






大家好,小编为大家解答python不同版本有什么区别的问题。很多人还不知道python3各个版本的区别,现在让我们一起来看看吧!
http://blog.csdn.net/pipisorry/article/details/42167987
应该学习哪个版本的Python?
对于这个问题,“先选择一个最适合你的Python教程,教程中使用哪个版本的Python,你就用那个版本。等学得差不多了,再来研究不同版本之间的差别".
但如果想要用Python开发一个新项目,那么该如何选择Python版本呢?大部分Python库都同时支持Python 2.7.x和3.x版本的python流星雨特效代码。Python 2.7将被支持到2020年,但是许多新的特性将不支持向后兼容。目前,如果你还不能完全放弃Python 2, 那最好使用Python 2.7 和 3+兼容的特性。对于两个版本支持特性的全面指引,可以在python.org上看Porting Python 2 Code 。
python3比较新, 改动大,但我还是倾向于使用"在趋势中将会越来越火"的版本, 而非"目前已经很稳定而且很成熟"的版本。但是如果Python3无法像Python2那么火, 那么整个Python语言就不可避免的随着时间的推移越来越落后, 因此我想其实选哪个的最坏风险都一样, 但是最好回报却是Python3的大. 其实两者区别也可以说大也可以说不大, 最终都不是什么大问题. 如果你喜欢python,请选择Python 3,这样这门语言才会走得更远。小编推荐python3.x,还因为目前python3已基本兼容大部分python库,不兼容的估计就是没多少人用的,应该可以找到替代。
但是,不管怎样为了在使用Python时避开某些版本中一些常见的陷阱,或需要移植某个Python项目时,依然有必要了解一下Python两个常见版本之间的主要区别。并且,系统中两个不同的python版本是可以共存的[python虚拟环境配置 - windows下多个python版本共存]
python2和python3的区别
1.性能
Py3.0运行 pystone benchmark的速度比Py2.5慢30%。Guido认为Py3.0有极大的优化空间,在字符串和整形操作上可以取得很好的优化结果。
Py3.1性能比Py2.5慢15%,还有很大的提升空间。
2.编码
Py3.X源码文件默认使用utf-8编码,这就使得以下代码是合法的:
>>> 中国 = 'china'
>>>print(中国)
china
3. 语法
1)去除了<>,全部改用!=
在Python 2里,为了得到一个任意对象的字符串表示,有一种把对象包装在反引号里(比如`x`)的特殊语法。在Python 3里,这种能力仍然存在,但是你不能再使用反引号获得这种字符串表示了。你需要使用全局函数repr()。
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | `x` | repr(x) |
| ② | `'PapayaWhip' + `2`` | repr('PapayaWhip'+ repr(2)) |
Note:x可以是任何东西 — 一个类,函数,模块,基本数据类型,等等。repr()函数可以使用任何类型的参数。
2)去除``,全部改用repr()
3)关键词加入as 和with,还有True,False,None
4)除法:[python除法]
5)加入nonlocal语句。使用noclocal x可以直接指派外围(非全局)变量
6)print
去除print语句,加入print()函数实现相同的功能。同样的还有 exec语句,已经改为exec()函数
在Python 2里,print是一个语句。无论你想输出什么,只要将它们放在print关键字后边就可以。
Python 3里,print()是一个函数。就像其他的函数一样,print()需要你将想要输出的东西作为参数传给它。
例如:
2.X: print "The answer is", 2*2
3.X: print("The answer is", 2*2)
2.X: print x, # 使用逗号结尾禁止换行
3.X: print(x, end=" ") # 使用空格代替换行
在Python 2里,如果你使用一个逗号(,)作为print语句的结尾,它将会用空格分隔输出的结果,然后在输出一个尾随的空格(trailing space),而不输出回车(carriage return)。在Python 3里,通过把end=' '作为一个关键字参数传给print()可以实现同样的效果。参数end的默认值为'\n',所以通过重新指定end参数的值,可以取消在末尾输出回车符。
2.X: print # 输出新行
3.X: print() # 输出新行
2.X: print >>sys.stderr, "fatal error"
3.X: print("fatal error", file=sys.stderr)
在Python 2里,你可以通过使用>>pipe_name语法,把输出重定向到一个管道,比如sys.stderr。在Python 3里,你可以通过将管道作为关键字参数file的值传递给print()来完成同样的功能。参数file的默认值为std.stdout,所以重新指定它的值将会使print()输出到一个另外一个管道。
2.X: print (x, y) # 输出repr((x, y))
3.X: print((x, y)) # 不同于print(x, y)!
