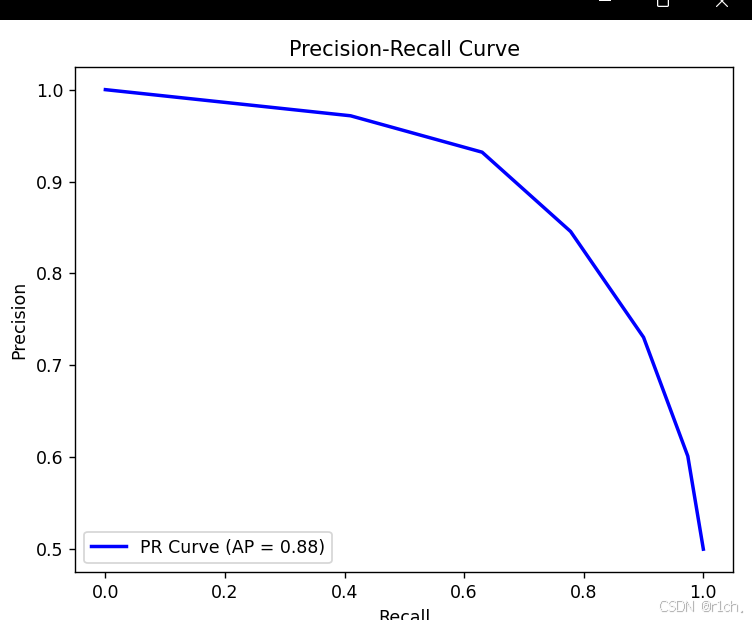
PR 曲线(Precision-Recall Curve)是评估二分类模型性能的一种重要工具,特别适用于正负样本极度不平衡的场景。它通过调整分类阈值,展示模型在不同权衡点下的**精确率(Precision)和召回率(Recall)**的变化情况,重点反映模型对正类样本的识别质量。
召回率(Recall)
含义:在所有真实正类样本中,被模型正确识别的比例,体现了模型捕捉正类样本的能力。
精确率(Precision)
含义:在所有被模型预测为正类的样本中,真实正类的比例,反映了模型预测结果的可靠性。
1.PR 曲线的构建方法
获取预测概率:
通过模型(例如逻辑回归、神经网络)获得每个样本预测为正类的概率值。
排序:
按预测概率从高到低对样本进行排序,以便依次考察不同阈值下的表现。
动态阈值设定:
依次将排序后的各个预测概率作为阈值。对于每个阈值,将预测值大于或等于该阈值的样本判定为正类,其余为负类。
计算指标:
针对每个阈值,统计对应的真阳性(TP)和假阳性(FP),进而计算精确率和召回率。
代码如下:
# 计算PR曲线
precision, recall, _ = precision_recall_curve(y, y_scores)
avg_precision = average_precision_score(y, y_scores)
# PR曲线
plt.subplot(1, 2, 2)
plt.plot(recall, precision, color="blue", lw=2,
label=f"PR Curve (AP = {avg_precision:.2f})")
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve")
plt.legend(loc="lower left")PR曲线越靠近右上角,模型性能越好
2.AUC-PR 的意义与解读
定义:当 AUC-PR 接近 1 时,说明模型在不同召回率下都能保持较高的精确率,即模型对正类的识别非常理想。
当 AUC-PR 接近正类的总体占比(例如 1%)时,则表明模型表现接近随机猜测。
AUC-PR 指的是 PR 曲线下方的面积,其取值范围为 [0,1]。
统计意义:
AUC-PR 反映了模型在各种召回率水平下维持高精确率的能力,尤其在正类样本稀少的情况下,这一指标对模型性能的区分更为敏感。
3.PR 曲线的优缺点
优点:
聚焦正类:直接反映模型对关键少数类的检测效果。
对类别不平衡敏感:在正类样本极少的情况下,能清晰展示精确率的下降趋势,帮助发现模型在识别正类时的不足。
缺点:
忽略负类信息:不涉及负类样本的区分能力(如特异度)。
阈值依赖性强:若业务需求要求在特定召回率或精确率下运行,则需要针对具体阈值进行详细分析。
4.PR曲线与ROC曲线的对比
| 特性 | PR曲线 | ROC曲线 |
| 核心指标 | Precision vs Recall | TPR (Recall) vs FPR |
| 数据敏感性 | 对类别不平衡敏感 | 对类别不平衡相对鲁棒 |
| 随机基线 | 水平线(Precision=正类占比) | 对角线(AUC=0.5) |
| 适用场景 | 正类稀少、关注误报成本 | 类别平衡、关注全局排序能力 |
| AUC解释 | 反映正类的精确-召回平衡 | 反映正负类的区分能力 |
五、代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_predict, StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import (
precision_recall_curve,
average_precision_score,
roc_curve,
roc_auc_score
)
# 生成随机数据(1000个样本,20个特征,二分类)
X, y = make_classification(
