






AI,其实是科学家理解和重构人类智能的产物,人们期待它像人一样理解和探索未知事物,进而发展生产力、延续人类文明。

当前AI已形成三大学派,即符号主义、连接主义、行为主义。符号主义又称逻辑主义、心理学派或计算机学派。该学派认为AI源于数理逻辑,经过大半个世纪的发展,符号主义依然是AI的主流派别。连接主义又称仿生学派或生理学派,该学派认为AI源于仿生学,特别是对人脑模型的研究。连接主义通过研究脑模型和模拟神经元,构建人工神经网络模型,开辟出AI发展的另一种途径。卷积神经网络、深度信念网络、深度神经网络训练方法等理论相继提出,这将连接主义的发展带入高潮。基于深度神经网络的方法在21世纪初给计算机视觉、语音识别、语义理解等领域带来了应用突破,使大量应用成功落地。行为主义又称进化主义或控制论学派。这个学派认为,AI源于控制论,即基于感知、控制和行为反馈的系统。控制论将信息论、神经系统、逻辑和计算机联系在一起,模拟人类在控制过程中的智能行为,如自寻优、自适应、自学习等。对控制论系统的研究为智能控制和智能机器人打下基础,推动了20世纪80年代智能控制和智能机器人系统的诞生。

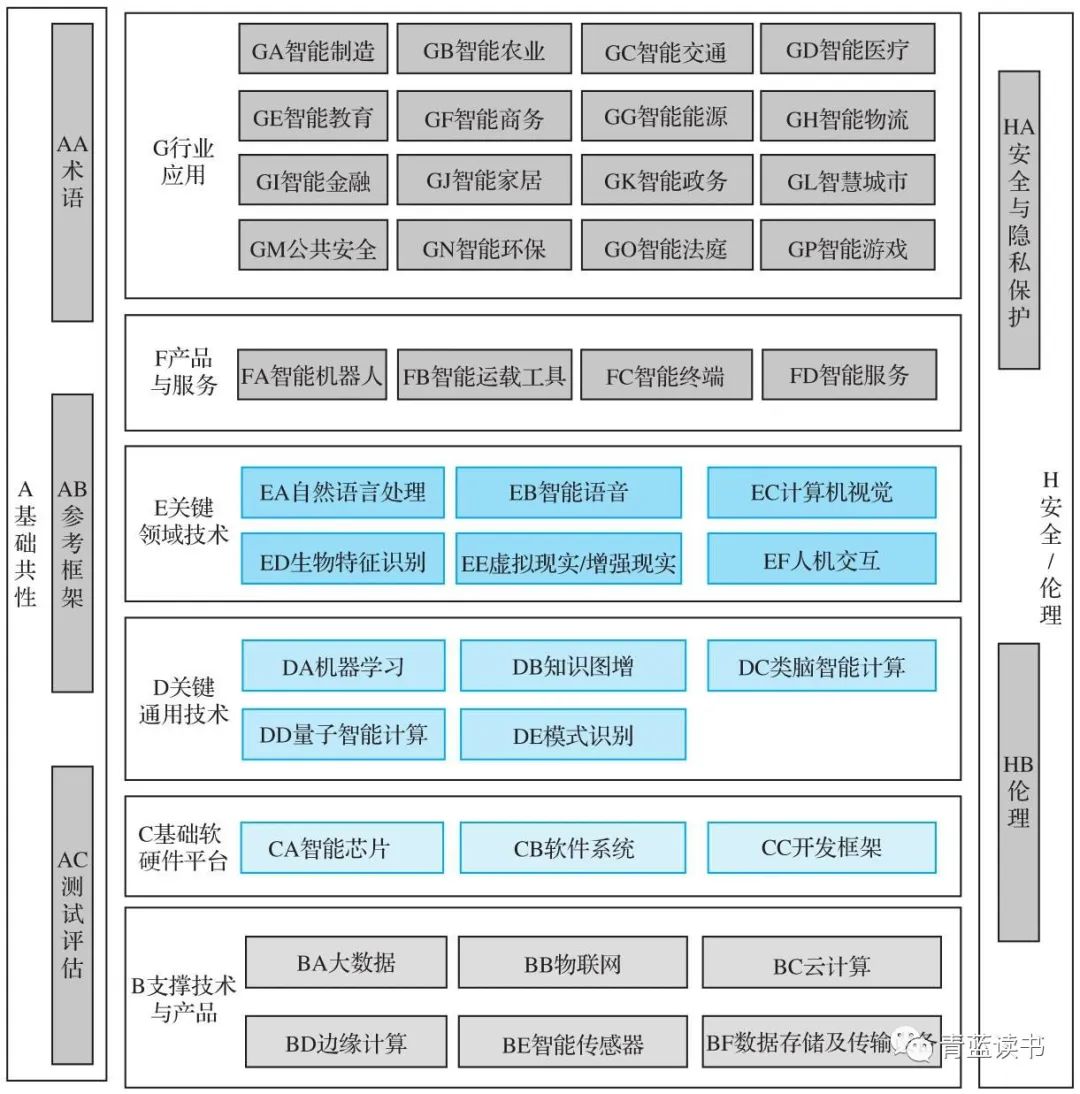
随着产业规模的扩大,协作越来越频繁,所以标准化成为政策中的一个高频词。
笔者认为AI落地产品可以分为两大类:第一类是以降本增效为主的产品,第二类是以增加愉悦度为主的产品。第一类AI的作用在于替代、改造生产流程,从而提升生产效率。通俗地讲就是人能做,AI也能做,但是AI做得更快更好。除了技术实现上的直接困难,还有几个基础性的难题——成本高、隐私难把控、安全有隐患。
这些难题指向的解决方法是:更廉价的算力、更高精度的算法,以及数据依赖更少、隐私保护更强的机制。当我们大谈场景落地时,需要有可行性研究的意识,这种意识不可只落在技术可行性上,还应考虑经济(市场)的可行性、安全的可行性和法律的可行性。
对于产品经理来说,要懂的是产品实现的核心技术逻辑、流程、路径和边界,目的是界定产品范围。对于业务和行业中不同的问题,一般可以通过变换技术手段来解决,当所用技术手段受限时,也可以通过产品规则规避。理解技术的局限性后,会在寻找解决问题的方案上更加游刃有余。当一项产品技术成熟时,技术创新的权重就降低了,而商业模式和业务创新的权重将升高。
在当下许多AI业务流程中,算法都是作为独立的职能模块进行开发,AI产品经理在懂得基本的软件产品技术原理之外,还应该了解相应的算法维度的知识,具体包括:
□ 以深度学习为代表的算法的整体流程和基本原理;
□ AI产品中算法的效果;
□ 选择和权衡算力,实现算法和算力之间的配合;
□ 从数据层面定义业务,完成算法功能边界的定义。
AI不能算一个行业,只能赋能到某个行业,因此,还应该找到一个纵深的赛道,比如安防赛道、交通赛道,然后深入理解行业业务,只有这样才能更好地实现AI为行业的赋能。
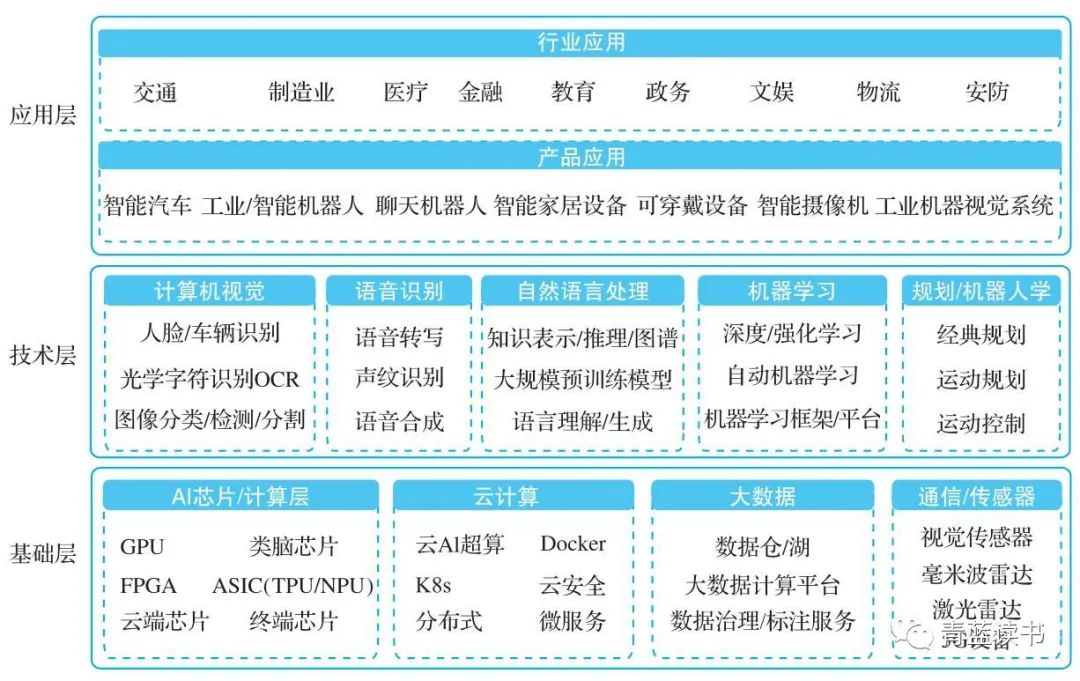
AI技术认知主要包含理论性内容、工程应用两大方面。理论性内容主要包括如机器学习、计算机视觉、语音识别、自然语言处理等算法的应用知识,工程应用主要包括算法任务的定义、模型训练和评价、落地部署应用等相关内容。产品生命周期过程管理关注产品全生命周期中每个环节的基本打造方法,其中涉及的知识是产品经理工作的基础。完整的知识应包括市场感知、产品定义、需求管理、产品设计、产品研发与协同、产品运营及营销等多个维度。
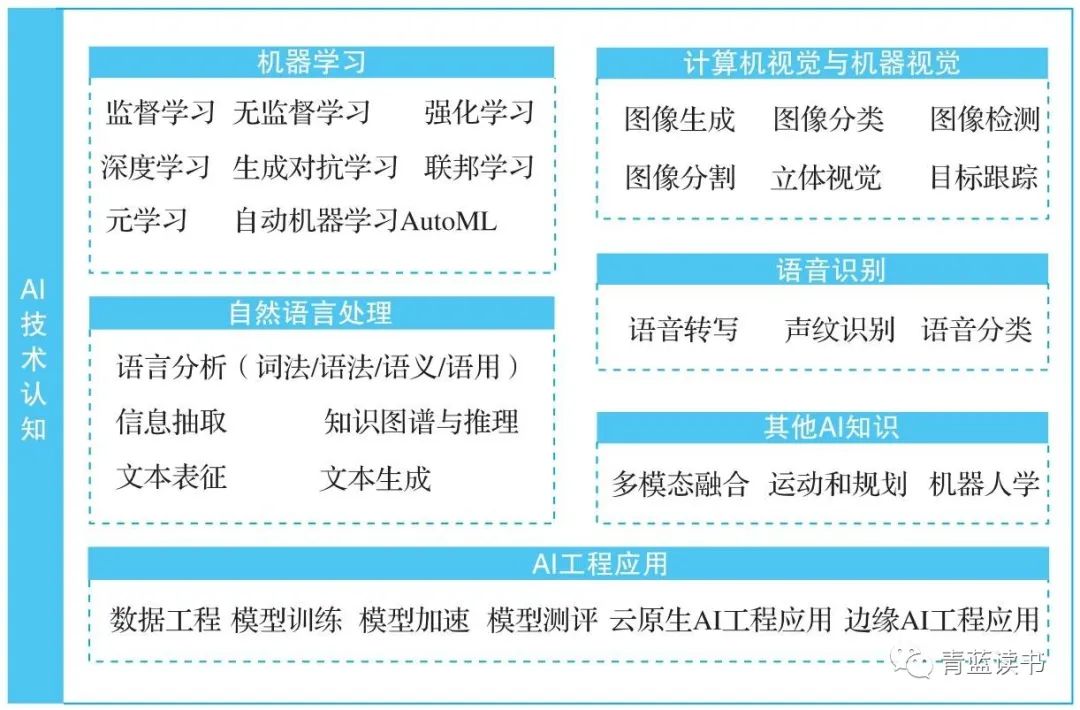
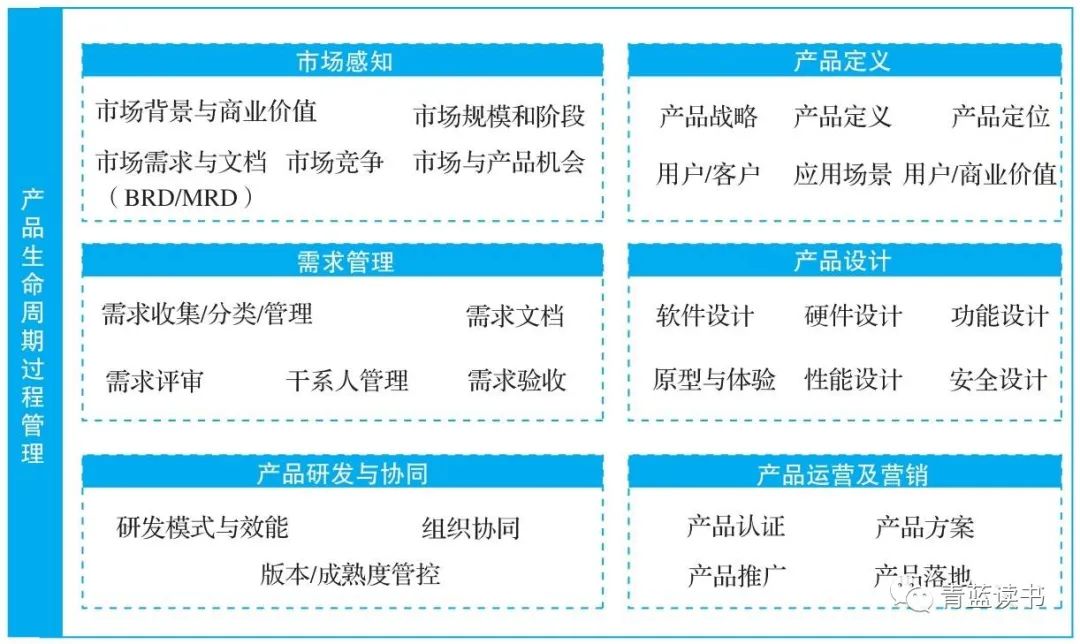
项目管理知识和行业业务知识覆盖特定行业中项目从商机、订单、交付、验收到上线运行的完整过程,涉及行业政策标准、业务理解、项目管理等多个方向。

从图灵测试的角度看,计算机只有具备了感知理解和交流能力(自然语言处理)、在存储交流中获得信息的能力(知识表示)、运用已知的信息回答和交流的能力(自动推理)、学习和适应新情况和模式的能力(机器学习),才能认为它可能是智能的。如果计算机还需要进行物理交互,则还需要具备观察的能力(计算机视觉)、反应和行动的能力(机器人学)等。上述这些能力实现覆盖了大部分AI技术。
AI技术涵盖领域很广,从感知维度看,涵盖了计算机视觉、语音识别、自然语言处理等;从认知维度看,涵盖了知识表示、知识推理等;从行动维度看,涵盖了机器人学、规划、决策等。而“学习”,贯穿了感知、认知和行动这三个维度。
机器学习由三个部分组成,分别是表示、评价和优化。表示是指建立问题与数据的抽象模型。“问题抽象”是对待解决的问题进行抽象化处理,即将问题转换成一道逻辑题或者数学题。比如,判断一张图片中的动物是否为猫,结果无外乎“是”或“不是”两种,那在算法上就可将它看成一个二分类问题,输出就可定义为0或1。“数据抽象”即用数据来刻画物理世界中的事物。
设计好模型之后,最重要的一步就是评价模型的好坏,这个时候就需要设定一个目标函数,该函数用于评估模型的优化目标和模型指标。以对猫的判别为例,在目标函数上,可通过特征向量距离来评价一个图像目标是否像猫。在数据集的准确率上,可以通过“错误率”等指标来评价分类模型。目标函数中存在许多未知参数,求解这些参数,让模型目标函数得到最优结果,即让模型能够获得最小错误率或者最小均方误差。算法优化的过程即逐步调整数据、算法或参数来达到最优目标的过程。
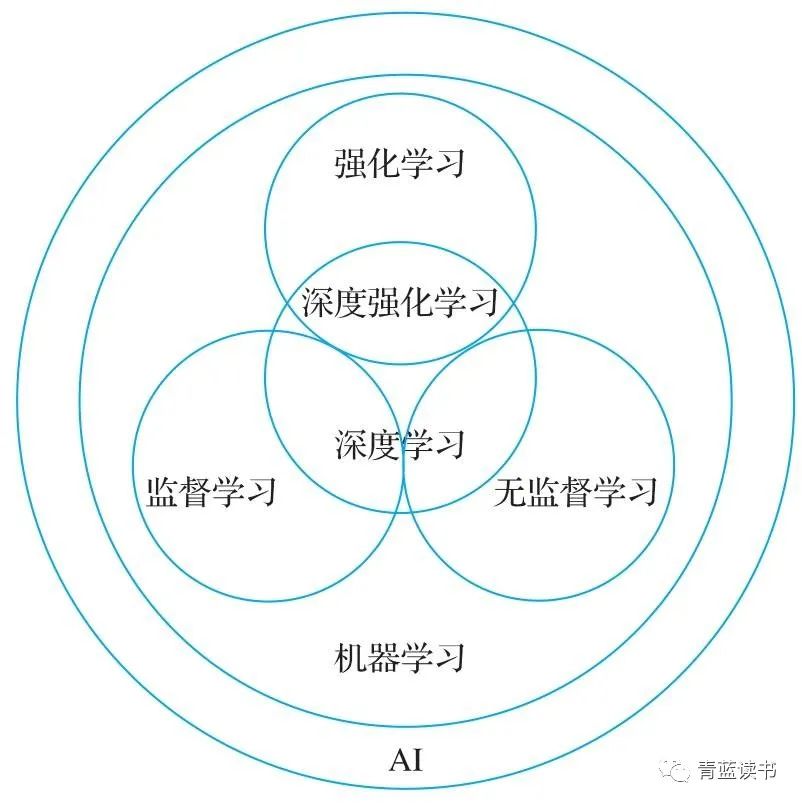
机器学习可以根据多种分类标准进行划分:按照函数的复杂度,机器学习可以分为线性模型和非线性模型;按照学习准则的差异,可以分为统计方法和非统计方法;按照华盛顿大学教授佩德罗·多明戈斯归纳的流派,可以分为符号主义、贝叶斯派、联结主义、进化主义、行为类比主义;按照数据样本提供的信息和反馈方式,可以分为监督学习、无监督学习和强化学习,另外近些年,半监督学习、自监督学习等范式也被提出。
监督学习是一种机器学习方法,即机器通过人工给定的标注。根据输出标签的不同,监督学习要处理的任务可以分为回归任务和分类任务两种。回归任务主要指预测某一实数结果的任务,如预测产品市场价格、股票价格等,使用的主要方法是线性回归。分类任务主要指预测某种样本所属类别的任务,如预测动物的分类、物品的分类等。常见的监督学习算法包括:k-近邻(k-Nearest Neighbors, kNN)算法、决策树、朴素贝叶斯。无监督学习与监督学习最大的不同是,前者不需要人工标注。在现实世界中,大部分数据也是没有被标注的,机器可以根据算法(如聚类、降维等)无监督学习可依靠算法找到数据内在的监督信息。对数据进行处理,实现机器视角的特征归类。在制造业中,由于缺陷的样式多种多样,可通过对正常和异常样本的对比实现产品是否正常的判断。
强化学习也叫增强学习,是智能体与环境通过交互完成序列化的过程,一般由系统环境、智能体(Agent)、状态、行动和奖励五个部分组成。强化学习是通过不断试错和追求最大化长期回报这两个特征来实现的,突破了监督学习标注数据的局限,也突破了非监督学习无法与环境动态交互的局限,为机器学习拓展了实现路径。强化学习十分适合用于决策类的场景,如训练控制算法和游戏AI等。在深度神经网络取得突破性进展之后,两者结合得到的深度强化学习更是助力AlphaGo、AlphaZero等象棋应用打败了人类。
半监督学习是在人工标注数据远远不够的情况下,通过少量标注数据和大量未标注数据进行学习的方式。在应用中,如何应用好大量未标注的数据,得到比应用大量标注数据更好的效果,是半监督学习方法需要关注的。
自监督学习是通过数据本身的标签或者变换得到的标签进行学习的,不需要专门的人工标注的标签。例如将图片中一部分区域遮挡,让机器学习如何恢复。
深度学习是近年来发展最快的机器学习分支。深度学习是深度神经网络及其训练方法的统称。最小可学习的神经网络被称为感知机,多个感知机进行层级连接组合就可以得到多层感知机。多层感知机也就是我们说的人工神经网络,而随着隐藏层的增加,网络深度也在增加,我们称具有两个以上隐藏层的神经网络为深度神经网络。深度学习算法本身是一种优化问题的方法,该方法的优化效果取决于网络结构(建模)和参数。在不同的应用场景中,通过调整网络结构,以及通过数据训练网络参数,可得到最优的应用模型。深度学习可以理解为一套解决问题的数学模型,通过构建公式和学习参数,得到最后的解决问题的表达式。
在云场景中,有丰富且强大的算力用于处理海量数据,在这种场景下深度学习可集中解决中心化的问题,并突破问题的边界;在端场景中,算力、存储小,故这种场景中的深度学习更讲究经济性。在模型维度,“大”路线最具代表性的就是基于Transformer技术路线的超大规模预训练模型(如GPT-3等),该模型追求强大的表征能力;“小”路线最具代表性的是包括MobileNet等在内的一系列用于端场景的模型,该模型关注如何在保持精度的情况下对算力和存储要求更小,并更快得到结果。在算力维度,“大”路线追求如何利用大规模算力快速实现分布式训练、推理;“小”路线追求如何极致利用小算力。在样本维度,“大”路线追求用更多的数据让机器泛化能力更强;“小”路线追求小样本学习,可以举一反“百”。在实际应用中,很多问题的分布是呈长尾性的,训练时看到的仅是80%的类型,而在落地应用过程中,对于处于长尾状态的20%的样本数据,可能模型从来没有见过,这会导致识别效果大幅下降。一直以来,神经网络都是以“黑箱”的形式存在的,当通过该模型对一个样本进行预测时,是由哪一层帮模型得到最终的判断,人们难以得知。深度学习可以在特定的场景中达到极高的精度,但是当模型迁移到相似场景的时候,效果却大大下降。在识别加入特定小扰动的第二张图片时,算法会立刻失效。近年来,许多攻击利用了深度学习这方面的弱点,比如在人脸识别应用中,只要人们戴上一副特制眼镜,系统就无法正确识别人脸了。
