







Linux下PCI设备驱动开发详解(六)
本章及其以后的几章,我们将通过PCI Express总线实现CPU和FPGA数据通信的简单框架,介绍linux PCI内核态设备驱动的实战开发(KMD)。
这个框架就是开源界非常有名的RIFFA(reuseable integration framework for FPGA accelerators),它是一个FPGA加速器的一种可重用性集成框架,是一个第三方开源PCIe框架。
该框架要求具备一个支持PCIe的工作站和一个带有PCIe连接器的FPGA板卡。RIFFA支持windows、linux,altera和xilinx,可以通过c/c++、python、matlab、java驱动来实现数据的发送和接收。驱动程序可以在linux或windows上运行,每一个系统最多支持5个FPGA device。
在用户端有独立的发送和接收端口,用户只需要编写几行简单代码即可实现和FPGA IP内核通信。
riffa使用直接存储器访问(DMA)传输和中断信号传输数据。这实现了PCIe链路上的高带宽,运行速率可以达到PCIe链路饱和点。
开源地址:https://github.com/KastnerRG/riffa
一、linux下PCI驱动结构
在《Linux下PCI设备驱动开发详解(四)》文章中,我们了解到,一般来说,用模块方式编写PCI设备驱动,通常至少要实现以下几个部分:初始化设备模块、设备打开模块、数据读写模块、中断处理模块、设备释放模块、设备卸载模块。
一般如下方式:
/* 指明该驱动程序适用于哪一些PCI设备 */
static struct pci_device_id demo = {
PCI_VENDOR_ID_DEMO,
PCI_DEVICE_ID_DEMO,
PCI_ANY_ID,
0,
0,
DEMO
};
/* 对特定PCI设备进行描述的数据结构 */
struct demo_card {
unsigned int magic;
/* 使用链表保存所有同类的PCI设备 */
struct demo_card *next;
...
};
/* 中断处理模块 */
static void demo_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
/* ... */
};
/* 设备文件操作接口 */
static struct file_operations demo_fops = {
owner: THIS_MODULE, /* demo_fops 所属的设备模块 */
read: demo_read, /* 读设备操作 */
write: demo_write, /* 写设备操作 */
ioctl: demo_ioctl, /* 控制设备操作 */
mmap:demo_mmap, /* 内存重映射操作 */
open:demo_open, /* 打开设备操作 */
release: demo_release /* 释放设备操作 */
/* ... */
};
/* 设备模块信息 */
static struct pci_driver demo_pci_driver = {
name: demo_MODULE_NAME, /* 设备模块名称 */
id_table:demo_pci_tbl, /* 能够驱动的设备列表 */
probe:demo_probe; /* 查找并初始化设备 */
remove:demo_remove /* 卸载设备模块 */
/* ... */
};
static int __init demo_init_module (void)
{
/* ... */
};
static void __exit demo_cleanup_module(void)
{
pci_unregister_driver(&demo_pci_driver);
}
/* 加载驱动程序模块入口 */
module_init(demo_init_nodule);
/* 卸载驱动程序模块入口 */
module_exit(demo_cleanup_module);
好的,带着这个框架我们进入到下面RIFFA框架的driver源代码分析。
二、初始化设备模块
我们直接给出源代码:
/**
* Called to initialize the PCI device.