exec语句
exec()函数使用一个包含任意Python代码的字符串作为参数,然后就像执行语句或者表达式一样执行它。exec()跟eval()是相似的,但是exec()更加强大并更具有技巧性。eval()函数只能执行单独一条表达式,但是exec()
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | exec codeString | exec(codeString) |
| ② | exec codeString in a_global_namespace | exec(codeString, a_global_namespace) |
| ③ | exec codeString in a_global_namespace, a_local_namespace | exec(codeString, a_global_namespace, a_local_namespace) |
- 在最简单的形式下,因为
exec()现在是一个函数,而不是语句,2to3会把这个字符串形式的代码用括号围起来。 - Python 2里的
exec语句可以指定名字空间,代码将在这个由全局对象组成的私有空间里执行。Python 3也有这样的功能;你只需要把这个名字空间作为第二个参数传递给exec()函数。 - 更加神奇的是,Python 2里的
exec语句还可以指定一个本地名字空间(比如一个函数里声明的变量)。在Python 3里,exec()函数也有这样的功能。
execfile语句
就像以前的exec语句,Python 2里的execfile语句也可以像执行Python代码那样使用字符串。不同的是exec使用字符串,而execfile则使用文件。在Python 3里,execfile语句已经被去掉了。如果你真的想要执行一个文件里的Python代码(但是你不想导入它),你可以通过打开这个文件,读取它的内容,然后调用compile()全局函数强制Python解释器编译代码,然后调用新的exec()函数。
| Notes | Python 2 | Python 3 |
|---|---|---|
execfile('a_filename') | exec(compile(open('a_filename').read(),'a_filename','exec')) |
7)输入函数改变了,删除了raw_input,用input代替: Python 2有两个全局函数,用来在命令行请求用户输入。第一个叫做input(),它等待用户输入一个Python表达式(然后返回结果)。第二个叫做raw_input(),用户输入什么它就返回什么。这让初学者非常困惑,并且这被广泛地看作是Python语言的一个“肉赘”(wart)。Python 3通过重命名raw_input()为input(),从而切掉了这个肉赘,所以现在的input()就像每个人最初期待的那样工作。
2.X:guess = int(raw_input('Enter an integer : ')) # 读取键盘输入的方法
3.X:guess = int(input('Enter an integer : '))
Note:如果你真的想要请求用户输入一个Python表达式,计算结果,可以通过调用input()函数然后把返回值传递给eval()。
I/O方法xreadlines()
在Python 2里,文件对象有一个xreadlines()方法,它返回一个迭代器,一次读取文件的一行。这在for循环中尤其有用。事实上,后来的Python 2版本给文件对象本身添加了这样的功能。
在Python 3里,xreadlines()方法不再可用了。2to3可以解决简单的情况,但是一些边缘案例则需要人工介入。
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | for line in a_file.xreadlines(): | for line in a_file: |
| ② | for line in a_file.xreadlines(5): | no change (broken) |
- 如果你以前调用没有参数的xreadlines(),2to3会把它转换成文件对象本身。在Python 3里,这种转换后的代码可以完成前同样的工作:一次读取文件的一行,然后执行for循环的循环体。
- 如果你以前使用一个参数(每次读取的行数)调用xreadlines(),2to3不能为你完成从Python 2到Python 3的转换,你的代码会以这样的方式失败:AttributeError: '_io.TextIOWrapper' object has no attribute 'xreadlines'。你可以手工的把xreadlines()改成readlines()以使代码能在Python 3下工作。(readline()方法在Python 3里返回迭代器,所以它跟Python 2里的xreadlines()效率是不相上下的。)
8)改变了顺序操作符的行为,例如x<y,当x和y类型不匹配时抛出TypeError而不是返回随即的 bool值
9)去除元组参数解包。不能def(a, (b, c)):pass这样定义函数了
10)新式的8进制字变量,相应地修改了oct()函数。
2.X的方式如下:
>>> 0666
438
>>> oct(438)
'0666'
3.X这样:
>>> 0666
SyntaxError: invalid token (<pyshell#63>, line 1)
>>> 0o666
438
>>> oct(438)
'0o666'
11)增加了 2进制字面量和bin()函数
>>> bin(438)
'0b110110110'
>>> _438 = '0b110110110'
>>> _438
'0b110110110'
12)扩展的可迭代解包。在Py3.X 里,a, b, *rest = seq和 *rest, a = seq都是合法的,只要求两点:rest是list对象和seq是可迭代的。
13)新的super(),可以不再给super()传参数,
>>> class C(object):
def __init__(self, a):
print('C', a)
>>> class D(C):
def __init(self, a):
super().__init__(a) # 无参数调用super()
>>> D(8)
C 8
<__main__.D object at 0x00D7ED90>
14)支持class decorator。用法与函数decorator一样:
>>> def foo(cls_a):
def print_func(self):
print('Hello, world!')
cls_a.print = print_func
return cls_a
>>> @foo
class C(object):
pass
>>> C().print()
Hello, world!
class decorator可以用来玩玩狸猫换太子的大把戏。更多请参阅PEP 3129
4. 字符串和字节串
Python 2有两种字符串类型:Unicode字符串和非Unicode字符串。Python 2有基于ASCII的str()类型,其可通过单独的unicode()函数转成unicode类型,但没有byte类型。
而在Python 3中,终于有了Unicode(utf-8)字符串,以及两个字节类:bytes和bytearrays。Python 3只有一种类型:Unicode字符串(Unicode strings)。只有str一种类型,但它跟2.x版本的unicode几乎一样。
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | u'PapayaWhip' | 'PapayaWhip' |
| ② | ur'PapayaWhip\foo' | r'PapayaWhip\foo' |
- Python 2里的Unicode字符串在Python 3里即普通字符串,因为在Python 3里字符串总是Unicode形式的。
- Unicode原始字符串(raw string)(使用这种字符串,Python不会自动转义反斜线"\")也被替换为普通的字符串,因为在Python 3里,所有原始字符串都是以Unicode编码的。
全局函数unicode()
Python 2有两个全局函数可以把对象强制转换成字符串:unicode()把对象转换成Unicode字符串,还有str()把对象转换为非Unicode字符串。
Python 3只有一种字符串类型,Unicode字符串,所以str()函数即可完成所有的功能。(unicode()函数在Python 3里不再存在了。)
| Notes | Python 2 | Python 3 |
|---|---|---|
unicode(anything) | str(anything) |
5.数据类型
1)Python 2有为非浮点数准备的int和long类型。int类型的最大值不能超过sys.maxint,而且这个最大值是平台相关的。可以通过在数字的末尾附上一个L来定义长整型,显然,它比int类型表示的数字范围更大。
在Python 3里,只有一种整数类型int,大多数情况下,它很像Python 2里的长整型。
Note:检查一个变量是否是整型,获得它的数据类型,并与一个int类型(不是long)的作比较。你也可以使用isinstance()函数来检查数据类型;再强调一次,使用int,而不是long,来检查整数类型。
sys.maxint
由于长整型和整型被整合在一起了,sys.maxint常量不再精确。但是因为这个值对于检测特定平台的能力还是有用处的,所以它被Python 3保留,并且重命名为sys.maxsize。
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | from sys import maxint | from sys import maxsize |