两个任务之间的特征和数据分布相似度越高,越适合使用迁移学习。随着模型参数规模不断增大,训练一个基础模型变得越来越昂贵,此时被证明有效的迁移学习开始发挥重要作用。随着BERT、GPT等大规模预训练模型(Pre-Trained Model, PTM)在自然语言处理领域获得巨大成功,大规模PTM获得广泛关注。大规模PTM可以从大批量的标注或未标注的数据中学习到强大的表征能力,基于大规模PTM对少量数据做进一步微调,即可复用和迁移其强大的表征能力,这在下游任务中表现更好。使用大规模PTM而不是从零开始学习,已经是在应用深度学习技术时人们的共识。
大规模PTM的核心是网络架构、大规模数据的设计和利用、高效的计算。
学术界和工业界对大规模PTM的期望达到了空前的高度,甚至期望进一步探索走向通用智能的道路。大规模PTM的思想与人类学习知识有诸多一致性,都是期望掌握强大的基础表征或学习能力之后,便可以触类旁通,用更少的信息就可以举一反三。
生成对抗网络(Generative Adversarial Networks, GAN)是一类无监督的机器学习模型。生成器和判别器都可以是神经网络,生成器生成仿真样本,判别器判别样本好坏,两者形成一种竞争对抗的关系,在竞争中两部分都不断优化提升。
快速实现模型从一个领域到另一个领域的转换,就好像人学会了辨别万物之后,再面对未知的东西,只需要针对一两张新图片进行再学习,就可以快速掌握。如何让机器也学会学习?元学习(Meta Learning)就是这样一种技术。
元学习在方法上可划分为三种:基于模型的方法、基于度量的方法和基于优化的方法。不同的数据进入网络则会得到多个不同的特征向量,在特征空间中特征向量之间的距离和真实语义下的相似度可一一对应,这种距离相当于一个度量,与之对应的元学习方法被称为基于度量(Metricbased)的元学习。基于度量的元学习具体落地的方法是孪生神经网络(Siamese Network)。孪生神经网络是一种相似性度量方法,当类别多但每个类别的样本数量很少,或分类任务中训练样本集很难达到用一般分类方法训练所需的数量时,可以使用这个方法。孪生神经网络学习的目标是让相同类别的图片度量距离尽量小,不同类别的图片度量距离尽量大。除了孪生神经网络之外,匹配网络(Matching Network)、关系网络(Relation Network)都是基于度量的元学习方法。
基于优化(Optimization-based)的元学习,由优化算法对网络参数进行训练,从而找到最优参数。优化算法一般通过反向传播算法(梯度下降的神经网络形式)不断进行迭代优化,更新权重,最终得到最优网络参数。对于从零开始训练的深度学习任务,网络参数一般都是从随机初始化开始的,随机初始化的缺点就是需要足量的数据和较长的时间才可以训练好一个模型。基于优化的元学习方法包括MAML(Model-Agnostic Meta-Learning[插图],未知模型的元学习)、Reptile(可扩展元学习)等。MAML期望在这N个训练任务中学到一套初始化参数,这套参数不是某个任务的最优解,而是N个任务的折中最优解。
如何解决隐私和数据安全问题,是AI发展必须面对的一个重要问题,而联邦学习是一个可行解决方案。联邦学习是多方合作的机器学习,是一种各个参与方可共同进行建模,在数据不出本地、保证数据安全的情况下对模型进行联合训练并共享最终模型的方法。联邦学习的核心是在本地训练模型以及加密、更新、共享参数,并最终优化出高质量的联合模型。联邦学习还会促进企业之间的合作,催生新的商业模式。当用户特征重叠多,但是用户身份重叠少的时候,对应为横向联邦学习;当用户特征重叠少,但是用户身份重叠多的时候,对应为纵向联邦学习;当用户特征和用户身份重叠都比较少的时候,对应为联邦迁移学习。
尽管联邦学习的研究时间不算长,但在产业界已有许多联邦学习的应用框架,如微众银行的FATE、谷歌的TensorFlow Federated、百度的PaddleFL、OpenMind的PySyft。PySyft是OpenMind开源的联邦学习计算框架,主要支持横向联邦学习,框架底层支持TensorFlow、Keras、PyTorch等热门深度学习框架。百度在2019年年底开源了联邦学习工具PaddleFL。PaddleFL通过PaddlePaddle生态引流,在用户推广上有一定的优势。
在消费金融机构中,消费者的有效标注样本量不足、样本分布好坏区分度小且偏离正常的分布规律,如使用这样的样本集训练模型,会由于样本偏离真实分布情况,导致系统容易学习到偏离真实情况的判断模型。解决办法是从信贷机构合作方获得更多的有效标注数据,从而增加样本量并调和样本分布。具体的解决方案是建立消费金融机构和信贷机构的业务及AI模型优化闭环,在持续的数据积累中使用联邦学习优化模型。
在深度学习技术成熟之前,传统机器学习需要经过问题定义、数据采集和标注、模型选择和设计、超参配置等步骤才能达到目的。
人们期望通过自动化平台实现大部分流程的自动化,而人工只需要输入数据。这样整体流程变成问题定义、数据收集、自动化机器学习、应用部署等步骤。
研究人员也在不断尝试使用数据增强的方法,实现样本集的扩充。数据增强指使用各种数据变换方法,在原来数据的基础上,变换生成更多有效的标注数据,从而增加可供模型学习的数据量,从而提高模型的泛化性能。以图像数据为例,常用的数据增强方法有图像的旋转或翻转、给图像增加噪声信号等。数据的增强往往很依赖相关的领域专家,不同的任务会使用不同的数据增强方法。自动数据增强,则是针对不同的数据集自动化搜索对应的数据增强方法,在不同的任务上都能使用最优的方法获得最好的数据增强效果。谷歌在2018年提出了利用强化学习来寻找数据增强策略的方法——AutoAugment,最终该方法在公开数据集上获得了理想的效果。为提升在遮挡情况下人脸的识别精度,通过GAN生成眼镜、口罩、妆容等数据,辅助提升人脸识别精度。
模型结构、网络参数及超参数的众多变量会产生海量组合,如果只是使用常规的随机搜索和网格搜索,则效率会很低。在这样的背景下,针对神经架构搜索和模型优化的研究开始火热起来。神经架构搜索(Neural Architecture Search, NAS)的核心是利用搜索算法来寻找对任务来说最优的神经网络结构。对深度神经网络进行搜索的难点在于,如何拼接不同的结构以及如何提升模型评估效率。搜索空间是一个可对算法进行搜索的网络结构的集合,包含网络结构(神经网络深度、各个层的宽度)和配置(如某层使用的算子类型、链接关系、算子对应的超参)。
一开始NAS的研究采用的是以固定整体架构和链接为方向的全局搜索空间的思路。NAS要调整的主要是每一层的操作(如卷积、池化等)和对应的参数,但全局搜索问题很明显——巨大的搜索空间使得优化速度非常慢。很多研究转向基于模块化单元的搜索空间,其中很多基本单元由人工设计且具有很好的效果,NAS只决定每一块的位置和参数。不同强化学习方法的差别在于如何设计智能体的搜索策略。最初的方法是将循环神经网络(RNN)作为控制策略网络,通过迭代策略网络生成新的网络架构。在强化学习中,搜索的策略还有Q-learning、蒙特卡洛树搜索(Monte Carlo Tree Search)等。
进化算法是一种仿生的、模拟生物进化过程(优胜劣汰)的优化算法。算法随机初始化一个种群,这里可以把种群看成简单的子网络或层类型,然后依次执行选择、交叉、变异算子,根据适应性评价完成迭代进化。
常用的搜索方法还有贝叶斯优化(Bayesian Optimization)、高斯过程(Gaussian Process)、随机森林(Random Forest)、基于梯度(Gradient-based)等。
知识蒸馏最早由Hinton在2015年提出,它的核心思想是将训练度大的、精度效果好的模型作为教师(Teacher)模型,然后用教师模型指导和训练学生(Student)模型。知识蒸馏有许多实现方法,比如学习样本在两个模型中推理得出的结果之间的差异,也就是学习教师模型告诉学生模型的答案;再比如学习拟合教师模型不同层之间的转换关系,也就是学习教师模型解决问题的中间过程,这在本质上会学习到更多信息。
比如将参数从FP32转换为FP16或INT8,在特征表达足够好的情况下,量化后的模型会有较好的速度提升。
上述压缩技术的落地,一方面要求使用者了解对应算法原理和实现细节,另一方面需要大量调参工作。另外,基于规则的剪枝策略并非最优压缩策略,因为针对某一模型的剪枝难以复用到另一个模型上,因此每个模型都需要花费许多人工成本。为了扩大模型生产的效率,提升压缩效率和稳定压缩质量,许多自动模型压缩技术方法被提出。在应用实践中,许多互联网AI头部企业都发布了自己的自动模型压缩框架,如腾讯AI Lab的PocketFlow、百度的PaddleSlim等。
在视觉领域的常用使AI具有可解释的方法有基于梯度的可解释性、基于掩码的可解释性、基于类激活映射的可解释性等,这些方法都是通过关注AI判别的区域来确定AI是否做出了正确判断。