*/
static int __init fpga_init(void)
{
int i;
int error;
/* 初始化host最大支持FPGA设备的个数 */
for (i = 0; i < NUM_FPGAS; i++)
atomic_set(&used_fpgas[i], 0);
/* 注册硬件驱动程序 */
error = pci_register_driver(&fpga_driver);
if (error != 0) {
printk(KERN_ERR "riffa: pci_module_register returned %d\n", error);
return (error);
}
/* 向内核注册一个字符设备(可选) */
error = register_chrdev(MAJOR_NUM, DEVICE_NAME, &fpga_fops);
if (error < 0) {
printk(KERN_ERR "riffa: register_chrdev returned %d\n", error);
return (error);
}
/* 向内核注册class */
#if LINUX_VERSION_CODE < KERNEL_VERSION(6, 4, 0)
mymodule_class = class_create(THIS_MODULE, DEVICE_NAME);
#else
mymodule_class = class_create(DEVICE_NAME);
#endif
if (IS_ERR(mymodule_class)) {
error = PTR_ERR(mymodule_class);
printk(KERN_ERR "riffa: class_create() returned %d\n", error);
return (error);
}
/* 创建设备文件节点 */
devt = MKDEV(MAJOR_NUM, 0);
device_create(mymodule_class, NULL, devt, "%s", DEVICE_NAME);
return 0;
}
OK,我们有看到了几个关键词,驱动程序、字符设备、class、文件节点。在《Linux下PCI设备驱动开发详解(三)》中,我们知道总线、设备、驱动模型:
系统启动后,会调用buses_init()函数创建/sys/bus文件目录,这部分系统在开机时已经帮我们准备好了。
接下去就是通过总线注册函数bus_register()进行总线注册(可选,一般不会注册新的总线),注册完成后,
在/sys/bus目录下生成device文件夹和driver文件夹,最后分别通过device_register()以及driver_register()函数注册对应的设备
和驱动。
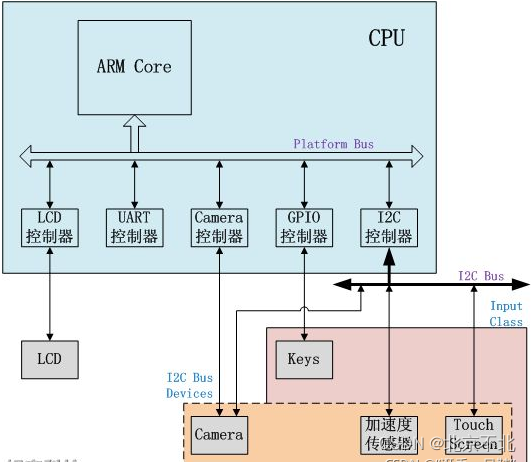
硬件拓扑描述linux设备模型中四个重要概念:
bus(总线):linux认为,总线是CPU和一个或多个设备之间信息交互的通道。而为了方便设备模型的抽象,所有设备都要连接到总线上。
class(分类):linux设备模型中,class的概念非常类似面向对象程序设计的class(类),它主要是集合具有类似功能或属性的设备,这样就可以抽象出一套可以在多个设备之间公用的数据结构和接口函数。
device(设备):抽象系统中所有的硬件设备,描述它的名字、属性、从属bus,从属class等信息。
driver(驱动):包括设备初始化、管理、read、write、销毁等接口实现。
三、probe探测硬件设备
/**
* probe设备
*/
static int __devinit fpga_probe(struct pci_dev *dev, const struct pci_device_id *id)
{
...
// Setup the PCIe device.
error = pci_enable_device(dev);
if (error < 0) {
printk(KERN_ERR "riffa: pci_enable_device returned %d\n", error);
return (-ENODEV);
}
// Enable bus master
pci_set_master(dev);
// Set the mask size
error = pci_set_dma_mask(dev, DMA_BIT_MASK(64));
if (!error)
error = pci_set_consistent_dma_mask(dev, DMA_BIT_MASK(64));
if (error) {
printk(KERN_ERR "riffa: cannot set 64 bit DMA mode\n");
pci_disable_device(dev);
return error;
}
// Allocate device structure.
sc = kzalloc(sizeof(*sc), GFP_KERNEL);
...
// Setup the BAR memory regions
error = pci_request_regions(dev, sc->name);
...
// PCI BAR 0
...
sc->bar0 = ioremap(sc->bar0_addr, sc->bar0_len);
...
// setup msi interrupts
error = pci_enable_msi(dev);
...
// Request an interrupt
error = request_irq(dev->irq, intrpt_handler, IRQF_SHARED, sc->name, sc);
// Set extended tag bit
error = pcie_capability_read_dword(dev,PCI_EXP_DEVCTL,&devctl_result);
...
error = pcie_capability_write_dword(dev,PCI_EXP_DEVCTL,(devctl_result|PCI_EXP_DEVCTL_EXT_TAG));
// Set IDO bits
...
error = pcie_capability_read_dword(dev,PCI_EXP_DEVCTL2,&devctl2_result);
error = pcie_capability_write_dword(dev,PCI_EXP_DEVCTL2,(devctl2_result | PCI_EXP_DEVCTL2_IDO_REQ_EN | PCI_EXP_DEVCTL2_IDO_CMP_EN));
// Set RCB to 128
error = pcie_capability_read_dword(dev,PCI_EXP_LNKCTL,&lnkctl_result);
...
error = pcie_capability_write_dword(dev,PCI_EXP_LNKCTL,(lnkctl_result|PCI_EXP_LNKCTL_RCB));
// Read device configuration
...
