






文章目录
前言
基于Python和YoloV4的图片标注功能实现报告前言
随着计算机视觉技术的不断发展,目标检测成为许多实际应用的关键技术之一。在众多目标检测算法中,Yolo(You Only Look Once)系列以其出色的速度和精度受到了广泛关注。YoloV4作为该系列的最新成员,在继承了前代版本优点的基础上,进一步提升了检测性能,为实际应用提供了强大的支持。
本报告旨在通过Python和YoloV4实现一个简单的图片标注功能,以便对图像中的目标进行自动识别和标注。通过这一功能的实现,我们不仅能够更加高效地处理和分析图像数据,还能够为后续的图像识别、目标跟踪等任务提供有力的支持。
通过本报告的介绍和实践,相信读者能够对YoloV4算法有更深入的了解,并掌握使用Python和YoloV4实现图片标注功能的基本方法。
一、YOLO是什么?
在计算机视觉领域,YOLO(You Only Look Once)是一种基于深度学习的目标检测算法。这种算法由Joseph Redmon等人于2016年提出,相比于传统的目标检测算法,如R-CNN、Fast R-CNN和Faster R-CNN等,YOLO具有更快的检测速度和更高的准确率。它的核心思想是将目标检测问题转化为一个回归问题,即通过一个神经网络直接预测目标的类别和位置。。
二、使用步骤
1.环境准备
在开始跑代码前我们需要先检查是否安装了所有需要的库,对此我们可以从requirements.txt中使用以下代码进行安装
代码如下(示例):
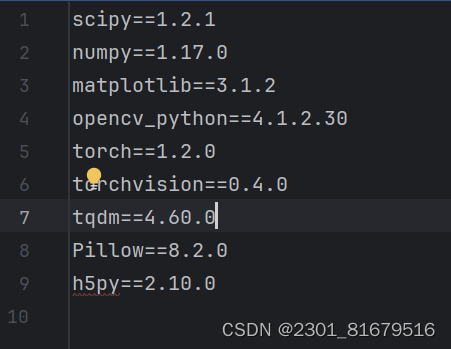
pip install -r requirements.txt 2.数据准备
关于数据集大家可以在网上自行查找并下载,我采用的数据集的链接放在这里给大家参考。
Animals 10 种动物图像数据集 / 数据集 / 超神经 (hyper.ai)
有了数据集后我们可以通过使用abellmg_exe来对我们的数据图像标记来得到标签数据。关于abellmg_exe的安装和使用我也将链接放在这里供大家参考查阅。
Windows下深度学习标注工具LabelImg安装和使用指南_windows安装labelimg-CSDN博客
3.训练数据
数据准备好后,我们就可以开始训练了,想要得到我们需要的权值文件我们需要对数据进行多次训练,我这由于电脑性能不行,就只训练了两次,下面的图片就是训练数据的截图:
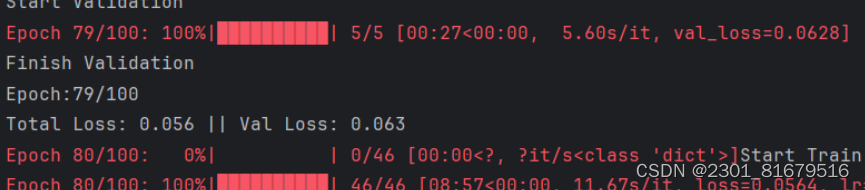
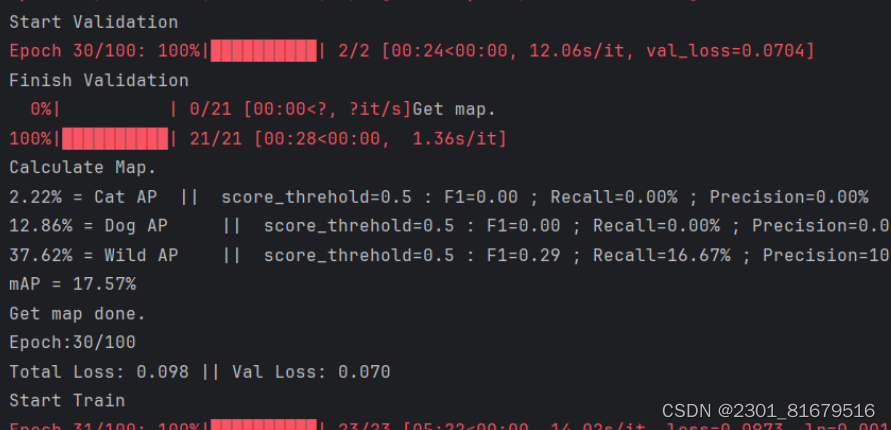
4.实验结果
以上步骤都完成之后我们便可以运行predict.py来进行最后的实验:
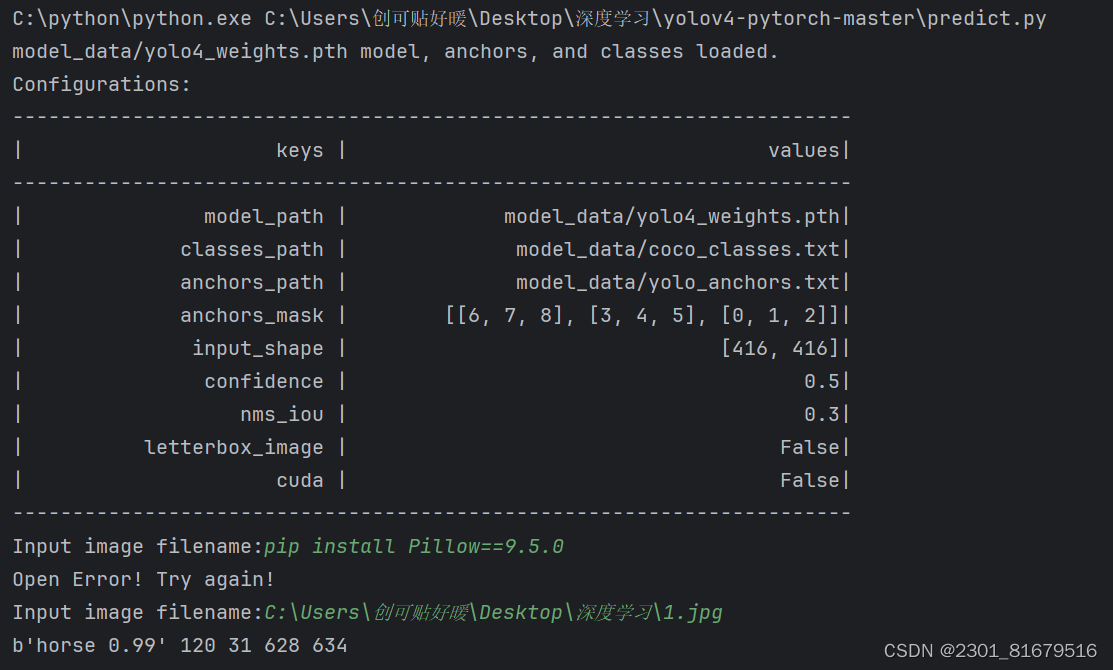

总结
以上就是今天分享的内容,本文仅仅简单介绍了YOLO的使用,希望可以给大家提供一点点帮助。















 2991
2991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