交流的过程可以视为针对不同模态的信息进行沟通和理解。在自动驾驶领域,视觉+激光雷达的方案会利用2D和3D信息进行融合分析。比如在一些场景中需要对图像进行清晰化处理,此时可以锐化图像边缘;又比如在模型训练时为了增强数据,可给图像增加噪声。当前大部分成像设备的输出都是数字信号,我们所处理的图像信息也是数字信号的一种。在数字图像处理中,一张图片代表的是一个矩阵,一张RGB图矩阵中的每个像素最少是由R、G、B三个通道组成。若某图片的分辨率为1920×1080,则说明该图像横向有1920个像素,纵向有1080个像素,而对该图像的处理就是对其中的1920×1080个像素,以及每个像素的三个通道进行处理。在处理图像时,常需要对图像做一系列基础的预处理操作,如图像变换、图像编码压缩和解码、图像增强和复原、图像描述等。在一些情况下需要对图像进行变换时,可使用傅里叶变换、沃尔什变换、离散余弦变换等处理技术,对空间域的图像进行变换域处理,这样不仅可减少计算量,而且可获得更有效的处理(如傅里叶变换可在频域中进行数字滤波处理)。压缩包括无损压缩和有损压缩两种。对于一张低质量图像,可以通过图像增强和复原来提高图像的质量。图像增强和复原的操作包括去除噪声、提高图像的清晰度、提升对比度等。如通过增强图像高频分量,可以让图像中物体边缘轮廓和细节更加清晰。图像复原需要了解图像降质的原因,以便根据降质过程建立“降质模型”,再采用某种滤波方法,恢复或重建原来的图像。从本质上讲,图像处理是一个优化问题,用深度学习可以比以往用人工规则方法更好地寻找到最优解。不过,深度学习在处理速度上比传统算法要慢得多,在实际应用中成本也较高。
随着传感器的发展,立体视觉的研究方法越来越多,主要集中在单目立体视觉、双目/多目视觉、程距法上。仅使用单个成像设备获得单张图像来获取深度信息,虽然在学术上有一些研究,但是由于获取信息本身的局限性,难以有效推广。但是可以通过单个成像设备,在与被拍摄物产生相对运动的情况下获取多张图像的信息,从而实现三维重建,比如在多工位移动目标的情况下使用单目进行测量。双目视觉即在两幅图像中找到对应的点,从而通过三角测量的方法求得深度。
一般一个完整的立体视觉系统可以分为几个主要组成部分或环节:图像采集、摄像机标定、特征与图像匹配、三维重建、内容理解。
当检测出图像特征时,还需要进行匹配,匹配的方法包括区域匹配、特征匹配、相位匹配等。
图像分类根据标签、任务类型可以划分为单标签分类、多标签分类和多任务分类。单标签根据类别的数量,又可以分为二分类和多分类。在实际应用中,一张图片往往不止包含一种识别任务,如人脸图片,在应用中,我们可能除了想了解人的身份外,还想了解人的性别、年龄等,所以对同一批图片就要做多种任务的识别。
比较流行的检测算法可以分为两大类:一类是R-CNN系列算法,包括R-CNN、Fast R-CNN、Faster R-CNN等,这类算法是基于两阶段(two-stage)实现检测的,即先在图像中产生目标候选框,然后对候选框做分类或回归;另一类是基于单阶段(one-stage)实现检测的,仅用一个网络同时预测目标位置和类别,比如YOLO、SSD。以R-CNN为例,其思想是通过选择性搜索提供众多候选区域,并将候选区域截取为小图,然后将小图送入特征网络由特征网络提取图片中的特征,再分类模块对特征进行分类。
根据对信息理解的深度,图像分割可以划分为普通分割、语义分割、实例分割和全景分割。图像分割的算法主要有五类:阈值分割、区域增长、边缘检测、聚类分割、深度神经网络方法。前四种方法属于传统图像分割方法,适合针对简单任务做普通分割,对于复杂的语义分割、实例分割、全景分割,一般使用深度神经网络方法,这会获得更加理想的效果。
在媒体和娱乐场景中,图像分割技术可实现人像和背景的分割。比如,背景的更换、通过分割人像来避免视频中的弹幕遮挡人脸,以及为图像中的人物换衣服、换头发颜色等,均是在图像分割结果的基础上进行的。
目标跟踪是计算机视觉中的一个重要应用,是针对连续图像或视频中的目标进行一致性匹配和追踪的技术。生成式方法是指在当前帧对目标区域建模,生成待跟踪目标的模型或特征,在后续帧中进行相似特征搜索比对,以求找到最相似的位置,即预测目标位置。光流法、粒子滤波、Meanshift、Camshift等都是生成式算法。这类算法的缺点比较明显,即缺乏对背景信息的利用,且目标本身的多变和多样性会影响建模质量,从而影响跟踪精度。判别式方法是指将目标和背景同时考虑,这种方法更注重两者的区别,通过对比两者的差异,得到目标的位置。判别式方法本质是对目标和背景做分类,引入背景信息以获得更好的效果。判别式方法包括结构化学习、TLD、SVM、随机森林、相关滤波等。判别式方法已逐渐占据主流地位,近年来火热的深度学习方法走的基本都是判别式的路线。
语音是由物体振动产生的声波,是一种搭载着信息的模拟信号。语音信号可以通过麦克风采集,通过模拟/数字(A/D)转换之后,得到音频数字信号。语音信号的A/D转换需要经过采样、量化和编码三个步骤。采样是将连续的模拟信号变成离散信号的过程,采样频率是每秒采样的次数。
根据奈奎斯特-香农采样定理,采样频率要高于模拟信号的2倍才不会失真,因此要达到人耳可分辨的频率,则采样频率需要在40kHz以上。在当前的语音识别中,经常使用16位来存储振幅值,16位表示将振幅的数值范围划分为65535个数。还可以采用非均匀量化的方式,即幅度小的区间量化间隔小,幅度大的区间量化间隔大。脉冲编码调制(Pause-Code Modulation, PCM)是原始数字信号编码技术,得到的是不经过压缩的裸音频数据。声道是指声音在录制时,在不同空间位置采集的独立音频,通过多音源的配合,可达到更好的听觉效果。
语音识别(Automatic Speech Recognition, ASR),是将音频信号转换为文字/文本信息的一种技术。语音识别的核心是将声音转换成文字,无法区分说话人,也无法理解文字所表达的意思。从技术处理的流程看,语音识别的输入是音频,中间经过预处理、特征提取、特征识别,最终输出为文本。
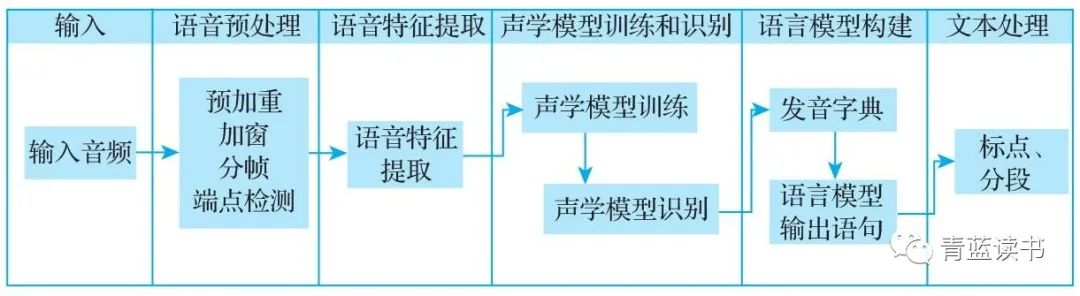
常用的预处理包括预加重、加窗、分帧、端点检测等。预加重就是在信号传输的开始增强信号的高频成分。从整体看,语音信号是随时间变化的,而非平稳过程,这是语音的时变特性。但在一个短的时间范围内信号可保持相对稳定,这个“短的时间”一般为10~30ms,这种特性可称为短时平稳特性。为了更好地实现语音分析,需要进行短时分析,即需要对语音信号进行分帧。
加窗是将窗函数与音频信号函数在时域进行相乘或在频域进行卷积,常用的窗函数有矩形窗、汉宁窗等。加窗可以使时域信号更好地满足快速傅里叶变换的周期要求。
端点检测是从音频信号中判断语音信息的开始点和结束点,从而剔除无效的噪声信号,保留有效语音信号。
预处理完成之后,会得到一段一段的波形信号。因为计算机难以直接处理波形信号,所以还需要对语音进行声学特征提取,得到计算机可用的向量表达。这里所说的向量一般被称为特征向量。常用的语音特征提取方法有:线性预测倒谱系数(Linear Predictive Cepstral Coefficient, LPCC)、梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient, MFCC)、线性预测系数(Linear Prediction Coefficient, LPC)等。
在语音识别过程中,声学模型的任务就是把帧识别成状态,以及将状态识别成音素,如图4-17所示。常用的声学模型包括隐马尔可夫模型(Hidden Markov Model, HMM)、高斯混合模型(Gaussian Mixture Model, GMM)。
发音字典是单词和发音对应的映射表。
根据不同的任务可以选择不同的模型做编码器和解码器,如CNN、RNN、LSTM等。
注意力机制就是将注意力放在更加需要关注的信息上,比如在模型中通过权重来构建解码器的上下文向量,就是这一机制的落地体现。
说话人识别(Speaker Recognition, SR)又称为声纹识别(Voiceprint Recognition, VPR),是一种通过音频特征来判别说话人身份的技术。由于在发音器官如舌头、口腔、声带,以及年龄、语言习惯、性格等上的差异,每个人的音频特征几乎是独一无二的,尽管在一些声音表演中可以模仿他人,但是在本质特征上仍有一定差异,因此声纹可以作为判别身份唯一性的重要手段。声纹识别是一个模式识别问题,声纹识别系统的构建需要经过训练和识别两个阶段。在训练阶段,首先收集大量各类身份的有效音频信息,然后为这些信息标注身份,接着进行训练,得到可用于部署的成熟的声纹识别模型。根据能否识别训练人员集以外的人员,声纹识别系统可以分为开集(Open-set)系统和闭集(Closed-set)系统。闭集系统即训练中包含了哪些人,识别的时候就只能识别哪些人。开集系统可以通过入库注册的方式,扩展待识别群体规模。在声纹识别过程中依然要经过两个步骤,分别是声纹注册和声纹比对。在声纹识别应用中,不同的应用场景会使用不同的应用模式,通常有1:1身份核验、1:N身份识别、N:N声纹聚类等几种。1:N身份识别是在多人说话的场景中,识别不同说话人的身份,这里要求说话人的身份是已经注册在库的人员。比如智能会议在记录语音信息的同时可以区别不同注册发言人的发言,这样可更高效地整理会议记录。N:N声纹聚类是在未知说话人身份的情况下,对相同说话人的发言进行聚合,以便于事后做进一步分析和整理。
