







 本文概述了机器学习平台的构建,强调了数据处理、建模和部署的重要性。数据处理涉及数据采集、存储和加工,包括对接、安全、网络瓶颈、网络爬虫和隐私保护。建模涵盖特征工程、试验、训练和评估模型。部署则关注模型在生产环境中的应用。文章还讨论了数据存储的可靠性、一致性、访问速度和版本控制,以及数据标记和样本数据的创建。此外,提到了在线教程和人工智能书籍资源,为学习者提供了指导。
本文概述了机器学习平台的构建,强调了数据处理、建模和部署的重要性。数据处理涉及数据采集、存储和加工,包括对接、安全、网络瓶颈、网络爬虫和隐私保护。建模涵盖特征工程、试验、训练和评估模型。部署则关注模型在生产环境中的应用。文章还讨论了数据存储的可靠性、一致性、访问速度和版本控制,以及数据标记和样本数据的创建。此外,提到了在线教程和人工智能书籍资源,为学习者提供了指导。
一、概述
下图是较简化的机器学习平台架构,概括了机器学习平台的主要功能和流程。本章会进行简要介绍,在功能章节再展开详述。机器学习最主要的三个步骤可概括为:数据处理、建模以及部署。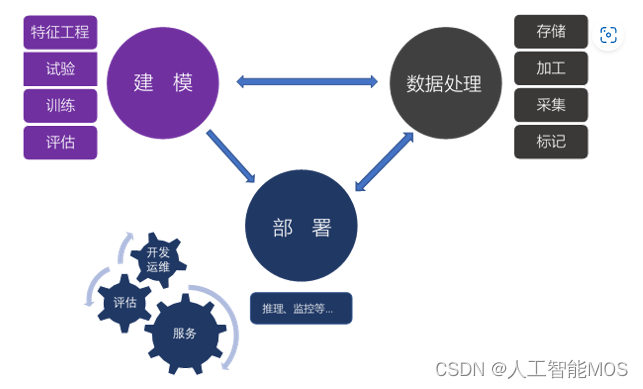
-
数据处理,即所有和数据相关的工作,包括存储、加工、采集和标记几大主要功能。前三者与大数据平台几乎一致,标记部分是机器学习平台所独有。数据存储较好理解,要根据存取的特点找到合适的存储系统。数据加工,也被称为ETL(Extract,Transform,Load),即将数据在不同的数据源间导入导出,并对数据进行聚合、变形、清洗等操作。数据采集,即从外部系统获得数据,包括通过网络爬虫来采集数据。数据标记,是将人类的知识附加到数据上,产生样本数据,以便训练出模型能对新数据推理预测。
-
建模,即创建模型的过程,包括特征工程、试验、训练及评估模型。特征工程,即通过数据科学家(也称为算法工程师)的知识来挖掘出数据更多的特征,将数据进行相应的转换后,作为模型的输入。试验,即尝试各种算法、网络结构及超参,来找到能够解决当前问题的最好的模型。模型训练,主要是平台的计算过程,好的平台能够有效利用计算资源,提高生产力并节省成本。
-
部署,是将模型部署到生产环境中进行推理应用,真正发挥模型的价值。部署这个词本身,可以仅仅代表将模型拷贝到生产环境中。但计算机软件的多年发展证明,提供一个好的服务需要考虑多种因素,并通过不断迭代演进,解决遇到的各种新问题,从而保持在较高的服务水平。
-
对平台的通用要求,如扩展能力,运维支持,易用性,安全性等方面。由于机器学习从研究到生产应用都还处于快速发展变化的阶段,所以框架、硬件、业务上灵活的扩展能力显得非常重要。任何团队都需要或多或少的运维工作,出色的运维能力能帮助团队有效的管理服务质量,提升生产效率。易用性对于小团队上手、大团队中新人学习都非常有价值,良好的用户界面也有利于深入理解数据的意义。安全性则是任何软件产品的重中之重,安全漏洞是悬在团队头上一把剑,不能依靠运气来逃避问题。
这里,不得不再分辨一下人工智能、机器学习、深度学习的含义,以便文中出现时,读者不会混淆。
-
人工智能,是人们最常听到的说法。在不需要严谨表达时,一般都可以用这个词来表达一些不同以往的"智能"应用。而实际上,程序员写的每一行逻辑代码都是"人工智能",每一个软件都饱含了"人工智能",不是"人类智能"。如果要严谨的表达,"人工智能"和"软件"并没有什么区别,也不表达什么意义深刻的"智能"革新产品。
但如果遵循普适的理解,那么"人工智能"一定是得有一些新奇的、超越以往的"人工智能"的东西,才能配得上这个词。比如,以往计算器(注意,不是计算机,是加减乘除的计算器)刚出现时,它就是新奇的事物,超越了人类的认知。在那个时刻,"计算器"就代表了"人工智能"的最高水平,是当之无愧的"人工智能"产品。
那么,什么时候适合用"人工智能"这个词汇呢?如果别人在用这个词汇说明什么,那就跟着用就好了,不必过于严谨。如果觉得有什么超越以往的"智能"的事物,那就用"人工智能"来介绍它。放之当下(2018年),图像中识别出物体、语音中识别出文本、自动驾驶等等就可以称为"人工智能"了(本文也没少用)。但电灯能感应到人后自动点亮,就不足以说是"人工智能"了。
-
机器学习。这是专业词汇,表达的是具有"学习"能力的软硬件产品,与程序员写就的代码相区别。可以认为,机器学习模型是一个函数,有输入输出,它的逻辑是数据驱动的,核心逻辑在数据中,不在代码中。
