






 这篇文章概述了近年来在多模态大模型领域的关键进展,介绍了13个开源模型,如NExT-GPT和DreamLLM,展示了它们在自然语言处理、计算机视觉和多模态理解方面的突破。模型的架构创新和优化,以及在特定场景的应用实例,预示着多模态大模型时代的到来和广泛应用潜力。
这篇文章概述了近年来在多模态大模型领域的关键进展,介绍了13个开源模型,如NExT-GPT和DreamLLM,展示了它们在自然语言处理、计算机视觉和多模态理解方面的突破。模型的架构创新和优化,以及在特定场景的应用实例,预示着多模态大模型时代的到来和广泛应用潜力。
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)在人工智能领域取得了显著的进展,特别是在自然语言处理、计算机视觉和多模态理解方面。这些模型能够理解和生成多种类型的数据,如文本、图像、音频和视频,为多模态学习和应用提供了强大的工具。
今天给大家汇总了13个开源多模态大模型,这些模型在各自的领域中刷新了多个SOTA记录,每个模型都将附上相关的论文和代码,一起看看多模态大模型的最新研究成果吧!
论文PDF和开源代码都整理好了
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取🆓

架构和创新
1、NExT-GPT: Any-to-Any Multimodal LLM(ICLR 2024)
NExT-GPT:任意对任意多模态 LLM