| ② | a_function(sys.maxint) | a_function(sys.maxsize) |
2)新增了bytes类型,对应于2.X版本的八位串,定义一个bytes字面量的方法如下:
>>> b = b'china'
>>> type(b)
<type 'bytes'>
str对象和bytes对象可以使用.encode() (str -> bytes) or .decode() (bytes -> str)方法相互转化。
>>> s = b.decode()
>>> s
'china'
>>> b1 = s.encode()
>>> b1
b'china'
3)types模块中的常量
types模块里各种各样的常量能帮助你决定一个对象的类型。在Python 2里,它包含了代表所有基本数据类型的常量,如dict和int。在Python 3里,这些常量被已经取消了。只需要使用基础类型的名字来替代。
| Notes | Python 2 | Python 3 |
|---|---|---|
types.UnicodeType | str | |
types.StringType | bytes | |
types.DictType | dict | |
types.IntType | int | |
types.LongType | int | |
types.ListType | list | |
types.NoneType | type(None) | |
types.BooleanType | bool | |
types.BufferType | memoryview | |
types.ClassType | type | |
types.ComplexType | complex | |
types.EllipsisType | type(Ellipsis) | |
types.FloatType | float | |
types.ObjectType | object | |
types.NotImplementedType | type(NotImplemented) | |
types.SliceType | slice | |
types.TupleType | tuple | |
types.TypeType | type | |
types.XRangeType | range |
☞
types.StringType被映射为bytes,而非str,因为Python 2里的“string”(非Unicode编码的字符串,即普通字符串)事实上只是一些使用某种字符编码的字节序列(a sequence of bytes)。
4)dict的.keys()、.items 和.values()方法返回迭代器,而之前的iterkeys()等函数都被废弃。同时去掉的还有dict.has_key(),用 in替代它吧
6.函数/方法
lambda函数:使用元组而非多个参数的lambda函数
在Python 2里,你可以定义匿名lambda函数(anonymous lambda function),通过指定作为参数的元组的元素个数,使这个函数实际上能够接收多个参数。事实上,Python 2的解释器把这个元组“解开”(unpack)成命名参数(named arguments),然后你可以在lambda函数里引用它们(通过名字)。在Python 3里,你仍然可以传递一个元组作为lambda函数的参数,但是Python解释器不会把它解析成命名参数。你需要通过位置索引(positional index)来引用每个参数。
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | lambda (x,): x+ f(x) | lambda x1: x1[0]+ f(x1[0]) |
| ② | lambda (x, y): x+ f(y) | lambda x_y: x_y[0]+ f(x_y[1]) |
| ③ | lambda (x,(y, z)): x+ y+ z | lambda x_y_z: x_y_z[0]+ x_y_z[1][0]+ x_y_z[1][1] |
| ④ | lambda x, y, z: x+ y + z | unchanged |
- 如果你已经定义了一个lambda函数,它使用包含一个元素的元组作为参数,在Python 3里,它会被转换成一个包含到x1[0]的引用的lambda函数。x1是2to3脚本基于原来元组里的命名参数自动生成的。
- 使用含有两个元素的元组(x, y)作为参数的lambda函数被转换为x_y,它有两个位置参数,即x_y[0]和x_y[1]。
- 2to3脚本甚至可以处理使用嵌套命名参数的元组作为参数的lambda函数。产生的结果代码有点难以阅读,但是它在Python 3下跟原来的代码在Python 2下的效果是一样的。
- 你可以定义使用多个参数的lambda函数。如果没有括号包围在参数周围,Python 2会把它当作一个包含多个参数的lambda函数;在这个lambda函数体里,你通过名字引用这些参数,就像在其他类型的函数里所做的一样。这种语法在Python 3里仍然有效。
函数属性func_*
在Python 2里,函数的里的代码可以访问到函数本身的特殊属性。在Python 3里,为了一致性,这些特殊属性被重新命名了。
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | a_function.func_name | a_function.__name__ |
| ② | a_function.func_doc | a_function.__doc__ |
| ③ | a_function.func_defaults | a_function.__defaults__ |
| ④ | a_function.func_dict | a_function.__dict__ |
| ⑤ | a_function.func_closure | a_function.__closure__ |
| ⑥ | a_function.func_globals | a_function.__globals__ |
| ⑦ | a_function.func_code | a_function.__code__ |
- __name__属性(原func_name)包含了函数的名字。
- __doc__属性(原funcdoc)包含了你在函数源代码里定义的文档字符串(docstring)
- __defaults__属性(原func_defaults)是一个保存参数默认值的元组。
- __dict__属性(原func_dict)是一个支持任意函数属性的名字空间。
- __closure__属性(原func_closure)是一个由cell对象组成的元组,它包含了函数对自由变量(free variable)的绑定。
- __globals__属性(原func_globals)是一个对模块全局名字空间的引用,函数本身在这个名字空间里被定义。
- __code__属性(原func_code)是一个代码对象,表示编译后的函数体。
特殊的方法属性
在Python 2里,类方法可以访问到定义他们的类对象(class object),也能访问方法对象(method object)本身。im_self是类的实例对象;im_func是函数对象,im_class是类本身。在Python 3里,这些属性被重新命名,以遵循其他属性的命名约定。
| Notes | Python 2 | Python 3 |
|---|---|---|
aClassInstance.aClassMethod.im_func | aClassInstance.aClassMethod.__func__ | |
aClassInstance.aClassMethod.im_self | aClassInstance.aClassMethod.__self__ | |
aClassInstance.aClassMethod.im_class | aClassInstance.aClassMethod.__self__.__class__ |
__nonzero__特殊方法
在Python 2里,你可以创建自己的类,并使他们能够在布尔上下文(boolean context)中使用。举例来说,你可以实例化这个类,并把这个实例对象用在一个if语句中。为了实现这个目的,你定义一个特别的__nonzero__()方法,它的返回值为True或者False,当实例对象处在布尔上下文中的时候这个方法就会被调用 。在Python 3里,你仍然可以完成同样的功能,但是这个特殊方法的名字变成了__bool__()。
当在布尔上下文使用一个类对象时,Python 3会调用__bool__(),而非__nonzero__()。
然而,如果你有定义了一个使用两个参数的__nonzero__()方法,2to3脚本会假设你定义的这个方法有其他用处,因此不会对代码做修改。
7.面向对象
1)引入抽象基类(Abstraact Base Classes,ABCs)。
2)容器类和迭代器类被ABCs化,所以cellections模块里的类型比Py2.5多了很多。另外,数值类型也被ABCs化。关于这两点,请参阅 PEP 3119和PEP 3141。
3)迭代器的next()方法改名为__next__(),并增加内置函数next(),用以调用迭代器的__next__()方法
4)增加了@abstractmethod和 @abstractproperty两个 decorator,编写抽象方法(属性)更加方便。
5)在Python 2里,你可以通过在类的声明中定义metaclass参数,或者定义一个特殊的类级别的(class-level)__metaclass__属性,来创建元类。在Python 3里,__metaclass__属性已经被取消了。
Python 2 Python 3
| ① | | unchanged |
|---|---|---|
| ② | | |
| ③ | | |
Note:2to3能够构建一个有效的类声明,即使这个类继承自多个父类。
