






在 Langchain 中,文档转换器是一种在将文档提供给其他 Langchain 组件之前对其进行处理的工具。通过清理、处理和转换文档,这些工具可确保 LLM 和其他 Langchain 组件以优化其性能的格式接收数据。
上一章我们了解了文档加载器,加载完文档之后还需要对文档进行转换。
- 文本分割器
- 集成
Text Splitters
文本分割器专门用于将文本文档分割成更小、更易于管理的单元。
理想情况下,这些块应该是句子或段落,以便理解文本中的上下文和关系。
分割器考虑了 LLM 处理能力的局限性。通过创建更小的块,LLM 可以在其上下文窗口内更有效地分析信息。
- CharacterTextSplitter
- RecursiveCharacterTextSplitter
- Split by tokens
- Semantic Chunking
- HTMLHeaderTextSplitter
- MarkdownHeaderTextSplitter
- RecursiveJsonSplitter
- Split Cod
CharacterTextSplitter
代码语言:javascript
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
separator:这是用于标识文本中自然断点的分隔符。在本例中,它被设置为“\n\n”,这意味着分割器将寻找双换行符作为潜在的分割点。chunk_size:此参数指定每个文本块的目标大小,以字符数表示。在这里,它被设置为 1000,这意味着分割器将旨在创建大约 1000 个字符长的文本块。chunk_overlap:此参数允许连续块之间重叠字符。它被设置为 200,这意味着每个块将包含前一个块末尾的 200 个字符。这种重叠可以帮助确保在块之间的边界上不会丢失任何重要信息。length_function:这是一个用于测量文本块长度的函数。在本例中,它被设置为内置的 len 函数,该函数计算字符串中的字符数。is_separator_regex:此参数指定分隔符是否为正则表达式。它被设置为 False,表示分隔符是一个纯字符串,而不是正则表达式模式。
CharacterTextSplitter根据指定的分隔符拆分文本,默认情况下分隔符设置为 ‘\n\n’。chunk_size参数确定每个块的最大大小,并且只有在可行的情况下才会进行拆分。如果字符串以 n 个字符开头,后跟一个分隔符,然后在下一个分隔符之前有 m 个字符,则如果 chunk_size 小于 n + m + len(separator),则第一个块的大小将为 n。
代码语言:javascript
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("book.pdf")
pages = loader.load_and_split()
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.split_text(pages[0].page_content)
print(len(texts))
# 4
texts[0]
"""
'Our goal with this book is to provide the guidance and framework for you,
the reader, to grow on \nthe path to being a truly excellent database
reliability engineer (DBRE). When naming the book we \nchose to use the
words reliability engineer , rather than administrator. \nBen Treynor,
VP of Engineering at Google, says the following about reliability engi‐
neering: \nfundamentally doing work that has historically been done by an
operations team, but using engineers with software \nexpertise, and banking
on the fact that these engineers are inherently both predisposed to, and
have the ability to, \nsubstitute automation for human labor. \nToday’s
database professionals must be engineers, not administrators.
We build things. We create \nthings. As engineers practicing devops,
we are all in this together, and nothing is someone else’s \nproblem.