// Create chnl_dir structs.
sc->recv = (struct chnl_dir **) kzalloc(sc->num_chnls*sizeof(struct chnl_dir*), GFP_KERNEL);
sc->send = (struct chnl_dir **) kzalloc(sc->num_chnls*sizeof(struct chnl_dir*), GFP_KERNEL);
...
j = allocate_chnls(dev, sc);
// Create spill buffer (for overflow on receive).
sc->spill_buf_addr = pci_alloc_consistent(dev, SPILL_BUF_SIZE, &hw_addr);
sc->spill_buf_hw_addr = hw_addr;
// Save pointer to structure
...
}
这个fpga_probe函数非常重要和关键了:
1. pci_enable_device():把PCI配置空间的command域的bit0和bit1设置成1,从而达到开启设备的目的,即把config控制寄存器映射成IO/MEM空间。
2. pci_set_master():设置主总线为DMA模式。
3. pci_set_dma_mask():辅助函数用于检查总线是否可以接收给定大小的总线地址(mask),如果可以,则通知总线层给定外围设备将使用该大小的总线地址。
4. kzalloc():内核态的内存分配,struct fpga_state 保存device_id、vendor_id、bar空间、通道数、接收/发送通道的地址信息等。
5. pci_request_regions():该函数用于请求PCIe设备的IO资源。在probe函数中,驱动程序会调用pci_request_regions函数来请求设备的IO资源。
6. ioremap():此函数用于映射PCIe设备的IO空间到内核地址空间。在probe函数中,驱动程序会调用pci_iomap函数来映射设备的IO空间。
7. pci_enable_msi():它允许PCI设备使用MSI中断机制,当函数被调用时,它将被指定的PCI设备启用MSI中断,并返回中断号。
8. request_irq():注册中断服务函数,当中断发生时,系统调用这个函数。
9. pcie_capability_write_dword(..., ..., PCI_EXP_DEVCTL_EXT_TAG):PCI_EXP_DEVCTL_EXT_TAG,标识设备的DevCtl设置了ExtTag+,设置了这个标识位,读请求tlp中requester ID字段会扩展一个8位的tag,表示能暂存数据包的数量,但是需要FPGA PCIe设备支持,否则会出现数据溢出而丢包。
10. pcie_capability_write_dword(..., ..., PCI_EXP_DEVCTL2_IDO_REQ_EN):IDO标识位。
11. pcie_capability_write_dword(..., ..., PCI_EXP_LNKCTL_RCB):读完成边界,是 Completer 响应读请求的一种地址边界对齐策略,应用于 CplD,RC 的 RCB 可以为 64B 或 128B,默认 64 B;EP、Bridge、Switch 等其他设备的 RCB 只能为 128 B。
12. allocate_chnls():这个主要是通过pci_alloc_consistent申请dma的读/写multi-page内存,并形成sglist环形链表,并保存在fpga_state中,完成用户态多通道dma的读写请求。
四、写操作
基本的读写操作通过ioctl来调用对应的driver驱动的实现。我们补充一下,ioctl是设备驱动程序中设备控制接口函数,一个字符设备驱动通常会实现设备打开、关闭、读、写等功能,在一些需要细分的情境下,如果需要扩展新的功能,通常以增设 ioctl() 命令的方式实现。
直接给出代码:
static long fpga_ioctl(struct file *filp, unsigned int ioctlnum,
unsigned long ioctlparam)
{
int rc;
fpga_chnl_io io;
fpga_info_list list;
switch (ioctlnum) {
case IOCTL_SEND:
if ((rc = copy_from_user(&io, (void *)ioctlparam, sizeof(fpga_chnl_io)))) {
printk(KERN_ERR "riffa: cannot read ioctl user parameter.\n");
return rc;
}
if (io.id < 0 || io.id >= NUM_FPGAS || !atomic_read(&used_fpgas[io.id]))
return 0;
return chnl_send_wrapcheck(fpgas[io.id], io.chnl, io.data, io.len, io.offset,
io.last, io.timeout);
case IOCTL_RECV:
if ((rc = copy_from_user(&io, (void *)ioctlparam, sizeof(fpga_chnl_io)))) {
printk(KERN_ERR "riffa: cannot read ioctl user parameter.\n");
return rc;
}
if (io.id < 0 || io.id >= NUM_FPGAS || !atomic_read(&used_fpgas[io.id]))