8.异常处理
9.模块变动
从Python 2到Python 3,标准库里的一些模块已经被重命名了。还有一些相互关联的模块也被组合或者重新组织,以使得这种关联更有逻辑性。
1)移除了cPickle模块,可以使用pickle模块代替。最终我们将会有一个透明高效的模块。
2)移除了imageop模块
3)移除了 audiodev, Bastion, bsddb185, exceptions, linuxaudiodev, md5, MimeWriter, mimify, popen2, rexec, sets, sha, stringold, strop, sunaudiodev, timing和xmllib模块
4)移除了bsddb模块(单独发布,可以从http://www.jcea.es/programacion/pybsddb.htm获取)
5)移除了new模块
6)os.tmpnam()和os.tmpfile()函数被移动到tmpfile模块下
7)tokenize模块现在使用bytes工作。主要的入口点不再是generate_tokens,而是 tokenize.tokenize()
8)http
在Python 3里,几个相关的HTTP模块被组合成一个单独的包,即http。
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | import httplib | import http.client |
| ② | import Cookie | import http.cookies |
| ③ | import cookielib | import http.cookiejar |
| ④ | import BaseHTTPServer import SimpleHTTPServer import CGIHttpServer | import http.server |
http.client模块实现了一个底层的库,可以用来请求HTTP资源,解析HTTP响应。http.cookies模块提供一个蟒样的(Pythonic)接口来获取通过HTTP头部(HTTP header)Set-Cookie发送的cookies- 常用的流行的浏览器会把cookies以文件形式存放在磁盘上,
http.cookiejar模块可以操作这些文件。 http.server模块实现了一个基本的HTTP服务器
9)urllib
Python 2有一些用来分析,编码和获取URL的模块,但是这些模块就像老鼠窝一样相互重叠。在Python 3里,这些模块被重构、组合成了一个单独的包,即urllib。
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | import urllib | import urllib.request, urllib.parse, urllib.error |
| ② | import urllib2 | import urllib.request, urllib.error |
| ③ | import urlparse | import urllib.parse |
| ④ | import robotparser | import urllib.robotparser |
| ⑤ | from urllib import FancyURLopener from urllib import urlencode | from urllib.request import FancyURLopener from urllib.parse import urlencode |
| ⑥ | from urllib2 import Request from urllib2 import HTTPError | from urllib.request import Request from urllib.error import HTTPError |
- 以前,Python 2里的
urllib模块有各种各样的函数,包括用来获取数据的urlopen(),还有用来将URL分割成其组成部分的splittype(),splithost()和splituser()函数。在新的urllib包里,这些函数被组织得更有逻辑性。2to3将会修改这些函数的调用以适应新的命名方案。 - 在Python 3里,以前的
urllib2模块被并入了urllib包。同时,以urllib2里各种你最喜爱的东西将会一个不缺地出现在Python 3的urllib模块里,比如build_opener()方法,Request对象,HTTPBasicAuthHandler和friends。 - Python 3里的
urllib.parse模块包含了原来Python 2里urlparse模块所有的解析函数。 urllib.robotparse模块解析robots.txt文件。- 处理HTTP重定向和其他状态码的
FancyURLopener类在Python 3里的urllib.request模块里依然有效。urlencode()函数已经被转移到了urllib.parse里。 Request对象在urllib.request里依然有效,但是像HTTPError这样的常量已经被转移到了urllib.error里。- 是否有提到2to3也会重写你的函数调用?比如,如果你的Python 2代码里导入了urllib模块,调用了urllib.urlopen()函数获取数据,2to3会同时修改import语句和函数调用。
| Notes | Python 2 | Python 3 |
|---|---|---|
| |
10)dbm#
所有的dbm克隆(dbm clone)现在在单独的一个包里,即dbm。如果你需要其中某个特定的变体,比如gnu dbm,你可以导入dbm包中合适的模块。
| Notes | Python 2 | Python 3 |
|---|---|---|
| import dbm | import dbm.ndbm | |
| import gdbm | import dbm.gnu | |
| import dbhash | import dbm.bsd | |
| import dumbdbm | import dbm.dumb | |
| import dbm |
11)xmlrpc
xml-rpc是一个通过http协议执行远程rpc调用的轻重级方法。一些xml-rpc客户端和xml-rpc服务端的实现库现在被组合到了独立的包,即xmlrpc。
| Notes | Python 2 | Python 3 |
|---|---|---|
| import xmlrpclib | import xmlrpc.client | |
| import xmlrpc.server |
12)其他模块
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | | import io |
| ② | | import pickle |
| ③ | import __builtin__ | import builtins |
| ④ | import copy_reg | import copyreg |
| ⑤ | import Queue | import queue |
| ⑥ | import SocketServer | import socketserver |
| ⑦ | import ConfigParser | import configparser |
| ⑧ | import repr | import reprlib |
| ⑨ | import commands | import subprocess |
- 在Python 2里,你通常会这样做,首先尝试把cStringIO导入作为StringIO的替代,如果失败了,再导入StringIO。不要在Python 3里这样做;io模块会帮你处理好这件事情。它会找出可用的最快实现方法,然后自动使用它。
- 在Python 2里,导入最快的pickle实现也是一个与上边相似的能用方法。在Python 3里,pickle模块会自动为你处理,所以不要再这样做。
- builtins模块包含了在整个Python语言里都会使用的全局函数,类和常量。重新定义builtins模块里的某个函数意味着在每处都重定义了这个全局函数。这听起来很强大,但是同时也是很可怕的。
- copyreg模块为用C语言定义的用户自定义类型添加了pickle模块的支持。
- queue模块实现一个生产者消费者队列(multi-producer, multi-consumer queue)。
- socketserver模块为实现各种socket server提供了通用基础类。
- configparser模块用来解析ini-style配置文件。
- reprlib模块重新实现了内置函数repr(),并添加了对字符串表示被截断前长度的控制。
- subprocess模块允许你创建子进程,连接到他们的管道,然后获取他们的返回值。
10.包内的相对导入
包是由一组相关联的模块共同组成的单个实体。在Python 2的时候,为了实现同一个包内模块的相互引用,你会使用import foo或者from foo import Bar。Python 2解释器会先在当前目录里搜索foo.py,然后再去Python搜索路径(sys.path)里搜索。在Python 3里这个过程有一点不同。Python 3不会首先在当前路径搜索,它会直接在Python的搜索路径里寻找。如果你想要包里的一个模块导入包里的另外一个模块,你需要显式地提供两个模块的相对路径。
假设你有如下包,多个文件在同一个目录下:
chardet/ | +--__init__.py | +--constants.py | +--mbcharsetprober.py | +--universaldetector.py
现在假设universaldetector.py需要整个导入constants.py,另外还需要导入mbcharsetprober.py的一个类。你会怎样做?
