






神经网络是深度学习的基础,正是深度学习的兴起,让停滞不前的人工智能再一次的取得飞速的发展。
其实神经网络的理论由来已久,灵感来自仿生智能计算,只是以前限于硬件的计算能力,没有突出的表现,
直至谷歌的AlphaGO的出现,才让大家再次看到神经网络相较于传统机器学习的优异表现。
本文主要介绍神经网络中的重要基础概念,然后基于这些概念手工实现一个简单的神经网络。
希望通过理论结合实践的方式让大家更容易的理解神经网络。
1. 神经网络是什么
神经网络就像人脑一样,整体看上去非常复杂,但是其基础组成部分并不复杂。
其组成部分中最重要的就是神经元(neural),sigmod函数和层(layer)。
1.1. 神经元
神经元(neural)是神经网络最基本的元素,一个神经元包含3个部分:
-
获取输入:获取多个输入的数据
-
数学处理:对输入的数据进行数学计算
-
产生输出:计算后多个输入数据变成一个输出数据
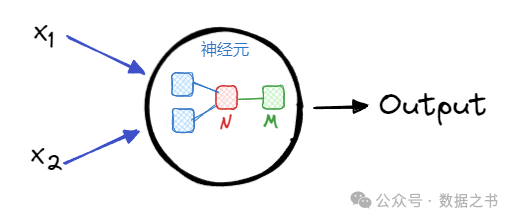
从上图中可以看出,神经元中的处理有2个步骤。
**第一个步骤:**从蓝色框变成红色框,是对输入的数据进行加权计算后合并为一个值(N)。
其中,分别是输入数据的权重。
一般在计算的过程中,除了权重,还会加上一个偏移参数,最终得到:
第二个步骤:从红色框变成绿色框,通过sigmoid函数是对N进一步加工得到的神经元的最终输出(M)。
1.2. sigmoid函数
sigmoid函数也被称为S函数,因为的形状类似S形。
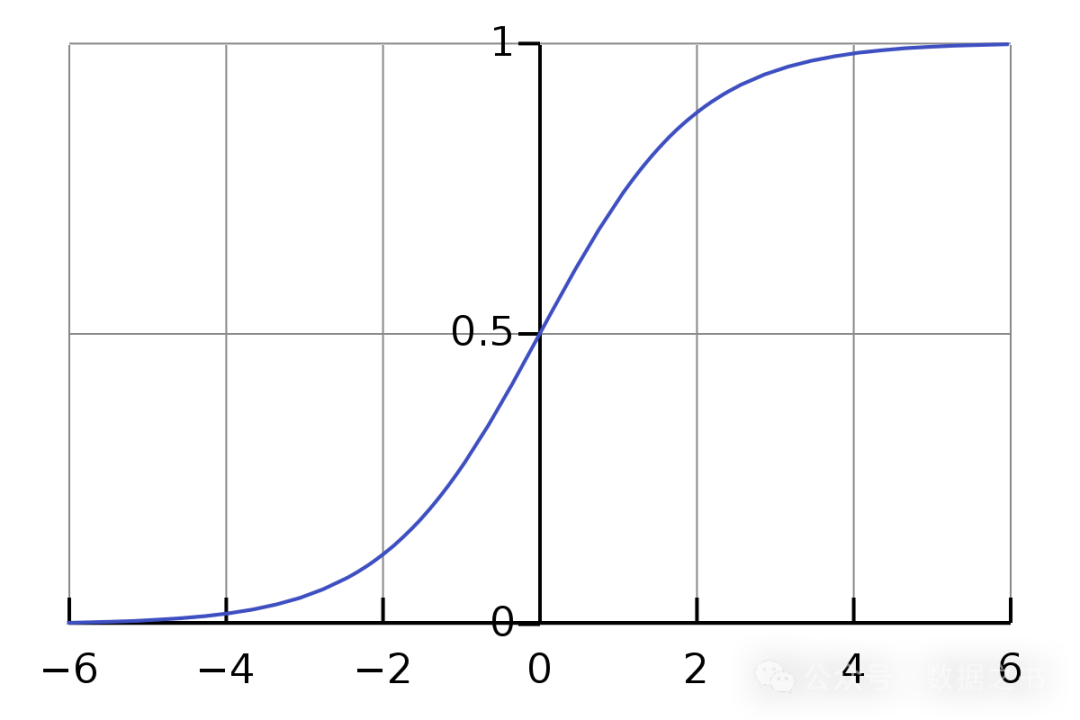
它是神经元中的重要函数,能够将输入数据的值映射到之间。
最常用的sigmoid函数是 ,当然,不是只有这一种sigmoid函数。
至此,神经元通过两个步骤,就把输入的多个数据,转换为一个之间的值。
1.3. 层
多个神经元可以组合成一层,一个神经网络一般包含一个输入层和一个输出层,以及多个隐藏层。
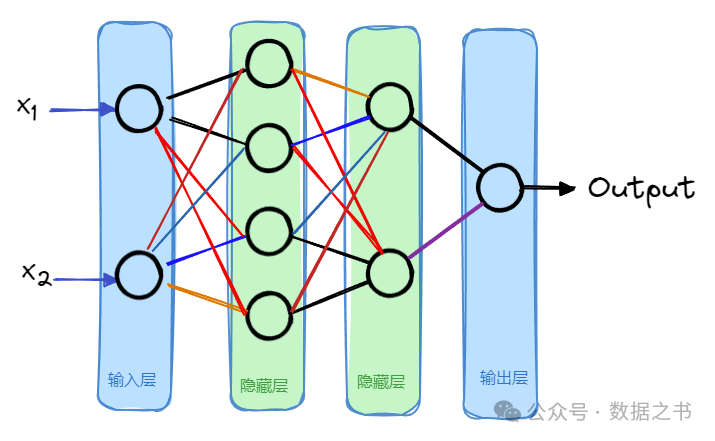
比如上图中,有2个隐藏层,每个隐藏层中分别有4个和2个神经元。
实际的神经网络中,隐藏层数量和其中的神经元数量都是不固定的,根据模型实际的效果来进行调整。
1.4. 网络
通过神经元和层的组合就构成了一个网络,神经网络的名称由此而来。
神经网络可大可小,可简单可复杂,不过,太过简单的神经网络模型效果一般不会太好。
因为一只果蝇就有10万个神经元,而人类的大脑则有大约1000亿个神经元,
这就是为什么训练一个可用的神经网络模型需要庞大的算力,这也是为什么神经网络的理论1943年就提出了,
但是基于深度学习的AlphaGO却诞生于2015年。
2. 实现一个神经网络
了解上面的基本概念只能形成一个感性的认知。
下面通过自己动手实现一个最简单的神经网络,来进一步认识神经元,sigmoid函数以及隐藏层是如何发挥作用的。
2.1. 准备数据
数据使用sklearn库中经典的鸢尾花数据集,这个数据集中有3个分类的鸢尾花,每个分类50条数据。