简述:本文提出了通用任意对任意MM-LLM系统NExT-GPT,该系统将LLM与多模态适配器和不同解码器连接,使NExT-GPT能感知输入并以任意组合生成文本、图像、视频和音频输出。利用现有高性能编码器和解码器,NExT-GPT仅需少量参数(1%)进行调优,有利于低成本训练和扩展。此外,研究人员引入模态切换指令调优(MosIT),并整理高质量数据集,使NExT-GPT具备复杂跨模态语义理解和内容生成能力。

2、DreamLLM: Synergistic Multimodal Comprehension and Creation(ICLR 2024)
DreamLLM:协同多模态理解与创造
简述:本文提出了DreamLLM,这是一个学习框架,它首先实现了多功能多模态大型语言模型(MLLM),该模型强调了多模态理解和创作之间的协同作用。DreamLLM 通过直接在原始多模态空间中采样来生成语言和图像,避免了外部特征提取器的局限性。此外,它能够生成原始交错文档,包括文本、图像和非结构化布局。DreamLLM是首个能生成自由格式交错内容的MLLM,实验证明,它作为零样本多模态通才表现出色,从增强的学习协同作用中获益。
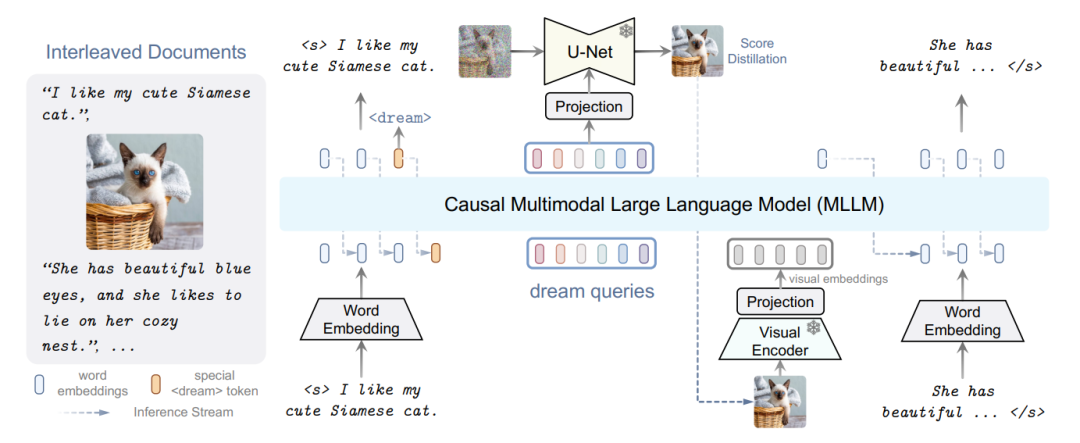
3、Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization(ICLR 2024)
具有动态离散视觉标记化的 LLM 统一语言视觉预训练
简述:本文提出了一种新的多模态大模型LaVIT,它通过将视觉内容转换为可被语言模型处理的离散标记,实现了视觉和语言数据的统一处理。这种方法打破了传统方法中将视觉输入仅作为提示的局限性,使LaVIT能够无差别地处理图像和文本,提高了模型在视觉语言任务中的性能。实验结果表明,LaVIT在处理大规模视觉语言任务方面优于现有模型。