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | import constants | from .import constants |
| ② | from mbcharsetproberimportMultiByteCharSetProber | from .mbcharsetproberimportMultiByteCharsetProber |
- 当你需要从包的其他地方导入整个模块,使用新的
from . import语法。这里的句号(.)即表示当前文件(universaldetector.py)和你想要导入文件(constants.py)之间的相对路径。在这个样例中,这两个文件在同一个目录里,所以使用了单个句号。你也可以从父目录(from .. import anothermodule)或者子目录里导入。 - 为了将一个特定的类或者函数从其他模块里直接导入到你的模块的名字空间里,在需要导入的模块名前加上相对路径,并且去掉最后一个斜线(slash)。在这个例子中,
mbcharsetprober.py与universaldetector.py在同一个目录里,所以相对路径名就是一个句号。你也可以从父目录(from .. import anothermodule)或者子目录里导入。
11.返回可迭代对象,而不是列表
某些函数和方法在Python中返回的是可迭代对象,而不像在Python 2中返回列表。
由于通常对这些对象只遍历一次,所以这种方式会节省很多内存。然而,如果通过生成器来多次迭代这些对象,效率就不高了。此时我们的确需要列表对象,可以通过list()函数简单的将可迭代对象转成列表。
range()
在Python 2.x中,经常会用xrange()创建一个可迭代对象,通常出现在“for循环”或“列表/集合/字典推导式”中。
这种行为与生成器非常相似(如”惰性求值“),但这里的xrange-iterable无尽的,意味着可能在这个xrange上无限迭代。
由于xrange的“惰性求知“特性,如果只需迭代一次(如for循环中),range()通常比xrange()快一些。不过不建议在多次迭代中使用range(),因为range()每次都会在内存中重新生成一个列表。{Python 3中的range()和Python 2中xrange()执行速度有差异。由于这两者的实现方式相同,因此理论上执行速度应该也是相同的。这里的速度差别仅仅是因为Python 3的总体速度就比Python 2慢。}
在Python 3中,range()的实现方式与xrange()函数相同,所以就不存在专用的xrange()(在Python 3中使用xrange()会触发NameError)。
Note:另一个值得一提的是,在Python 3.x中,range有了一个新的__contains__方法。__contains__方法可以有效的加快Python 3.x中整数和布尔型的“查找”速度。但由于Python 2.x中的range或xrange没有__contains__方法,所以在Python 2中的整数和浮点数的查找速度差别不大。
Python 2
print range(3)
print type(range(3))[0, 1, 2]
<type 'list'>Python 3
print(range(3))
print(type(range(3)))
print(list(range(3)))
range(0, 3)
<class 'range'>
[0, 1, 2]函数sum()能作用于迭代器:所以2to3也没有在这里做出修改。就像返回值为视图(view)而不再是列表的字典类方法一样,这同样适用于min(),max(),sum(),list(),tuple(),set(),sorted(),any(),all()。
Python 3中其他不再返回列表的常用函数和方法:
- zip() 在Python 2里,全局函数
zip()可以使用任意多个序列作参数,返回一个由元组构成的列表。第一个元组包含了每个序列的第一个元素;第二个元组包含了每个序列的第二个元素;依次递推下去。在Python 3里,zip()返回一个迭代器,而非列表。 - map()
- filter() : 在Python 2里,
filter()方法返回一个列表,这个列表是通过一个返回值为True或者False的函数来检测序列里的每一项得到的。在Python 3里,filter()函数返回一个迭代器,不再是列表。最简单的情况下,2to3会用一个list()函数来包装filter(),list()函数会遍历它的参数然后返回一个列表。然而,如果filter()调用已经被list()包裹,2to3不会再做处理,因为这种情况下filter()的返回值是否是一个迭代器是无关紧要的。为了处理filter(None, ...)这种特殊的语法,2to3会将这种调用从语法上等价地转换为列表解析。 - 字典的.key()方法
- 字典的.value()方法
- 字典的.item()方法
python3中被移除的函数:
而apply()、 callable()、coerce()、 execfile()、reduce()和reload()函数都被去除了.现在可以使用hasattr()来替换 callable(). hasattr()的语法如:hasattr(string, '__name__')
Python 2有一个叫做apply()的全局函数,它使用一个函数f和一个列表[a, b, c]作为参数,返回值是f(a, b, c)。你也可以通过直接调用这个函数,在列表前添加一个星号(*)作为参数传递给它来完成同样的事情。在Python 3里,apply()函数不再存在了;必须使用星号标记法。
在Python 3里,reduce()函数已经被从全局名字空间里移除了,它现在被放置在fucntools模块里。
在Python 2里,你可以用intern()函数作用在一个字符串上来限定(intern)它以达到性能优化。在Python 3里,intern()函数被转移到sys模块里了。
在Python 2里,你可以使用全局函数callable()来检查一个对象是否可调用(callable,比如函数)。在Python 3里,这个全局函数被取消了。为了检查一个对象是否可调用,可以检查特殊方法__call__()的存在性。
| Notes | Python 2 | Python 3 |
|---|---|---|
callable(anything) | hasattr(anything,'__call__') |
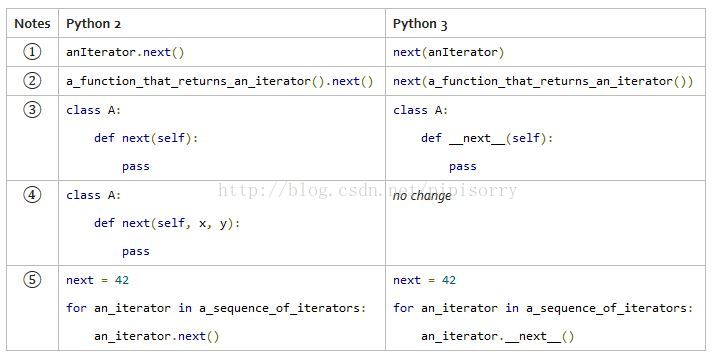
next()函数和.next()方法
由于会经常用到next()(.next())函数(方法),所以还要提到另一个语法改动(实现方面也做了改动):在Python 2.7.5中,函数形式和方法形式都可以使用,而在Python 3中,只能使用next()函数(试图调用.next()方法会触发AttributeError)。
Python 2
my_generator = (letter for letter in 'abcdefg')
next(my_generator)
my_generator.next()
'b'
Python 3
my_generator = (letter for letter in 'abcdefg')
next(my_generator)
'a'
my_generator.next()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-14-125f388bb61b> in <module>()
----> 1 my_generator.next()