文本相关的声纹识别需要用户按照系统规定的内容进行发音,比如朗读指定的数字、字母等,这种验证限定了发音内容范围,降低了比对识别难度,可以得到更高的识别精度。在有高精度要求、需要交互配合的环境中会采用这种模式,如在金融相关的安全验证中。文本无关的声纹识别无须按照系统指定内容进行发音,无须进行特定的交互,更多的是在无感的情况下进行声纹识别。由于发音内容多样,这种模式识别的难度较大,精度较低,更多应用在一些安防取证相关的非配合式场景中。
自然语言处理(Natural Language Processing, NLP)是计算机和AI领域中的重要应用方向。自然语言处理根据应用过程中理解和回应两个环节,可以分为自然语言理解(Natural Language Understanding, NLU)和自然语言生成(Natural Language Generation, NLG)。NLU主要解决机器如何理解自然语言的问题,包括文本分类、实体识别、语句分析、机器阅读理解等。NLG则关注机器在理解自然语言之后如何做出回应,并将回应转换成人类可理解的语言,包括自动摘要、机器翻译、自动问答。
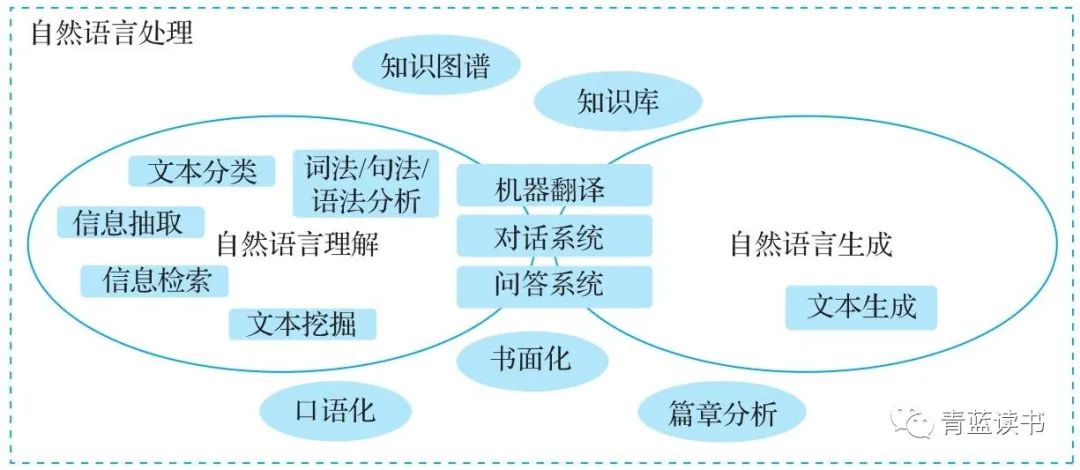
NLP一般划分为形态学、语法学、语义学、语用学四个层次。形态学又称词汇形态学或词法,主要研究词的内部结构;语法学主要研究句子结构以及句子中各个组成部分的规则和关系;语义学主要研究语言的含义,关注从词到句阐述的表面客观意义;语用学主要研究语言在现实中的使用,关注影响语言行为的标准和规则,包括在上下文、文化、规则等的约束下整体篇章语言的理解和使用的问题。语用则研究词句在不同上下文语境中的语义,如“房子”在某个语境中究竟是指住的地方还是资产。词法分析是NLP的基础性工作,包括分词、新词发现、词性标注、拼写矫正等。
句法分析可以分为两类——依存句法分析和句法结构分析。依存句法分析是分析词与词之间的依赖关系,如句子中词汇之间的从属、并列、递进等关系,从而得到更深层的语义信息;句法结构分析是分析句子的语法结构,比如主干与各成分之间的关系,如“主谓宾定状从”等。
语言模型(Language Modeling, LM)的作用是根据给定前一个字或词去预测文本中的下一个字或词,从而预测整个句子。语言模型早期使用N-gram方法,然后使用LSTM,再后来陆续使用预训练表征方法。
词表征是将词语转换成计算机向量。在Word2Vec相关的深度学习方法出现之后,如何在词语的表征中包含词语的语义信息,而不是简单的字符代号,成为词表征任务的主要研究方向。
核心语义角色包括施事者、受事者等,附属语义角色包括地点、时间、方式、原因等。文本蕴含(Textual Entailment)是指文本间的语义联系,即两个文本之间的推理关系。将代表同一个实体的不同代词划分到相同集合的过程成为指代消解。信息抽取(Information Extraction)是指将篇章语句中非结构化信息自动提取为实体(Entity)、关系(Relation)、事件(Event)等机器可理解的结构化信息的过程。信息抽取一般包括命名实体识别、关系抽取、事件提取等。命名实体识别(Named Entity Recognition, NER)是信息抽取中的子任务,主要用于定位文本中的命名实体并对其进行分类。早期主要通过规则和词典的方式,即通过关键词、位置词、标点符号等方式设计规则模板、常识字典等,然后使用匹配的方式进行实体抽取;随着机器学习的出现,NER问题被当作序列标注问题,也就是将文本中的词句当作序列,通过机器学习的方式对句子中的词进行标记,这类似分类问题,但是每个词不是独立的,而是与前后序列有关联的。简单说,如果输入是一个句子,则输出是对这个句子中实体的标记。常用的机器学习方法包括隐马尔可夫模型、最大熵(ME)等;近些年随着深度学习的发展,NER的研究全面转向深度神经网络,包括使用注意力机制、图神经网络方法的深度模型。在实际操作中,可通过种子语料的标注,建立初始的模型,经过模型的挖掘聚合,得到更多相似的语料,并进行进一步的筛选,扩大种子集。经过反复的迭代,最终可得到高精度的模型。
关系抽取(Relation Extraction, RE)即获取文本中实体之间的语义联系。一般RE使用SPO(Subject, Predication, Object)三元组结构,比如句子“中国的首都是北京”,对应的三元组结构为(中国,首都,北京)。
根据是否有确定的关系集合,RE可以分为限定关系抽取和开放式关系抽取。限定关系抽取中所有关系集合都是事先确定好的,此时RE变成一个分类问题。开放式关系抽取在抽取关系集合和语料等领域均可能是开放、不确定的。
事件提取(Event Extraction, EE)关注文本中发生的事件信息,并通过结构化的形式进行存储和展示,如事件的发生时间、地点、过程等。
当前已有许多知识图谱类产品被构建,比如WordNet、HowNet、Google-KG等。为了扩大知识图谱规模,在互联网出现后,出现了群体智能构建方式,比如通过维基百科、百度百科等半结构化数据对知识进行组织。随着互联网规模越来越大,面对内容生产规模爆炸式发展,自动化机器学习构建方法被提出,即通过自动化信息抽取的技术,实现快速自动化知识图谱构建。
在知识图谱中,实体和关系一般通过(实体,关系,实体)三元组来表示,如(中国,首都,北京),Word2Vec技术是将单词转换成计算机可理解的向量,而知识图谱是将三元组结构数据转换成向量。整体的技术实现思路是构建实体和关系的表达、构建评价函数、学习实体和关系的向量表达。知识图谱表征技术包括平移距离模型、语义匹配模型。语义匹配模型利用基于相似性的评价函数,根据实体在语义以及向量中的包含关系的相似性来度量两个实体的关系。
三元组数据一般存储在图数据库中。比较知名的图数据库包括Neo4j、FlockDB、GraphDB等。模式层是数据的组织模式,包括数据层之上的经过提炼的知识,通常使用本体库(Ontology)来管理。知识图谱的构建一般是利用自动化技术对结构化、半结构化、非结构化数据进行知识抽取,并将数据存储到模式层和数据层。根据先构建数据层还是模式层,知识图谱的构建有两种方式:自顶向下和自底向上。自顶向下的构建方式是先构建模式层,再构建数据层。模式层的构建可以通过从人工构建的高质量数据中抽取本体和模式信息,然后再根据已构建好的模式层,从更大规模的数据中抽取数据来构建数据层。自底向上的构建方式一般是先通过自动化或半自动化的方式在大量的数据中抽取实体、关系、属性等来构建知识图谱的数据层,再通过数据层来组织构建模式层。现在的知识图谱大多使用自底向上的方式构建,如卡内基梅隆大学的NELL。

知识融合就是对冗余信息进行整理,形成统一的知识,其中的关键技术包括实体消歧和指代消解。
本体构建:是构建知识图谱模式层的技术,主要是构建本体库,通过公理、规则和约束条件规范实体、关系、属性等之间的联系。一般来说,本体的构成要素包括类或概念、关系、函数、公理、实例。类或概念包含了对象、任务、功能、行为等,包括定义和描述;关系是多个概念之间的联系,概念之间的关系是多种多样的,比如整体-部分关系通过Part-of表达,概念间的继承关系通过Kind-of表达,概念和实例之间的关系通过Instance-of表达等;函数是关系的一种定义,可以通过定义函数来定义两个概念之间的关系;公理是各种情况下均真实的描述;实例则是概念的一个真实应用对象。
需要对信息进行可信度的判断,保留高置信度的知识,从而保证知识图谱的质量。比如根据用户贡献知识的历史和领域来评估其所贡献知识的质量,还有对某条信息在抽取过程中出现的次数进行可信度评分,同时通过可信知识库对信息进行修正。
关系型数据库、图数据库、RDF模型都可以对知识图谱进行存储,但是当数据规模较大时,关系型数据库需要管理和维护大量数据表,数据的管理代价会很大。图数据库天然适合知识图谱数据的存储,即用节点表示对象、用边表示关系。图数据库在查询速度上要优于关系型数据库,多跳查询性能更好,但是更新复杂,在数据分布式存储场景中实现的代价很高。RDF(Resource Description Framework,资源描述框架)是专门为三元组形式设计的数据模型,在主语-谓语-宾语(SPO)三元组中,使用六重索引(SPO、SOP、PSO、POS、OSP、OPS)方式进行搜索。
在存储方案中,基于图数据库的Neo4j和基于RDF的gStore是两个比较知名的原生知识图谱存储方案。
知识问答可以理解为在特定场景下的语义搜索,这类应用在智能客服等场景中使用较多。
基于知识图谱的推荐系统也有非常广泛的应用,在电商、社交、支付等互联网消费场景中,对用户行为、关系等进行画像分析,可以获得用户的兴趣爱好、消费倾向与时机等。利用知识图谱技术,可构建用户和产品的关系,从而推断用户规律性和阶段性的需求,从而实现精准推荐。
尽管知识图谱技术已经在许多场景中落地应用,但仍存在许多长期待解决的问题:
1)无论是实体还是关系,都面临更大规模的数据量和连接量,尤其是视频、图像、音频等多模态非结构化、半结构化数据呈爆炸态势,如何在数据层面兼顾质量和数量,构建高质量的知识图谱?
2)如何找到更好的表征方式来表达知识图谱结构中的实体和关系等,以帮助计算机更好地计算,挖掘更有效的信息?
3)如何找到更合理的数据模型和更高效的查询手段,提升在大规模知识图谱下的数据应用效率?
