






今天,是2022年的第一个工作日。
每年的元旦节前后,都会是Python兼职接单的小高潮,这段时间各个行业对爬虫类的需求会暴增,圈子里很多朋友在元旦假期都没闲着,两天赚上万的不在少数。
所以近来问我技术变现+兼职接单问题的朋友也特别多,我把问题总结下来,发现大部分人都有着相同的困惑。

* 技术0基础,想用Python赚钱,不知道要学哪些技术
* 不熟悉主流技术,实战经验较少,想接私活,担心搞不定项目
* 从来没接过私活,没经验担心踩坑
怎样接Python私活?
当初刚学Python,就有朋友来介绍我去接单做私活,我还记得是为一家公司爬数据,那一单我赚了5.5K。从那之后逐渐熟练,在业余时间陆续接了很多数据收集处理的私活,平均每月靠兼职做私活都能赚 2万 左右。
Python技术接单多赚钱快的活,大体上都是爬虫类的。主要是爬取网站、小程序或者APP的数据,对数据进行分析与处理,或者直接向客户提供爬虫程序与技术支持。
重点技术
爬虫,作为接私活用得最多的技术,是兼职必备神技。但很多人都表示爬虫有点复杂,学了很久都没掌握。其实只要掌握了正确的实现思路,爬虫学起来也很快。
首先,先搞清楚爬虫的工作原理。爬虫通常由目标信息网站、页面抓取、页面分析、数据存储四个步骤组成。其爬取网站资源的细节流程如下:

* 导入对应的库用于请求和网页解析
* 再请求网页获得源代码
* 初始化Soup对象
* 用浏览器打开目标网页
* 定位所需要的资源的位置
* 然后分析该位置的源代码
* 找到用于定位的标签及属性
* 最后编写解析代码获得想要的资源
常见技术问题
当我们熟悉原理和流程后,实现起爬虫来也就游刃有余了,一般网站的数据都可以轻松爬取。
当然,这并不意味着这就够了,掌握基础爬虫,的确可以在不设防的小网站中随意获得资源,可真正有价值的资源,往往都在有着完善反爬虫措施的大型站点中。
这时,就到了Python爬虫学习的重点环节——网站反爬虫策略及其应对方案。这里说一说常见的主流反爬措施:

* 目标检测出是爬虫封了IP
* 目标返回了加密过的数据
* 目标返回了脏数据,无法辨认
* 目标网站必须登录才能访问
* Javascript动态渲染,爬虫无法读取
* 目标网站有验证码无法访问
* ajax异步传输,爬虫抓取到空信息
* 图片伪装与混淆+CSS偏移+SVG映射