为了简化,只取其中前100条数据来使用,也就是取2个分类的鸢尾花数据。
from sklearn.datasets import load_iris ds = load_iris(as_frame=True, return_X_y=True) data = ds[0].iloc[:100] target = ds[1][:100] print(data) print(target)
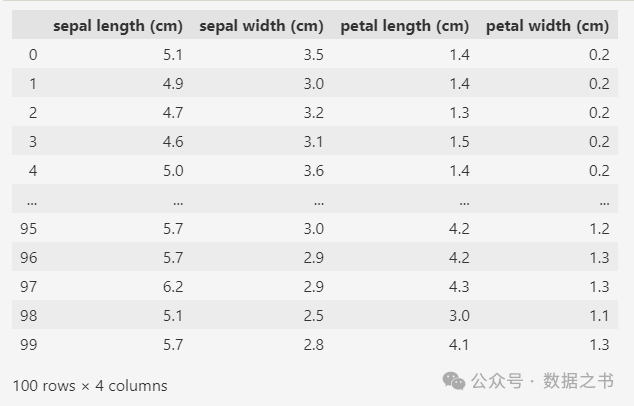
变量data中100条数据,每条数据包含4个属性,分别是花萼的宽度和长度,花瓣的宽度和长度。

变量target中也是100条数据,只有0和1两种值,表示两种不同种类的鸢尾花。
2.2. 实现神经元
准备好了数据,下面开始逐步实现一个简单的神经网络。
首先,实现最基本的单元–神经元。
本文第一节中已经介绍了神经元中主要的2个步骤,分别计算出和。
计算时,依据每个输入元素的权重()和整体的偏移;
计算时,通过sigmoid函数。
def sigmoid(x): return 1 / (1 + np.exp(-1 * x)) @dataclass class Neuron: weights: list[float] = field(default_factory=lambda: []) bias: float = 0.0 N: float = 0.0 M: float = 0.0 def compute(self, inputs): self.N = np.dot(self.weights, inputs) + self.bias self.M = sigmoid(self.N) return self.M
上面的代码中,Neuron类表示神经元,这个类有4个属性:
其中属性weights和bias是计算时的权重和偏移;
属性N和M分别是神经元中两步计算的结果。
Neuron类的compute方法根据输入的数据计算神经元的输出。
2.3. 实现神经网络
神经元实现之后,下面就是构建神经网络。
我们的输入数据是带有4个属性(花萼的宽度和长度,花瓣的宽度和长度)的鸢尾花数据,
所以神经网络的输入层有4个值()。
为了简单起见,我们的神经网络只构建一个隐藏层,其中包含3个神经元。
最后就是输出层,输出层最后输出一个值,表示鸢尾花的种类。
由此形成的简单神经网络如下图所示:
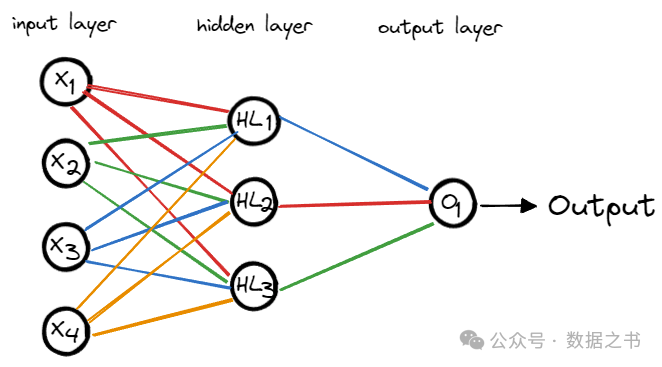
实现的代码:
@dataclass class MyNeuronNetwork: HL1: Neuron = field(init=False) HL2: Neuron = field(init=False) HL3: Neuron = field(init=False) O1: Neuron = field(init=False) def __post_init__(self): self.HL1 = Neuron() self.HL1.weights = np.random.dirichlet(np.ones(4)) self.HL1.bias = np.random.normal() self.HL2 = Neuron() self.HL2.weights = np.random.dirichlet(np.ones(4)) self.HL2.bias = np.random.normal() self.HL3 = Neuron() self.HL3.weights = np.random.dirichlet(np.ones(4)) self.HL3.bias = np.random.normal() self.O1 = Neuron() self.O1.weights = np.random.dirichlet(np.ones(3)) self.O1.bias = np.random.normal() def compute(self, inputs): m1 = self.HL1.compute(inputs) m2 = self.HL2.compute(inputs) m3 = self.HL3.compute(inputs) output = self.O1.compute([m1, m2, m3]) return output
MyNeuronNetwork类是自定义的神经网络,其中的属性是4个神经元。
HL1,HL2,HL3是隐藏层的3个神经元;O1是输出层的神经元。
__post__init__函数是为了初始化各个神经元。
因为输入层是4个属性(),所以神经元HL1,HL2,HL3的weights初始化为4个随机数组成的列表,
偏移(bias)用一个随时数来初始化。
对于神经元O1,它的输入是隐藏层的3个神经元,所以它的weights初始化为3个随机数组成的列表,
偏移(bias)还是用一个随时数来初始化。
最后还有一个compute函数,这个函数描述的就是整个神经网络的计算过程。
首先,根据输入层()的数据计算隐藏层的神经元(HL1,HL2,HL3);
然后,以隐藏层的神经元(HL1,HL2,HL3)的输出作为输出层的神经元(O1)的输入,并将O1的计算结果作为整个神经网络的输出。
2.4. 训练模型
上面的神经网络中各个神经元的中的参数(主要是weights和bias)都是随机生成的,
所以直接使用这个神经网络,效果一定不会很好。
所以,我们需要给神经网络(MyNeuronNetwork类)加一个训练函数,用来训练神经网络中各个神经元的参数(也就是个各个神经元中的weights和bias)。
@dataclass class MyNeuronNetwork: # 略... def train(self, data: pd.DataFrame, target: pd.Series): ## 使用 随机梯度下降算法来训练 pass
上面的train函数有两个参数data(训练数据)和target(训练数据的标签)。
我们使用随机梯度下降算法来训练模型的参数。
