










1. 引言
大模型的训练和推理任务,本质就是海量数据处理的过程。强大的算力集群,不仅需要高性能的 AI 加速卡和高性能的 RDMA 网络,还离不开高性能存储系统的支持。
当前,在大模型训练任务的数据读取、Checkpoint 加载,推理任务的快速分发和镜像加载等场景,数据的大小少则几十 GiB,多则几百 TiB 甚至至多达到数 PiB。存储速度越快,算力空闲时间越短。这需要一套能够支持大规模算力集群、海量数据场景的高性能存储加速系统。
2. RapidFS 存储加速集群
在 Create 2025 大会,昆仑芯 3 万卡集群正式发布。为此,我们为 RapidFS 存储加速服务部署了数百台国产 CPU 服务器,集群设计总吞吐接近 10 TiB/s,以满足 3 万卡昆仑芯集群大规模数据读写需求。
我们使用部分资源进行了 RapidFS 性能测试(更多测试细节见后文)。
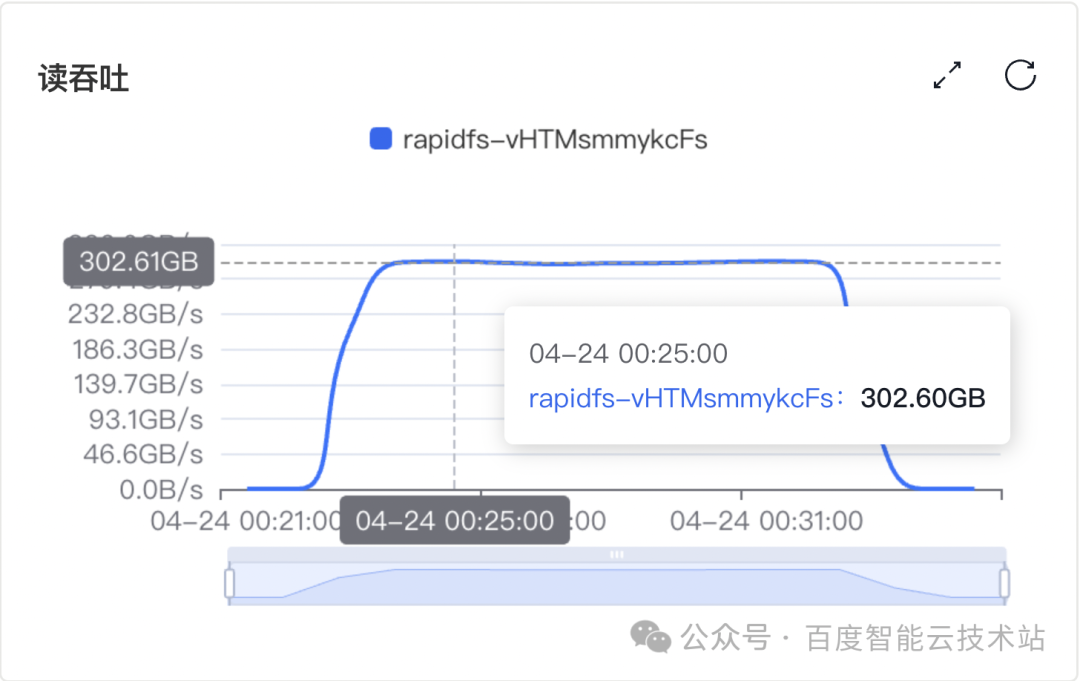
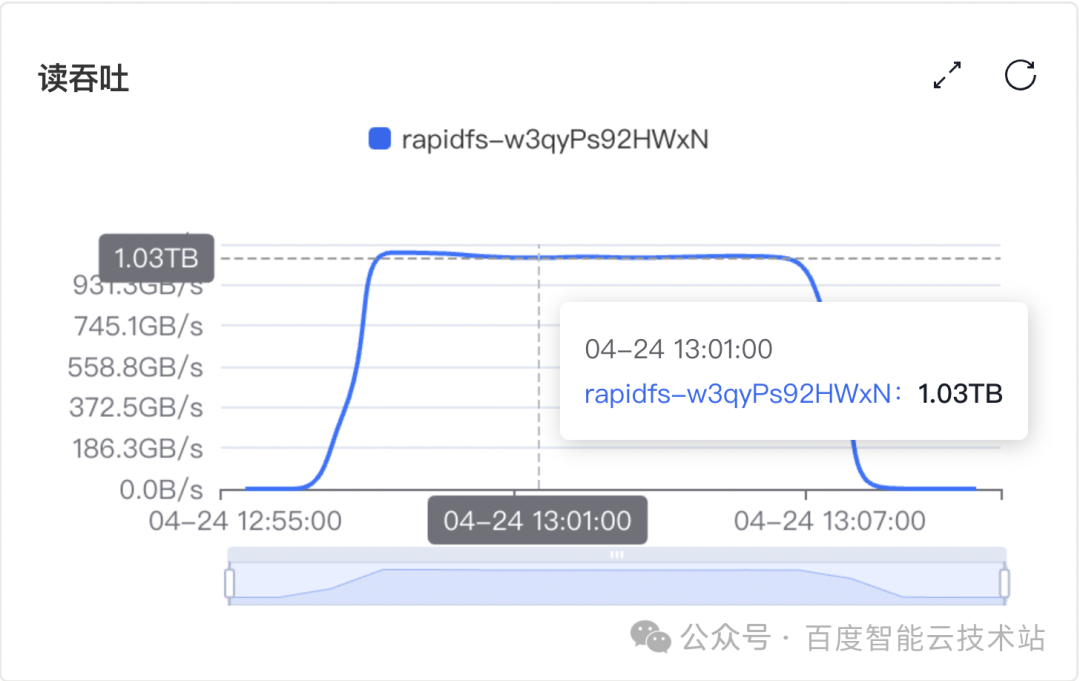
测试结果显示,20 个 RapidFS 存储节点稳定提供了 302 GiB/s 吞吐,70 个 RapidFS 存储节点稳定提供了 1.03 TiB/s 吞吐。单台 RapidFS 存储节点可提供 15 GiB/s 吞吐,折合单 TiB(裸容量)300 MiB/s。
这些数据表明 RapidFS 存储加速集群的吞吐性能,随着集群规模线性增长。单台 RapidFS 存储节点经过软硬一体的协同优化,充分发挥出国产 CPU 的性能和软件加速效果。
同时,这也意味着在 70 个 RapidFS 存储节点提供加速的情况下,100 个计算节点并发加载 10 GiB 的文件仅需 1 秒,让数据随叫随到。