机器学习的"学习过程",如果也用函数来类比,那么就是首先给模型传入输入,获得输出。然后将模型的输出与期望的输出(即样本数据中的标记结果)进行比较。并根据比较结果来更新模型中的数据,以便下一次的模型输出能够与期望结果更接近。这个过程,和人学习时的题海战术很类似。
由此看出,机器学习的学习过程是机器直接学习规律,改进数据,逐渐形成逻辑。而不是先有人类学习规律后,再写成代码。故称之为"机器学习"。
-
深度学习。这是机器学习的子领域,但带来了非常大的变革,因此成为了流行的词汇。从字面上解释,所谓深度学习,即在机器学习时,数据组织成了多层次的、有"深度"的网络。传统成功的机器学习算法一般是三层,而深度学习能够实现多达上千层的网络。层次越多,可以认为机器学习模型就能越"聪明",越有"智能"。
深度学习成功的解决了大量和人类认知相关的问题,如:图像中识别物体、物体位置、人脸,语音中更精确的识别文字,文字中翻译、理解含义等。一方面,将机器学习模型的效果大大提升,另一方面,反而降低了机器学习模型应用的难度,让更多的人能够参与进来。最近的一次"人工智能"热潮,也是深度学习所带来的。
二、功能
机器学习平台上最重要的三个功能为:数据处理、建模、部署(也可称为推理)。每一个都可自成体系,成为一个独立的平台。本章从功能角度来描述机器学习平台,给读者以完整的认识。在不同的使用场景下,只需要部分功能,可删可减,不需要面面俱到。
比如,采用预构建的人工智能云服务时,在建模、部署上并不需要投入,主要精力会在数据处理上。再比如,对于以研究为主的团队来说,利用公开数据集进行模型评估等工作,不需要数据处理,也不需要部署。甚至对于个人研究者,强大的平台也不是必须的,手工作坊就能满足需求。
再比如,团队需要比较强大的平台。虽然说工欲善其事必先利其器,但是,常常是业务需求生死攸关的情况,相比之下提升平台从而提高生产力的工作,还没到不做不可的时候。这时候,平台的功能如果不能产生立竿见影、显著的成效,可以缓一缓,先实现投入产出较高的功能,待以后再增量开发或重构。如何很好的平衡开发投入,是艺术也是持续的话题,这里就不展开了。
在建设平台时,要注意合理利用现有的成果。比如,一些在发展初期的平台,其实已经解决了核心需求,可以直接拿来用。还有一些大数据平台,通过改造也能很好的解决机器学习的计算问题。再不济,多使用开源的小模块,在系统中减少一些重复开发的工作。
总之,平台对服务稳定性、时效性、生产力、成本等各方面有很大的价值,但建设平台不是一朝一夕的事情,也没有一个平台能满足各种需求。比如关系型数据库经过了多年的成熟发展,除了流行的几种数据库外,也不断的有满足新需求的新数据库出现。如,理论容量无限的分布式关系数据库,还有不少大企业根据自己的应用情况开发的高性能数据库系统,以及兴起的各种NoSQL数据库。在使用数据库时,不少团队会组合多种数据库来满足需求。在建设机器学习平台时也如此,除了用已有的平台外,可能还需要自己搭建一些周边的支持系统。
数据
机器学习的本质即通过数据来理解信息,掌握知识。因此,数据是机器学习的知识来源,没有数据,计算机就无处学习知识,巧妇难做无米之炊。绝大部分机器学习系统需要样本数据,并从而进行学习。对于Alpha go这样的强化学习系统,数据全部从规则中生成,则不需要外部的数据。自动驾驶虽然也涉及到强化学习的部分,却需要与实际环境交互的数据,数据的收集难度就更高了。
人类文明早期就开始了数据的利用。结绳记事的信息中,就有相当一部分是产量等数据信息。前些年流行的大数据系统更是将数据的作用进一步发挥出来,并产生了丰富、成熟的分布式存储系统、数据加工流程、数据采集等平台和工具。机器学习平台可直接重用这些大数据平台中的工具。数据标记是机器学习特有的数据需求,数据标记就是在数据上加上人类知识,形成样本数据的过程。
数据的建设上要根据需求来定。如,强化学习不需要数据采集系统;小数据量的业务也不需要强大的分布式存储系统;企业数据已经有了强大的数据加工能力,尽量不要再建立新的数据加工流水线。
数据采集
数据采集,即将系统外部的数据导入到机器学习平台中。包括企业内部的数据导入,企业间的数据交换,以及通过网络爬虫抓取数据等。
对接
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









