







} catch (IOException e) {
e.printStackTrace();
}
}
try (InputStream input = new FileInputStream(f);
OutputStream output = new FileOutputStream(t)) {
int fLenght = (int) f.length();
byte[] data = new byte[fLenght];
System.out.println("文件长度为" + fLenght);
int n;
while ((n = input.read(data)) != -1) {
output.write(data);
}
}
}
##### Filter模式(或者装饰器模式:Decorator)
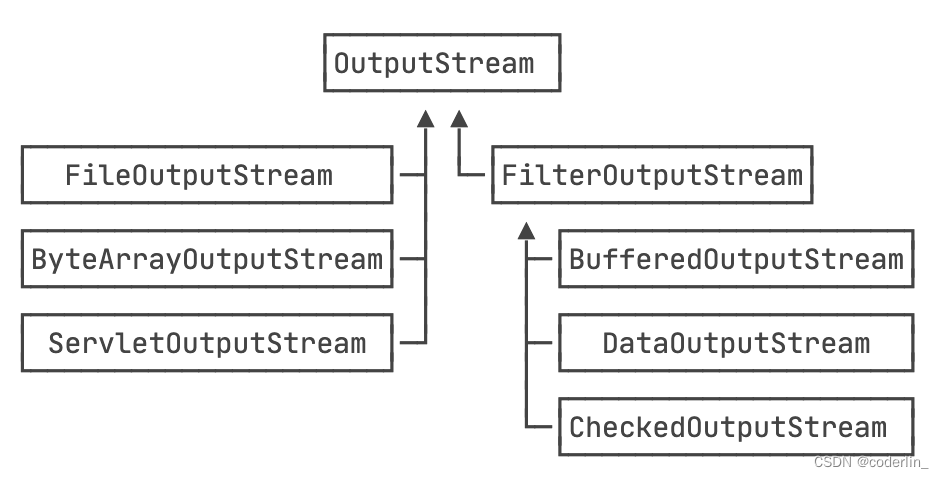
当我们需要给一个“基础”InputStream附加各种功能时,我们先确定这个能提供数据源的InputStream,因为我们需要的数据总得来自某个地方,例如,FileInputStream,数据来源自文件:
InputStream file = new FileInputStream(“test.gz”)
我们希望FileInputStream能提供缓冲的功能来提高读取的效率,因此我们用BufferedInputStream包装这个InputStream,得到的包装类型是BufferedInputStream,但它仍然被视为一个InputStream:
InputStream buffered = new BufferedInputStream(file);
最后,如果这个文件已经被gzip压缩,我们可以封装一个`GZIPInputStream`,
InputStream gzip = new GZIPInputStream(buffered);
无论我们封装多少次,得到的对象始终是InputStream,我们直接用InputStream来引用它,就可以正常读取

上述这种通过一个“基础”组件再叠加各种“附加”功能组件的模式,称之为`Filter模式(或者装饰器模式:Decorator)`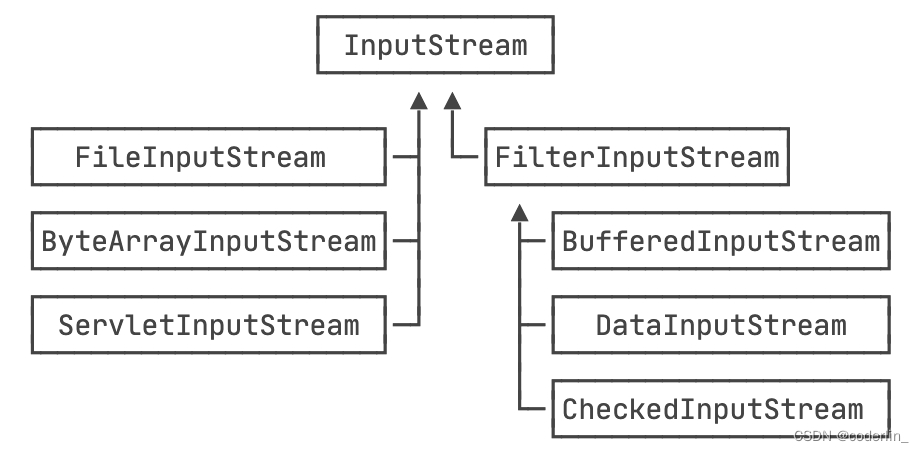
##### 操作Zip
ZipInputStream是一种FilterInputStream,他直接读取zip包的内容。
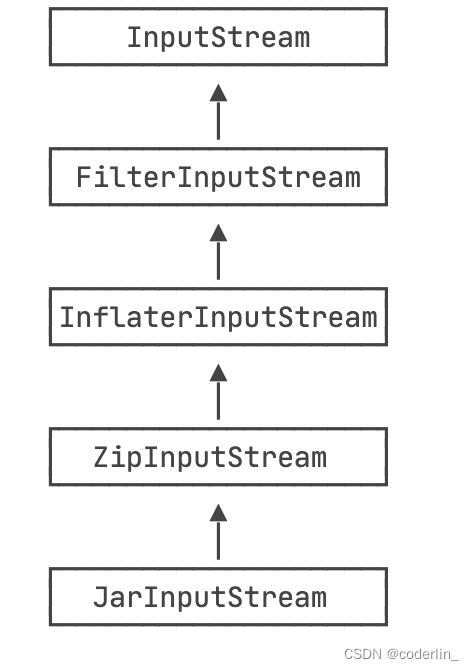
读取
创建一个 ZipInputStream,循环调用getNextEntry(),直到返回null,表示zip流结束
getNextEntry返回一个zipEntry,一个ZipEntry表示一个压缩文件或目录,如果是压缩文件,我们就用read()方法不断读取,直到返回-1
try (ZipInputStream zip = new ZipInputStream(new FileInputStream(…))) {
ZipEntry entry = null;
while ((entry = zip.getNextEntry()) != null) {
String name = entry.getName();
if (!entry.isDirectory()) {
int n;
while ((n = zip.read()) != -1) {
…
}
}
}
}
###### 写入zip包
try (ZipOutputStream zip = new ZipOutputStream(new FileOutputStream(…))) {
File[] files = …
for (File file : files) {
zip.putNextEntry(new ZipEntry(file.getName()));
zip.write(Files.readAllBytes(file.toPath()));
zip.closeEntry();
}
}
##### 序列化
序列化是指把一个Java对象变成二进制内容,本质上就是一个byte[]数组。
为什么需要序列化,因为通过byte[]可以保存到文件,也可以通过网络发送出去。
顾名思义反序列化就是将byte[]数组转位java对象。
###### java对象序列化
要实现序列化,就要实现java.io.Serializ
[video(video-8PGqMbZO-1716354551447)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=1804892953)(image-https://img-blog.csdnimg.cn/img_convert/d03a705143646f4f3f6ea879d59b2788.png)(title-必看视频!获取2024年最新Java开发全套学习资料 备注Java)]
able接口,而Serializable接口没有定义任何方法和属性,