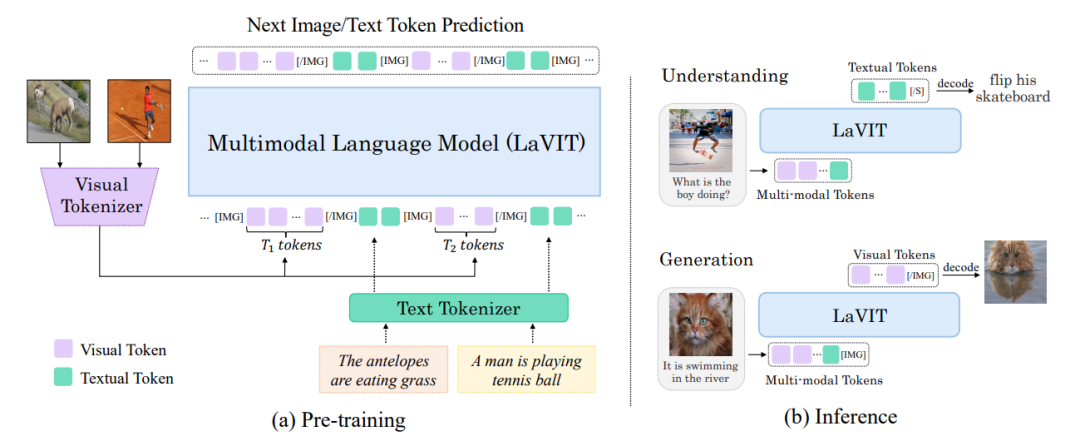
4、MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
MoE-LLaVA:大型视觉语言模型专家组合
简述:本文提出了一种名为MoE-tuning的新的大型视觉语言模型(LVLM)训练策略,该策略构建了一个参数数量多但计算成本恒定的稀疏模型,解决了多模态学习和模型稀疏性相关的性能下降问题。还提出了MoE-LLaVA框架,一种基于MoE的稀疏LVLM架构,它在部署期间只激活部分专家,从而减少了计算成本。实验表明,MoE-LLaVA在视觉理解方面表现出色,并减少了模型输出的幻觉。MoE-LLaVA使用30亿个稀疏激活的参数,在各种视觉理解数据集上性能与LLaVA-1.5-7B相当,甚至在某些基准测试中超过了LLaVA-1.5-13B。
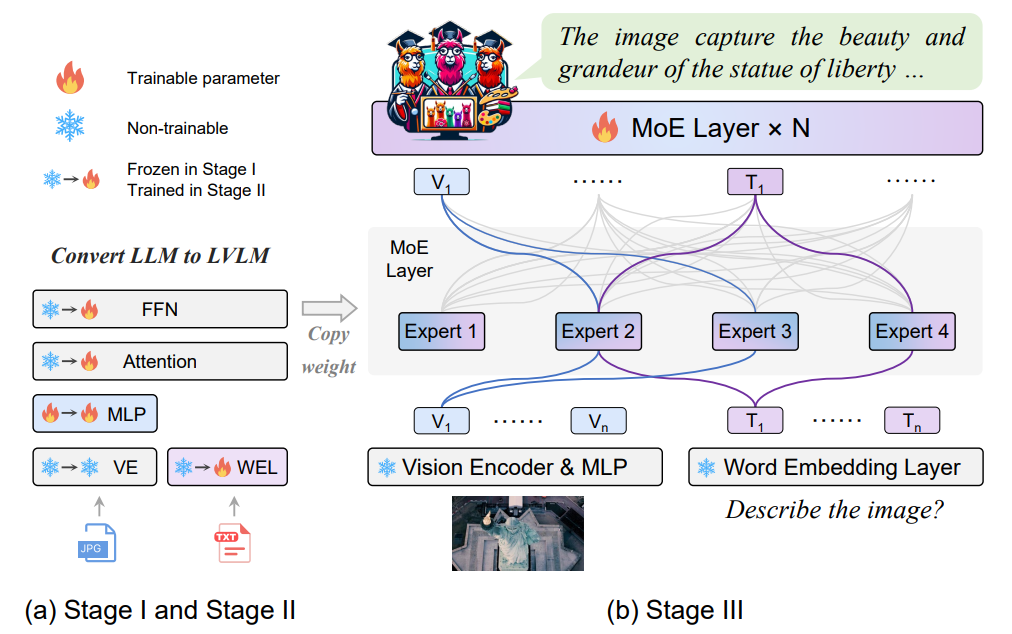
5、LEGO:Language Enhanced Multi-modal Grounding Model
语言增强型多模态接地模型
简述:现有的多模态模型重点捕捉每个模态内的全局信息,但忽视了跨模态感知局部信息的重要性。为了解决这个问题,本文提出了LEGO,一个语言增强的多模态定位模型,LEGO不仅捕捉全局信息,还在需要细致理解输入数据内部细节的任务上表现出色,具有精确的识别和定位能力。
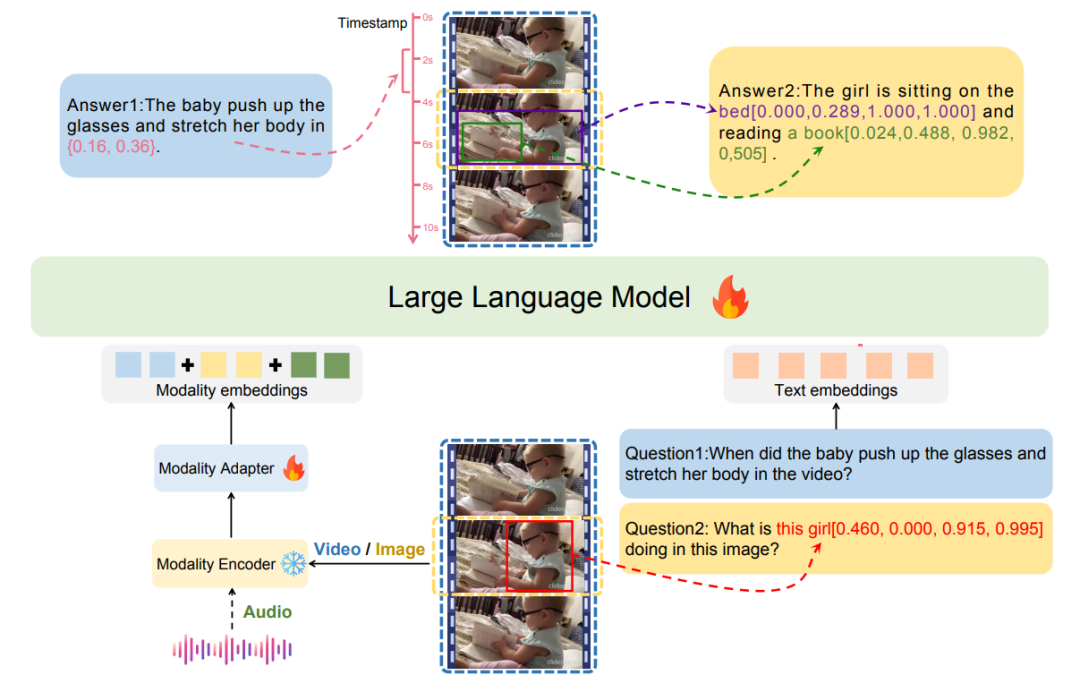