搞不定这些问题,就无法完全掌握Python爬虫技术,尤其是各种反爬虫的措施,已经成为我们爬取数据的最大障碍。
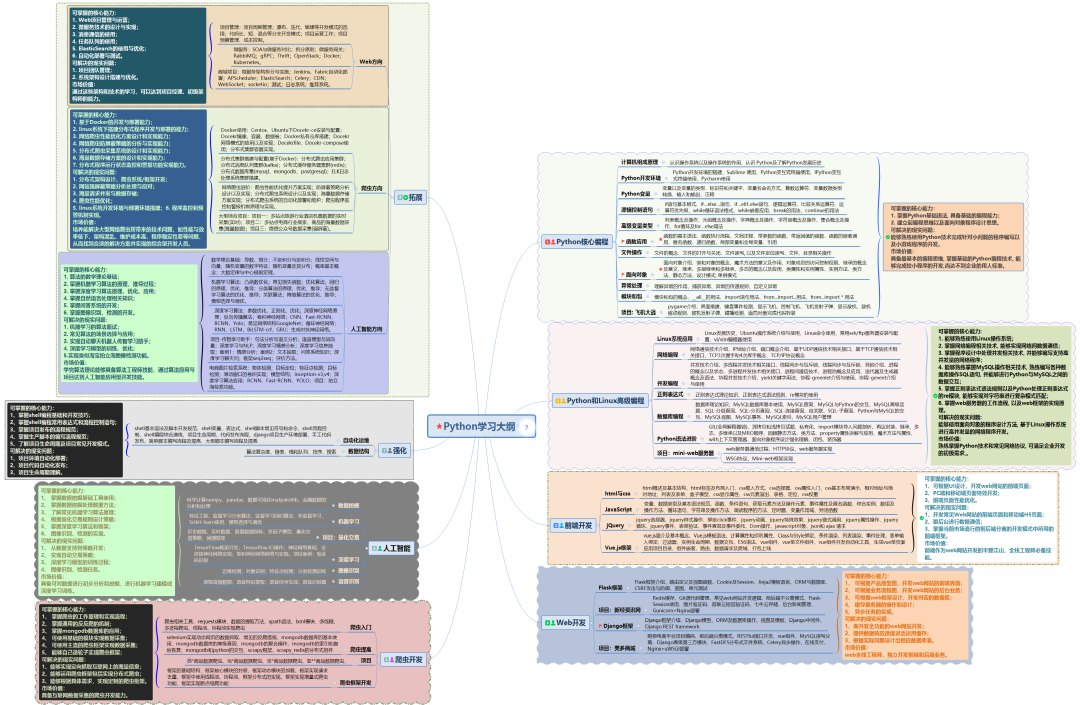
对于从来没有接触过编程的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
👉Python学习大纲👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉Python书籍和视频合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
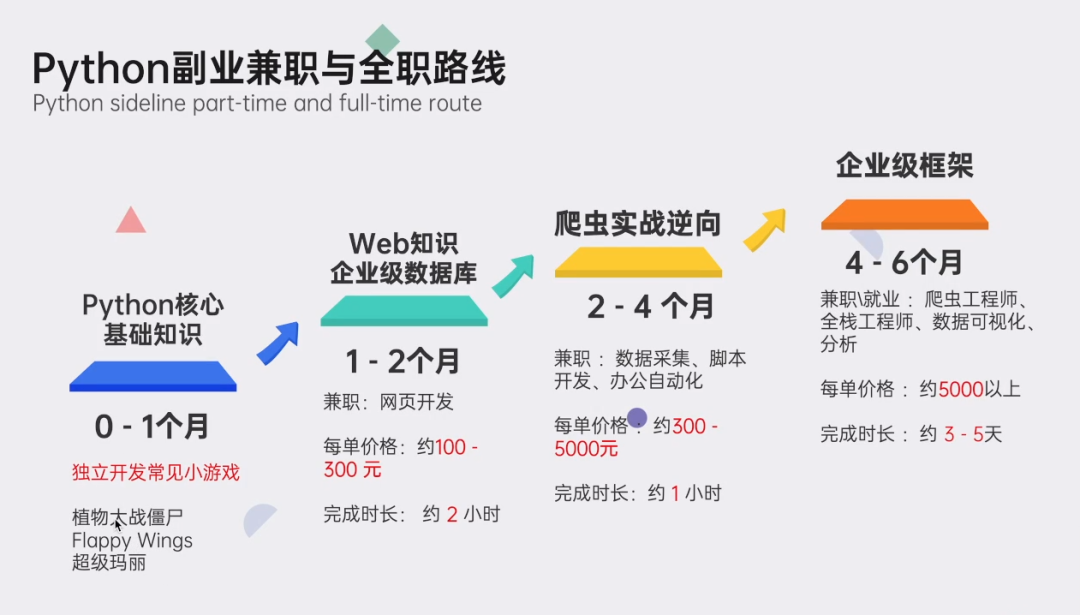
👉Python副业创收路线👈
这些资料都是非常不错的,朋友们如果有需要《Python学习路线&学习资料》,点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
如有侵权,请联系删除。















 110
110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









