






前言
排序,就是将一组数据按特定的规则调换位置,使这组数据具有某种顺序关系,一般就是递增或递减。
在接触C语言不久,我们就会遇到其中一种有名的排序算法——“冒泡排序”,不知道你是否已经掌握了,如果还没有的话,不妨听一下我的讲解版本,或许能有一点启发。
记住,理解冒泡排序非常重要的一点是,你要知道这个名字“冒泡”并不是随便乱取的,通过画图你可以看到它的过程真的就像在“冒泡”,可以抓住这个形象的过程去理解。 当然冒泡可以向左冒,也可以向右冒。
讲解
实现冒泡的逻辑:
冒泡排序指的是在排序时,每次比较数组中相邻的两个数组元素的值,(假设我们现在要从小到大排序)如果前面的数大于后面的数,就将较小的数调换到较大的数前面。
现在我们假设有一组数据:7,6,14,5,2,如果用冒泡法对其进行排序,排成从小到大,那么每轮排序的过程我们可以画图: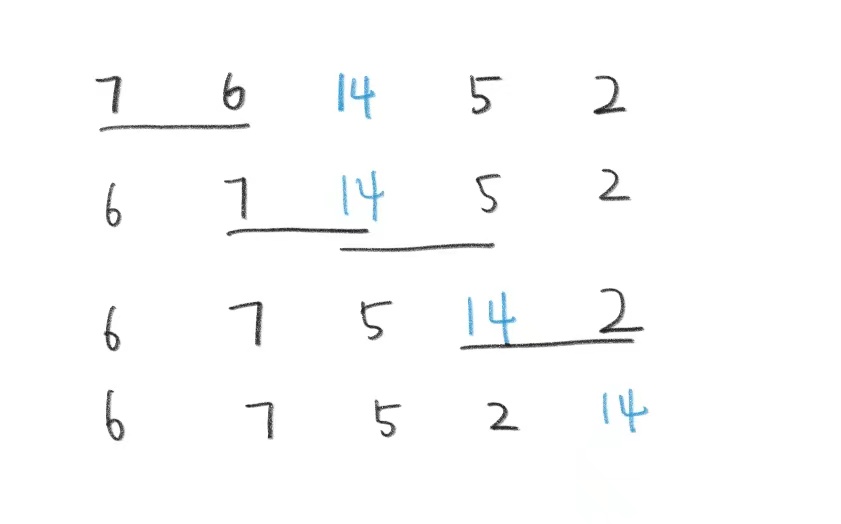
图中下划线代表当下正在两两比较的两个数据。可以看到两两比较的结果就是14作为当前数组中最大的数被一路调换位置,到了数组的末尾位置(因为14作为数组最大的数,其实已经到了该到的位置,下一轮两两比较就与14无关了,它就像一个冒出当前范围的泡泡)
以上是一轮冒泡,现在我们再看一轮:

此时可以看到,7被一路换到了14的前面也就是它应该到的位置,14则无需再进行比较,下一轮的7也无需再参与两两比较了。
可以看到每一轮冒泡我们就能让一个数去到它该去的位置,也可以总结出一轮冒泡的规律:
冒泡排序每一轮冒泡就是一次整个数组的两两比较,规则很简单,两两比较所以会有前和后,前是从数组第一个元素开始的,而当后遍历到了最后一个元素就不会再往后遍历了因为已经没有元素了,而此时我们的前是到倒数第二个元素,所以我们可以得出每次冒泡(也就是每轮整个数组的两两遍历)的代码应该是:
int j = 0;
for (j = 0; j < sz - 1 - i; j++)//一会解释
{
if (arr[j] > arr[j + 1])//如果“前”比“后”大,就交换
{
int tmp;//创建一个中间变量,用于交换
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}在上面我们不断提到“轮”这个字眼,因为我们冒几次泡是需要确定的,上面代码中的for语句执行一次只能冒出一个泡泡,也就是只能让当前最大的数去到它应该去的位置,所以为了让所有数都去到应该取的位置,我们就需要将这个for语句循环sz-1次。sz-1是什么?
int arr[] = { 7,6,14,5,2 };
int sz = sizeof(arr) / sizeof(arr[0]);//数组元素个数sz是数组元素个数,那么sz-1就是我们应该冒泡的轮数,因为当sz-1个元素都去到了该去的位置,剩下的那个也已经无需再排了。
所以我们现在再写一个外循环来控制上面这个负责两两比较的for循环的执行次数:
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp;
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}那么,现在我来解释一下为什么内循环要写成for (j = 0; j < sz - 1 - i; j++),这个j < sz - 1 - i应该怎么理解呢?
我们上面说到,除了第一轮冒泡外,每一轮冒泡都有我们不去排的数,也就是先前已经排好了的数,上面第二轮冒泡我们不排的是14,第三轮冒泡我们不排的是14与7。这也说明我们每一轮冒泡需要两两比较的次数是不一样的,是变化的。而这个变化恰好就与我们的i变量有关,或者说恰好可以用变量i来表示:
如果没有-i,for (j = 0; j < sz - 1; j++)是什么效果?每一轮我们都会两两比较sz-1次,对于这个例子,5个元素,我们冒泡4轮,每一轮两两比较4次肯定是没必要的。
那for (j = 0; j < sz - 1 - i ; j++),带上-i后是什么效果? 第一轮冒泡,此时i为0,j<sz-1,也就是这一轮我们要两两比较4次,没错; 第二轮冒泡,此时i为1,j<sz-2,也就是两两比较3次,没错……最后一轮,此时i为sz-2也就是3,j<sz-4,也就是两两比较1次,没错。
所以可以看出,写成for (j = 0; j < sz - 1 - i ; j++)是非常正确的、符合预期的。
交换两个元素的值:
如果不理解交换两个元素的值的代码为什么这么写的读者,也可以再听一下解释:
int tmp;
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;可能会有人好奇为什么不能写成:
arr[j] = arr[j + 1];
arr[j + 1] = arr[j];这是初学C语言的我们确实可能会犯下的错,注意代码的执行顺序是从上到下,而arr[j] = arr[j + 1];的'='可不是等号,是赋值运算符,所以当执行到arr[j + 1] = arr[j];的时候其实此时的arr[j]的值已经变为arr[j + 1]的值了,这相当于把arr[j + 1]的值再赋值给arr[j + 1],是不能达到我们预期的交换的效果的。
所以我们可以先把arr[j]的值赋给一个额外创建的变量tmp,将arr[j + 1] 的值赋给arr[j],要将arr[j]原本的值赋给arr[j + 1]时我们只用将tmp的值赋给arr[j + 1]就行了。
所以讲到这里,我们已经得出了冒泡排序的代码,我们可以将其封装成一个函数:
void bubble_sort(int* arr, int sz)//传过来的是数组名arr,是数组首元素地址,所以用整型指针接收arr
//因为传过来的是数组首元素地址,所以不知道数组大小,所以要把元素个数一起传过来
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp;
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
相应的,main函数里应该是这样的:
int main()
{
int arr[] = { 7,6,14,5,2 };
int sz = sizeof(arr) / sizeof(arr[0]);//数组元素个数
bubble_sort(arr,sz);//调用冒泡排序函数
print(arr, sz);//排序完打印看看效果
return 0;
}这时可以看到我还写了一个函数print()专门用于打印数组,这样可以让我们的main函数更整洁,也可以提高复用性,下次打印就不用再写一次了,这是封装函数的好处,我们要尽早习惯这种做法。
//写一个函数实现对数组的打印
void print(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}完整代码参考

vs运行效果:

可以看到我们的这组数据就成功地从小到大排序了。
小结
我们可以总结出一些东西来帮助我们理解冒泡排序:
n个数冒泡排序,就要进行n-1轮冒泡;(第一轮n-1次两两比较)
对于我们的双层循环,i控制的是轮数,j才是负责控制两两比较的;
每轮要进行的两两比较是越来越少的,恰好可以用 j < sz - 1 - i表示;
每一轮冒泡,可以理解为把当前要比较范围内的最值一路冒到了最边上。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