6、InternLM-XComposer2: Mastering Free-form Text-ImageComposition and Comprehension in Vision-Language Large Models
InternLM-XComposer2:掌握视觉语言大模型中的自由格式文本图像合成和理解
简述:本文提出了 InternLM-XComposer2,一种先进的视觉语言模型,擅长自由格式的文本图像合成和理解,该模型能从多输入创建定制内容,超越传统视觉语言理解。采用部分 LoRA 方法,专为图像标记调整参数,保持语言知识完整,平衡视觉理解和文本创作。实验显示,基于InternLM2-7B的InternLM-XComposer2在长文本多模态创作中表现优异,视觉语言理解能力超越现有模型,某些评估与GPT-4V和Gemini Pro相当或更佳,展现卓越多模态理解能力。

7、mPLUG-PaperOwl: Scientific Diagram Analysis with the Multimodal Large Language Model
mPLUG-PaperOwl:使用多模态大型语言模型进行科学图表分析
简述:本文提出了多模态图理解数据集M-Paper,解析优质论文的Latex源文件,将图表与相关段落对齐,形成专业图表分析样本。M-Paper是首个支持联合理解多个科学图表的数据集,包括图像或Latex格式的图形和表格。为确保副驾驶与用户意图一致,还引入“轮廓”作为控制信号,可由用户直接给出或修改。使用最先进的 Mumtimodal LLM 进行的综合实验表明,在这个数据集上进行训练显示出更强的科学图表理解性能,包括图表标题、图表分析和大纲推荐。

论文PDF和开源代码都整理好了