As engineers, we apply repeatable processes, establ ished knowledge,
and expert judgment'
"""
texts[1]
"""
'things. As engineers practicing devops, we are all in this together, and nothing is someone else’s \nproblem. As engineers, we apply repeatable processes, establ ished knowledge, and expert judgment \nto design, build, and operate production data stores and the data structures within. As database \nreliability engineers, we must take the operational principles and the depth of database expertise \nthat we possess one ste p further. \nIf you look at the non -storage components of today’s infrastructures, you will see sys‐ tems that are \neasily built, run, and destroyed via programmatic and often automatic means. The lifetimes of these \ncomponents can be measured in days, and sometimes even hours or minutes. When one goes away, \nthere is any number of others to step in and keep the quality of service at expected levels. \nOur next goal is that you gain a framework of principles and practices for the design, building, and'
"""
RecursiveCharacterTextSplitter
关键区别在于,如果结果块仍然大于所需的 chunk_size,它将继续分割结果块,以确保所有最终块都在指定的大小限制内。它由字符列表参数化。
代码语言:javascript
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
separators=["\n\n", "\n", " ", ""],
chunk_size=50,
chunk_overlap=40,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.split_text(pages[0].page_content)
print(len(texts))
texts[2]
"""
'book is to provide the guidance and framework for'
"""
texts[3]
"""
'provide the guidance and framework for you, the'
"""
在文本拆分的上下文中,“递归”意味着拆分器将重复将其拆分逻辑应用于生成的块,直到它们满足某些标准,例如小于指定的最大长度。这在处理需要分解成更小、更易于管理的片段(可能在不同的粒度级别)的非常长的文本时特别有用。
Split By Tokens
原文:“The quick brown fox jumps over the lazy dog。”
标记:[“The”、“quick”、“brown”、“fox”、“jumps”、“over”、“the”、“lazy”、“dog”]
在此示例中,文本根据空格和标点符号拆分为标记。每个单词都成为单独的标记。在实践中,标记化可能更复杂,尤其是对于具有不同书写系统的语言或处理特殊情况(例如,“don’t”可能拆分为“do”和“n’t”)。
有各种标记器。
TokenTextSplitter 来自 tiktoken 库。
代码语言:javascript
from langchain_text_splitters import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=1)
texts = text_splitter.split_text(pages[0].page_content)
texts[0]
"""
'Our goal with this book is to provide the guidance'
"""
texts[1]
"""
' guidance and framework for you, the reader, to'
"""
SpacyTextSplitter 来自spacy库。
代码语言:javascript
from langchain_text_splitters import SpacyTextSplitter
text_splitter = SpacyTextSplitter(chunk_size=1000)
texts = text_splitter.split_text(pages[0].page_content)
NLTKTextSplitter来自nltk库。
代码语言:javascript
from langchain_text_splitters import NLTKTextSplitter
text_splitter = NLTKTextSplitter(chunk_size=1000)
texts = text_splitter.split_text(pages[0].page_content)
我们甚至可以利用 Hugging Face 标记器。
代码语言:javascript
from transformers import GPT2TokenizerFast
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
text_splitter = CharacterTextSplitter.from_huggingface_tokenizer(
tokenizer, chunk_size=100, chunk_overlap=10
)
texts = text_splitter.split_text(pages[0].page_content)
HTMLHeaderTextSplitter
HTMLHeaderTextSplitter是一个网页代码分块器,它根据 HTML 元素拆分文本,并将相关元数据分配给分块内的每个标头。它可以返回单个分块或将具有相同元数据的元素组合在一起,以保持语义分组并保留文档的结构上下文。此拆分器可与分块管道中的其他文本拆分器结合使用。
代码语言:javascript
from langchain_text_splitters import HTMLHeaderTextSplitter
html_string = """
<!DOCTYPE html>
<html>
<body>
<div>
<h1>Foo</h1>
<p>Some intro text about Foo.</p>