return 0;
return chnl_recv_wrapcheck(fpgas[io.id], io.chnl, io.data, io.len, io.timeout);
case IOCTL_LIST:
list_fpgas(&list);
if ((rc = copy_to_user((void *)ioctlparam, &list, sizeof(fpga_info_list))))
printk(KERN_ERR "riffa: cannot write ioctl user parameter.\n");
return rc;
case IOCTL_RESET:
reset((int)ioctlparam);
break;
default:
return -ENOTTY;
break;
}
return 0;
}
在处理ioctl_send的时候,我们发现实现用户数据拷贝到内核态之后,调用了chnl_send_wrapcheck,将api层打包过来的参数一一传递过去。
直接给出chnl_send_wrapcheck():
static inline unsigned int chnl_send_wrapcheck(struct fpga_state * sc, int chnl,
const char __user * bufp, unsigned int len, unsigned int offset,
unsigned int last, unsigned long long timeout)
{
// Validate the parameters.
...
// Ensure no simultaneous operations from several threads
...
ret = chnl_send(sc, chnl, bufp, len, offset, last, timeout);
// Clear the busy flag
...
return ret;
}
这段代码主要做了一些避免错误的判断,值得一提的就是通过自旋锁避免了多线程错误的判断,其实我们可以知道riffa架构支持多线程,之后调用了chnl_send.
static inline unsigned int chnl_send(struct fpga_state * sc, int chnl,
const char __user * bufp, unsigned int len, unsigned int offset,
unsigned int last, unsigned long long timeout)
{
...
// Convert timeout to jiffies.
...
// Clear the message queue.
while (!pop_circ_queue(sc->send[chnl]->msgs, &msg_type, &msg));
// Initialize the sg_maps
sc->send[chnl]->sg_map_0 = NULL;
sc->send[chnl]->sg_map_1 = NULL;
// Let FPGA know about transfer.
DEBUG_MSG(KERN_INFO "riffa: fpga:%d chnl:%d, send (len:%d off:%d last:%d)\n", sc->id, chnl, len, offset, last);
write_reg(sc, CHNL_REG(chnl, RX_OFFLAST_REG_OFF), ((offset<<1) | last));
write_reg(sc, CHNL_REG(chnl, RX_LEN_REG_OFF), len);
if (len == 0)
return 0;
// Use the send common buffer to share the scatter gather data
sg_map = fill_sg_buf(sc, chnl, sc->send[chnl]->buf_addr, udata, length, 0, DMA_TO_DEVICE);
if (sg_map == NULL || sg_map->num_sg == 0)
return (unsigned int)(sent>>2);
// Update based on the sg_mapping
udata += sg_map->length;
length -= sg_map->length;
sc->send[chnl]->sg_map_1 = sg_map;
// Let FPGA know about the scatter gather buffer.
write_reg(sc, CHNL_REG(chnl, RX_SG_ADDR_LO_REG_OFF), (sc->send[chnl]->buf_hw_addr & 0xFFFFFFFF));
write_reg(sc, CHNL_REG(chnl, RX_SG_ADDR_HI_REG_OFF), ((sc->send[chnl]->buf_hw_addr>>32) & 0xFFFFFFFF));
write_reg(sc, CHNL_REG(chnl, RX_SG_LEN_REG_OFF), 4 * sg_map->num_sg);
DEBUG_MSG(KERN_INFO "riffa: fpga:%d chnl:%d, send sg buf populated, %d sent\n", sc->id, chnl, sg_map->num_sg);
// Continue until we get a message or timeout.