许多受众少的语言往往因缺乏海量的双语平行语料而无法进行监督学习,此时可通过反向翻译(Back Translation)的方式,将目标语翻译成源语,组成新双语语料后再进行翻译。这是典型的无监督机器翻译的落地思路。
语音直译可实现跨模态的语言映射,这也让单模型可以学到不同模态信息之间的关联。
在对话系统中,一般会包括自然语言理解(Natural Language Understanding, NLU)、对话状态追踪(Dialogue State Tracking, DST)、对话策略(Dialogue Policy, DP)、自然语言生成(Natural Language Generation, NLG)等模块,如果需要进行语音输入和输出,还会包括自动语音识别(Automatic Speech Recognition, ASR)、文本转语音(Text To Speech, TTS)等模块。

在一些需要多轮对话、开放式的聊天场景中,要想满足需求,则对应语料库会非常庞大,此时需要在检索方法上使用一定的加速策略。生成式对话系统可以看作解决的是序列到序列(Seq2Seq)的问题。
在多模态技术的研究中,主要包含五类任务:表征(Representation)、转换(Translation)、对齐(Alignment)、融合(Fusion)和协同学习(Co-learning)。表征是最基础的工作,不同模态的信息之间存在互补性、冗余性。对表征的研究方向包括联合表征、协同表征等。联合表征是将不同模态的信息映射到相同的特征空间;协同表征则是针对不同模态采用不同的特征空间,但不同模态之间要有一定的约束。转换也可以称为映射,是将一个模态的信息转换为另外一个模态的过程,类似语言之间的翻译,比如语音合成是将文本信息翻译成语音。
协同学习是通过其他模态的信息优势,协助信息资源稀缺的模态建立模型。多模态协同包括并行、非并行、混合三类学习方式。具体的方法有多种,如协同训练,即当一个模态的标注数据非常少时,利用协同训练生成更多的标注训练数据;再如迁移学习,即将一个数据充分、干净的特征表示从一种模态迁移到另外一种模态。
多模态融合有非常多的应用,包括视觉问答(Visual Question Answer, VQA)、视觉常识推理(Visual Commonsense Reasoning, VCR)等,在更上层的业务应用上还包括自动驾驶、机器人、虚拟数字人等。
主动传感器有声呐设备、激光雷达等。主动传感器需要向外界发射信号,并感知和接收反射信号。
以一个三维自由空间中的具有6个自由度的刚性物体为例,物体所在原点为(x,y,z),物体可以围绕x轴、y轴、z轴分别平移,也可以围绕x轴、y轴、z轴分别转动,因此共有6个自由度。
在很多时候,机器人在地图上判断自身位置时,并不能直接测量出结果,而是通过传感器估算其最佳状态,再通过信任状态猜测出位置状态。
任何应用都具备功能和非功能两种特性:功能特性是指应用可以直接为业务带来价值,如AI应用中的人脸检测、比对、属性识别、库管理等;非功能特性是指没有为业务直接带来价值,但可间接保障系统可用,如容灾、安全、运维等。云技术的出现,特别是云原生技术的出现,使得开发者不再需要过度关注底层的非功能特性,可更加专注功能特性的开发。
企业的IT建设经历了从服务器到云化再到云原生化三个阶段。
当业务应用和人员规模都变得庞大时,单体应用的开发、迭代、测试等流程就变得低效了,而微服务可以很好地解决这个问题。微服务是将统一的后端服务拆解为多个松耦合的子应用。Serverless既是一种架构模式,也是一种产品形态。按照云原生计算基金会(CNCF)的定义:Serverless架构是采用FaaS(函数即服务)和BaaS(后端即服务)来解决问题的一种设计。简单来说,Serverless旨在让用户专注于业务逻辑,无须考虑服务器、存储类型、网络带宽、自动扩缩容等问题。Serverless通过云函数等方式,降低了用户的运维时间、运营成本,大大缩短了应用上线周期。
DevOps提倡打破开发、测试、部署之间的壁垒,利用自动化、智能化等手段,提高软件质量,提升开发、测试、部署的效率,缩短软件开发周期。对比瀑布式开发和敏捷开发,DevOps在业务拆解上会更细,迭代和交付的效率会更高。
无论打开阿里云、百度云还是腾讯云,都能看到众多AI的云应用。互联网厂商还提供了云化的AI生产能力,如百度的BML、阿里的PAI等。
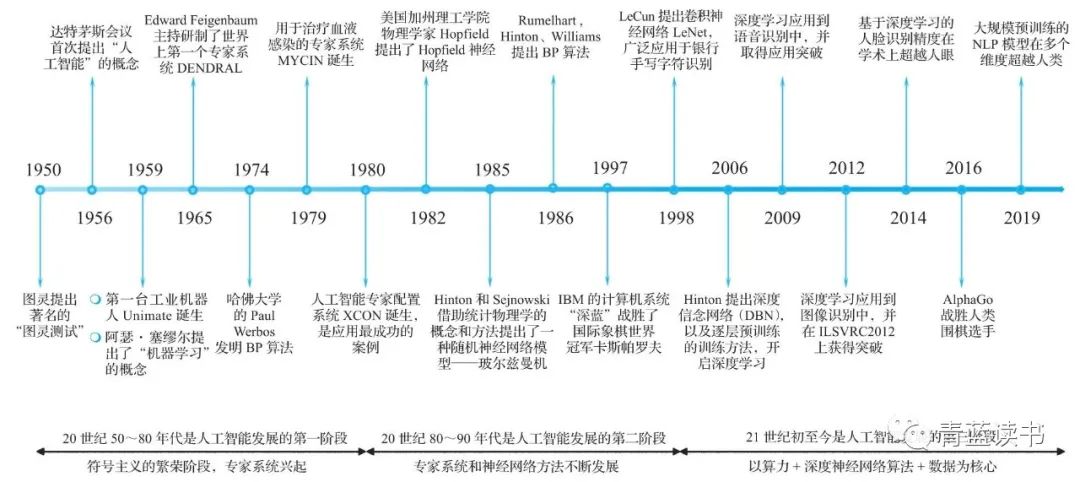
技术变革早期可能发生在高校实验室和论文中,但规模化的认知升级需要通过重要事件来推动。
笔者定义横向发展为AI行业化,纵向发展为AI赋能百业。AI的行业化是寻找稳定的、标准的能力或者载体,如AI芯片、多模态AI平台、虚拟数字人等,这些区别于传统业务和产品的“新物种”,让AI本身成为一个行业。而AI赋能百业,更多的是在原有业务基础上使用AI工具进行优化。最关键的是要看准市场需求、市场规模、市场阶段和时机、市场竞争。市场需求源于两大类,一类是源于对生产率的提升,另一类则是交互体验的升级。总潜在市场(Total Addressable Market, TAM),可服务市场(Serviceable Available Market, SAM):SAM是TAM的子集,指企业的产品或服务可占据、渠道可触达的市场,或者说有可能购买企业的产品或服务的用户总数。可获得市场(Serviceable Obtainable Market, SOM),指的是企业的产品或服务当前所获取或未来将要获取的用户群体,即对产品或服务感兴趣并愿意付费的用户群体。根据集中度,市场可以分为头部市场、尾部市场(分散市场)。头部市场集中度高,很容易出现赢者通吃的局面,比如互联网支付、互联网短视频领域。
企业销售收入是比较难获取的数据,对于头部企业来说,可以通过产业联盟、上市公司年报、招股说明书、行业人员访谈等方式获取企业公开的收入情况。
AI产品的竞品分析可以从产品形态、商业模式、功能、性能、精度、价格、用户、场景等多个方面入手。在AI产品中,改良算法精度、解锁应用场景、提升硬件算力、降低成本都是改良的路子。商业模式解决的更多是资源配置效率问题。技术创新解决的却是资源生产问题。从应用角度看,可能一个小小的技术创新就会带来商业应用的巨变,这又成为突破式创新了。
AI产品经理需要搭建技术和场景条件的桥梁,即充分理解场景需求并提供充分的场景条件限制,以寻求场景和技术的可行结合方案。
在实际应用中用户反馈的不一定是用户需求,用户需求不一定是产品需求。
产品战略是企业、部门、产品线为其所经营和生产的产品制定的全局规划。同样是做一款产品,要打什么样的市场、该产品是临时性角色还是核心拳头产品、是打品牌还是打造高附加值场景、是下沉中低端市场还是针对高端市场、是独立产品还是组合产品、是战略投入还是试验性投入,这些都应该事先深入考虑。
在AI产品中,产品的形态则更加多元和富有创新性,共包含两种主要的类型:第一种是对原有产品提供AI能力加持后得到的产品形态,如AI能力加持下的软件定义摄像机;第二种是因AI而存在的创新产品形态,比如虚拟数字人、自动送餐机器人等。
客户关注的是买卖是否值得,用户关注的是产品是否好用。打造产品应该关注客户群和用户群画像,关注客户购买力及其对产品的核心诉求,关注用户对外观、品质、功能、性能等的要求,在产品设计时要对客户和用户的需求做权衡。
如对于算法,其召回率和精确率是一对跷跷板的两端:有些场景要求更高的召回率,即从数据中找到更多有效数据,找出的数据错误率可以高,但是不能有漏掉的情况;有些场景要求更高的精确率,即可以漏掉部分数,但是找出的数据必须是对的。不同的场景对算法实现有不同的要求,明确场景可帮助算法更契合场景需求。
商业模式一般包括价值主张、目标群体、分销渠道、客户关系、收入来源、核心资源、关键业务、重要伙伴、成本结构等多个维度的内容。
在产品设计中,常常会先对产品的整体功能进行拆解,对高度相关的功能进行聚合,对相关性弱的功能进行解耦,形成模块化的功能板块。
建模语言(Unified Modeling Language, UML)。UML是一种用来对软件系统的开发进行可视化、规范定义、构造和文档化的面向对象的标准建模语言。它其实是一套图形化的建模规范,约定了图形元素、角色、语法等,目的是帮助用户快速构建可视化、图形化、规范化的需求及系统分析材料。UML包括结构图和行为图等数十种图,结构图包括类图、组件图、部署图、包图等,行为图包括用例图、活动图、状态机图等,其中的类图、活动图、用例图、序列图、状态机图等比较适合产品经理使用。除了UML图,还有思维导图、流程图、线框图、架构图等众多形态的工具可供产品经理使用。静态图表达产品的定义、属性、结构性,比如是什么、由什么组成等,这类图包括产品功能结构图、信息结构图、系统架构图、用例图等;动态图表达产品的行为特性,比如业务是如何流转的、数据是如何流转的,这类图包括业务流程图、数据流程图、状态图等。信息结构图主要用于对产品的信息进行抽象和重新归类。
产品经理一般需要对外提供物理视角和功能逻辑视角的系统架构图。绘制业务流程图需要关注业务内容、用户、信息起止、异常处理、规范五个方面。好的结构层设计可以缩短用户触达信息的路径,减少用户学习成本。框架层是比结构层更加细粒度的具体化的设计,主要包括界面设计、导航设计、信息设计三部分。界面设计的核心是让用户快速看到想要看到的元素,淡化对用户来说不重要的元素,还要明确哪个部分表达什么;导航设计是在产品功能丰富、无法通过少量页面展示的时候,帮用户通过页面跳转合理触达延伸页面;信息设计关注哪些信息是用户更想看到和触达的。
除了软件部分,智能硬件一般需要经过工业设计、结构设计、开模、芯片选型、PCB方案设计、整机验证、包装设计与生产、验证和测试认证、产品内测、备料、小批量试产、大批量生产等过程。
工业设计(Industrial Design)即融合工学、美学、经济学各个领域知识进行工业产品设计。工业设计追求的是产品在可行性、外观、经济性、安全性等各个维度上达到平衡。
A有需求,A做产品设计,A交给B生产,最后产品交给A销售,那么B就是我们说的OEM厂商,B提供“代工”服务,这种协作模式就称为OEM(Original Equipment Manufacture,原始设备制造)。
ODM(Original Design Manufacture,原始设计制造)是需求厂商(A)委托设计制造商(B)进行产品设计、研发、生产、维护等一系列服务的一种生产模式。
支持某个功能并不能完全说明产品的可用性,还需要配合性能参数来完整描述产品能力。用于描述产品的性能常见参数包括各类速度、精度、功耗、稳定性等。比如网络传输速度、文件读写速度、算法处理速度、特征提取速度、搜索速度等。速度很多时候决定了产品的应用成本,往往处理速度越快,应用成本越低。在AI产品中,最常见的速度如视频图像应用中的解码速度、延时、系统算法吞吐速度、特征搜索速度等。
比如在图像识别产品中常用的召回率、精准率,语音识别产品中的唤醒率、词句错误率等,地图产品中的定位精度、出行路线规划用时的偏差程度等都是精度。精度代表一个行为多次重复后准确的程度或比例,对精度的评价一般采用统计学和定量的方法,即统计多次样本测试中成功达成目标的样本比例。比如在图像识别产品中,召回率代表的是算法能够检出全部的目标图像的能力,而精准率代表的是检出的目标图像有多少是正确的问题,两个指标组合起来才能完整评价该图像识别产品的性能,但在不同应用场景中,关注的或者要求的指标也会有所不同。
对于芯片级产品,还需要从更细的粒度来拆解功耗指标,比如动态功耗和静态功耗。动态功耗是设备运行时或者信号改变时所需的功耗,静态功耗是设备上电但是信号没有改变时所需的功耗。
稳定性一般是产品按照标准压力或峰值流量80%以上的压力运行来测算得到的。
