







import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Crime {
private static class CMapper extends Mapper<LongWritable , Text, Text, Text>{
Text dis=new Text();
Text cnumber =new Text();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String line = value.toString();
String[] l = line.split(“,”);
dis.set(l[11]);
cnumber.set(l[1]);
context.write(dis, cnumber);
}
}
public static class CReduce extends Reducer<Text, Text, Text, IntWritable>{
private int sum=0;
public void reduce(Text key, Iterable
for(Text t : values){
sum=sum+1;
}
context.write(new Text(key),new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf,“crime1”);
job.setJobName(“crime1”);
job.setJarByClass(Crime.class);
job.setMapperClass(CMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(CReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}

这里是按从小到大的顺序进行警区的排序,由此看出犯罪数量最少的警区是警区1,犯罪数量最多的是警区934,判断出来警区1 的治安比较好。


2.这里是按警区进行分组,然后统计每一组的逮捕数量,逮捕数量即为警察在案件发生后,成功抓捕犯罪人员的次数。逮捕数量高,说明这个警区的警察抓捕成功率更高,更容易抓到犯罪人员。
//这里的代码实现的是按地区District进行分组,然后统计逮捕数
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Crime {
private static class CMapper extends Mapper<LongWritable , Text, Text, IntWritable>{
Text dis=new Text();
//private final static IntWritable one = new IntWritable();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String line = value.toString();
String[] l = line.split(“,”);
dis.set(l[11]);
String arr=l[8];
String a =“FALSE”;
int b=0;
if (arr.equals(a)){
b=1;
}
else {
b=0;
}
if(b==0){
context.write(dis, new IntWritable(1));
}
}
}
public static class CReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException{
int count = 0;
for (IntWritable val : values) {
count = count +val.get();
}
context.write(new Text(key), new IntWritable(count));
}
}
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf,“crime1”);
job.setJobName(“crime1”);
job.setJarByClass(Crime.class);
job.setMapperClass(CMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(CReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}

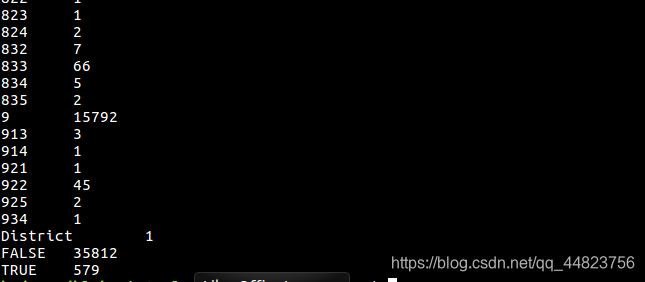
3.将上面两个分析的结果文件合并在一起,文件合并,合并后的文件名称为ave
import java.io.IOException;
import java.util.Vector;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Crime {
private static class CMapper extends Mapper<LongWritable , Text, Text, Text>{
private FileSplit inputsplit;
int cnum=0;
int arr1=0;
Text dis=new Text();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
inputsplit = (FileSplit)context.getInputSplit();
String filename = inputsplit.getPath().getName();
if(filename.contains(“cnumber”)){
String s1 = value.toString();
String[] split1 = s1.split(“\t”);
dis=new Text(split1[0]);
cnum=Integer.parseInt(split1[1]);
context.write(dis, new Text(“cnumber”+cnum));
}
if(filename.contains(“arr”)){
String s2 = value.toString();
String[] split2 = s2.split(“\t”);
dis=new Text(split2[0]);
arr1=Integer.parseInt(split2[1]);
context.write(dis, new Text(“arr”+arr1));
}
}
}
public static class CReduce extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException{
Vector a = new Vector();
Vector b = new Vector();
for(IntWritable value : values){
String line = value.toString();
if(line.startsWith(“cnumber”)){
a.add(line.substring(“cnumber”.length()));
}
if(line.startsWith(“arr”)){
b.add(line.substring(“arr”.length()));
}
}
for(String w1 : a) {
for(String w2 : b){
context.write(new Text(key+“/t”+w1),new Text(w2));
}
}
}
总结
虽然我个人也经常自嘲,十年之后要去成为外卖专员,但实际上依靠自身的努力,是能够减少三十五岁之后的焦虑的,毕竟好的架构师并不多。
架构师,是我们大部分技术人的职业目标,一名好的架构师来源于机遇(公司)、个人努力(吃得苦、肯钻研)、天分(真的热爱)的三者协作的结果,实践+机遇+努力才能助你成为优秀的架构师。
如果你也想成为一名好的架构师,那或许这份Java成长笔记你需要阅读阅读,希望能够对你的职业发展有所帮助。

}
}
for(String w1 : a) {
for(String w2 : b){
context.write(new Text(key+“/t”+w1),new Text(w2));
}
}
}
总结
虽然我个人也经常自嘲,十年之后要去成为外卖专员,但实际上依靠自身的努力,是能够减少三十五岁之后的焦虑的,毕竟好的架构师并不多。
架构师,是我们大部分技术人的职业目标,一名好的架构师来源于机遇(公司)、个人努力(吃得苦、肯钻研)、天分(真的热爱)的三者协作的结果,实践+机遇+努力才能助你成为优秀的架构师。
如果你也想成为一名好的架构师,那或许这份Java成长笔记你需要阅读阅读,希望能够对你的职业发展有所帮助。
[外链图片转存中…(img-1l8mrUWm-1714141607539)]















 1766
1766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