while (1) {
while ((nomsg = pop_circ_queue(sc->send[chnl]->msgs, &msg_type, &msg))) {
prepare_to_wait(&sc->send[chnl]->waitq, &wait, TASK_INTERRUPTIBLE);
// Another check before we schedule.
if ((nomsg = pop_circ_queue(sc->send[chnl]->msgs, &msg_type, &msg)))
tymeout = schedule_timeout(tymeout);
finish_wait(&sc->send[chnl]->waitq, &wait);
if (signal_pending(current)) {
free_sg_buf(sc, sc->send[chnl]->sg_map_0);
free_sg_buf(sc, sc->send[chnl]->sg_map_1);
return -ERESTARTSYS;
}
if (!nomsg)
break;
if (tymeout == 0) {
printk(KERN_ERR "riffa: fpga:%d chnl:%d, send timed out\n", sc->id, chnl);
free_sg_buf(sc, sc->send[chnl]->sg_map_0);
free_sg_buf(sc, sc->send[chnl]->sg_map_1);
return (unsigned int)(sent>>2);
}
}
tymeout = tymeouto;
// Process the message.
switch (msg_type) {
case EVENT_SG_BUF_READ:
// Release the previous scatter gather data?
if (sc->send[chnl]->sg_map_0 != NULL)
sent += sc->send[chnl]->sg_map_0->length;
free_sg_buf(sc, sc->send[chnl]->sg_map_0);
sc->send[chnl]->sg_map_0 = NULL;
// Populate the common buffer with more scatter gather data?
if (length > 0) {
sg_map = fill_sg_buf(sc, chnl, sc->send[chnl]->buf_addr, udata, length, 0, DMA_TO_DEVICE);
if (sg_map == NULL || sg_map->num_sg == 0) {
free_sg_buf(sc, sc->send[chnl]->sg_map_0);
free_sg_buf(sc, sc->send[chnl]->sg_map_1);
return (unsigned int)(sent>>2);
}
// Update based on the sg_mapping
udata += sg_map->length;
length -= sg_map->length;
sc->send[chnl]->sg_map_0 = sc->send[chnl]->sg_map_1;
sc->send[chnl]->sg_map_1 = sg_map;
write_reg(sc, CHNL_REG(chnl, RX_SG_ADDR_LO_REG_OFF), (sc->send[chnl]->buf_hw_addr & 0xFFFFFFFF));
write_reg(sc, CHNL_REG(chnl, RX_SG_ADDR_HI_REG_OFF), ((sc->send[chnl]->buf_hw_addr>>32) & 0xFFFFFFFF));
write_reg(sc, CHNL_REG(chnl, RX_SG_LEN_REG_OFF), 4 * sg_map->num_sg);
DEBUG_MSG(KERN_INFO "riffa: fpga:%d chnl:%d, send sg buf populated, %d sent\n", sc->id, chnl, sg_map->num_sg);
}
break;
case EVENT_TXN_DONE:
// Update with the true value of words transferred.
sent = (((unsigned long long)msg)<<2);
// Return as this is the end of the transaction.
free_sg_buf(sc, sc->send[chnl]->sg_map_0);
free_sg_buf(sc, sc->send[chnl]->sg_map_1);
DEBUG_MSG(KERN_INFO "riffa: fpga:%d chnl:%d, sent %d words\n", sc->id, chnl, (unsigned int)(sent>>2));
return (unsigned int)(sent>>2);
break;
default:
printk(KERN_ERR "riffa: fpga:%d chnl:%d, received unknown msg: %08x\n", sc->id, chnl, msg);