<div>
<h2>Bar main section</h2>
<p>Some intro text about Bar.</p>
<h3>Bar subsection 1</h3>
<p>Some text about the first subtopic of Bar.</p>
<h3>Bar subsection 2</h3>
<p>Some text about the second subtopic of Bar.</p>
</div>
<div>
<h2>Baz</h2>
<p>Some text about Baz</p>
</div>
<br>
<p>Some concluding text about Foo</p>
</div>
</body>
</html>
"""
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
html_header_splits
"""
[Document(page_content='Foo'),
Document(page_content='Some intro text about Foo. \nBar main section Bar subsection 1 Bar subsection 2', metadata={'Header 1': 'Foo'}),
Document(page_content='Some intro text about Bar.', metadata={'Header 1': 'Foo', 'Header 2': 'Bar main section'}),
Document(page_content='Some text about the first subtopic of Bar.', metadata={'Header 1': 'Foo', 'Header 2': 'Bar main section', 'Header 3': 'Bar subsection 1'}),
Document(page_content='Some text about the second subtopic of Bar.', metadata={'Header 1': 'Foo', 'Header 2': 'Bar main section', 'Header 3': 'Bar subsection 2'}),
Document(page_content='Baz', metadata={'Header 1': 'Foo'}),
Document(page_content='Some text about Baz', metadata={'Header 1': 'Foo', 'Header 2': 'Baz'}),
Document(page_content='Some concluding text about Foo', metadata={'Header 1': 'Foo'})]
"""
MarkdownHeaderTextSplitter
类似于 HTMLHeaderTextSplitter ,专用于 markdown 文件。
代码语言:javascript
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly"
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits
"""
[Document(page_content='Hi this is Jim \nHi this is Joe', metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}),
Document(page_content='Hi this is Lance', metadata={'Header 1': 'Foo', 'Header 2': 'Bar', 'Header 3': 'Boo'}),
Document(page_content='Hi this is Molly', metadata={'Header 1': 'Foo', 'Header 2': 'Baz'})]
"""
RecursiveJsonSplitter
代码语言:javascript
import requests
# This is a large nested json object and will be loaded as a python dict
json_data = requests.get("https://api.smith.langchain.com/openapi.json").json()
from langchain_text_splitters import RecursiveJsonSplitter
splitter = RecursiveJsonSplitter(max_chunk_size=300)
# Recursively split json data - If you need to access/manipulate the smaller json chunks
json_chunks = splitter.split_json(json_data=json_data)
json_chunks
"""
{'openapi': '3.0.2',
'info': {'title': 'LangSmith', 'version': '0.1.0'},
'paths': {'/api/v1/sessions/{session_id}': {'get': {'tags': ['tracer-sessions'],
'summary': 'Read Tracer Session',
'description': 'Get a specific session.'}}}},
{'paths': {'/api/v1/sessions/{session_id}': {'get': {'operationId': 'read_tracer_session_api_v1_sessions__session_id__get'}}}},
{'paths': {'/api/v1/sessions/{session_id}': {'get': {'parameters': [{'required': True,
'schema': {'title': 'Session Id', 'type': 'string', 'format': 'uuid'},
'name': 'session_id',
'in': 'path'},
{'required': False,
'schema': {'title': 'Include Stats',
'type': 'boolean',
'default': False},
'name': 'include_stats',
'in': 'query'},
{'required': False,
'schema': {'title': 'Accept', 'type': 'string'},
'name': 'accept',
'in': 'header'}]}}}},
{'paths': {'/api/v1/sessions/{session_id}': {'get': {'responses': {'200': {'description': 'Successful Response',
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/TracerSession'}}}}}}}}},