AttributeError: 'generator' object has no attribute 'next'
迭代器方法next()
在Python 2里,迭代器有一个next()方法,用来返回序列里的下一项。在Python 3里这同样成立,但是现在有了一个新的全局的函数next(),它使用一个迭代器作为参数。
最简单的例子,你不再调用一个迭代器的next()方法,现在你将迭代器自身作为参数传递给全局函数next()。
假如你有一个返回值是迭代器的函数,调用这个函数然后把结果作为参数传递给next()函数。(2to3脚本足够智能以正确执行这种转换。)
假如你想定义你自己的类,然后把它用作一个迭代器,在Python 3里,你可以通过定义特殊方法__next__()来实现。
如果你定义的类里刚好有一个next(),它使用一个或者多个参数,2to3执行的时候不会动它。这个类不能被当作迭代器使用,因为它的next()方法带有参数。
这一个有些复杂。如果你恰好有一个叫做next的本地变量,在Python 3里它的优先级会高于全局函数next()。在这种情况下,你需要调用迭代器的特别方法__next__()来获取序列里的下一个元素。(或者,你也可以重构代码以使这个本地变量的名字不叫next,但是2to3不会为你做这件事。)
12.其它
1)xrange() 改名为range(),要想使用range()获得一个list,必须显式调用:
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
2)bytes对象不能hash,也不支持 b.lower()、b.strip()和b.split()方法,但对于后两者可以使用 b.strip(b’\n\t\r \f’)和b.split(b’ ‘)来达到相同目的
3)字典
字典类方法has_key()
在Python 2里,字典对象的has_key()方法用来测试字典是否包含特定的键(key)。Python 3不再支持这个方法了。你需要使用in运算符。
Note:运算符or的优先级高于运算符in,运算符in的优先级大于运算符+.
返回列表的字典类方法
在Python 2里,许多字典类方法的返回值是列表。其中最常用方法的有keys,items和values。在Python 3里,所有以上方法的返回值改为动态视图(dynamic view)。在一些上下文环境里,这种改变并不会产生影响。如果这些方法的返回值被立即传递给另外一个函数,并且那个函数会遍历整个序列,那么以上方法的返回值是列表或者视图并不会产生什么不同。在另外一些情况下,Python 3的这些改变干系重大。如果你期待一个能被独立寻址元素的列表,那么Python 3的这些改变将会使你的代码卡住(choke),因为视图(view)不支持索引(indexing)。
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | a_dictionary.keys() | list(a_dictionary.keys()) |
| ② | a_dictionary.items() | list(a_dictionary.items()) |
| ③ | a_dictionary.iterkeys() | iter(a_dictionary.keys()) |
| ④ | [i for iin a_dictionary.iterkeys()] | [i for iin a_dictionary.keys()] |
| ⑤ | min(a_dictionary.keys()) | no change |
- 使用list()函数将keys()的返回值转换为一个静态列表,出于安全方面的考量,2to3可能会报错。这样的代码是有效的,但是对于使用视图来说,它的效率低一些。你应该检查转换后的代码,看看是否一定需要列表,也许视图也能完成同样的工作。
- 这是另外一种视图(关于items()方法的)到列表的转换。2to3对values()方法返回值的转换也是一样的。
- Python 3里不再支持iterkeys()了。如果必要,使用iter()将keys()的返回值转换成为一个迭代器。
- 2to3能够识别出iterkeys()方法在列表解析里被使用,然后将它转换为Python 3里的keys()方法(不需要使用额外的iter()去包装其返回值)。这样是可行的,因为视图是可迭代的。
- 2to3也能识别出keys()方法的返回值被立即传给另外一个会遍历整个序列的函数,所以也就没有必要先把keys()的返回值转换到一个列表。相反的,min()函数会很乐意遍历视图。这个过程对min(),max(),sum(),list(),tuple(),set(),sorted(),any()和all()同样有效。
4)string.letters和相关的.lowercase和.uppercase被去除,请改用string.ascii_letters 等
5)如果x < y的不能比较,抛出TypeError异常。2.x版本是返回伪随机布尔值的
6)__getslice__系列成员被废弃。a[i:j]根据上下文转换为a.__getitem__(slice(I, j))或 __setitem__和__delitem__调用
7)file类被废弃,
在Py2.5中:
>>> file
<type 'file'>
在Py3.X中:
>>> file
Traceback (most recent call last):
File "<pyshell#120>", line 1, in <module>
file
NameError: name 'file' is not defined
8)更多
全局函数isinstance()
isinstance()函数检查一个对象是否是一个特定类(class)或者类型(type)的实例。在Python 2里,你可以传递一个由类型(types)构成的元组给isinstance(),如果该对象是元组里的任意一种类型,函数返回True。在Python 3里,你依然可以这样做,但是不推荐使用把一种类型作为参数传递两次。
| Notes | Python 2 | Python 3 |
|---|---|---|
| isinstance(x,(int,float,int)) | isinstance(x,(int,float)) |
basestring数据类型
Python 2有两种字符串类型:Unicode编码的字符串和非Unicode编码的字符串。但是其实还有另外 一种类型,即basestring。它是一个抽象数据类型,是str和unicode类型的超类(superclass)。它不能被直接调用或者实例化,但是你可以把它作为isinstance()的参数来检测一个对象是否是一个Unicode字符串或者非Unicode字符串。在Python 3里,只有一种字符串类型,所以basestring就没有必要再存在了。
| Notes | Python 2 | Python 3 |
|---|---|---|
| isinstance(x, basestring) | isinstance(x, str) |
itertools模块
Python 2.3引入了itertools模块,它定义了全局函数zip(),map(),filter()的变体(variant),这些变体的返回类型为迭代器,而非列表。在Python 3里,由于这些全局函数的返回类型本来就是迭代器,所以这些itertools里的这些变体函数就被取消了。(在itertools模块里仍然还有许多其他的有用的函数,而不仅仅是以上列出的这些。)
| Notes | Python 2 | Python 3 |
|---|---|---|