public interface Serializable {
}
它是一个空接口。我们把这样的空接口称为“标记接口”(Marker Interface),实现了标记接口的类仅仅是给自身贴了个“标记”,并没有增加任何方法。
借助ObjectOutputStream,他负责将数据对象写入字节流
public class Main {
public static void main(String[] args) throws IOException {
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
try (ObjectOutputStream output = new ObjectOutputStream(buffer)) {
// 写入int:
output.writeInt(12345);
// 写入String:
output.writeUTF(“Hello”);
// 写入Object:
output.writeObject(Double.valueOf(123.456));
}
System.out.println(Arrays.toString(buffer.toByteArray()));
}
}
打印的buffer是一个byte数组
###### 反序列化
try (ObjectInputStream input = new ObjectInputStream(…)) {
int n = input.readInt();
String s = input.readUTF();
Double d = (Double) input.readObject();
}
反序列化时,由JVM直接构造出Java对象,不调用构造方法,构造方法内部的代码,在反序列化时根本不可能执行。
##### 字符流 Reader
Reader是IO提供的另一个输入流接口,跟InputStream区别是,InputStream是以字节流为准,单位是byte,而Reader是一个字符流,单位是char。

这个方法读取字符流的下一个字符,并返回字符表示的int(也就是可以用char来转换。),范围是0~65535(char表示范围,像InputStream的byte只能是0-255)。如果已读到末尾,返回-1。
###### FileReader
FileReader是Reader的子类,类似于FileInputStream于InputStream的关系。
// Java8不支持UTF_8
try (Reader reader = new FileReader(“./test.txt”, StandardCharsets.UTF_8)) {
int n;
while ((n = reader.read()) != -1) {
System.out.println((char) n);
}
}
也支持缓冲区读取
try (Reader reader = new FileReader(“./test.txt”)) {
char[] buffer = new char[5];
int n;
// n返回读取的char数
while ((n = reader.read(buffer)) != -1) {
System.out.println(buffer);
}
}
打印结果
hello
worl
d.中文l
###### CharArrayReader
CharArrayReader可以在内存中模拟一个Reader,它的作用实际上是把一个char[]数组变成一个Reader,这和ByteArrayInputStream非常类似:
try (Reader reader = new CharArrayReader(“Hello”.toCharArray())) {
}
###### StringReader
直接把String作为数据源。
try (Reader reader = new StringReader(“Hello”)) {
}
###### Reader和InputStream
普通的Reader实际上是基于InputStream构造的,因为Reader需要从InputStream中读入字节流(byte),然后,根据编码设置,再转换为char就可以实现字符流。如果我们查看FileReader的源码,它在内部实际上持有一个FileInputStream;
InputStreamReader可以把任务InputStream转位Reader
// 持有InputStream:
InputStream input = new FileInputStream(“src/readme.txt”);
// 变换为Reader:
Reader reader = new InputStreamReader(input, “UTF-8”);
##### Writer
Reader是带编码转换器的InputStream,它把byte转换为char,而Writer就是带编码转换器的OutputStream,它把char转换为byte并输出(把char转位byte然后写进去)。