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取🆓
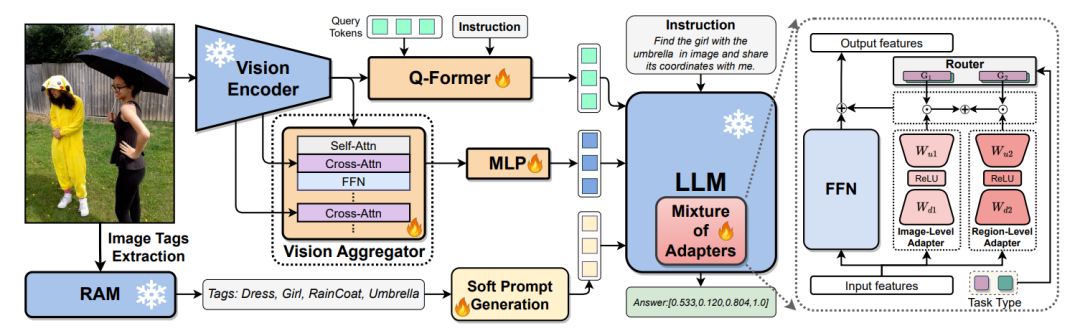
8、LION : Empowering Multimodal Large Language Modelwith Dual-Level Visual Knowledge
LION:赋能具有双级视觉知识的多模态大型语言模型
简述:本文提出了LION,一种双层次的视觉知识增强多模态大型语言模型,通过在细粒度和高级语义层面整合视觉知识来提高模型的性能。LION使用视觉聚合器整合细粒度空间感知视觉知识,并采用阶段级指令调优策略减少任务间的冲突。此外,它还利用软提示方法结合图像标签的高级语义,以减轻不完美预测标签的影响。实验结果显示,LION在多个多模态基准测试中优于现有模型。
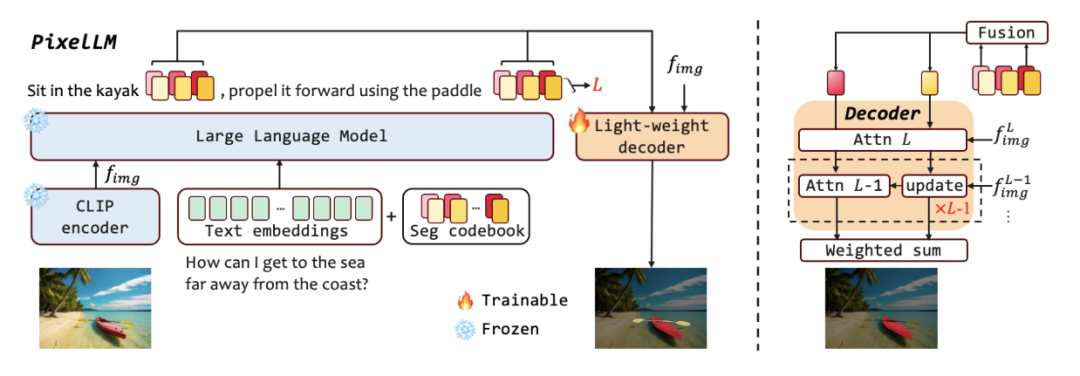
9、PixelLM: Pixel Reasoning with Large Multimodal Model
PixelLM:使用大型多模态模型进行像素推理
简述:本文提出了PixelLM,这是一个用于像素级推理和理解的有效且高效的模型,它的核心是一个轻量级的像素解码器和全面的分割码本。PixelLM通过解码器生成掩码来编码详细的目标信息,避免了需要额外昂贵分割模型的需求。研究人员还提出了一个目标细化损失来提高模型区分多个目标的能力。PixelLM在多个像素级图像推理和理解任务中表现优异,超越了成熟的方法。
模型优化和特定场景应用
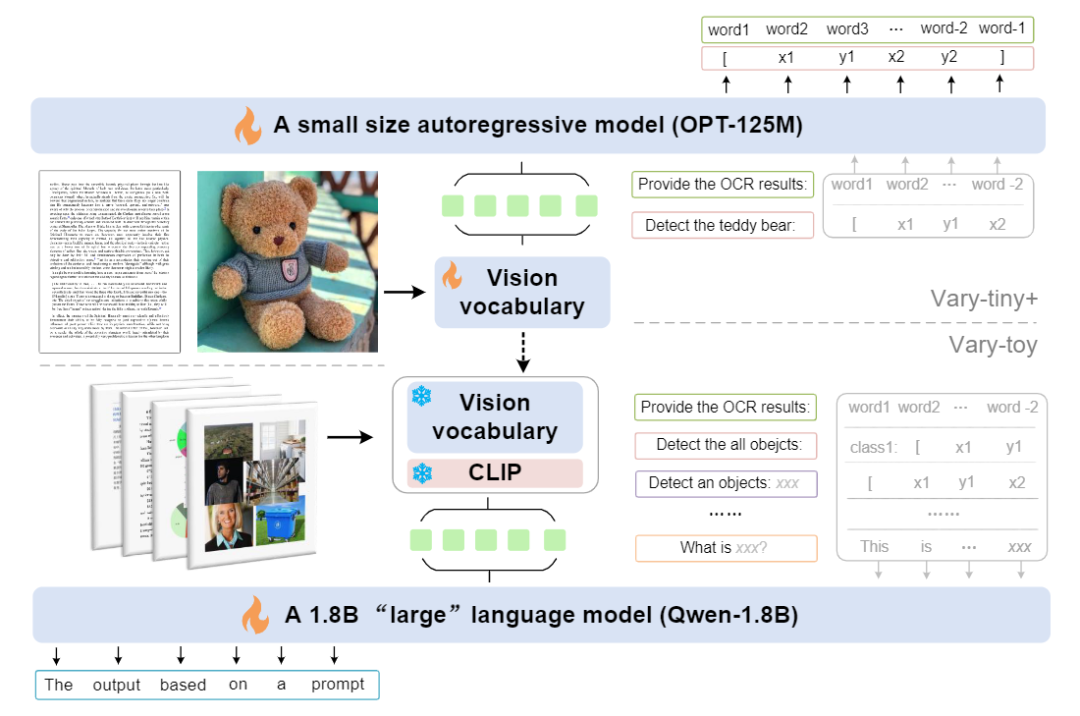