| ① | itertools.izip(a, b) | zip(a, b) |
| ② | itertools.imap(a, b) | map(a, b) |
| ③ | itertools.ifilter(a, b) | filter(a, b) |
| ④ | from itertools import imap, izip, foo | from itertools import foo |
- 使用全局的zip()函数,而非itertools.izip()。
- 使用map()而非itertools.imap()。
- itertools.ifilter()变成了filter()。
- itertools模块在Python 3里仍然存在,它只是不再包含那些已经转移到全局名字空间的函数。2to3脚本能够足够智能地去移除那些不再有用的导入语句,同时保持其他的导入语句的完整性。
对元组的列表解析
在Python 2里,如果你需要编写一个遍历元组的列表解析,你不需要在元组值的周围加上括号。在Python 3里,这些括号是必需的。
| Notes | Python 2 | Python 3 |
|---|---|---|
| [i for iin1,2] | [i for iin(1,2)] |
os.getcwdu()函数
Python 2有一个叫做os.getcwd()的函数,它将当前的工作目录作为一个(非Unicode编码的)字符串返回。由于现代的文件系统能够处理能何字符编码的目录名,Python 2.3引入了os.getcwdu()函数。os.getcwdu()函数把当前工作目录用Unicode编码的字符串返回。在Python 3里,由于只有一种字符串类型(Unicode类型的),所以你只需要os.getcwd()就可以了。
| Notes | Python 2 | Python 3 |
|---|---|---|
| os.getcwdu() | os.getcwd() |
关于代码风格
以下所列的“修补”(fixes)实质上并不算真正的修补。意思就是,他们只是代码的风格上的事情,而不涉及到代码的本质。但是Python的开发者们在使得代码风格尽可能一致方面非常有兴趣(have a vested interest)。为此,有一个专门o描述Python代码风格的官方指导手册 — 细致到能使人痛苦 — 都是一些你不太可能关心的在各种各样的细节上的挑剔。鉴于2to3为转换代码提供了一个这么好的条件,脚本的作者们添加了一些可选的特性以使你的代码更具可读性。
set()字面值(literal)(显式的)
在Python 2城,定义一个字面值集合(literal set)的唯一方法就是调用set(a_sequence)。在Python 3里这仍然有效,但是使用新的标注记号(literal notation):大括号({})是一种更清晰的方法。这种方法除了空集以外都有效,因为字典也用大括号标记,所以{}表示一个空的字典,而不是一个空集。
☞2to3脚本默认不会修复set()字面值。为了开启这个功能,在命令行调用2to3的时候指定-f set_literal参数。
| Notes | Before | After |
|---|---|---|
| set([1,2,3]) | {1,2,3} | |
| set((1,2,3)) | {1,2,3} | |
| set([ifor iin a_sequence]) | {i for iin a_sequence} |
全局函数buffer()(显式的)
用C实现的Python对象可以导出一个“缓冲区接口”(buffer interface),它允许其他的Python代码直接读写一块内存。(这听起来很强大,它也同样可怕。)在Python 3里,buffer()被重新命名为memoryview()。(实际的修改更加复杂,但是你几乎可以忽略掉这些不同之处。)
☞2to3脚本默认不会修复buffer()函数。为了开启这个功能,在命令行调用2to3的时候指定-f buffer参数。
| Notes | Before | After |
|---|---|---|
| x =buffer(y) | x =memoryview(y) |
逗号周围的空格(显式的)
尽管Python对用于缩进和凸出(indenting and outdenting)的空格要求很严格,但是对于空格在其他方面的使用Python还是很自由的。在列表,元组,集合和字典里,空格可以出现在逗号的前面或者后面,这不会有什么坏影响。但是,Python代码风格指导手册上指出,逗号前不能有空格,逗号后应该包含一个空格。尽管这纯粹只是一个美观上的考量(代码仍然可以正常工作,在Python 2和Python 3里都可以),但是2to3脚本可以依据手册上的标准为你完成这个修复。
☞2to3脚本默认不会修复逗号周围的空格。为了开启这个功能,在命令行调用2to3的时候指定-f wscomma参数。
| Notes | Before | After |
|---|---|---|
| a ,b | a, b | |
| {a :b} | {a: b} |
惯例(Common idioms)(显式的)
在Python社区里建立起来了许多惯例。有一些比如while 1: loop,它可以追溯到Python 1。(Python直到Python 2.3才有真正意义上的布尔类型,所以开发者以前使用1和0替代。)当代的Python程序员应该锻炼他们的大脑以使用这些惯例的现代版。
☞2to3脚本默认不会为这些惯例做修复。为了开启这个功能,在命令行调用2to3的时候指定-f idioms参数。
__future__模块
Python 3.x引入了一些与Python 2不兼容的关键字和特性,在Python 2中,可以通过内置的__future__模块导入这些新内容。如果你希望在Python 2环境下写的代码也可以在Python 3.x中运行,那么建议使用__future__模块。例如,如果希望在Python 2中拥有Python 3.x的整数除法行为,可以通过下面的语句导入相应的模块。
- from __future__ import division
下表列出了__future__中其他可导入的特性:
| 特性 | 可选版本 | 强制版本 | 效果 |
|---|---|---|---|
| nested_scopes | 2.1.0b1 | 2.2 | PEP 227:Statically Nested Scopes |
| generators | 2.2.0a1 | 2.3 | PEP 255:Simple Generators |
| division | 2.2.0a2 | 3.0 | PEP 238:Changing the Division Operator |
| absolute_import | 2.5.0a1 | 3.0 | PEP 328:Imports: Multi-Line and Absolute/Relative |
| with_statement | 2.5.0a1 | 2.6 | PEP 343:The “with” Statement |
| print_function | 2.6.0a2 | 3.0 | PEP 3105:Make print a function |
| unicode_literals | 2.6.0a2 | 3.0 | PEP 3112:Bytes literals in Python 3000 |
[https://docs.python.org/2/library/future.html]
示例:from platform import python_version
For循环变量与全局命名空间泄漏
好消息是:在Python 3.x中,for循环中的变量不再会泄漏到全局命名空间中了!