{'paths': {'/api/v1/sessions/{session_id}': {'get': {'responses': {'422': {'description': 'Validation Error',
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/HTTPValidationError'}}}}},
'security': [{'API Key': []}, {'Tenant ID': []}, {'Bearer Auth': []}]}}}},
...
{'components': {'securitySchemes': {'API Key': {'type': 'apiKey',
'in': 'header',
'name': 'X-API-Key'},
'Tenant ID': {'type': 'apiKey', 'in': 'header', 'name': 'X-Tenant-Id'},
'Bearer Auth': {'type': 'http', 'scheme': 'bearer'}}}}]
"""
Split Code
Langchain 中的“Split Code”概念是指将代码划分为更小、更易于管理的段或块的过程。
代码语言:javascript
from langchain_text_splitters import Language
[e.value for e in Language]
"""
['cpp',
'go',
'java',
'kotlin',
'js',
'ts',
'php',
'proto',
'python',
'rst',
'ruby',
'rust',
'scala',
'swift',
'markdown',
'latex',
'html',
'sol',
'csharp',
'cobol',
'c',
'lua',
'perl']
"""
向量存储是一种专门用于存储和管理向量嵌入的数据库。
向量存储旨在高效处理大量向量,提供根据特定标准添加、查询和检索向量的功能。它可用于支持语义搜索等应用程序,在这些应用程序中,您可以查找与给定查询在语义上相似的文本段落或文档。
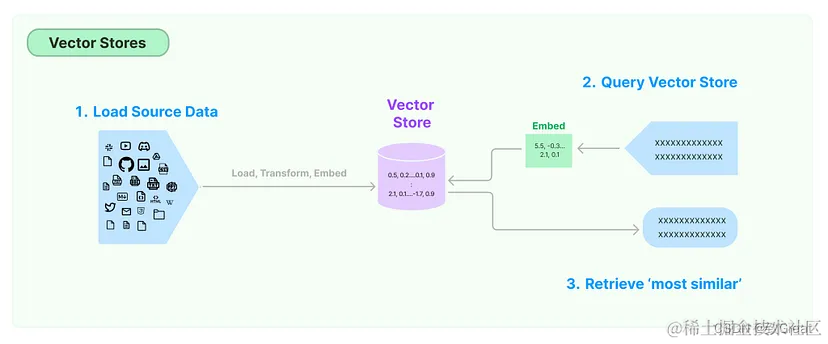
嵌入向量是文本的数字表示,可以捕捉文本的内容和含义。
内容和含义相似的文本会具有相似的向量,也就是说,它们在嵌入空间中的向量之间的距离会很小。
例如,“猫在沙发上睡觉”和“小猫在沙发上打盹”这两个句子的单词不同,但含义相似。它们的嵌入向量在嵌入空间中彼此接近,反映了它们的语义相似性。嵌入向量的这一特性对于各种自然语言处理任务至关重要,例如语义搜索、文本聚类和机器翻译,在这些任务中,理解文本的含义至关重要。
如前所述,我们使用文档加载器加载文档,然后使用文档转换器将文本分成块。接下来,我们为每个块生成嵌入,并将这些嵌入及其相应的拆分存储在向量存储中。
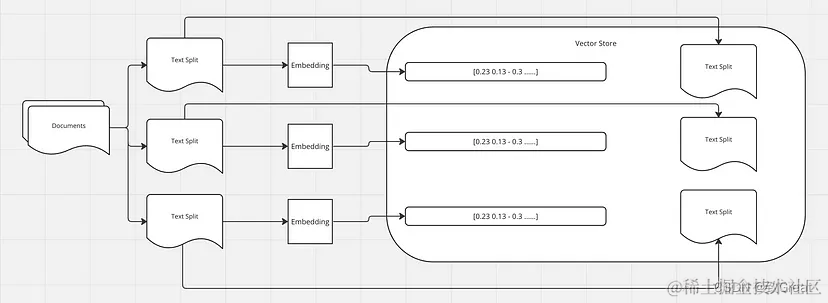
当您在向量存储中执行查询时,查询文本首先会使用与生成存储在向量存储中的文本的嵌入相同的流程或模型转换为嵌入向量。这可确保查询和存储的文本在同一向量空间中表示,从而实现有意义的比较。
将查询转换为嵌入后,向量存储会根据相似度度量(例如余弦相似度)搜索最相似的向量(即最相似的文本)。然后检索与这些相似向量相对应的文本作为查询结果。
在 Langchain 工作流中,这些检索到的文本可以进一步处理,方法是将它们与原始查询一起传递给大型语言模型 (LLM) 进行进一步分析或处理。例如,LLM 可以根据查询和检索到的文本生成响应,或者可以执行一些需要理解类似文本提供的上下文的任务。 Langchain 中存在不同的向量存储实现,每种实现都针对不同的用例和存储要求进行了优化。一些向量存储可能使用内存存储以实现快速访问,而另一些向量存储可能使用基于磁盘的存储以实现可扩展性。完整列表:
https://python.langchain.com/v0.2/docs/integrations/vectorstores/
首先,让我们处理向量存储之前的部分:
代码语言:javascript
import os
os.environ["OPENAI_API_KEY"] = "your-key"
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
embeddings = OpenAIEmbeddings()
llm_model = "gpt-4"
llm = ChatOpenAI(temperature=0.0, model=llm_model)
loader = PyPDFLoader("book.pdf")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
text_splits = text_splitter.split_documents(docs)
print(len(text_splits))
# 6
OpenAIEmbeddings是为了生成嵌入而创建的,并且 的实例ChatOpenAI是为了与 GPT-4 模型交互而创建的。
PyPDFLoader从名为“book.pdf”的 PDF 文件中加载文本。加载的文本存储在变量中docs。
RecursiveCharacterTextSplitter将加载的文本拆分为较小的块,每个块的最大大小为 1500 个字符,连续块之间有 150 个字符的重叠。该split_documents方法用于执行拆分,并将生成的文本块列表存储在 中text_splits。
Chroma
Chroma是一个开源向量数据库,专为高效存储和查询向量嵌入而设计。它与 Langchain 集成良好,使其成为在该环境中使用嵌入的开发人员的热门选择。
pip install chromadb
Chroma 优先考虑开发人员的易用性。它提供了一个简单的 API,其中包含添加、获取、更新和删除等常见数据库操作,以及基于相似性的查询功能。
代码语言:javascript
from langchain.vectorstores import Chroma
persist_directory = "./data/db/chroma"
vectorstore = Chroma.from_documents(
documents=text_splits,
embedding=embeddings,
persist_directory=persist_directory
)
print(vectorstore._collection.count()) # 6
persist_directory是 Chroma 将持久存储其数据的路径。这可确保即使应用程序终止后数据仍然可用。
该from_documents方法采用以下参数:
documents:要存储在向量存储中的文本文档(或文本拆分)列表。在本例中,text_splits假定为先前从较大文档中拆分出来的文本块列表。embeddingOpenAIEmbeddings:用于为文档生成嵌入的嵌入模型。这应该是可以从文本(例如对话中较早的文本)生成嵌入的类的实例。persist_directory:矢量存储将在磁盘上保存其数据的目录。这设置为persist_directory先前定义的变量。
代码语言:javascript
query = "what is the purpose of the book?"