10、Small Language Model Meets with Reinforced Vision Vocabulary
小型语言模型与增强视觉词汇相遇
简述:本文提出了Vary-toy,这是一个小型化的 Vary 和 Qwen-1.8B 模型,适合在消费级GPU上训练和部署。Vary-toy 通过改进的视觉词汇,不仅保留了 Vary 的特性,还增强了通用性。在实验中,Vary-toy 在多个基准测试中取得了不错的成绩,如 DocVQA 的 65.6% ANLS、ChartQA 的 59.1% 准确率、RefCOCO 的 88.1% 准确率和 MMVet 的 29% 准确率。
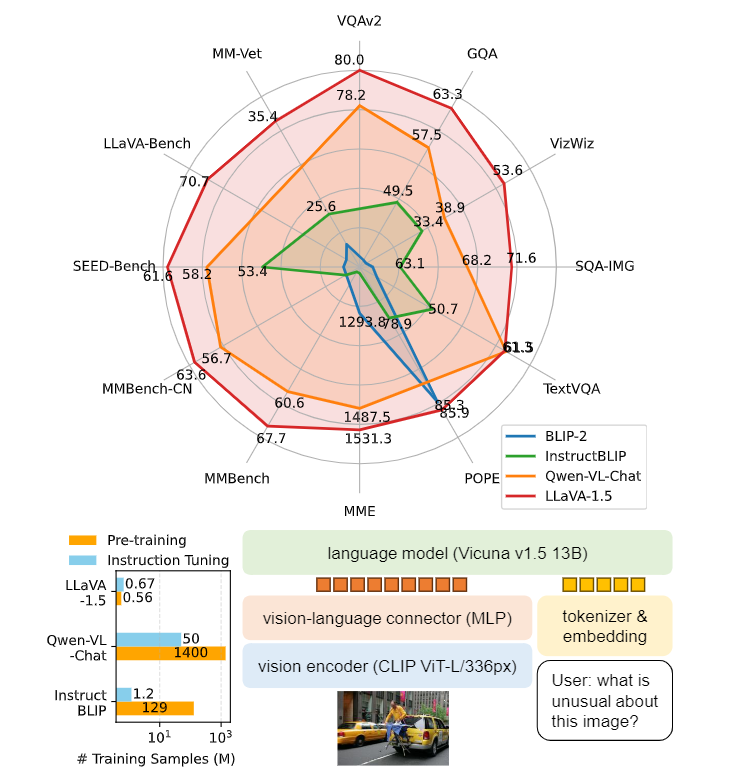
11、Improved Baselines with Visual Instruction Tuning
通过可视化指令调优改进基线
简述:大型多模态模型(LMM)在视觉教学调优方面取得进展,LLaVA 的全连接视觉语言跨模态连接器表现出色,数据效率高。本文通过简单修改 LLaVA,使用 MLP 投影和 VQA 数据,建立更强大基线,在 11 个基准测试中实现最先进。最终的 13B 检查点仅使用 1.2M 数据,在单个节点上训练完成。这使得最先进的 LMM 研究更易获得。
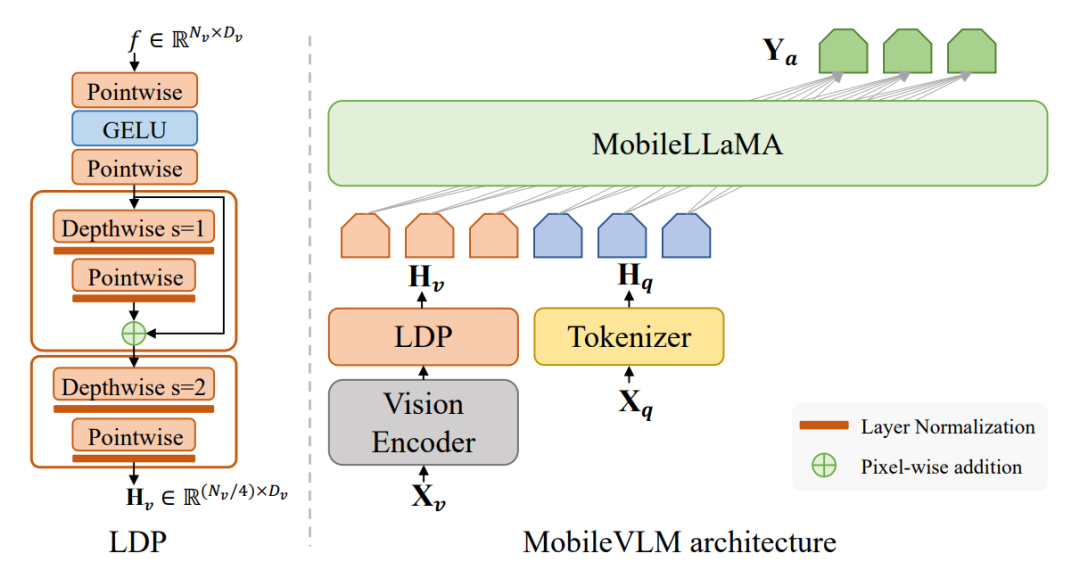
12、MobileVLM: A Fast, Strong and Open Vision Language Assistantfor Mobile Devices