这是Python 3.x中做的一个改动,在“What’s New In Python 3.0”中有如下描述:
“列表推导不再支持[… for var in item1, item2, …]这样的语法,使用[… for var in (item1, item2, …)]代替。还要注意列表推导有不同的语义:现在列表推导更接近list()构造器中的生成器表达式这样的语法糖,特别要注意的是,循环控制变量不会再泄漏到循环周围的空间中了。”
更多关于Python 2和Python 3的文章
Should I use Python 2 or Python 3 for my development activity?
Porting Python 2 Code to Python 3
How keep Python 3 moving forward
Python2.x到Python3.x的转换
python3和python2虽然不兼容,但他们之间差别并没很多人想像的那么大。你只需要对自己的代码稍微做些修改就可以很好的同时支持python2和python3的。
一、放弃python 2.6之前的python版本
python 2.6之前的python版本缺少一些新特性,会给你的迁移工作带来不少麻烦。如果不是迫不得已还是放弃对之前版本的支持吧。
二、使用 2to3 工具对代码进行检查和转换
2to3是python自带的一个代码转换工具,可以将python2的代码自动转换为python3的代码。当然,不幸的是转换出的代码并没有对python2的兼容做任何的处理。所以我们并不真正使用2to3转换出的代码。执行2to3.py 查看输出信息,并修正相关问题。为了简化这个转换过程,这个脚本会将你的Python 2程序源文件作为输入,然后自动将其转换到Python 3的形式。
[将chardet移植到Python 3(porting chardet to Python 3]描述如何运行这个脚本,并展示不能自动修复的情况,附录描述了它自动修复的内容。
A backup of the originalfile is made unless -n is also given
Writing the changes back isenabled with the -w flag
linux下
$/usr/bin/2to3 -w DIRNAME
windows下
""" python2 convert to python3 E:\mine\pythonworkspace\test27> python d:\python3.4.2\tools\s\2to3.py -w ..\dirname(or filename) """
[26.7. 2to3 - Automated Python 2 to 3 code translation]
三、使用python -3执行python程序
2to3 可以检查出很多python2&3的兼容性问题,但也有很多问题是2to3发现不了的。在加上 -3 参数后,程序在运行时会在控制台上将python2和python3不一致,同时2to3无法处理的问题提示出来。比如python3和python2中对除法的处理规则做过改变。使用-3参数执行4/2将提示 DeprecationWarning: classic int division 。
四、from __future__ import
“from __future__ import”后即可使使用python的未来特性了。python的完整future特性可见 __future__ 。python3中所有字符都变成了unicode。在python2中unicode字符在定义时需要在字符前面加 u,但在3中则不需要家u,而且在加u后程序会无法编译通过。为了解决该问题可以 “from future import unicode_literals” ,这样python2中字符的行为将和python3中保持一致,python2中定义普通字符将自动识别为unicode。[__future__ — Future statement definitions]
还有一种方式是使用拓展包[Python到python的编译器允许你在老版本中使用Python 3.6的一些功能 ]
五、import问题
python3中“少”了很多python2的包,在大多情况下这些包之是改了个名字而已。我们可以在import的时候对这些问题进行处理。
例如,python3中ConfigParser模块改名为了configparser,如果想在python2和python3两种解析器下都可以运行的话,可以这样:
try
#建议按照python3的名字进行import
try: # python3 import configparser except: # python2 import ConfigParser as configparser
当然也可以使用下面检查当前运行python版本的方法解决。
检查当前运行的python版本
有时候你或许必须为python2和python3写不同的代码,你可以用下面的代码检查当前系统的python版本。
import sys if sys.version < '3': import ConfigParser else: import configparser as ConfigParser
六、使用python3的方式写程序
python2中print是关键字,到了python3中print变成了函数。事实上在python2.6中已经带了print函数,所以对print你直接按照2to3中给出的提示改为新写法即可。在python3中对异常的处理做了些变化,这个和print类似,直接按照2to3中的提示修改即可。
七、six: Python 2 and 3 Compatibility Library
six 提供了一些简单的工具用来封装 Python 2 和 Python 3 之间的差异性。我并不太推荐使用six。如果不需要支持python2.6之前的python版本,即使不用six也是比较容易处理兼容性问题的。使用six会让你的代码更像python2而不是python3。
python3的普及需要每位pythoner的推动,或许你还无法立即升级到python3,但请现在就开始写兼容python3的代码,并在条件成熟时升级到python3。
全面的了解从python2迁移到python3的相关问题:Supporting Python 3: An in-depth guide
from:http://blog.csdn.net/pipisorry/article/details/42167987
ref: Dive Into Python 3 :Porting Code to Python 3 with 2to3
Index of Python Enhancement Proposals (PEPs)















 3468
3468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