docs_resp = vectorstore.similarity_search(query=query, k=3)
print(len(docs_resp))
print(docs_resp[0].page_content)
vectorstore.persist()
"""
Our goal with this book is to provide the guidance and framework for you, the reader, to grow on
the path to being a truly excellent database reliability engineer (DBRE). When naming the book we
chose to use the words reliability engineer , rather than administrator.
Ben Treynor, VP of Engineering at Google, says the following about reliability engi‐ neering:
fundamentally doing work that has historically been done by an operations tea...
"""
该查询将用于在向量存储中搜索类似的文档。
该similarity_search方法采用以下参数:
query:用于搜索类似文档的文本查询。k:要检索的最相似文档的数量。在本例中,k=3表示将返回前3个最相似的文档。结果,docs_resp是与查询最相似的文档列表。persist方法使用创建向量存储时指定的当前状态保存到vectorstore磁盘的persist_directory`
Faiss
FAISS 是Facebook AI Similarity Search的缩写,是 Facebook 开发的一款功能强大的开源库,用于对高维向量进行高效的相似性搜索。
代码语言:javascript
from langchain_community.vectorstores import FAISS
db = FAISS.from_documents(text_splits, embeddings)
print(db.index.ntotal) # 6
docs = db.similarity_search(query)
print(docs[0].page_content)
"""
Our goal with this book is to provide the guidance and framework for you, the reader, to grow on
the path to being a truly excellent database reliability engineer (DBRE). When naming the book we
chose to use the words reliability engineer , rather than administrator.
Ben Treynor, VP of Engineering at Google, says the following about reliability engi‐ neering:
fundamentally doing work that has historically been done by an operations team, but using engineers with software
expertise, and banking on the fact that these engineers are inherently both predisposed to, and have the ability to,
substitute automation for human labor.
...
"""
db.save_local("faiss_index")
可以加载Embedding模型构建Faiss
代码语言:javascript
from langchain_huggingface import HuggingFaceEmbeddings
# from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores.faiss import FAISS
from langchain_core.documents import Document
documents = [
Document(
meta_data={'text': 'PC'},
page_content='个人电脑',
),
Document(
meta_data={'text': 'doctor'},
page_content='医生办公室',
)
]
embedding_path = r'H:\pretrained_models\bert\english\paraphrase-multilingual-mpnet-base-v2'
embedding_model = HuggingFaceEmbeddings(model_name=embedding_path)
db = FAISS.from_documents(documents, embedding=embedding_model)
db.save_local('../.cache/faiss.index')
db = FAISS.load_local('../.cache/faiss.index', embeddings=embedding_model, index_name='index',allow_dangerous_deserialization=True)
docs = db.similarity_search_with_score('台式机电脑')
print(docs)
代码语言:javascript
from langchain_text_splitters import (
Language,
RecursiveCharacterTextSplitter,
)
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
# Call the function
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docs
"""
[Document(page_content='def hello_world():\n print("Hello, World!")'),
Document(page_content='# Call the function\nhello_world()')]
"""
JS_CODE = """
function helloWorld() {
console.log("Hello, World!");
}
// Call the function
helloWorld();
"""
代码语言:javascript
js_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.JS, chunk_size=60, chunk_overlap=0
)
js_docs = js_splitter.create_documents([JS_CODE])
js_docs
"""
[Document(page_content='function helloWorld() {\n console.log("Hello, World!");\n}'),
Document(page_content='// Call the function\nhelloWorld();')]
"""
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的所有 ⚡️ 大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
全套 《LLM大模型入门+进阶学习资源包》↓↓↓ 获取~















 2487
2487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