MobileVLM:适用于移动设备的快速、强大和开放的视觉语言助手
简述:本文提出了 MobileVLM,一个为移动设备设计的强大多模态视觉语言模型。它结合了专为移动设备设计的语言模型和预训练的多模态视觉模型,通过高效的投影仪实现跨模态交互。MobileVLM在典型的视觉语言模型基准测试中表现出色,与更大模型相比毫不逊色,并且在高通骁龙 888 CPU 和 NVIDIA Jeston Orin GPU 上对其进行了性能评估,分别达到了每秒 21.5 个令牌和 65.3 个令牌的推理速度,这是行业领先的成绩。
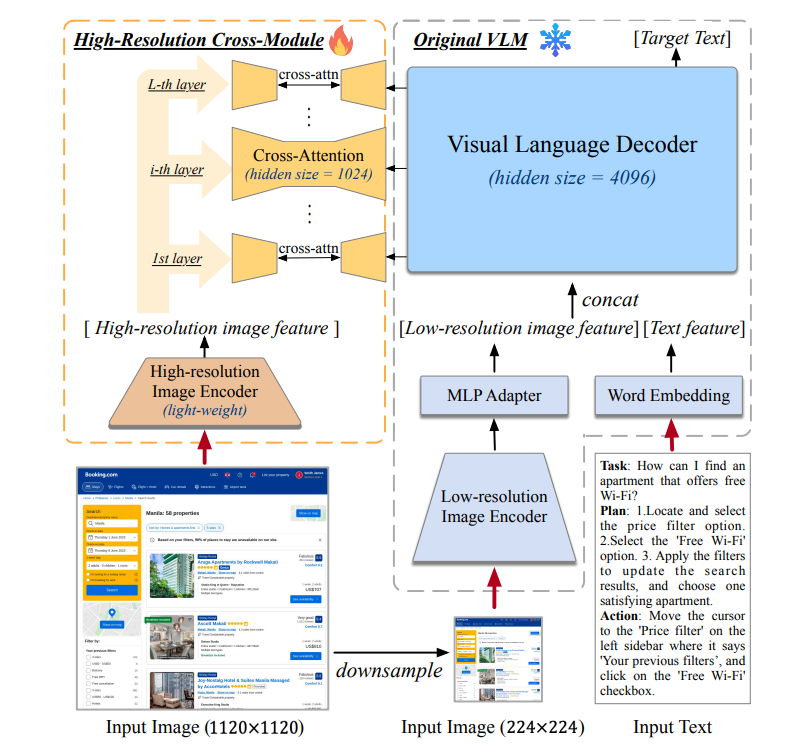
13、CogAgent:A Visual Language Model for GUI Agents
CogAgent:GUI 代理的可视化语言模型
简述:本文介绍了CogAgent,一个180亿参数的视觉语言模型(VLM),专门用于GUI理解和导航。CogAgent使用低和高分辨率图像编码器,支持分辨率为1120*1120的输入,能识别微小页面元素和文本。作为通用VLM,CogAgent在多个基准测试上实现最先进技术,包括VQAv2、OK-VQA等。它仅使用屏幕截图作为输入,优于基于LLM的方法,这些方法使用提取的HTML文本。
人工智能大模型越来越火了,离全民大模型的时代不远了,大模型应用场景非常多,不管是做主业还是副业或者别的都行,技多不压身,我这里有一份全套的大模型学习资料,希望给那些想学习大模型的小伙伴们一点帮助!
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