产品经理需要预先对产品应用场景的安全等级提出预判和需求,以降低交付风险。
面对大量的用户需求,产品经理需要进行长期维护管理,此时需求池是一个不错的工具。需求池就是对用户需求进行统一汇总的池子,一般会按照定义、详细内容、时间、重要性、来源、类型、状态等对需求进行统一管理。
为了让需求评审更加高效,产品经理需要明白需求评审应该针对什么样的人群、使用什么样的方式、达成什么样的目的。因此需求干系人在评审前要进行预审,并提前抛出问题,产品经理预先进行准备与说明,这样可提高多人会议的效率。
在产品需求阶段,评审内容包括产品规划、产品需求、需求计划。如果是产品规划阶段,评审的内容则是商业需求文档、产品规划书;如果是产品需求阶段,评审的内容则是需求文档;如果是需求计划阶段,则评审的是排期计划表。在Scrum敏捷开发中,需求一般通过待办列表(Backlog)的形式进行管理,弱化了整体的需求评审,一般将需求评审拆分成多个以双周或月为单位的迭代Sprint,通过Sprint计划会、每日站会、Sprint评审会的形式,将集中式需求评审分解到整个开发过程中。
产品经理主要考虑可以通过组合哪些需求以在最短的时间内输出最小可行、可独立可售卖的产品版本,以满足客户及项目的需要;开发经理考虑的是人力分配、技术实现在时间维度上的可行性;项目经理考虑的是人力、计算资源、数据资源等的协调。
需求的验收包括对功能、性能、安全性、稳定性、运行环境等进行验收。产品经理作为用户对产品进行使用把关。
随着软件产品应用的规模化和社会化大分工的加深,打造一个闭环产品链条变得越来越复杂,自动化、智能化、联网化的产品往往需要大规模的生产协作。
随着场景推广和规模化应用,AI算法应用进入大生产时代,平台型产品应运而生。随着场景应用的深入,AI产品与场景业务的边界逐渐模糊,形成系统化且深度结合行业业务的AI产品。
在AI产业发展早期,算法是AI公司的核心能力,也是AI公司最小可售卖的产品,可被行业应用系统集成。尽管从商业模式上看,这并非一个好的、轻松的业务,却是AI商业化的第一步。
任务定义是模型开发流程中的第一步,任务定义直接影响后续模型精度。任务定义应该由AI产品经理和算法人员共同完成。在任务定义中,业务规则可能直接影响到算法实现。在算法中,很多任务会变成分类任务、回归任务。很多时候,依靠客户简单的语言描述很难完整定义任务和类别,需要层层深入。产品经理还要关注任务中的争议边界。任务可被定义为简单任务和困难任务,简单任务的边界清晰,比如猫和狗的分类,非常容易划分。但是有些任务的边界非常模糊,比如识别车辆的颜色。AI产品经理要想理解算法功能边界、任务定义和类别定义,就需要看大量的数据,并与算法研究员进行深入沟通,明确各种类别数据的分布情况,并整理完备的任务定义、类别定义样本示例图。在算法维度,产品经理需要将常用的产品需求文档转变成算法需求描述,在此过程中可通过严谨的语言描述任务的定义、任务分类的定义、应用的场景、算法识别的功能边界、正样例图片、负样例图片、混淆样本的划分规则等,和标注说明文档有些类似。
数据工程一般包含数据采集、数据生成、数据预处理、数据标注、数据清洗/质检等几个环节。如果采集的数据质量差,如存在模糊、噪声多等问题,那么哪怕标注得很准确,最终模型的精度也不会很高。根据模型训练的经验,获取清晰有效的数据的成本,要比花大量时间进行数据预处理的成本低得多。
图像的标注包括拉框、标签分类、关键点标注、语义分割、3D点云等,语音的标注包括对说话内容、说话人等的标注,文本的标注则包括对文本分类、情感等任务的标注。拉框是找出图像中感兴趣物体(ROI)的位置,并通过框选的方式将物体标定出来。在拉框的同时,通过不同的标签来标注框的类型,比如人脸、帽子等。语义分割是对图像进行像素级的划分,并对分割的闭合区域进行分类。人脸关键点标注有丰富的应用,如人脸识别中人脸的矫正、人脸姿势的辨别、表情辨别、疲劳检测等。
简单的数据生成可以是对已有的标注数据进行简单的数据变换,如对图像增加噪声、转换图像风格等。通过转换图像风格获取数据,可提升训练数据的扰动性,降低模型过拟合的可能性。较为复杂的数据生成,如通过深度生成对抗网络的方式生成数据,这类数据可以用于模型训练,然后通过真实数据迁移到实际应用场景。在一些长尾的场景和任务中,数据获取难度很大,为了获取充足的训练数据,会使用第二种方式,比如通过游戏画面模拟极端路况来获取自动驾驶场景数据等。用于自监督学习的数据很多就是通过生成方式得到的,如通过时序语义关系、自动寻找数据中的关联关系等方法。比如,基于“完形填空”任务生成数据,即将一个句子中的部分词语或短句去除,让机器学习自动填充;再比如,遮挡部分图像并让机器学习自动进行恢复,从而自动构建具备一定监督信息的数据。
常见的算法框架有Caffe、TensorFlow、PyTorch、PaddlePaddle等。算法框架涵盖很多基础算子、算法训练的工具以及可视化的工具链等,为算法开发提供了底层支持。在深度神经网络中,算子指的是一个操作(Operator/OP),比如图像算法中的卷积(Covolution)就是一个算子,其通过一个核矩阵实现对像素空间数值的计算。
这些主干网络已被反复验证有效,也在工程落地中被反复使用,比如Googlenet、ResNet、ResNeXt、MobileNet等。上述网络结构和主干网络本质上都是数学公式,比如ax+bx2+cx3=y。在训练过程中,x是我们在实际业务中“喂”给公式(网络)的数据,y是我们的标注结果,而a、b、c是我们要学习的网络参数。训练本质上就是求解拟合业务数据的最优解的过程。
无论是训练方法还是跳出局部最优,都是通过配置超参数实现的。比如配置以什么方式给模型提供初始化参数,使用什么方法控制网络参数的更新(如使用随机梯度下降的优化方法)等。
如何将多个模型串成流水线是算法开发的一项重要工作,可以理解为业务算法架构。其中除了考虑算法精度外,还需要考虑算法性能以及后续更多业务的扩展性。
不同的推理产品硬件厂商针对自己的硬件提供了丰富的推理优化工具链,比如NVIDIA(英伟达)的TensorRT、Intel的OpenVINO等,这些本质上都是通过解析模型来做结构优化,从而提升速度、统一格式,使业务集成应用更便利。模型解析是将开源框架训练的模型(比如PyTorch、MXNet等)转换成TensorRT支持的模型(如Caffe、ONNX等)并进行解析;优化会对模型中非必要的结构进行去除操作、对可以合并的部分进行合并,并将处理后的模型输出为引擎。执行是对序列化的结果进行反序列化和推理。
要解决深度神经网络模型参数量大、计算量大、速度慢等问题,一方面要提升算力,另一方面要量化模型。量化是指将信号的连续取值近似为有限多个离散值的过程,可理解成一种信息压缩的方法。而模型量化,主要是对模型中的参数进行量化。量化方法有二值化、线性量化等,目的是将参数从FP32直接转换为FP16或INT8。量化模型一般有以下几种方法:
1)直接将浮点数转换成量化数,这一般会带来很大的精度损失。
2)基于数据校准的方法,提供真实的数据用于精度的校准。
3)基于重新训练微调(Finetune)的方法,这种方法在精度上更有保证。
方法1和2属于离线方式,方法3需要训练,属于在线方式。
模型转换和量化需要依赖完备的工具链,很多时候这些操作是在成熟的计算平台上进行的,如NVIDIA系列的GPU。随着AI计算产业的发展,越来越多的AI芯片产品进入市场,如华为的Atlas系列、寒武纪的MLU系列。硬件平台的适配是将模型以及算法SDK适配和移植到特定平台。新的芯片平台在工具链、新算子的支持上依然需要大量的投入才可以赶上成熟的硬件平台。
定量评估是指通过客观指标进行计算来评估算法或者系统的精度或者性能,比如通过对标注数据和推理结果的比较,计算出精确率、召回率等指标。定量评估的最大优点是客观。定量评估的第一步是建立一个好的度量测试集。
定性评估可以更加直观地看到识别效果的好坏,如果识别效果不好,也很容易分析问题的原因。
精度一般指算法或系统检测、识别的准确率的大小。
算法模型的精度测试定义了三类概念:基础概念是指最基础的常识、方法和变量,包括度量基准、测试集以及混淆矩阵等;基础指标是在运用基础概念及变量进行计算后得出的指标,包括准确率、精确率、召回率等;二级指标是在基础指标上再进行计算得出的更直观的精度评估指标,如ROC曲线、AUC等。基础概念包括度量基准、测试集、真实值、预测值、置信度、阈值、正样本、负样本、真正类、真负类、假正类、假负类和混淆矩阵。
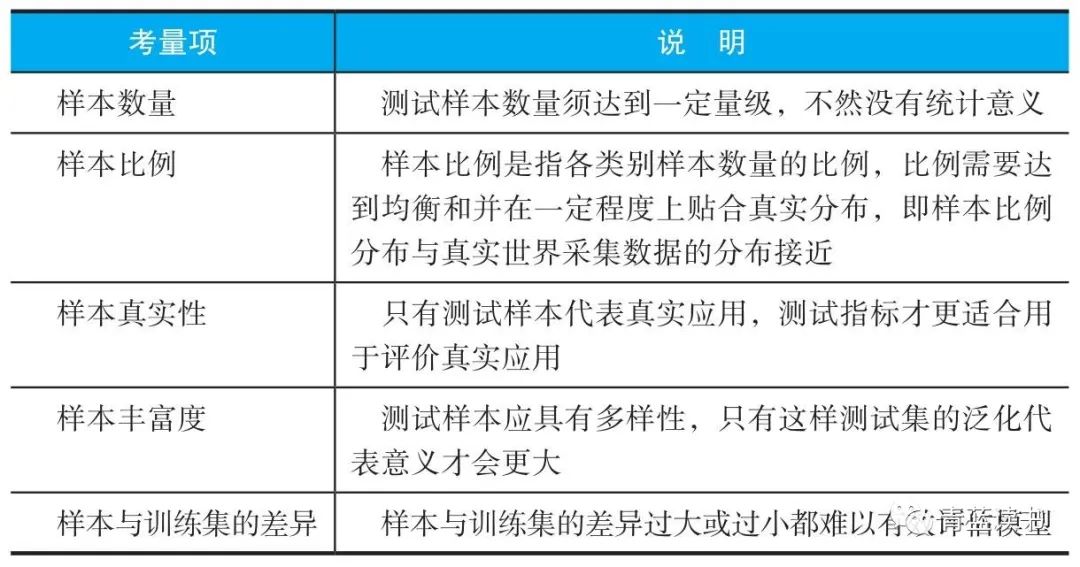
度量基准(Benchmark):在算法评估中,最重要的衡量工具就是度量基准。度量基准是评价算法好坏的规则和标准,这些规则和标准可以包括测试的方法、测试集、样本比例等。其中最重要的是测试集。
如果说预测值是判定结论,那么置信度就是判定结论的中间结果。深度学习方法其实是一种概率方法。当模型输出置信度时,我们通常需要对置信度进行判断,看是否符合判定标准,而这个作为判定依据的标准值就是阈值。但如果将阈值调高,如置信度必须高于90%才可输出,那么输出的结论会更加准确。
在二分类任务中,常将感兴趣或者关注的类别设置为正样本,将背景类别设置为负样本。
真负类(TN):当某张负样本图片经过模型预测,得到的预测值与真实值一致时,我们称之为真负类。假正类(FP):当某张负样本图片经过模型预测,得到的预测结果为正样本时,则该图片称为假正类。
混淆矩阵的列代表预测类别,列的总数表示预测为该类别的数据实例的数目;行代表数据的真实归属类别,行的总数表示该类别的数据实例的数目。
错误率(Error Rate):错误率是错误识别的样本数量占总样本数量的比例。
精确率(Precision):精确率又称PPV(Positive Predictive Value),是指预测为真正类的样本数量占所有预测为正类样本数量的比例,TP/(TP+FP)
召回率(Recall):召回率又称敏感度(Sensitivity)或TPR(True Positive Rate),是指找到真正类样本的数量占所有真正类样本数量的比例,TP/(TP+FN)
误报率(FAR):误报率又称FPR(False Positive Rate),是指假正类样本数量占总的真负类样本数量的比例,FP/(TN+FP)
在实际应用中,评价一个算法模型的好坏不会仅以精确率或者召回率作为单一的度量标准,而是对两者进行综合评价,F值(F-measure,又称F-Score)是精确率P和召回率R的均衡指标。当系数β=1时,公式会变成如下形式(此时的F值为F1)。2PR/(P+R)。F1是精确率和召回率的等权调和平均,此时F1的核心理念在于,在提高精确率和召回率的同时,减少两者的差异。当精确率和准确率均为100%的时候,F1达到最大值1。F1越高,即越接近1,说明这个算法模型的精确率和召回率的表现均越好。
以人脸识别为例,任何两个特征比对后都会有一个相似程度,或者称为置信度,置信度越高则被识别的两个人脸属于同一个人的可能性越高。因此可以通过设置一个标准(即前面介绍的阈值),如当置信度超过80分的时候,我们就认为这两个脸属于同一个人。当产品需要应用在精度更高但对漏报忍受度较高的场景中时,我们可以提高阈值。ROC(Receiver Operating Characteristic)曲线是受试者工作特征曲线的简称,ROC曲线是以召回率(TPR)为纵坐标、误报率(FPR)为横坐标绘制的曲线。当基于同一个测试集对算法模型进行评估时,不同的算法模型的ROC曲线呈现的形状会有一定的差异,通过ROC曲线可以客观地评价算法模型的优劣。ROC曲线越陡峭,表示算法模型分辨的效果越好,因为算法模型在获得更高TPR的时候有着更低的FPR,也就是在识别更多正确正样本的同时,会抑制误报率。在完全理想的情况下,ROC曲线是一条覆盖纵坐标和最顶端横线的折线。