Writer是所有字符输出流的超类,它提供的方法主要有:
* 写入一个字符(0~65535):void write(int c);
* 写入字符数组的所有字符:void write(char[] c);
* 写入String表示的所有字符:void write(String s)。
###### FileWirter
跟FileReader类似
try (Reader reader = new FileReader("./test.txt"); Writer writer = new FileWriter("./test2.txt")) {
char[] buffer = new char[5];
int n;
while ((n = reader.read(buffer)) != -1) {
System.out.println("正在写入数据" + buffer);
writer.write(buffer);
}
System.out.println("写入成功");
}
###### CharArrayWriter
CharArrayWriter可以在内存中创建一个Writer,它的作用实际上是构造一个缓冲区,可以写入char,最后得到写入的char[]数组,这和ByteArrayOutputStream非常类似:
try (CharArrayWriter writer = new CharArrayWriter()) {
writer.write(65);
writer.write(66);
writer.write(67);
char[] data = writer.toCharArray(); // { ‘A’, ‘B’, ‘C’ }
}
内存中创建一个Writer,模拟写入。
###### StringWriter
StringWriter也是一个基于内存的Writer,它和CharArrayWriter类似。实际上,StringWriter在内部维护了一个StringBuffer,并对外提供了Writer接口。
###### OutputStreamWriter
与InputStreamReader相似。OutputStreamWriter可以讲OutputStream转位Writer
try (Writer writer = new OutputStreamWriter(new FileOutputStream(“readme.txt”), “UTF-8”)) {
// TODO:
}
###### 小结
* inputStream用户读取文件的字节流,单位是byte,read方法返回字节的int表示(0-255)
* Reader基于InputStream封装,他是以char为单位的字符流,read方法返回char的int表示,可以用(char) n来转换返回的数据。
* outputStream用户用来写入的字节流,单位是byte。
* Writer是基于outputStream封装的字符流,单位是char。
* InputStream: FileInputStream. ByteArrayInputStream
* outStream: FIleOutputStream byteArrayOutputStream
* Reader: FIleReader CharByteReader StringReader InputStreamReader(InputStream->Reader)
* Writer: FileWriter charByteWriter StringWriter OutputStreamWriter(OutputStream->Writer)
##### PrintStream和PrintWriter
`PrintStream是一种FilterOutputStream,它在OutputStream的接口上,额外提供了一些写入各种数据类型的方法:`
* 写入int:print(int)
* 写入boolean:print(boolean)
* 写入String:print(String)
* 写入Object:print(Object),实际上相当于print(object.toString())
…
以及对应的一组println()方法,它会自动加上换行符。
看着很像System.out.xxx
事实上`System.out.println()`实际上就是使用`PrintStream`打印各种数据。其中,`System.out`是系统默认提供的`PrintStream`
PrintStream和OutputStream相比,除了添加了一组print()/println()方法,可以打印各种数据类型,比较方便外,它还有一个额外的优点,就是不会抛出IOException,这样我们在编写代码的时候,就不必捕获IOException。