3. RapidFS 产品简介
RapidFS 是一款近计算存储加速工具。依托对象存储 BOS 作为数据湖存储底座,构建容量与性能解耦、冷热分层、透明流转的高性能存储方案。以 POSIX 挂载和 HDFS 协议,为上层计算应用提供统一文件访问入口,加速 AI 训练与推理、海量数据处理与分析、数据分发等业务场景下的存储访问。
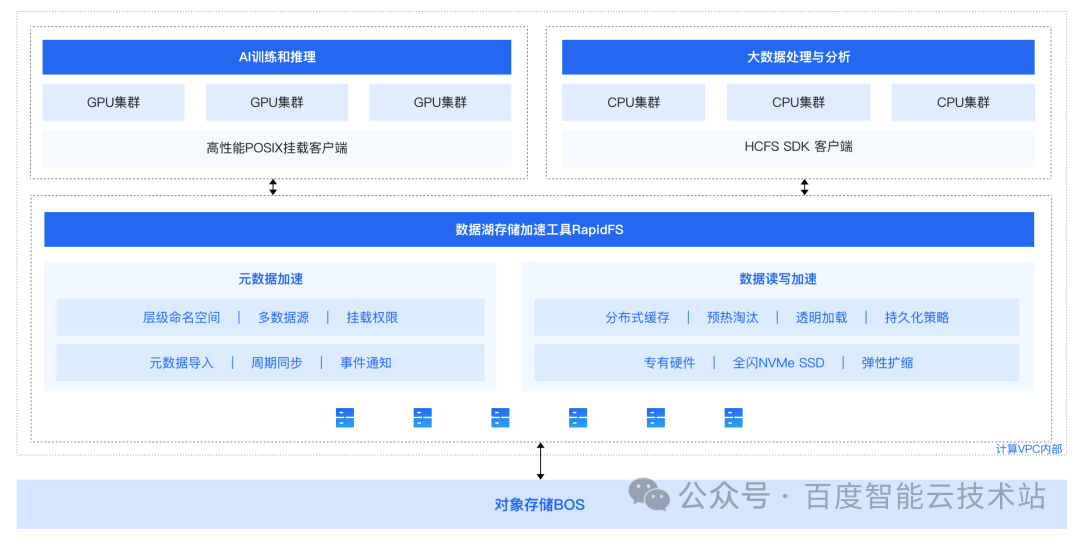
4. 性能测试详细说明
4.1. 服务器配置
在本次测试的昆仑芯 3 万卡集群中,百度智能云 RapidFS 以全托管集群方式部署于国产 CPU 服务器,作为近计算存储加速服务使用。详细配置如下:

4.2. 测试规模
我们分别对 20 个存储节点和 70 个存储节点规模的 RapidFS 集群进行了性能测试。
4.3. 测试方法
按照 DeepSeek V3 模型文件构造 160 个 4.3 GiB 文件,总计 688 GiB。将这些文件导入对象存储 BOS 并加载至 RapidFS 存储加速集群中。每个计算节点开启 8 进程从 RapidFS 存储加速集群中读取模型文件,持续压测 600 秒。
4.4. 测试结果
测试集群 A:20 个 RapidFS 存储节点
测试集群 B:70 个 RapidFS 存储节点
百度智能云 RapidFS 存储加速集群用数据证明了国产算力基础设施的突破潜力。存储性能与算力需求实现「同频共振」,成为大模型训练与推理的效率助推器。

















 1753
1753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