为了使识别出来的词序列和标准词序列之间保持一致,需要替换、删除或者插入某些词,用这些插入、替换或删除的词的总数除以标准词序列中词的总数的百分比即为WER(字错误率)。
速度一般是对算法或者系统的推理速度进行考察,针对不同的技术应用,有不同的评价指标。如针对图像识别类产品进行评价,通常采用QPS,而针对视频、语音、文本识别类产品进行评价又有不同指标。QPS(吞吐量):针对图像识别算法,通常使用QPS来衡量系统的速度。测量QPS时通常是将单张图像重复或者将批量图像一次性送进系统进行处理,通过计算单位时间内系统处理图像的数量来计算系统的速度。
□ 支持的路数:路数指的是接入实时视频的数量,通常有一个实时视频接入就算一路。该速度指标在智慧城市、智慧安防、智能相机等需要应用实时视频算法的系统中使用较多。
□ 倍速:对于处理离线视频的系统,可使用倍速进行评价。由于离线视频有别于实时视频,对其可采用加速处理的方式,因此,经常以在配备某些算法的情况下以支持处理离线视频的倍速来衡量相应系统。在视频正常播放的情况下处理完成,表示倍速为1。在智慧城市、安防等产品或系统中,经常会用到倍速指标。
□ 时延:时延是评价系统实时性的指标,时延用于表示从用户提出反馈到系统给出反馈所用时间,只有当时延小于特定的时间值时才算具有实时性。一般来说,时延=系统输出时间点-系统输入时间点。
系统对实时性响应的要求一般存在三种级别:第一种是人不可感知的实时性响应,一般是毫秒级甚至纳秒级响应;第二种是人可感知的短实时性响应。人可感知的最短时间是一般都为0.5毫秒到1秒;第三种是人大延迟响应,通常这类系统的用户可承受的时延在数十秒到数小时不等,如做历史档案回溯、历史数据融合分析等的系统。
算力的评价一般以TFLOPS(每秒可计算的浮点数的数量)或者TOPS(每秒可计算的整数的数量)为单位。
面对爆发式增长的应用需求,算法的长尾效应使得投产比过高、技术底座薄弱问题显现,同时AI技术和行业的融合应用依然存在鸿沟,上述这些都需要有一个平台型底座来支撑业务的快速迭代开发。
算法的长尾体现在两方面,第一是对AI业务来说,许多业务无法仅使用一个算法就完成业务闭环和满足交付条件。比如面向城市治理的解决方案,常常需要交付可对人脸、人、车、非机动车、物品等众多内容进行识别的产品。第二是在单个业务任务中,数据样本的长尾使得做好一个任务的难度增大。需要加入长尾样本以提升算法的召回率,而提升召回率可能带来更多误报,这又需要不断加入负样本来降低误报率。面对算法长尾,我们期望算法可以进行小样本学习,使其拥有更强的泛化能力。另外,在AI人才紧缺、业务膨胀的情况下,市场期望响应业务的算法和模型的迭代速度可以更快,所以AI领域需要一个泛化能力强、门槛低、效率高的算法开发和应用平台,AI中台应运而生。
算力应用的形态多样,可以是一体机、公有云、边端设备等,具体选择什么形态的应用,需要结合特定的场景来决定。AI训练生产层关注如何将数据、模型、工具、AI框架等加工成业务需要的算法应用。在AI框架上可构建针对音频、视频、文本等不同模态的任务框架,以及包括可视化、基模型等在内的一系列基础工具。数据管理提供数据标注、清洗、存储等管理功能;模型管理是对训练过程中从算法配置、训练、适配到评价等每个环节进行管理,目的是高效、高质量输出算法。
AI推理运行层是业务最终生产运行的平台,在实际产品中,推理产品可以是云原生化的服务,也可以是基于端设备的边缘计算产品。当前AI推理运行和训练是割裂的。未来的AI中台应该打破这种割裂的局面,实现推理运行和算法优化无障碍连通。若运行中存在中心计算、端边计算的情况,则AI中台还应实现云边端协同的能力,从而支撑更丰富的业务交互类产品。
AI中台应具备应对图、文、音、表等全模态信息的能力。第二是全链条生产层面,AI中台应可支持数据管理、模型训练、推理运行、资产(数据、模型、知识等)管理等所有环节。在全链条的生产过程中,如何更快、更好地实现数据标注、模型训练及部署上线,是AI中台面临的另一个挑战。
自动化是解法,它涵盖两个维度:第一个是机器学习算法的维度,包括自动化调整参数、自动化数据增强、构建高精度的模型,这部分是AutoML的研究领域;第二个是整体流程自动化维度,即实现从业务数据的反馈到算法提升优化,再重新部署应用的流程自动化,这部分一方面靠技术来支撑,另一方面要考虑协同方式,如ModelOps就是关注如何快速实现模型快速生产的技术和实践。
利用AI中台,企业不仅可以是使用AI的用户,还可以是构建和出售AI的供应商。
但若企业在地域上存在分隔或在端边应用中对功耗、性价比等有要求,需要进行分布式的算力部署,那么在算力的管理上就会变得更加复杂。由于成本和响应要求,实际业务中有非常多的端边应用,且相对独立,在有条件的情况下实现端云协同,是一种不错的解决方案。端云协同也意味着AI中台不仅要接入数据,在算力管理层面还要管理众多异构的计算单元,所以还需要关注端计算单元状态、算力、数据等维度的通信,以及端侧算力的接入平台及数据汇聚平台,这是一个庞大的工程。
首先是针对一个业务算法的异构算力的管理利用。在计算中,有些类型的计算更适合用CPU处理,而神经网络矩阵运算更适合用NPU、GPU等并行计算来实现,但是由于异构通信、多媒体处理流水线中还有编解码等其他环节,有时候需要根据算法的特性在异构的情况下进行算力的分配,其中分配的内容包括CPU的核心数量、GPU数量、显存等,以求最大化发挥异构算力中每个环节的性能。其次是在多种业务算法并存的情况下对算力进行精细化分配。在实际业务中,往往众多独立的算法共同服务一项业务并分布到不同的算力单元上,但由于算法本身速度有差异,会有“木桶效应”的存在,即因某一算法慢而拖慢了其他算法及整体业务的处理速度。这时需要从不同业务算法性能出发进行算力分配,计算速度慢的模块应该分配更多的计算单元,减少整体等待时间。当然,也可动态分配算力,以保持整体的高性能。
AI中台要有众包功能,即可在其上完成数据分发、多人标注、清洗、审核、合并等一系列流程。面向专业级用户,AI中台应具备更精细化的针对模型参数、训练、评价等进行管理的功能;面向初级用户,AI中台应提供自动化、低代码类服务。
算法的生产过程一般包含调参、训练、评价、应用部署等4个环节。调参是对生产要素的配置,这里的生产要素是指模型、技术参数、数据,以及训练用的超参数等。在训练中要关注是否满足预期,如果不满足,要尽早停止。因此训练过程需要丰富的过程可视化、过程排查工具,以保证模型朝着正确的方向学习,降低训练代价。算法的发布可以理解为投放到App商店中,而应用部署就是下载使用App。如百度的AI市场、华为的好望算法商城。
在AI中台的推理运行部分就需要关注多算法部署与融合的问题。推理训练闭环是指当推理运行的算法判别结果被反馈为误报、精度不高、无法满足新任务时,快速将数据反馈到训练侧并进行快速适配以解决算法出现的问题。在算法完成训练时,通过A/B测试、灰度发布等手段,更新推理运行的算法服务,从而实现在线算法更新。
但是在AI判别时需要将数据上传至公有云。由于公有云不是物理隔离,故数据泄露风险高,在对数据安全要求高的场景中不能使用公有云部署。
在公有云AI中台中,最具代表性的产品有百度的BML和EasyDL,两者的区别主要在面向的用户上。BML面向具有更高专业水平的用户,EasyDL则面向初级用户。
AI中台看似是非常庞大的应用体系,实际上在小规模的业务应用中也可以精简使用,形成以业务闭环为导向的系统,特别是针对长尾、不断新增的需求,“推理-错误反馈-训练-更新”的闭环应用机制是很好的解决方案。以新增类目为例,当新增西红柿类目时,由于算法未训练和识别过西红柿,因此识别效率和准确率都低,尽管西红柿类目录入后系统可以根据相似度进行排序,并保证西红柿排在靠前的位置,但依然需要用户点击选择来确认。用户的点击选择其实就是对算法进行标注,标注的数据可以流转到后台,对算法进行增量训练,如评估算法效果满足要求,则可以在无人使用的时候自动部署更新。
G端场景的特点是数据和应用更倾向于私有化、项目规模化、工程系统化。项目中的定制化需求多,需求碎片化现象严重。以安防摄像机赛道的海康威视为例,它的主营业务就是解决安防市场中的碎片化的需求,并形成了一套成本可控的产品打造方法。
相比以往在相机中将算法固化在硬件中,难以在用户侧更改,软件定义硬件使得硬件的能力可随算法的变更而变化,这样可更加灵活地满足市场需求。
用户侧闭环响应是出让产品生产能力给用户,提升用户侧定制化响应能力,从而满足用户众多的定制化需求。比如通过应用低代码系统和巧妙的无感标注设计,可以实现用户的自主定制和系统自动训练优化。算法只需要针对每个人、每张图片进行“注册”,我们称这种方法为开放集(Open Set)方法。
面对碎片化市场,核心的产品策略是扩张碎片需求适用范围,哪怕扩张的范围不太大,也可能带来产品竞争力的大幅提升。
对于传统的视频流摄像机要获取关键事件和信息,需要全量视频回溯,但通过智能摄像机识别,可以更快关注到特定目标和事件信息,而非仅是事后回溯。在城市治理相关的应用中,智能摄像机一般需要规模化的铺设,单个产品无法形成应用闭环,因此需要完整的端边云结合的整体方案,其中就会包括数据中台、业务中台等。由于边缘算力的大幅提升,智能摄像机的算力在满足自身的视频智能分析的需求外,还可以提供一部分算力给周边的传统视频流摄像机帮它进行智能化升级,这就是智能1拖N方案。华为首先提出了智能1拖N摄像机产品,可大幅减少智能化改造成本。
面向B端的AI产品一般都围绕降本、增效、提质来研发。本质上,这样的AI产品还是在做人可以做,但是机器做效率更高的事情,但是对于“替代”和“辅助”,两者在产品设计和要求上是有巨大差别的。
吴恩达:通过执行试点项目来蓄势:即通过在企业内部找到技术可行、可应用落地、目标可明确量化、6~12个月可以出效果的解决方案。从简单、可行、有价值的项目入手,做出标杆效果。
构建AI产品时,应建立替代方案以及对应的投资回报模型。比如使用AI产品提升了产品良率和质检效率,降低了人力成本,但增加了一次性产品投入、建设费用和后期运行维护成本等。平衡产品的商业价值和用户价值是打造AI产品要考虑的关键点之一。在算法应用中,功能、精度、速度往往是产品竞争力的组成部分,但在一定的成本控制下,三者往往又是相互竞争的关系。三者的相互平衡体现了产品特性设计上的平衡。
对于一些算法型企业,出售算法SDK显然不是一个好的商业模式,特别是在面向碎片化的私有化场景下,算法产品也会变得碎片化,这会使打造业务闭环的成本过高。面对这样的问题,市场上也有好的商业模式值得借鉴,如云厂商的SaaS服务就特别适合中小企业业务。面向规模化企业,以“授人以渔”的方式提供“AI中台+服务咨询”解决方案,可大大降低产品在碎片私有化场景中落地的成本。
面向个人的AI产品的目标是超越现有产品的体验感,业务模式更倾向于“交互产品+运营”,产品更多是一种交互载体,而内容和生态是运营的重点,交互方式和智能程度的提升是直接影响体验的两个方面。人工智能技术的成熟让人机交互向非接触式的语音、视觉交互跨越,让人机交互方式变得越来越像人与人之间的交互。
元宇宙的优势在于模仿真实世界,可以非接触地完成很多在真实世界中因物理极限难以实现的行为,比如在教育方面提供沉浸式、身临其境式的学习体验,又如在远程网络会议中提升现场感,从而提升沟通效率,颠覆现有办公模式。但是在元宇宙中最核心的要素还是人,虚拟数字人则是真实世界通往元宇宙的桥梁。每个人都可以构建自己的虚拟数字人形象,以C2C的方式在元宇宙中生产内容,让其他个体消费。
宏观层面关注的是灵魂拷问:为什么要做这个产品?为什么现在做?现在做还有机会吗?公司的战略意图是什么?