这里略去了具体的代码,完整的代码可以在文章的末尾下载。
此外,再实现一个预测函数predict,传入测试数据集,
然后用我们训练好的神经网络模型来预测测试数据集的标签。
@dataclass class MyNeuronNetwork: # 略... def predict(self, data: pd.DataFrame): results = [] for idx, row in enumerate(data.values): pred = self.compute(row) results.append(round(pred)) return results
2.5. 验证模型效果
最后就是验证模型的效果。
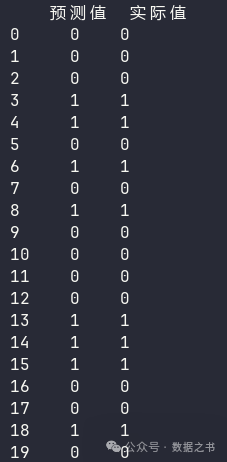
def main(): # 加载数据 ds = load_iris(as_frame=True, return_X_y=True) # 只用前100条数据 data = ds[0].iloc[:100] target = ds[1][:100] # 划分训练数据,测试数据 # test_size=0.2 表示80%作为训练数据,20%作为测试数据 X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2) # 创建神经网络 nn = MyNeuronNetwork() # 用训练数据集来训练模型 nn.train(X_train, y_train) # 检验模型 # 用训练过的模型来预测测试数据的标签 results = nn.predict(X_test) df = pd.DataFrame() df["预测值"] = results df["实际值"] = y_test.values print(df)
运行结果可以看出,模型的效果还不错,20条测试数据的预测结果都正确。
3. 总结
本文中的的神经网络示例是为了介绍神经网络的一些基本概念,所以对神经网络做了尽可能的简化,为了方便去手工实现。
而实际环境中的神经网络,不仅神经元的个数,隐藏层的数量极其庞大,而且其计算和训练的方式也很复杂,手工去实现不太可能,
一般会借助TensorFlow,Keras和PyTorch等等知名的python深度学习库来帮助我们实现。
4. 代码下载
代码量不大,总共也就200行不到,感兴趣的话可以下载后运行试试。
simple_nn.zip: https://url11.ctfile.com/f/45455611-1242350800-e67991?p=6872 (访问密码: 6872)

既然大模型现在这么火热,各行各业都在开发搭建属于自己企业的私有化大模型,那么势必会需要大量大模型人才,同时也会带来大批量的岗位?“俗话说站在风口,猪都能飞起来”可以说大模型这对于我们来说就是一个机会,一个可以改变自身的机会,就看我们能不能抓住了。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