break;
}
}
return 0;
}
将数据写入指定的FPGA通道。除非配置了非零超时,否则将阻塞,直到所有数据都发送到 FPGA。如果超时不为零,则该函数将阻塞,直到发送所有数据或超时毫秒过去。来自 bufp 指针的用户数据将被发送,最多 len 字(每个字 == 32 位)。通道将被告知预期数据量和偏移量。如果 last == 1,则 FPGA 通道将在发送后将此事务识别为完成。如果 last == 0,则 FPGA 通道将需要额外的事务。
成功后,返回发送的字数。出错时,返回负值。
核心思想就是,初始化sg_maps,通过bar空间告知FPGA通道号、长度、大小等信息、使用通用buffer发送数据、更新sg_mapping,最后进入到while(1)的循环函数中。
while(1)大循环,只有当处理完Tx数据完成中断或出错时函数才会返回。在每一轮执行中,首先执行内嵌的小while,在小while中首先读取对应通道上的send消息队列,若返回值为0说明成功出队,小while运行一遍后就会执行下面的代码;若返回值为1说明队列可能是空的,也就是还没有中断到来,此时调用prepare_to_wait函数将本进程添加到等待队列里,然后执行schedule_timeout休眠该进程(有阻塞时间限制),此时在用户看来表现为ioctl函数阻塞等待,但中断还能在后台运行(中断也是一个进程)。
若此时驱动接收到一个该通道的Tx中断,那么在中断回调函数里将中断信息推入消息队列后就会唤醒chnl_send所在的进程。进程唤醒后调用finish_wait函数将本进程pop出等待队列并用signal_pending查看是否因信号而被唤醒,如果是 需要返回给用户并让其再次重试。如果不是被信号唤醒,则再去读一下消息队列,此时会将消息类型存入msg_type,消息存入msg中,然后退出小while。
接下来进入一个switch语句,这个switch是根据msg_type消息类型选择处理动作的,即中断处理的下半部。
若执行Tx SG读完成中断,则消息类型发送EVENT_SG_BUF_READ,数据填0,其实是没用的数据。在这里如果剩余长度大于0或者剩余溢出值大于0时就会重新执行上一段讲述的过程,即从上一次分配的结尾处再分配SG缓冲区,并发送SG链表给FPGA等等,不过一般不会发送这种情况,除非分配页时的get_user_pages函数锁定物理页出现了问题,少分了页才会出现这样的现象。
然后FPGA就会按SG链表一个一个SG缓存块的进行流式DMA传输,传输完毕后FPGA发送一个Tx数据读完成中断,即EVENT_TXN_DONE消息类型。这里比较好处理,调用dma_unmap_sg取消内存空间的SGDMA映射,然后释放掉页。
五、读操作
读操作和写操作类似,不再详细描述。
函数chnl_recv用于将FPGA发送的数据读到缓冲区内。
首先调用宏DEFINE_WAIT初始化等待队列项;然后把传入的参数timeout换算成毫秒,这个时间是最长阻塞时间。
剩下的就是中断处理过程,等待读完成。
六、销毁/卸载设备
释放设备模块主要是负责释放对设备的控制权,释放占用的内存和中断等,所做的事情正好和打开设备模块相反。
static void __exit fpga_exit(void)
{
device_destroy(mymodule_class, devt);
class_destroy(mymodule_class);
pci_unregister_driver(&fpga_driver);
unregister_chrdev(MAJOR_NUM, DEVICE_NAME);
}
本文从详细介绍了RIFFA框架的驱动模块,涉及的内容非常多,内核页面、中断处理等。
一个驱动的框架主要包括:初始化设备模块、设备打开模块、数据读写模块、中断处理模块、设备释放模块、设备卸载模块。
七、未完待续
Linux下PCI设备驱动开发详解(七),将详细分析一下RIFFA的环形通信队列,最大的好处就是不需要对后续的队列内容进行搬移,可以后续由入队(写入)覆盖。
八、参考资料
https://blog.csdn.net/mcupro/article/details/121526536
https://zhuanlan.zhihu.com/p/534098236
_exit fpga_exit(void)
{
device_destroy(mymodule_class, devt);
class_destroy(mymodule_class);
pci_unregister_driver(&fpga_driver);
unregister_chrdev(MAJOR_NUM, DEVICE_NAME);
}
本文从详细介绍了RIFFA框架的驱动模块,涉及的内容非常多,内核页面、中断处理等。
一个驱动的框架主要包括:初始化设备模块、设备打开模块、数据读写模块、中断处理模块、设备释放模块、设备卸载模块。
## 七、未完待续
Linux下PCI设备驱动开发详解(七),将详细分析一下RIFFA的环形通信队列,最大的好处就是不需要对后续的队列内容进行搬移,可以后续由入队(写入)覆盖。
## 八、参考资料
https://blog.csdn.net/mcupro/article/details/121526536
https://zhuanlan.zhihu.com/p/534098236
















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