为了充分了解人脸识别产品的情况,你决定先做竞品调研,这样在做用户调研的时候,也就知道该需求对应哪些方案,而且可能已经有很多竞品公司已推销过这些方案,用户说不定比你还懂。针对小规模场景,如常见的楼宇、厂区等的人脸通关,一般会使用边缘计算形态的产品,如带屏显的智能人脸识别设备等。针对大规模的场景,如城市级别的安防人脸识别应用,需要端边云联合的整体解决方案。其中在端侧,主要是智能摄像机。
制造业的发展经历了四个阶段:第一阶段是机械化,即通过杠杆类机械和人工的电机控制,实现人在体力上的解放;第二阶段是自动化,即通过电机等实现了工业过程中的流水线自动化;第三阶段是信息化,即对设备、产品、订单、物流等全工业进行信息化管理;第四阶段是智能化,这是以机器视觉、工业互联网、工业大脑等为契机实现的。上述每个阶段都不是孤立存在的,最终的生产制造必定是四化融合。制造业最核心的问题包括成本高、周期长、投入大、良率低。
解决长尾问题有一个好的方法,就是在客户侧进行优化,也就是将算法的优化工作交给客户。
当前无论是辅助驾驶系统ADAS、驾驶员监控系统DMS,还是L4的自动驾驶系统,都应用了众多以计算机视觉和多传感器融合的AI技术。
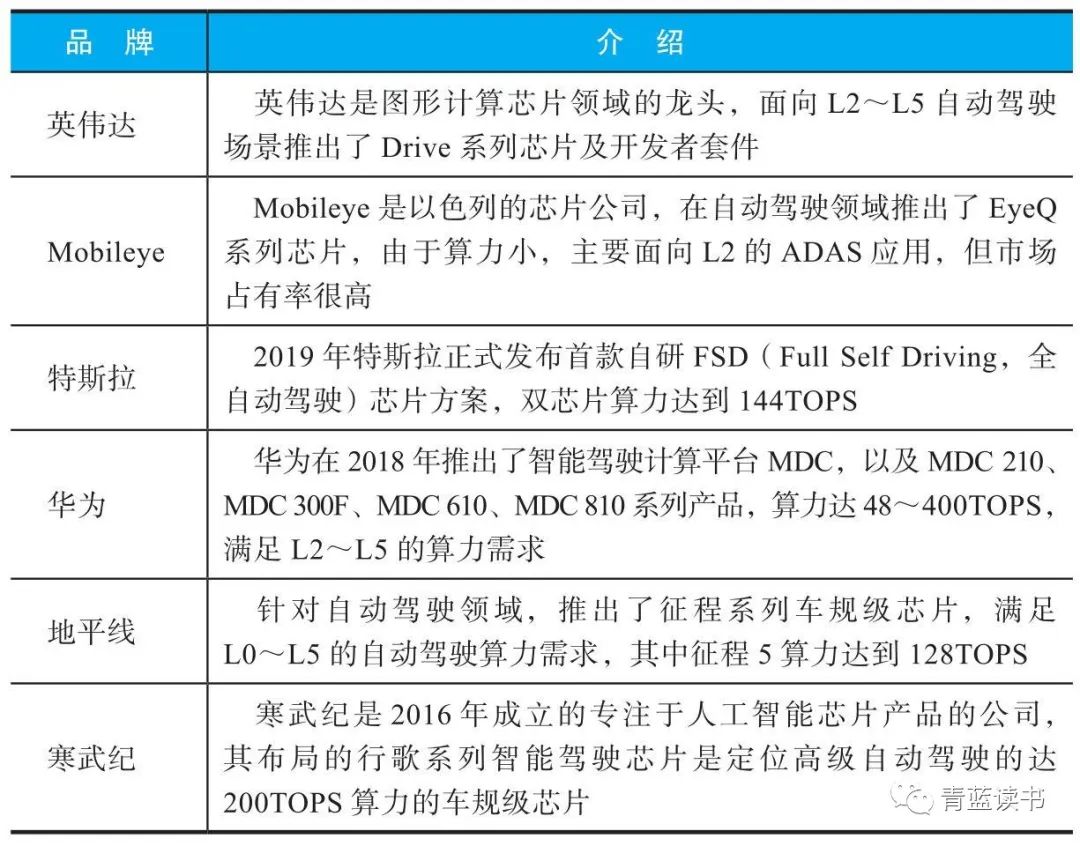
驾驶辅助系统分为预警类、主动安全类型等,这些离散的提供辅助驾驶的模块化系统统称为先进驾驶辅助系统(Advanced Driving Assistance System, ADAS)。ADAS包含众多辅助系统,常见的有前向碰撞预警(Forward Collision Warning, FCW)、车道偏离预警(Lane Departure Warning, LDW)、自适应巡航控制(Adaptive Cruise Control, ACC)、自动泊车系统(Automatic Parking System, APS)等。
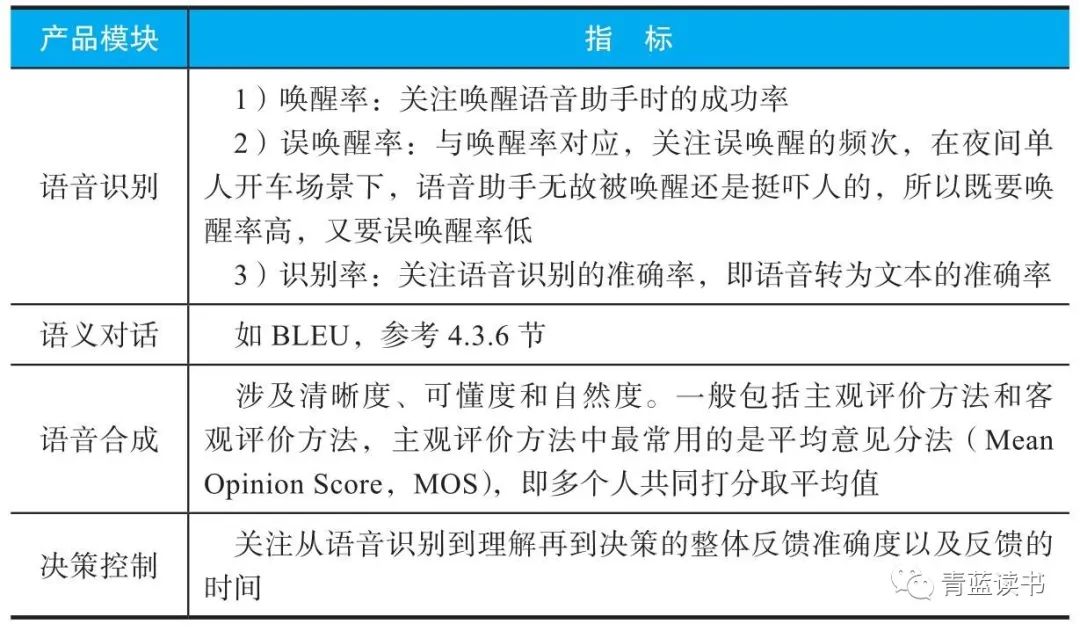
这款产品划分为语音识别、语义对话、语音合成、决策控制四大部分,这四大部分分别模拟了人的听、理解、说、行动四个环节。这四个环节在产品层面关注的目标是不一样的:语音识别关注的是如何听得准,不轻易误报;语义对话更加关注如何理解说话人意图、给说话人满意的反馈;而语音合成关注的是怎么让机器说话的声音自然好听;决策控制关注的是如何在机器理解之后将用户意图转变为一种操作行为。
一般从性质划分,项目可包含商机项目、交付项目、产品开发项目、预研/探索性项目等。商机项目、交付项目更多是面向客户的,产品开发项目、预研/探索性项目更多是面向内部开发的(也包含与外部联合开发)。在AI产品应用中,算法难以一次性适配所有场景,因此面对新项目时,常常需要进行PK测试或者概念验证。如果产品不成熟,有时则需要通过轻量级的定制开发,以满足客户的试用要求。
如何验证AI技术在项目中的可行性呢?概念验证(Proof of Concept, POC),就是为解决可行性问题而存在的环节。由于一家企业仅能代表一家的技术水平,无法代表整个行业,因此,许多商机项目的POC环节会邀请多家企业进行比拼,因此POC环节也是不同企业的PK环节。

交付项目管理是一个专业活儿,根据美国项目管理协会(Project Management Institute, PMI)的PMBOK知识体系,项目管理可分为5个大过程、10个知识领域、49个小过程,该体系全面系统地介绍了项目管理领域的基础理论、方法和工具。其中5个大过程分别是项目启动、规划、执行、监控和收尾;10个知识领域即项目的范围、时间、成本、质量、资源、沟通、风险、采购、相关方、运维,其中包括与这10个领域知识相关的管控方式和方法。
在POC阶段哪怕只测试一部分功能,也应该在内部向销售商务人员甚至向客户说明现有产品的交付范围,以避免他人对产品预期过高,导致交付失败。
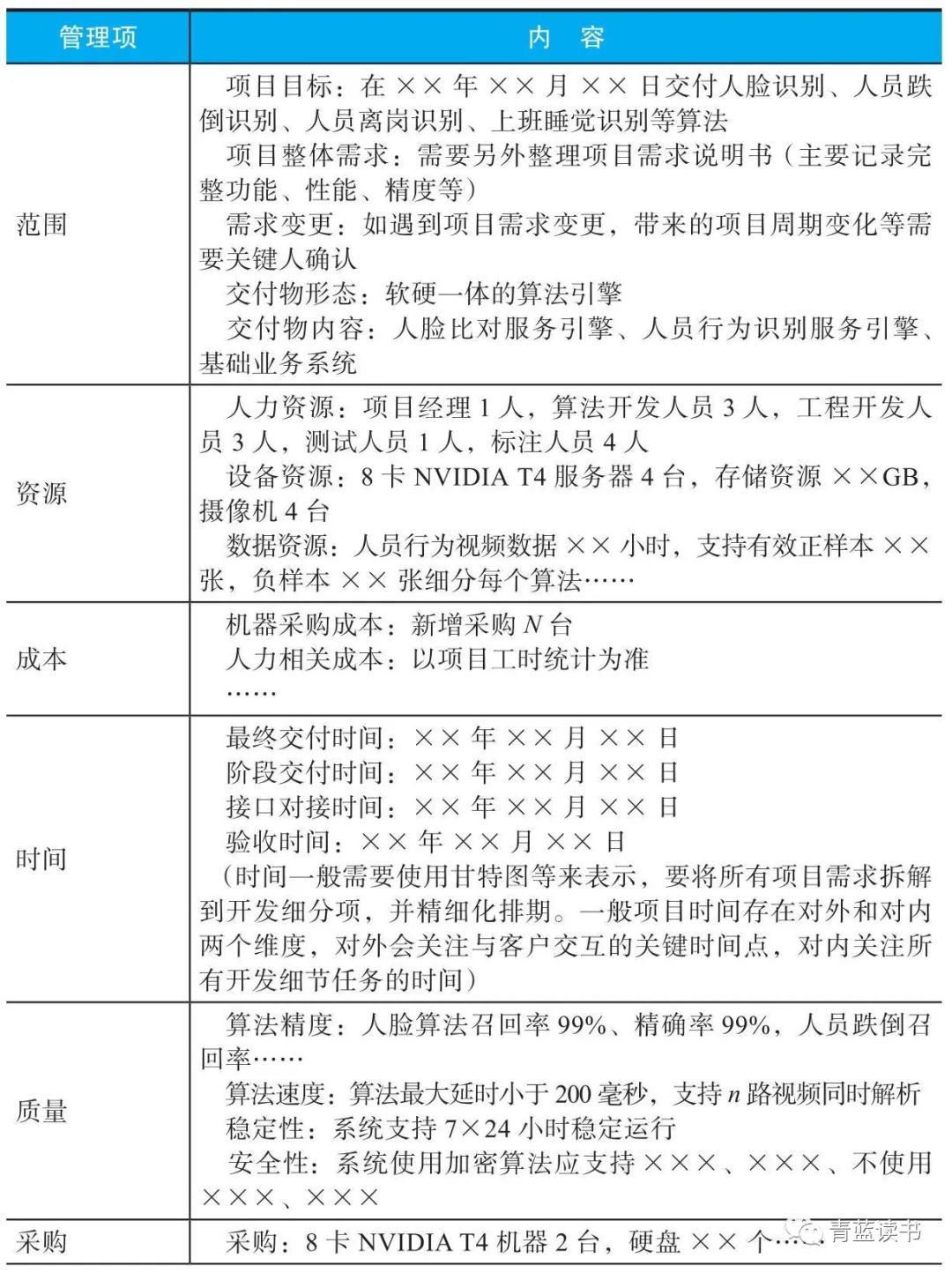
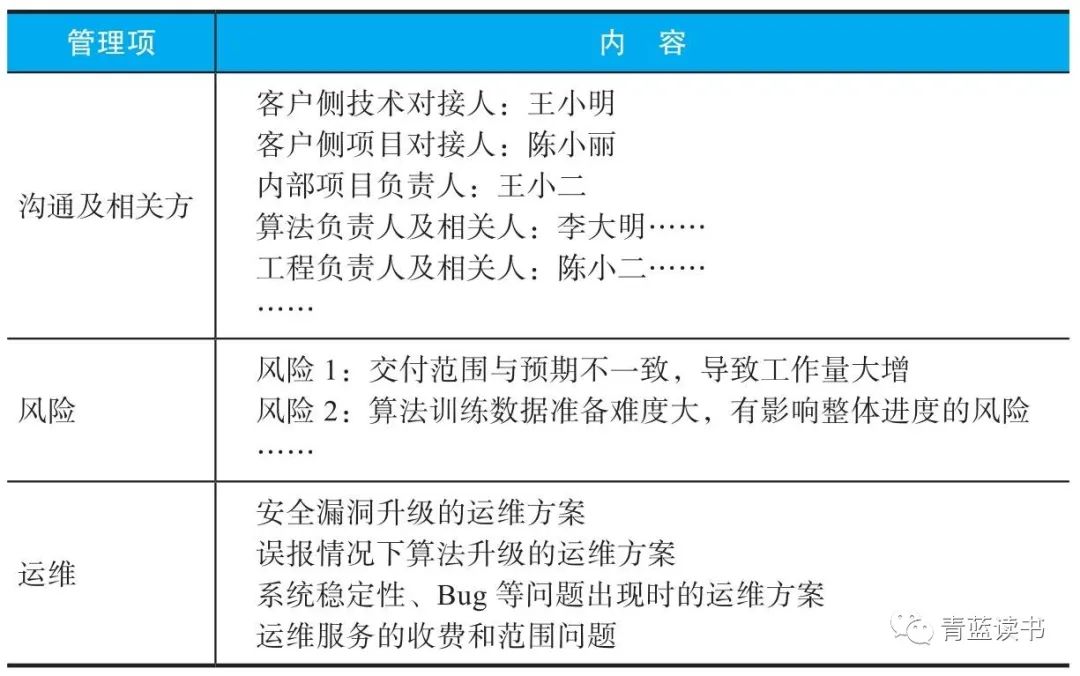
对需求的描述一定要清晰完整,应与客户用多种描述方式确认,除了口头描述,还应该利用邮件、图像等方式。例如在沟通算法需求时,对于“边界是什么”需要核对清楚,这样才能避免后期的麻烦。在算法边界问题上,最好的沟通方式是用样例图。
在交付初期,除了明确交付需求,还要明确验收测试的方案,要精细化到使用的数据、计算方式等,并通过公开透明的形式进行内外同步。这样一方面可避免毫无必要的争论,另一方面可以明确目标,帮助项目快速完成验收。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