n_samples=1000,
n_features=20,
n_classes=2,
random_state=42
)
# 初始化KNN分类器
knn = KNeighborsClassifier(n_neighbors=5)
# 十折分层交叉验证(保持类别分布)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# 获取预测概率(使用交叉验证)
y_scores = cross_val_predict(
knn, X, y, cv=cv,
method="predict_proba", n_jobs=-1
)[:, 1] # 取正类的概率
# 计算ROC曲线
fpr, tpr, _ = roc_curve(y, y_scores)
roc_auc = roc_auc_score(y, y_scores)
# 计算PR曲线
precision, recall, _ = precision_recall_curve(y, y_scores)
avg_precision = average_precision_score(y, y_scores)
# 绘制图形
plt.figure(figsize=(12, 5))
# ROC曲线
plt.subplot(1, 2, 1)
plt.plot(fpr, tpr, color="darkorange", lw=2,
label=f"ROC Curve (AUC = {roc_auc:.2f})")
plt.plot([0, 1], [0, 1], color="navy", lw=2, linestyle="--")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve")
plt.legend(loc="lower right")
# PR曲线
plt.subplot(1, 2, 2)
plt.plot(recall, precision, color="blue", lw=2,
label=f"PR Curve (AP = {avg_precision:.2f})")
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve")
plt.legend(loc="lower left")
plt.tight_layout()
plt.show()
六、总结与建议
核心总结
ROC曲线与PR曲线的本质区别
ROC曲线:关注模型对正负样本的全局排序能力,通过TPR(召回率)与FPR的权衡,衡量模型区分正负类的能力。
PR曲线:聚焦正类样本的精准识别质量,通过精确率(Precision)与召回率(Recall)的平衡,评估模型对关键少数类的捕获能力。
关键指标的意义
AUC-ROC:模型对正负样本的排序能力(值越接近1,区分能力越强)。
AUC-PR:模型在召回正类时维持高精确率的能力(值越接近1,查全与查准的平衡越好)。
适用场景
| 场景特征 | 优先选择曲线 | 原因 |
| 类别平衡(正负各50%) | ROC曲线 | 全面反映整体排序能力 |
| 类别极度不平衡(正类<10%) | PR曲线 | 避免ROC虚高,直接暴露正类识别缺陷 |
| 业务关注误报成本(如法律判决) | PR曲线 | 精确率的微小变化直接影响业务结果 |
| 业务依赖排序(如推荐系统) | ROC曲线 | AUC-ROC直接反映推荐列表的优劣顺序 |
结语
ROC和PR曲线是模型评估的“双翼”,前者衡量全局排序能力,后者聚焦正类识别精度。理解其本质差异,结合业务需求灵活应用,方能避开评估陷阱,让模型真正赋能实际场景。记住:没有绝对的最优曲线,只有最适合业务目标的权衡点。

















 1782
1782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