###### 有PirntStream就有PrintWriter,
PrintStream最终输出的总是byte数据,而PrintWriter则是扩展了Writer接口,它的print()/println()方法最终输出的是char数据。
public class Main {
public static void main(String[] args) {
StringWriter buffer = new StringWriter();
try (PrintWriter pw = new PrintWriter(buffer)) {
pw.println(“Hello”);
pw.println(12345);
pw.println(true);
}
System.out.println(buffer.toString());
}
}
小结
`PrintStream是一种能接收各种数据类型的输出,打印数据时比较方便:`
* System.out是标准输出;
* System.err是标准错误输出。
`PrintWriter是基于Writer的输出。`
##### Files
虽然Files是java.nio包里面的类,但他俩封装了很多读写文件的简单方法,极大的方便了我们读写文件。
byte[] data = Files.readAllBytes(Path.of(“/path/to/file.txt”));
// 默认使用UTF-8编码读取:
String content1 = Files.readString(Path.of(“/path/to/file.txt”));
// 可指定编码:
String content2 = Files.readString(Path.of(“/path”, “to”, “file.txt”), StandardCharsets.ISO_8859_1);
// 按行读取并返回每行内容:
List lines = Files.readAllLines(Path.of(“/path/to/file.txt”));
Files.readString是java11后支持的
###### 写入文件
// 写入二进制文件:
byte[] data = …
Files.write(Path.of(“/path/to/file.txt”), data);
// 写入文本并指定编码:
Files.writeString(Path.of(“/path/to/file.txt”), “文本内容…”, StandardCharsets.ISO_8859_1);
// 按行写入文本:
List lines = …
Files.write(Path.of(“/path/to/file.txt”), lines);
Files工具类还有copy()、delete()、exists()、move()等快捷方法操作文件和目录。
>
> Files提供的读写方法,受内存限制,只能读写小文件,例如配置文件等,不可一次读入几个G的大文件。读写大型文件仍然要使用文件流,每次只读写一部分文件内容。
>
>
>
# 总结:心得体会
既然选择这个行业,选择了做一个程序员,也就明白只有不断学习,积累实战经验才有资格往上走,拿高薪,为自己,为父母,为以后的家能有一定的经济保障。
学习时间都是自己挤出来的,短时间或许很难看到效果,一旦坚持下来了,必然会有所改变。不如好好想想自己为什么想进入这个行业,给自己内心一个答案。
面试大厂,最重要的就是夯实的基础,不然面试官随便一问你就凉了;其次会问一些技术原理,还会看你对知识掌握的广度,最重要的还是你的思路,这是面试官比较看重的。
最后,上面这些大厂面试真题都是非常好的学习资料,通过这些面试真题能够看看自己对技术知识掌握的大概情况,从而能够给自己定一个学习方向。包括上面分享到的学习指南,你都可以从学习指南里理顺学习路线,避免低效学习。
**大厂Java架构核心笔记(适合中高级程序员阅读):**

的大文件。读写大型文件仍然要使用文件流,每次只读写一部分文件内容。
>
>
>
# 总结:心得体会
既然选择这个行业,选择了做一个程序员,也就明白只有不断学习,积累实战经验才有资格往上走,拿高薪,为自己,为父母,为以后的家能有一定的经济保障。
学习时间都是自己挤出来的,短时间或许很难看到效果,一旦坚持下来了,必然会有所改变。不如好好想想自己为什么想进入这个行业,给自己内心一个答案。
面试大厂,最重要的就是夯实的基础,不然面试官随便一问你就凉了;其次会问一些技术原理,还会看你对知识掌握的广度,最重要的还是你的思路,这是面试官比较看重的。
最后,上面这些大厂面试真题都是非常好的学习资料,通过这些面试真题能够看看自己对技术知识掌握的大概情况,从而能够给自己定一个学习方向。包括上面分享到的学习指南,你都可以从学习指南里理顺学习路线,避免低效学习。
**大厂Java架构核心笔记(适合中高级程序员阅读):**
[外链图片转存中...(img-JWZJ1dGS-1716456340041)]















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









